常用的数据挖掘软件
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
数据挖掘工具软件介绍(weka)

11
WEKA EXPLORER CLASSIFY
分类器输出文本
Classifier output 区域的文本有一个滚动条以便浏览结果。按住 Alt 和 Shift 键,在这个区域点击鼠标左键,会出现一个对话框, 让你用各种格式(目前可用 JPEG 和 EPS)保存输出的结果。
输出结果
16
WEKA EXPLORER Visualize
3. Polygon. 创建一个形式自由的多边形并选取其中的点。左键点 击添加多边形的顶 点,右键点击完成顶点设置。起始点和最终点会自动连接起来因 此多边形总是闭 合的。 4. Polyline. 可以创建一条折线把它两边的点区分开。左键添加折 线顶点,右键结束 设置。折线总是打开的(与闭合的多边形相反)。 使用 Rectangle,Polygon 或 Polyline 选取了散点图的一个区域后 ,该区域会变成灰色。这时点击Submit 按钮会移除落在灰色区域 之外的所有实例。点击Clear 按钮会清除所选区域而不对图形产 生任何影响。
17
Weka 试验(Experiment)
Experimenter 有两种模式:一种具有较简单的界面, 并提供了试验所需要的大部分功能,另一种则 提供了一个可以使用 Experimenter 所有功能的界面。 你可使用 Experiment Configuration Mode 单选 按钮在这两者间进行选择。 ������ Simple ������ Advanced
8
WEKA EXPLORER
处理属性
数据分析的所有工具和技术

数据分析的所有工具和技术在当今数字化时代,数据已经成为了企业以及个人决策制定中不可或缺的一部分。
而数据分析则是将数据转化为有用信息,帮助人们做出更好的决策。
但是,在进行数据分析的过程中,需要使用各种工具和技术。
在本文中,我们将介绍数据分析中应用广泛的工具和技术。
一、数据分析工具1. Excel:Excel是最常见的数据分析工具之一。
利用Excel可以进行各种数据处理和计算。
Excel还提供了各种图表和可视化工具,方便人们更好地理解和展示数据。
2. Tableau:Tableau是一款基于云的数据可视化和分析平台,可以帮助人们快速构建各种交互式图表和报表。
3. Python:Python是一种高级编程语言,可以进行数据处理、分析和可视化。
Python还提供了丰富的库和工具,例如Pandas、Numpy和Matplotlib等,可以帮助人们进行高效的数据分析和可视化。
4. R语言:R语言是一种专门用于统计分析和可视化的编程语言。
它提供了丰富的数据分析和可视化工具以及各种包,例如ggplot2和dplyr等。
5. SAS:SAS是一种商业化的统计分析软件,可以用于各种数据分析和建模领域。
它提供了强大的数据分析和数据挖掘工具,可以在各种商业和学术领域得到广泛应用。
二、数据分析技术1. 数据挖掘:数据挖掘是通过自动或半自动的方式从大型数据集中提取出有用的信息或模式的过程。
在数据挖掘中,常用的技术包括分类、聚类、关联规则和异常检测等。
2. 机器学习:机器学习是一种人工智能领域中的技术,可以帮助人们使用算法和模型来自动化数据分析和决策制定。
在机器学习中,常用的技术包括监督学习、无监督学习和强化学习等。
3. 数据可视化:数据可视化是将数据转换成更易于人们理解的图表和图像的过程。
常用的数据可视化技术包括直方图、散点图、线性回归和热力图等。
4. 预测分析:预测分析是利用历史数据和模型来预测未来事件的发展趋势。
常用的预测分析技术包括趋势分析、时间序列分析、假设检验和回归分析等。
款常用的数据挖掘工具推荐
12款常用的数据挖掘工具推荐数据挖掘工具是使用数据挖掘技术从大型数据集中发现并识别模式的计算机软件。
数据在当今世界中就意味着金钱,但是因为大多数数据都是非结构化的。
因此,拥有数据挖掘工具将成为帮助您获得正确数据的一种方法。
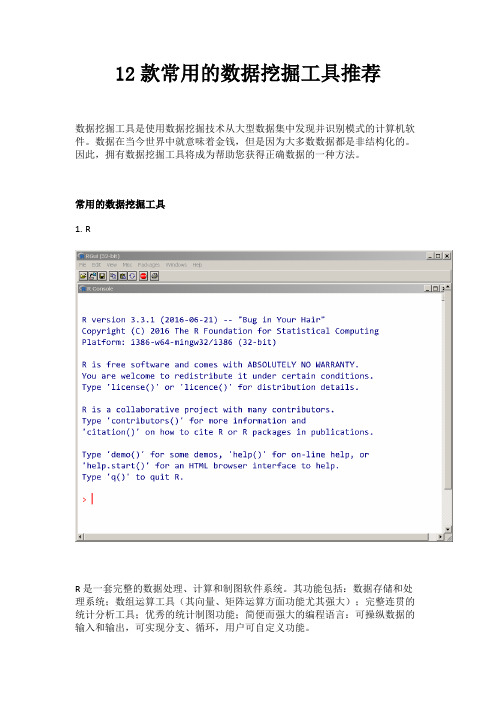
常用的数据挖掘工具1.RR是一套完整的数据处理、计算和制图软件系统。
其功能包括:数据存储和处理系统;数组运算工具(其向量、矩阵运算方面功能尤其强大);完整连贯的统计分析工具;优秀的统计制图功能;简便而强大的编程语言:可操纵数据的输入和输出,可实现分支、循环,用户可自定义功能。
2.Oracle数据挖掘(ODM)Oracle Data Mining是Oracle的一个数据挖掘软件。
Oracle数据挖掘是在Oracle 数据库内核中实现的,挖掘模型是第一类数据库对象。
Oracle数据挖掘流程使用Oracle 数据库的内置功能来最大限度地提高可伸缩性并有效利用系统资源。
3.TableauTableau提供了一系列专注于商业智能的交互式数据可视化产品。
Tableau允许通过将数据转化为视觉上吸引人的交互式可视化(称为仪表板)来实现数据的洞察与分析。
这个过程只需要几秒或几分钟,并且通过使用易于使用的拖放界面来实现。
5. ScrapyScrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
6、WekaWeka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
Weka高级用户可以通过Java编程和命令行来调用其分析组件。
同时,Weka也为普通用户提供了图形化界面,称为Weka KnowledgeFlow Environment和Weka Explorer。
和R相比,Weka在统计分析方面较弱,但在机器学习方面要强得多。
数据处理分析及软件应用

数据处理分析及软件应用数据处理和分析是指在获取和收集数据后,对数据进行处理和分析的过程。
它的目的是帮助我们从数据中发现模式、趋势、关联和异常,并基于这些发现做出决策和预测。
数据处理和分析的过程可以通过各种软件工具来完成,下面我将介绍一些常用的数据处理和分析软件应用。
1. Microsoft Excel: Microsoft Excel是一种功能强大的电子表格软件,广泛应用于数据处理和分析。
它提供了各种数据处理和分析函数,如排序、筛选、计数、求和、平均值、标准差等。
此外,Excel还支持图表和图形的创建,可以用来可视化数据结果。
2. MATLAB: MATLAB是一种用于科学计算和数据分析的编程环境和编程语言。
它提供了丰富的数据处理和分析函数,可以处理各种类型的数据。
MATLAB还具有强大的可视化功能,可以生成高质量的图表和图形。
3. Python: Python是一种通用的编程语言,也被广泛用于数据处理和分析。
Python拥有丰富的库和工具,如NumPy、Pandas、SciPy和Matplotlib,这些库提供了各种数据处理和分析功能。
Python还具有高度灵活性和可扩展性,可以满足各种不同的数据处理和分析需求。
4. R: R是一种用于统计计算和数据分析的编程语言和环境。
它提供了丰富的统计和图形函数,可以进行各种复杂的数据处理和分析。
R还拥有一个强大的包管理系统,用于扩展其功能。
5. Tableau: Tableau是一种用于数据可视化和探索性分析的商业智能工具。
它提供了直观易用的界面,可以帮助用户在数据中发现模式和趋势。
Tableau支持多种图表和图形类型,用户可以通过拖放方式创建和订制图表。
6. SPSS: SPSS是一种专业的统计分析软件,被广泛用于各种统计分析和数据挖掘任务。
它具有全面的统计方法和功能,支持从数据导入到模型建立和结果解释的整个工作流程。
上述软件应用都在数据处理和分析领域具有广泛的应用,并且每种软件都有其特点和优势。
数据挖掘与分析软件使用教程

数据挖掘与分析软件使用教程一、介绍数据挖掘与分析软件的概念及应用领域数据挖掘与分析软件是指通过对大量数据进行处理和分析,从中发掘潜在的模式、关系和规律,以便帮助用户做出决策和预测的工具。
它在各个领域都有着广泛的应用,如业务智能、市场调研、金融风控、医疗诊断等。
在业务智能领域,数据挖掘与分析软件可以帮助企业通过对销售数据、客户行为等信息进行分析,找出产品的热销点、客户的偏好,从而指导市场营销策略的制定。
在金融风控领域,数据挖掘与分析软件可以通过对客户的信用记录、历史交易数据等进行分析,帮助银行等金融机构评估客户的风险,制定更科学的贷款策略。
在医疗诊断领域,数据挖掘与分析软件可以对大量的临床数据进行分析,辅助医生进行疾病的诊断和治疗,提高医疗水平。
二、常见的数据挖掘与分析软件1. SASSAS(Statistical Analysis System)是一款功能强大的数据挖掘与分析软件,提供了丰富的数据处理和分析函数。
它支持多种数据格式的导入和导出,灵活的数据变换和清洗,可以进行数据可视化和统计分析等操作。
2. SPSSSPSS(Statistical Package for the Social Sciences)是一款统计分析软件,广泛应用于社会科学和市场研究等领域。
它提供了各种统计分析方法和模型,可以进行数据描述、推断性统计分析等。
3. R语言R语言是一种开源的数据挖掘与分析软件,具有丰富的数据分析和建模函数。
它提供了强大的统计分析和绘图功能,支持数据可视化和报表生成,可以进行数据预处理、机器学习、深度学习等。
三、数据挖掘与分析软件的基本操作1. 数据导入和清洗数据挖掘与分析软件通常支持多种数据格式的导入,如文本文件、Excel表格、数据库等,用户可以根据实际需求选择导入方式。
导入数据后,需要进行数据清洗操作,去除重复值、缺失值等,以确保数据的质量。
2. 数据变换和特征工程在进行数据分析之前,常常需要对数据进行变换和处理,以提取出更有价值的特征。
研究生科研数据分析软件

研究生科研数据分析软件随着科学技术的进步,数据分析在研究生科研中的重要性也日益凸显。
为了更高效地处理和分析大量的科研数据,许多研究生借助科研数据分析软件来完成各种统计和数据挖掘工作。
本文将介绍几种常用的研究生科研数据分析软件。
1. SPSS(Statistical Package for the Social Sciences)SPSS是一种广泛使用的统计分析软件,特别适用于社会科学领域的数据分析。
它提供了丰富的分析工具和统计方法,包括描述性统计、回归分析、方差分析等。
SPSS具有友好的用户界面,操作简单易学,适合初学者使用。
2. MATLABMATLAB是一种强大的科学计算和数据可视化软件,广泛应用于各个学科的科研工作中。
它提供了丰富的数学函数和工具箱,可用于数据分析、模拟和优化等。
MATLAB还支持自定义算法和编程,因此对于需要灵活性和个性化定制的研究项目来说,是一个理想的选择。
3. R语言R语言是一种免费的开源编程语言和环境,主要用于统计计算和图形绘制。
它拥有强大的数据分析和统计建模功能,并具有丰富的数据处理和可视化函数库。
由于R语言开放源代码,研究生们可以方便地自行编写和共享自己的数据分析程序,并与其他研究人员进行交流和合作。
4. PythonPython是一种通用的编程语言,也被广泛应用于科学计算和数据分析领域。
Python具有丰富的科学计算库(如NumPy、Pandas和Matplotlib),可以进行数据处理、统计分析和可视化。
Python还具有简单易用的语法和良好的可读性,方便研究生们进行快速原型开发和实验。
5. SAS(Statistical Analysis System)SAS是一个完整的统计分析系统,适用于各个领域的数据分析和决策支持。
SAS提供了丰富的数据处理和分析功能,包括描述性统计、数据挖掘、机器学习等。
它也具备高效的图形绘制和报表生成能力。
尽管SAS是商业软件,但在一些特定的科研领域中仍然得到广泛使用。
常用统计数据分析软件

常用统计数据分析软件数据分析在现代社会中扮演着越来越重要的角色,而统计数据分析软件就是其中不可或缺的工具之一。
在大数据时代,数据的处理和分析变得非常复杂和庞大,需要借助先进的统计分析软件来加快分析和决策过程。
本文将介绍一些常用的统计数据分析软件,并讨论它们的特点和优势。
1. SPSSSPSS(统计数据分析软件)是一种统计分析软件,它具有强大的功能和易于使用的界面。
SPSS可以用于数据管理、数据清理、描述性统计、假设检验、回归分析、聚类分析、因子分析等。
它可以帮助用户探索和理解数据,支持多种数据类型和数据格式,适用于不同行业和领域的数据分析工作。
2. SASSAS(统计分析系统)是另一种流行的统计数据分析软件,它提供了广泛的数据处理和分析功能。
SAS可以用于数据的整理和准备、统计分析、数据挖掘和预测建模等。
SAS具有丰富的统计算法和模型,可以针对不同类型的数据进行分析和建模。
3. RR是一种开源的统计计算和图形软件,它被广泛应用于数据科学和统计分析领域。
R具有丰富的包和工具,可以进行各种统计分析、数据可视化、机器学习和深度学习等。
R的优势在于它的灵活性和可扩展性,用户可以自行编写代码和算法来实现特定的分析任务。
4. ExcelExcel是一种广泛使用的电子表格软件,它也提供了一些简单的统计分析功能。
Excel可以用于数据输入、数据清理、数据可视化和基本的统计计算等。
虽然Excel的统计功能相对有限,但对于一些简单的数据分析任务仍然很有用。
5. PythonPython是一种通用的编程语言,也被广泛应用于数据分析和统计建模。
Python有许多强大的库和框架,如Pandas、NumPy、Matplotlib和SciPy,可以支持各种数据处理和分析任务。
通过编写Python代码,用户可以实现复杂的统计分析和机器学习算法。
总结而言,常用的统计数据分析软件包括SPSS、SAS、R、Excel和Python等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
<4>
数据挖掘软件介绍
Knime:数据流模式的挖掘软件
类似数据流(data flow)的方式来建立分析挖掘流 程
用户可选择性地运行一些或全部的分析步骤 用Java开发的,可以扩展使用Weka中的挖掘算法 通过插件的方式,用户可以加入自己的处理模块,
@attribute children numeric 改为
@attribute children {0,1,2,3}
<16>
数据预处理
“age”和“income”的离散化需要借助WEKA中名为 “Discretize”的Filter来完成
点击“choose”后,出现一颗“Filter树” ,逐级找到 “weka.filters.unsupervised.attribute.Discretize”,点击 后进行离散化,例如“bins=3”则会将属性分成三段
用Weka进行分类
测试选项
应用选定的分类器后得到的结果会根据 Test Option 一栏中 的选择来进行测试。共有四种测试模式: • Using training set. 根据分类器在用来训练的实例上的预测 效果来评价它。 • Supplied test set. 从文件载入的一组实例,根据分类器在这 组实例上的预测效果来评价它。点击 Set… 按钮将打开一个 对话框来选择用来测试的文件。 • Cross-validation. 使用交叉验证来评价分类器,所用的折数 填在Folds 文本框中。 • Percentage split. 从数据集中按一定百分比取出部分数据放 在一边作测试用,根据分类器这些实例上预测效果来评价它 。取出的数据量由% 一栏中的值决定。
Classifier model (full training set). 用文本表示的基于整个训练集的分类模型
所选测试模式的结果可以分解为以下几个部分
Summary. 一列统计量,描述了在指定测试模式下,分类器预测 class 属性的 准确程度。
Detailed Accuracy By Class. 更详细地给出了关于每一类的预测准确度的描述 Confusion Matrix. 给出了预测结果中每个类的实例数。其中矩阵的行是实际
—— 做中国领先的科研资源提供商
《大数据处理》配套课件
第七章 常用的数据挖掘软件
总课时:6小时(实验:4小时)
<1>
提纲
➢ 数据挖掘软件介绍 ➢ Weka ➢ RapidMiner ➢ Knime
<2>
数据挖掘软件介绍
Weka:名气最大的机器学习和数据挖掘软件
高级用户可以通过Java编程和命令行来调用其分析 组件
的类,矩阵的列是预测得到的类,矩阵元素就是相应测试样本的个数。
<21>
用Weka进行分类
结果列表在训练了若干分类器之后,结果列表中也就包含了若干个条目。 左键点击这些条目可以在生成的结果之间进行切换浏览。右键点击某个条 目则会弹出一个菜单,包括如下的选项:
View in main window. 在主窗口中显示输出该结果. View in separate window. 打开一个独立的新窗口来显示结果。 Save result buffer. 弹出一个对话框,使得输出结果的文本可以保存成一个文本文件。 Load model. 从一个二进制文件中载入以前训练得到的模型对象。 Save model. 把模型对象保存到一个二进制文件中。对象是以 Java“序列化”的形式保存的 Re-evaluate model on current test set. 通过 Supplied test set 选项下的 Set 按钮指定一个数据集,已建立的分类模型将在这个数据集上测试它的表现。 Visualize classifier errors. 弹出一个可视化窗口,把分类结果做成一个散点图。其中正确分
<6>
提纲
➢ 数据挖掘软件介绍 ➢ Weka ➢ RapidMiner ➢ Knime
<7>
Weka简介
WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过 /ml/weka得到。
为普通用户提供了图形化界面 在Weka论坛有大量的扩展包 很多其它开源数据挖掘软件也支持调用Weka的分
析功能
<3>
数据挖掘软件介绍
RapidMiner:耶鲁大学的研究成果
免费提供数据挖掘技术和库 数据挖掘过程简单,强大和直观 多层次的数据视图,确保有效和透明的数据 400多个数据挖掘运营商支持 强大的可视化引擎 耶鲁大学已成功地应用在许多不同的应用领域,包
<11>
Weka的数据格式
关系声明 关系名称在ARFF文件的第一个有效行来定义,格式为 @relation <relation-name> <relation-name>是一个字符串。如果这个字符串包含空格, 它必须加上引号(指英文标点的单引号或双引号)。
属性声明 属性声明用一列以“@attribute”开头的语句表示。数据集中 的每一个属性都有它对应的“@attribute”语句,来定义它的 属性名称和数据类型。 @attribute <attribute-name> <datatype>
<19>
用Weka进行分类
Class属性设置
WEKA 中的分类器被设计成经过训练后可以预测 一个 class 属性,也就是预测的目 标。默认的, 数据集中的最后一个属性被看作 class 属性。如 果想训练一个分类器,让它预测一个不同的属性 ,点击Test options 栏下方的那一栏,会出现一 个属性的下拉列表以供选择。
<12>
数据准备
使用WEKA作数据挖掘,面临的第一个问题往往是数 据不是ARFF格式的。
WEKA还提供了对CSV文件的支持,而这种格式是 被很多其他软件所支持的。
此外,WEKA还提供了通过JDBC访问数据库的功能 。
<13>
“Explorer”界面
<14>
数据属性
例如,bank-data数据各属性的含义如下:
同时weka也是新西兰的一种鸟名,而WEKA的主要开发者来自 新西兰。
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担 数据挖掘任务的机器学习算法,包括对数据进行预处理,分类 ,回归、聚类、关联规则以及在新的交互式界面上的可视化。
2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学 的Weka小组荣获了数据挖掘和知识探索领域的最高服务奖, Weka系统得到了广泛的认可,被誉为数据挖掘和机器学习历 史上的里程碑,是现今最完备的数据挖掘工具之一(已有11年 的发展历史)。Weka的每月下载次数已超过万次。
并可以集成到其它各种各样的开源项目中
<5>
数据挖掘软件介绍
IBM Intelligent Miner:IBM的商业级产品
简单易用 能处理大数据量的挖掘 功能一般,没有数据探索功能 与其他软件接口差,只能用DB2,连接DB2以外的
数据库时,如Oracle, SAS, SPSS需要安装 DataJoiner作为中间软件
<15>
数据预处理
有些算法,只能处理所有的属性都是分类型的情况 。这时候就需要对数值型的属性进行离散化。
在这个数据集中有3个变量是数值型的,分别是 “age”,“income”和“children”。
其中“children”只有4个取值:0,1,2,3。
在UltraEdit中直接修改ARFF文件,把
@data % % 14 instances % sunny,85,85,FALSE,no sunny,80,90,TRUE,no overcast,83,86,FALSE,yes rainy,70,96,FALSE,yes rainy,68,80,FALSE,yes rainy,65,70,TRUE,no overcast,64,65,TRUE,yes sunny,72,95,FALSE,no sunny,69,70,FALSE,yes rainy,75,80,FALSE,yes sunny,75,70,TRUE,yes overcast,72,90,TRUE,yes overcast,81,75,FALSE,yes rainy,71,91,TRUE,no
<20>
用Weka进行分类
分类器、测试选项和class属性都设置好后,点击Start 按钮就 可以开始学习过程。右边的Classifier output 区域会被填充一 些文本,描述训练和测试的结果。
输出结果分为几个部分
Run information. 给出了学习算法各选项的一个列表。包括了学习过程中涉及 到的关系名称,属性,实例和测试模式。
id a unique identification number age age of customer in years (numeric) sex MALE / FEMALE region inner_city/rural/suburban/town income income of customer (numeric) married is the customer married (YES/NO) children number of children (numeric) car does the customer own a car (YES/NO) save_acct does the customer have a saving account (YES/NO) current_acct does the customer have a current account (YES/NO) mortgage does the customer have a mortgage (YES/NO) pep did the customer buy a PEP (Personal Equity Plan) after the last mailing (YES/NO)