12章-数据库管理系统-数据库系统概论(第五版)
数据库系统概论王珊第五版学习笔记

第一章1.数据库的四个基本概念:数据、数据库、数据库管理系统、数据库系统。
数据:是数据库中存储的基本对象。
描述事物的符号称为数据。
数据库:是长期存储在计算机内、有组织的、可共享的大量数据的集合。
数据库数据具有永久存储、有组织和可共享三个基本特点。
数据库管理系统:是计算机的基础软件。
数据库系统:是由数据库、数据库管理系统、应用程序和人组成的存储、管理、处理和维护数据的系统。
2.数据处理和数据管理。
数据处理:指对各种数据进行手机、存储、加工和传播的一系列活动的总和。
数据管理:指对数据进行分类、组织、编码、存储、检索和维护。
3.数据独立性。
物理独立性:指用户的应用程序与数据库中数据的物理存储是相互独立的。
逻辑独立性:指用户的应用程序与数据库的逻辑结构是相互独立的。
4.数据模型------是对现实世界数据特征的抽象(现实世界的模拟)。
数据模型是数据库系统的核心和基础。
概念模型:信息模型,按照用户的观点来对数据和信息建模,主要用于数据库设计。
逻辑模型:按照计算机系统的观点对数据建模。
物理模型:描述数据在计算机内部的表示方式和存取方法。
数据模型组成要素:数据结构、数据操作、数据的完整性约束条件。
5.信息世界中的基本概念。
实体:客观存在并可相互区别的事物。
属性:实体所具有的某一特征。
码:唯一标识实体的属性集。
联系:失误内部以及事物之间是有联系的。
实体内部的联系通常是指组成实体的个属性之间的联系,实体之间的联系通常是指不同实体集之间的联系。
实体之间的联系有一对一、一对多和多对多等各种类型。
6.数据完整性约束条件。
实体完整性:检查主码值是否唯一,检查主码的各个属性是否为空。
实体完整性在创建表时用primary key 主键来定义。
参照完整性:检查增删改时检查外码约束。
在创建表时用外码foreign key短语定义。
用户定义完整性:创建表中定义属性的同时,可以根据应用要求定义属性上的约束条件,即属性值限制。
列值非空(not null)、列值唯一(unique)、检查列值是否满足一个条件表达式(check 短语)7.数据库系统的模式。
数据库系统概论(第5版)复习备考资料.doc
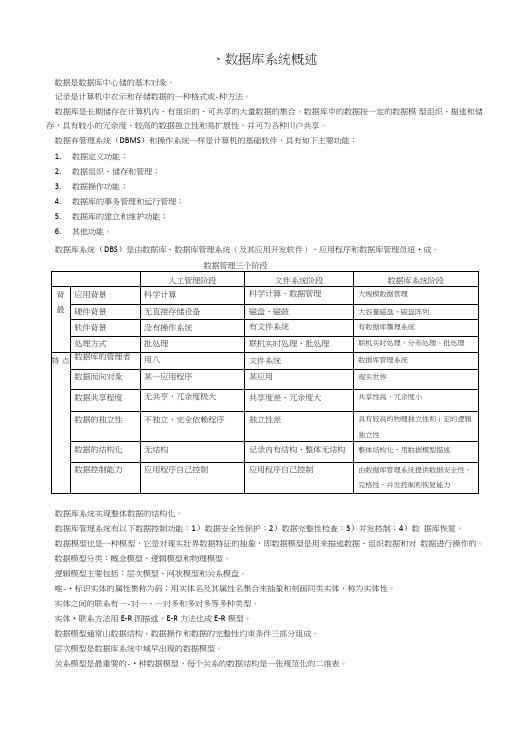
、数据库系统概述数据是数据库中心储的基木对彖。
记录是计算机中衣示和存储数据的一种格式或-种方法。
数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种川户共享。
数据弃管理系统(DBMS)和操作系统一样是计算机的基础软件,具有如下主要功能:1.数据定义功能;2.数据组织、储存和管理;3.数据操作功能;4.数据库的事务管理和运行管理;5.数据库的建立和维护功能;6.其他功能。
数据库系统(DBS)是由数据库、数据库管理系统(及其应用开发软件)、应用程序和数据库管理员纽•成。
数据管理三个阶段数据库系统实现整体数据的结构化。
数据库管理系统有以下数据控制功能:1)数据安全性保护;2)数据完整性检査:3)并发控制;4)数据库恢复。
数据模型也是一种模型,它是对现实壯界数据特征的抽象,即数据模型是用来描述数据、组织数据和对数据进行操作的。
数据模型分类:概念模型、逻辑模型和物理模型。
逻辑模型主要包括:层次模型、网状模型和关系模盘。
唯-•标识实体的属性集称为码;用实体名及其属性名集合来抽象和刻画同类实体,称为实体性。
实体之间的联系有一-对一、一对多和多对多等多种类型。
实体•联系方法用E-R图描述,E-R方法也成E-R模型。
数据模型通常山数据结构、数据操作和数据的完整性约朿条件三部分组成。
层次模型是数据库系统中域早出现的数据模型。
关系模型是最重要的-•种数据模型,每个关系的数据结构是一张规范化的二维表。
关系模型:对关系的描述,要求关系必须是规范化的。
关系的完整性约束条件包括三犬类:实体完整性、参照完整性和用户定义的完整性。
操作对彖和操作结果都是关系。
在数据模型中有“型”和“值”的概念。
模式是数据库中全体数据的逻辑结构和特征的描述。
数据廂系统的三级模式结构是指数据廂系统是山外模式、模式和内模式三级构成。
一个数据库只冇一个模式,也只冇一个内模式。
数据库系统概论(第五版)课件

总学时:32学时,其中24学时理论,8学时上机
关于教材
教材
数据库系统概论(第五版),王珊,萨师煊著 高等教育出版社,2014.12
参考书
《数据库系统导论(An Introduction to Database Systems )》(第 七版)C.J.Date著 ,机械工业出版社,数据库领域中的权 威著作。(剑桥大学) 《数据库系统概念(Database System Concepts)》(第六版) Silberschatz著, 机械工业出版社。(耶鲁大学)
描述事物的符号记录
数据的种类
文本、图形、图像、音频、视频、学生的档案记录、货物的 运输情况等
数据的特点
数据与其语义是不可分的
数据举例
数据的含义称为数据的语义,数据与其语义是不可分的。
例如 93是一个数据
语义1:学生某门课的成绩 语义2:某人的体重 语义3:某个年级的学生人数 语义4:请同学给出。。。
物理独立性
指用户的应用程序与存储在磁盘上的数据库中数据是相互独立的。 当数据的物理存储改变了,应用程序不用改变。
逻辑独立性
指用户的应用程序与数据库的逻辑结构是相互独立的。数据的逻 辑结构改变了,用户程序也可以不变。
数据独立性是由DBMS的二级映像功能来保证的
数据由DBMS统一管理和控制
文件系统的记录示例
学生文件的记录结构
学号 姓名 性别 系 年龄 住址 联系电话 学时
课程文件的记录结构
课程号
课程名
学生选课文件的记录结构
学号
课程号
成绩
文件中记录内部有结构,但记 姓名 性别 年龄 系别
日期 学校 家庭出身
数据库系统概念第五版12章

数据库系统概念第五版12章C H A P T E R12Indexing and HashingSolutions to Practice Exercises12.1Reasons for not keeping several search indices include:a.Every index requires additional CPU time and disk I/O overhead duringinserts and deletions.b.Indices on non-primary keys might have to be changed on updates,al-though an index on the primary key might not(this is because updatestypically do not modify the primary key attributes).c.Each extra index requires additional storage space.d.For queries which involve conditions on several search keys,ef?ciencymight not be bad even if only some of the keys have indices on them.Therefore database performance is improved less by adding indices whenmany indices already exist.12.2In general,it is not possible to have two primary indices on the same relationfor different keys because the tuples in a relation would have to be stored in different order to have same values stored together.We could accomplish this by storing the relation twice and duplicating all values,but for a centralized system,this is not ef?cient.5354Chapter12Indexing and Hashing12.3The following were generated by inserting values into the B+-tree in ascendingorder.A node(other than the root)was never allowed to have fewer than n/2values/pointers.a.b.c.12.4?With structure12.3.a:9:InsertInsertExercises 55Delete 23:Delete19:With structure 12.3.b:Insert 9:Insert 10:56Chapter 12Indexing and Hashing Insert 8:Delete23:With structure12.3.c:Insert 9:Insert 10:Insert8:Delete 23:Exercises57 Delete19:12.5If there are K search-key values and m?1siblings are involved in the redistri-bution,the expected height of the tree is:log (m?1)n/m (K)12.6The algorithm for insertion into a B-tree is:Locate the leaf node into which the new key-pointer pairshould be inserted.If there is space remaining in that leaf node,perform the insertion at the correct location,and the task is over.Otherwise insert the key-pointer pair conceptu-ally into the correct location in the leaf node,and then split it along the middle.The middle key-pointer pair does not go into either of the resultant nodes of the split operation.Instead it is inserted into the parent node,along with the tree pointer to the new child.If there is no space in the parent,a similar proce-dure is repeated.The deletion algorithm is:Locate the key value to be deleted,in the B-tree.a.If it is found in a leaf node,delete the key-pointer pair,and the recordfrom the?le.If the leaf node contains less than n/2 ?1entries as a resultof this deletion,it is either merged with its siblings,or some entries areredistributed to it.Merging would imply a deletion,whereas redistributionwould imply change(s)in the parent node’s entries.The deletions mayripple upto the root of the B-tree.b.If the key value is found in an internal node of the B-tree,replace it andits record pointer by the smallest key value in the subtree immediately toits right and the corresponding record pointer.Delete the actual record inthe database?le.Then delete that smallest key value-pointer pair from thesubtree.This deletion may cause further rippling deletions till the root ofthe B-tree.Below are the B-trees we will get after insertion of the given key values.We assume that leaf and non-leaf nodes hold the same number of search key values.58Chapter12Indexing and Hashinga.b.c.Exercises 5912.7Extendable hash structure000 001 010 011 100101 110 11112.8 a.Delete 11:From the answer to Exercise 12.7,change the third bucket to:At this stage,it is possible to coalesce the second and third buckets.Then it is enough if the bucket address table has just four entries instead of eight.For the purpose of this answer, we do not do the coalescing.b.Delete 31:From the answer to 12.7,change the last bucketto:c.Insert 1:From the answer to 12.7,change the ?rst bucket to:d.Insert 15:From the answer to 12.7,change the last bucket to:60Chapter12Indexing and Hashing12.9Let i denote the number of bits of the hash value used in the hash table.Letbsize denote the maximum capacity of each bucket.delete(value K l)beginj=?rst i high-order bits of h(K l);delete value K l from bucket j;coalesce(bucket j);endcoalesce(bucket j)begini j=bits used in bucket j;k=any bucket with?rst(i j?1)bits same as thatof bucket j while the bit i j is reversed;i k=bits used in bucket k;if(i j=i k)return;/*buckets cannot be merged*/if(entries in j+entries in k>bsize)return;/*buckets cannot be merged*/move entries of bucket k into bucket j;decrease the value of i j by1;make all the bucket-address-table entries,which pointed to bucket k,point to j;coalesce(bucket j);endNote that we can only merge two buckets at a time.The common hash pre?x of the resultant bucket will have length one less than the two buckets merged.Hence we look at the buddy bucket of bucket j differing from it only at the lastbit.If the common hash pre?x of this bucket is not i j,then this implies that thebuddy bucket has been further split and merge is not possible.When merge is successful,further merging may be possible,which is han-dled by a recursive call to coalesce at the end of the function.12.10If the hash table is currently using i bits of the hash value,then maintain acount of buckets for which the length of common hash pre?x is exactly i.Consider a bucket j with length of common hash pre?x i j.If the bucket is being split,and i j is equal to i,then reset the count to1.If the bucket is beingExercises61 split and i j is one less that i,then increase the count by1.It the bucket if being coalesced,and i j is equal to i then decrease the count by1.If the count becomes 0,then the bucket address table can be reduced in size at that point.However,note that if the bucket address table is not reduced at that point, then the count has no signi?cance afterwards.If we want to postpone the re-duction,we have to keep an array of counts,i.e.a count for each value of com-mon hash pre?x.The array has to be updated in a similar fashion.The bucket address table can be reduced if the i th entry of the array is0,where i isthe number of bits the table is using.Since bucket table reduction is an expensive operation,it is not always advisable to reduce the table.It should be reduced only when suf?cient number of entries at the end of count array become0. 12.11We reproduce the account relation of Figure12.25below.A-217Brighton750A-101Downtown500A-110Downtown600A-215Mianus700A-102Perryridge400A-201Perryridge900A-218Perryridge700A-222Redwood700A-305Round Hill350Bitmaps for branch nameBrighton100000000Downtown011000000Mianus000100000Perryridge000011100Redwood000000010Round hill000000001Bitmaps for balanceL1000000000L2000010001L3011100110L4100001000where,level L1is below250,level L2is from250to below500,L3from500to below750and level L4is above750.62Chapter12Indexing and HashingTo?nd all accounts in Downtown with a balance of500ormore,we?nd the union of bitmaps for levels L3and L4and then intersect it with the bitmap forDowntown.Downtown011000000L3011100110L4100001000L3∪L4111101110Downtown011000000Downtown∩(L3∪L4)011000000Thus,the required tuples are A-101and A-110.12.12No answer。
数据库系统概论第五版课后习题答案

第1章绪论1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据( Data ) :描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500 这个数字可以表示一件物品的价格是 500 元,也可以表示一个学术会议参加的人数有 500 人,还可以表示一袋奶粉重 500 克。
( 2 )数据库( DataBase ,简称 DB ) :数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
( 3 )数据库系统( DataBas 。
Sytem ,简称 DBS ) :数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。
( 4 )数据库管理系统( DataBase Management sytem ,简称 DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析 DBMS 是一个大型的复杂的软件系统,是计算机中的基础软件。
目前,专门研制 DBMS 的厂商及其研制的 DBMS 产品很多。
数据库系统概论第五版资料

1. 并发控制的主要方法是封锁机制。
2. 标准SQL授权语句中允许权限传播的短语为grant。
3. 函数依赖可能造成的数据异常有数据冗余、删除异常、插入异常、和修改异常四种4. 关系数据库的完整性约束包括域完整性、实体完整性和参照完整性、用户自定义的完整性。
5.分E-R图之间的冲突主要有属性冲突、命名冲突、结构冲突三种6.数据库系统的逻辑模型按照计算机的观点对数据建模,主要包括层次模型、网状模型和关系模型、面向对象模型、对象关系模型等7. 一个关系的候选码中的属性被称为主属性、其它属性被称为非主属性8. 最经常使用的概念模型是E-R9. 在关系模型中,关系操作包括查询、插入、删除和修改等10. 嵌入式SQL语句中为了和主语言语句进行区分,在SQL语句前加前缀EXEC SQL,以分号结束。
11.数据库角色实际上是一组与数据库操作相关的各种权限。
12.DBMS的全称是数据库管理系统。
13. 数据库系统的三级模式结构是指数据库系统是由外模式、内模式和模式三级构成。
14. 传统的集合操作包括并、交、差、和笛卡尔积。
15. SQL语言具有两种使用方式,分别称为交互式SQL和嵌入式SQL。
16. 在SQL语言中,为了数据库的安全性,设置了对数据的存取进行控制的语句,对用户授权使用grant语句,收回所授的权限使用revoke语句。
17. 数据库设计的几个步骤是需求分析、概念结构设计、逻辑结构设计、物理设计、系统实施、系统运行和维护。
18.关系模型是目前最常用也是最重要的一种数据模型。
采用该模型作为数据的组织方式的数据库系统称为关系数据库系统。
19. SQL语言集数据操纵、数据定义和数据控制功能于一体,充分体现了关系数据语言的特点和优点。
20.三级模式之间的两层映像保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。
21.事务必须具备4个特性:原子性、一致性、隔离性和持久性。
22. 数据完整性可分为:实体完整性、参照完整性和用户自定义完整性。
数据库系统概论第五版知识点
数据库系统概论第五版知识点嘿,朋友!咱们今天来聊聊数据库系统概论第五版的那些知识点,这可真是个有趣又实用的话题。
你知道吗,数据库就像是一个超级大的仓库,里面存放着各种各样的宝贝数据。
而数据库系统呢,就是管理这个大仓库的一套规则和方法。
比如说,数据模型就像是仓库的布局设计。
关系模型,那就是把数据当成一张张整齐的表格,清晰又明了。
层次模型呢,就像一个有层次的架子,数据一层一层摆放。
网状模型,则像一张错综复杂的网,把数据都连在一起。
你说有趣不?再来说说数据库的结构。
这就好比是仓库的框架,有内有外,有大有小。
外模式,就像是仓库给外面的人展示的窗口,让人能看到一部分东西。
模式呢,是整个仓库的整体规划。
内模式,则是仓库内部的具体构造和存储方式。
还有啊,数据库的安全性也很重要。
这就好像是给仓库加上锁,防止坏人偷东西。
设置用户权限、加密数据,这些都是保护数据库的手段。
要是没有这些安全措施,那数据不就像没人看守的财宝,随时可能被偷走啦?说到数据库的完整性,这就像是保证仓库里的东西都是完好无损、准确无误的。
通过各种约束条件,确保数据的质量,不能有错误、缺失或者不符合规则的情况。
查询处理和优化呢,就好比是在仓库里快速找到你想要的宝贝。
怎么能更快更准地找到,这可是有技巧的。
优化查询语句,选择合适的索引,就像给找宝贝的路铺上了快车道。
数据库的并发控制,就像是在仓库里很多人同时找东西,得协调好,不能乱套,不能一个人拿了东西,另一个人以为还在。
备份和恢复,这可是数据库的保命绝招。
万一仓库出了问题,比如着火啦、被水淹啦,有了备份就能重新把宝贝都找回来。
总之,数据库系统概论第五版的知识点就像是一套精细的宝库管理秘籍,掌握了这些,就能把数据这个大宝藏管理得井井有条。
学会了这些,无论是处理大量的数据,还是保证数据的安全、准确,都能得心应手。
朋友,你说是不是这个理儿?。
数据库系统概论第五版课后习题完整答案王珊
数据库系统概论第五版课后习题完整答案第1章课后习题1.1 填空题1.关系数据库是一种______数据库______。
•关系•层次•网络•面向对象2.数据库系统的三级模式结构是______外模式______、______模式______和______内模式______。
•外模式•模式•内模式•逻辑模式•子模式1.2 选择题1.下列关于数据库系统的描述中,正确的是______B______。
A. 数据库系统是由软件、硬件、数据、人员和存储设备等部分组成的系统。
B. 数据库系统是一种计算机软件,用于管理和组织数据的集合。
C. 数据库系统的主要目标是提供对数据的有效存储、管理和访问。
D. 数据库系统一般包括文件系统、数据库管理系统和应用系统三大部分。
2.关于数据库系统中的数据模型,以下选项中错误的是______B______。
A. 数据模型描述了有关数据的概念和结构,是数据库系统中数据定义的工具。
B. 数据模型只有一种,不能根据不同的需求选择合适的数据模型。
C. 常见的数据模型有层次模型、网络模型、关系模型和面向对象模型等。
D. 数据模型可以帮助人们理解和使用数据库系统中的数据。
1.3 简答题1.数据库系统的特点有哪些?答:数据库系统具有以下特点:•数据独立性:数据库系统通过数据与应用程序之间的逻辑独立性和物理独立性,使得应用程序与数据的存储结构和存取方式解耦,提高了应对数据结构和存储方式变化的灵活性和可维护性。
•数据共享性:数据库系统能够支持多个用户对数据的并发访问,实现数据的共享与共用,提高了数据的利用率和工作效率。
•数据一致性:数据库系统通过强制数据完整性约束的方式,保证了数据的一致性,避免了数据冗余和不一致的问题。
•数据持久性:数据库系统能够对数据进行长期的持久性存储,确保数据的安全性和可靠性。
•数据的高效管理:数据库系统通过采用高效的数据存储结构和存取方式,提高了数据的管理和处理效率。
2.数据库系统的三级模式结构是什么?答:数据库系统的三级模式结构包括外模式、模式和内模式。
数据库系统概论第五版课后答案
数据库系统概论第五版课后答案第1章绪论1.试述数据、数据库、数据库系统、数据库管理系统的概念。
答:(l)数据(Data):描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500这个数字可以表示一件物品的价格是500元,也可以表示一个学术会议参加的人数有500人,还可以表示一袋奶粉重500克。
(2)数据库(DataBase,简称DB):数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
(3)数据库系统(DataBas。
Sytem,简称DBS):数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。
(4)数据库管理系统(DataBaseManagementsytem,简称DBMs):数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析DBMS是一个大型的复杂的软件系统,是计算机中的基础软件。
目前,专门研制DBMS的厂商及其研制的DBMS产品很多。
著名的有美国IBM公司的DBZ关系数据库管理系统和IMS层次数据库管理系统、美国Oracle公司的orade关系数据库管理系统、s油ase公司的s油ase关系数据库管理系统、美国微软公司的SQLServe,关系数据库管理系统等。
数据库系统概论第五版课后习题答案王珊(供参考)
第1章绪论1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据( Data ) :描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500 这个数字可以表示一件物品的价格是 500 元,也可以表示一个学术会议参加的人数有 500 人,还可以表示一袋奶粉重 500 克。
( 2 )数据库( DataBase ,简称 DB ) :数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
( 3 )数据库系统( DataBas 。
Sytem ,简称 DBS ) :数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。
( 4 )数据库管理系统( DataBase Management sytem ,简称 DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析 DBMS 是一个大型的复杂的软件系统,是计算机中的基础软件。
目前,专门研制 DBMS 的厂商及其研制的 DBMS 产品很多。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
进程间总的通信开销上升
操作系统的负担增大,空间、时间效率不高
DBMS必须设立并维护若干后台进程,增加了进程切换
要访问的数据不在内存时会造成性能问题
临界区问题(Critical Section)
❖ 适用情况
用户数不庞大(非OLTP应用):Oracle 7之前版本, Ingres,
Informix早期版本
12.2.1 N方案:DBMS与应用程序相融合的方案
❖ 优点
没有进程切换开销 实现比较简单
❖ 缺点
内存的需求量比较大:多DBMS副本 代码冗余使系统性能下降
❖ 适用情况
用户数少的小型DBMS
An Introduction to Database System
12.2 DBMS进程结构和多线索机制
An Introduction to Database System
12.2.2 2N方案:一个DBMS进程对应一个用户进程
❖ 解决N方案中DBMS代码段在内存中不能被共享
应用程序与DBMS副本分开 2N方案
❖ 一用户一进程(Shadow进程)
N个用户进程---N个DBMS进程(共2N个进程)
An Introduction to Database System
12.2.1 N方案:DBMS与应用程序相融合的方案 12.2.2 2N方案:一个DBMS进程对应一个用户进程 12.2.3 N+1方案:一个DBMS进程对应所有用户进程 12.2.4 N+M方案:M个DBMS进程对应N个用户进程 12.2.5 多线索(Multi_Threaded) DBMS的概念
12.2.3 N+1方案:一个DBMS进程对应所有用户进程
❖ 优点
采用多线索(Multi_Threaded)技术
➢提高系统性能,降低系统资源的开销,简化DBMS许多 部分的设计
❖ 缺点
DBMS的设计整体上较复杂 消息系统过于昂贵
❖ 实际系统
Sybase
An Introduction to Database System
12.1 DBMS的基本功能(续)
❖ 其他功能
DBMS与网络中其他软件系统的通信功能 与其他DBMS或文件系统的数据转换功能 异构数据库之间的互访和互操作功能
An Introduction to Database System
12.2 DΒιβλιοθήκη MS进程结构和多线索机制12.2.1 N方案:DBMS与应用程序相融合的方案 12.2.2 2N方案:一个DBMS进程对应一个用户进程 12.2.3 N+1方案:一个DBMS进程对应所有用户进程 12.2.4 N+M方案:M个DBMS进程对应N个用户进程 12.2.5 多线索(Multi_Threaded) DBMS的概念
12.1 DBMS的基本功能 12.2 DBMS的进程结构和多线索机制 12.3 DBMS系统结构 12.4 语言处理层 12.5 数据存取层 12.6 缓冲区管理 12.7 数据库物理组织
An Introduction to Database System
12.1 DBMS的基本功能
1. 数据库定义和创建 2. 数据组织、存储和管理 3. 数据存取 4. 数据库事务管理和运行管理 5. 数据库的建立和维护 6. 其他功能
❖ 优点
改进了2N方案,提高了内存资源的利用率
❖ 缺点
没有克服2N方案的本质弱点 分派程序给系统增加了开销并可能成为瓶颈 DBMS进程动态增减的开销亦很大
❖ 实际系统
Oracle Informix
An Introduction to Database System
12.2 DBMS进程结构和多线索机制
❖ 目的
从宏观和总体的角度把握数据库管理系统的基本概念 和基本原理,以便更好地使用和维护数据库管理系统 。
An Introduction to Database System
第十二章 数据库管理系统
❖ DBMS是一种复杂的系统软件,主要是实现对共享数 据有效的组织、存储、管理和存取。围绕数据,其应 具有如下基本功能。
12.2.1 N方案:DBMS与应用程序相融合的方案 12.2.2 2N方案:一个DBMS进程对应一个用户进程 12.2.3 N+1方案:一个DBMS进程对应所有用户进程 12.2.4 N+M方案:M个DBMS进程对应N个用户进程 12.2.5 多线索(Multi_Threaded) DBMS的概念
❖ 线程
将进程中的程序代码与进程所占资源相分离,从而在一个
地址空间运行多个指令流
An Introduction to Database System
一、 线程的概念(续)
An Introduction to Database System
二、 多线索(Multi_Threaded)DBMS ❖ DBMS是一个Task ❖用 户 申 请 数 据 库 服 务 时 , Task 分 配 至 少 一 个
An Introduction to Database System
12.2 DBMS进程结构和多线索机制
12.2.1 N方案:DBMS与应用程序相融合的方案 12.2.2 2N方案:一个DBMS进程对应一个用户进程 12.2.3 N+1方案:一个DBMS进程对应所有用户进程 12.2.4 N+M方案:M个DBMS进程对应N个用户进程 12.2.5 多线索(Multi_Threaded) DBMS的概念
❖ DBMS的实现,既要充分利用计算机硬件、操作系统、编 译系统和网络通信等技术,又要突出对海量数据存储、管 理和处理的特点,还要保证其存取数据和运行事务的高效 率,这是一个复杂而综合的软件设计开发过程。
❖ 清晰、合理的层次结构不仅可以使用户更清楚地认识 DBMS,更重要的是有助于DBMS的设计和维护。
☆这些定义存储数据字典(亦称为系统目录)
An Introduction to Database System
12.1 DBMS的基本功能(续)
❖ 数据组织、存储和管理
数据的种类 ➢ 数据字典 ➢ 用户数据 ➢ 存取路径
任务 ➢ 确定以何种文件结构和存取方式在存储器上组织这些数据 ➢ 如何实现数据之间的联系 ➢ 提供多种存取方法(如索引查找、hash查找、顺序查找等)
12.2 DBMS进程结构和多线索机制
12.2.1 N方案:DBMS与应用程序相融合的方案 12.2.2 2N方案:一个DBMS进程对应一个用户进程 12.2.3 N+1方案:一个DBMS进程对应所有用户进程 12.2.4 N+M方案:M个DBMS进程对应N个用户进程 12.2.5 多线索(Multi_Threaded) DBMS的概念
An Introduction to Database System
12.2.4 N+M方案:M个DBMS进程对应N个用户进程
❖M个DBMS进程-- N个用户进程(一般 M < N) ❖ DBMS 进 程 不 负 责 多 任 务 调 度 , 每 个 用 户 进 程 也
不固定地对应于某个DBMS进程 ❖ 用 户 的 数 据 库 请 求 被 动 态 分 配 给 某 个 DBMS 进 程
来处理 ❖ DBMS进程的分派由分派程序完成
An Introduction to Database System
12.2.4 N+M方案:M个DBMS进程对应N个用户进程
An Introduction to Database System
12.2.4 N+M方案:M个DBMS进程对应N个用户进程
An Introduction to Database System
12.1 DBMS的基本功能(续)
❖ 数据库定义和创建
外模式、模式、内模式的定义
➢在关系数据库中就是建立数据库(或模式)、表、视图、 索引等
数据库完整性的定义 创建用户、安全保密定义(如用户口令、级别、角色、
存取权限) 存取路径(如索引)的定义
12.2.2 2N方案:一个DBMS进程对应一个用户进程
An Introduction to Database System
12.2.2 2N方案:一个DBMS进程对应一个用户进程
❖ 优点
DBMS对各数据库用户的多任务调度由OS完成
➢ 简化了用户进程与DBMS的接口 ➢ 实现起来比较简单
❖ 缺点
An Introduction to Database System
12.1 DBMS的基本功能(续)
❖ 数据库的建立和维护
建立数据库
➢数据库的初始建立 ➢数据的转换
维护数据库
➢数据库的转储和恢复 ➢数据库的重组织和重构造 ➢性能监测分析
An Introduction to Database System
An Introduction to Database System
12.2.1 N方案:DBMS与应用程序相融合的方案
❖ N个DB用户--N个进程
连入式方案
❖ SGA(Shared Global Area)
共享全局区
字典定义信息 数据和索引缓冲块 日志缓冲块 封锁控制块
An Introduction to Database System
An Introduction to Database System
12.1 DBMS的基本功能(续)
❖ 数据库事务管理和运行管理
目的
➢ 维护事务的ACID特性,保证数据库系统的正常运行
任务
➢ 多用户环境下事务的管理和和安全性、完整性控制 ➢ 数据库恢复、并发控制和死锁检测(或死锁防止) ➢ 安全性检查和存取控制 ➢ 完整性检查和执行 ➢ 运行日志的组织管理
An Introduction to Database System