对应分析方法与对应图解读方法
SPSS软件中对应分析

对应分析当A 与B 的取值较少时,把所得的数据放在一张列联表中,就可以很直观的对A 与B 之间及它们的各种取值之间的相关性作出判断,当ij P 较大时,则说明属性变量A 的第i 状态与B 的第j 状态之间有较强的依赖关系.但是,当A 或者B 的取值比较多时,就很难正确的作出判断,此时就需要利用降维的思想简化列联表的结构.几个基本定义:我们此处讨论因素A 有n 个水平,因素B 有p 个水平。
行剖面:当变量A 的取值固定为i 时(i=1,2,…,n ),变量B 的各个状态相对出现的概率情况,即:可以方便的把第i 行表示成在p 维欧氏空间中的一个点,其坐标为:),,,(..2.1i ip i i i i rip p p p p p p = ,i=1,2,… , n ,实际上,该坐标可以看成p 维超平面121=+++p x x x 上的点。
记n 个行剖面的集合为n(r)。
由于列联表行与列的地位是对等的,由上面行剖面的定义方法,可以很容易的定义列剖面。
列剖面:),,,(..2.1j njj j j j cjp p p p p p p = ,j=1,2,… , p,实际上,该坐标可以看成n 维超平面121=+++n x x x 上的点。
记p 个列剖面的集合为p(c)。
定义了行剖面和列剖面之后,我们看到属性变量A 的各个取值情况可以用p 维空间的n 个点来表示,而B 的不同取值情况可以用n 维空间上的p 个点来表示。
而对应分析就是利用降维思想,把A 的各个状态表现在一张二维图上,又把B 的各个状态表现在一张二维图上,且通过后面的分析可以看到,这两张二维图的坐标有着相同的含义,即可以把A 的各个取值与B 的各个取值同时在一张二维图上表示出来。
距离:通过行剖面与列剖面的定义,A 的不同取值可以利用P 维空间中的不同点表示,各个点的坐标分别为ri P (i=1,2,…,n )。
而B的不同取值可以用n 维空间中的不同点表示,各个点的坐标分别为cj P (j=1,2,…,p )。
多元统计分析-对应分析

03
列联表检验的零假设是两变量 X和Y 相互独立,计算一个卡方统计量,与列联表中频数取值 和零假设下期望取值之差有关,当卡方 很大时否定零假设。
BA
患慢性支 未患慢性 气管炎 支气管炎
吸烟
43
162
不吸烟
13
121
为了探讨吸烟与慢性支气管炎有无关系, 调查了339人,情况如表所示:
设想有两个随机变量A,B:A:1表示吸 烟,
对应分析
对应分析基本步骤: 建立列联表
利用对应图解释结 果。
1
2
3
一.获取对应分析 数据 确定研究目的, 选择对应分析 所需数据,应 该包括的背景 资料。
对应分析
4
5
二、对应分析 的原理
01
由于R型因子分析和 02
设原始数据矩阵为:
Q型因子分析是反映
一个整体的不同侧面,
R型因子分析是从列
来讨论(对变量),
k
特征根。
Zu k
设 1 2…
三、对应图u 1u 11u 21 A和l(0Bu <的p 1 i<非m零in特(n征,p根)),为其矩相阵应 u 2u 12u 22 的特征u p 向2量为
v 1 v 1 1v 2 1 v n 1 v 2 v 1 2 v 2 2 v n 2
我们知道因子载荷矩阵的含义是原始变量与公共因子之间的 相关系数,所以如果我们构造一个平面直角坐标系,将第一 公共因子的载荷与第二个公共因子的载荷看成平面上的点, 在坐标系中绘制散点图,则构成对应图。
Q型因子分析是从行
来讨论(对样品),
因此 在的
他们之
联 x系1。1
间
存在
x12
内
对应分析方法与对应图解读方法

对应分析方法与对应图解读方法——七种分析角度对应分析是一种多元统计分析技术,主要分析定性数据Category Data方法,也是强有力的数据图示化技术,当然也是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表和卡方的独立性检验,如何解释对应图,当然大家也可以看到如何用SPSS操作对应分析和对数据格式的要求!对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:概念发展(Concept Development)新产品开发 (New Product Development)市场细分 (Market Segmentation)竞争分析 (Competitive Analysis)广告研究 (Advertisement Research)主要回答以下问题:谁是我的用户?还有谁是我的用户?谁是我竞争对手的用户?相对于我的竞争对手的产品,我的产品的定位如何?与竞争对手有何差异?我还应该开发哪些新产品?对于我的新产品,我应该将目标指向哪些消费者?数据的格式要求对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析。
多个变量间——多元对应分析。
案例分析:自杀数据分析上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别和年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN(开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)当然,我们拿到的最初原始数据可能是SPSS数据格式记录表,其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。
聚类分析、对应分析、因子分析、主成分分析spss操作入门

Within-group linkage:组内平均连接法
• • • •
•
Байду номын сангаас
以两类个体两两之间距离的平均数作为类间距离。 d (d1 d 2 d 3 d 9 ) 9
将两类个体合并为一类后,以合并后类中所有个体之间的 平均距离作为类间距离。 d (d1 d 2 d 3 d 4 d 5 d 6 ) 6
输出结果
当采用“特征根大于1”的 方法提取因子时,所有变 量的共同度过均较高,各 变量的丢失信息较少,效 果理想。
此操作目的在于检验原始变量之 间是否存在一定线性关系,若线性 关系不显著,则不适合做因子分析
20
输出结果
看correlation矩阵,若对角线上元素的值较接近1,其 他大多数元素的绝对值均较小,说明变量之间相关性较 强,适合做因子分析。
因子 编号 特征 根值 方差 贡献率 累积方差 贡献率
23
软件操作
Method:因子旋转的方法,Varimax—方差最大 法, Quartimax— 四次方最大法, Equamax— 等量 最大法, Display:输出与因子旋转相关的信息,Rotated solution— 旋 转 后 的 因 子 载 荷 矩 阵 , Loading plot(s)—旋转后的因子载荷散点图
聚类输出结果
初始类中心情况 中心点偏移情况
最终类中心情况
最终类成员情况
15
基本介绍: 一种数据简化的技术; 将原有变量中的信息重叠部分提取并综合成因子,实现减少变量个数的目的; 提取出来的因子能够反映原来众多变量的主要信息; 原始的变量是可观测的显在变量,而提取因子是不可观测的潜在变量;
对应分析数据

对应分析数据一、概述对应分析数据是一种数据分析方法,用于研究两个或者多个变量之间的关系。
通过对数据进行对应分析,可以揭示变量之间的相关性,并匡助我们理解数据暗地里的模式和趋势。
本文将介绍对应分析数据的基本概念、步骤和应用场景。
二、基本概念1. 对应分析对应分析是一种多元数据分析方法,它通过将多个变量映射到一个低维空间中,从而揭示变量之间的关系。
对应分析可以匡助我们发现数据中的结构和模式,进而进行更深入的分析。
2. 对应图对应图是对应分析结果的可视化表示。
对应图通常是一个二维平面图,其中每一个数据点表示一个观测值,不同的颜色或者符号表示不同的组别或者类别。
通过观察对应图,我们可以看到数据点之间的关系和趋势。
三、步骤对应分析数据的步骤如下:1. 数据准备首先,需要准备要进行对应分析的数据。
数据可以是任何类型的,可以是定量数据(如数值)或者定性数据(如类别)。
确保数据的质量和完整性非常重要。
2. 数据标准化对应分析需要对数据进行标准化,以消除不同变量之间的量纲差异。
常用的标准化方法包括Z-score标准化和归一化等。
3. 计算对应分析利用对应分析的算法,对标准化后的数据进行计算,得到对应分析的结果。
对应分析的算法有多种,常用的包括主成份分析(PCA)和多维尺度分析(MDS)等。
4. 绘制对应图将对应分析的结果绘制成对应图,以便更直观地观察数据之间的关系和趋势。
对应图可以通过各种数据可视化工具来实现,如散点图、气泡图等。
5. 解读对应图通过观察对应图,我们可以解读数据之间的关系和趋势。
可以观察数据点的分布情况、类别之间的距离和相对位置等。
根据对应图的结果,可以进一步进行数据分析和决策。
四、应用场景对应分析数据在各个领域都有广泛的应用,以下列举几个常见的应用场景:1. 市场调研对应分析数据可以匡助市场调研人员了解不同产品或者品牌之间的关系和竞争状况。
通过对应分析,可以发现市场中的潜在细分市场和目标客户群体。
对应分析方法与对应图解读方法 (2)

对应分析方法与对应图解读方法——七种分析角度对应分析就是一种多元统计分析技术,主要分析定性数据Category Data方法,也就是强有力的数据图示化技术,当然也就是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表与卡方的独立性检验,如何解释对应图,当然大家也可以瞧到如何用SPSS操作对应分析与对数据格式的要求!对应分析就是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:概念发展(Concept Development)新产品开发(New Product Development)市场细分(Market Segmentation)竞争分析(Competitive Analysis)广告研究(Advertisement Research)主要回答以下问题:谁就是我的用户?还有谁就是我的用户?谁就是我竞争对手的用户?相对于我的竞争对手的产品,我的产品的定位如何?与竞争对手有何差异?我还应该开发哪些新产品?对于我的新产品,我应该将目标指向哪些消费者?数据的格式要求对应分析数据的典型格式就是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析。
多个变量间——多元对应分析。
案例分析:自杀数据分析上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别与年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN(开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)当然,我们拿到的最初原始数据可能就是SPSS数据格式记录表,其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。
Correspondence

目录
一 培训目标 Correspondence的功能用途
二
三
Correspondence的操作流程
数据解读 主要的编辑功能 操作Tips
Specializing in China market researchTM
四 五
数据解读
相比较而言,退 休在家的年长者 则更多是非口香 糖消费者。
重度和中度消费者特征相近, 人群特点是:高学历、单身、 年轻、以学生居多。
重度消费者:一天吃一次以上口香糖 中度消费者:一周吃一到六次口香糖 轻度消费者:一个月吃两三次或更少
轻度消费者 以中青年上 班族为主。
数据来源:CNRS(2008.1-12)
年轻学生
步骤六:定义两轴——定义Y轴
定义Y轴方法同定义X轴一样,在Filter选项中的Y轴Rows 中输入想保留的变量数,其他三个数设置为0。 定义Y轴名称同定义X轴名称方法相同。 两轴均定义好后,点击Reset Al始值
Specializing in China market researchTM
别之间的对应关系)。
该统计研究技术在市场细分、产品定位、品 牌形象以及满意度研究等领域应用比较多。
Specializing in China market researchTM
Correspondence功能
对交叉表运行结果进行图形化演示 按相关性处理数据
大量处理数据的快捷方法 描述目标市场时,一种很好的演示手段
Correspondence 相关分析
媒介与消费行为研究部 2009年5月
Specializing in China market researchTM
应用统计学对应分析等
重庆交通大学管理学院
22:22:28
1、什么是典型相关分析? 典型相关分析是研究两组变量之间相关关系 的多元统计分析方法.它借用主成分分析降维的 思想,分别对两组变量提取主成分,且使两组变 量提取的主成分之间的相关程度达到最大,而从 同一组内部提取的各主成分之间互不相关,用从 两组之间分别提取的主成分的相关性来描述两组 变量整体的线性相关关系.
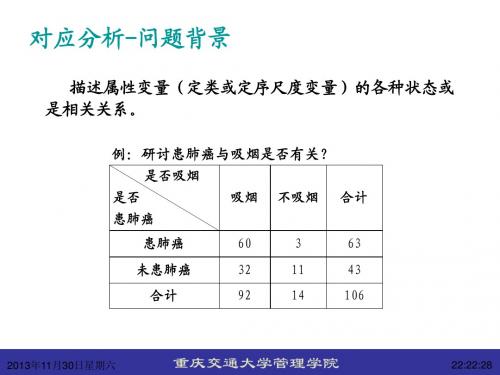
对应分析-问题背景
描述属性变量(定类或定序尺度变量)的各种状态或 是相关关系。
例:研讨患肺癌与吸烟是否有关?
是否吸烟 是否 患肺癌 患肺癌 未患肺癌 合计 60 32 92 3 11 14 63 日星期六
重庆交通大学管理学院
22:22:28
当属性变量A和B的状态较多时,很难透过列联表作 出判断。 怎样简化列联表的结构? 利用降维的思想。如因子分析和主成分分析。但因 子分析的缺陷是在于无法同时进行R型因子分析和Q 型因子分析。 怎么办?
2013年11月30日星期六
重庆交通大学管理学院
22:22:28
其优点是可以把方差分析和线性模型方法相结合,估 计模型中各个参数,而这些参数值使各个变量的效应和变 量间的交互作用效应得以数量化。
(2)Logistic 模型 是将概率比取对数后,再进行参数化而获得。设因变 量y为二值定性变量,用0和1表示两个不同状态,y=1的概 率p=P(y=1)是研究对象。若有多个因素影响y的取值,这 些因素就是自变量,记为:x1,x2…xk(既可以是定性变量 也可以是定量变量)。 Logistic 线性回归模型:
信度分类
内在信度:调查表中的一组问题(或整个调查表)是否测 量的是同一个概念,也就是这些问题之间的内在一致性 如何。 • 最常用的内在信度系数为克朗巴哈α系数和折半信度。 外在信度:在不同时间进行测量时调查表结果的一致性程 度。最常用的外在信度指标是重测信度,即用同一问卷 在不同时间对同一对象进行重复测量,然后计算一致程 度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对应分析方法与对应图解读方法——七种分析角度
对应分析是一种多元统计分析技术,主要分析定性数据Category Data方法,也是强有力的数据图示化技术,当然也是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表和卡方的独立性检验,如何解释对应图,当然大家也可以看到如何用SPSS操作对应分析和对数据格式的要求!
对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:
概念发展(Concept Development)
新产品开发(New Product Development)
市场细分(Market Segmentation)
竞争分析(Competitive Analysis)
广告研究(Advertisement Research)
主要回答以下问题:
谁是我的用户?
还有谁是我的用户?
谁是我竞争对手的用户?
相对于我的竞争对手的产品,我的产品的定位如何?
与竞争对手有何差异?
我还应该开发哪些新产品?
对于我的新产品,我应该将目标指向哪些消费者?
数据的格式要求
对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析。
多个变量间——多元对应分析。
案例分析:自杀数据分析
上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别和年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN(开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)
当然,我们拿到的最初原始数据可能是SPSS数据格式记录表,
其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。
要回答的问题是:
1-不同性别的人在选择自杀方式上有什么差别?
2-不同年龄的人在选择自杀方式上有什么差别?
3-不同性别年龄的人在选择自杀方式上有什么差别?
我们首先,把性别字段乘上10加上年龄字段生成新字段sexage,取值是11-15,21-25,然后分别用M/F和年龄组中值代表Sexage字段的变量值标,这样我们就可以进行简单对应分析了!
现在问大家,如果你看到上面的6×10的矩阵-列联表,你能看出什么差异?
现在我们采用SPSS软件进行对应分析!
(我现在用的是SPSS17.0多语言版本,前两天听博易智讯的人说,现在SPSS已经有18.0版本了,不过从对应分析方法角度我还是希望用11.5版本,因为可以自己拆分重新组合修改图形,现在的版本是图片了,不能随心所欲的修改,不爽!)
分别定义好行列变量以及它们的取值范围!
对应分析中,6×10的列联表(交互表)可以得到行列维度最小值减1的维度,我们看到第一维度Dim1解释了列联表的60.4%,第二维度Dim2解释了列联表的33.0%,说明在两个维度上已经能够说明数据的93.4%,这是比较理想的,当然我们也可以看卡方检验等!
下面我们主要解释如何解读对应图(小蚊子的博客中也有非常相似的解释,我非常欣赏他的博客)
首先对SPSS分析得到的对应图进行修饰和编辑,在零点增加两条中线!
解读方法:
1-总体观察:
我们从图上左右可以看出,左边全部是M*,男性,右边F*全部是女性,说明男女有显著差异;同时看横轴中线上方都是年龄大的,下面都是年龄小的,说明年龄有差异;这样就一目了然看出和回答了前两个问题;
2-观察邻近区域
我们从图上可以看出,老的男性比较喜欢HANG,GAS和GUN是年轻男性的偏好;老的女性比较喜欢DAWN,年轻的女性比较偏好POISON;
3-向量分析——偏好排序
我们可以从中心向任意点连线-向量,例如从中心向GUN做向量,然后让所有的人往这条向量及延长线上作垂线,垂点越靠近向量正向的表示越偏好这种方法。
记住:是垂点到GUN正向排名,从图中我们可以看出,希望GUN方法的人依次是M15、M30、M45、M60、M80、F15等等;依次类推,我们还可以从中心向任意一种方法作垂线,都可以排出每种方法选择人群的偏好次序;当然,你也可以从中心往所有的人作向量,得到每一类人在选择六种方法上的偏好排名!
你是否可以看出,F15年轻的女性对六个“品牌”的偏好吗?
4-向量的夹角——余弦定理
接着,我们可以从向量夹角的角度看不同方法或不同人之间的相似情况,从余弦定理的角度看相似性!
从图上我们可以看出,当我们从中心向任意两个点(相同类别)做向量的时候,夹角是锐角的话表示两个方法具有相似性,锐角越小越相似;也就是说,GUN和GAS是相似品牌,当如也是竞争品牌,也具有替代性,如果这次开枪没有自杀成功,下次他一定选择毒气啦;我们也看出F15和F30的人比较相似,但F15与M80就有非常大的差异了,因为如果作向量他们是钝角,几乎是平角了!
5-从距离中的位置看:
越靠近中心,越没有特征,越远离中心,说明特征越明显
从这张对应图中我们看到,有些点远离中心,有些点靠近中心,这说明什么呢?从几何空间的角度,如果我对每一人都一样的好,在规范图上我就应该站在大家的重心,也就是中心;这说明越靠近中心的点,越没有差异,(记住:没有差异并不代表不重要,只是没有差异,因为统计的技术是研究差异的技术,差异越大往往重要性就大!),越远离中心特征越明显,也就是说,如果听到一个M80的人自杀了,估计你就会想到是不是HANG 啦!
心的品牌,消费者不易识别,也说明你的品牌定位没有显著可识别的特征,没有差异认知!
6-坐标轴定义和象限分析
我们还没有定义坐标轴呢?从第一点的分析,其实我们很快就可以定义坐标轴的含义了!(当然有时候对应图的座位是非常难定义的)
因此,落在第四象限的是年轻的女性所喜欢的品牌!
7-产品定位:理想点与反理想点模型
我们可以在图上以POISON为定位点,以POISON为圆心,以它的利益为半径画圆,那么我们可以得出这样的结论:越先圈进来的人就是最喜欢这个品牌的消费群,越先圈进来的品牌越可能是竞争品牌;当然,你也可以以某类人作为圆心,同意解读;如果POISON是市场不存在的,在调查中可以设定为理想点,这样我们就可以得到理想点模型,同理也可以得到反理想点模型分析!
8-市场细分和定位
最后,研究人员可以根据前面的分析和自身市场状况,进行市场细分,找到目标消费群,然后定位进行分析!最终选择不同的目标市场制定有针对性的营销策略和市场投放!
我们也可以尝试采用多元对应分析,但不如简单对应分析有意义!
.
简单对应分析的优点:
定性变量划分的类别越多,这种方法的优势越明显,揭示行变量类别间与列变量类别间的联系,将类别联系直观地表现在二维图形中(对应图),可以将名义变量或次序变量转变为间距变量。
简单对应分析的缺点:不能用于相关关系的假设检验,维度要由研究者决定,有时候对应图解释比较困难,对极端值比较敏感。
如有侵权请联系告知删除,感谢你们的配合!
精品。