数据仓库与数据挖掘基础第6章关联规则(赵志升)
数据仓库与数据挖掘技术 第6章4关联规则1
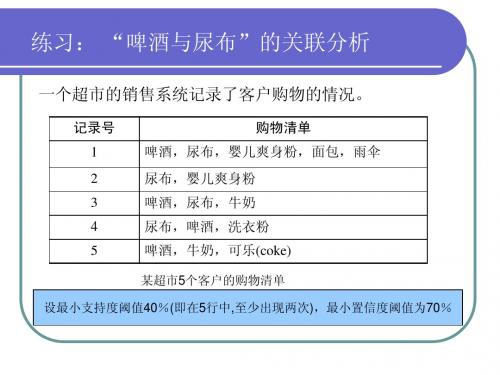
一个超市的销售系统记录了客户购物的情况。
记录号 1 2 3 4 5 购物清单 啤酒,尿布,婴儿爽身粉,面包,雨伞 尿布,婴儿爽身粉 啤酒,尿布,牛奶 尿布,啤酒,洗衣粉 啤酒,牛奶,可乐(coke)
某超市5个客户的购物清单 设最小支持度阈值40%(即在5行中,至少出现两次),最小置信度阈值为70%
R1:啤酒→尿布,supp=60%,conf=0.6/0.8=75%。 R2:尿布→啤酒,supp=60%,conf=0.6/0.8=75%。 R3:牛奶→啤酒,supp=40%,conf=0.4/0.4=100%。 R4:啤酒→牛奶,supp=40%,conf=0.4/0.8=50%。 R5:尿布→婴儿爽身粉,supp=40%,conf=0.4/0.8=50100%。
频繁单项集 单 项 集 {啤酒} {尿布} {婴儿爽身粉} {牛奶} 支 持 度 4 4 2 2
频繁双项集 双 项 集 {啤酒,尿布} {啤酒,牛奶} {尿布,婴儿爽身粉} 支 持 度 3 2 2
R1:啤酒→尿布,supp=3/5=60%,conf=3/4=75% R2:尿布→啤酒,supp=3/5=60%,conf=3/4=75% R3:牛奶→啤酒,supp=2/5=40%,conf=2/2=100% R4:啤酒→牛奶,supp=2/5=40%,conf=2/4=50% R5:尿布→婴儿爽身粉,supp=2/5=40%,conf=2/4=50% R6:婴儿爽身粉→尿布,supp=2/5=40%,conf=2/2=100%
数据挖掘方法——关联规则(自己整理)PPT课件

3.多层关联规则挖掘算法
对于很多的应用来说,由于数据分布的分散性,所以很难在数据最细节的层次上发现一些强 关联规则。当我们引入概念层次后,就可以在较高的层次上进行挖掘。虽然较高层次上得出的规 则可能是更普通的信息,但是对于一个用户来说是普通的信息,对于另一个用户却未必如此。所 以数据挖掘应该提供这样一种在多个层次上进行挖掘的功能。
(1)
如 :if A then B。则它的支持度Support=P(A and B) 2. Confidence(可信度):它是针对规则而言的。
Confidence=p(condition and result)/p(condition)。
(2)
如:If B and C then A。则它的可信度Confidence=p(B and C and A)/p(B and C)。 把满足最小支持度阈值和最小置信度阈值的规则成为强规则。项的集合称
多层关联规则的分类:根据规则中涉及到的层次,多层关联规则可以分为同层关联规则和层 间关联规则。
多层关联规则的挖掘基本上可以沿用“支持度-可信度”的框架。不过,在支持度设置的问题 上有一些要考虑的东西。
4.多维关联规则挖掘算法
对于多维数据库而言,除维内的关联规则外,还有一类多维的关联规则。例如:年龄(X, “20…30”) 职业(X,“学生”)==> 购买(X,“笔记本电脑”)在这里我们就涉及到三个 维上的数据:年龄、职业、购买。
该算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和 预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小 支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集 合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定 义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被 留下来。为了生成所有频集,使用了递推的方法。
数据挖掘关联规则

一、数据挖掘中的关联规则是什么:所谓关联规则,是指数据对象之间的相互依赖关系,而发现规则的任务就是从数据库中发现那些确信度(Conk一dente)和支持度(Support)都大于给定值的强壮规则。
从数据库中发现关联规则近几年研究最多。
目前,已经从单一概念层次关联规则的发现发展到多个概念层次的关联规则的发现。
在概念层次上的不断深人,使得发观的关联规则所提供的信息越来越具体,实际上这是个逐步深化所发现知识的过程。
在许多实际应用中,能够得到的相关规则的数目可能是相当大的,而且,用户也并不是对所有的规则感兴趣,有些规则可能误导人们的决策,所以,在规则发现中常常引人”兴趣度”(指一则在一定数据域上为真的知识被用户关注的程度)概念。
而基于更高概念层次上的规则发现研究(如一般化抽象层次上的规则和多层次上的规则发现)则是当前研究的重点之一。
二、关联规则数据挖掘中最经典的案例:关联规则数据挖掘中最经典的案例就是沃尔玛的啤酒和尿布的故事。
沃尔玛拥有世界上最大的数据仓库系统,为了能够准确了解顾客在其门店的购买习惯,沃尔玛对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。
沃尔玛数据仓库里集中了其各门店的详细原始交易数据。
在这些原始交易数据的基础上,沃尔玛利用数据挖掘方法对这些数据进行分析和挖掘。
一个意外的发现是:“跟尿布一起购买最多的商品竟是啤酒!”经过大量实际调查和分析,揭示了一个隐藏在“尿布与啤酒”背后的美国人的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。
产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
三、关联规则的一些定义与属性:考察一些涉及许多物品的事务:事务1 中出现了物品甲,事务2 中出现了物品乙,事务 3 中则同时出现了物品甲和乙。
那么,物品甲和乙在事务中的出现相互之间是否有规律可循呢?在数据库的知识发现中,关联规则就是描述这种在一个事务中物品之间同时出现的规律的知识模式。
《数据挖掘关联规则》PPT课件

值 s(A B )|{ |T D |A B T}|| ||D ||
规则 AB 在数据集D中的支持度为s, 其中s 表示
D中包含AB (即同时包含A和B)的事务的百分 率.
8
度量有趣的关联规则
可信度 c D中同时包含A和B的事务数与只包含A的事务 数的比值
24
加权关联规则的描述
对于项目集 X、Y, X、Y,XI ∩Y =φ ,如果有 wsup( X ∪Y )≥wminsup,且 conf(X→Y)≥minconf, 则称 X→Y 是一条加权关联规则。
25
权值的设定
加权支持度 (1)、平均值: (2)、归一化:
(3)、最大值:
w'sup(x)1k(jk1wj)sup(x)
证明:设n为事务数.假设A是l个事务的子集,若 A’ A , 则A’ 为l’ (l’ l )个事务的子集.因此, l/n ≥s(最小 支持度), l’/n ≥s也成立.
18
Apriori 算法
Apriori算法是一种经典的生成布尔型关联规则的频 繁项集挖掘算法.算法名字是缘于算法使用了频繁项 集的性质这一先验知识.
方法: 由频繁k-项集生成候选(k+1)-项集,并且 在DB中测试候选项集
性能研究显示了Apriori算法是有效的和可伸缩 (scalablility)的.
21
The Apriori 算法—一个示例
Database TDB
Tid Items
10
A, C, D
20
B, C, E
C1
1st scan
threshold )
for each itemset l1 Lk-1
《数据仓库与数据挖掘》(陈志泊)——习题答案

数据仓库与数据挖掘习题答案第1章数据仓库的概念与体系结构1。
面向主题的,相对稳定的。
2。
技术元数据,业务元数据。
3。
联机分析处理OLAP。
4. 切片(Slice),钻取(Drill—down和Roll—up等)。
5。
基于关系数据库。
6。
数据抽取,数据存储与管理。
7. 两层架构,独立型数据集市,依赖型数据集市和操作型数据存储,逻辑型数据集市和实时数据仓库。
8。
可更新的,当前值的.9。
接近实时。
10. 以报表为主,以分析为主,以预测模型为主,以营运导向为主.11。
答:数据仓库就是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,通常用于辅助决策支持.数据仓库的特点包含以下几个方面:(1)面向主题。
操作型数据库的数据组织是面向事务处理任务,各个业务系统之间各自分离;而数据仓库中的数据是按照一定的主题域进行组织。
主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点领域,一个主题通常与多个操作型业务系统或外部档案数据相关。
(2)集成的.面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。
而数据仓库中的数据是在对原有分散的数据库数据作抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企事业单位一致的全局信息。
也就是说存放在数据仓库中的数据应使用一致的命名规则、格式、编码结构和相关特性来定义.(3)相对稳定的。
操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。
数据仓库的数据主要供单位决策分析之用,对所涉及的数据操作主要是数据查询和加载,一旦某个数据加载到数据仓库以后,一般情况下将作为数据档案长期保存,几乎不再做修改和删除操作,也就是说针对数据仓库,通常有大量的查询操作及少量定期的加载(或刷新)操作。
数据仓库和数据挖掘技术 第6章4关联规则课件

2020/4/24
1
购物篮分析 一个引发关联规则挖掘的典型例子
2020/4/24
2
应用:购物分析
市场购物分析结果将帮助商场内商品应如何合理摆放进行规划设计。 其中一种策略就是将常常一起购买的商品摆放在相邻近的位置,
以方便顾客同时购买这两件商品;如:如果顾客购买电脑的同时常 也会购买一些金融管理类软件,那么将电脑软件摆放在电脑硬件附 近显然将有助于促进这两种商品的销售。 而另一种策略则是将电脑软件与电脑硬件分别摆放在商场的两端, 这就会促使顾客在购买两种商品时,走更多的路从而达到诱导他们 购买更多商品的目的。比如:顾客在决定购买一台昂贵电脑之后, 在去购买相应金融管理软件的路上可能会看到安全系统软件,这时 他就有可能购买这一类软件。 市场购物分析可以帮助商场主管确定那些物品可以进行捆绑减价销 售,如一个购买电脑的顾客很有可能购买一个捆绑减价销售的打印 机。
(1)支持度s:support(X=>Y)=P(X∪Y)
P(X∪Y):X和Y这两个项目集在事务集D中同时出现的概率
(2)置信度c:confidence(X=>Y)= P(Y|X)
P(Y|X) :在出现项目集X的事务集D中,项目集Y也同时出现的概率
(3)关联规则X=>Y成立的条件是:①它具有支持度,即事务集D中至少 有s%的事务包含X∪Y;②它具有置信度,即事务集D中包含X的事务 至少有c%同时也包含Y
强规则:满足最小支持度阈值(minsup)和最小置信度阈值(minconf) 的规则(用0%和100%之间的值而不是用0到1之间的值表示)
2020/4/24
6
什么是关联挖掘?
关联规则挖掘: 在交易数据、关系数据或其他信息载体中, 查找存在于项目集合或对象集合之间的频繁 模式、关联、相关性、或因果结构。
《数据仓库与数据挖掘》(关联规则)

顾客 X 购买的商品涉及不同抽象层次( “ computer ” 在比“ laptop computer”高的抽象层) ,因此是多层关联规则。 (3)基于规则中涉及到的数据的维数 基于规则中涉及到的数据的维数,关联规则可以分为单维的和多维的。 单维关联规则:处理单个维中属性间的关系,即在单维的关联规则中,只 涉及到数据的一个维。 例如:用户购买的物品: “咖啡=>砂糖” ,这条规则只涉及到用户的购买 的物品。 多维关联规则:处理多个维中属性之间的关系,即在多维的关联规则中, 要处理的数据将会涉及多个维。 例如:性别=“女”=>职业=“秘书” ,这条规则就涉及到两个维中字段的信 息,是两个维上的一条关联规则。
集的集合。 将该候选项集的集合记作 Ck。 设 l1 和 l2 是 Lk-1 中的项集, 记号 li[j]表示 li 的第 j 项。执行连接 Lk-1 和 Lk-1,其中 Lk-1 的元素 是可连接,如果它们前(k-2)个项相同而且第(k-2)项不同(为 简单计,设 l1[k-1]<l2[k-1]) ,即:
confidence(XY)= (包含 X 和 Y 的事务数 / 包含 X 的事务数)×100%
〖定义 8-3〗置信度和支持度均大于给定阈值(即最小置信度 阈值和最小支持度阈值) 。即: support(XY) >= min_sup confidence(XY) >= min_conf 的关联规则称为强规则;否则称为弱规则。 数据挖掘主要就是对强规则的挖掘。通过设置最小支持度和最小置
主要内容
关联规则挖掘的基本概念 关联规则挖掘的过程 Apriori 算法 Apriori 算法的变形 频繁模式增长(FP-增长)算法 其他关联规则挖掘算法 关联规则价值衡量的方法 关联规则挖掘的应用
数据仓库与数据挖掘基础第2章OLAP(赵志升)XXXX修改

4.1 OLAP的分类
2.MOLAP MOLAP存储模式使得分区的聚合和其源数据的复本以多
维结构存储在分析服务器计算机上。根据分区定义为是本地 分区还是远程分区,该计算机可以是定义分区的分析服务器 计算机,或别的分析服务器计算机。用于存储分区数据的多 维结构位于分析服 OLAP的定义和特点
整个数据(仓)库系统的工具层大 致可以分为三类,或者说三个发展阶段: (1)以MIS为代表的查询、报表类工具 (2)以OLAP为代表的验证型工具 (3)以及以DM为代表的挖掘型工具
4.1 OLAP的分类
OLAP系统按照其存储器的数据存储格式可以分为关系OLAP (RelationalOLAP,简称ROLAP)、多维OLAP (MultidimensionalOLAP,简称MOLAP)和混合型OLAP (HybridOLAP,简称HOLAP)三种类型。
4.1 OLAP的分类
4.1 OLAP的分类
3.HOLAP
由于MOLAP和ROLAP有着各自的优点和缺点(如下表 所示),且它们的结构迥然不同,这给分析人员设计OLAP 结构提出了难题。为此一个新的OLAP结构——混合型 OLAP(HOLAP)被提出,它能把MOLAP和ROLAP两种结构的 优点结合起来。迄今为止,对HOLAP还没有一个正式的定 义。但很明显,HOLAP结构不应该是MOLAP与ROLAP结构的 简单组合,而是这两种结构技术优点的有机结合,能满 足用户各种复杂的分析请求。
数据仓库与数据挖掘
Data Warehouse and Data Mining
河北北方学院:赵志升
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一节 关联规则挖掘
1、购物篮分析
牛奶 面包 谷类
牛奶 面包 糖 鸡旦
市 场
分
顾客1
顾客2
析 员
牛奶 面包 黄油
糖 鸡旦
顾客3
顾客4
第一节 关联规则挖掘
➢ 问题:什么商品组或集合顾客多半会在一次购 物时同时购买?
➢ 回答:需要分析商店的顾客事务零售数据,并 在其上运行购物篮分析。
第一节 关联规则挖掘
2、基本概念 设I={i1,i2,…,im}是项的集合,。设任务
相关的数据D是数据库事务的集合,其中每个 事务T是项的集合,使得TI。每一个事务有一 个标识符TID。设A是一个项集,事务T包含A ,当且仅当AT。关联规则是形如AB的蕴涵 式,其中AI, BI,且AB=Ø 。
sup port( A B) P( A B)
第一节 关联规则挖掘
1、购物篮分析 ✓ 规则的支持度和置信度是两个规则兴趣度度量
,反映规则的有用性和确定性,上述规则的支 持度2%意味分析中的全部事务的2%同时购买 计算机和操作系统软件。置信度60%意味购买 计算机的顾客60%也购买操作系统软件。 ✓ 关联规则被认为是有趣的,如果它满足最小支 持度阈值和最小置信度阈值。这些阈值可由用 户和领域专家设定。
第六章 挖掘大型数据库中的 关联规则
1、关联规则挖掘 2、挖掘事务数据库的单维布尔关联规则 3、挖掘事务数据库的多层关联规则 4、挖掘关系数据库和数据仓库的多维关联规则 5、由关联挖掘到相关分析
第六章 挖掘大型数据库中的 关联规则
❖ 关联规则挖掘发现大量数据中项集之间有趣的 关联或相关联系。
❖ 从大量商务事务记录中发现有趣的关联关系, 可以帮助许多商务决策的制定,如分类设计、交 叉购物和贱卖分析。
第二节 挖掘事务数据库的单维布尔关联规则
1、Apriori算法 例如,设已有包含9
个事务的事务数据库,即 |D|=9,各事务按字典 次序存放,设最小事务支 持度计数为2 。
根据下列标准,关联规则有多种分类方法: ➢ 根据规则中所处理的值的类型:若规则考虑项
的在与不在,则它是布尔关联规则;若规则描 述的是量化的项或属性之间的关联,则它是量 化关联规则。如,下列为一个量化关联规则:
age( X ,"23...33") income( X ,"42K...62K") buys( X ," fashion _ car") X为顾客变量,age和income为量化属性。
第一节 关联规则挖掘
1、购物篮分析 ✓ 可以想象全域是商店中可利用的商品的集合,
则每钟商品有一个布尔变量,表示该商品的有 无。每个篮子可以用一个布尔向量表示。可以 分析布尔向量,得到反映商品频繁关联或同时 购买的购买模式。 ✓ 这些模式可以用关联规则的形式表示:
computer operating _ system _ software [sup port 2%, confidence 60%]
第一节 关联规则挖掘
2、基本概念 关联规则的挖掘包含两个基本步骤:
➢ 找出所有频繁项集:这些项集出现的频繁性 至少和预定义的最小支持计数一样。
➢ 由频繁项集产生强关联规则:这些规则必须 满足最小支持度和最小置信度。
挖掘关联规则的总体性能由第一步决定。
第一节 关联规则挖掘
3、关联规则挖掘的分类标准 购物篮分析只是关联规则挖掘的一种形式。
confidence( A B) P(B | A)
第一节 关联规则挖掘
2、基本概念 ➢ 项的集合称为项集,包含K个项的项集称为
K-项集。集合{computer,software}是一 个2-项集。项集的出现频率是包含项集的事 务数简称为频率、支持计数或计数。 ➢ 项集满足最小支持度,若项集的出现频率大 于或等于最小支持度与D中事务总数的乘积。 ➢ 如果项集满足最小支持度,则称它为频繁项 集。
第一节 关联规则挖掘
3、关联规则挖掘的分类标准 ➢ 根据规则集所涉及的抽象层:有些挖掘关联规
则的方法可以在不同的抽象层发现规则。如,
age( X ,"23...33") buys( X ,"os _ software") age( X ,"23...33") buys( X , software")
➢ 分析的结果可以用于市场规划、广告策划、分 类设计。例如,购物篮分析可以帮助经理设计 不同的商店布局,以及规划什么商品降价。
第一节 关联规则挖掘
1、购物篮分析 ✓ 策略一:经常购买的商品可以放近一些,以便
进一步刺激这些商品一起销售。 ✓ 策略二:将经常购买的商品放在商店的两端,
可能诱发买这些商品的顾客一路挑选其他商品。
购买的商品涉及不同的抽象层,称所挖掘的规则 集由多层关联规则组成。否则,规则只涉及单 一抽象层的项或属性,则该集合包含单层关联 规则。
第一节 关联规则挖掘
3、关联规则挖掘的分类标准 ➢ 根据关联规则的各种扩充:关联规则可以扩充
到相关分析,以识别项是否相关。用最大模式 (最大的频繁模式)或频繁闭项集显著压缩挖 掘所产生的频繁项集数。
第一节 关联规则挖掘
3、关联规则挖掘的分类标准 ➢ 根据规则中涉及的数据维:若关联规则中的项
或属性每个只涉及一个维,则它是单维关联规 则;若关联规则涉及两个或多个维,则它是多 维关联规则。如
单维:buys( X ,"computer") buys( X ,"os _ software") 多维:age( X ,"23...33") income( X ,"42K...62K") buys( X ," fashion _ car")
第二节 挖掘事务数据库的单维布尔关联规则
1、Apriori算法 Apriori算法是一种最有影响的挖掘布尔关联
规则频繁项集的算法,通过侯选项集找频繁项集。 基本思路: Apriori使用一种称作逐层搜索的迭代 方法,K-项集用于探索(K+1)-项集。首先,找 出频繁1-项集的集合,记为L1; L1用于找频繁2项集的集合L2 ,而L2用于找L3,如此下去,直到 找到频繁K-项集。找每个LK需要一次数据库扫描。 其过程包括:连接和剪枝两个方面。