R语言实验五
R语言实验报告
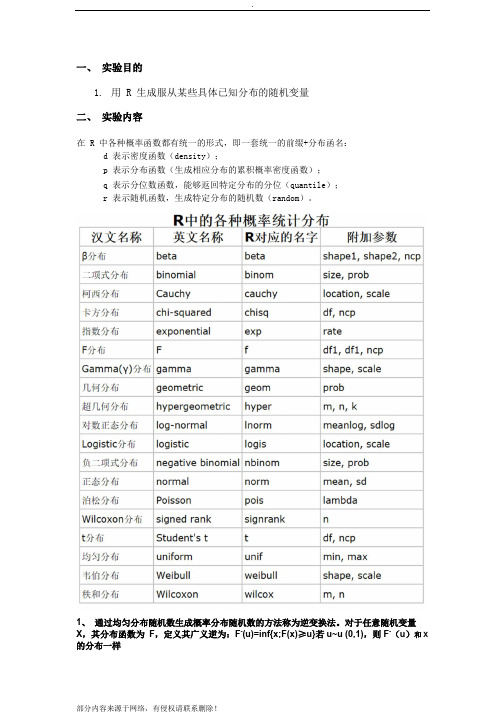
一、实验目的1.用 R 生成服从某些具体已知分布的随机变量二、实验内容在 R 中各种概率函数都有统一的形式,即一套统一的前缀+分布函名:d 表示密度函数(density);p 表示分布函数(生成相应分布的累积概率密度函数);q 表示分位数函数,能够返回特定分布的分位(quantile);r 表示随机函数,生成特定分布的随机数(random)。
1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x)≥u}若u~u (0,1),则F-(u)和X 的分布一样Example 1 如果X~Exp(1)(服从参数为 1 的指数分布),F(x)=1-e-x。
若u=1-e-x并且u~u(0,1),则X=-logU~Exp(1)则可以解出x=-log(1-u)通过随机数生成产生的分布与本身的指数分布结果相一致R 代码如下:nsim = 10^4U = runif(nsim)X = -log(U)Y = rexp(nsim)X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。
R语言-医药研究 logistic regression

科学技术献祖国5医药研究 logistic regression介绍R 语言的应用实际上都是在介绍算法,算法的本质属于脑筋急转弯,所以算法是不能申请组专利保护的。
然而算法一旦固化到电子产品当中,产生了可以摸得到的商品,这种商品就可以注册版权,受知识产权的保护。
同样的新发现的药物也是可以申请专利受法律保护,这就是现在药物发掘的工作如火如荼的原因。
那些制药公司都希望尽可能多的申请药物专利从中谋利。
在这里我们将简单介绍新的药品是如何发现的。
药品实验都是在生物活体上进行的,使用的实验对象可以是:小白鼠,狗,或者是其它的单细胞,多细胞生物。
关键的一点是使用的实验对象必须是完全相同的,实验结果才能有可比性。
举一个例子,双胞胎个体就是完全相同的生物个体,因为它们是从单一的受精卵分裂出来的。
但实验中我们有时需要用到上百个完全相同的实验个体,通过使用双胞胎不可能得到足够的实验对象。
另外一种办法,可以通过选种的方法来生成众多的完全相同的实验个体。
例如说我们可以有一百个小白鼠,它们每一个都有着完全相同的基因组成。
因为这些小白鼠是通过选种培育出来的,它们都有着共同的单一祖先。
在下面的实验中,我们使用200个这样具有相同基因组成的小白鼠。
介绍疼痛实验,一般是使用一束强光照射到小白鼠的尾巴上。
如果小白鼠的尾巴突然间抽动就说明小白鼠有了疼痛的感觉,这种实验是用来研究哺乳类动物对疼痛承受能力的方法。
吗啡是一种止疼药物,使用吗啡后哺乳类动物都会迟钝对疼痛的感觉。
研究人员新近发现了另外一种药物被称作代尔9号也可以用作麻醉剂。
研究人员想用吗啡与代尔9号相比较来明白哪种药物更有效。
研究人员也想知道当这两种药物同时被使用的时候,它们的药性可不可以相互促进。
发现这种相互促进的药性是十分重要的,因为单一使用某种药物可能会毒性非常的大。
如果有另外一种药物能使它们之间互相促进,就可以在两种药物都使用非常小的剂量的状况下达到比较好的医治效果。
这种药物互相作用在研究杀虫剂的课题中也经常被用到。
R语言综合实验报告

学号:2013310200629姓名:王丹学院:理学院专业:信息与计算科学成绩:日期:年月日基于工业机器人能否准确完成操作的时间序列分析摘要:时间序列分析是预测领域研究的重要工具之一,它描述历史数据随时间变化的规律,并用于预测数据。
本文首先介绍了一些常用的时间序列模型,包括建模前对数据的预处理、模型的识别以及模型的预测等。
通过多种方法分析所得到的数据,实现准确建模,可以得出正确的结论。
关键词:自回归(AR)模型,滑动平均(MA)模型,自回归滑动平均(ARMA)模型,ARMA最优子集一、问题提出,问题分析随着社会日新月异的发展,不断创新的科技为我们的生活带来了越来越多的便利。
机器人也逐渐走向了我们的生活,工厂里使用机器人去工作也可以大大减少生产成本,但为了保证产品质量,工厂使用的机器人应该多次测试,确保动作准确无误。
现有一批数据,包含了来自工业机器人的时间序列(机器人需要完成一系列的动作,与目标终点的距离以英寸为单位被记录下来,重复324次得到该时间序列),对于这些离散的数据,我们期望从中发掘一些信息,以便对机器人做更好的改进或者确定机器人是否可以投入使用。
但我们从中并不能看出什么,需要借助工具做一些处理,对数据进行分析。
时间序列分析是通过直观的数据比较或作图观测,去寻找序列中包含的变化规律,这种分析方法称为描述性时序分析。
在物理、天文、海洋学等科学领域,这种描述性时序分析方法经常能够使人们发现一些意想不到的规律,操作起来十分简单而且直观有效,因此从史前到现在一直被人们广泛使用,它也是我们进行统计时序分析的第一步。
我们将利用自回归(AR)模型、滑动平均(MA)模型以及自回归滑动平均(ARMA)模型去解决遇到的问题。
二、数据描述和初步分析下面是我们接收到的数据,数据来源:/~kchan/TSA.htm0.0011 0.0011 0.0024 0.0000 -0.0018 0.0055 0.0055 -0.00150.0047 -0.0001 0.0031 0.0031 0.0052 0.0034 0.0027 0.00410.0041 0.0034 0.0067 0.0028 0.0083 0.0083 0.0030 0.00320.0035 0.0041 0.0041 0.0053 0.0026 0.0074 0.0011 0.0011-0.0001 0.0008 0.0004 0.0000 0.0000 -0.0009 0.0038 0.00540.0002 0.0002 0.0036 -0.0004 0.0017 0.0000 0.0000 0.00470.0021 0.0080 0.0029 0.0029 0.0042 0.0052 0.0056 0.00550.0055 0.0010 0.0043 0.0006 0.0013 0.0013 0.0008 0.00230.0043 0.0013 0.0013 0.0045 0.0037 0.0015 0.0013 0.00130.0029 0.0039 -0.0018 0.0016 0.0016 -0.0003 0.0000 0.00090.0017 0.0017 0.0030 -0.0001 0.0070 -0.0008 -0.0008 0.00090.0025 0.0031 0.0002 0.0002 0.0022 0.0020 0.0003 0.00330.0033 0.0044 -0.0010 0.0048 0.0019 0.0019 0.0031 0.00200.0017 0.0014 0.0014 0.0039 0.0052 0.0020 0.0012 0.00120.0031 0.0022 0.0040 0.0038 0.0038 0.0007 0.0016 0.00240.0003 0.0003 0.0057 0.0006 0.0009 0.0040 0.0040 0.00350.0032 0.0068 0.0028 0.0028 0.0048 0.0035 0.0042 -0.0020-0.0020 0.0023 -0.0011 0.0062 -0.0021 -0.0021 0.0000 -0.0019-0.0005 0.0048 0.0048 0.0027 0.0009 -0.0002 0.0079 0.00790.0017 0.0034 0.0030 0.0025 0.0025 0.0004 0.0031 0.0057-0.0003 -0.0003 0.0006 0.0018 0.0022 0.0042 0.0042 0.0055-0.0005 -0.0053 0.0028 0.0028 0.0005 0.0036 0.0017 -0.0043-0.0043 0.0066 -0.0016 0.0055 -0.0011 -0.0011 -0.0049 0.00470.0056 0.0057 0.0057 -0.0002 0.0056 0.0037 0.0012 0.00120.0018 -0.0025 -0.0011 0.0027 0.0027 0.0039 0.0058 0.00030.0040 0.0040 0.0042 0.0000 0.0056 -0.0029 -0.0029 -0.00260.0016 0.0019 0.0015 0.0015 0.0007 0.0007 -0.0044 -0.0030-0.0030 0.0013 0.0029 -0.0010 0.0009 0.0009 -0.0016 0.00000.0000 0.0014 0.0014 -0.0003 0.0009 -0.0068 0.0003 0.0003-0.0012 0.0037 -0.0019 0.0023 0.0023 -0.0033 -0.0002 -0.00100.0021 0.0021 0.0026 -0.0002 0.0011 0.0028 0.0028 -0.00040.0026 -0.0015 0.0002 0.0002 0.0018 -0.0005 0.0004 -0.0008-0.0008 0.0018 0.0019 0.0029 -0.0022 -0.0022 0.0010 -0.00330.0020 0.0000 0.0000 0.0003 0.0007 -0.0009 -0.0035 -0.00350.0010 0.0007 0.0028 -0.0008 -0.0008 -0.0034 -0.0010 -0.0018-0.0021 -0.0021 -0.0006 -0.0018 -0.0046 -0.0017 -0.0017 -0.0001-0.0029 0.0020 -0.0049 -0.0049 -0.0021 -0.0027 -0.0018 -0.0015-0.0015 0.0051 -0.0002 0.0000 -0.0006 -0.0006 -0.0012 0.00120.0000 0.0021 0.0021 -0.0001 0.0022 0.0055 -0.0010 -0.00100.0048 0.0006 0.0026 0.0004 0.0004 0.0000 0.0000 0.00080.0044 0.0044 0.0002 0.0036这一群数目庞大的数据,以我们直观的判断,它们错综复杂,且毫无规律可言,根本不能从中得到有用的消息。
r语言实验报告

r语言实验报告R语言实验报告介绍•本文旨在对R语言实验报告进行相关介绍和指导。
准备工作•在开始编写R语言实验报告之前,需要进行一些准备工作:–安装R语言环境–确保安装必要的R包–理解实验要求和相关数据集实验报告结构•一个完整的R语言实验报告通常包含以下几个部分:1. 标题•实验报告的标题应简明扼要地描述实验内容。
2. 引言•引言部分应包含以下内容:–实验的背景和目的–实验所采用的数据集和方法的简要介绍3. 数据分析•数据分析部分是实验报告的重点,应包含以下内容:–数据的读取和预处理–数据的可视化–统计分析方法的应用–结果的解释和讨论4. 结论•结论部分应总结实验的结果,并对实验的目的和方法进行评价。
5. 参考文献•参考文献部分应列举实验报告中所引用的相关文献。
编写要点•在编写R语言实验报告时,需要遵守以下要点:1. 语法规范•使用清晰、准确的语法表达实验过程和结果。
2. 结果的解释•对于结果的解释,应该尽量采用简洁明了的语言,避免使用过于专业的术语或过于复杂的句子结构。
3. 图表的使用•图表是实验报告中常用的可视化工具,应合理使用图表来展示数据和结果,并配以简洁明了的图题和注解。
4. 逻辑性和连接性•实验报告应具有良好的逻辑性和连接性,各部分之间应有明确的联系和衔接,以确保整篇报告的连贯性。
结语•编写一份规范、完整的R语言实验报告需要系统的学习和实践,希望本文对您有所帮助。
参考文献•[参考文献1]•[参考文献2]继续编写一份更详细的R语言实验报告:R语言实验报告介绍•本文旨在对R语言实验报告进行相关介绍和指导。
准备工作•在开始编写R语言实验报告之前,需要进行一些准备工作:–安装R语言环境:确保在电脑上成功安装R语言的最新版本。
–确保安装必要的R包:根据实验需求,安装并加载所需的R包,例如ggplot2、dplyr等。
–理解实验要求和相关数据集:认真阅读实验要求,理解实验的目的和需求,并熟悉所使用的数据集。
r语言编程实验报告总结

r语言编程实验报告总结
本次实验主要是对R语言编程的学习和掌握进行实践操作,通过实验了解R语言的基本语法和数据结构,掌握R语言的编程方法和数据分析技巧。
在实验中,我们学习了R语言的基础知识,如基本数据类型、变量、运算符、数据结构等。
同时,我们也学习了R语言的控制结构,如条件语句、循环语句等,这些控制结构可以帮助我们更好地控制程序的执行。
除此之外,我们还学习了R语言的函数和包的使用,在实验中我们使用了一些常用的包,如ggplot2包和dplyr包,这些包可以帮助我们更加方便地进行数据分析和绘图。
同时,我们也学习了如何自己编写函数,并且熟练掌握了函数的调用和参数传递。
通过实验,我们还学习了如何进行数据处理和数据分析,包括数据的读取和写入、数据的清洗和转换、数据的统计分析和可视化等等。
我们使用R语言对一些真实数据进行了处理和分析,这些数据包括房价、气温、人口等等。
在实验中,我们遇到了一些问题,如代码错误、数据异常等等,但是通过对问题的分析和解决,我们不断提升了自己的编程能力和数据分析技能。
综上所述,通过本次实验,我们深入了解了R语言的编程方法和数据分析技巧,掌握了一些常用的包和函数,并且在实践中熟悉了数据处理和分析的整个过程,这对我们今后的学习和工作都具有重要的
意义。
r语言实验报告

武夷学院实验报告课程名称:大数据挖掘与统计机器学习项目名称:多元统计分析与R语言建模姓名:__张树捷__专业:数学与应用数学班级:__2班_学号:__20171071203__同组成员:无_时间:______一、实验部分:P37 3m=seq(0,3000,by=300)hist(as.matrix(jie),m,freq=F,col=1:7)m=seq(0,3000,by=300)hist(as.matrix(jie),m,freq=T,col=1:7)m=seq(0,96000,by=3000)t<-as.matrix(jie)cumsum(t)hist(cumsum(t),m,freq=F,col=1:12,las=3) 累计频率图:p55 二、2barplot(apply(dier,1,mean),las=3)#按行作均值条形图barplot(apply(dier,2,mean))#按列作均值图条形图boxplot(dier)#按列作箱尾图boxplot(dier,horizontal = T)#箱尾图中图形按水平放置stars(dier,full=T,key.loc = c(13,1.5))#具有图例的360度星相图stars(dier,full=T,draw.segments = T,key.loc = c(13,1.5))#具有图例的3 60度彩色星相图summary(dier)#数据分析图表faces(dier,ncol.plot = 7)#按每行7个作脸谱图library(MSG)#加载msg包andrews_curve(dier)#绘制调和曲线图P87 4cor(disan)#计算相关系数矩阵plot(disan)#散点图library(psych)#加载psych包corr.test(disan)#y,x1,x2,x3的相关系数fm=lm(y~.,data=disan)#显示多元线性回归模型summary(fm)#多元线性回归系数t检验(拟合优度检验)由于P<0.05,于是在05.0=α水平处拒绝0H ,接受1H ,即x1,x2,x3与y 之间存在回归关系。
R语言实验指导书
R语⾔实验指导书R语⾔实验指导书(⼆)2016年10⽉27⽇实验三创建与使⽤R语⾔数据集⼀、实验⽬得:1.了解R语⾔中得数据结构。
2.熟练掌握她们得创建⽅法,与函数中⼀些参数得使⽤。
3.对创建得数据结构进⾏,排序、查找、删除等简单得操作。
⼆、实验内容:1.向量得创建及因⼦得创建与查瞧有⼀份来⾃澳⼤利亚所有州与⾏政区得20个税务会计师得信息样本 1 以及她们各⾃所在地得州名。
州名为:tas, sa, qld, nsw, nsw, nt, wa, wa, qld, vic, nsw, vic, qld, qld, sa, tas, sa, nt, wa, vic。
1)将这些州名以字符串得形式保存在state当中。
2)创建⼀个为这个向量创建⼀个因⼦statef。
3)使⽤levels函数查瞧因⼦得⽔平。
2.矩阵与数组。
i.创建⼀个4*5得数组如图,创建⼀个索引矩阵如图,⽤这个索引矩阵访问数组,观察结果。
3.将之前得state,数组,矩阵合在⼀起创建⼀个长度为3得列表。
4.创建⼀个数据框如图。
5.将这个数据框按照mpg列进⾏排序。
6.访问数据框中drat列值为3、90得数据。
三、实验要求要求学⽣熟练掌握向量、矩阵、数据框、列表、因⼦得创建与使⽤。
实验四数据得导⼊导出⼀、实验⽬得1.熟练掌握从⼀些包中读取数据。
2.熟练掌握csv⽂件得导⼊。
3.创建⼀个数据框,并导出为csv格式。
2.查瞧R语⾔⾃带得数据集airquality(纽约1973年5-9⽉每⽇空⽓质量)。
3.列出airquality得前⼗列,并将这前⼗列保存到air中。
4.查瞧airquality中列得对象类型。
5.查瞧airquality数据集中各成分得名称6.将air这个数据框导出为csv格式⽂件。
(write、table (x, file ="", sep ="", row、names =TRUE, col、names =TRUE, quote =TRUE))三、实验要求要求学⽣掌握从包中读取数据,导⼊csv⽂件得数据,并学会将⽂件导出。
报告R语言实验五..docx
实验五常见分布的相关计算、随机抽样与模拟【实验类型】验证性【实验学时】2 学时【实验目的】1、掌握常见分布的分布函数、密度函数(或分布列)及分位数的计算方法;2、掌握样本统计量的计算方法及所表达的意义;3、了解随机模拟的基本思想及其应用。
【实验内容】1、组合数与组合方案的生成、概率的计算,2、常见分布的分布函数、密度函数(或分布列)以及分位数的计算;3、随机数的生成与随机模拟(蒙特卡洛仿真)。
【实验方法或步骤】第一部分、课件例题:1.#从1~5个数中,随机取3个的全部组合combn(1:5,3) #共10种组合方案combn(1:5,3,FUN=mean) #对每种组合方案求均值2.choose(5,3) #从5个数里面选3个的组合数目choose(50,3)factorial(10) #计算10!3.#3.从一副完全打乱的52张扑克中任取4张,计算下列事件的概率#(1)抽取4张依次为红心A,方块A,黑桃A和梅花A的概率1/prod(49:52) #prod()表示连乘积#(2)抽取4张为红心A,方块A,黑桃A和梅花A的概率.1/choose(52,4)4.设在15只同类型的零件中有2只是次品,一次任取3只,以X表示次品的只数,求X的分布律.x<-c(1,1,rep(0,13));x #样本空间(用1表示次品, 0为正品)X<-combn(x,3,FUN=sum) #从样本空间中任取3个元素的方案,并对每个方案求和,共455个数(取值0,1,2)p<-numeric(3) #定义p为数值型的3维向量,且初值为0for (i in 1:3)p[i]<-sum(X==i-1)/length(X) #sum(X==i-1)表示对X取值为i-1的个数求和,X的长度为455p5.# 例5.3 :计算3σ原则对应的概率x <- 1:3; p <- pnorm(x) - pnorm(-x); p# 例5.4 :令α=0.025,计算上α分位点z α .alpha <- 0.025; z <- qnorm(1-alpha); z6.#例5.5 :计算P{X≤160},其中X~U[150,200]。
R语言实验报告
R语言实验报告一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n,mean=0,sd=1)其中,n为产生随机值个数(长度),mean是平均数,sd是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中;计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结 这次试验是我第一次接触R 语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
武汉理工大学R语言实验报告
第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象
记录,实验过程发现的问题等)
原始数据(E:/fire.txt):
xy
3.4 26.2
1.8 17.8
4.6 31.3
2.3 23.1
3.1 27.5
5.5 36
0.7 14.1
3 22.3
2.6 19.6
4.3 31.3
2.1 24
1.1 17.3
6.1 43.2
4.8 36.4
3.8 26.1
打开 R 软件后依次按一下程序输入函数命令进行回归分析
1.数据准备
fire <- read.table('E:/fire.txt', head = T)
#读取数据
2.回归分析
plot(fire$y ~ fire$x)
#散点图:
fire.reg <- lm(fire$y ~ fire$x, data = fire)
summary(fire.reg)
#回归分析表:
#回归拟合
anova(fire.reg)
#方差分析表
abline(fire.reg, col = 2, lty = 2)
#拟合直线
3.残差分析 fire.res <- residuals(fire.reg) #残差 fire.sre <- rstandard(fire.reg) #学生化残差 plot(fire.sre) abline(h = 0) text(11, fire.sre[11], label = 11, adj = (-0.3), col = 2) #标注点
2. 一旦我们将时间序列读入 R,下一步通常是用这些数据绘制时间序列图,我 们可以使用 R 中的 plot.ts()函数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验五常见分布的相关计算、随机抽样与模拟【实验类型】验证性【实验学时】2 学时【实验目的】1、掌握常见分布的分布函数、密度函数(或分布列)及分位数的计算方法;2、掌握样本统计量的计算方法及所表达的意义;3、了解随机模拟的基本思想及其应用。
【实验内容】1、组合数与组合方案的生成、概率的计算,2、常见分布的分布函数、密度函数(或分布列)以及分位数的计算;3、随机数的生成与随机模拟(蒙特卡洛仿真)。
【实验方法或步骤】第一部分、课件例题:1.#从1~5个数中,随机取3个的全部组合combn(1:5,3) #共10种组合方案combn(1:5,3,FUN=mean) #对每种组合方案求均值2.choose(5,3) #从5个数里面选3个的组合数目choose(50,3)factorial(10) #计算10!3.#3.从一副完全打乱的52张扑克中任取4张,计算下列事件的概率#(1)抽取4张依次为红心A,方块A,黑桃A和梅花A的概率1/prod(49:52) #prod()表示连乘积#(2)抽取4张为红心A,方块A,黑桃A和梅花A的概率.1/choose(52,4)4.设在15只同类型的零件中有2只是次品,一次任取3只,以X表示次品的只数,求X 的分布律.x<-c(1,1,rep(0,13));x #样本空间(用1表示次品, 0为正品)X<-combn(x,3,FUN=sum) #从样本空间中任取3个元素的方案,并对每个方案求和,共455个数(取值0,1,2)p<-numeric(3) #定义p为数值型的3维向量,且初值为0for (i in 1:3)p[i]<-sum(X==i-1)/length(X) #sum(X==i-1)表示对X取值为i-1的个数求和,X的长度为455p5.# 例5.3 :计算3σ原则对应的概率x <- 1:3; p <- pnorm(x) - pnorm(-x); p# 例5.4 :令α=0.025,计算上α分位点z α.alpha <- 0.025; z <- qnorm(1-alpha); z6.#例5.5 :计算P{X≤160},其中X~U[150,200]。
p<-punif(160, min=150, max=200); p# 例5.6 :已知X~E(1/241),计算P{50<X≤100} 。
p<-pexp(100, rate=1/241)-pexp(50, rate=1/241); p# 例5.7 :已知X~B(80,0.01),计算P{X≥4} 。
p <- 1-pbinom(3, size=80, prob=0.01); p# 例5.8 :已知X~B(180,0.01),且P{X≤k}≥0.95,求k 。
n <- 180; p <- 0.01; k <- qbinom(0.95, n, p); k# 例5.9 :已知X~B(1000,0.01),求P{X≥2} 。
p1 <- 1-pbinom(1, size=1000, prob=0.001); p1p2 <- 1-ppois(1, lambda=1000*0.001); p27.x<-c(0:10,50);xxm<-mean(x);xmc(xm,mean(x,trim=0.10)) #去掉两端各10%数据后取平均8.x<-c(12,9,11,5,1,4,8,3,2,10,6,7);xy<-1:12;yvar(x) #方差sd(x) #标准差var(x,y) #协方差cov(x,y) #协方差9.x<-c(12,9,11,5,1,4,8,3,2,10,6,7,NA);x sort(x) #默认升序,不处理缺失数据sort(x,decreasing=TRUE) #降序sort(x,st=TRUE) #处理缺失数据sort(x,decreasing =TRUE,st=FALSE)10.#10.x<-c(12,9,11,5,1,4,8,3,2,10,6,7,NA)median(x)median(x,na.rm=TRUE)11.分位数quantile(1:10)12.#用于求解样本k阶中心矩的程序moment.R为:moment<-function(x, k, mean=0)sum((x-mean)^k)/length(x)skew <- function(x, flag = 1){ #计算偏度系数的程序 mu <- mean(x)if (flag == 1){m2 <- moment(x, 2, mean=mu)m3 <- moment(x, 3, mean=mu)Cs <- m3/sqrt(m2^3) }else{n <- length(x); S <- sd(x)Cs<-n/(n-1)/(n-2)*sum((x-mu)^3)/S^3}Cs}x<-rnorm(10000) #服从正态分布的随机数skew(x) #默认使用第一种方法(有偏)计算偏度系数skew(x,2) #使用第二种方法(无偏)计算偏度系数13.x<-rnorm(12) # 服从正态分布的随机数Fn<-ecdf(x) # 经验分布函数op<-par(mfrow=c(3,1),mgp=c(1.5,0.8,0),mar=0.1+c(3,3,2,1)) # 绘制多图, 3 行 1 列plot(Fn) # 默认参数,不画竖线plot(Fn,verticals=TRUE) # 有竖线plot(Fn,verticals=TRUE,do.points=FALSE) # 不画点par(op) # 多组图14. 生成随机数x <- rnorm(1000)par(mai=c(0.9, 0.9, 0.6, 0.2)) # 图形边界参数hist(x, prob = TRUE, col = "lightblue", # 直方图main="Normal Distribution")curve(dnorm(x), add = TRUE, col="red", lwd=2) # 绘制正态密度曲线expr<-expression(paste(mu==0, ",", sigma==1))legend(1, 0.35, legend = expr, col="red", lwd=2) # 添加给定内容的图例15.生成 10 个随机数,且每次的运算的结果均相同。
set.seed(166)runif(10)set.seed(166)runif(10)16.bootstrap.ci <- function(x, B, alpha=0.05){medians <- numeric(B) # 生成一个长度为 B 的向量for(i in 1:B){sam <- sample(x, replace=TRUE) # 有放回抽样medians[i] <- median(sam) # 向量每个元素为中位数}quantile(medians, c(alpha/2, 1-alpha/2)) # 百分位数函数,计算置信水平为 1- α的置信区间}#例5.11::用样本中位数计算总体中位数θ的置信区间x<-c(136.3, 136.6, 135.8, 135.4, 134.7, 135.0, 134.1, 143.3, 147.8, 148.8, 134.8, 135.2, 134.9, 146.5, 141.2, 135.4, 134.8, 135.8, 135.0, 133.7, 134.4, 134.9, 134.8, 134.5, 134.3, 135.2) # 样本bootstrap.ci(x, B=1000, alpha=0.05) # 置信水平为 0.95例5.12 的求解:train<-function(n){t1 <- sample(c(0, 5, 10), size=n, replace=T,prob=c(0.7, 0.2, 0.1)) # 火车出发时刻t2 <- rnorm(n, mean=30, sd=2) # 从 A 站到 B 站的运行时间t3 <- sample(c(28, 30, 32, 34), size=n, replace=T,prob=c(0.3, 0.4, 0.2, 0.1)) # 此人到达 B 站时刻sum( t1+t2 > t3)/n # 成功 ( 赶上火车 ) 出现的频率}train(10000) # 模拟 10000 次试验并计算概率#求解定积分的quad1() 函数quad1<-function(fun, a, b, M=1, n=1e6){ #M 为函数上界x<-runif(n, min=a, max=b)y<-runif(n, min=0, max=M) # 生成矩形区域的随机数k<-sum(y<fun(x)) # 落在曲边梯形内的随机点个数k/n*M*(b-a) } #k/n 表示梯形面积与矩形面积的比值#例5.13fun<-function(x) exp(-x^2) # 被积函数quad1(fun, a=-1, b=1) # 计算定积分integrate(fun,-1,1) # 使用 R 中的积分函数#求解二重积分的quad2() 函数quad2<-function(fun, a, b, c, d, M=1, n=1e6){ #M 为上界x<-runif(n, min=a, max=b)y<-runif(n, min=c, max=d)z<-runif(n, min=0, max=M) # 生成长方体内的随机数对k<-sum(z<fun(x,y)) # 落在曲顶柱体内的随机点个数k/n*M*(b-a)*(d-c) #k/n 表示曲顶柱体占长方体体积比值}#例5.14fun<-function(x,y) sqrt((x^2+y^2<=1)*(1-x^2-y^2)) # 定义被积函数,定义域内函数值不变,定义域外函数值为 0quad2(fun, a=-1, b=1, c=-1, d=1) # 计算二重积分RandomWalk<-function(n=10000){ # 编制函数par(mai=c(0.9, 0.9, 0.5, 0.2)) # 图形参数plot(c(0, 100), c(0, 100), type="n", xlab="X", ylab="Y", main="Random Walk in Two Dimensions")x<-y<-50 # 两变量同时赋值points(50, 50, pch=16, col="red", cex=1.5) # 绘制初始点for (i in 1:n){xi<-sample(c(1, 0, -1), 1) # 从 1,0,-1 中抽样一次yi<-sample(c(1, 0, -1), 1)lines(c(x, x+xi), c(y, y+yi)) # 绘制步骤的连线x <- x + xi; y <- y + yi # 下一步行走位置if (x>100 | x<0 | y>100 | y<0) break }} # 判断结束条件RandomWalk() # 调用函数第二部分、教材例题:1.#例5.1.2X<-c(1,1,0 ,1 ,0, 0, 1, 0 ,1 ,1,1, 0 ,1, 1 ,0 ,1,0 ,0 ,1, 0 ,1 ,0,1, 0 ,0 ,1,1 ,0 ,1, 1, 0, 1)theta<-mean(X)t<-theta/(1-theta)t#2#例5.1.4X<-c(0.59132754,0.12854935,0.46900228,0.29835980,0.24341462, 0.06566637,0.40085536,2.99687123,0.05278912,0.09898594) lambda<- 1/mean(X)lambdalambda<- 1/sd(X) #使用二阶矩进行矩法估计lambda#3#例5.1.5f <- function(P)(P^517)*(1-P)^483optimize(f,c(0,1),maximum = TRUE)#4#z.test()函数定义z.test<-function(x,n,sigma,alpha,u0=0,alternative="two.sided"){ options(digits=4)result<-list( )mean<-mean(x)z<-(mean-u0)/(sigma/sqrt(n))p<-pnorm(z,lower.tail=FALSE)result$mean<-meanresult$z<-zresult$p.value<-pif(alternative=="two.sided"){p<-2*presult$p.value<-p}else if (alternative == "greater"|alternative =="less" ){result$p.value<-p}else return("your input is wrong")result$conf.int<- c(mean-sigma*qnorm(1-alpha/2,mean=0, sd=1,lower.tail = TRUE)/sqrt(n),mean+sigma*qnorm(1-alpha/2,mean=0, sd=1,lower.tail = TRUE)/sqrt(n))result}#求置信区间的程序:conf.int<-function(x,n,sigma,alpha){options(digits=4)mean<-mean(x)c(mean-sigma*qnorm(1-alpha/2,mean=0, sd=1,lower.tail = TRUE)/sqrt(n),mean+sigma*qnorm(1-alpha/2,mean=0, sd=1,lower.tail = TRUE)/sqrt(n))}#例5.2.1x<-c(175 ,176 ,173,175,174,173,173,176,173,179 )result<-z.test(x,10,1.5,0.05)result$conf.intx<-c(175 ,176 ,173,175,174,173,173,176,173,179 )conf.int(x,10,1.5,0.05)#5#不知道方差,用函数t.test( )来求置信区间x<-c(175 , 176 , 173 , 175 ,174 ,173 , 173, 176 , 173,179 ) t.test(x)t.test(x)$conf.int #提取出置信区间的部分#6#函数chisq.var.test( )可以用来求σ 2 置信区间chisq.var.test <- function (x,var,alpha,alternative="two.sided"){ options(digits=4)result<-list( )n<-length(x)v<-var(x)result$var<-vchi2<-(n-1)*v/varresult$chi2<-chi2p<-pchisq(chi2,n-1)if(alternative == "less"|alternative=="greater"){result$p.value<-p} else if (alternative=="two.sided") {if(p>.5)p<-1-pp<-2*presult$p.value<-p} else return("your input is wrong")result$conf.int<-c((n-1)*v/qchisq(alpha/2, df=n-1, lower.tail=F),(n-1)*v/qchisq(alpha/2, df=n-1, lower.tail=T))result}#7#编写函数求置信区间two.sample.ci<-function(x,y,conf.level=0.95, sigma1,sigma2 ){ options(digits=4)m=length(x);n=length(y)xbar=mean(x)-mean(y);alpha = 1 - conf.levelzstar= qnorm(1-alpha/2)* (sigma1/m+sigma2/n)^(1/2)xbar +c(-zstar, +zstar)}#例5.3.1x<-c(628,583,510,554,612,523,530,615)y<-c(535,433,398,470,567,480,498,560,503,426)sigma1<-2140sigma2<-3250two.sample.ci(x,y,conf.level=0.95, sigma1,sigma2)#8#例5.3.2x<-c(628,583,510,554,612,523,530,615)y<-c(535,433,398,470,567,480,498,560,503,426)t.test(x,y,var.equal=TRUE)#9#例5.3.3x<-c(20.5,19.8,19.7,20.4,20.1,20.0,19.0,19.9)y<-c(20.7,19.8,19.5,20.8,20.4,19.6,20.2)var.test(x,y)#10#例5.4.1prop.test(38,200,correct=TRUE) #函数prop.test( )对p进行估计与检验binom.test(38,200) #函数binom.test( )可以求其置信区间#11#例5.5.1like<-c(478, 246)people<-c(1000, 750)prop.test(like, people)#自己编写没有修正的两比例之间的区间估计函数ratio.ci()ratio.ci<-function(x, y, n1, n2, conf.level=0.95){xbar1=x/n1;xbar2=y/n2xbar=xbar1-xbar2alpha = 1 - conf.levelzstar=qnorm(1-alpha/2)*(xbar1*(1-xbar1)/n1+xbar2*(1-xbar2)/n2)^(1/2) xbar +c(-zstar, +zstar)}ratio.ci(478,246,1000,750,conf.level=0.95)#12#例5.6.1#定义函数size.norm1( )求样本容量size.norm1<-function(d,var,conf.level) {alpha = 1 - conf.level((qnorm(1-alpha/2)*var^(1/2))/d)^2}size.norm1(2,500,conf.level=0.95)#13#通过循环确定样本容量,定义函数size.norm2( ) size.norm2<-function(s,alpha,d,m){t0<-qt(alpha/2,m,lower.tail=FALSE)n0<-(t0*s/d)^2t1<-qt(alpha/2,n0,lower.tail=FALSE)n1<-(t1*s/d)^2while(abs(n1-n0)>0.5){n0<-(qt(alpha/2,n1,lower.tail=FALSE)*s/d)^2 n1<-(qt(alpha/2,n0,lower.tail=FALSE)*s/d)^2}n1}#例5.6.2size.norm2(10,0.01,2,100)#14#估计比例p时样本容量的确定,定义函数size.bin( ) size.bin<-function(d, p, conf.level=0.95) {alpha = 1 - conf.level((qnorm(1-alpha/2))/d)^2*p*(1-p)}#例5.6.3size.bin(0.03, 0.9, 0.95)第三部分、课后习题:5.1x=seq(3,21,by=2)y=c(21,16,15,26,22,14,21,22,18,25)u=rep(x,y)u1=mean(u)s1=sd(u)a=u1-sqrt(3)*s1ab=u1+sqrt(3)*s1b因此,α,β的矩估计值为:2.217379、22.402625.2x=seq(0,6,by=1)y=c(17,20,10,2,1,0,0)x1=x*ymu=mean(x1)mu结论:平均每升水中大肠杆菌个数为7.142857时,才能使上述情况的概率达到最大.5.3(1)x=c(482,493,457,471,510,446,435,418,394,469 )t.test(x)结论:置信水平为0.95的置信区间为[432.3069,482.6931](2)chisq.var.test<-function(x,var,alpha,alternative="two.sided"){options(digits=4)result<-list()n<-length(x)v<-var(x)result$var<-v;chi2<-(n-1)*v/varresult$chi2<-chi2;p<-pchisq(chi2,n-1)result$p.value<-pif(alternative=="less")result$p.value<-pchaisq(chi2,n-1,loer.tail=F)else if(alternative=="two.sider")result$p.value<-2*min(pchaisq(chi2,n-1),pchaisq(chi2,n-1,lower,tail=F)) result$conf.int<-c((n-1)*v/qchisq(alpha/2,df=n-1,lower.tail=FALSE),(n-1)*v/qchisq(alpha/2,df=n-1,lower.tail=TRUE))result}x<-c(482,493,457,471,510,446,435,418,394,469)chisq.var.test(x,var(x),0.10,alternative="two.side")结论:σ的置信水平为0.90的置信区间为[659.8,3357.0]5.4(1)X<-c(25,28,23,26,29,22)Y<-c(28,23,30,35,21,27)var.test(X,Y)结论:由于P值(=0.2)>0.05,因此认为两种卷烟中尼古丁含量的方差相等。