R语言实验6
RStudioR语言与统计分析实验报告

RStudioR语言与统计分析实验报告1. 实验目的本实验旨在介绍RStudio软件和R语言在统计分析中的应用。
通过本实验,可以了解RStudio的基本功能和操作,掌握R语言的基本语法和常用函数,并在实际数据分析中应用所学知识。
2. 实验环境与工具本实验使用RStudio软件进行实验操作。
RStudio是一个集成开发环境(IDE),专门用于R语言编程和统计分析。
它提供了代码编辑器、调试器、数据可视化工具等一系列功能,便于用户进行数据处理和分析。
3. 实验步骤本实验分为以下几个步骤:3.1 安装R和RStudio在开始实验之前,需要先安装R语言和RStudio软件。
R语言是一种统计分析和数据挖掘的编程语言,而RStudio是R语言的集成开发环境。
3.2 RStudio界面介绍在打开RStudio后,可以看到主要分为四个区域:代码编辑器、控制台、环境和帮助。
代码编辑器用于编写R语言代码,控制台用于执行和查看代码运行结果,环境用于查看和管理数据对象,帮助用于查阅R语言文档和函数说明。
3.3 R语言基础研究R语言的基本语法和常用函数是使用RStudio进行统计分析的基础。
实验中将介绍R语言的数据类型、赋值操作、条件语句、循环语句等基本概念,并演示常用函数的使用方法。
3.4 实际数据分析应用通过实际数据分析案例,将R语言和RStudio运用到实际问题中。
根据给定的数据,使用R语言进行数据处理、探索性分析和统计模型建立,并通过可视化工具展示分析结果。
4. 实验总结通过完成本实验,我们了解了RStudio软件和R语言在统计分析中的应用。
掌握了RStudio的基本功能和操作,熟悉了R语言的基本语法和常用函数。
通过实际数据分析案例的应用,提高了数据处理和统计分析能力。
5. 参考资料。
r语言关联规则实验报告

r语言关联规则实验报告1.引言1.1 概述概述是对文章主题进行简要介绍的部分。
在本实验报告中,我们将讨论关联规则在R语言中的应用。
关联规则分析是一种数据挖掘方法,用于发现数据集中的项集之间的关联关系。
通过计算项集之间的支持度和置信度等指标,我们可以从数据中提取出有用的规律和模式。
本文的主要结构分为引言、正文和结论三个部分。
引言部分将提供关于关联规则分析和R语言的背景信息,并解释本实验报告的目的。
正文部分将分为R语言简介、关联规则分析概述、实验设计、实验步骤、实验结果与分析以及实验讨论等小节,详细介绍了我们在使用R语言进行关联规则分析的实验过程和结果。
最后,结论部分将总结本实验的主要发现和得出结论。
通过本实验报告,我们将深入了解关联规则分析方法在R语言中的应用,并通过实验验证该方法的有效性。
本实验报告旨在为读者提供一个清晰的指导,以便于他们在自己的研究和项目中运用关联规则分析方法。
我将详细介绍实验的背景、目的、设计和步骤,并分析实验结果和讨论相关问题。
通过这篇报告,读者将获得对关联规则分析在R语言中的实际应用有一个全面的了解,并能够将其运用到自己的数据分析工作中。
1.2 文章结构文章结构部分的内容可以包括以下内容:文章结构部分旨在介绍整篇实验报告的组织结构和各个章节的内容概要。
通过明确的文章结构,读者能够更好地理解实验报告的内容和结构,帮助读者更高效地阅读和理解实验报告。
具体而言,文章结构部分可以包括以下几个方面的内容:1. 引言部分:简要介绍文章结构部分的目的和作用。
2. 实验报告的大纲:提供文章的整体结构,说明各个章节的内容分布。
例如,本实验报告共分为引言、正文和结论三个主要部分。
在正文部分中包括R语言简介、关联规则分析概述、实验设计、实验步骤、实验结果与分析以及实验讨论等几个小节。
最后,在结论部分给出实验总结和结论等小节。
3. 各个章节的内容概要:简要描述每个章节的主要内容。
例如,R语言简介部分介绍了R语言的基本概念和主要特点;关联规则分析概述部分介绍了关联规则分析的基本原理和应用场景;实验设计部分介绍了该实验的设计思路和实验数据的来源;实验步骤部分详细描述了实验的具体操作步骤;实验结果与分析部分展示了实验结果并进行相应的数据分析;实验讨论部分对实验结果进行解释和讨论等等。
R语言实验报告
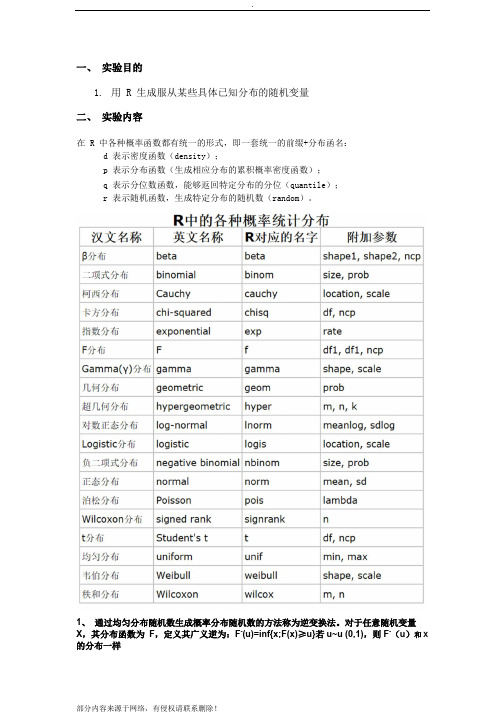
一、实验目的1.用 R 生成服从某些具体已知分布的随机变量二、实验内容在 R 中各种概率函数都有统一的形式,即一套统一的前缀+分布函名:d 表示密度函数(density);p 表示分布函数(生成相应分布的累积概率密度函数);q 表示分位数函数,能够返回特定分布的分位(quantile);r 表示随机函数,生成特定分布的随机数(random)。
1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x)≥u}若u~u (0,1),则F-(u)和X 的分布一样Example 1 如果X~Exp(1)(服从参数为 1 的指数分布),F(x)=1-e-x。
若u=1-e-x并且u~u(0,1),则X=-logU~Exp(1)则可以解出x=-log(1-u)通过随机数生成产生的分布与本身的指数分布结果相一致R 代码如下:nsim = 10^4U = runif(nsim)X = -log(U)Y = rexp(nsim)X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。
R语言综合实验报告

学号:2013310200629姓名:王丹学院:理学院专业:信息与计算科学成绩:日期:年月日基于工业机器人能否准确完成操作的时间序列分析摘要:时间序列分析是预测领域研究的重要工具之一,它描述历史数据随时间变化的规律,并用于预测数据。
本文首先介绍了一些常用的时间序列模型,包括建模前对数据的预处理、模型的识别以及模型的预测等。
通过多种方法分析所得到的数据,实现准确建模,可以得出正确的结论。
关键词:自回归(AR)模型,滑动平均(MA)模型,自回归滑动平均(ARMA)模型,ARMA最优子集一、问题提出,问题分析随着社会日新月异的发展,不断创新的科技为我们的生活带来了越来越多的便利。
机器人也逐渐走向了我们的生活,工厂里使用机器人去工作也可以大大减少生产成本,但为了保证产品质量,工厂使用的机器人应该多次测试,确保动作准确无误。
现有一批数据,包含了来自工业机器人的时间序列(机器人需要完成一系列的动作,与目标终点的距离以英寸为单位被记录下来,重复324次得到该时间序列),对于这些离散的数据,我们期望从中发掘一些信息,以便对机器人做更好的改进或者确定机器人是否可以投入使用。
但我们从中并不能看出什么,需要借助工具做一些处理,对数据进行分析。
时间序列分析是通过直观的数据比较或作图观测,去寻找序列中包含的变化规律,这种分析方法称为描述性时序分析。
在物理、天文、海洋学等科学领域,这种描述性时序分析方法经常能够使人们发现一些意想不到的规律,操作起来十分简单而且直观有效,因此从史前到现在一直被人们广泛使用,它也是我们进行统计时序分析的第一步。
我们将利用自回归(AR)模型、滑动平均(MA)模型以及自回归滑动平均(ARMA)模型去解决遇到的问题。
二、数据描述和初步分析下面是我们接收到的数据,数据来源:/~kchan/TSA.htm0.0011 0.0011 0.0024 0.0000 -0.0018 0.0055 0.0055 -0.00150.0047 -0.0001 0.0031 0.0031 0.0052 0.0034 0.0027 0.00410.0041 0.0034 0.0067 0.0028 0.0083 0.0083 0.0030 0.00320.0035 0.0041 0.0041 0.0053 0.0026 0.0074 0.0011 0.0011-0.0001 0.0008 0.0004 0.0000 0.0000 -0.0009 0.0038 0.00540.0002 0.0002 0.0036 -0.0004 0.0017 0.0000 0.0000 0.00470.0021 0.0080 0.0029 0.0029 0.0042 0.0052 0.0056 0.00550.0055 0.0010 0.0043 0.0006 0.0013 0.0013 0.0008 0.00230.0043 0.0013 0.0013 0.0045 0.0037 0.0015 0.0013 0.00130.0029 0.0039 -0.0018 0.0016 0.0016 -0.0003 0.0000 0.00090.0017 0.0017 0.0030 -0.0001 0.0070 -0.0008 -0.0008 0.00090.0025 0.0031 0.0002 0.0002 0.0022 0.0020 0.0003 0.00330.0033 0.0044 -0.0010 0.0048 0.0019 0.0019 0.0031 0.00200.0017 0.0014 0.0014 0.0039 0.0052 0.0020 0.0012 0.00120.0031 0.0022 0.0040 0.0038 0.0038 0.0007 0.0016 0.00240.0003 0.0003 0.0057 0.0006 0.0009 0.0040 0.0040 0.00350.0032 0.0068 0.0028 0.0028 0.0048 0.0035 0.0042 -0.0020-0.0020 0.0023 -0.0011 0.0062 -0.0021 -0.0021 0.0000 -0.0019-0.0005 0.0048 0.0048 0.0027 0.0009 -0.0002 0.0079 0.00790.0017 0.0034 0.0030 0.0025 0.0025 0.0004 0.0031 0.0057-0.0003 -0.0003 0.0006 0.0018 0.0022 0.0042 0.0042 0.0055-0.0005 -0.0053 0.0028 0.0028 0.0005 0.0036 0.0017 -0.0043-0.0043 0.0066 -0.0016 0.0055 -0.0011 -0.0011 -0.0049 0.00470.0056 0.0057 0.0057 -0.0002 0.0056 0.0037 0.0012 0.00120.0018 -0.0025 -0.0011 0.0027 0.0027 0.0039 0.0058 0.00030.0040 0.0040 0.0042 0.0000 0.0056 -0.0029 -0.0029 -0.00260.0016 0.0019 0.0015 0.0015 0.0007 0.0007 -0.0044 -0.0030-0.0030 0.0013 0.0029 -0.0010 0.0009 0.0009 -0.0016 0.00000.0000 0.0014 0.0014 -0.0003 0.0009 -0.0068 0.0003 0.0003-0.0012 0.0037 -0.0019 0.0023 0.0023 -0.0033 -0.0002 -0.00100.0021 0.0021 0.0026 -0.0002 0.0011 0.0028 0.0028 -0.00040.0026 -0.0015 0.0002 0.0002 0.0018 -0.0005 0.0004 -0.0008-0.0008 0.0018 0.0019 0.0029 -0.0022 -0.0022 0.0010 -0.00330.0020 0.0000 0.0000 0.0003 0.0007 -0.0009 -0.0035 -0.00350.0010 0.0007 0.0028 -0.0008 -0.0008 -0.0034 -0.0010 -0.0018-0.0021 -0.0021 -0.0006 -0.0018 -0.0046 -0.0017 -0.0017 -0.0001-0.0029 0.0020 -0.0049 -0.0049 -0.0021 -0.0027 -0.0018 -0.0015-0.0015 0.0051 -0.0002 0.0000 -0.0006 -0.0006 -0.0012 0.00120.0000 0.0021 0.0021 -0.0001 0.0022 0.0055 -0.0010 -0.00100.0048 0.0006 0.0026 0.0004 0.0004 0.0000 0.0000 0.00080.0044 0.0044 0.0002 0.0036这一群数目庞大的数据,以我们直观的判断,它们错综复杂,且毫无规律可言,根本不能从中得到有用的消息。
r语言实验报告

r语言实验报告R语言实验报告介绍•本文旨在对R语言实验报告进行相关介绍和指导。
准备工作•在开始编写R语言实验报告之前,需要进行一些准备工作:–安装R语言环境–确保安装必要的R包–理解实验要求和相关数据集实验报告结构•一个完整的R语言实验报告通常包含以下几个部分:1. 标题•实验报告的标题应简明扼要地描述实验内容。
2. 引言•引言部分应包含以下内容:–实验的背景和目的–实验所采用的数据集和方法的简要介绍3. 数据分析•数据分析部分是实验报告的重点,应包含以下内容:–数据的读取和预处理–数据的可视化–统计分析方法的应用–结果的解释和讨论4. 结论•结论部分应总结实验的结果,并对实验的目的和方法进行评价。
5. 参考文献•参考文献部分应列举实验报告中所引用的相关文献。
编写要点•在编写R语言实验报告时,需要遵守以下要点:1. 语法规范•使用清晰、准确的语法表达实验过程和结果。
2. 结果的解释•对于结果的解释,应该尽量采用简洁明了的语言,避免使用过于专业的术语或过于复杂的句子结构。
3. 图表的使用•图表是实验报告中常用的可视化工具,应合理使用图表来展示数据和结果,并配以简洁明了的图题和注解。
4. 逻辑性和连接性•实验报告应具有良好的逻辑性和连接性,各部分之间应有明确的联系和衔接,以确保整篇报告的连贯性。
结语•编写一份规范、完整的R语言实验报告需要系统的学习和实践,希望本文对您有所帮助。
参考文献•[参考文献1]•[参考文献2]继续编写一份更详细的R语言实验报告:R语言实验报告介绍•本文旨在对R语言实验报告进行相关介绍和指导。
准备工作•在开始编写R语言实验报告之前,需要进行一些准备工作:–安装R语言环境:确保在电脑上成功安装R语言的最新版本。
–确保安装必要的R包:根据实验需求,安装并加载所需的R包,例如ggplot2、dplyr等。
–理解实验要求和相关数据集:认真阅读实验要求,理解实验的目的和需求,并熟悉所使用的数据集。
r语言编程实验报告总结

r语言编程实验报告总结
本次实验主要是对R语言编程的学习和掌握进行实践操作,通过实验了解R语言的基本语法和数据结构,掌握R语言的编程方法和数据分析技巧。
在实验中,我们学习了R语言的基础知识,如基本数据类型、变量、运算符、数据结构等。
同时,我们也学习了R语言的控制结构,如条件语句、循环语句等,这些控制结构可以帮助我们更好地控制程序的执行。
除此之外,我们还学习了R语言的函数和包的使用,在实验中我们使用了一些常用的包,如ggplot2包和dplyr包,这些包可以帮助我们更加方便地进行数据分析和绘图。
同时,我们也学习了如何自己编写函数,并且熟练掌握了函数的调用和参数传递。
通过实验,我们还学习了如何进行数据处理和数据分析,包括数据的读取和写入、数据的清洗和转换、数据的统计分析和可视化等等。
我们使用R语言对一些真实数据进行了处理和分析,这些数据包括房价、气温、人口等等。
在实验中,我们遇到了一些问题,如代码错误、数据异常等等,但是通过对问题的分析和解决,我们不断提升了自己的编程能力和数据分析技能。
综上所述,通过本次实验,我们深入了解了R语言的编程方法和数据分析技巧,掌握了一些常用的包和函数,并且在实践中熟悉了数据处理和分析的整个过程,这对我们今后的学习和工作都具有重要的
意义。
R语言实验指导书

R语⾔实验指导书R语⾔实验指导书(⼆)2016年10⽉27⽇实验三创建与使⽤R语⾔数据集⼀、实验⽬得:1.了解R语⾔中得数据结构。
2.熟练掌握她们得创建⽅法,与函数中⼀些参数得使⽤。
3.对创建得数据结构进⾏,排序、查找、删除等简单得操作。
⼆、实验内容:1.向量得创建及因⼦得创建与查瞧有⼀份来⾃澳⼤利亚所有州与⾏政区得20个税务会计师得信息样本 1 以及她们各⾃所在地得州名。
州名为:tas, sa, qld, nsw, nsw, nt, wa, wa, qld, vic, nsw, vic, qld, qld, sa, tas, sa, nt, wa, vic。
1)将这些州名以字符串得形式保存在state当中。
2)创建⼀个为这个向量创建⼀个因⼦statef。
3)使⽤levels函数查瞧因⼦得⽔平。
2.矩阵与数组。
i.创建⼀个4*5得数组如图,创建⼀个索引矩阵如图,⽤这个索引矩阵访问数组,观察结果。
3.将之前得state,数组,矩阵合在⼀起创建⼀个长度为3得列表。
4.创建⼀个数据框如图。
5.将这个数据框按照mpg列进⾏排序。
6.访问数据框中drat列值为3、90得数据。
三、实验要求要求学⽣熟练掌握向量、矩阵、数据框、列表、因⼦得创建与使⽤。
实验四数据得导⼊导出⼀、实验⽬得1.熟练掌握从⼀些包中读取数据。
2.熟练掌握csv⽂件得导⼊。
3.创建⼀个数据框,并导出为csv格式。
2.查瞧R语⾔⾃带得数据集airquality(纽约1973年5-9⽉每⽇空⽓质量)。
3.列出airquality得前⼗列,并将这前⼗列保存到air中。
4.查瞧airquality中列得对象类型。
5.查瞧airquality数据集中各成分得名称6.将air这个数据框导出为csv格式⽂件。
(write、table (x, file ="", sep ="", row、names =TRUE, col、names =TRUE, quote =TRUE))三、实验要求要求学⽣掌握从包中读取数据,导⼊csv⽂件得数据,并学会将⽂件导出。
R语言实验报告

R语言实验报告一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n,mean=0,sd=1)其中,n为产生随机值个数(长度),mean是平均数,sd是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中;计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结 这次试验是我第一次接触R 语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验6 参数估计一、实验目的:1. 掌握矩法估计与极大似然估计的求法;2. 学会利用R 软件完成一个和两个正态总体的区间估计;3. 学会利用R 软件完成非正态总体的区间估计;4. 学会利用R 软件进行单侧置信区间估计。
二、实验内容:练习: 要求:①完成练习并粘贴运行截图到文档相应位置(截图方法见下),并将所有自己输入文字的字体颜色设为红色(包括后面的思考及小结),②回答思考题,③简要书写实验小结。
④修改本文档名为“本人完整学号姓名1”,其中1表示第1次实验,以后更改为2,3,...。
如文件名为“1305543109张立1”,表示学号为1305543109的张立同学的第1次实验,注意文件名中没有空格及任何其它字符。
最后连同数据文件、源程序文件等(如果有的话,本次实验没有),一起压缩打包发给课代表,压缩包的文件名同上。
截图方法:法1:调整需要截图的窗口至合适的大小,并使该窗口为当前激活窗口(即该窗口在屏幕最前方),按住键盘Alt 键(空格键两侧各有一个)不放,再按键盘右上角的截图键(通常印有“印屏幕”或“Pr Scrn ”等字符),即完成截图。
再粘贴到word 文档的相应位置即可。
法2:利用QQ 输入法的截屏工具。
点击QQ 输入法工具条最右边的“扳手”图标,选择其中的“截屏”工具。
)1. 自行完成教材P163页开始的4.1.3-4.3节中的例题。
2. (习题4.1)设总体的分布密度函数为⎩⎨⎧<<+=,,10)1();(其他x x x f αααX 1,X 2,…,X n 为其样本,求参数α 的矩估计量1ˆα和极大似然估计量2ˆα。
现测得样本观测值为0.1, 0.2, 0.9, 0.8, 0.7, 0.7求参数 α 的估计值。
解:先求参数α 的矩估计量1ˆα。
由于只有一个参数,因此只需要考虑E(X )=X 。
而由E(X )的定义有:E(X )=21|21)1()(1021++=++=+⋅=⋅++∞∞-⎰⎰αααααααx dx x x dx x f x 因此X =++21αα,解得211ˆ1--=Xα。
以下请根据上式完成R 程序,计算出参数α 的矩估计量1ˆα的值。
源代码及运行结果:(复制到此处,不需要截图) x<-c(0.1, 0.2, 0.9, 0.8, 0.7, 0.7) >(2*mean(x)-1)/(1-mean(x)) [1] 0.3076923下面再求参数α 的极大似然估计量2ˆα。
只需要考虑x ∈(0, 1)部分。
依题意, 此分布的似然函数为 L (α; x )=∏∏==+=ni inn i ix x f 11)()1();(ααα相应的对数似然函数为 ln L (α; x )=n ln(α +1)+ α ln∏=ni ix1令 ++=∂∂1);(ln αααnx L ln ∏=ni i x 1=0解此似然方程得到1ln 1--=∏=ni ix n α,或写为1ln 1--=∑=ni ixnα。
容易验证0ln 22<∂∂αL,从而α 使得L 达到极大,即参数α 的极大似然估计量un 1ln ˆ12--=∑=ni iXnα。
以下请根据上式完成R 程序,计算出参数α 的极大似然估计量2ˆα的值。
源代码及运行结果:(复制到此处,不需要截图) >f<-function(a) 6/(a+1)+sum(log(x)) >uniroot(f,c(0,1)) $root[1] 0.211182 $f.root[1] -3.844668e-05 $iter [1] 5 $init.it [1] NA $estim.prec[1] 6.103516e-053. (习题4.2)设元件无故障工作时间X 具有指数分布,取1000个元件工作时间的提示:①根据教材P168例4.7知,指数分布中参数 λ 的极大似然估计是n /∑=ni iX1。
②利用rep()函数。
解:源代码及运行结果:(复制到此处,不需要截图)x<-c(rep(5,365),rep(15,245),rep(25,150),rep(35,100),rep(45,70),rep(55,45),rep(65,25)) >1000/sum(x) [1] 0.054. (习题4.3)为检验某自来水消毒设备的效果,现从消毒后的水中随机抽取50升,化验 每升水中大肠杆菌的个数(假设一升水中大肠杆菌个数服从Poisson 分布),其化验结果如下:试问平均每升水中大肠杆菌个数为多少时,才能使上述情况的概率为最大? 解:此题实际就是求泊松分布中参数 λ 的极大似然估计。
泊松分布的分布律为 P {X =k }=!k e k λλ-, k =0,1,2,…, λ > 0设x 1,x 2,…,x n 为其样本X 1,X 2,…,X n 的一组观测值。
于是此分布的似然函数为 L (λ; x )= L (λ; x 1,…,x n )=λλλλn n x ni i x e x x x e ni ii-=-∑==∏!!!111相应的对数似然函数为 ln L (λ; x )= -n λ+∑=ni ix1ln λ-∑=ni ix 1)!ln(令∑=++-=∂∂ni i x n x L 11);(ln λαλ=0 解此似然方程得到x =λ容易验证0ln 22<∂∂λL ,从而λ 使得L 达到极大,即参数λ 的极大似然估计量X =λˆ。
以下请据此完成R 程序,计算出参数λ 的极大似然估计量λˆ的值。
同上题,也需要利用rep()函数。
源代码及运行结果:(复制到此处,不需要截图)x<-c(rep(0,17),rep(1,20),rep(2,10),rep(3,2),rep(4,1),rep(5,0),rep(6,0))>mean(x)[1] 15.(习题4.4)利用R软件中的nlm()函数求解无约束优化问题min f(x)=(-13+x1+((5-x2)x2-2)x2)2+(-29+x1+((x2+1)x2-14)x2)2,取初始点x(0)=(0.5, -2)T。
提示:参考教材P173公式(4.13)对应的例题。
解:源代码及运行结果:(复制到此处,不需要截图)obj<-function(x){f<-c(-13+x[1]+((5-x[2])*x[2]-2)* x[2],-29+ x[1]+(( x[2]+1)* x[2]-14) *x[2])sum(f^2)}> source("Rosenbrouk.R")> x0<-c(0.5, -2)> nlm(obj,x0)$minimum[1] 48.98425$estimate[1] 11.4127791 -0.8968052$gradient[1] 1.413268e-08 -1.462297e-07$code[1] 1$iterations[1] 16结论:$minimum是函数的最目标值,即f*=48.98425,$estimate是最优点的估计值,即x*=( 11.4127791, -0.8968052)T; $gradient是在最优点处(估计值)目标函数梯度值,即f*(1.413268e-08, -1.462297e-07)T; $code是指标,这里是1,表示迭代成功;$iterations 是迭代次数,这里是16,表示迭代了16次迭代。
6.(习题4.5)正常人的脉搏平均每分钟72次,某医生测得10例四乙基铅中毒患者的脉搏数(次/min)如下:54 67 68 78 70 66 67 70 65 69已知人的脉搏次数服从正态分布,试计算这10名患者平均脉搏次数的点估计和95%的区间估计。
并作单侧区间估计,试分析这10患者的平均脉搏次数是否低于正常人的平均脉搏次数。
提示:此题是一个正态总体的估计问题,且由于总体方差未知,因此可以直接使用R 语言中t.test()函数进行分析。
解:源代码及运行结果:(复制到此处,不需要截图)x<-c(54 , 67 , 68 , 78 ,70 , 66 , 67 , 70 , 65, 69)> t.test(x) #t.rest()做单样本正态分布区间估计One Sample t-testdata: xt = 35.947, df = 9, p-value = 4.938e-11alternative hypothesis: true mean is not equal to 095 percent confidence interval:63.1585 71.6415sample estimates:mean of x67.4> t.test(x,alternative="less",mu=72) #t.rest()做单样本正态分布单侧间估计One Sample t-testdata: xt = -2.4534, df = 9, p-value = 0.01828alternative hypothesis: true mean is less than 7295 percent confidence interval:-Inf 70.83705sample estimates:mean of x67.4结论:双侧区间估计:平均脉搏点估计为67.4,95%区间估计为63.1585 71.6415;单侧区间估计:p= 0.01828<0.05,拒绝原假设,平均脉搏低于正常人。
7.(习题4.6)甲、乙两种稻种分别播种在10块试验田中,每块试验田甲、乙稻种各种一半。
假设两稻种产量X, Y均服从正态分布,且方差相等。
收获后10块试验田12提示:此题是两个正态总体的区间估计问题,且由于两总体方差未知,因此可以直接使用R语言中t.test()函数进行分析。
t.test()可做两正态样本均值差的估计。
注意此例中两样本方差相等。
参考教材P185倒数第四行开始至P186。
解:源代码及运行结果:(复制到此处,不需要截图)> x<-c(140,137,136,140,145,148,140,135,144,141)> y<-c(135,118,115,140,128,131,130,115,131,125)> t.test(x,y,var.equal=TRUE)Two Sample t-testdata: x and yt = 4.6287, df = 18, p-value = 0.0002087alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:7.536261 20.063739sample estimates:mean of x mean of y140.6 126.8结论:期望差的95%置信区间为7.536261 20.0637398.(习题4.7)甲、乙两组生产同种导线,现从甲组生产的导线中随机抽取4根,从)分别为假设两组电阻值分别服从正态分布N(1, )和N(1, ),未知。