R语言实验
RStudioR语言与统计分析实验报告

RStudioR语言与统计分析实验报告1. 实验目的本实验旨在介绍RStudio软件和R语言在统计分析中的应用。
通过本实验,可以了解RStudio的基本功能和操作,掌握R语言的基本语法和常用函数,并在实际数据分析中应用所学知识。
2. 实验环境与工具本实验使用RStudio软件进行实验操作。
RStudio是一个集成开发环境(IDE),专门用于R语言编程和统计分析。
它提供了代码编辑器、调试器、数据可视化工具等一系列功能,便于用户进行数据处理和分析。
3. 实验步骤本实验分为以下几个步骤:3.1 安装R和RStudio在开始实验之前,需要先安装R语言和RStudio软件。
R语言是一种统计分析和数据挖掘的编程语言,而RStudio是R语言的集成开发环境。
3.2 RStudio界面介绍在打开RStudio后,可以看到主要分为四个区域:代码编辑器、控制台、环境和帮助。
代码编辑器用于编写R语言代码,控制台用于执行和查看代码运行结果,环境用于查看和管理数据对象,帮助用于查阅R语言文档和函数说明。
3.3 R语言基础研究R语言的基本语法和常用函数是使用RStudio进行统计分析的基础。
实验中将介绍R语言的数据类型、赋值操作、条件语句、循环语句等基本概念,并演示常用函数的使用方法。
3.4 实际数据分析应用通过实际数据分析案例,将R语言和RStudio运用到实际问题中。
根据给定的数据,使用R语言进行数据处理、探索性分析和统计模型建立,并通过可视化工具展示分析结果。
4. 实验总结通过完成本实验,我们了解了RStudio软件和R语言在统计分析中的应用。
掌握了RStudio的基本功能和操作,熟悉了R语言的基本语法和常用函数。
通过实际数据分析案例的应用,提高了数据处理和统计分析能力。
5. 参考资料。
R语言实验报告
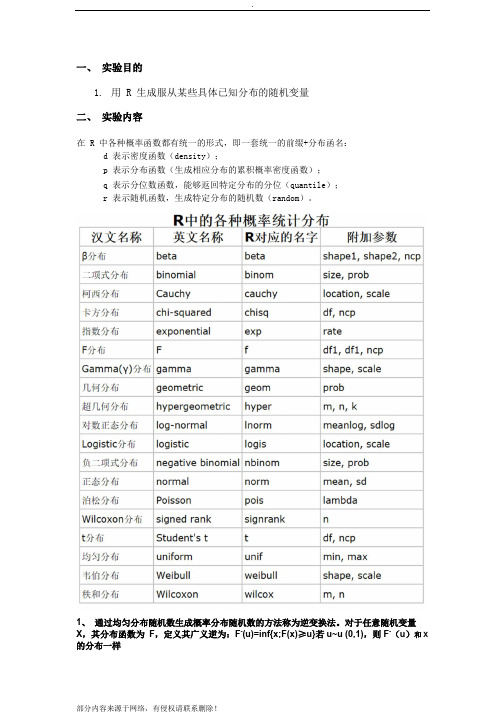
一、实验目的1.用 R 生成服从某些具体已知分布的随机变量二、实验内容在 R 中各种概率函数都有统一的形式,即一套统一的前缀+分布函名:d 表示密度函数(density);p 表示分布函数(生成相应分布的累积概率密度函数);q 表示分位数函数,能够返回特定分布的分位(quantile);r 表示随机函数,生成特定分布的随机数(random)。
1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x)≥u}若u~u (0,1),则F-(u)和X 的分布一样Example 1 如果X~Exp(1)(服从参数为 1 的指数分布),F(x)=1-e-x。
若u=1-e-x并且u~u(0,1),则X=-logU~Exp(1)则可以解出x=-log(1-u)通过随机数生成产生的分布与本身的指数分布结果相一致R 代码如下:nsim = 10^4U = runif(nsim)X = -log(U)Y = rexp(nsim)X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。
r语言编程实验报告总结

r语言编程实验报告总结
本次实验主要是对R语言编程的学习和掌握进行实践操作,通过实验了解R语言的基本语法和数据结构,掌握R语言的编程方法和数据分析技巧。
在实验中,我们学习了R语言的基础知识,如基本数据类型、变量、运算符、数据结构等。
同时,我们也学习了R语言的控制结构,如条件语句、循环语句等,这些控制结构可以帮助我们更好地控制程序的执行。
除此之外,我们还学习了R语言的函数和包的使用,在实验中我们使用了一些常用的包,如ggplot2包和dplyr包,这些包可以帮助我们更加方便地进行数据分析和绘图。
同时,我们也学习了如何自己编写函数,并且熟练掌握了函数的调用和参数传递。
通过实验,我们还学习了如何进行数据处理和数据分析,包括数据的读取和写入、数据的清洗和转换、数据的统计分析和可视化等等。
我们使用R语言对一些真实数据进行了处理和分析,这些数据包括房价、气温、人口等等。
在实验中,我们遇到了一些问题,如代码错误、数据异常等等,但是通过对问题的分析和解决,我们不断提升了自己的编程能力和数据分析技能。
综上所述,通过本次实验,我们深入了解了R语言的编程方法和数据分析技巧,掌握了一些常用的包和函数,并且在实践中熟悉了数据处理和分析的整个过程,这对我们今后的学习和工作都具有重要的
意义。
R语言实验报告.

一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100 名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1 把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n 为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n, mean = 0, sd = 1)其中,n 为产生随机值个数(长度),mean 是平均数,sd 是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中; 计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结这次试验是我第一次接触R语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
R语言实验三

R语⾔实验三实验三数组的运算、求解⽅程(组)和函数极值、数值积分【实验类型】验证性【实验学时】2 学时【实验⽬的】1、掌握向量的四则运算和内积运算、矩阵的⾏列式和逆等相关运算;2、掌握线性和⾮线性⽅程(组)的求解⽅法,函数极值的求解⽅法;3、了解 R 中数值积分的求解⽅法。
【实验内容】1、向量与矩阵的常见运算;2、求解线性和⾮线性⽅程(组);3、求函数的极值,计算函数的积分。
【实验⽅法或步骤】第⼀部分、课件例题:1.向量的运算x<-c(-1,0,2)y<-c(3,8,2)v<-2*x+y+1vx*yx/yy^xexp(x)sqrt(y)x1<-c(100,200); x2<-1:6; x1+x22.x<-1:5y<-2*1:5x%*%ycrossprod(x,y)x%o%ytcrossprod(x,y)outer(x,y)3.矩阵的运算A<-matrix(1:9,nrow=3,byrow=T);AA+1 #A的每个元素都加上1B<-matrix(1:9,nrow=3); BC<-matrix(c(1,2,2,3,3,4,4,6,8),nrow=3); C D<-2*C+A/B; D #对应元素进⾏四则运算x<-1:9A+x #矩阵按列与向量相加E<-A%*%B; E #矩阵的乘法y<-1:3A%*%y #矩阵与向量相乘crossprod(A,B) #A的转置乘以Btcrossprod(A,B) #A乘以B的转置4.矩阵的运算A<-matrix(c(1:8,0),nrow=3);At(A) #转置det(A) #求矩阵⾏列式的值diag(A) #提取对⾓线上的元素A[lower.tri(A)==T]<-0;A #构造A对应的上三⾓矩阵qr.A<-qr(A);qr.A #将矩阵A分解成正交阵Q与上三⾓阵R的乘积,该结果为⼀列表Q<-qr.Q(qr.A);Q;R<-qr.R(qr.A);R #显⽰分解后对应的正交阵Q与上三⾓阵Rdet(Q);det(R);Q%*%R #A=Q*Rqr.X(qr.A) #显⽰分解前的矩阵5.解线性⽅程组A<-matrix(c(1:8,0),nrow=3,byrow=TRUE) b<-c(1,1,1)x<-solve(A,b); x #解线性⽅程组Ax=bB<-solve(A); B #求矩阵A 的逆矩阵BA%*%B #结果为单位阵f<-function(x) x^3-x-1 #建⽴函数uniroot(f,c(1,2)) #输出列表中f.root为近似解处的函数值,iter为迭代次数,estim.prec为精度的估计值uniroot(f,lower=1,upper=2) #与上述结果相同polyroot(c(-1,-1,0,1)) #专门⽤来求多项式的根,其中c(-1,-1,0,1)表⽰对应多项式从零次幂项到⾼次幂项的系数7.求解⾮线性⽅程组(1)⾃编函数: (Newtons.R)Newtons<-function (funs, x, ep=1e-5, it_max=100){index<-0; k<-1while (k<=it_max){ #it_max 表⽰最⼤迭代次数x1 <- x; obj <- funs(x);x <- x - solve(obj$J, obj$f); #Newton 法的迭代公式norm <- sqrt((x-x1) %*% (x-x1))if (norm}; k<-k+1 }obj <- funs(x);list(root=x, it=k, index=index, FunVal= obj$f)} # 输出列表(2)调⽤求解⾮线性⽅程组的⾃编函数funs<-function(x){ f<-c(x[1]^2+x[2]^2-5, (x[1]+1)*x[2]-(3*x[1]+1)) # 定义函数组J<-matrix(c(2*x[1], 2*x[2], x[2]-3, x[1]+1), nrow=2,byrow=T) # 函数组的 Jacobi 矩阵list(f=f, J=J)} # 返回值为列表 : 函数值 f 和 Jacobi 矩阵 Jsource("F:/wenjian_daima/Newtons.R") # 调⽤求解⾮线性⽅程组的⾃编函数Newtons(funs, x=c(0,1))8.⼀元函数极值f<-function(x) x^3-2*x-5 # 定义函数optimize(f,lower=0,upper=2) # 返回值 : 极⼩值点和⽬标函数f<-function(x,a) (x-a)^2 # 定义含有参数的函数optimize(f,interval=c(0,1),a=1/3) # 在函数中输⼊附加参数9.多元函数极值(1)obj <-function (x){ # 定义函数F<-c(10*(x[2]-x[1]^2),1-x[1]) # 视为向量sum (F^2) } # 向量对应分量平⽅后求和nlm(obj,c(-1.2,1))(2)fn<-function(x){ # 定义⽬标函数F<-c(10*(x[2]-x[1]^2), 1-x[1])t(F)%*%F } # 向量的内积gr <- function(x){ # 定义梯度函数F<-c(10*(x[2]-x[1]^2), 1-x[1])J<-matrix(c(-20*x[1],10,-1,0),2,2,byrow=T) #Jacobi 矩阵2*t(J)%*%F } # 梯度optim(c(-1.2,1), fn, gr, method="BFGS")最优点 (par) 、最优函数值 (value)10.梯形求积分公式(1)求积分程序: (trape.R)trape<-function(fun, a, b, tol=1e-6){ # 精度为 10 -6N <- 1; h <- b-a ; T <- h/2 * (fun(a) + fun(b)) # 梯形⾯积 repeat{h <- h/2; x<-a+(2*1:N-1)*h; I <-T/2 + h*sum(fun(x)) if(abs(I-T) < tol) break; N <- 2 * N; T = I }; I}(2)source("F:/wenjian_daima/trape.R") # 调⽤函数f<-function(x) exp(-x^2)trape(f,-1,1)(3)常⽤求积分函数f<-function(x)exp(-x^2) # 定义函数integrate(f,0,1)integrate(f,0,10)integrate(f,0,100)integrate(f,0,10000) # 当积分上限很⼤时,结果出现问题integrate(f,0,Inf) # 积分上限为⽆穷⼤ft<-function(t) exp(-(t/(1-t))^2)/(1-t)^2 # 对上述积分的被积函数 e 2 作变量代换 t=x/(1+x) 后的函数integrate(ft,0,1) # 与上述计算结果相同,且精度较⾼第⼆部分、教材例题:1.随机抽样(1)等可能的不放回的随机抽样:> sample(x, n) 其中x为要抽取的向量, n为样本容量(2)等可能的有放回的随机抽样:> sample(x, n, replace=TRUE)其中选项replace=TRUE表⽰有放回的, 此选项省略或replace=FALSE表⽰抽样是不放回的sample(c("H", "T"), 10, replace=T)sample(1:6, 10, replace=T)(3)不等可能的随机抽样:> sample(x, n, replace=TRUE, prob=y)其中选项prob=y⽤于指定x中元素出现的概率, 向量y与x等长度sample(c("成功", "失败"), 10, replace=T, prob=c(0.9,0.1))sample(c(1,0), 10, replace=T, prob=c(0.9,0.1))2.排列组合与概率的计算1/prod(52:49)1/choose(52,4)3.概率分布qnorm(0.025) #显著性⽔平为5%的正态分布的双侧临界值qnorm(0.975)1 - pchisq(3.84, 1) #计算假设检验的p值2*pt(-2.43, df = 13) #容量为14的双边t检验的p值4.limite.central( )的定义limite.central <- function (r=runif, distpar=c(0,1), m=.5,s=1/sqrt(12),n=c(1,3,10,30), N=1000) {for (i in n) {if (length(distpar)==2){x <- matrix(r(i*N, distpar[1],distpar[2]),nc=i)}else {x <- matrix(r(i*N, distpar), nc=i)}x <- (apply(x, 1, sum) - i*m )/(sqrt(i)*s)hist(x,col="light blue",probability=T,main=paste("n=",i), ylim=c(0,max(.4, density(x)$y))) lines(density(x), col="red", lwd=3)curve(dnorm(x), col="blue", lwd=3, lty=3, add=T)if( N>100 ) {rug(sample(x,100))}else {rug(x)}}}5.直⽅图x=runif(100,min=0,max=1)hist(x)6.⼆项分布B(10,0.1)op <- par(mfrow=c(2,2))limite.central(rbinom,distpar=c(10,0.1),m=1,s=0.9)par(op)7.泊松分布: pios(1)op <- par(mfrow=c(2,2))limite.central(rpois, distpar=1, m=1, s=1, n=c(3, 10, 30 ,50)) par(op)8.均匀分布:unif(0,1)op <- par(mfrow=c(2,2))limite.central( )par(op)9.指数分布:exp(1)op <- par(mfrow=c(2,2))limite.central(rexp, distpar=1, m=1, s=1)par(op)10.混合正态分布的渐近正态性mixn <- function (n, a=-1, b=1){rnorm(n, sample(c(a,b),n,replace=T))}limite.central(r=mixn, distpar=c(-3,3),m=0, s=sqrt(10), n=c(1,2,3,10)) par(op)11.混合正态分布的渐近正态性op <- par(mfrow=c(2,2))mixn <- function (n, a=-1, b=1){rnorm(n, sample(c(a,b),n,replace=T))}limite.central(r=mixn, distpar=c(-3,3),m=0,s=sqrt(10),n=c(1,2,3,10)) par(op)第三部分、课后习题:3.1a=sample(1:100,5)asum(a)3.2(1)抽到10、J、Q、K、A的事件记为A,概率为P(A)=其中在R中计算得:> 1/choose(52,20)[1] 7.936846e-15(2)抽到的是同花顺P(B)=在R中计算得:> (choose(4,1)*choose(9,1))/choose(52,5) [1] 1.385e-05 3.3#(1)x<-rnorm(1000,mean=100,sd=100)hist(x)#(2)y<-sample(x,500)hist(y)#(3)mean(x)mean(y)var(x)var(y)3.4x<-rnorm(1000,mean=0,sd=1) y=cumsum(x)plot(y,type = "l")plot(y,type = "p")3.5x<-rnorm(100,mean=0,sd=1) qnorm(.025)qnorm(.975)t.test(x)由R结果知:理论值为[-1.96,1.96],实际值为:[-0.07929,0.33001]3.6op <- par(mfrow=c(2,2))limite.central(rbeta, distpar=c(0.5 ,0.5),n=c(30,200,500,1000))par(op)3.7N=seq(-4,4,length=1000)f<-function(x){dnorm(x)/sum(dnorm(x))}n=f(N)result=sample(n,replace=T,size = 1000)standdata=rnorm(1000)op<-par(mfrow=c(1,2)) #1⾏2列数组按列(mfcol)或⾏(mfrow)各⾃绘图hist(result,probability = T) lines(density(result),col="red",lwd=3)hist(standdata,probability = T)lines(density(standdata),col="red",lwd=3) par(op)。
r语言实验报告

r语言实验报告R语言实验报告引言R语言是一种广泛应用于数据分析和统计建模的开源编程语言,具有丰富的包和函数库,适用于各种数据处理和可视化任务。
本实验旨在探讨R语言在数据处理和可视化方面的应用,通过实际案例展示其强大的功能和灵活性。
数据导入与处理我们需要导入数据集,并进行初步的处理。
在R语言中,可以使用read.csv()函数导入csv格式的数据文件,然后通过head()函数查看数据的前几行,以了解数据结构和内容。
接下来,可以使用subset()函数筛选出需要的数据列,并使用na.omit()函数删除缺失值,确保数据的完整性和准确性。
数据可视化数据可视化是数据分析的重要环节,可以帮助我们更直观地理解数据的分布和关系。
在R语言中,可以使用ggplot2包来绘制各种类型的图表,如散点图、折线图和直方图等。
通过设置不同的参数和颜色,可以定制化图表的样式,使其更具有美感和可读性。
统计分析除了数据可视化,R语言还提供了丰富的统计分析函数,可以帮助我们进行各种统计推断和建模分析。
例如,可以使用lm()函数进行线性回归分析,通过summary()函数查看回归模型的拟合效果和显著性检验结果。
此外,还可以使用t.test()函数进行假设检验,判断样本均值之间是否存在显著差异。
结果解释与总结我们需要对分析结果进行解释和总结。
在解释结果时,应该清晰地说明分析方法和推断过程,避免歧义和误导。
在总结部分,可以简要概括分析的主要发现和结论,指出数据分析对问题的解决和决策的重要性和价值。
结论通过本实验,我们深入探讨了R语言在数据处理和可视化方面的应用,展示了其强大的功能和灵活性。
R语言不仅可以帮助我们高效地处理和分析数据,还可以帮助我们更好地理解数据的特征和规律。
希望本实验可以帮助读者更好地掌握R语言的应用技巧,提升数据分析和统计建模的能力。
r语言实验报告

r语言实验报告标题:R语言在数据分析中的应用及指导意义导语:R语言作为一种广泛应用于数据分析与统计建模的编程语言,在各个领域中发挥着重要的作用。
本文将对R语言在数据分析中的应用进行探讨,并总结出相关的指导意义,希望能够为数据分析初学者提供一定的参考和帮助。
一、R语言的基础概述R语言是一种开源的编程语言,具备灵活、高效、优雅的特点,被广泛应用于数据科学和统计学领域。
R语言拥有丰富的数据处理、数据可视化和数据分析库,能够满足不同层次的数据分析需求。
二、R语言在数据预处理中的应用1.数据清洗:R语言提供了丰富的数据清洗函数和技术,可以对数据中的缺失值、异常值和重复值进行处理,提高数据的质量。
2.数据转换:R语言能够通过函数和技术,对数据进行转换和重构,实现数据格式的统一和规整,为后续的分析提供基础。
三、R语言在数据分析中的应用1.统计分析:R语言提供了众多的统计分析函数和包,能够进行常见的统计分析,如描述性统计、假设检验、方差分析等。
2.数据建模:R语言拥有强大的建模功能,可以进行线性回归、逻辑回归、决策树、聚类等建模分析,为数据科学家提供了广泛的选择。
3.机器学习:R语言支持各种机器学习算法,如朴素贝叶斯、支持向量机、随机森林等,可以进行模式识别、预测和分类等任务。
四、R语言在数据可视化中的应用1.基础绘图:R语言提供了各类绘图函数,如散点图、柱状图、线图等,能够直观地展示数据的分布和趋势。
2.高级可视化:通过使用R语言的各种包,如ggplot2、plotly 等,可以制作专业、美观的可视化图表,提升数据分析的表达力。
3.交互式可视化:R语言可以与Shiny等工具结合,实现交互式可视化,使用户能够灵活地探索数据,在分析过程中进行实时调整和观察。
五、R语言在数据分析中的指导意义1.灵活性:R语言的灵活性使得分析人员能够根据需求进行自由创造和探索,满足不同场景下的分析需求。
2.社区支持:R语言拥有庞大的社区,用户可以在社区中获取丰富的资源、经验和技术支持,提高分析效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
精心整理实验8假设检验(二)一、实验目的:1.掌握若干重要的非参数检验方法( 2检验——列联表独立性检验,Mcnemar检验——对一个样本两种研究方法是否有差异的检验,符号检验,Wilcoxon 符号秩检验,Wilcoxon秩和检验);2.掌握另外两个相关检验:Spearman秩相关检验,Kendall秩相关检验。
二、实验内容:练习:要求:①完成练习并粘贴运行截图到文档相应位置(截图方法见下),并将所有自己输入文字的字体颜色设为红色(包括后面的思考及小结),②回答思考题,③简要书写实验小结。
④修改本文档名为“本人完整学号姓名1”,其中1表示第1次实验,以后更改为2,3,...。
如文件名为“09张立1”,表示学号为09的张立同学的第1次实验,注意文件名中没有空格及任何其它字符。
最后连同数据文件、源程序文件等(如果有的话,本次实验没有),一起压缩打包发给课代表,压缩包的文件名同上。
截图方法:法1:调整需要截图的窗口至合适的大小,并使该窗口为当前激活窗口(即该窗口在屏幕最前方),按住键盘Alt键(空格键两侧各有一个)不放,再按键盘右上角的截图键(通常印有“印屏幕”或“PrScrn”等字符),即完成截图。
再粘贴到word文档的相应位置即可。
法2:利用QQ输入法的截屏工具。
点击QQ输入法工具条最右边的“扳手”图标,选择其中的“截屏”工具。
)1.自行完成教材第五章的例题。
2.(习题5.11)为研究分娩过程中使用胎儿电子监测仪对剖腹产率有无影响,对5824例分娩的经产妇进行回顾性调查,结果如下表所示,试进行分析。
5824例经产妇回顾性调查结果HHP=9.552e-10<0.05,拒绝原假设,分娩过程中使用胎儿电子监测仪对剖腹产率有影响3.(习题5.12)在高中一年级男生中抽取300名考察其两个属性:B是1500米长跑,C是每天平均锻炼时间,得到4×3列联表,如下表所示。
试对 =0.05,检验B 与C是否独立。
300名高中学生体育锻炼的考察结果H H 4. (习题5.13)为比较两种工艺对产品的质量是否有影响,对其产品进行抽样检查,其结果如下表所示。
试进行分析。
两种工艺下产品质量的抽查结果解:提出假设:H0:两种工艺对产品的质量没影响H1:两种工艺对产品的质量有影响源代码及运行结果:(复制到此处,不需要截图)P=0.6372>0.05,接受原假设,两种工艺对产品的质量没影响5.(习题5.14)应用核素法和对比法检测147例冠心病患者心脏收缩运动的符合情况,其结果如下表所示。
试分析这两种方法测定结果是否相同。
两法检查室壁收缩运动的符合情况解:提出假设:H0:这两种方法测定结果不相同H6.,现对13.3213.0614.0211.8613.5813.7713.5114.4214.4415.43将它们作为一个样本进行检验。
试分析,该鱼塘中鱼的长度是在中位数之上,还是在中位数之下。
(1)用符号检验分析;(2)用Wilcoxon符号秩检验分析。
解:(1)用符号检验分析提出假设:H0:M>=14.6H1:M<14.6提出假设:H0:M>=14.6H1:M<14.6源代码及运行结果:(复制到此处,不需要截图)x<-c(13.32,13.06,14.02,11.86,13.58,13.77,13.51,14.42,14.44,15.43)>wilcox.test(x,mu=14.6,al="l",exact=F)Wilcoxonsignedranktestwithcontinuitycorrectiondata:xV=4.5,p-value=0.01087alternativehypothesis:truelocationislessthan14.67.20t(5)分析各种的检验方法,试说明哪种检验法效果最好。
解:(1)符号检验法提出假设:H0:两测定无显着差异H1:两测定有显着差异源代码及运行结果:(复制到此处,不需要截图)>x<-c(48.0,33.0,37.5,48.0,42.5,40.0,42.0,36.0,11.3,22.0,36.0,27.3,14.2,32.1,52.0,38.0, 17.3,20.0,21.0,46.1)>y<-c(37.0,41.0,23.4,17.0,31.5,40.0,31.0,36.0,5.7,11.5,21.0,6.1,26.5,21.3,44.5,28.0,22(2)Wilcoxon符号秩检验法提出假设:H0:两测定无显着差异H1:两测定有显着差异源代码及运行结果:(复制到此处,不需要截图)>x<-c(48.0,33.0,37.5,48.0,42.5,40.0,42.0,36.0,11.3,22.0,36.0,27.3,14.2,32.1,52.0,38.0, 17.3,20.0,21.0,46.1)>y<-c(37.0,41.0,23.4,17.0,31.5,40.0,31.0,36.0,5.7,11.5,21.0,6.1,26.5,21.3,44.5,28.0,22 .6,20.0,11.0,22.3)>wilcox.test(x,y,paired=T,exact=F)HH>y<-c(37.0,41.0,23.4,17.0,31.5,40.0,31.0,36.0,5.7,11.5,21.0,6.1,26.5,21.3,44.5,28.0,22 .6,20.0,11.0,22.3)>wilcox.test(x,y,exact=F)Wilcoxonranksumtestwithcontinuitycorrectiondata:xandyW=274.5,p-value=0.04524alternativehypothesis:truelocationshiftisnotequalto0结论:P=0.04524<0.05,拒绝原假设,两测定有显着差异(4)两独立样本t检验,要求判断独立性、正态性和方差齐性HHalternativehypothesis:two-sidedWarningmessage:Inks.test(x,pnorm,mean(x),sd(x)):Kolmogorov-Smirnov检验里不应该有连结>ks.test(y,pnorm,mean(y),sd(y))One-sampleKolmogorov-Smirnovtestdata:yD=0.10142,p-value=0.973 alternativehypothesis:two-sided结论:HHF=1.1406,numdf=19,denomdf=19,p-value=0.7772 alternativehypothesis:trueratioofvariancesisnotequalto1 95percentconfidenceinterval:0.45147882.8817689sampleestimates:ratioofvariances1.140639结论:P=0.7772>0.05,接受原假设,两组数据方差相同③能否作t检验?如果能,请按照前面各题的格式、内容写出作t检验的过程HHalternativehypothesis:truedifferenceinmeansisnotequalto095percentconfidenceinterval:0.812552915.8774471sampleestimates:meanofxmeanofy33.21524.870结论:P=0.03082<0.05,拒绝原假设,两测定有显着差异(5)分析各种的检验方法,试说明哪种检验法效果最好。
结论:8.HH>x<-c(24,17,20,41,52,23,46,18,15,29)>y<-c(8,1,4,7,9,5,10,3,2,6)>cor.test(x,y,method="spearman",exact=F)Spearman'srankcorrelationrhodata:xandyS=10,p-value=5.484e-05alternativehypothesis:truerhoisnotequalto0sampleestimates:rho0.93939390.8222222结论:P=0.000935<0.05,拒绝原假设,学习等级与学习成绩有关系9.(习题5.18)为比较一种新疗法对某种疾病的治疗效果,将40名患者随机地分为两组,每组20人,一组采用新疗法,另一组用原标准疗法。
经过一段时间的治疗后,对每个患者的疗效作仔细的评估,并划分为差、较差、一般、较好和好5个等级。
两组处于不同等级的患者人数下表所示。
试分析,由此结果能否认为新方法的疗效显着地优于原疗法。
(?=0.05)不同方法治疗后的结果HHP=0.05509>0.05,接受原假设,即认为新方法的疗效不显着地优于原疗法思考:1.?2检验针对的哪一类型的数据?A.连续型变量;B.无序分类变量;C.有序分类变量B.无序分类变量2.符号检验、Wilcoxon符号秩检验和Wilcoxon秩和检验针对的哪一类型的数据?A.连续型变量;B.无序分类变量;C.有序分类变量C.有序分类变量3.顺序统计量与秩统计量是一样的吗?在R语言中分别利用什么函数可以求因为符号检验利用了观测值跟原假设的中心位置之差的符号来进行检验,但是它只计算符号的个数,而不考虑每个符号差中所包含的绝对值的大小,而符号秩检验还利用了绝对值的大小,考虑了绝对值距中心位置的远近,自然比仅仅利用符号更有效。
6.符号检验和Wilcoxon符号秩检验都可以用于单个样本的检验,来判断一个样本是否来自某个总体;也可以用于两配对(成对)样本的检验,来判断两个相关总体是否存在显着性差异。
Wilcoxon秩和检验主要是用于哪类问题的检验?两个配对样本的检验、两个独立样本的检验。
7.参数检验中的均值检验,两配对样本t检验可以转化为单样本t检验,即检验_正三、。