R语言实验报告
大数定律和中心极限定理的r语言实验报告

大数定律和中心极限定理是概率论中的两个重要概念。
大数定律描述了在独立重复试验中,当试验次数趋于无穷时,某一事件发生的频率趋于其概率。
中心极限定理则指出,无论试验中的个体之间的差异有多大,当试验次数足够多时,试验结果的平均值将接近正态分布。
以下是一个简单的R语言实验报告,用于演示大数定律和中心极限定理。
大数定律和中心极限定理的R语言实验
实验目的:通过模拟实验,观察大数定律和中心极限定理的现象。
实验原理:
1.大数定律:在大量独立重复试验中,某一事件的相对频率趋近于该事件的概率。
2.中心极限定理:无论个体之间的差异有多大,当试验次数足够多时,试验结果的平均值将接近正态分布。
实验步骤:
1.生成1000个0到1之间的随机数,模拟1000次掷硬币试验(正面概率为0.5)。
2.计算正面朝上的频率。
3.使用R语言绘制频率直方图和正态分布曲线。
4.重复步骤1-3多次(例如100次),观察频率的稳定性。
5.计算100次试验中每次试验得分的平均值的频数分布,并绘制直方图和正态分布曲线。
实验结果:
1.正面朝上的频率逐渐稳定于0.5。
2.频率直方图接近正态分布。
3.平均值的频数分布也接近正态分布。
实验分析:
实验结果验证了大数定律和中心极限定理。
在大量独立重复试验中,正面朝上的频率趋近于0.5,符合大数定律。
同时,试验结果的平均值分布接近正态分布,符合中心极限定理。
结论:通过R语言模拟实验,我们观察到了大数定律和中心极限定理的现象,加深了对这两个定理的理解。
RStudioR语言与统计分析实验报告

RStudioR语言与统计分析实验报告1. 实验目的本实验旨在介绍RStudio软件和R语言在统计分析中的应用。
通过本实验,可以了解RStudio的基本功能和操作,掌握R语言的基本语法和常用函数,并在实际数据分析中应用所学知识。
2. 实验环境与工具本实验使用RStudio软件进行实验操作。
RStudio是一个集成开发环境(IDE),专门用于R语言编程和统计分析。
它提供了代码编辑器、调试器、数据可视化工具等一系列功能,便于用户进行数据处理和分析。
3. 实验步骤本实验分为以下几个步骤:3.1 安装R和RStudio在开始实验之前,需要先安装R语言和RStudio软件。
R语言是一种统计分析和数据挖掘的编程语言,而RStudio是R语言的集成开发环境。
3.2 RStudio界面介绍在打开RStudio后,可以看到主要分为四个区域:代码编辑器、控制台、环境和帮助。
代码编辑器用于编写R语言代码,控制台用于执行和查看代码运行结果,环境用于查看和管理数据对象,帮助用于查阅R语言文档和函数说明。
3.3 R语言基础研究R语言的基本语法和常用函数是使用RStudio进行统计分析的基础。
实验中将介绍R语言的数据类型、赋值操作、条件语句、循环语句等基本概念,并演示常用函数的使用方法。
3.4 实际数据分析应用通过实际数据分析案例,将R语言和RStudio运用到实际问题中。
根据给定的数据,使用R语言进行数据处理、探索性分析和统计模型建立,并通过可视化工具展示分析结果。
4. 实验总结通过完成本实验,我们了解了RStudio软件和R语言在统计分析中的应用。
掌握了RStudio的基本功能和操作,熟悉了R语言的基本语法和常用函数。
通过实际数据分析案例的应用,提高了数据处理和统计分析能力。
5. 参考资料。
R语言实验报告
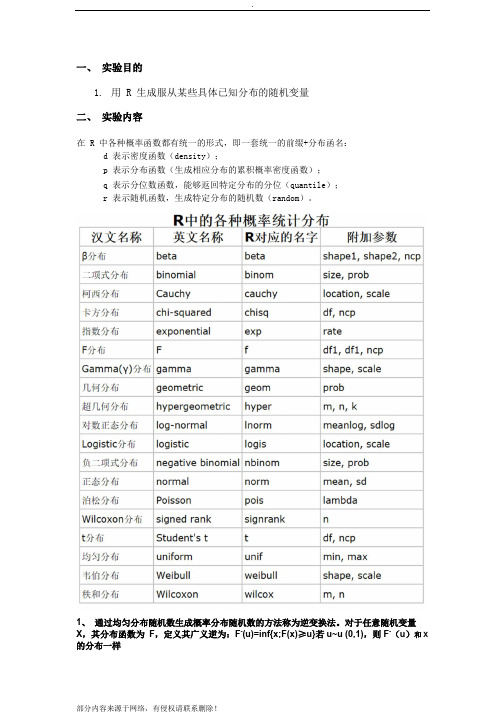
一、实验目的1.用 R 生成服从某些具体已知分布的随机变量二、实验内容在 R 中各种概率函数都有统一的形式,即一套统一的前缀+分布函名:d 表示密度函数(density);p 表示分布函数(生成相应分布的累积概率密度函数);q 表示分位数函数,能够返回特定分布的分位(quantile);r 表示随机函数,生成特定分布的随机数(random)。
1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x)≥u}若u~u (0,1),则F-(u)和X 的分布一样Example 1 如果X~Exp(1)(服从参数为 1 的指数分布),F(x)=1-e-x。
若u=1-e-x并且u~u(0,1),则X=-logU~Exp(1)则可以解出x=-log(1-u)通过随机数生成产生的分布与本身的指数分布结果相一致R 代码如下:nsim = 10^4U = runif(nsim)X = -log(U)Y = rexp(nsim)X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。
报告R语言实验五..docx

实验五常见分布的相关计算、随机抽样与模拟【实验类型】验证性【实验学时】2 学时【实验目的】1、掌握常见分布的分布函数、密度函数(或分布列)及分位数的计算方法;2、掌握样本统计量的计算方法及所表达的意义;3、了解随机模拟的基本思想及其应用。
【实验内容】1、组合数与组合方案的生成、概率的计算,2、常见分布的分布函数、密度函数(或分布列)以及分位数的计算;3、随机数的生成与随机模拟(蒙特卡洛仿真) 。
【实验方法或步骤】第一部分、课件例题:1.#从1~5 个数中,随机取3个的全部组合combn(1:5,3) # 共10 种组合方案combn(1:5,3,FUN=mean) # 对每种组合方案求均值choose(5,3) # 从5 个数里面选3个的组合数目choose(50,3)factorial(10) # 计算10!3.#3. 从一副完全打乱的52张扑克中任取 4 张,计算下列事件的概率#(1) 抽取 4 张依次为红心A,方块A,黑桃A和梅花A的概率1/prod(49:52) #prod() 表示连乘积#(2) 抽取 4 张为红心A,方块A,黑桃A和梅花A的概率.1/choose(52,4)4.设在15 只同类型的零件中有2只是次品,一次任取3只,以X表示次品的只数,求X的分布律.x<-c(1,1,rep(0,13));x # 样本空间( 用1 表示次品, 0 为正品) X<-combn(x,3,FUN=sum) #从样本空间中任取 3 个元素的方案,并对每个方案求和,共455 个数(取值0,1,2 )p<-numeric(3) # 定义p 为数值型的 3 维向量,且初值为0for (i in 1:3)p[i]<-sum(X==i-1)/length(X) #sum(X==i-1) 表示对X 取值为i-1 的个数求和,X 的长度为455# 例5.3 :计算3σ 原则对应的概率x <- 1:3; p <- pnorm(x) - pnorm(-x); p# 例5.4 :令α=0.025 ,计算上α 分位点z α alpha <- 0.025; z <- qnorm(1-alpha); z6.#例5.5 :计算P{X≤160} ,其中X~U[150,200] 。
r语言编程实验报告总结

r语言编程实验报告总结
本次实验主要是对R语言编程的学习和掌握进行实践操作,通过实验了解R语言的基本语法和数据结构,掌握R语言的编程方法和数据分析技巧。
在实验中,我们学习了R语言的基础知识,如基本数据类型、变量、运算符、数据结构等。
同时,我们也学习了R语言的控制结构,如条件语句、循环语句等,这些控制结构可以帮助我们更好地控制程序的执行。
除此之外,我们还学习了R语言的函数和包的使用,在实验中我们使用了一些常用的包,如ggplot2包和dplyr包,这些包可以帮助我们更加方便地进行数据分析和绘图。
同时,我们也学习了如何自己编写函数,并且熟练掌握了函数的调用和参数传递。
通过实验,我们还学习了如何进行数据处理和数据分析,包括数据的读取和写入、数据的清洗和转换、数据的统计分析和可视化等等。
我们使用R语言对一些真实数据进行了处理和分析,这些数据包括房价、气温、人口等等。
在实验中,我们遇到了一些问题,如代码错误、数据异常等等,但是通过对问题的分析和解决,我们不断提升了自己的编程能力和数据分析技能。
综上所述,通过本次实验,我们深入了解了R语言的编程方法和数据分析技巧,掌握了一些常用的包和函数,并且在实践中熟悉了数据处理和分析的整个过程,这对我们今后的学习和工作都具有重要的
意义。
报告R语言实验五..docx

实验五常见分布的相关计算、随机抽样与模拟【实验类型】验证性【实验学时】2 学时【实验目的】1、掌握常见分布的分布函数、密度函数(或分布列)及分位数的计算方法;2、掌握样本统计量的计算方法及所表达的意义;3、了解随机模拟的基本思想及其应用。
【实验内容】1、组合数与组合方案的生成、概率的计算,2、常见分布的分布函数、密度函数(或分布列)以及分位数的计算;3、随机数的生成与随机模拟(蒙特卡洛仿真)。
【实验方法或步骤】第一部分、课件例题:1.#从1~5个数中,随机取3个的全部组合combn(1:5,3) #共10种组合方案combn(1:5,3,FUN=mean) #对每种组合方案求均值2.choose(5,3) #从5个数里面选3个的组合数目choose(50,3)factorial(10) #计算10!3.#3.从一副完全打乱的52张扑克中任取4张,计算下列事件的概率#(1)抽取4张依次为红心A,方块A,黑桃A和梅花A的概率1/prod(49:52) #prod()表示连乘积#(2)抽取4张为红心A,方块A,黑桃A和梅花A的概率.1/choose(52,4)4.设在15只同类型的零件中有2只是次品,一次任取3只,以X表示次品的只数,求X的分布律.x<-c(1,1,rep(0,13));x #样本空间(用1表示次品, 0为正品)X<-combn(x,3,FUN=sum) #从样本空间中任取3个元素的方案,并对每个方案求和,共455个数(取值0,1,2)p<-numeric(3) #定义p为数值型的3维向量,且初值为0for (i in 1:3)p[i]<-sum(X==i-1)/length(X) #sum(X==i-1)表示对X取值为i-1的个数求和,X的长度为455p5.# 例5.3 :计算3σ原则对应的概率x <- 1:3; p <- pnorm(x) - pnorm(-x); p# 例5.4 :令α=0.025,计算上α分位点z α .alpha <- 0.025; z <- qnorm(1-alpha); z6.#例5.5 :计算P{X≤160},其中X~U[150,200]。
R语言实验报告.

一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100 名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1 把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n 为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n, mean = 0, sd = 1)其中,n 为产生随机值个数(长度),mean 是平均数,sd 是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中; 计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结这次试验是我第一次接触R语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。