Semantic-head based resolution of scopal ambiguities
Semantic features

Perception Features refer to something such as comments, opinions, ideas from speakers to listeners in the aspect involving in subjective, individual and connotative feeling, etc.
Semantic Feature
In a word, a word has its own features that can make it distinguished from others that can be seen to have necessary comparison with it. When studying the meanings of words and analyzing the semantic features, we can know clearly about the similarities ,resemblances they share and differences that make them different.
Semantic Componential Analysis
Semantic componential analysis is useful in helping us to distinguish the meaning of words and have a better mastery of meaning and usages of the words. Generally, in lexical semantic componential analysis , we use “[ ]” to stand for the semantic feature that a language unit has; “+” to represent the feature that a language unit has; “-” to account for the feature that a language unit does not have.
英语语言文学专业硕士研究生培养方案.doc
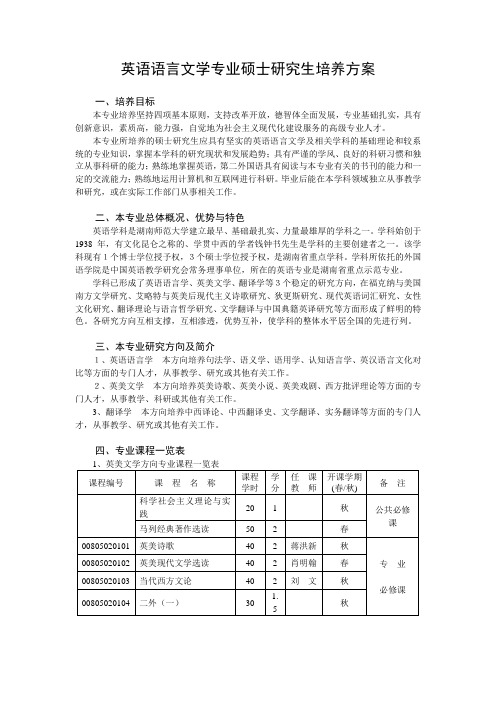
英语语言文学专业硕士研究生培养方案一、培养目标本专业培养坚持四项基本原则,支持改革开放,德智体全面发展,专业基础扎实,具有创新意识,素质高,能力强,自觉地为社会主义现代化建设服务的高级专业人才。
本专业所培养的硕士研究生应具有坚实的英语语言文学及相关学科的基础理论和较系统的专业知识,掌握本学科的研究现状和发展趋势;具有严谨的学风、良好的科研习惯和独立从事科研的能力;熟练地掌握英语,第二外国语具有阅读与本专业有关的书刊的能力和一定的交流能力;熟练地运用计算机和互联网进行科研。
毕业后能在本学科领域独立从事教学和研究,或在实际工作部门从事相关工作。
二、本专业总体概况、优势与特色英语学科是湖南师范大学建立最早、基础最扎实、力量最雄厚的学科之一。
学科始创于1938年,有文化昆仑之称的、学贯中西的学者钱钟书先生是学科的主要创建者之一。
该学科现有1个博士学位授予权,3个硕士学位授予权,是湖南省重点学科。
学科所依托的外国语学院是中国英语教学研究会常务理事单位,所在的英语专业是湖南省重点示范专业。
学科已形成了英语语言学、英美文学、翻译学等3个稳定的研究方向,在福克纳与美国南方文学研究、艾略特与英美后现代主义诗歌研究、狄更斯研究、现代英语词汇研究、女性文化研究、翻译理论与语言哲学研究、文学翻译与中国典籍英译研究等方面形成了鲜明的特色。
各研究方向互相支撑,互相渗透,优势互补,使学科的整体水平居全国的先进行列。
三、本专业研究方向及简介1、英语语言学本方向培养句法学、语义学、语用学、认知语言学、英汉语言文化对比等方面的专门人才,从事教学、研究或其他有关工作。
2、英美文学本方向培养英美诗歌、英美小说、英美戏剧、西方批评理论等方面的专门人才,从事教学、科研或其他有关工作。
3、翻译学本方向培养中西译论、中西翻译史、文学翻译、实务翻译等方面的专门人才,从事教学、研究或其他有关工作。
四、专业课程一览表五、各专业课程开设具体要求课程编号:00805020101课程名称:英美诗歌英文名称:English Poetry任课教师:蒋洪新适用学科、方向:英语语言文学专业的英美文学、翻译学方向,世界文学和比较文学专业预修课程:英美文学选读、英美文学史课程内容:本课程从英语诗歌的欣赏知识入手,继而对英美诗歌和诗论进行较为系统导读。
生物信息数据库

NCBI:
二、重要生物信息数据库
生物信息学数据的表示形式
生物信息学数据的表示形式
平面文件 (flat-file)
– 信息在文件中顺序存放且具有特定格式 – 记录(Entry)通过“获得号”(accession #)
唯一确定 – 同一文件间和不同文件间信息的联系均
通过ac认为这些蛋白质具有 相同的折叠方式。在这些情况下,结构的相似性主要依 赖于二级结构单元的排列方式或拓扑结构。
蛋白质结构分类数据库CATH
类型Class、构架Architecture 、拓扑结构Topology和 同源性Homology 。
分类基础是蛋白质结构域。与SCOP不同的是,CATH 把蛋白质分为4类,即a主类、b主类,a-b类(a/b型 和a+b型)和低二级结构类。低二级结构类是指二级 结构成分含量很低的蛋白质分子。
描述了结构和进化关系。 SCOP数据库从不同层次对蛋白质结构进行分类,以反
映它们结构和进化的相关性。 第一个分类层次为家族,通常将序列相似性程度在30%
以上的蛋白质归入同一家族,有比较明确的进化关系。 超家族:序列相似性较低,结构和功能特性表明它们有
共同的进化起源,将其视作超家族。 折叠类型:无论有无共同的进化起源,只要二级结构单
EMBL格式: 欧洲分子生物学EMBL数据库的每个条目是一份纯文 本文件,每一行最前面是由两个大写字母组成的识别 标志,常见的识别标志列举在后面的表中。识别标志 “特性表”FT包含一批关键字,它们的定义已经与 GenBank和DDBJ统一。下欧洲国家的许多数据库如 SWISS-PROT、ENZYME、TRANSFAC等,都采用 与EMBL一致的格式。
1)头部包含关于整个序列的信息(描述字符),从 LOCUS行到 ORIGIN行;
farthest point sampling 参考文献

farthest point sampling参考文献"Farthest Point Sampling"(FPS,最远点采样)是一种在点云或数据集中选择最具代表性点的方法,常用于计算机图形学、计算机视觉和机器学习等领域。
以下是一些可能有关Farthest Point Sampling的参考文献,注意这里列举的文献可能在我最后训练数据的时候已存在,但实际的发展可能还有更新:1.Title:"A Multi-Scale Point Cloud Descriptor Based on Farthest Point Sampling"-Authors:Chuyuan Men,Yifei Huang,Hao Su,Leonidas J.Guibas-Published in:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017.2.Title:"Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs"-Authors:Charles R.Qi,Wei Liu,Chenxia Wu,Hao Su,Leonidas J.Guibas-Published in:arXiv preprint arXiv:1711.09869,2017.3.Title:"PointNet:Deep Learning on Point Sets for3D Classification and Segmentation"-Authors:Charles R.Qi,Hao Su,Kaichun Mo,Leonidas J.Guibas-Published in:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017.请注意,要获取这些文献,你可能需要通过学术搜索引擎、图书馆数据库或相关领域的学术出版物检索工具进行查找。
利用稀疏表示方法对图像进行去雾超分辨

摘要摘要随着科技的不断进步,人们进入了信息时代。
数字图像作为一种信息传播的重要形式,其分辨率的高低以及一些浑浊的介质会影响人们获取图像中的信息。
在现实世界中,有非常多的因素会影响图像的分辨率,如快门、散弹噪声、抖动、衍射极限、传感器、聚焦、颜色混叠等。
在物体成像中也存在着很多浑浊的介质,如水滴、颗粒、烟雾等。
这些因素和介质都会导致图像的分辨率降低,以及图像中的部分信息丢失,因此,提高图像的分辨率和去除图像中的雾就显得尤为重要。
当成像设备与成像环境均不够完善时,采用数学算法提高图像质量,即利用稀疏表示方法对图像进行去雾超分辨,这样做的优点是既不受硬件设备和环境条件的限制,还能使成本降低,具有广阔的应用前景。
稀疏表示理论在图像处理方面的应用备受关注,如图像去噪、人脸识别、图像超分辨率重建等。
通过训练字典可以将图像补丁稀疏表示,再用最少的原子代表图像补丁,准确获取图像的纹理特征信息。
本文的创新点在于利用稀疏表示方法对图像进行超分辨的同时又加入了对图像去雾的研究,得出的图片效果要好于单独去雾和单独超分辨的图像。
本文主要研究内容如下:1.利用超完备字典中适当选择的元素稀疏线性组合表示图像补丁。
由此为每个输入的低分辨率补丁都找到相对应的稀疏系数,通过该系数得出高分辨率输出。
2.高、低分辨率图像补丁的联合训练,可以加强高、低分辨率图像补丁对间稀疏表示的相似性。
因此,低分辨率图像补丁的稀疏表示能够与高分辨率图像补丁字典一起应用,生成高分辨率的图像补丁。
3.在利用稀疏表示方法对图像进行超分辨率重建的过程中,其求解是一个不适定问题,为了进一步提高图像的重建质量,在重建过程中引入了正则化约束。
4.在广泛了解现有的图像去雾的方法后,决定将暗通道先验模型这种去雾算法和稀疏表示的图像去雾算法相结合。
此方法使用暗通道先验模型来去掉图像中的雾,使用稀疏表示方法去掉图像中的细节噪声,提高图像分辨率。
相对以往的暗通道先验模型来说,此方法的去雾霾效果稍好一些,保真度也稍好一些。
semantic leaps

09级7班李梦琦2009237Semantic Leaps: Frame-shifting and Conceptual Blending inMeaning ConstructionSemantic leaps is written by Seana Coulson and published by Cambridge University Press in 2001. This book explores how people combine knowledge from different domains to understand and express new ideas. Concentrating on dynamic aspects of on-line meaning construction, Coulson identifies two related sets of processes: frame-shifting and conceptual blending. Frame-shifting is semantic reanalysis in which existing elements in the contextual representation are reorganized into a new frame. Conceptual blending is a set of cognitive operations for combining partial cognitive models. By addressing linguistic phenomenon often ignored in traditional meaning research, Coulson explains how processes of cross-domain mapping, frame-shifting, and conceptual blending enhance the explanatory adequacy of traditional frame-based systems for natural language processing. The focus is on how the constructive processes speakers use to assemble, link, and adapt simple cognitive models underlie a broad range of productive language behavior.This book is divided into 10 chapters. Chapter 1 talks about semantic leaps, i.e. productive language behavior, background and connections. Chapter 2 discusses frame-shifting and models of language processing. The author discusses approaches to comprehension, i.e. composition, semantic indeterminacy, sense, etc. Chapter 3 is about models of sentential integration, such as frame-shifting in text processing, in sentential integration and frame-based models. Chapter 4 relates frame-shifting to thebrain. It seems that successful frame-shifting is more difficult than the mere integration of an unexpected word congruent with the contextually evoked frame. Results suggest that frame-based retrieval of background knowledge plays an important role in general processes of sentential integration. However, results argue against the idea that there is a special role for the right hemisphere in frame-shifting. Frame-shifting in jokes appears to differ only quantitatively from other sorts of sentential integration.Part Ⅱis about conceptual blending. Chapter 5 is about conceptual blending in modified noun phrases. The author cites several examples, such as nominal compounds, predicating and non-predicating adjectives, privative adjectives, etc. The author concludes that an important assumption of compositional approaches is that categories have necessary and sufficient conditions that can be combined with algorithmic operations. However, since categories are not normally defined by necessary and sufficient conditions, there is no reason to believe that complex categories result from the combination of such conditions. The author poses analyzability and compositionality, and suggests that the same processes of conceptual integration that underlie meaning construction in noun phrases also operate for statements of analogy, metaphors, and identity in counterfactual utterances. Chapter 6 discusses conceptual blending in metaphor and analogy. What’s projected in metaphor is not static information in long-term memory, but dynamically constructed entities in working memory. Conceptual blending theory allows us to drop the old idea of concept as static information in long-term memory in favor ofdynamically constructed models constrained both by information in long-term memory and by local, contextual cues. Chapter 7 talks about counterfactual conditionals. Blending theory suggests people use simplified, partial models, and use rhetorical goals to restrict their inferences. The flexibility of meaning construction is such that the spaces we link can be as close as a match before and after being lit.Part Ⅲis the application of blending, framing and blaming. Chapter 8 is about framing in discourse. It talks about cultural models of action, responsibility and punishment. Chapter 9 is about frame-shifting and scalar implicature. By employing diverse rhetorical strategies, speakers adapt cultural models to suit a variety of ideological outlooks and argumentative needs. Cultural models, pragmatic scale and rhetorical strategies are all tools we use to construct and reconstruct a cultural understanding of the world we both inhabit and create. Chapter 10 gives the space structuring model.The theory of frame shifting has been applied to many language phenomena, such as jokes, etc. Frame shifting is the result o f the new development of Frame semantics. The conceptual blending theory is the new development of mental space theory on the basis of conceptual metaphor theory. Both of them are of the dynamic study of language. They try to solve the problem o f on-line meaning construction. Frame shifting proposes that the new frame is reconstructed by absorbing the structure of the old frame in order to construct meaning. Conceptual blending theory focuses on the mapping between mental spaces and the construction of the new blend space. They are part o f the meaning construction theory. Although they are different, theyare also related to each other closely.Coulson believes that the semantic and pragmatic reanalysis that reorganizes existing elements in the message-level representation is known as frame-shifting, and frame-shifting is retrieving a new frame from long-term memory to reinterpret information in working memory. It is widely applied in the research related to humor, and it is also integrated with conceptual blending theory to explain various kinds of language phenomena. As a meta-theoretical metaphor, frame-shifting is potentially less constraining than the metaphors of “conceptual space”and “blending”, and avoids the multiplication of “spaces”implied by entailments of the “space”and “blending metaphors”. Frame-shifting supports conceptual links to humor, metonymy, and other forms of figurative language, and affords a ready path for connecting the cognitive and neural levels of language to the social and cultural levels.Frame-shifting provides many language phenomena with theoretical support. It is usually compared with the conceptual blending theory, and is often integrated with it to explain and describe language phenomena. It is complementary with conceptual blending theory, which makes it more persuasive.。
基于GLNet和HRNet的高分辨率遥感影像语义分割
基于GLNet和HRNet的高分辨率遥感影像语义分割赵紫旋1,2,吴谨1,2,朱磊1,3(1. 武汉科技大学信息科学与工程学院,湖北武汉 430081;2. 冶金自动化与检测技术教育部工程中心,湖北武汉 430000;3. 中冶南方连铸技术工程有限责任公司,湖北武汉 430223)摘要:在GLNet(Global-Local Network)中,全局分支采用ResNet(Residual Network)作为主干网络,其侧边输出的特征图分辨率较低,而且表征能力不足,局部分支融合全局分支中未充分学习的特征图,造成分割准确率欠佳。
针对上述问题,提出了一种基于GLNet和HRNet(High-Resolution Network)的改进网络用于高分辨率遥感影像语义分割。
首先,利用HRNet取代全局分支中原有的ResNet主干,获取表征能力更强,分辨率更高的特征图。
然后,采用多级损失函数对网络进行优化,使输出结果与人工标记更为相似。
最后,独立训练局部分支,以消除全局分支中特征图所带来的混淆。
在高分辨率遥感影像数据集上,对所提出的改进网络进行训练和测试,实验结果表明,改进网络在全局分支和局部分支上的平均绝对误差(Mean Absolute Error,MAE)分别为0.0630和0.0479,在分割准确率和平均绝对误差方面均优于GLNet。
关键词:高分辨率遥感影像;语义分割;全局分支;局部分支;独立训练中图分类号:TP751.1 文献标识码:A 文章编号:1001-8891(2021)05-0437-06High-resolution Remote Sensing Image Semantic SegmentationBased on GLNet and HRNetZHAO Zixuan1,2,WU Jin1,2,ZHU Lei1,3(1. School of Information and Engineering, Wuhan University of Science and Technology, Wuhan 430081, China;2. Engineering Research Center of Metallurgical Automation and Measurement Technology, Ministry of Education, Wuhan 430000, China;3. WISDRI CCTEC Engineering Co. Ltd, Wuhan 430223, China)Abstract: The backbone of a convolutional neural network global branch, a residual network (ResNet), obtains low-resolution feature maps at side outputs that lack feature representation. The local branch aggregates the feature maps in the global branch, which are not fully learned, resulting in a negative impact on image segmentation. To solve these problems in GLNet (Global-Local Network), a new semantic segmentation network based on GLNet and High-Resolution Network (HRNet) is proposed. First, we replaced the original backbone of the global branch with HRNet to obtain high-level feature maps with stronger representation. Second, the loss calculation method was modified using a multi-loss function, causing the outputs of the global branch to become more similar to the ground truth. Finally, the local branch was trained independently to eliminate the confusion produced by the global branch. The improved network was trained and tested on the remote sensing image dataset. The results show that the mean absolute errors of the global and local branches are 0.0630 and 0.0479, respectively, and the improved network outperforms GLNet in terms of segmentation accuracy and mean absolute errors.Key words: high-resolution remote sensing image, semantic segmentation, global branch, local branch, trained independently0 引言图像的语义分割将属于相同目标类别的图像子区域聚合起来,是高分辨率遥感影像信息提取和场景理解的基础,也是实现从数据到信息对象化提取的关键步骤,具有重要的意义。
英语语言学测试题及答案
英语语言学测试题及答案一、选择题(每题2分,共20分)1. The term "phoneme" refers to:A. A single soundB. A unit of soundC. A letter of the alphabetD. A combination of sounds答案:B2. The study of language change over time is known as:A. PhoneticsB. PhonologyC. Historical LinguisticsD. Syntax答案:C3. Which of the following is a branch of linguistics that deals with the meaning of words?A. SemanticsB. PragmaticsC. MorphologyD. Syntax答案:A4. The smallest unit of meaning in a language is called:A. A wordB. A morphemeC. A syllableD. A phoneme答案:B5. The process of forming words by combining smaller units is known as:A. SyntaxB. MorphologyC. SemanticsD. Phonology答案:B6. The study of the rules governing the structure of sentences is called:A. SyntaxB. SemanticsC. PragmaticsD. Morphology答案:A7. The branch of linguistics that deals with the social context in which language is used is:A. SociolinguisticsB. PsycholinguisticsC. NeurolinguisticsD. Computational Linguistics答案:A8. The study of how language is processed in the brain is known as:A. PsycholinguisticsB. NeurolinguisticsC. SociolinguisticsD. Computational Linguistics答案:B9. The process of acquiring a first language is called:A. Second language acquisitionB. Foreign language learningC. Language learningD. First language acquisition答案:D10. The concept that language is arbitrary means that:A. It is randomB. It is meaninglessC. There is no necessary connection between the form of a word and its meaningD. It is always logical答案:C二、填空题(每题2分,共20分)1. The study of speech sounds is called ____________.答案:Phonetics2. The branch of linguistics that examines how language is used in social contexts is ____________.答案:Sociolinguistics3. The smallest meaningful unit of language is known as the ____________.答案:Morpheme4. The process of combining morphemes to form words is known as ____________.答案:Morphology5. The study of the way language is structured and organized is called ____________.答案:Linguistics6. The branch of linguistics that deals with the rules governing the formation of words is ____________.答案:Morphology7. The study of the way meaning is conveyed in language is known as ____________.答案:Semantics8. The branch of linguistics that deals with the rules governing the formation of sentences is ____________.答案:Syntax9. The study of the way language is used in everyday life is called ____________.答案:Pragmatics10. The study of the way language is processed in the brain is known as ____________.答案:Neurolinguistics三、简答题(每题10分,共40分)1. Explain the difference between phonetics and phonology.答案:Phonetics is the study of speech sounds and theirproduction, while phonology is the study of the sound system of a language, including the rules governing the use of these sounds.2. What is the Sapir-Whorf hypothesis?答案:The Sapir-Whorf hypothesis suggests that the language a person speaks influences the way they perceive the world and think.3. Describe the role of sociolinguistics in understanding language.答案:Sociolinguistics helps us understand how language varies with different social contexts, such as class, gender, ethnicity, and age, and how these variations influence language use.4. How does first language acquisition differ from second language acquisition?答案:First language acquisition is the process of learning a native language during early childhood, while second language acquisition is the process of learning a new language after the age of language development. The process of second language acquisition is influenced by the learner's first language and cognitive abilities.。
谱聚类算法综述_蔡晓妍
*)基金项目:国家863计划资助项目(2005AA147030)。
蔡晓妍 博士生,主要研究方向为智能信息处理、网络与信息安全;戴冠中 教授,博士生导师,主要研究领域为自动控制、信息安全;杨黎斌 博士生,研究方向为网络与信息安全、嵌入式系统。
计算机科学2008V ol .35№.7 谱聚类算法综述*)蔡晓妍 戴冠中 杨黎斌(西北工业大学自动化学院 西安710072)摘 要 谱聚类算法是近年来国际上机器学习领域的一个新的研究热点。
谱聚类算法建立在谱图理论基础上,与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解的优点。
本文首先介绍了图论方法用于聚类的基本理论,然后根据图划分准则对谱聚类算法进行分类,着重阐述了各类中的典型算法,并对算法进行了比较分析,最后进行总结并提出了几个有价值的研究方向。
关键词 谱聚类,谱图理论,图划分 Survey on Spectral C lustering AlgorithmsCA I Xiao -yan DA I Guan -zho ng YA N G Li -bin(C ollege of Autom ation ,Northw estern Polytechnical University ,Xi 'an 710072,China )A bstract Spectral clustering alg orithms a re new ly dev elo ping technique in recent year s .Unlike the traditional cluste -ring alg orithms ,these apply spect ral g raph theo ry to solve the clustering of no n -co nv ex sphere of sample spaces ,so that they can be conver ged to g lo bal o ptimal solution .In this paper ,the clustering principle based o n g raph theory is first in -troduced ,and then spectra l clustering alg orithms are catego rized acco rding to rules of g raph pa rtition ,and typical alg o -rithms are studied emphatically ,as well as their advantage s and disadvantage s are presented in de tail .F inally ,some v al -uable directions fo r fur ther research are pro po sed .Keywords Spec tral clustering ,Spectral g raph theo ry ,G raph par titio n 1 引言聚类分析是机器学习领域中的一个重要分支[1],是人们认识和探索事物之间内在联系的有效手段。
Semantic features
Semantic Features of Words
Semantic Features
The appearance of the conception of semantic feature was influence by the phonology theory created by two preventatives of the early Prague School in 20th century Trubetzkoy(特鲁别茨柯 伊)and Jakobson. Trubetzkoy: proposed distinctive feature in the
Grammatical Feature(ten): grammatical markers in language use in communication
Person Numbers Gender Tense Voice Reference Negation and Affirmation Size Time
Semantic Feature
In a word, a word has its own features that can make it distinguished from others that can be seen to have necessary comparison with it. When studying the meanings of words and analyzing the semantic features, we can know clearly about the similarities ,resemblances they shபைடு நூலகம்re and differences that make them different.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
In (1) the negation adverb nicht outscopes the focus particle auch. This information is required to get a correct translation. The preferred reading in (2) is the one where nicht has scope over the modal verb kann (konnen). In these examples the syntactic con gurational information (relative c-command relations) for German supports the preferred scoping: the operator with the widest scope is c-commanding the operator with narrow scope. However, this is not easily carried over to English, since there is no verb movement in the English sentence of (2), so not does not c-command can in this case. In this paper we focus on the underspeci cation of scope introduced by quantifying noun phrases, adverbs, and particles. The underspeci ed representations we use, VITs, resemble the ideas of Underspeci ed Discourse Representation Structures Rey93] and Hole Semantics Bos95]. Firstly, VITs, the Verbmobil Interface Terms are described in Section 2. Section 3 then shows how VITs are built up in the compositional semantics of the Verbmobil system. Section 4 discusses how structural constraints can help to resolve the underspeci ed VIT structures. The section following gives an evaluation of how well the resolution algorithm fares on real dialogues examples. Finally, Section 6 sums up the previous discussion.
Sometimes a distinction is made between the Underspeci ed Logics underlying the work by most of the authors mentioned above and the Quasi Logics of e.g. AC92]. In contrast to the \underspeci ed" representations, the Quasi Logical Form is assumed to have a wellde ned model-theoretic mapping on its own (i.e., separate from the mapping over the fully resolved logical form). Making such a distinction is not relevant to the discussion in the present paper. The ideas we describe should be equally applicable to both these types of semantics | regardless of the underlying models.
Gehort zum Antragsabschnitt: 8
Die vorliegende Arbeit wurde im Rahmen des Verbundvorhabens Verbmobil vom Bundesministeriumfur Bildung, Wissenschaft, Forschung und Technologie (BMBF) unter dem Forderkennzeichen 01 IV 101 R gefordert. Die Verantwortung fur den Inhalt dieser Arbeit liegt bei den Autoren.
Bjorn Gamback, Johan Bos
Universitat des Saarlandes, Computerlinguistik
Semantic-Head Based Reห้องสมุดไป่ตู้olution of Scopal Ambiguities
Report 194
Mai 1997
Mai 1997
Bjorn Gamback, Johan Bos Computerlinguistik Bau 17.2 Universitat des Saarlandes 66041 Saarbrucken e-mail: bos/gam@coli.uni-sb.de Tel.: (0681) 302 - 4680 Fax: (0681) 302 - 4351
1
1
Verbmobil Report 194
(1) das pa t auch nicht that ts also not `that does not t either' (2) ich kann sie nicht verstehen I can you not understand `I can not understand you'
Semantic-Head Based Resolution of Scopal Ambiguities
Abstract
We present an algorithm for scope resolution in underspeci ed semantic representations. Scope preferences are suggested on the basis of semantic argument structure. The major novelty of this approach is that, on the one side, we maintain an (with respect to scopal ambiguities) underspeci ed semantic representation, and on the other side, at the same time suggest a scope resolution possibility. The algorithm is evaluated on four \reallife" dialogues and fares surprisingly well: about 80% of the utterances containing scopal ambiguities are correctly interpreted by the suggested resolution, leaving errors in only 5.7% of the overall utterances.
2 Underspeci ed Semantic Representations
The Verbmobil Interface Term, VIT for short BES96] is a representation that encodes the linguistic information of a natural language utterance. The goal is to describe a consistent interface structure in order to perform communication between the di erent language analysis modules within the Verbmobil system in a smooth and consistent way. Besides semantic structure, the VIT contains prosodic, syntactic, and discourse information. In this paper we will pay attention only to the semantic parts of the VIT. These are 1. the top label, 2
1 Introduction
Scopal ambiguities are known to be problematic for natural language processing (NLP). Resolving scope might lead to the well known combinatorial explosion puzzle. In NLP-applications like semantic-based machine translation, resolution of scope can be avoided if the translation takes place at a semantic representational level that encodes scopal ambiguites: the idea is to have a common representation for all of the possible interpretations of an ambiguous expression, as in ACGR91]. Scopal ambiguities in the source language can then be carried over to the target language. Recent research Rey93, Bos95, Pin95, CCvE+ 96, Poe95] has used the term underspeci cation to describe this idea.1 However, underspeci cation has a clear disadvantage. Syntactic restrictions on scope ambiguities are not encoded in underspeci ed representations. This lack of information is problematic if we want to generate a natural language string (from underspeci ed semantic representations) in a machine translation system like Verbmobil, a semantic-based machine translation system which translates spoken German and Japanese into English Wah93, KGN94, BGL+96, GLM96]. Clear scope con gurations (preferences) in the source language are easily lost in the target language. Consider the following examples: