蒙科立编码转换
蒙古文wps office2002中几种蒙古文之间的转换

蒙古文wps office2002中几种蒙古文之间的转换我们熟悉的蒙古文输入法有赛音蒙文输入法,明安途蒙文输入法、蒙科立蒙文输入法等。
但是用过的人都知道有个让人头疼的问题,这些输入法都无法直接兼容。
比方说我的文章是用赛音蒙文输入的,那么我把文章拿过去另一个地方的时候,人家电脑上安装的蒙文输入法未必是赛音蒙文,那么我的文章就不会被兼容,文章内容就不能正常显示了,无奈之下重新输入的情况也会出现。
其实,这三个蒙文输入法虽然不能直接兼容,但是可以转换的。
下面介绍一下我所了解的转换方法:一、赛音蒙文输入的内容转换成明安途输入的内容1.打开蒙古文wps office2002,打开用赛音输入的内容。
2.复制内容,打开notepad ( 记事本) ,粘贴内容。
3.文件/另存为,这是注意了,起名另存为UNICODE编码的TXT文件。
(另存时修改“编码”方式为“UNICODE”)4.打开明安途转换工具,打开刚才另存的文件,编辑/转换赛音。
5.复制已转换的内容,打开明安途编辑器进行粘贴,然后全选内容,取消UNICODE, 再次全选,进入wpsoffice2002 粘贴即可完成。
二、明安途蒙文输入的内容转换成蒙科立输入的内容1.打开wps office2002 ,全选内容进行复制。
2.打开明安途编辑器,进行粘贴,起名保存。
3.打开蒙科立转换工具,打开文件,打开刚才的文件,点击“转换”命令。
4.打开刚才文件所在目录,会发现多了个“*_Mink”名称的新文件,点击打开,进行全选复制。
5.wps office2002中打开一个新文件进行粘贴,你会发现字体都已成了蒙科立字体的了,到此已完成转换。
编码快速转换的方法
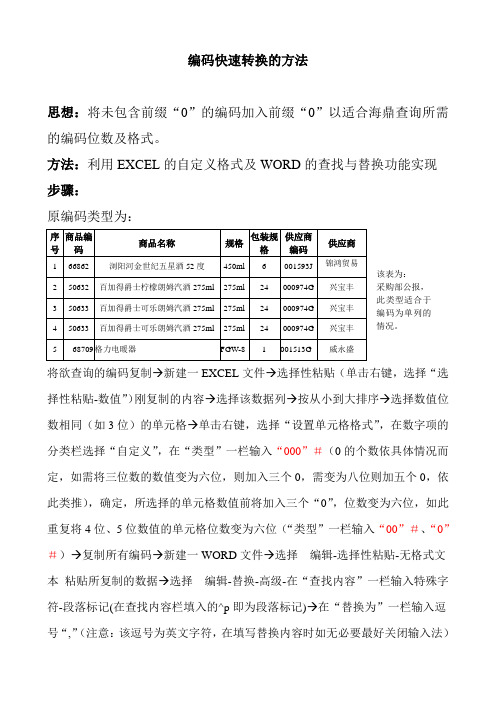
编码快速转换的方法思想:将未包含前缀“0”的编码加入前缀“0”以适合海鼎查询所需的编码位数及格式。
方法:利用EXCEL 的自定义格式及WORD 的查找与替换功能实现 步骤: 原编码类型为:将欲查询的编码复制→新建一EXCEL 文件→选择性粘贴(单击右键,选择“选择性粘贴-数值”)刚复制的内容→选择该数据列→按从小到大排序→选择数值位数相同(如3位)的单元格→单击右键,选择“设置单元格格式”,在数字项的分类栏选择“自定义”,在“类型”一栏输入“000”#(0的个数依具体情况而定,如需将三位数的数值变为六位,则加入三个0,需变为八位则加五个0,依此类推),确定,所选择的单元格数值前将加入三个“0”,位数变为六位,如此重复将4位、5位数值的单元格位数变为六位(“类型”一栏输入“00”#、“0”#)→复制所有编码→新建一WORD 文件→选择 编辑-选择性粘贴-无格式文本 粘贴所复制的数据→选择 编辑-替换-高级-在“查找内容”一栏输入特殊字符-段落标记(在查找内容栏填入的^p 即为段落标记)→在“替换为”一栏输入逗号“,”(注意:该逗号为英文字符,在填写替换内容时如无必要最好关闭输入法)该表为:采购部公报, 此类型适合于编码为单列的情况。
→点击“全部替换”或“替换”将所有编码替换为海鼎接受的格式(即六位编码加逗号如066862,050632,)→将编码复制到海鼎的查询模块就可以进行查询了。
原编码类型为:将欲查询的编码复制,新建一WORD 文件→选择 编辑-选择性粘贴-无格式文本 粘贴所复制的数据→选择 编辑-替换-高级-在“查找内容”一栏输入特殊字符-制表符(在查找内容栏填入的^t 即为制表符)→在“替换为”一栏输入特殊字符-段落标记(在替换为栏填入的^p 即为段落标记)→将所有编码复制后参考上面的方法(粘贴到EXCEL 表格时选择“文本”格式)将所有编码替换为海鼎接受的格式。
该表为:管家卡资料重发 此类型适合于编码为多列的情况。
在线编码转换的使用方法

在线编码转换的使用方法
一、输入源码
在进行在线编码转换之前,首先需要将需要进行转换的源码复制到剪贴板中,或者将源码文件上传到指定的位置。
二、选择目标编码
在选择目标编码时,用户可以根据需要选择不同的目标编码,如UTF-8、GBK等。
这些编码方式各有特点,用户可以根据实际情况进行选择。
例如,UTF-8是一种国际化的编码方式,支持多种语言字符,被广泛应用于网页和电子邮件等场景;而GBK则是一种简体中文字符集编码方式,适用于中文字符的编码。
三、开始转换
在选择好目标编码后,点击开始转换按钮,系统会自动将源码转换为对应的目标编码。
转换过程需要一定的时间,具体时间取决于源码的大小和复杂度。
四、查看转换结果
转换完成后,用户可以查看转换结果。
如果转换成功,用户可以直接复制转换后的代码进行使用;如果转换失败,用户需要检查源码是否正确,或者尝试选择其他的目标编码进行转换。
五、错误处理
在进行在线编码转换时,可能会遇到一些错误,如源码中含有无法识别的字符等。
此时,用户需要仔细检查源码,找出错误的原因并进行修复。
同时,系统也会给出相应的错误提示,帮助用户更好地解决问题。
如果遇到其他问题或困难,用户可以联系在线客服寻求帮助。
蒙古文语料编码转换与校对方法研究

蒙古文语料编码转换与校对方法研究如今信息现代化的时代,信息的传播、资源的共享也都被电子化、网络化。
大部分信息都是以文字形式传播和共享。
对蒙古文信息而言适应信息时代发展要求是必然的。
随着蒙古文信息处理的发展出现了多种蒙古文编码,例如赛音、蒙科立、明安图、智能编码等。
各种编码字库中,蒙古文字形的对应的编码都不一样,互不兼容,如果没有安装对应的蒙古文字库,计算机里的蒙古文资料将显示为乱码,不能使用。
这样会导致蒙古文信息资源无法传播、共享和研究。
解决这些问题的最有效方法就是编码转换,转换成统一的编码。
本文由蒙古文编码转换和编码校对两大部分构成。
编码转换部分中,首先对目前应用较广泛的两种编码-蒙科立编码、智能编码以及蒙古文国际标准编码进行了详细的分析和对比。
其次将蒙科立编码、智能编码两种编码转换为蒙古文国际标准编码。
编码转换为基于蒙古文变形显现字符集和控制字符使用规则的一种转换方法。
编码转换过程中,先通过编码范围判断和编码在词中不同位置的词形判断编码类型。
编码类型确定之后,如果是蒙科立编码则用蒙科立编码转换为标准码的算法将其转换为标准编码。
如果是智能编码,则用智能编码转换为标准编码的算法将其转换为标准编码。
非标准蒙古文编码,例如蒙科立编码、智能编码都属于形码。
标准编码为音码。
转换成标准编码时,由于这些编码并不是与国际标准编码一一对应,有大量的不确定因素,做不到完全正确的编码转换,会出现错误编码。
另外键盘录入也会产生编码错误。
因此要对转换后的标准编码或者录入产生的蒙古文国际标准编码进行校对。
本文的编码校对是基于蒙古文元音阴阳和谐规则的校对方法。
校对规则为同一字中阴阳元音不能混合出现。
即词中第一个出现的元音为阳性元音,则词中后续出现的元音也是阳性。
词中第一个出现的元音为阴性元音,则词中后续出现的元音也是阴性。
否则将错误编码替换为对应的正确编码。
编码校对实现过程中,用判断元音辅音的算法判断当前编码是元音还是辅音;用判断元音阴阳性算法判断元音的阴阳性;词中第一个出现的元音用获取第一个元音的元音的算法得到;利用获取正确元音错误元音算法对后续出现的原因进行判断,最后用校对单词算法将错误编码替换为为正确编码。
Windows和Linux的字符编码转换

前谈过一篇关于Linux下面Unicode使用的文章。
那个主要是针对多字节和宽字符的转换而谈的。
今天说的有些类似,主要是windows下面关于字符编码转换和Linux下面的不同。
我移植的那部分程序中,有函数是用来实现UTF-8和GBK之间的转换的。
其实其他很多不同类型的字符之间转换都可以用这种方法。
先说windows。
因为windows下面没有函数可以实现这一功能,所以得自己写。
思路很简单,就是利用之前讲过的那两个函数来实现,即:MultiByteToWideChar和WideCh arToMultiByte来实现。
先将其中一种编码(如UTF-8)利用MultiByteToWideChar转换为宽字节,然后再利用WideCharToMultiByte转换为另一种编码(如GBK)。
反过来也是一样的。
下面给出代码:LONG UTF8ToGBK(const void * lpUTF8Str, string & str){if(lpUTF8Str == NULL) return -1;int nRetLen = 0;//获取转换到Unicode编码后所需要的字符空间长度nRetLen = ::MultiByteToWideChar(CP_UTF8, 0,(char *)lpUTF8Str, -1, NULL, NULL);WCHAR *lpUnicodeStr = new WCHAR[nRetLen + 1];//为Unicode字符串空间//转换到Unicode编码nRetLen = ::MultiByteToWideChar(CP_UTF8, 0,(char *)lpUTF8Str, -1, lpUnicodeStr, nRetLen);if(!nRetLen){delete []lpUnicodeStr; return -1;}//获取转换到GBK编码后所需要的字符空间长度nRetLen = ::WideCharToMultiByte(CP_ACP, 0, lpUnicodeStr,-1, NULL, NULL, NULL, NULL);CHAR *lpGBKStr = new CHAR[nRetLen + 1];nRetLen = ::WideCharToMultiByte(CP_ACP, 0, lpUnicodeStr,-1, (char *)lpGBKStr, nRetLen, NULL, NULL);//转换到GBK编码if(!nRetLen){delete []lpUnicodeStr;delete []lpGBKStr;return -2;}str = lpGBKStr;delete []lpUnicodeStr;delete []lpGBKStr;return 0;}再来看Linux,它已经提供了函数可以实现这一功能,不仅如此,Linux还可以实现批量文件的字符编码转换呢。
蒙古文编码向拉丁转写转换和分音节算法实现

蒙古文编码向拉丁转写转换和分音节算法实现孟和吉雅;山丹【摘要】在蒙古文单词拼写中有很多型同音异词,从字面上难以辨别和区分型同字符的差异,这对蒙古文信息处理方面都带来了一定的困难.但在蒙古文的文字信息处理过程中,解决型同音异词,确定其编码是一项重要研究内容.该文重点讨论如何实现蒙古文的拉丁转写和切分音节,来确定那些型同音异词中的型同字符的问题.%The Mongolian has, lots of words with the same type but different pronunciation. Which challenges the Mongolian information processing. Therefore, it is essential in Mongolian information processing to solve these kind of words and determine the codes. This paper mainly discusses how to realize Latin transformation and syllable segmentation for such words in Mongolian.【期刊名称】《中文信息学报》【年(卷),期】2011(025)004【总页数】4页(P101-104)【关键词】蒙古文;音节;拉丁转写【作者】孟和吉雅;山丹【作者单位】内蒙古大学计算机学院,内蒙古呼和浩特010020;内蒙古社会科学院,内蒙古呼和浩特010020【正文语种】中文【中图分类】TP3911 前言蒙古语是中国蒙古族自治地方的通用语言之一。
在上世纪70、80年代开始研究蒙古文信息处理时,主要是从文字处理开始的,而且制定的蒙古文编码也是表现“字型”为主。
经过几十年的发展,蒙古文信息处理研究已经不仅仅局限于文字处理方面,在语音合成、语音识别、文字识别等也有了一定成果。
《2024年蒙汉语码转换研究》范文

《蒙汉语码转换研究》篇一一、引言随着全球化的推进和信息技术的飞速发展,语言交流的多样性变得越来越重要。
蒙汉语码转换作为一种特殊的语言交流方式,其重要性逐渐凸显。
蒙汉语码转换研究,不仅对于深入了解两种语言的特点及其背后的文化背景有着重要意义,还有助于推动语言技术的创新和语言服务的发展。
本文将针对蒙汉语码转换的相关问题进行研究分析,为进一步探讨蒙汉语码转换的应用与发展提供参考。
二、蒙汉语码转换概述蒙汉语码转换,是指在不同语言之间进行文字编码的转换,使蒙文和汉字在计算机系统中实现互通。
这种转换主要涉及字符编码的转换和语义信息的传递。
蒙文和汉字分别属于不同的文字体系,因此,进行蒙汉语码转换需要解决文字编码、语义对应等关键问题。
三、蒙汉语码转换的技术方法(一)基于规则的转换方法基于规则的转换方法是通过制定一定的转换规则来实现蒙汉语码的转换。
这种方法需要建立一套完整的规则体系,包括字符编码的对应关系、语法规则、语义对应等。
在应用中,该方法需结合具体场景和需求,灵活运用规则进行转换。
(二)基于统计的转换方法基于统计的转换方法则是通过分析大量语料库中的数据来寻找蒙汉两种语言之间的对应关系。
这种方法主要利用自然语言处理技术和机器学习算法,对语料库进行训练和优化,从而实现蒙汉语码的自动转换。
(三)混合方法混合方法则是结合了基于规则和基于统计两种方法的优点,既考虑了语言的规则性,又利用了统计数据来提高转换的准确率。
这种方法在处理复杂语言现象时具有较好的表现。
四、蒙汉语码转换的应用与发展(一)应用领域蒙汉语码转换在多语言环境下的信息处理、跨文化交流、教育、翻译等领域具有广泛的应用价值。
例如,在多语言环境下的信息处理中,蒙汉语码转换技术可以实现不同语言之间的互通,提高信息处理的效率;在跨文化交流中,该技术有助于促进不同民族之间的交流与理解;在教育领域,该技术可以辅助双语教学,帮助学生更好地掌握两种语言;在翻译领域,该技术可以辅助计算机辅助翻译,提高翻译的准确性和效率。
am码代码转换

AM (Amplitude Modulation) 码转换通常指的是在数字信号和模拟信号之间进行转换的过程。
在一个典型的 AM 系统中,数字数据(通常是二进制)被转换为模拟信号,然后通过改变载波信号的振幅进行传输。
接收端则通过检测载波振幅的变化来恢复原始的数字数据。
如果你想将数字信号转换为 AM 调制信号,你可以遵循以下步骤:1. **二进制数据编码**:首先,你需要将你的数字数据(通常是二进制)进行编码。
这可能涉及到将二进制数据转换为其他格式,如曼彻斯特编码或差分曼彻斯特编码,以便于在模拟信号中传输。
2. **载波生成**:然后,你需要生成一个载波信号。
这个载波信号通常是一个正弦波,其频率远高于你的数据信号的频率。
3. **调制**:接下来,你将数字数据信号与载波信号进行调制。
在 AM 调制中,这通常涉及到改变载波信号的振幅以匹配数据信号的振幅。
例如,如果你的数据信号是高电平,那么你可能会增加载波信号的振幅;如果你的数据信号是低电平,那么你可能会减少载波信号的振幅。
4. **传输**:然后,你可以通过你的通信通道(如无线电波、电线等)传输调制后的 AM 信号。
5. **解调**:在接收端,你需要对接收到的 AM 信号进行解调以恢复原始的数字数据。
这通常涉及到检测载波信号的振幅变化,并将其转换回原始的数字数据。
具体的实现方法可能因你使用的硬件和软件平台而异。
在一些情况下,你可能需要使用专门的硬件(如调制器、解调器、滤波器等)来执行这些步骤。
在其他情况下,你可能可以使用编程语言(如 Python、C++ 等)和相关的库或框架来实现这些功能。
需要注意的是,AM 调制通常对噪声和失真比较敏感,因此在一些应用中可能不是最佳选择。
例如,在无线通信中,FM(频率调制)或 PM(相位调制)可能更为常见。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
蒙科立编码转换
蒙科立编码转换是一种在少数民族语言信息化处理中常用的技术,它可以将蒙古文字符转换为数字化编码,实现信息的计算机化和网络化传输。
蒙科立编码转换的作用在于实现了蒙古文字符的数字化。
蒙古文是一种复杂的文字系统,包含了许多不同形状和音节的字符,而计算机只能识别二进制数字。
因此,通过蒙科立编码转换,可以将蒙古文字符转换为二进制数字,使得计算机可以处理和存储蒙古文信息。
蒙科立编码转换可以实现蒙古文信息的跨平台传输和显示。
在互联网时代,信息的传输和共享需要使用不同的设备和平台。
而蒙科立编码转换提供了一种通用的编码标准,可以将蒙古文信息在不同的设备上实现统一的编码和解码,避免了因为不同平台和软件之间的差异而导致的乱码和无法正常传输的问题。
另外,蒙科立编码转换可以实现蒙古文信息的加密和安全传输。
在信息传输过程中,有时候需要保护信息的隐私和安全。
而蒙科立编码转换可以提供加密技术,将蒙古文信息进行加密处理,避免信息被恶意攻击和窃取。
蒙科立编码转换还可以实现蒙古文信息的压缩和存储。
蒙古文字符数量较多,存储和传输需要占用较多的空间。
而蒙科立编码转换可以提供压缩技术,将蒙古文信息进行压缩处理,减少空间占用和传输
负载,提高信息处理的效率和可靠性。
综上所述,蒙科立编码转换是一种在少数民族语言信息化处理中常用的技术,可以实现蒙古文字符的数字化、跨平台传输和显示、加密和安全传输、压缩和存储等功能。
它对于保护和促进少数民族语言文化的发展具有重要的意义。