mycat生产实施方案
基于Mycat的交通大数据存储方案

基于Mycat的交通大数据存储方案作者:陈宇收来源:《电子技术与软件工程》2018年第16期摘要随着城市汽车保有量的累年增多,传统的使用关系型数据库存储交通生产数据的解决方案缺陷逐渐暴露,具体表现在存储容量达到上限、存取效率随着存储数据增多逐渐变慢等,不但给数据存储、维护带来了极大不便,而且还影响到正常交通业务的开展,因此,迫切需要改变通过Mycat技术体系的应用,不但解决了交通大数据的存储瓶颈,而且通过基于Mycat建立的高可用数据库存储方案的设计,还保障了数据存储能够持续、不间断的提供访问支持,保障了交通大数据存储能够高质量、高效率的进行。
【关键词】Mycat 交通大数据分布式数据存储1 引言随着人们生活质量的提高以及汽车行业的飞速发展,使得汽车购置出现了爆炸式的增长,直接导致了针对车辆的过车数据、违章数据等呈现直线上升,并逐渐积累成一定规模的海量数据,不但给传统的数据管理工作带来了极大负担,而且如何有效的完成这些新增数据的存储管理,并实现对这些数据的高效、准确、便捷分析,最终为构建安全便捷、畅通高效、绿色智能的交通管理体系提供数据依据已经成为当前交通大数据存储研究的重点。
在大数据存储领域,当前主流的解决方案为Hbase数据库、Hive数据仓库以及传统结构化的解决方案Oracle RAC等,其中Hbase虽然通过分布式存储方案能够有效完成交通大数据的存储,但由于其数据存储为非结构化,不支持使用SQL语句完成交通数据记录的高效存取,所以针对交通大数据频繁的记录筛选应用存在一定的不足;Hive数据仓库在应用时,虽然其凭借结构化的存储模式能够较好的支持SQL语言的统计、分析,但是由于其定位在数据仓库存储,对单个记录的输入、变更及删除支持不友好,而交通大数据是实时单个记录的生产方式,所以也不宜采用;Oracle RAC虽然兼顾了结构化存储以及海量数据存储等应用需求,然而由于Oralce为商业软件,成本昂贵,所以当建设Oracle RAC集群时,其成本势必高昂,不利于商业化推广。
基于 MyCat 分布式数据库解决方案的学汇总

基于MyCat 分布式数据库解决方案的学汇总最近公司推荐了mycat分布式中间件解决数据库分布式方案,今天到mycat官网学了一翻(),汇总下几个重点:1、mycat是什么?mycat是一个开源的分布式数据库系统,是一个实现了MySQL 协议的Server,前端用户可以把它看作是一个数据库代理,用MySQL 客户端工具和命令进行访问,后端可以用MySQL 原生(Native)协议访问数据库(不限于MYSQL数据库), 其核心功能是分表分库,即将一个多表水平分割为N 个小表,存储在后端的数据库中。
以下是几种通俗的方式介绍MYCAT:1)对于DBA 来讲:Mycat 就是MySQL Server,而Mycat 后面连接的MySQL Server,就好象是MySQL 的存储引擎,如InnoDB,MyISAM 等,因此,Mycat 本身并不存储数据,数据是在后端的MySQL 上存储的,因此数据可靠性以及事务等都是MySQL 保证的,简单的说,Mycat 就是MySQL 最佳伴侣,它在一定程度上让MySQL 拥有了能跟Oracle PK 的能力。
2)对于开发来讲:Mycat 就是一个近似等于MySQL 的数据库服务器,你可以用连接MySQL 的方式去连接Mycat(除了端口不同,默认的Mycat 端口是8066 而非MySQL 的3306,因此需要在连接字符串上增加端口信息),大多数情况下,可以用你熟悉的对象映射框架使用Mycat,但建议对于分片表,尽量使用基础的SQL 语句,因为返样能达到最佳性能,特别是几千万甚至几百亿条记录的情况下。
3)对于架构师来讲:Mycat 是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用于多租户应用开发、平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的Mycat 智能优化模块,系统的数据访问瓶颈和热点一目了然,根据返些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同存储引擎上,而整个应用的代码一行也不用改变。
mycat路由解析开发指南

Mycat路由解析开发指南1切换解析器配置解析器的切换修改server.xml文件中的以下内容:在<system></system>内部加入<!--默认的sql解析器,可选值fdbparser,druidparser --><property name="defaultSqlParser">druidparser</property>druidparser为新解析器,fdbparser为原先的解析器。
2Druid解析器的优势1、性能更高。
druidparser为新解析器,该解析器单独从解析性能上比原解析器(fdbparser)快5倍以上,甚至10倍以上,sql越长,快的倍数越多。
曾经对一个长sql解析测试,能达到40倍左右。
2、支持的语法更多。
下面列举一些fdbparser不支持,但是druidparser支持的语法:(1)Insert into ….on duplicate key update…..(2)Insert into (),()…语句(3)带注释(comment)的create table语句(4)alter table … change….语句;(5)alter table … modify….语句;(6)添加索引时带索引名称的;如alter table coding_rule add unique ux_indexname (prefix);之前很多不支持的语法mycat需要使用hint来支持,现在只需要换成druidparser 就可以了。
3、编码更容易。
Druid解析出路由信息可以有两种方式:visitor方式、statement方式,其api比较方便的提取表名、条件表达式、字段列表、值列表等信息。
而且可以很容易的通过ast语法树改写sql,这对人工智能路由比较有帮助。
3路由解析流程本文采用自顶向下方式,从粗到细逐步展开路由解析流程。
mycat的核心流程

mycat的核心流程Mycat一款面向联机事务处理(OLTP)应用的中间件软件,具有优异的性能和高可用性特性,是处理大规模数据的理想解决方案。
它独特的架构可以像系统数据库一样处理大规模的数据,同时保证高可用性、服务器稳定性以及安全性。
Mycat的核心流程是将应用程序发出的SQL请求分发到逻辑数据库,实现数据库分片、分布式存储和路由,从而在多个服务器上执行查询操作。
Mycat的核心流程涉及两个主要方面,即SQL解析和数据拆分。
SQL解析指的是将用户提交的SQL语句解析为相关的语义动作,并将其拆分为多个子语句,以便进行正确的查询。
Mycat解析子语句时不仅会解析SQL语句的语义,而且还会考虑相关的数据库设计要求。
Mycat的SQL解析基于ANTLR实现,它是一个开源的语言处理引擎,可以解释SQL语句,分析词法和语法,识别和计算各种SQL表达式。
Mycat还可以检查SQL语句是否满足分布式数据库所要求的语义要求,并通过查询优化树来完成系统内部的查询优化。
数据拆分是Mycat中涉及到的第二个核心流程,它指的是将用户要查询或修改的数据拆分成多个片段,分布存储在物理服务器上。
Mycat接收用户提交的请求后,会使用数据拆分算法进行拆分,以保证任务的完整性和数据的一致性。
Mycat的数据拆分算法支持Hash、Range、List三种类型的拆分策略,根据实际的数据特征进行选择,以保证拆分的效率和性能。
Mycat的核心流程是SQL解析和数据拆分,它们使用户能够使用Mycat进行分布式数据库查询和修改,在多台服务器上获取所需数据。
Mycat不仅具有分布式数据处理能力,可以有效降低成本,还可以支持各种类型的复杂查询。
此外,Mycat具有高可用性、负载均衡、数据完整性与安全性的优点,可以有效地提高数据库的复杂度,支持数据库高速处理。
Mycat→实现数据库的读写分离与高可用

Mycat→实现数据库的读写分离与⾼可⽤开⼼⼀刻 上语⽂课,不⼩⼼睡着了 坐在边上的同桌突然叫醒了我,并⼩声说道:“读课⽂第三段” 我⽴马起⾝⼤声读了起来 正在⿊板写字的⽼师吓了⼀跳,⽼师郁闷的看着我,问道:“同学有什么问题吗?” 我貌似知道了什么,淡定地说了⼀句:“这段写的真好!我给⼤伙念念!” ⽼师还较真了:“你说说看,好在哪⾥?” 顿时我就⽆语了,脸⿊着望向了同桌了,⼼想着:“这是个畜⽣啊!”前情回顾 中讲到了基于mysql5.7.18的主从复制结构的搭建,⽐较简单,只要细⼼点,很容易搭建成功。
从代码层⾯实现了读写分离(实现⽅式:注解+aop),需要配置两个数据源:masterDataSource、slaveDataSource,分别针对主从数据库,另外还需要在代码层⾯明确指定⽤哪个数据源。
会增⼤代码量(虽然只是增加⼀个注解),并且耦合在代码中不利于拓展与后续维护,⼀旦进⾏修改就需要重新编译打包,最严重的是如果数据库宕机了,应⽤就会抛异常,完全不能正常服务了。
那么有没有其他层⾯的更优⽅案呢?肯定是有的,我们可以从数据库的层⾯来实现读写分离,应⽤代码不感知连接的是什么数据库,按平时单库的⽅式处理即可,具体实现我们往下看。
mysql主从实现 Mycat不负责任何的数据同步问题,mysql的主从复制还得从mysql层⾯来实现;如果没有实现mysql的主从复制,后⽂就都成了。
mysql的主从复制是实现读写分离的基础,具体的搭建过程请参考:,本⽂就不展⽰详细的搭建过程了。
我的mysql主从信息如下 master:192.168.1.210;slave:192.168.1.211;需要复制的数据库:mycat_dbMycat搭建 Mycat是什么?是数据库中间件,介于数据库与应⽤之间,进⾏数据处理与交互的中间件服务,可以简单的理解成数据库代理,我们的应⽤只需要与数据库中间件交互,⽽⽆需关注复杂的数据库部署。
MySQL主从复制、读写分离实现(MyCat)及运用

1 主从复制1.1 概述主从复制是指将主数据库的DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL 复制的有点主要包含以下三个方面:1.主库出现问题,可以快速切换到从库提供服务。
2.实现读写分离,降低主库的访问压力。
3.可以在从库中执行备份,以避免备份期间影响主库服务。
1.2 原理从上图来看,复制分成三步:1.Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
2.从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
3.slave重做中继日志中的事件,将改变反映它自己的数据。
1.3 搭建1.3.1 服务器准备1.两台服务器安装MySQL,并完成基础的初始化工作;2.放行MySQL数据库端口(3306),或者关闭防火墙#放行3306端口firewall-cmd --zone=public --add-port=3306/tcp -permanent#关闭防火墙systemctl disable firewalld --now1.3.2 主库配置1.修改配置文件/etc/my.conf#mysql服务ID,保证整个集群环境中唯一,取值范围:1-2^32-1,默认为1server-id=1#是否只读,1代表只读,0代表读写read-only=0#忽略的数据,指不需要同步的数据库#binlog-ignore-db=mysql#指定同步的数据库#binlog-do-db=db012.重启数据库systemctl restart mysqld3.创建远程连接的账号,并授予主从复制的权限-- 创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务CREATE USER'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';-- 为'itcast'@'%'用户分配主从复制权限GRANT REPLICATION SLAVE ON*.*TO'itcast'@'%';4.通过命令,查看二进制坐标show master status;字段含义说明:file : 从哪个日志文件开始推送日志文件position :从哪个位置开始推送日志binlog_ignore_db : 指定不需要同步的数据库4.开启同步操作start relica; -- 8.0.22之后2.CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
Mycat配置分库分表(垂直分库、水平分表)、全局序列
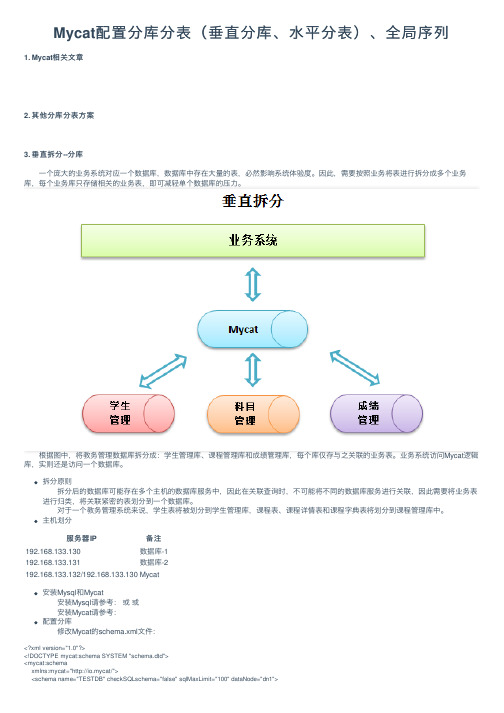
Mycat配置分库分表(垂直分库、⽔平分表)、全局序列1. Mycat相关⽂章2. 其他分库分表⽅案3. 垂直拆分--分库 ⼀个庞⼤的业务系统对应⼀个数据库,数据库中存在⼤量的表,必然影响系统体验度。
因此,需要按照业务将表进⾏拆分成多个业务库,每个业务库只存储相关的业务表,即可减轻单个数据库的压⼒。
根据图中,将教务管理数据库拆分成:学⽣管理库、课程管理库和成绩管理库,每个库仅存与之关联的业务表。
业务系统访问Mycat逻辑库,实则还是访问⼀个数据库。
拆分原则 拆分后的数据库可能存在多个主机的数据库服务中,因此在关联查询时,不可能将不同的数据库服务进⾏关联,因此需要将业务表进⾏归类,将关联紧密的表划分到⼀个数据库。
对于⼀个教务管理系统来说,学⽣表将被划分到学⽣管理库,课程表、课程详情表和课程字典表将划分到课程管理库中。
主机划分服务器IP备注192.168.133.130数据库-1192.168.133.131数据库-2192.168.133.132/192.168.133.130Mycat安装Mysql和Mycat 安装Mysql请参考:或或 安装Mycat请参考:配置分库 修改Mycat的schema.xml⽂件:<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schemaxmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="t_student" dataNode="dn2"></table></schema><dataNode name="dn1" dataHost="host1" database="education" /><dataNode name="dn2" dataHost="host2" database="education" /><dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="192.168.133.130:3306" user="root" password="123456"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM2" url="192.168.133.131:3306" user="root" password="123456"></writeHost></dataHost></mycat:schema> 对于数据库education,仅把表t_student划分到第⼆个节点,即主机2上,其余的表t_schedule、t_schedule_detail、t_subject_dict默认划分到第⼀个节点。
Mycat介绍

会及时修复,解决了生产中应用的后顾之忧
Mycat的资料非常全,包括志愿者提供的资料,用户分享的经验资料,以及官方
定期更新的《Mycat权威指南》,绝大多数技术问题,都可以通过文档和社区交 流来解决 式,名利双收,一举两得。
如果需要专业技术支持服务,也可以跟Mycat社区交流,通过赞助开源项目的方
为什么选择MYCAT
性能问题
数据库连接过多
E-R分片难处理 可用性问题
MySQL Member表
Standby切换故障
MySQL 应用
成本和伸缩性问题
依赖高成本的硬件设备
Mycat
MySQL
Member表
官方网站
mycat
官方QQ群
106088787
github地址
欢迎加入Mycat社区,做中国的Apache
https:///MyCATApache
使用MYCAT
子版发布,众筹预售超过200本,成为开源项目中的首创。 O2O的众多领域和公司。
截至2015年4月,超过60个项目采用Mycat,涵盖电信、电子商务、物流、移动应用、
MYCAT社区的发展
截至2014年5月,Mycat官方QQ群(106088787)已经超过1700人,大多数为资
深IT工程师、架构师、DBA、以及一些CXO和高端猎头,成为国内最有影响力的高 端IT专业群 到Mycat里,从而吸引和聚集了一大批业内大数据和云计算方面的资深工程师, Mycat社区成为名副其实的国内大数据领域实力派成员。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
mycat生产实施方案
Mycat生产实施方案
一、引言
Mycat是一个开源的分布式数据库中间件,它提供了对MySQL数据
库的高可用、负载均衡、分库分表等功能。
在大规模的数据存储和
访问场景下,Mycat能够有效地提升数据库的性能和稳定性。
因此,本文将介绍Mycat生产实施方案,帮助您更好地使用Mycat来提升
数据库的处理能力和可靠性。
二、Mycat生产实施方案
1. 硬件环境准备
在实施Mycat之前,首先需要准备好适用的硬件环境。
需要确保服
务器的性能和稳定性能够满足Mycat的需求,包括CPU、内存、硬
盘等方面的配置。
同时,还需要考虑网络带宽和安全防护等方面的
因素,以确保Mycat能够在稳定可靠的环境下运行。
2. 软件环境准备
除了硬件环境,还需要准备好适用的软件环境。
首先需要安装和配置MySQL数据库,然后再安装Mycat中间件,并进行相应的配置和优化。
在软件环境准备阶段,需要特别注意各个组件之间的兼容性和稳定性,以确保整个系统能够正常运行。
3. 数据库架构设计
在实施Mycat之前,需要对数据库架构进行设计和优化。
这包括数据库的分库分表设计、索引优化、SQL语句优化等方面。
通过合理的数据库架构设计,能够有效地提升数据库的性能和可靠性,从而更好地支持Mycat中间件的运行。
4. Mycat配置和优化
Mycat的配置和优化是实施过程中的关键环节。
需要根据实际的业务需求和硬件环境,对Mycat进行相应的配置和优化,包括负载均衡策略、读写分离配置、连接池配置等方面。
通过合理的配置和优化,能够更好地发挥Mycat中间件的性能和功能优势。
5. 测试和监控
在实施Mycat之后,需要进行相应的测试和监控工作。
通过压力测
试、性能测试等手段,验证Mycat中间件的稳定性和性能表现。
同时,需要建立完善的监控系统,实时监控Mycat中间件的运行状态和性能指标,及时发现和解决潜在的问题。
6. 故障处理和优化
最后,需要建立完善的故障处理和优化机制。
当Mycat中间件出现故障或性能下降时,需要能够快速定位问题并进行相应的处理。
同时,还需要不断地进行优化工作,提升Mycat中间件的稳定性和性能,以满足不断增长的业务需求。
三、结语
Mycat生产实施方案的实施,是一个复杂而又重要的工作。
通过合理的硬件环境准备、软件环境准备、数据库架构设计、Mycat配置和优化、测试和监控、故障处理和优化等一系列工作,能够更好地发挥Mycat中间件的优势,提升数据库的性能和可靠性,为业务的发展提供有力的支持。
希望本文能够帮助您更好地实施Mycat,并取得良好的效果。