简单的java解析文本文件批量导入数据库
java处理Txt文件并且存入数据库
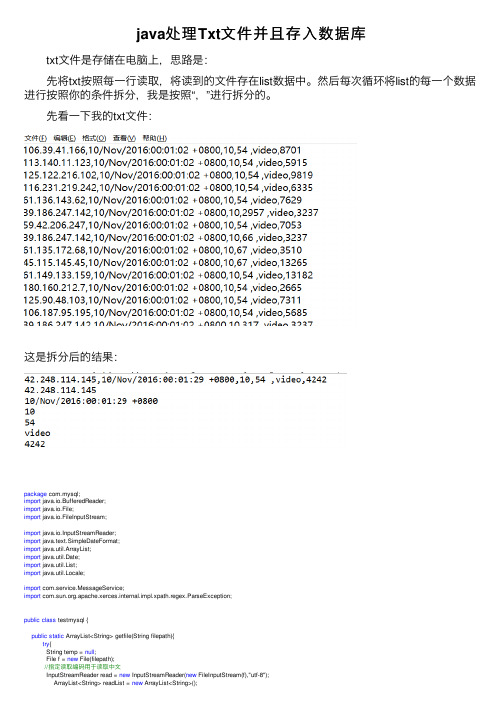
java处理Txt⽂件并且存⼊数据库 txt⽂件是存储在电脑上,思路是: 先将txt按照每⼀⾏读取,将读到的⽂件存在list数据中。
然后每次循环将list的每⼀个数据进⾏按照你的条件拆分,我是按照“,”进⾏拆分的。
先看⼀下我的txt⽂件:这是拆分后的结果:package com.mysql;import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.InputStreamReader;import java.text.SimpleDateFormat;import java.util.ArrayList;import java.util.Date;import java.util.List;import java.util.Locale;import com.service.MessageService;import .apache.xerces.internal.impl.xpath.regex.ParseException;public class testmysql {public static ArrayList<String> getfile(String filepath){try{String temp = null;File f = new File(filepath);//指定读取编码⽤于读取中⽂InputStreamReader read = new InputStreamReader(new FileInputStream(f),"utf-8");ArrayList<String> readList = new ArrayList<String>();BufferedReader reader=new BufferedReader(read);//bufReader = new BufferedReader(new FileReader(filepath));while((temp=reader.readLine())!=null &&!"".equals(temp)){readList.add(temp);}read.close();return readList;}catch (Exception e) {e.printStackTrace();}return null;}//改变时间的格式public static String parseDate(String dateStr) throws java.text.ParseException{SimpleDateFormat input_date = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH); SimpleDateFormat output_date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String finalDate = "";try {Date parse_date = input_date.parse(dateStr);finalDate = output_date.format(parse_date);} catch (ParseException e) {e.printStackTrace();}return finalDate;}public static void main(String[] args) throws java.text.ParseException {//txt⽂件读取ArrayList<String> list=getfile("D:\\result.txt");//List<String> list1=new ArrayList<String>();int num=list.size();for (int i = 0; i < num; i++) {//System.out.println(list.get(i));if (list.get(i)!=null) {String[] s=list.get(i).split(",");String data=parseDate(s[1]);//txt每⾏可以分割成6个字符串存到是s[],String sql = "insert into detailresult(ip,time,day,traffic,type,id) values('" + s[0] + "','" +data+ "','" +s[2] + "','" + s[3] +"','" + s[4] +"','" + s[5] + "')";MessageService.add(sql);}}System.out.println("添加成功");}}。
Java一次性读取或者写入文本文件所有内容

Java⼀次性读取或者写⼊⽂本⽂件所有内容⼀次性读取⽂本⽂件所有内容我们做⽂本处理的时候的最常⽤的就是读写⽂件了,尤其是读取⽂件,不论是什么⽂件,我都倾向于⼀次性将⽂本的原始内容直接读取到内存中再做处理,当然,这需要你有⼀台⼤内存的机器,内存不够者……可以⼀次读取少部分内容,分多次读取。
读取⽂件效率最快的⽅法就是⼀次全读进来,很多⼈⽤readline()之类的⽅法,可能需要反复访问⽂件,⽽且每次readline()都会调⽤编码转换,降低了速度,所以,在已知编码的情况下,按字节流⽅式先将⽂件都读⼊内存,再⼀次性编码转换是最快的⽅式,典型的代码如下:public String readToString(String fileName) {String encoding = "UTF-8";File file = new File(fileName);Long filelength = file.length();byte[] filecontent = new byte[filelength.intValue()];try {FileInputStream in = new FileInputStream(file);in.read(filecontent);in.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}try {return new String(filecontent, encoding);} catch (UnsupportedEncodingException e) {System.err.println("The OS does not support " + encoding);e.printStackTrace();return null;}}⼀次性写⼊⽂本⽂件所有内容/*** ⼀次性写⼊⽂本⽂件所有内容** @param fileName* @param content*/public static void saveStringTOFile(String fileName, String content){FileWriter writer=null;try {writer = new FileWriter(new File(fileName));writer.write(content);} catch (IOException e) {// TODO ⾃动⽣成的 catch 块e.printStackTrace();} finally {try {writer.close();} catch (IOException e) {// TODO ⾃动⽣成的 catch 块e.printStackTrace();}}System.out.println("写⼊成功!!!");}。
java读取excel文件数据导入mysql数据库

java读取excel⽂件数据导⼊mysql数据库这是我来公司的第⼆周的⼀个⼩学习任务,下⾯是实现过程:1.建⽴maven⼯程(⽅便管理jar包)在pom.xml导⼊ jxl,mysql-connector 依赖可以在maven仓库搜索2.建⽴数据库连接类,数据库对应实体类2.编写数据库表对应的实体类,get、set⽅法等3.下⾯是编写读取excel⽂件的类,和运⾏主类package service;import java.io.File;import java.sql.ResultSet;import java.sql.SQLException;import java.util.ArrayList;import java.util.List;import jxl.Sheet;import jxl.Workbook;import excel.DB;import excel.Student;public class StudentService {/*** 查询Student表中所有的数据* @return*/public static List<Student> getAllByDb(){List<Student> list=new ArrayList<Student>();try {DB db=new DB();String sql="select * from student";ResultSet rs= db.Search(sql, null);while (rs.next()) {int id=rs.getInt("id");String s_name=rs.getString("s_name");String age=rs.getString("age");String address=rs.getString("address");list.add(new Student(id, s_name, age,address));}} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}return list;}/*** 查询指定⽬录中电⼦表格中所有的数据* @param file ⽂件完整路径* @return*/public static List<Student> getAllByExcel(String file){List<Student> list=new ArrayList<Student>();try {Workbook rwb=Workbook.getWorkbook(new File("F:\\student.xls"));Sheet rs=rwb.getSheet(0);//表int clos=rs.getColumns();//得到所有的列int rows=rs.getRows();//得到所有的⾏System.out.println("表的列数:"+clos+" 表的⾏数:"+rows);for (int i = 1; i < rows; i++) {for (int j = 0; j < clos; j++) {//第⼀个是列数,第⼆个是⾏数String id=rs.getCell(j++, i).getContents();//默认最左边编号也算⼀列所以这⾥得j++ String s_name=rs.getCell(j++, i).getContents();String age=rs.getCell(j++, i).getContents();String address=rs.getCell(j++, i).getContents();System.out.println("id:"+id+" name:"+s_name+" sex:"+age+" address:"+address); list.add(new Student(Integer.parseInt(id), s_name,age,address));}}} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}return list;}/*** 通过Id判断是否存在* @param id* @return*/public static boolean isExist(int id){try {DB db=new DB();ResultSet rs=db.Search("select * from student where id=?", new String[]{id+""});if (rs.next()) {return true;}} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}return false;}public static void main(String[] args) {System.out.println(isExist(1));}}运⾏主类:package service;import java.util.List;import excel.DB;import excel.Student;public class TestExcelToDb {public static void main(String[] args) {//得到表格中所有的数据List<Student> listExcel=StudentService.getAllByExcel("F:\\student.xls");DB db=new DB();for (Student student : listExcel) {int id=student.getId();System.out.println(id);if (!StudentService.isExist(id)) {//不存在就添加String sql="insert into student (id,s_name,age,address) values(?,?,?,?)";String[] str=new String[]{id+"",student.getS_name(),student.getAge(),student.getAddress()+""};db.AddU(sql, str);}else {//存在就更新String sql="update student set s_name=?,age=?,address=? where id=?";String[] str=new String[]{student.getS_name(),student.getAge(),student.getAddress()+"",id+""};db.AddU(sql, str);}}}}数据库截图:[Excel数据表头要与数据库字段对应]总结:以上是使⽤了 jxl实现的读取excel⽂件内容,并且将数据传到mysql,缺陷是:jxl仅⽀持EXCEL2003。
java excel导入解析

java excel导入解析Java Excel导入解析:实现数据批量处理的利器在如今信息爆炸的时代,大量的数据需要被快速导入和解析,这就要求我们寻找高效的工具来处理这些数据。
而Java语言作为一种广泛使用的编程语言,其强大的功能和丰富的类库使得它成为了数据处理的首选。
本文将介绍如何使用Java语言来实现Excel的导入解析,从而实现数据的批量处理。
一、背景介绍Excel作为一种常见的办公软件,被广泛用于存储和处理各种数据。
然而,当数据量较大时,手动操作显然是不现实的,因此我们需要通过编程的方式来实现对Excel数据的导入和解析。
二、Excel导入解析的基本原理1. 导入Excel数据Java语言提供了丰富的类库,其中包括了用于解析Excel文件的类库。
我们可以使用Apache POI或JExcel等类库来实现对Excel 文件的读取和导入。
通过这些类库,我们可以将Excel文件中的数据读取到Java程序中,从而实现数据的导入。
2. 解析Excel数据导入Excel数据后,我们需要对数据进行解析,以便进行后续的处理。
通常情况下,Excel文件中的数据是以表格的形式存储的,我们可以通过遍历表格的行和列来获取数据。
在遍历过程中,我们可以根据需要对数据进行处理,比如筛选特定条件下的数据、计算数据的统计信息等。
三、Excel导入解析的具体实现步骤1. 引入类库在开始编写Java程序之前,我们需要先引入相关的类库。
以Apache POI为例,我们可以通过Maven等方式将其引入到项目中。
2. 创建工作簿在导入Excel文件之前,我们需要先创建一个工作簿对象,用于表示Excel文件。
可以通过WorkbookFactory类的静态方法来创建工作簿对象。
例如:```javaWorkbook workbook = WorkbookFactory.create(new File("data.xlsx"));```3. 获取工作表工作簿中包含了多个工作表,我们需要根据需要选择特定的工作表进行操作。
java操作txt或xls文件批量导入数据

// db.insertDB(FltNum); // } } @SuppressWarnings("static-access") public String[] generateSql(String userName) throws IOException{ StringBuffer sbf = new StringBuffer(); String[] str = new String[2]; String uuid = UUIDUtil.getUUID(); sbf.append("insert into user values('"+uuid+"','" + userName +"','"+default_password+"',"+Constants.ENABLED+","+Constants.NUllDELETE+","+Constants.AUDITING+",'"+uuid+" @','"+formatDateTime()+"',"+Constants.REGEDIT_USER+");/n"); sbf.append("insert into users values('"+uuid+"',"+ null+","+Constants.MALE+","+null+","+null+",'60.176.36.250','"+formatDateTime()+"',"+null+","+null+","+null+","+null+" ,"+null+","+null+",0,"+null+","+null+",0,0,0,'"+formatDateTime()+"','1036',0,"+null+","+null+","+null+","+null+","+null+",'1 1',"+null+","+null+","+null+","+null+","+null+");/n"); sbf.append("insert into user_user_group values('"+uuid+"','"+ uuid +"','"+Constants.PERSONAL_USER+"');/n"); UUID = uuid; str[0]=sbf.toString(); str[1]=UUID; return str; } public String formatDateTime(){ Date date = new Date(); /** * 时间格式化 2009-12-31 09:04:31 */ SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); System.out.println(sdf.format(date)); return sdf.format(date); } private String tranStr(String oldstr) { String newstr = ""; try { newstr = new String(oldstr.getBytes("ISO-8859-1"), "utf-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return newstr; } public static boolean isNumeric(String str){ Pattern pattern = pile("[0-9]*"); return pattern.matcher(str).matches(); } public static boolean isTwoCharacter(String str){
基于java对doc文档的分词,导入数据库

基于java对doc⽂档的分词,导⼊数据库这篇word⽂档都是正规的⽂本⽂字,有⼀定的格式,其中没有图⽚等难以处理的内容我也是刚学习对word⽂档的处理,其中也有很对不懂的地⽅Apache POI是的开放源码函式库,POI提供API给Java程序对Microsoft Office格式档案读和写的功能。
1、⾸先我下载了poi的包 /download.html ⽹址2、然后就是利⽤函数对⽂档的处理读取doc⽂档public static String contextOfDoc(File file) {String str = "";try {FileInputStream fis = new FileInputStream(file);HWPFDocument doc = new HWPFDocument(fis);str = doc.getDocumentText();doc.close();fis.close();} catch (Exception e) {e.printStackTrace();// TODO: handle exception}return str;}测试public static void main(String[] args) {File file = new File("src/1.doc");String str = contextOfDoc(file);String[] arr = str.split("\r");for (int i = 9; i < 284; i++) {System.out.println(arr[i]);}}先切分⽂档,分为⽬录和内容public static String[] cataAndContext() {File file = new File("src/1.doc");String textAll = docIo.contextOfDoc(file);String[] str = textAll.split("第五篇");return str;}对⽬录和内容分别切分public static List<String> typePart(String str) {//File file = new File("src/1.doc");//all//String textAll = docIo.contextOfDoc(file);String[] partOne = str.split("新技术篇");//第⼀篇到⽬录String partOneCatalog = partOne[1].split("⽹络安全篇")[0];String partNest = partOne[1].split("⽹络安全篇")[1];//第⼆篇⽬录String partTowCatalog = partNest.split("基础篇")[0];partNest = partNest.split("基础篇")[1];//第三篇⽬录String partThreeCatalog = partNest.split("国家信息化政策规划篇")[0];partNest = partNest.split("国家信息化政策规划篇")[1];//第四篇⽬录String partForeCatalog = partNest.split("附录")[0];List<String> strList = new ArrayList<>();strList.add(partOneCatalog);strList.add(partTowCatalog);strList.add(partThreeCatalog);strList.add(partForeCatalog);return strList;}对内容的处理public static void main(String[] args) throws Exception {FileInputStream fis = new FileInputStream("src/3.doc");WordExtractor wordExtractor = new WordExtractor(fis);String[] paragraphs = wordExtractor.getParagraphText();List<String> lists = getParas(paragraphs);CRUD c = new CRUD();List<String> catas = c.getCatalogs();for (int i = 0; i < catas.size()-1; i++) {String context = getContext(catas.get(i), catas.get(i+1), lists);c.insertContext(catas.get(i), context);}}public static String getContext(String start,String end,List<String> paras) { String context = "";for (int i = 0; i < paras.size(); i++) {if (paras.get(i).equals(start)) {for (int j = i+1; j < paras.size(); j++) {if(paras.get(j).equals(end)) {return context;}context = context + paras.get(j);}}}return context;}public static List<String> getParas(String[] paras) {List<String> paraList = new ArrayList<>();for (int i = 289; i < paras.length; i++) {paraList.add(paras[i].trim());}return paraList;}数据库的crudpublic List<String> getCatalogs(){List<String> lists = new ArrayList<>();Connection connection = Dbuitl.getConnection();String sql = "select catalog from catalogs";PreparedStatement preparedStatement = null;ResultSet resultSet = null;try {Statement statement = connection.createStatement();resultSet = statement.executeQuery(sql);while (resultSet.next()) {lists.add(resultSet.getString("catalog"));}} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {Dbuitl.close(preparedStatement);Dbuitl.close(connection);}return lists;}public void insert(String type,String cata) {Connection connection = Dbuitl.getConnection();String sql = "insert into catalogs(type,catalog) value(?,?)";PreparedStatement preparedStatement = null;ResultSet resultSet = null;try {preparedStatement = connection.prepareStatement(sql);preparedStatement.setString(1, type);preparedStatement.setString(2, cata);preparedStatement.executeUpdate();} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {Dbuitl.close(preparedStatement);Dbuitl.close(connection);}}public void insertContext(String catalog,String context) {Connection connection = Dbuitl.getConnection();String sql = "insert into context(catalog,context) value(?,?)"; PreparedStatement preparedStatement = null;ResultSet resultSet = null;try {preparedStatement = connection.prepareStatement(sql); preparedStatement.setString(1, catalog);preparedStatement.setString(2, context);preparedStatement.executeUpdate();} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {Dbuitl.close(preparedStatement);Dbuitl.close(connection);}}public void insertSheet(String sheet,String type) {Connection connection = Dbuitl.getConnection();String sql = "insert into sheet(sheet,type) value(?,?)";PreparedStatement preparedStatement = null;ResultSet resultSet = null;try {preparedStatement = connection.prepareStatement(sql); preparedStatement.setString(1, sheet);preparedStatement.setString(2, type);preparedStatement.executeUpdate();} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {Dbuitl.close(preparedStatement);Dbuitl.close(connection);}}。
Java实现批量导入excel表格数据到数据库中的方法

Java实现批量导⼊excel表格数据到数据库中的⽅法本⽂实例讲述了Java实现批量导⼊excel表格数据到数据库中的⽅法。
分享给⼤家供⼤家参考,具体如下:1、创建导⼊抽象类package mon.excel;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.PrintStream;import java.sql.SQLException;import java.util.ArrayList;import java.util.List;import org.apache.poi.hssf.eventusermodel.EventWorkbookBuilder.SheetRecordCollectingListener;import org.apache.poi.hssf.eventusermodel.FormatTrackingHSSFListener;import org.apache.poi.hssf.eventusermodel.HSSFEventFactory;import org.apache.poi.hssf.eventusermodel.HSSFListener;import org.apache.poi.hssf.eventusermodel.HSSFRequest;import org.apache.poi.hssf.eventusermodel.MissingRecordAwareHSSFListener;import stCellOfRowDummyRecord;import org.apache.poi.hssf.eventusermodel.dummyrecord.MissingCellDummyRecord;import org.apache.poi.hssf.model.HSSFFormulaParser;import org.apache.poi.hssf.record.BOFRecord;import org.apache.poi.hssf.record.BlankRecord;import org.apache.poi.hssf.record.BoolErrRecord;import org.apache.poi.hssf.record.BoundSheetRecord;import org.apache.poi.hssf.record.FormulaRecord;import belRecord;import belSSTRecord;import org.apache.poi.hssf.record.NoteRecord;import org.apache.poi.hssf.record.NumberRecord;import org.apache.poi.hssf.record.RKRecord;import org.apache.poi.hssf.record.Record;import org.apache.poi.hssf.record.SSTRecord;import org.apache.poi.hssf.record.StringRecord;import ermodel.HSSFWorkbook;import org.apache.poi.poifs.filesystem.POIFSFileSystem;/*** 导⼊抽象类* Created by charlin on 2017/9/7.*/public abstract class HxlsAbstract implements HSSFListener {private int minColumns;private POIFSFileSystem fs;private PrintStream output;private int lastRowNumber;private int lastColumnNumber;/** Should we output the formula, or the value it has? */private boolean outputFormulaValues = true;/** For parsing Formulas */private SheetRecordCollectingListener workbookBuildingListener;private HSSFWorkbook stubWorkbook;// Records we pick up as we processprivate SSTRecord sstRecord;private FormatTrackingHSSFListener formatListener;/** So we known which sheet we're on */private int sheetIndex = -1;private BoundSheetRecord[] orderedBSRs;@SuppressWarnings("unchecked")private ArrayList boundSheetRecords = new ArrayList();// For handling formulas with string resultsprivate int nextRow;private int nextColumn;private boolean outputNextStringRecord;private int curRow;private List<String> rowlist;@SuppressWarnings( "unused")private String sheetName;public HxlsAbstract(POIFSFileSystem fs)throws SQLException {this.fs = fs;this.output = System.out;this.minColumns = -1;this.curRow = 0;this.rowlist = new ArrayList<String>();}public HxlsAbstract(String filename) throws IOException,FileNotFoundException, SQLException {this(new POIFSFileSystem(new FileInputStream(filename)));}//excel记录⾏操作⽅法,以⾏索引和⾏元素列表为参数,对⼀⾏元素进⾏操作,元素为String类型// public abstract void optRows(int curRow, List<String> rowlist) throws SQLException ;//excel记录⾏操作⽅法,以sheet索引,⾏索引和⾏元素列表为参数,对sheet的⼀⾏元素进⾏操作,元素为String类型 public abstract void optRows(int sheetIndex,int curRow, List<String> rowlist) throws Exception;/*** 遍历 excel ⽂件*/public void process() throws IOException {MissingRecordAwareHSSFListener listener = new MissingRecordAwareHSSFListener(this);formatListener = new FormatTrackingHSSFListener(listener);HSSFEventFactory factory = new HSSFEventFactory();HSSFRequest request = new HSSFRequest();if (outputFormulaValues) {request.addListenerForAllRecords(formatListener);} else {workbookBuildingListener = new SheetRecordCollectingListener(formatListener);request.addListenerForAllRecords(workbookBuildingListener);}factory.processWorkbookEvents(request, fs);}/*** HSSFListener 监听⽅法,处理 Record*/@SuppressWarnings("unchecked")public void processRecord(Record record) {int thisRow = -1;int thisColumn = -1;String thisStr = null;String value = null;switch (record.getSid()) {case BoundSheetRecord.sid:boundSheetRecords.add(record);break;case BOFRecord.sid:BOFRecord br = (BOFRecord) record;//进⼊sheetif (br.getType() == BOFRecord.TYPE_WORKSHEET) {// Create sub workbook if requiredif (workbookBuildingListener != null && stubWorkbook == null) {stubWorkbook = workbookBuildingListener.getStubHSSFWorkbook();}// Works by ordering the BSRs by the location of// their BOFRecords, and then knowing that we// process BOFRecords in byte offset ordersheetIndex++;if (orderedBSRs == null) {orderedBSRs = BoundSheetRecord.orderByBofPosition(boundSheetRecords);}sheetName = orderedBSRs[sheetIndex].getSheetname();}break;case SSTRecord.sid:sstRecord = (SSTRecord) record;break;case BlankRecord.sid:BlankRecord brec = (BlankRecord) record;thisRow = brec.getRow();thisColumn = brec.getColumn();thisStr = "";break;case BoolErrRecord.sid:BoolErrRecord berec = (BoolErrRecord) record;thisRow = berec.getRow();thisColumn = berec.getColumn();thisStr = "";break;case FormulaRecord.sid:FormulaRecord frec = (FormulaRecord) record;thisRow = frec.getRow();thisColumn = frec.getColumn();if (outputFormulaValues) {if (Double.isNaN(frec.getValue())) {// Formula result is a string// This is stored in the next recordoutputNextStringRecord = true;nextRow = frec.getRow();nextColumn = frec.getColumn();} else {thisStr = formatListener.formatNumberDateCell(frec);}} else {thisStr = '"' + HSSFFormulaParser.toFormulaString(stubWorkbook, frec.getParsedExpression()) + '"';}break;case StringRecord.sid:if (outputNextStringRecord) {// String for formulaStringRecord srec = (StringRecord) record;thisStr = srec.getString();thisRow = nextRow;thisColumn = nextColumn;outputNextStringRecord = false;}break;case LabelRecord.sid:LabelRecord lrec = (LabelRecord) record;curRow = thisRow = lrec.getRow();thisColumn = lrec.getColumn();value = lrec.getValue().trim();value = value.equals("")?" ":value;this.rowlist.add(thisColumn, value);break;case LabelSSTRecord.sid:LabelSSTRecord lsrec = (LabelSSTRecord) record;curRow = thisRow = lsrec.getRow();thisColumn = lsrec.getColumn();if (sstRecord == null) {rowlist.add(thisColumn, " ");} else {value = sstRecord.getString(lsrec.getSSTIndex()).toString().trim();value = value.equals("")?" ":value;rowlist.add(thisColumn,value);}break;case NoteRecord.sid:NoteRecord nrec = (NoteRecord) record;thisRow = nrec.getRow();thisColumn = nrec.getColumn();// TODO: Find object to match nrec.getShapeId()thisStr = '"' + "(TODO)" + '"';break;case NumberRecord.sid:NumberRecord numrec = (NumberRecord) record;curRow = thisRow = numrec.getRow();thisColumn = numrec.getColumn();value = formatListener.formatNumberDateCell(numrec).trim();value = value.equals("")?" ":value;// Formatrowlist.add(thisColumn, value);break;case RKRecord.sid:RKRecord rkrec = (RKRecord) record;thisRow = rkrec.getRow();thisColumn = rkrec.getColumn();thisStr = '"' + "(TODO)" + '"';break;default:break;}// 遇到新⾏的操作if (thisRow != -1 && thisRow != lastRowNumber) {lastColumnNumber = -1;}// 空值的操作if (record instanceof MissingCellDummyRecord) {MissingCellDummyRecord mc = (MissingCellDummyRecord) record;curRow = thisRow = mc.getRow();thisColumn = mc.getColumn();rowlist.add(thisColumn," ");}// 如果遇到能打印的东西,在这⾥打印if (thisStr != null) {if (thisColumn > 0) {output.print(',');}output.print(thisStr);}// 更新⾏和列的值if (thisRow > -1)lastRowNumber = thisRow;if (thisColumn > -1)lastColumnNumber = thisColumn;// ⾏结束时的操作if (record instanceof LastCellOfRowDummyRecord) {if (minColumns > 0) {// 列值重新置空if (lastColumnNumber == -1) {lastColumnNumber = 0;}}// ⾏结束时,调⽤ optRows() ⽅法lastColumnNumber = -1;try {optRows(sheetIndex,curRow, rowlist);} catch (Exception e) {e.printStackTrace();}rowlist.clear();}}}2、创建导⼊接⼝package mon.excel;import java.util.List;public interface HxlsOptRowsInterface {public static final String SUCCESS="success";/*** 处理excel⽂件每⾏数据⽅法* @param sheetIndex* @param curRow* @param rowlist* @return success:成功,否则为失败原因* @throws Exception*/public String optRows(int sheetIndex, int curRow, List<String> rowlist) throws Exception; }3、创建实现类,在这个⽅法实现把导⼊的数据添加到数据库中package mon.excel;import java.util.List;public class HxlsInterfaceImpl implements HxlsOptRowsInterface {@Overridepublic String optRows(int sheetIndex, int curRow, List<String> datalist)throws Exception {//在这⾥执⾏数据的插⼊//System.out.println(rowlist);//saveData(datalist);return "";}}4、导⼊⼯具实现package mon.excel;import java.io.FileNotFoundException;import java.io.IOException;import java.sql.SQLException;import java.util.ArrayList;import java.util.List;/*** excel导⼊⼯具* Created by charlin on 2017/9/7.*/public class ExcelImportUtil extends HxlsAbstract{//数据处理beanprivate HxlsOptRowsInterface hxlsOptRowsInterface;//处理数据总数private int optRows_sum = 0;//处理数据成功数量private int optRows_success = 0;//处理数据失败数量private int optRows_failure = 0;//excel表格每列标题private List<String> rowtitle ;//失败数据private List<List<String>> failrows;//失败原因private List<String> failmsgs ;//要处理数据所在的sheet索引,从0开始private int sheetIndex;public ExcelImportUtil(String filename, int sheetIndex, HxlsOptRowsInterface hxlsOptRowsInterface) throws IOException, FileNotFoundException, SQLException {super(filename);this.sheetIndex = sheetIndex;this.hxlsOptRowsInterface = hxlsOptRowsInterface;this.rowtitle = new ArrayList<String>();this.failrows = new ArrayList<List<String>>();this.failmsgs = new ArrayList<String>();}@Overridepublic void optRows(int sheetIndex,int curRow, List<String> rowlist) throws Exception {/*for (int i = 0 ;i< rowlist.size();i++){System.out.print("'"+rowlist.get(i)+"',");}System.out.println();*///将rowlist的长度补齐和标题⼀致int k=rowtitle.size()-rowlist.size();for(int i=0;i<k;i++){rowlist.add(null);}if(sheetIndex == this.sheetIndex){optRows_sum++;if(curRow == 0){//记录标题rowtitle.addAll(rowlist);}else{String result = hxlsOptRowsInterface.optRows(sheetIndex, curRow, rowlist);if(!result.equals(hxlsOptRowsInterface.SUCCESS)){optRows_failure++;//失败数据failrows.add(new ArrayList<String>(rowlist));failmsgs.add(result);}else{optRows_success++;}}}}public long getOptRows_sum() {return optRows_sum;}public void setOptRows_sum(int optRows_sum) {this.optRows_sum = optRows_sum;}public long getOptRows_success() {return optRows_success;}public void setOptRows_success(int optRows_success) {this.optRows_success = optRows_success;}public long getOptRows_failure() {return optRows_failure;}public void setOptRows_failure(int optRows_failure) {this.optRows_failure = optRows_failure;}public List<String> getRowtitle() {return rowtitle;}public List<List<String>> getFailrows() {return failrows;}public List<String> getFailmsgs() {return failmsgs;}public void setFailmsgs(List<String> failmsgs) {this.failmsgs = failmsgs;}}5、导⼊实现⽅法:public static void main(String[] args){ExcelImportUtil importUtil;try {importUtil = new ExcelImportUtil("d:/data.xls",0, new HxlsInterfaceImpl());importUtil.process();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}}更多关于java相关内容感兴趣的读者可查看本站专题:《》、《》、《》、《》及《》希望本⽂所述对⼤家java程序设计有所帮助。
java项目实现数据导入方法

java项目实现数据导入方法数据导入是在Java项目中常见的任务之一。
在实际开发中,我们经常需要将外部数据导入到我们的项目中,以便进行进一步的处理和分析。
本文将介绍一种常用的数据导入方法,帮助读者了解如何在Java项目中实现数据导入。
我们需要明确导入的数据来源。
数据可以来自各种不同的地方,例如本地文件、数据库、Web服务等。
在本文中,我们将以本地文件作为数据来源进行讲解。
1. 读取本地文件在Java中,我们可以使用java.io包中的File类来读取本地文件。
通过创建一个File对象,并指定文件的路径,我们就可以获取到文件的相关信息。
例如:```javaFile file = new File("C:/data.txt");```这段代码将创建一个File对象,表示位于C盘根目录下的data.txt文件。
2. 解析文件数据一旦我们获取到了文件对象,下一步就是解析文件中的数据。
数据的格式可能是各种各样的,例如文本文件、CSV文件、JSON文件等。
针对不同的格式,我们可以使用不同的方法来解析数据。
例如,如果文件是一个文本文件,我们可以使用Java的IO流来逐行读取文件内容,并进行相应的处理。
代码示例:```javatry (BufferedReader br = new BufferedReader(new FileReader(file))) {String line;while ((line = br.readLine()) != null) {// 对每一行数据进行处理// ...}} catch (IOException e) {e.printStackTrace();}```上述代码使用了Java 7中引入的try-with-resources语法,可以自动关闭资源,非常方便。
3. 数据处理与存储在解析文件数据时,我们可以根据具体需求对数据进行相应的处理。
例如,可以将数据存储到数据库中,或者将数据转换为Java对象进行进一步的操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
package util;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* 批量导入数据库
* @author Administrator
*
*/
public class InsertDB {
public Connection getConnection() {
Connection conn = null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection(
"jdbc:oracle:thin:@****:**:**", "**",
"**");
} catch (Exception e) {
e.printStackTrace();
}
return conn;
}
public static void main(String[] args) {
InsertDB rt = new InsertDB();
rt.AhPhoneInsert("C:\\Documents and Settings\\Administrator\\桌面\\C.txt");// 参数为你的txt文件路径
}
//数据记录导入
public boolean AhPhoneInsert(String file){
try {
Connection con = getConnection();
PreparedStatement ps = null,ps1=null,ps2=null;
ResultSet rs = null;
BufferedReader br = new BufferedReader(
(new InputStreamReader(new FileInputStream(new File(file)),
"utf-8")));// 编码方式为utf-8,txt保存时编码方式也要选择为utf-8
String line;
try {
String sql ="insert into C values(?)";
try {
con.setAutoCommit(false);
ps = con.prepareStatement(sql);
int n=0;
while ((line = br.readLine()) != null) {
String phone = line.trim();
ps.setString(1, phone);
ps.addBatch();
n++;
if(n>1000){
ps.executeBatch();
n=0;
}
}
ps.executeBatch();
mit();
} catch (SQLException e) {
e.printStackTrace();
}finally{
if(null!=rs){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=ps){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=ps2){
try {
ps2.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=ps1){
try {
ps1.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=con){
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return true;
}
}。