sas 程序应用总结
SAS总结

SAS主要内容提取SAS系统中的如下三种方法可以达到同样的目的:INSIGHT(“交互式数据分析”)Analyst(“分析家”)直接编程。
Explorer :资源管理SAS的逻辑库分为临时库和永久库两种。
临时库只有一个,名为Work,存放在Work中的SAS文件叫临时文件,这些临时文件当退出SAS系统时会被自动删除。
SAS文件是指储存在SAS逻辑库中的成员,SAS的用户文件的主要类型有:SAS数据集SAS程序SAS逻辑库名最多用8个字符;数据集和变量的名字最多用32个字符。
3. SAS数据集包括两部分1、描述部分包括:Name(变量名)、Type(类型)、Length(长度)、Format(输出格式)、Informat(输入格式)、Label(标签)。
2,数据部分操作部分:数据集的导入1) 在SAS应用工作空间中,选择菜单“File”→“Import Data…”,打开导入向导“Import Wizard”第一步:选择导入类型(Select import type)。
2) 在第二步的“Select file”对话框中,单击“Browse”按钮,在“打开”对话框中选择所需要的Excel文件,返回。
然后,单击“Option”按钮,选择所需的工作表。
3) 在第三步的“Select library and member”对话框中,选择导入数据集所存放的逻辑库以及数据集的名称。
4) 在第四步的“Create SAS Statements”对话框中,可以选择将系统生成的程序代码存放的位置,完成导入过程。
在insight中为了区分变量在分析中的不同作用,又按变量的测量水平分为两类:1、区间型变量(interval variable):区间型变量必须是数值型变量,可以对其观测值进行四则运算,计算各种统计量;2、列名型变量(nominal variable):列名型变量可以是数值型的,也可以是字符型的,在INSIGHT中常起分类作用。
SAS软件应用的几点经验

1997年第3期 统计与信息论坛 1997年9月25日SA S软件应用的几点经验朱 钰摘 要 文章参考了一些统计著作,并结合笔者的实际应用心得,就SA S统计软件的应用谈了自己的看法。
关键词 SA S软件 比例风险回归 方差分析 广义逆矩阵 误差 平方和在统计发展的过程中,统计计算经历了不同的阶段,由单独的手工计算到使用各种各样的计算器作为辅助计算手段的阶段,再到现在以计算机为主要手段的统计计算阶段。
在统计计算发展的不同阶段中,统计计算与统计方法的关系也各有不同。
在手工统计计算阶段,统计计算直接与统计方法相联系,不懂统计方法便无法实现统计运算;在使用各种各样的计算器(无论是机械的还是电子的)的阶段,这些计算手段的作用只是加快了计算的速度,统计计算与统计方法之间的关系并没有受到影响;在以作为计算手段的现阶段,统计计算与统计方法之间的关系产生了巨大的变化。
这种变化源于统计软件包的发明和使用。
统计软件包是将各种统计计算过程所编成的便于使用的程序。
有些程序太简单、太方便了,以至操作者不需要理解统计方法也可以完成统计计算。
这就带来了统计方法以及相应的统计计算结果被误用及滥用的危险性。
消除这种危险性的一种途径就是对各种统计软件包的深入了解与掌握,也就是说,关于统计软件包的学习与研究,应该是当前统计方法的使用者普遍重视的问题,应该把对已有的普遍应用的统计软件的应用研究看作和统计方法的学习同样的重要。
目前,国内关于国际流行的统计软件的介绍往往有过于简略的倾向。
这种倾向对于上述的危险性起着不良的作用。
对于统计软件的使用,首先应该熟读该软件的使用说明或手册,弄清楚该软件的编写特点,以及在处理具体的问题时该软件采用的是哪一家的理论,然后才能运行该软件,并对输出结果进行分析。
在对一个软件多次使用之后,逐渐找出该软件的弱点,并采取相应的补救办法,达到对该软件灵活使用或高级运用。
以下拟就本人使用SA S统计软件的几点经验,以实际应用较多的方差分析方法为主对以上观点略作说明。
sas实践总结与体会

sas实践总结与体会SAS是一套用于数据分析与管理的软件,在各种企业、机构和学术界中广泛应用。
在实践中,我结合自己的经验,总结出了一些关于SAS使用的体会和总结,旨在帮助初次接触SAS的人士更好地理解并使用这一软件。
一、前期准备在运用SAS进行数据分析之前,需要进行一些基本的前期准备工作,包括建立可用的数据源并进行数据清洗、理解SAS语法并掌握SAS程序的编写与操作。
此外,还需要考虑项目的目标和数据分析的需求,并为此做出准备。
建立可用的数据源并进行数据清洗是一项至关重要的工作,如果数据不准确或存在缺失,则结果无法保证准确。
在数据清洗中,需要关注数据的格式、缺失值、异常值和重复等问题,并根据数据类型、范围和特征采取相应的清洗方法和策略。
理解SAS语法并掌握SAS程序的编写与操作是使用SAS的基础,要成功进行数据分析需要熟练运用SAS语言和工具。
需要熟悉SAS的各种操作和函数,掌握数据预处理、数据转换和模型建立等基本操作,以及熟悉宏、数组、循序操作和条件判断等高级编程技术。
二、数据预处理在进行数据分析之前,需要对数据进行预处理。
数据预处理是数据分析的第一步,可以清除无用信息,减小数据文件的体积,提高数据的质量,更好地适应数据分析需求。
常见的预处理方法包括数据缩放、数据标准化、缺失值处理和重采样等方法。
数据缩放是一种常见的数据预处理方法,用于将数据归一化到相同的尺度上,消除变量之间的量纲差异,方便后续的数据分析。
数据缩放的方法包括最小-最大缩放、标准化缩放和对数变换等方法,根据数据的特点和分析目标选择不同的方法进行缩放。
缺失值处理是另一种常用的预处理方法,用于处理数据中存在的缺失值。
常见的缺失值处理方法包括删除法、替换法、插补法和基于模型的方法,根据数据的特点和缺失值的特征选择相应的缺失值处理方法。
需要注意的是,缺失值处理可能会影响结果的准确性,因此需要在处理缺失值之前对数据进行充分的分析和理解。
三、模型建立在数据预处理之后,需要根据分析目的和数据特征选择适当的模型进行建立。
(完整版)SAS程序汇总

目录SAS基础 (2)创建数据集 (2)其他软件产生的标准格式文件与SAS数据集之间的互相转换。
(2)从外部文件(文本文件)读取数据 (2)排序 (4)计算产生新变量 (4)数据集的拆分 (4)数据集的合并 (5)纵向连接 (5)横向合并 (5)计量资料的描述 (6)计算几何均数 (6)制作频数表 (6)单变量描述 (7)多变量描述 (8)两样本均数的比较 (9)单一总体均数的可信区间 (9)两总体均数相差的可信区间 (9)单样本均数的t检验 (10)原始数据已知-ttest (10)原始数据未知 (10)配对资料两样本均数比较的t检验 (11)MEANS (12)UNIVARIATE (12)TTest (12)成组资料两样本均数比较的t检验 (13)两样本均数的等效性检验 (13)完全随机设计资料的方差分析 (14)相关 (15)绘制散点图 (15)绘制分层散点图 (17)Pearson相关系数及其置信区间的计算 (17)Spearman相关系数的计算 (18)简单线性回归 (18)简单线性回归方程的估计及假设检验 (18)绘制回归直线置信带、预测带 (19)根据输出的残差数据绘制残差图 (19)多变量回归分析 (20)卡方检验 (21)独立四格表资料的卡方检验 (21)配对四格表资料率的比较的卡方检验 (22)R*C表资料的卡方检验 (23)关联性分析 (24)基于秩次的非参数检验 (25)配对样本的符号秩和检验 (25)单样本的符号秩和检验 (25)两独立样本的秩和检验 (26)多组独立样本的秩和检验 (28)随机区组样本的秩和检验 (28)Logistic回归与生存分析 (29)Logistic回归 (29)二分类Logistic回归 (29)有序LOGISTIC回归 (31)多分类LOGISTIC回归 (31)生存分析 (32)寿命表方法进行生存率的估计 (32)K-M法进行生存率的估计 (33)Cox回归 (34)SAS基础创建数据集其他软件产生的标准格式文件与SAS数据集之间的互相转换。
SAS编程法总结

1.3 SAS数据集整理
data chap1.example1_2; input ID $1-2 name $3-10 sex$11-12 +1 weight +1 height; cards; 01 姚籽萱 女 50.5 1.63 02 徐若黛 女 51 1.53 03 张 林 男 60 1.72 04 谢欣然 女 62 1.70 05 夏 天 女 54 1.67 06 刘子然 男 70 1.80 07 赵 赵 男 65 1.75 08 章 峰 男 84 1.68 ; run; /*以上程序新建了包含了表格的数据集 chap2.example1_2*/
普通卡 87/01/27 5 /*输入数据*/
1.3 SAS数据集整理
• 提交后,在Output输出记录窗口显示
• 同时,在新建的逻辑库chap1中,出现了 数据集example1_1
1.3 SAS数据集整理
注意: • 日期格式的变量在SAS中默认保存为从1960年1月 1日至某日期的天数,如1964年10月6日,默认输 出为1740。在打印输出日期格式的变量时,为了 得到特定格式,务必使用format语句指定输出格 式。 • 而SAS数据集中,可在Column Attributes,单击弹 出的对话框中的format后的 按钮,选择设臵变 量的输出格式。
1.3 SAS数据集整理
• 方法二:Viewtable 新建数据集
• 步骤一:打开新表 Tools|Table Editor • 步骤二:定义变量 Column Attributes • 步骤三:输入数据、保存数据集
1.3 SAS数据集整理
(2)在数据集中增加、筛选变量和观测 • 在DATA步中可以直接利用新建变量语句来产生新变量。
关于SAS软件应用小结

关于SAS软件应用小结SAS(STATISTICAL ANALYSIS SYSTEM)是由美国NORTH CAROLINA州立大学1966年开发的统计分析软件。
1976年SAS软件研究所(SAS INSTITUTE INC。
)成立,开始进行SAS系统的维护、开发、销售和培训工作。
期间经历了许多版本,并经过多年来的完善和发展,SAS系统在国际上已被誉为统计分析的标准软件,在各个领域得到广泛应用。
SAS (Statistical Analysis System)是一个模块化、集成化的大型应用软件系统。
它由数十个专用模块构成,功能包括数据访问、数据储存及管理、应用开发、图形处理、数据分析、报告编制、运筹学方法、计量经济学与预测等等。
SAS系统基本上可以分为四大部分:SAS数据库部分;SAS分析核心;SAS开发呈现工具;SAS对分布处理模式的支持极其数据仓库设计。
SAS系统主要完成以数据为中心的四大任务:数据访问;数据管理(sas 的数据管理功能并不很出色,而是数据分析能力强大所以常常用微软的产品管理数据,再导成sas数据格式.要注意与其他软件的配套使用);数据TechWeb旗下Intelligent Enterprise网站称SAS是商业分析领域的…优势公司‟中国北京,(2009年1月14日)-商业分析领域的全球领先公司SAS被评为2009年12家最具影响力的商业技术供应商之一,这已是SAS连续第8年获此殊荣。
SAS和其他获奖公司由于在实现战略目标方面的卓越远见、技术创新和客户向导而获得信息周刊技术网络(InformationWeek Business Technology Network)旗下“智能企业”(Intelligent Enterprise)网站的肯定。
候选公司名单由“智能企业”编辑部联合12名独立评委提出,最终获奖者由主编Doug Henschen决定。
他说:“我们连续10年评出Intelligent Enterprise编辑选择奖,以引导读者了解这些具有创新精神和影响力的供应商。
SAS程序汇总

SAS程序汇总SAS(Statistical Analysis System)是一种广泛使用的统计分析软件,具有强大的数据处理与分析能力。
以下是一份SAS程序汇总,包括数据读取、数据清洗、统计分析和报告生成等常用功能。
1.数据读取SAS可以读取多种数据格式,包括CSV、Excel、Access等。
下面是一个读取CSV格式文件的示例代码:```sasdata mydata;infile 'data.csv' dlm=',' firstobs=2;input id $ age height weight;run;```2.数据清洗在数据清洗过程中,可以删除重复值、处理缺失值、去除异常值等。
以下是一个处理缺失值和异常值的示例代码:```sasdata clean_data;set mydata;if missing(age) then age = mean(age); /* 处理缺失值 */if weight > 200 then delete; /* 去除异常值 */run;```3.统计分析SAS提供了丰富的统计分析功能,包括描述统计、方差分析、回归分析等。
以下是一个简单的描述统计分析的示例代码:```sasproc means data=clean_data mean std min max;var age height weight;run;```4.报告生成SAS可以生成各种类型的报告,包括表格、图表、统计分析结果等。
以下是一个生成简单表格和图表的示例代码:```sasods html file='report.html';proc print data=clean_data;title 'Cleaned Data Set';run;proc sgplot data=clean_data;scatter x=age y=weight;title 'Scatter Plot of Age and Weight';run;ods html close;```以上仅是一些常用的SAS程序示例,实际应用中可能需要根据具体需求进行调整和扩展。
sas的应用
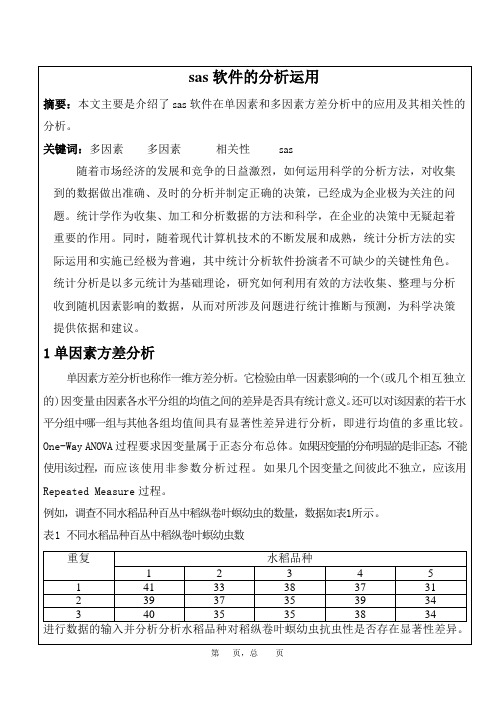
表1不同水稻品种百丛中稻纵卷叶螟幼虫数
重复
水稻品种
1
2
3
4
5
1
41
33
38
37
31
2
39
37
35
39
34
3
40
35
35
38
34
进行数据的输入并分析分析水稻品种对稻纵卷叶螟幼虫抗虫性是否存在显著性差异。
1)准备分析数据;2)启动分析过程;3)设置分析变量并比较。
Corrected Total 14 224.0000000
R-Square Coeff Var Root MSE c Mean
0.901786 3.189062 1.658312 52.00000
Source DF Type III SS Mean Square F Value Pr > F
b 4 72.0000000 18.0000000 6.55 0.0122
212
370
2605
8
192
330
2450
运用sas软件后,得分析结果:
由此可得回归方程:Y=3.45261+0.49600X1+0.00920X2。复相关系数的平方:R2=0.9989(R-Square)显著性:由复相关系数的值可以看出是高度显著的。
例如,从由五名操作者操作的三台机器每小时产量中分别各抽取1个不同时段的产量,观测到的产量如表2所示。试进行产量是否依赖于机器类型和操作者的方差分析。
表2三台机器五名操作者的产量数据
机器1
机器2
机器3
操作者1
53
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
PROPORTION (百分数)。
MIDPOINTS:指定各组组中值以确定各组组段。可以使用循环变量语法。 ENDPOINTS 指定各组组上限以确定各组组段。可以使用循环变量语法。当与 MIDPOINTS 同时指定时本选项起作用。
NORMAL:指定正态曲线估计和绘制。还可以指定子选项 MU=值SIGMA=值。默认 MU(均值),SIGMA(标准差)均为
样本估计值。其估计结果、正态性拟合优度和正态概率图的分位点会在输出窗输出。可以用子选项 NOPRINT 取消估
计结果的计算输出。
Ø CFILL 指定直方图的填充颜色。如 CFILL=BLUE。指定填充颜色为蓝色。 Ø PFILL 指定直方的填充模式。其值为 Pn。P 可以为 L、R、X、S 和 E 四个字母。当为 L、R 和 X 四个字母时,n 必
var
分析变量名列表;
freq 频数变量;
output out=输出数据集 统计量关键字=保存
变量名;
by 分组变量;
run; HISTOGRAM(条形图) 语句
HISTOGRAM 变量名表/ 绘图选择项;
VSCALE:指定垂直坐标轴的尺度。即指定直方的绘制单位。可以为 COUNT (频数),PERCENT (百分 ),PROP|
杨庆 重庆医科大学 09 级临床医学七年制一系
SAS 上机应用总结
计量单变量分析 一、计量单变量分析的内容
Ø 位置度量:用来描述定量资料的集中趋势。常用 的统计量有算术平均数(均数)、几何均数、中 位数、众数和分位数。 变异度量:用来描述定量资料的离散趋势。常用统计量有全距、四分位间距、方差、标
准差和 变异系数。分布度量 分布分析:用来描述分布接近正态分布的程度。 使用的指标有偏度系数(Skewness) 和峰度系数 (Kurtosis)。也常用直方图,盒式图,QQ 图等图示法。 对应 SAS 过程模块 Ø 在 SAS 系统中,主要常用的模块如下:MEANS 过程可以用于正态或者近似正态资料的位置度量和离散度量统计量 计算 UNIVARIATE 过程是功能最全面的计量单变量统计描述模块,不仅可以计算位置度量和离散度量统计量而且可 以绘制分布图。 CHART 过程可以用于绘制直方图和输出频数表 FREQ 过程可以用于计算百分比、构成比和率。同时该模块也可以用于数据核查。 二、MEANS 过程 Ø 功能:用于正态或者近似正态资料的描述统计量计算 Ø 用途: 正态或者近似正态资料的描述统计量计算
须指定 1-5 间的 正整数。当为字母 S 和 E,n 则略去。如 PFILL=X1。
Ø GRID 指定绘制网格。HREF 指定绘制水平参考线。 VREF 指定绘制垂直参考线。
Ø NAME 指定在 SAS/GRAPH 系统中的 显示名称。
PROBPLOT 语句 Ø PROBPLOT 变量名表/绘图选择项;
1
杨庆 重庆医科大学 09 级临床医学七年制一系
FREQ 变量名; 当输入的数据为频数表资料时,需要使用 FREQ 语句。该变量类型必须为数值变量,其值表示对应观察例的频数 如
果该变量值为非正整数则计算时只取整数部分,若该值缺失或者小于 1 则相应的观测不参加计算。负数数据报错。
三、UNIVARIATE 过程
NORMAL 指定正态曲线估计和绘制。还可以指定子选项
MU=值,SIGMA=值。默认 MU(均值),SIGMA(标准差)均为样本估计值。其估计结果、正态性拟合优度和正态概率图
的分位点将在输出窗输出。可以用子选项 NOPRINT 取消估计结果 的计算输出。
Ø Means 过程通过使用统计量关键字来指定需要计算的项目。在默认情况下自动计算 N (例数),MEAN(均值), STDDEV|STD(标准差),MAX (最大值),MIN(最小值),CV(变异系数)。一旦指定计算统计量则取消默认的统计量计算 输出。 常用统计量 N (例数),MEAN(均值),STDDEV|STD(标准差),MAX (最大值),MIN(最小值),CV(变异系数),RANGE(全距),VAR(方 差),CSS(离均差平方和),USS(平方和),NMISS(非缺失例数),SUM(和),SUMWGT(权重和)。 分位数 MEDIAN|P50( 中 位数) Q3|P75(上四分位数) Q1|P25(下四分位数), QRANGE(四分位间距),P1,P5,P10,P90,P95,P99。 分布度量 SKEWNESS|SKEW(偏度系数) KURTOSIS|KURT(峰度系数)。 可信区间 STDERR(标准误),CLM(可信区间),LCLM(可信区间下限),UCLM(可信区间上限)。 样本均数与总体均数的 t 检验 T( t 统计量),PROBT(t 统计量的概率值) FREQ 语句 格式
Ø 计算均数的可信区间 Ø 样本均数与总体均数比较的 t 检验 Ø 粗步数据校验 Ø 基本格式: Proc means data=数据集选项; class 分组变量列表; var 分析变量列表; freq 频数变量; output out=输出数据集名 统计量关键字=保存变量名; run; VAR 语句 格式: VAR 变量名; 在 SAS 过程中使用 VAR 语句指定参与计算的 变量名 :VAR 语句中可以使用变量名列表的形式,通过使用变量名列表的形式,在一次过程调用中就能计算 多个变量的统计结果。 列表中的变量类型为数值类型 CLASS 语句 格式 CLASS 分组变量名; CLASS 语句指定分组变量名 该变量类型即可以是字符类型也可以是数值类型 通过指定分组变量名要求 SAS 分组计算统计量或者进行分组比较 变量名可以采用变量名列表的形式。Means 过程 统计量关键字和选项
Ø 功能:全面的单变量描述统计分析过程
Ø 用途 分布分析 ,绘制分布图形:茎叶图、直方图、箱式图、正态概率图等 分布检验:正态性检验,指数分布检验
数据分布观察:检查观测极端值、编制频数表 、集中趋势和离散趋势的统计量数计算、任意分位数计算、
稳健估计
格式 proc univariate data=数据集名选项;