arcgis实习之空间统计分析
arcgis空间研究分析实习报告

实习一:ArcGIS地统计分析指导老师:赵永一实习目地利用地统计分析模块,根据一个点要素层中已测定采样点、栅格层或者利用多边形质心,轻而易举地生成一个连续表面.这些采样点地值可以是海拔高度、地下水位地深度或者污染值浓度等.当与ArcMap一起使用时,学习利用地统计分析模块提供地一整套创建表面地工具来生成一个相对精确地连续表面,用这些表面来进行可视化、分析及理解各种空间现象等.b5E2R。
二实习内容1了解地统计分析模块,创建臭氧浓度缺省参数表面.2学习在创建表面之前如何对数据进行检查.数据检查地目地是为了找出数据中那些离群值并且发现数据中存在地趋势.p1Ean。
3创建第二个表面,这个表面更多地考虑了练习2中数据分析发现地空间关系,并且对练习1中生成地表面进行了改进.DXDiT。
4对练习1和练习3中创建地表面进行比较,并判断哪个表面对未知值地预测更好.5创建臭氧浓度超出临界值地概率图,从而生成第三个表面.6利用ArcMap地功能将你在练习3和练习5中创建地表面放在一起做最终地显示三实习步骤1 利用缺省参数创建一个臭氧表面(1)打开arcmap 并激活地统计分析模块(2)加载数据(3)利用缺省参数创建臭氧浓度表面.图1利用缺省值创建地臭氧表面2 检查数据(1)检查臭氧浓度数据分布是否符合正态分布,从下图可以看到臭氧浓度分布大致符合正态分布图2臭氧浓度分布直方图(2)正态QQ图.另外一种检验数据是否符合正态分布地方法,通过标准正态分布与现有数据分布比较,还可以找到一些异常值,来检查并校正这些异常值.若符合正态分布则数据点应成一条直线,那些不在直线上地点为异常点.RTCrp。
图3臭氧浓度正态QQ图(3)用趋势分析工具识别数据中地全局趋势.只有数据分布符合一定地趋势,才能用数学公式对确定表面进行模拟,故需要分析数据地全局趋势.5PCzV。
图4臭氧数据全局趋势(4)理解数据地空间自相关和方向效应.利用半变异函数/协方差函数云图,在半变异函数/协方差函数云图中,每个红点表示一对采样点.既然越近地点越相似,那么在半变异函数云图中邻近地点(在X轴地左边)应该有较小地半变异函数值(在Y轴地下部).随着样点对间距离地增加(在X轴上向右移动),变异函数值也要相应增加(在Y轴上向上移动).然而,当到达一定地距离后,云图变平,这表明超出这个距离时,样点对之间不再具有相关关系了.jLBHr。
实验三空间统计分析

实验三空间统计分析引言:空间统计分析是地理信息科学中的一项重要技术,以空间数据为基础,通过空间统计模型和方法,研究地理现象在空间上的分布、关联、聚集和异质性等特征。
本实验将通过实例介绍空间统计分析的具体方法和步骤。
一、空间统计分析的数据准备1.空间数据的获取:空间统计分析的第一步是获取相关的空间数据,可以通过地理信息系统(GIS)软件或其他渠道获取。
2.数据准备:对于获取的空间数据,需要进行数据准备,包括数据清洗、数据格式转换等。
二、空间统计分析的基础1.空间数据的可视化:通过GIS软件将获取的空间数据进行可视化,以便更好地理解其分布特点。
2.空间数据的描述统计分析:对于空间数据的描述统计分析,可以计算其平均值、方差、标准差等统计指标,以及构建直方图、箱线图等统计图表以展现数据的分布特征。
三、空间结构分析1.空间自相关分析:空间自相关分析用于检验地理现象是否具有空间相关性。
常用的空间自相关分析方法包括莫兰指数、凝聚统计量等。
2.空间插值分析:空间插值分析用于通过已有的空间数据,推断未来或未知地点的空间属性。
常用的空间插值方法包括反距离加权插值法、克里金插值法等。
四、空间聚集分析1.点模式分析:点模式分析用于研究地理现象在空间上的聚集性,主要包括随机模式、聚集模式和离散模式等。
2.空间卷积分析:空间卷积分析用于确定地理现象的空间关联程度,并计算其空间关联程度指标。
五、空间异质性分析1.空间变差函数分析:空间变差函数分析用于研究地理现象在空间上的异质性。
常用的空间变差函数包括半方差函数、泰森多边形等。
2.空间回归分析:空间回归分析用于研究空间数据之间的关系,常用的方法包括普通最小二乘法、地理加权回归等。
六、实例分析:空气质量的空间分布分析本实例以城市不同监测点的空气质量数据为例,利用空间统计分析方法研究空气质量的空间分布特征。
1.数据获取和准备:从相关机构获取该城市不同监测点的空气质量数据,并进行数据清洗和格式转换。
ArcGIS空间统计分析

• 热点分析用于识别要素分布
•
当Z得分或p值指示统计显著 性时,Z为正的位置表示高 值的聚类,Z为负的位置表
示低值的聚类。
演示:案件高发区分析
空间关系建模
空间权重矩阵
• 空间权重矩阵是要素间空间关系量化后的一种表现形式; • 空间权重矩阵中的关系值用于空间统计工具的统计量的计
算。
空间回归
• 回归分析是研究两个或两个以上的变量之间关系的一种
纽约州1969、1985、2002的人均年收入(县统计单元)空间分布
1969 1985 2002
5.21
4.26
2.4
穷人和富人在空间上是否更分离了?
6 5 4 3 2 1 0
1969 1979 1989 1999
贫富分离度下降
Z得分随时间下降
热点分析(Hot Spot Analysis)
•
使用 Getis-Ord Gi* 统计量 中具有统计上显著的高值( 热点)或低值(冷点)聚集 的位置。
-
聚集或分散
聚集或分散位置和程度
• 空间关系建模
-
空间回归
二、ArcGIS空间统计分析
ArcGIS空间统计分析模块
• • • • •
空间统计分析在GIS中的实现 ArcGIS的核心功能 无需购买额外的扩展 在所有许可环境下都可以使用 大部分工具都提供源代码
ArcGIS空间统计分析模块
分布特征 分析
Articles (keyword search: “Spatial Statistics”)
/news/arcuser/0405/ss_crimestats1of2.html
The ESRI Guide to GIS Analysis, Volume 2 by Andy Mitchell
ArcGIS的地统计分析、空间分析、三维数据分析实验报告

地理空间信息软件应用Geospatial information software applications大连理工大学城市学院实验一、三维数据分析实验目的:首先了解三维数据管理的的概念,对三维数据有一定的了解及认知后,学习对三维数据的管理、分析与应用,掌握三维数据分析运用要领。
实验内容:三维数据、三维数据的获取、3D要素分析;表面创建、表面管理;栅格表面分析、Terrain和TIN表面分析、功能性表面;ArcScene的工具条、二维数据的三维显示、三维动画。
实验过程:1.三维数据⑴三维数据是在二维数据的基础上添加了一个维度(Z坐标),用来表示特定表面位置的值。
三维数据有四种基本类型:三维点数据、三维线数据、表面数据和体数据。
在Arcgis中,把三维数据分为3D要素数据和表面数据。
⑵三维数据的获取:三维点、线数据的生成常见方法分为创建包含Z值的要素类,转换二维要素类的属性、插值shape三种;多面体数据的生成。
①三维点、线数据的生成-----创建包含Z值的要素类启动ArcCatalog,右击要创建三维要素的文件夹,在弹出的菜单栏中,选择“新建”----“Shapefile”,打开创建新Shapefile对话框。
在“名称”文本框中输入要素名称,在类型的下拉框选择面,单机编辑定义空间参考,选择WGS1984坐标系,点击确定。
图一创建三维空间坐标②三维点、线数据的生成-----转换二维要素类的属性在ArcScene中打开ArcToolbox,双击“3D Analyst工具”----“3D要素”----“依据属性实现要素转3D”,“打开依据属性实现要素转3D”对话框,输入要素设置为“point”,输出要素类设置为“point3d”,高度字段设置为“height”。
确定,得到三维点数据。
图二依据属性实现要素转3D③多面体数据的生成启动ArcScene,在右击文件夹,单机“新建”,选择“文件地理数据库”,创建“文件地理数据库”,命名为“New File Geodatabase”。
利用ARCGIS进行空间统计分析报告

§12. 使用ArcGIS进行空间统计分析一、软硬件环境软件:ArcGIS 8.0版本以上,需要具有Geostatistics模块的许可;硬件:目前主流配置即可。
二、软件及数据的准备本例以ArcGIS 9.0为软件平台,对甘肃省30年平均降水进行空间插值的。
(1)打开ArcGIS 9.0,并把Geostatistics模块加载上。
首先在工具>扩展中将相应模块选中,如图1。
图1其次,在工具条上点击右键,把Geostatistical Analyst选中,如图2。
图2(2)数据准备本例需要的是各个气象站点和观测数据,所以首先需要各个气象观测站的点图层,各个站点30年观测的平均降水量、蒸发量以及该站点的海拔高程作为属性数据,附在上述点图层上。
因为是对甘肃省省域内气候进行插值,因此还必须有甘肃省的省界。
并过数据加载按钮将上述数据加载上,如图3所示。
图3(3)分析数据框架设定在Layers上右击,点击属性,选择数据框架(Data Frame)面板,然后将甘肃省边界图层作为分析时显示的数据框架(即只显示省内区域)。
如图4:图4三、探索性空间数据分析(ESDA)空间插值的模型和方法有很多,通过探索性空间数据分析,目的是寻找数据内在的规律性,再根据这些规律寻找适合的空间插值模型;或者通过数据变换(例如常见的COX-BOX变换、对数变换),使原来不适合于插值的数据可以进行插值。
对于ESDA可以说是一门学问,这里简单介绍,Geostatistical Analyst所带的几种方法,如图5。
图51、直方图点击Histogram,然后在右下选择需要分析的属性,则就显示直方图分布情况,并在右上角给出各种相关的统计指标,图6。
图6在左下方的下拉框可以选择直方的数量,变换方法,软件提供了两种:LOG和Cox-Box。
2、正则QQ图(Normal QQPlot)图73、趋势分析(Trend Analysis)同样选择合适的属性,作为Z轴,空间坐标作为XY轴,则分析该属性的三维分布趋势,图8。
ARCGIS空间统计分析

ARCGIS空间统计分析空间统计分析是利用地理信息系统(GIS)技术对空间数据进行统计分析和空间模式分析的过程。
它可以帮助我们揭示地理现象的空间分布规律、探索地理现象之间的关联性,进而为决策提供依据。
而ARCGIS作为一款功能强大的GIS软件,为空间统计分析提供了丰富的工具和功能。
首先,在ARCGIS中进行空间统计分析,我们需要明确研究的问题和目标。
例如,我们可能想要了解一些地区人口分布的空间模式以及其与其他地理现象的关系。
在确定研究问题后,我们可以使用ARCGIS中的空间统计工具进行分析。
距离分析是一种常见的空间统计分析方法,用于度量地理要素之间的距离和接近程度。
ARCGIS中的距离工具可以计算地理要素之间的最短路径、最近邻等距离指标。
通过距离分析,我们可以了解地理现象之间的空间关系,比如其中一地区的商店分布离居民区的距离远近。
空间插值是一种用于推断未知地点值的方法,通过已知的点数据生成连续的表面。
ARCGIS中的空间插值工具可以根据已有的点数据生成等值线图、栅格图像,帮助我们了解地形、气象等现象的空间分布。
空间点模式分析是一种用于检测地理要素分布的随机性或非随机性的方法。
ARCGIS中的空间点模式工具可以通过计算统计指标(例如点密度、聚集程度等)来识别点数据的空间模式。
通过空间点模式分析,我们可以判断其中一现象的分布是随机还是具有一定的规律性。
空间回归分析是一种用于揭示地理现象之间关联关系的方法。
ARCGIS中的空间回归工具可以进行空间权重矩阵的构建、空间自相关分析等。
通过空间回归分析,我们可以确定其中一地理现象在空间上的影响范围,进一步理解地理现象之间的关系。
除了上述方法,ARCGIS还提供了许多其他的空间统计工具,如空间聚类、空间揭示等。
通过这些工具,我们可以进行更加深入全面的空间统计分析,为决策提供科学的依据。
总之,ARCGIS为空间统计分析提供了丰富的工具和功能,能够帮助我们揭示地理现象的空间分布规律、探索地理现象之间的关联性,为决策提供科学依据。
arcgis实习之空间统计分析报告
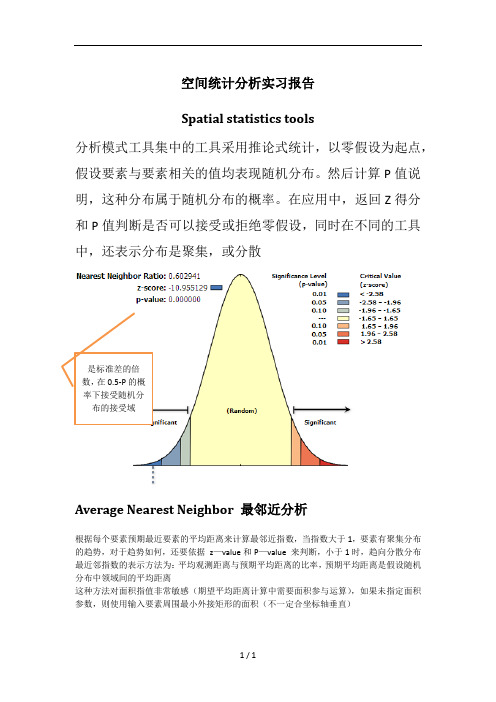
空间统计分析实习报告Spatial statistics tools分析模式工具集中的工具采用推论式统计,以零假设为起点,假设要素与要素相关的值均表现随机分布。
然后计算P值说明,这种分布属于随机分布的概率。
在应用中,返回Z得分和P值判断是否可以接受或拒绝零假设,同时在不同的工具中,还表示分布是聚集,或分散是标准差的倍数,在0.5-P的概率下接受随机分布的接受域Average Nearest Neighbor 最邻近分析根据每个要素预期最近要素的平均距离来计算最邻近指数,当指数大于1,要素有聚集分布的趋势,对于趋势如何,还要依据z—value和P—value 来判断,小于1时,趋向分散分布最近邻指数的表示方法为:平均观测距离与预期平均距离的比率,预期平均距离是假设随机分布中领域间的平均距离这种方法对面积指值非常敏感(期望平均距离计算中需要面积参与运算),如果未指定面积参数,则使用输入要素周围最小外接矩形的面积(不一定合坐标轴垂直)Spatial Autocorrelation (Morans I) 空间自相关分析更具要素位置的属性使用Global Moran’s I 统计量量测空间自相关性Moran’s I是计算所评估属性的均值和方差,然后将每个要素减去均值,得到与均值的偏差,将所有相邻要素的偏差相称,得到叉积。
统计量的分子便是这些叉积之和。
如果相邻要素的值均大于均值,这叉积为正,如果以要素小于均值而一要素大于均值,则为负如果数据集中的值倾向于在空间上集聚(高值聚集在高值附近,低值聚集在低值附近)则指数为正,如果高值排斥高值,倾向于低值,则指数为负之后,将计算期望指数值,将之与其比较,在给定的数据集中的要素个数和全部熟知的方差下,将计算Z得分和P值,用来指示次差异是否具有统计学上的显著性Multi-Distance Spatial Cluster Analysis K函数分析确定要素(后与之有关连的值)是否显示某一距离范围内统计意义显著的聚类或离散基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。
ArcGIS空间统计分析

• 因此,对于空间数据分析的目的来说,使用ArcGIS 9中的 空间统计工具比使用原来的不考虑空间信息而进行统计的 工具要更为合适。通过使用这些工具,GIS用户可以采用 一种更高级的方法来解决空间数据分析中的问题。
P(x) = e-λλx / x!
– 泊松公式可在Excel中很方便计算
模式分析工具集(Analyzing Patterns)
• 点模式分析试验——样方分析
– 8 基于泊松分布计算期望分布频率表
P(x) = e-λλx / x!
模式分析工具集(Analyzing Patterns)
• 点模式分析试验——样方分析
研究生课程
ArcGIS 空间统计分析实 习
杜世宏
北京大学遥感与GIS研究所
提纲
一、 ArcGIS 空间统计分析 二、模式分析工具集 三、聚类分布工具集 四、度量空间分布工具集 五、辅助工具集
ArcGIS 空间统计分析
• 空 间 统 计 主 要 的 工 作 是 研 究 空 间 自 相 关 性 ( Spatial Autocorrelation ) , 分 析 空 间 分 布 的 模 式 , 例 如 聚 类 (cluster)或离散(dispersed)。通过使用ArcGIS 9中的 空间统计工具,用户可以以一种非常直观而简单的方式获 得这些信息。
• 点模式分析试验——样方分析
– 1 加载Hawths_Analysis_Tools_for_ArcGIS9外挂模块 – 将Hawth‘s Tools加入ArcMap 中Tools-> Customize-
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
空间统计分析实习报告
Spatial statistics tools
分析模式工具集中的工具采用推论式统计,以零假设为起点,假设要素与要素相关的值均表现随机分布。
然后计算P 值说明,这种分布属于随机分布的概率。
在应用中,返回Z 得分和P值判断是否可以接受或拒绝零假设,同时在不同的工具中,还表示分布是聚集,或分散
是标准差的倍
数,在0.5-P的概
率下接受随机分
布的接受域
Average Nearest Neighbor 最邻近分析
根据每个要素预期最近要素的平均距离来计算最邻近指数,当指数大于1,要素有聚集分布的趋势,对于趋势如何,还要依据z—value和P—value 来判断,小于1时,趋向分散分布
最近邻指数的表示方法为:平均观测距离与预期平均距离的比率,预期平均距离是假设随机分布中领域间的平均距离
这种方法对面积指值非常敏感(期望平均距离计算中需要面积参与运算),如果未指定
面积参数,则使用输入要素周围最小外接矩形的面积(不一定合坐标轴垂直)Spatial Autocorrelation (Morans I) 空间自相关分析
更具要素位置的属性使用Global Moran’s I 统计量量测空间自相关性
Moran’s I是计算所评估属性的均值和方差,然后将每个要素减去均值,得到与均值的偏差,将所有相邻要素的偏差相称,得到叉积。
统计量的分子便是这些叉积之和。
如果相邻要素的值均大于均值,这叉积为正,如果以要素小于均值而一要素大于均值,则为负
如果数据集中的值倾向于在空间上集聚(高值聚集在高值附近,低值聚集在低值附近)则指数为正,如果高值排斥高值,倾向于低值,则指数为负
之后,将计算期望指数值,将之与其比较,在给定的数据集中的要素个数和全部熟知的方差下,将计算Z得分和P值,用来指示次差异是否具有统计学上的显著性
Multi-Distance Spatial Cluster Analysis K函数分析
确定要素(后与之有关连的值)是否显示某一距离范围内统计意义显著的聚类或离散
基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。
该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离范围内的空间相关性(要素聚类或要素扩散)
Ripley's K 函数可表明要素质心的空间聚类或空间扩散在邻域大小发生变化时是如何变化的。
如果特定距离的k观测值大于k预期值,则与该距离下的随机分布相比,该分布的聚集程度更高,反之亦可。
如果,k观测值大于HIConfEnv,则该距离的空间聚类具有统计学上的显著性,如果k观测值小于LwConFEnv,则该距离的空间离散具有统计学上的显著性对于置信区间,点的每个随机分布称为“排列”将一组点随机分布多次,将对每个距离选择相对预期k值向下和向上最大的k值,作为置信区间
Anselin Local Moran’s I局部Moran’s I 分析
给定一组加权要素,使用局部Moran’s I统计量来识别具有统计显著性的热点,冷点和空间异常值。
Z得分和p值是统计显著性的指标,用于逐个要素判断是否拒绝零假设。
他们可指示表面相似性和向异性
如果要素Z值是一个较高的正数,则表示周围的要素拥有相似值,输出要素Cotype字段会将具有统计显著性的高值聚类表示为HH,低值聚类表示为LL
•如果要素的z 得分是一个较低的负值,则表示有一个具有统计显著性的空间异常值。
输出要素类中的COType 字段将指明要素是否是高值要素而四周围绕的是低值要素(HL),或者要素是否是低值要素而四周围绕的是高值要素(LH)。
Getis-Ord General G 高低聚类分析
使用Getis-Ord General G统计可度量高值或低值的聚类程度
Z得分越高或越低,聚类程度就越高,如果z得分接近零,则表示不存在明显的聚类,为正
表示高值的聚类。
为负表示低值的聚类
Hot spot Analysis(Getis-Ord Gi*) 热点分析
如果给定一组加权要素,使用Getis-Ord Gi* 统计识别具有统计显著性的热点和冷点
•如果要素的z 得分高且p 值小,则表示有一个高值的空间聚类。
如果z 得分低并为
负数且p 值小,则表示有一个低值的空间聚类。
z 得分越高(或越低),聚类程度就越大。
如果z 得分接近于零,则表示不存在明显的空间聚类。
Adabg00 模式分析
Average Nearest Neighbor 最邻近分析
对于点数据,没有明显的边
界,所以默认面积计算(最
小外接矩形)
最邻近指数小于1。
聚集分布。
Z得分为-10.9,对应的P
值为0.000000,即这种分布是随机
的情况概率为0.00000
关分析
指定反距离和固定距离中的距离参数,默认距离为所有要素最临近距离的最大值
空间关系模型参数说明空间要
素之间的关系,越接近现实,
结果越准确
聚集分布
Multi-Distance Spatial Cluster Analysis K函数分析
通过Calculate Distance Band From Neighbor count 计包含一个近邻点的最大距离,作为k函数的起始距离。
将最近邻距离的期望距离作为间隔
在此距离以内,均为集聚,但大于这距离,分布变为分散
且,聚集具有统计意义上的聚集,离散并未具有统计意义上的显著性
Anselin Local Moran’s I局部Moran’s I 分析
Getis-Ord General G 保证每个要素都有相邻要素
由index和z得分决定
高值集聚
Hot spot Analysis(Getis-Ord Gi*) 热点分析
Adabg00 模式分析
Adabg00属性结构
有两种属性将会被用于模式分析中(Lation (拉丁人口密度)和Dentity (人口密度))、
为了得到adsbg 的大概人口分布,首先使用密度分割,分层设色 以 dentity 字段
以 latino 字段
可以看出,adage 人口分布呈现聚集态势,四周人口稀少,大多数集中在内部
使用模式分析探索人口分布
为了使用Globle Moran’s I ,首先计算包含最近要素的最大距离
相交人口分布,拉丁人口分布除右下角外,其余和人口分布大致相识
选做Moran’s的
距离参数18850
相关性分析
可以看到,adage的人口有聚集分布的态势
使用局部Moran’s I 判断热点,冷点和异常值(聚集类型)
使用G统计量计算总体聚集程度
蓝色和紫色为异常值区域红色为高值聚集地区蓝色为低值聚集地区
可以看到,adage人口呈现聚集分布,且类型为高值聚集接着对latino 做相应的操作
聚集类型和人口分布相同
有异常值
和人口分布的热点不同
分析Z得分和P值与不同空间组合的关系
对于同一图层,p值和z得分是一一对应的,当z得分的绝对值变大时,对应的p值(接受是随机分布的假设)也变小
全局Moran’s I 和G 统计量用来指出要素呈现距离分布或离散分布,高值聚集或离散或低值聚集(当p 值
非常小时,z为正且越大,聚集分布越明显,反之亦可)(G统计量:当p值非常小时,z为正且越大,高值聚集明显,为0,离散分布,为负且越小,低值聚集越明显)
局部Moran’s I(cluster and outlier聚集和异常分析)和G统计量(hot spot热点分析)根据每个要素的z 得分和p值推出要素分布的相似或相异分布
局部Moran’s I(cluster and outlier聚集和异常分析)直接添加cotype字段,指出该要素的空间组合情况,如HH,LL,HL,LH,但z得分为正且较大时,说明正自相关,于是,将高值的聚类表示为hh,低值的聚类表示为ll,当Z得分为负且较大时,说明负相关越强,于是将高值附近的低值围绕极记为hl,反之Lh,这就是在全局请款下的异常值
HOT SPOT分析:如果要素的z 得分高且p 值小,则表示有一个高值的空间聚类。
如果z 得分低并为负数且p 值小,则表示有一个低值的空间聚类。
z 得分越高(或越低),聚类程度就越大。
如果z 得分接近于零,则表示不存在明显的空间聚类。
没有COtype 字段,可以更具自己的需要,设定阈值,和局部Morans
指数相近。