joinmap使用图文教程
mapjoin hint 的写法

mapjoin hint 的写法摘要:一、MapJoin简介1.MapJoin的作用2.何时使用MapJoin3.MapJoin的优点和缺点二、MapJoin的写法1.使用MapJoin的基本语法2.处理多表连接的MapJoin3.处理MapJoin的性能优化三、MapJoin的Hint1.使用MapJoin Hint的基本方法2.MapJoin Hint的参数说明3.实际应用中的MapJoin Hint示例正文:一、MapJoin简介MapJoin是一种在大数据处理场景中,针对某一列进行关联查询的技术。
它能够有效地提高查询效率,尤其适用于数据量较大且关联条件较简单的场景。
在使用MapJoin之前,我们需要了解它的作用、适用场景以及优缺点。
二、MapJoin的写法1.使用MapJoin的基本语法MapJoin的语法格式如下:```SELECT column1, column2, ...FROM table1JOIN table2ON table1.column = table2.columnUSING MAPJOIN (table2.column);```其中,`USING MAPJOIN (table2.column)`表示使用MapJoin对`table2.column`进行处理。
2.处理多表连接的MapJoin在多表连接的场景中,我们可以在第一个JOIN条件之后,使用`USING MAPJOIN (table2.column)`对某一列进行MapJoin处理。
如果需要对多列进行MapJoin处理,可以在`USING MAPJOIN`之后,使用逗号分隔多个列名。
3.处理MapJoin的性能优化在使用MapJoin时,需要注意以下几点性能优化:(1)尽量缩小MapJoin的输入数据量;(2)合理选择MapJoin的列;(3)适当调整MapJoin的参数。
三、MapJoin的Hint1.使用MapJoin Hint的基本方法在编写查询时,我们可以通过在`USING MAPJOIN (table2.column)`后面添加Hint,来指导数据库优化器如何处理MapJoin。
map join 写法

map join 写法Map Join是一种常见的Join操作,它将两个数据集按照某个键进行匹配,并将匹配的结果合并成一个新的数据集。
在Map Join中,一个数据集作为驱动表,另一个数据集作为被驱动表。
驱动表会被加载到内存中,而每个驱动表的键值都会被传递给被驱动表,以查找匹配的行。
以下是一个使用Python语言实现Map Join的示例代码:```python# 假设我们有两个数据集data1和data2,它们都有一个键列key data1 = [('a', 1), ('b', 2), ('c', 3)]data2 = [('a', 'x'), ('b', 'y'), ('d', 'z')]# 将数据集转换为Pandas的DataFrame对象df1 = pd.DataFrame(data1, columns=['key', 'value1'])df2 = pd.DataFrame(data2, columns=['key', 'value2'])# 使用merge函数进行Map Join操作result = df1.merge(df2, on='key', how='inner')# 输出结果print(result)```在这个示例中,我们首先将两个数据集转换为Pandas的DataFrame对象。
然后,我们使用merge函数进行Map Join操作,其中on参数指定了键列的名称,how参数指定了Join的方式(这里是内连接)。
最后,我们输出结果。
需要注意的是,在实际使用中,我们需要根据实际情况选择合适的Join方式,并考虑数据的加载方式、内存使用等因素,以避免出现性能问题。
hive map join用法

hive map join用法Hive是一种基于Hadoop的数据仓库系统,它支持SQL语言和MapReduce编程模型。
在Hive中,MapReduce程序可以使用Join操作来将两个或多个表中的数据合并在一起,但是这种操作需要传输大量数据,因此效率较低。
为了解决这个问题,Hive提供了Map Join (Map端Join)的机制,能够将一个小表的数据加载到内存中,并且对大表进行Join操作,大大提高了查询效率。
Map Join的使用方法在Hive中,Map Join的使用非常简单。
只需指定JOIN操作中要进行Map Join的表,并开启Map Join操作即可。
具体方法如下:1. 在查询中指定Join操作的表SELECT *FROM table1 t1 JOIN table2 t2 ON (t1.id = t2.id)2. 设置Map Join操作为了开启Map Join操作,可以使用Hive语句中的“Map Join”关键字进行设定:SET hive.auto.convert.join=true;SET hive.mapjoin.smalltable.filesize=25000000;这两个参数分别表示:• hive.auto.convert.join:自动转换Join算法,如果为true时,会自动将Join中小表的数据放到大表相应的节点进行Join,否则按默认的Shuffle Map Join方式执行(需要对大表数据进行Shuffle操作)。
• hive.mapjoin.smalltable.filesize:控制小表的大小,如果小表的大小小于该值,则视为小表,可以使用Map Join;否则视为大表,需要使用Shuffle Map Join操作。
在设置好Map Join操作后,执行查询语句即可生效。
如果查询中包含的Join操作为Map Join,则会打印出相关日志信息,如下所示:Status: Running (Executing on Yarn cluster with App idapplication_1611376104826_0001)Map 1: MapredLocalTaskAlias -> Map 1Input -> Map 2Output -> Map 1Condition -> EQUALSFile Output Operator [FS_2]table:{"key":{},"value":{}}Select Operator [SEL_1]outputColumnNames:["_col0","_col1","_col2"]Filter Operator [FIL_3]predicate:(UDFToDouble(_col0) < 10.0)TableScan [TS_0]alias:t1filterExpr:(UDFToDouble(id) < 10.0)filterExprRepeated:falseSelect Operator [SEL_2]outputColumnNames:["_col0","_col1","_col2"]Filter Operator [FIL_3]predicate:(UDFToDouble(_col0) < 10.0)TableScan [TS_1]alias:t2filterExpr:(UDFToDouble(id) < 10.0)filterExprRepeated:false其中,Map 1是Map Join执行的进程,Input是表示要进行Map Join的小表,Output 是指Map Join的输出结果,Condition表示Join的条件。
(完整版)jionmap使用说明

在Excel中输入,横向是用到的株系,纵向是marker,主题内容填A或B,保存为.csv(逗号分隔)格式。
然后打开写字板,在写字板中打开这个.csv格式文件,另存为.loc格式即可。
在我给你的例子中,name = demoF2popt = F2nloc =65nind = 104name表示名字(自己取),popt表示群体,如F2;nloc表示标记的数目,nind表示单株的数目。
下面是标记名称和单株的基因型,在F2中,对于共显性标记,采用ABH记录法。
即:亲本1的纯合带型记为“A”,亲本2的纯合带型记为“B”,杂合带型记为“H”,缺失数据记为“-”。
对于显性标记,若亲本1无带时,只有A和C,有带记为“C”,无带记为“A”。
若亲本2无带时,只有B和D,有带记为“D”,无带记为“B”。
在EXCEL中按以上格式整理后,考入文本文档,例如取名jiansheng安装好joinmap后,打开joinmap,点击file,再点击new project,然后取一个文件名,点击保存,这时进入一个新的joinmap界面,再点击file,点击load data,选择上面我们的文本文档jiansheng,点击打开,又进入一个新的界面,会出现name = demoF2popt = F2nloc =65nind = 104finial number indivals=104这时点击options,再点calution options,可以修改LOD lower 值,假定改为5.选择后,点击OK,又回到刚才的界面。
然后点击LOD grouping tree,然后点击calcuate,(或者计算器的那个图形)。
然后,会出现树状的图形。
如果你上面选的LOD值为5.0,则你用右键点击用5.0/1(56)、5.0/2(5),5.0/3(2)这里5.0表示LOD,1表示连锁群,56表示标记数。
这里共有3个连锁群。
如果你以前选择LOD=3,这里会出现1个连锁群,所以你自己可以选择LOD值,这样连锁上的标记数也不同。
sql 中 map join 的用法-概述说明以及解释

sql 中map join 的用法-概述说明以及解释1.引言1.1 概述引言部分是文章的开篇,是为了让读者对接下来要讨论的内容有一个整体的了解。
在本篇文章中,我们将介绍SQL 中的Map Join 的用法。
Map Join 是一种优化技术,可以在数据处理中提高查询的效率和性能。
在大数据处理过程中,通常需要对大量数据进行关联查询。
传统的Join 操作会消耗大量的计算资源和时间,特别是对于大型数据集来说。
而Map Join 则通过将一个表加载到内存中,并通过哈希表的方式进行关联查询,从而提高查询速度。
本文将介绍Map Join 的概念、优势以及使用场景,帮助读者更好地了解和应用这一优化技术。
1.2文章结构1.2 文章结构:本文将首先介绍什么是Map Join,包括其定义和原理。
然后,将探讨Map Join 相对于其他Join 类型的优势,以及在什么样的场景下可以使用Map Join。
接着,我们将总结Map Join 的作用,并讨论其局限性和未来发展方向。
通过这些内容,读者将对Map Join 有一个全面的了解,进一步提高其在SQL 数据处理中的应用能力。
1.3 目的在本文中,我们将探讨SQL 中Map Join 的用法。
通过深入了解什么是Map Join 以及它的优势和使用场景,我们旨在帮助读者更好地理解如何利用Map Join 提升SQL 查询的性能和效率。
同时,我们也将分析Map Join 的局限性和未来发展方向,为读者提供更全面的视角和理解。
通过本文的阐述,读者将能够掌握Map Join 在SQL 查询中的作用和应用,提高其在数据处理中的实用性和价值。
2.正文2.1 什么是Map JoinMap Join是一种优化技术,用于优化SQL查询中的连接操作。
在传统的连接操作中,数据库会将两个表中的数据合并到一个中间表中,然后再进行查询操作。
这种方式在处理大量数据时可能会导致性能下降,因为需要将所有数据加载到内存中进行比较。
(仅供参考)Icimapping 连锁图中文操作说明
• 对连锁群重命名: 鼠标指向连锁群”Chromsome4”, 然后右击, 从弹出的快捷菜 单中选择”Rename”实现对”Chromosome4”的重命名, 或者…
• 将连锁群上移或下移
• 删除连锁群内的所有标记
• 改变连锁群首尾标记的循序
12
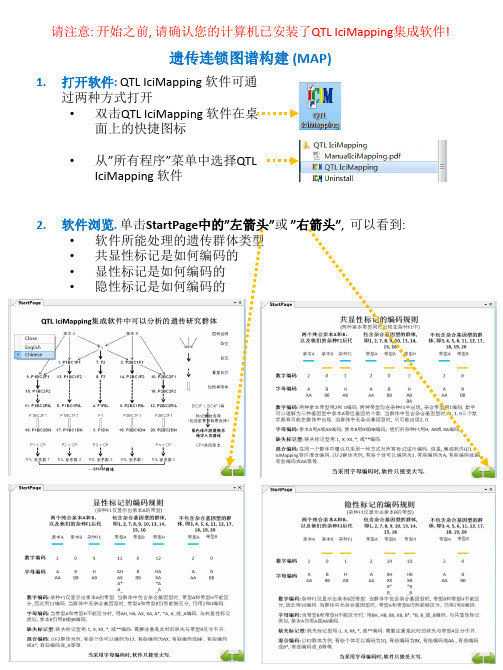
遗传连锁图谱构建
15. 高级用户 – 在EXCEL中管理遗传群体的信息 • 工作表”GeneralInfo”定义遗传群体的一些基本信息, 每项信息占1行.
记移动到”Chromosome4”): 鼠标指向所要移动的标记”F6L9.78”, 然后右击, 从 弹出的快捷菜单中选择”Move to -> Chromosome4”将 ”F6L9.78”移动 到”Chromosome4”; 对”SNP53”, “FRI”和”CNP254”重复上述过程.
• 对连锁群”Chromsome4”再排序: 鼠标指向连锁群”Chromsome4”, 然后右击, 从弹出的快捷菜单中选择”Ordering”实现对”Chromosome4”的重排序
13
如何构建整合图谱?
• 选择软件的IMP功能 • 向工程中导入待整合的
图谱. 例如, 把软件中附 带的”Arab_1.imp”打开. • 依次执行”Grouping”, “Ordering”, “Rippling (可 选项)”, 和”Outputting”建 立整合图谱.
14
如果想要计算F2群体中, 2个显性标记间的重组率, 怎么办?
• 从标记群中删除标记 (例如”Group4”中的”FRI”和”SNP254”): 鼠标指向待删除 标记” FRI”, 然后右击, 从弹出的快捷菜单中, 选择”Delete” 将”FRI” 从”Group4[*]”中删除; 对”SNP254”重复上述过程.
mapjoin 和 inner join原理 -回复
mapjoin 和inner join原理-回复MapJoin 和Inner Join 是两种常用的数据处理技术,用于在大数据处理过程中合并不同数据源的数据。
本文将详细介绍MapJoin 和Inner Join 的原理,并逐步回答与之相关的问题。
一、MapJoin 原理MapJoin 是一种基于MapReduce 的数据处理技术,用于合并两个数据集,其中一个数据集较小,可以完全加载到内存中,而另一个数据集较大,需要进行分布式处理。
MapJoin 的原理如下:1. 将小数据集加载到内存中:MapJoin 首先将较小的数据集加载到内存中,以便在处理过程中快速访问。
2. 将大数据集进行分片处理:接着,MapJoin 将较大的数据集进行分片处理,并将每个分片分发到不同的机器上。
3. 对每个分片与小数据集进行Join:然后,每个机器将自己负责的数据分片与小数据集进行Join 操作,比较匹配条件,生成匹配的结果。
4. 汇总所有结果:最后,MapJoin 将所有机器的结果汇总,生成最终的合并结果。
MapJoin 的特点是可以大大减少数据的扫描次数,提高处理效率。
但是,由于需要将小数据集加载到内存中,如果数据集过大,可能会导致内存不足或性能下降。
二、Inner Join 原理Inner Join 是一种常见的SQL 操作,用于合并两个数据集中满足匹配条件的行。
Inner Join 的原理如下:1. 比较匹配条件:Inner Join 首先根据指定的匹配条件,比较两个数据集中的每一行,找出满足条件的行。
2. 合并匹配行:对于每一对匹配的行,Inner Join 会将它们合并成一行,并添加到最终结果中。
3. 处理不匹配的行:如果存在一个数据集中有匹配的行,而另一个数据集中没有匹配的行,则Inner Join 可以根据配置选择保留还是过滤这些数据。
Inner Join 的特点是保留满足匹配条件的行,并可以通过配置选择处理不匹配的行。
oracle mapjoin用法
oracle mapjoin用法Oracle MapJoin 用法详解1. 介绍Oracle MapJoin 是一种优化技术,用于对SQL 查询中的表连接操作进行优化。
它通过将连接操作转化为MapReduce 形式的操作来提高查询性能。
本文将一步一步回答关于Oracle MapJoin 的用法问题,以帮助读者更好地理解和应用此技术。
2. MapJoin 的基本概念在传统的连接操作中,通常会使用Nested Loop Join 或Hash Join 等方法。
然而,如果待连接的表的数据量非常大时,这些传统的连接方式往往无法满足性能要求。
这时,Oracle MapJoin 技术就派上用场了。
MapJoin 将连接操作拆解为两个阶段:Map 阶段和Join 阶段。
在Map 阶段中,将待连接的表分割为多个小块,并分别加载到内存中。
而在Join 阶段中,通过对这些小块数据进行MapReduce 操作,完成连接操作。
这种方式可以提高查询的效率,特别是在大数据量场景下。
3. 实际应用使用Oracle MapJoin 需要满足一定的条件和操作步骤。
下面将一步一步回答使用过程中可能会遇到的问题。
问题1:如何判断是否适合使用MapJoin?回答1:首先,需要确定待连接的表的大小是否足够大。
如果表的大小在几千行到几百万行之间,那么考虑使用MapJoin 可能会带来性能提升。
其次,需要确保查询的复杂度不会导致MapJoin 的性能下降。
可以通过分析查询计划来判断是否适合使用MapJoin。
问题2:如何开启MapJoin 优化?回答2:在执行连接查询之前,需要设置以下两个参数:- `/*+ USE_HASH_MAPJOIN(true) */`:启用MapJoin 优化。
- `/*+ USE_NL(true) */`:启用Nested Loop Join 优化,以便在MapJoin 无法使用时进行切换。
问题3:如何进行MapJoin 的调优?回答3:可以通过以下方式对MapJoin 进行调优:- 增加`/*+ MAPJOIN_MAP_SELECT */` 提示语句来选择需要在Map 阶段执行的字段,减少内存消耗和数据传输量。
mysql中join 用法
mysql中join 用法MySQL中的JOIN语法是用于将两个或多个相关的表连接起来,以便在一个查询中检索相关联的数据。
JOIN操作可用于联接表,将其组合,并组合它们的行来创建一个完整的结果集,也就是展示出查询结果的所有列,而不是单独查询各自的表。
本文将以中括号为主题,解释MySQL中使用JOIN的语法、类型以及实例,帮助读者更好地理解JOIN操作。
一、JOIN操作的语法MySQL中JOIN操作的语法如下所示:SELECT [column_list] FROM table1 JOIN table2 ON [join_condition];其中,column_list表示要选择的列,table1和table2表示要连接的两个表,join_condition表示连接的条件,可以是单个或多个表中的列等值条件。
二、JOIN类型MySQL中JOIN操作有多种类型,可以根据需求选择不同类型的JOIN来实现。
下面列出了MySQL中的常见JOIN类型:1. INNER JOININNER JOIN操作基于某种关联条件将两个表中的行匹配,并且仅返回两个表中都存在的行。
另外,此操作也称为等值连接或自然连接,并且是MySQL中默认的连接类型。
INNER JOIN语句的示例:SELECT a.id, , b.salary FROM employees a INNER JOIN salaries b ON a.emp_no = b.emp_no;这个查询语句将从两个表中选择id、name和salary列,并通过连接条件'emp_no'将两个表合并起来进行匹配。
2. LEFT JOINLEFT JOIN操作基于某种关联条件将两个表中的行匹配,并且返回左表中的所有行,而只返回右表中与左表中的行匹配的行。
LEFT JOIN语句的示例:SELECT a.id, , b.salary FROM employees a LEFT JOIN salaries b ON a.emp_no = b.emp_no;这条查询语句将从employees和salaries表中选择各自的id、name、salary 列,并基于连接条件'emp_no'连接这些列。
python中join方法的用法
python中join方法的用法1. 嘿,你知道吗,python 里的 join 方法可太好用啦!就像把散落的珍珠串成漂亮项链一样。
比如说,你有个列表['a', 'b', 'c'],用逗号把它们连接起来,就可以这样写哦:",".join(['a', 'b', 'c']),结果不就出来啦!2. 哇塞,join 方法真的神奇啊!它能把一堆元素快速整合起来。
比如我们有一群小伙伴的名字['小明', '小红', '小刚'],想把他们名字连起来,用join 呀," ".join(['小明', '小红', '小刚']),这多简单快捷呀,不是吗?3. 哎呀呀,join 方法简直是神器呀!它就像个魔法棒一样。
假设我们有一堆数字[1, 2, 3],想把它们连成一串,那就用 join 呗,"".join(str(i) for i in [1, 2, 3]),是不是感觉很妙?4. 嘿呀,join 方法太有趣啦!它可以把看似杂乱无章的东西变得有条有理。
像有一些单词['hello', 'world', 'python'],用 join 让它们变成一个整齐的句子," ".join(['hello', 'world', 'python']),多有意思啊!5. 哇哦,join 方法真的超厉害呢!这就好比是一个厉害的指挥家,能让元素们乖乖听话。
比如有一些符号['+', '-', ''],让 join 来指挥它们,"".join(['+', '-', '']),你说厉害不厉害?6. 哈哈,join 方法真的绝了!它就像个神奇的胶水一样。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
文档来源为:从网络收集整理.word 版本可编辑.欢迎下载支持.
1 新建 new project
点击 dataset 新建 new
dataset 设置数据格式和大小
选择数据 复制 粘贴到矩
阵 检测数据是否有错误
第一个错误蓝色选中 之
后错误显示红色
点击错误处 按下F2 修改
再次检测数据是否错误
创建群体节点 计算位点基因型频率情况:
计算连锁群
设置参数,然后计算
确定那个群 需要作出连锁图 右键点击 使之成为红色 点击create group using the grouping tree
点击计算
点击calculate map 生产连锁遗传图
用另一种直观的方式查看基因型
点击(De-)Colorize
用最大似然法再次利用group1作图
选择group 并选择ML 点击OK
点击calculate map 再次作图
最后将两张图放在一起比较
右键点击选择两个连锁MAP
点击join 里的 combine maps
OK 完成 更多调试请自我感觉!这只是一个example ! Its finished by Dragon, please call me Dragon! [使用文档中的独特引言吸引读者的注意力,或者使用此空间强调要点。
要在此页面上的任何位置放置此文本框,只需拖动它即可。
] Info 数
据概要 不可更改的数
据显示
Loci 和 individual 显示的是loci 和 individual 的名称和序号,在这里可以删除一些loci 和 individual。