凌阳音频压缩算法--SPCE061A单片机教材书
基于SPCE061A的交通灯倒计时语音输入输出的设计

基于SPCE061A的交通灯倒计时语音输入输出的设计作者:杨岚涂小敏王玉芬来源:《现代电子技术》2009年第01期摘要:常见的语音控制系统多采用单片机和专用的语音处理芯片来完成,其缺点是语音处理芯片的性价比普遍不高,导致开发成本高,且开发周期较长。
在深入研究凌阳SPCE061A单片机在语音处理方面的优越性能后,设计了一套智能交通灯语音播报控制系统。
给出了控制系统方案设计,并重点讲述系统语音设计方案,包括语音输入电路、语音输出电路以及语音输入和语音输出的流程图等。
关键词:SPCE061A;交通灯;语音输入;语音输出中图分类号:TP368.1 文献标识码:B文章编号:1004-373X(2009)01-192-03Design of Traffic Light Countdown Voice Input and Output Based on SPCE061AYANG Lan,TU Xiaomin,WANG Yufen(College of Information Science and Engineering,Wuhan University of Science and Technology,Wuhan,430081,China)Abstract:The designing of voice control system often uses single chip computer and voice processing chip.The shortcoming is the lower cost-effective of voice processing chip and longer development cycle.After an in-depth study on the advan-tages of voice processing of SunplusSPCE061A,a smart traffic light voice broadcast control system is designed.The system′s design is given and the voice system′s design is foc used on.Including the circuit of voice input,voice output and the flow chart of voice input,voice output.Keywords:SPCE061A;traffic light;voice input;voice output近年来,随着城市交通的智能化和人性化,语音控制技术在智能交通方面的的应用越来越广泛。
基于凌阳SPCE061A的语音控制小车设计
语音控制是最为直接的人机对话方式,而小车以其生动、典型、学习形式喜闻乐见、涉及知识面广等特点,可作为电子类专业同学们学习、实践的良好载体。
凌阳SPCE061A单片机,具有简单的语音处理功能,不需要外挂语音处理芯片,因此采用SPCE061A作为主控芯片。
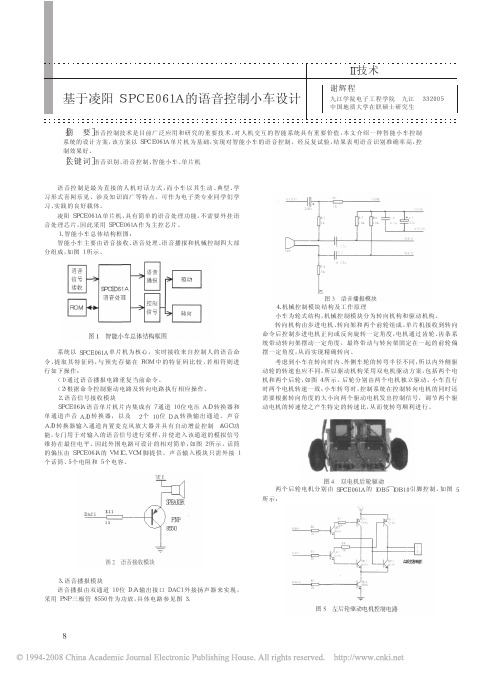
1、智能小车总体结构框图:智能小车主要由语音接收、语音处理、语音播报和机械控制四大部分组成,如图1所示。
图1智能小车总体结构框图系统以SPCE061A单片机为核心,实时接收来自控制人的语音命令,提取其特征码,与预先存储在ROM中的特征码比较,若相符则进行如下操作:(1)通过语音播报电路重复当前命令。
(2)根据命令控制驱动电路及转向电路执行相应操作。
2、语音信号接收模块SPCE06lA语音单片机片内集成有7通道10位电压A/D转换器和单通道声音A/D转换器,以及2个10位D/A转换输出通道。
声音A/D转换器输入通道内置麦克风放大器并具有自动增益控制(AGC)功能,专门用于对输入的语音信号进行采样,并使进入该通道的模拟信号维持在最佳电平。
因此外围电路可设计的相对简单,如图2所示。
话筒的偏压由SPCE06lA的VMIC、VCM脚提供。
声音输入模块只需外接1个话筒、5个电阻和5个电容。
图2语音接收模块3、语音播报模块语音播报由双通道10位D/A输出接口DAC1外接扬声器来实现,采用PNP三极管8550作为功放,具体电路参见图3。
图3语音播报模块4、机械控制模块结构及工作原理小车为轮式结构,机械控制模块分为转向机构和驱动机构。
转向机构由步进电机、转向架和两个前轮组成。
单片机接收到转向命令后控制步进电机正向或反向旋转一定角度,电机通过齿轮、齿条系统带动转向架摆动一定角度,最终带动与转向架固定在一起的前轮偏摆一定角度,从而实现精确转向。
考虑到小车在转向时内、外侧车轮的转弯半径不同,所以内外侧驱动轮的转速也应不同。
所以驱动机构采用双电机驱动方案,包括两个电机和两个后轮,如图4所示。
凌阳单片机 5.3 语音自动播放

Sunplus SPCE061A 微控制器语音播放(自动播放)语音播放一、单片机实现语音播放的原理二、语音播放程序示例三、创建一个语音播放程序四、小结和注意事项五、疑难解答一、单片机实现语音播放的原理语音录制存储流程 语音采样在定时中断的控制下,以一定的速率(8KHz )进行AD 转换压缩编码将采集到的数据以某种算法压缩编码存储将编码后的数据保存到存储介质中语音资源压缩编码存储数据队列定时中断AD采样语音语音播放流程数据提取语音数据送入解压缩队列数据解码解压缩数据并送入输出队列转换为模拟信号在定时中断的控制下进行数模转换转换为声音模拟信号经滤波、放大,通过扬声器输出解压缩队列语音资源解压缩取数据输出队列定时中断DAC输出语音用SPCE061A播放语音开始播放播放初始化语音资源播放完毕?开始解码,填入播放队列停止播放定时中断从播放队列取出数据送DAC输出返回YN播放队列设置中断播放循环中断服务自动播放与手动播放 自动播放解压缩队列语音资源解压缩取数据输出队列定时中断DAC输出语音SACM_Decoder(); SACM_A2000_FillQueue();SP_GetResource();手动播放二、语音播放程序示例语音播放程序示例// 中断服务程序 //用户接口函数在hardware.asm 中定义的用户API ,用户可以根据需要修改 F_SP_SACM_A2000_In it_ F_SP_InitQueue F_SP_ReadQueueF_SP_WriteQueueF_SP_RampUpDAC1…… ……语音函数库用户API语音播放程序三、创建一个语音播放程序创建一个语音播放程序 第1 步:新建工程创建一个语音播放程序 第2 步:复制语音播放需要的文件到工程所在的文件夹语音播放支持文件,在“IDE安装目录->Example -> 61_Exa -> Record”文件夹下可以找到sacmv26e.libhardware.inchardware.asmA2000格式的语音资源,在“IDE安装目录-> Example -> VoiceExa-> ex1_A2000->Voice”文件夹下可以找到这里选择了d1.24k和ww.24k两个文件在Project 菜单项,选择Add to Project -> Files 找到工程所在的文件夹,选择hardware.asm 、hardware.inc 两个文件(按住Ctrl 键点选),确定。
声控小车设计论文

声控小车设计中文摘要:声控小车指的是能够在人的语音命令控制下完成具体动作的小车,主要由控制板、驱动电路和车体组成,同时还要编辑合适的软件来具体控制小车的动作。
控制板主要负责软件的写入,能够完成语音信号的压缩、存储、辨识、响应等功能,而驱动电路则能够根据控制板送来的驱动信号对车体上的直流电机和继电器进行控制,从而完成具体的动作。
在本次设计中,控制板我们将采用凌阳公司的16位单片机,驱动电路将根据单片机的控制原理由我们利用模拟器件自己焊接。
软件的编写将主要参考单片机的C语言程序设计,编译环境为凌阳公司的IDE 1.16.1.具体软件编写和硬件功能实现将在正文中详细讲述。
关键词:凌阳16位单片机,语音识别,单片机C语言编程,驱动电路设计英文摘要:The audio-control car is a kind of car that can be controlled by human's voice and can achieve many functions such as Turn-right ,Turn-left, Go-ahead and Back-off.The car is composed of 3 parts: control board, drive board and base. The software should be downloaded in the control board is also necessary. For the control board, it should have 2 qualifications: first, the software can be planted in, second, the voice signal can be compacted, stored, differentiated and responded. For the drive board, it should control the DC motor and the relay directly via the signal that sent by the control board.For this design, we will use the Single Chip Microprocessor (SCM) manufactured by Sunplus Corporation as the control board, so the drive board should be fit for the SCM. The software will be compiled in the IDE 1.6.1 also provided by Sunplus Corporation. The design process will be introduced in the following text in details.Keywords: Single Chip Microprocessor, Audio control, program design.目录:前言 (3)一、硬件电路设计及连接 (3)1.1 SPCE061A (3)1.1.1 SPCE061A总述 (3)1.1.2SPCE061A 性能 (3)1.1.3 选择SPCE061A的理由 (4)1.1.4 凌阳16位单片机SPCE061A实物图 (4)1.1.5 SPCE061A内部结构框图 (5)1.2.车体驱动电路 (6)1.2.1车体驱动电路设计思路 (6)1.2.2实际驱动电路 (7)1.3、小车车底部分 (8)1.4.硬件部分结论 (8)二、软件编写与调试 (9)2.1主程序流程图 (9)2.2 控制口连接方式 (10)2.3.RAM中数据存取方式 (11)2.4语音训练和识别 (12)2.4.1语音命令训练过程 (12)2.4.2语音识别过程 (13)2.5 具体动作的实现 (13)2.6语音命令的重新训练 (14)2.7程序的组成和调试 (14)2.8程序代码下载 (15)三、小车的操作说明: (15)3.1使用方法 (15)3.2使用时的注意事项 (15)四、结论 (16)五、参考书目 (16)正文:前言:本次设计的目的是利用凌阳16位单片机SPCE061A的语音播放和语音识别资源进行语音控制,使小车能在具体的语音命令下完成前进、后退、左拐、右拐的动作。
基于16位单片机SPCE061A的导览器初步实现

基于16位单片机SPCE061A的导览器初步实现
任德学;高强;张亮;郑晓庆
【期刊名称】《天津理工大学学报》
【年(卷),期】2008(24)6
【摘要】本文介绍了凌阳16位单片机SPCE061A的主要特点,设计了一种基于SPCE061A的导览器系统,并给出了硬件的设计扩展和软件设计流程.实验表明,该系统可以有效的用于博物馆、展览馆等博览景点中.
【总页数】3页(P77-79)
【作者】任德学;高强;张亮;郑晓庆
【作者单位】天津理工大学,自动化学院,天津,300191;天津理工大学,自动化学院,天津,300191;天津理工大学,自动化学院,天津,300191;天津理工大学,自动化学院,天津,300191
【正文语种】中文
【中图分类】TP205
【相关文献】
1.基于Freescale 16位单片机抢答器的设计与实现 [J], 程启明;常琳;汪明媚;王映斐
2.基于凌阳16位单片机SPCE061A悬挂运动控制系统 [J], 贡雪梅;李新钊;胡春雷;钱建松
3.u'nSP16位单片机与PIC8位单片机基于CAN总线的通信实现 [J], 王兴贵;房伟;李楠
4.基于16位单片机SPCE061A的智能家居系统设计 [J], 高荣山;周东辉;张颜岭
5.基于新型16位单片机SPCE061A的波形发生器 [J], 蔡教武
因版权原因,仅展示原文概要,查看原文内容请购买。
SPCE061A是凌阳公司设计的一种16位单片机

SPCE061A是凌阳公司设计的一种16位单片机,该款单片机资源丰富,具有极高的性价比,该单片机内置有2路DA转换,8路AD转换及在线仿真,并且有16×16位的乘法运算和内积运算的DSP功能,这为它进行复杂的语音数字信号的压缩编码与解码提供了便利,还可以做数字滤波器。
这些特点为我们进行在语音处理尤其是语音识别领域的应用提供了便利。
语音识别技术在各个层面均有广泛的应用前景。
电脑软件领域,例如:语音命令、语音输入,对话系统、查询系统、教学软件、游戏软件等;消费性电子产品领域,例如:电子记事本、声控玩具、语音拔号功能的手机等;工业产品领域,例如:车用移动电话、车用导航系统等;电话系统领域,例如:语音识别总机服务、语音拔号、语音订票订位等。
1 语音识别基本原理语音识别就是让机器听得懂人们所讲的话,基本框架如图1和图2所示。
图1是语音训练模型的部分:将已知的语音信号经由端点侦测(End Point Detection)及特征参数求取(Feature Extraction)而产生标准的语音参考样本。
将待测的语音信号,经与图1同样的处理步骤求得特征参数后再与前述的标准语音参考样本对比,找出最相似的参考样本作为辨识的结果。
2 语音识别分类若依使用者的限制而言可分为特定人语音与非特定人语音识别。
2.1 特定人语音识别使用特定人语音识别系统前,须先把使用者的语音参考样本存入当成比对的资料库,即特定人语音识别系统在使用前就必须先进行图1的训练学习步骤。
2.2 非特定人语音识别使用本系统前根本不需要先学习,便能直接使用。
一套最佳的语音识别系统是不须经过学习便能进行语音识别,但通常辩识率都比较低。
另外以说话方式的连续是否又可分为非连续语音识别和连续语音识别。
对于非连续语音来说,识别所说的每一个字必须分开辨认;而连续语音识别可以一般自然流利的说话方式来进行人性化的语音识别,但由于关系到相连音的问题,很难达到好的辨认效果。
基于凌阳SPCE061A单片机远程家电控制器的研制

2
系统 硬 件 电路 的 设计
统 会 发 出 挂 机 指 令 ,O 8恢 复 高 电平 , 电 器 断 开 , 话 线 两 端 的 电 IA 继 电 压 恢 复 到 6 V左 右 的 正 常 电 压 , 而 实现 挂 机 。其 电路 如 图 4所 示 : 5 从
后 . 片 机 就 可 以控 制 摘 机 电 路 , 现模 拟 摘机 。其 电路 如 图 3所 示 : 单 实
图 3 铃 音检 测 模 块
23 摘 机 模 块 -
当 C U检 测 到 有 振 铃 信 号 并 且 计 数 已经 达 到 系 统所 设 定 的 可 以 P 摘 机 的次 数 . 片 机 会 送 出 摘 机信 号, I A 单 使 O 8脚 为 低 电平 , 即继 电 器 工
一
铃音检测模块 的主体芯片是 HT 0 0 振铃信号经 过隔直 电容后 , 93 。
1 系 统 工 作过 程
对 家 电进 行 远 程控 制 , 当有 电话 接 入 时 , 制 器 首 先 进 行 振 铃 计 控 数 . 振 铃 次数 大于 六 次 而 无 人 接 听 时 , 备 会 自动 摘 机 , 现 控 制 器 当 设 实 的 网络 联 机 , 作 者 根 据 语 音 提 示 输 入 密 码 , 操 当系 统 接 收 到 来 自对 方 的 按 键 信 号后 . 过 按 键 译 码 分 析 处 理 , 配 密 码 。 密 码 正 确 之 后 , 经 匹 根 据 语 音 提示 进 行 相 应 操 作 。系 统 会 根 据 按 键 所 对 应 的 操 作 发 出 指 令 , 进 行 状 态 查 询 . 电控 制 , 话 , 改 密 码 的 选 择 , 现 对 家 电 的 远 程 家 通 修 实 控制。如图 1 示 : 所
SPCE061A单片机引脚

锁相环
RAM
FLASH
CPU时 钟
时 基 双 16位 中 断 控 制 T/C
低电压 监测与复位
’nSP内 核
7通 道
单通道
双通道
串行设备
10位 ADC 语 音 ADC 10位 DAC 接 口 SIO
异步串行通 信 口 UART
内部总线
32位 通 用 I/O端 口
图4.2 SPCE061A内部结构图
第7页
第2页
● 具有可编程音频处理功能。 ● 低功耗,系统处于备用状态下(时钟处于停止状态)耗电 小于2 μA@3.6 V。 ● 两个16位可编程定时器/计数器(可自动预置初值)。 ● 两路10位数/模转换(DAC)输出通道。 ● 32位通用可编程输入/输出端A口和B口。 ● 14个中断源(定时器A、B,时基信号,两个外部时钟源, 触键唤醒等)。 ● 具有触键唤醒功能。 ● 使用凌阳音频编码SACM_S240方式(2.4 kb/s),能容纳 210 s语音数据。
第10页
SLEEP
63
VCP
8
XROMT PVPP XTEST (61. 69.14 )
VDDH
51. 52. 75
VDD VSS VSS VSS VDD
7 9 19. 24 38. 49. 50. 62 15. 36
睡眠状态指示,当 CPU 进入睡眠状态时,输出高电平 锁相环压控振荡器阻容输入端
第9页
DAC2
22
VREF2
23
AGC
25
OPI
26
MICOUT
27
MICN
28
MICP
33
VRT
35
VCM
34
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第7章 凌阳音频压缩算法7.1 背景介绍7.1.1 音频的概述(特点、分类)我们所说的音频是指频率在20 Hz~20 kHz的声音信号,分为:波形声音、语音和音乐三种,其中波形声音就是自然界中所有的声音,是声音数字化的基础。
语音也可以表示为波形声音,但波形声音表示不出语言、语音学的内涵。
语音是对讲话声音的一次抽象。
是语言的载体,是人类社会特有的一种信息系统,是社会交际工具的符号。
音乐与语音相比更规范一些,是符号化了的声音。
但音乐不能对所有的声音进行符号化。
乐谱是符号化声音的符号组,表示比单个符号更复杂的声音信息内容。
7.1.2 数字音频的采样和量化将模拟的(连续的)声音波形数字元化(离散化),以便利数字计算机进行处理的过程,主要包括采样和量化两个方面。
数字音频的质量取决于:采样频率和量化位数这两个重要参数。
此外,声道的数目、相应的音频设备也是影响音频质量的原因。
7.1.3 音频格式的介绍音频文件通常分为两类:声音文件和MIDI文件(1)声音文件:指的是通过声音录入设备录制的原始声音,直接记录了真实声音的二进制采样数据,通常文件较大;(2)MIDI文件:它是一种音乐演奏指令序列,相当于乐谱,可以利用声音输出设备或与计算机相连的电子乐器进行演奏,由于不包含声音数据,其文件尺寸较小。
1)声音文件的格式WAVE文件——*.WAVWAVE文件使用三个参数来表示声音,它们是:采样位数、采样频率和声道数。
在计算机中采样位数一般有8位和16位两种,而采样频率一般有11025Hz(11KHz),22050Hz(22KHz)、44100Hz(44KHz)三种。
我们以单声道为例,则一般WAVE文件的比特率可达到88K~704Kbps。
具体介绍如下:(1) WAVE格式是Microsoft公司开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范;(2) 用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持。
(3) WAVE格式支持MSADPCM、CCITT A Law、CCITT µ Law和其它压缩算法,支持多种音频位数、采样频率和声道,是PC机上最为流行的声音文件格式。
(4) 但其文件尺寸较大,多用于存储简短的声音片段。
AIFF文件——AIF/AIFF(1) AIFF是音频交换文件格式(Audio Interchange File Format)的英文缩写,是苹果计算机公司开发的一种声音文件格式;(2) 被Macintosh平台及其应用程序所支持,Netscape Navigator浏览器中的LiveAudio也支持AIFF格式,SGI及其它专业音频软件包同样支持这种格式。
(3) AIFF支持ACE2、ACE8、MAC3和MAC6压缩,支持16位44.1Kz立体声。
Audio文件——*.Audio(1) Audio文件是Sun Microsystems公司推出的一种经过压缩的数字声音格式,是Internet中常用的声音文件格式;(2) Netscape Navigator浏览器中的LiveAudio也支持Audio格式的声音文件。
MPEG文件——*.MP1/*.MP2/*.MP3(1) MPEG是运动图像专家组(Moving Picture Experts Group)的英文缩写,代表MPEG标准中的音频部分,即MPEG音频层(MPEG Audio Layer);(2) MPEG音频文件的压缩是一种有损压缩,根据压缩质量和编码复杂程度的不同可分为三层(MPEG Audio Layer1/2/3),分别对应MP1、MP2和MP3这三种声音文件;(3) MPEG音频编码具有很高的压缩率,MP1和MP2的压缩率分别为4:1和6:1~8:1,而MP3的压缩率则高达10:1~12:1,也就是说一分钟CD音质的音乐,未经压缩需要10MB存储空间,而经过MP3压缩编码后只有1MB左右,同时其音质基本保持不失真,因此,目前使用最多的是MP3文件格式。
RealAudio文件——*.RA/*.RM/*.RAM(1) RealAudio文件是RealNerworks公司开发的一种新型流式音频(Streaming Audio)文件格式;(2) 它包含在RealMedia中,主要用于在低速的广域网上实时传输音频信息;(3) 网络连接速率不同,客户端所获得的声音质量也不尽相同:对于28.8Kbps的连接,可以达到广播级的声音质量;如果拥有ISDN或更快的线路连接,则可获得CD音质的声音。
2)MIDI文件——*.MID/*.RMI(1) MIDI是乐器数字接口(Musical Instrument Digital Interface)的英文缩写,是数字音乐/电子合成乐器的统一国际标准;(2) 它定义了计算机音乐程序、合成器及其它电子设备交换音乐信号的方式,还规定了不同厂家的电子乐器与计算机连接的电缆和硬件及设备间数据传输的协议,可用于为不同乐器创建数字声音,可以模拟大提琴、小提琴、钢琴等常见乐器;(3) 在MIDI文件中,只包含产生某种声音的指令,这些指令包括使用什么MIDI 设备的音色、声音的强弱、声音持续多长时间等,计算机将这些指令发送给声卡,声卡按照指令将声音合成出来,MIDI在重放时可以有不同的效果,这取决于音乐合成器的质量;(4) 相对于保存真实采样资料的声音文件,MIDI文件显得更加紧凑,其文件尺寸通常比声音文件小得多。
7.1.4 语音压缩编码基础语音压缩编码中的数据量是指:数据量=(采样频率×量化位数)/8(字节数) ×声道数目。
压缩编码的目的:通过对资料的压缩,达到高效率存储和转换资料的结果,即在保证一定声音质量的条件下,以最小的资料率来表达和传送声音信息。
压缩编码的必要性:实际应用中,未经压缩编码的音频资料量很大,进行传输或存储是不现实的。
所以要通过对信号趋势的预测和冗余信息处理,进行资料的压缩,这样就可以使我们用较少的资源建立更多的信息。
举个例子,没有压缩过的CD品质的资料,一分钟的内容需要11MB的内存容量来存储。
如果将原始资料进行压缩处理,在确保声音品质不失真的前提下,将数据压缩一半,5.5MB就可以完全还原效果。
而在实际操作中,可以依需要来选择合适的算法。
常见的几种音频压缩编码:1) 波形编码:将时间域信号直接变换为数字代码,力图使重建语音波形保持原语音信号的波形形状。
波形编码的基本原理是在时间轴上对模拟语音按一定的速率抽样,然后将幅度样本分层量化,并用代码表示。
译码是其反过程,将收到的数字序列经过译码和滤波恢复成模拟信号。
如:脉冲编码调制(Pulse Code Modulation,PCM)、差分脉冲编码调制(DPCM)、增量调制(DM)以及它们的各种改进型,如自适应差分脉冲编码调制(ADPCM)、自适应增量调制(ADM)、自适应传输编码(Adaptive Transfer Coding,ATC)和子带编码(SBC)等都属于波形编码技术。
波形编码特点:高话音质量、高码率,适于高保真音乐及语音。
2) 参数编码:参数编码又称为声源编码,是将信源信号在频率域或其它正交变换域提取特征参数,并将其变换成数字代码进行传输。
译码为其反过程,将收到的数字序列经变换恢复特征参量,再根据特征参量重建语音信号。
具体说,参数编码是通过对语音信号特征参数的提取和编码,力图使重建语音信号具有尽可能高的准确性,但重建信号的波形同原语音信号的波形可能会有相当大的差别。
如:线性预测编码(LPC)及其它各种改进型都属于参数编码。
该编码比特率可压缩到2Kbit/s-4.8Kbit/s,甚至更低,但语音质量只能达到中等,特别是自然度较低。
参数编码特点:压缩比大,计算量大,音质不高,廉价!3) 混合编码:混合编码使用参数编码技术和波形编码技术,计算机的发展为语音编码技术的研究提供了强有力的工具,大规模、超大规模集成电路的出现,则为语音编码的实现提供了基础。
80年代以来,语音编码技术有了实质性的进展,产生了新一代的编码算法,这就是混合编码。
它将波形编码和参数编码组合起来,克服了原有波形编码和参数编码的弱点,结合各自的长处,力图保持波形编码的高质量和参数编码的低速率。
如:多脉冲激励线性预测编码(MPLPC),规划脉冲激励线性预测编码(KPELPC),码本激励线性预测编码(CELP)等都是属于混合编码技术。
其数据率和音质介于参数和波形编码之间。
总之,音频压缩技术之趋势有两个:1)降低资料率,提高压缩比,用于廉价、低保真场合(如:电话)。
2)追求高保真度,复杂的压缩技术(如:CD)。
语音合成、辨识技术的介绍:按照实现的功能来分,语音合成可分两个档次:(1) 有限词汇的计算机语音输出(2) 基于语音合成技术的文字语音转换(TTS:Text-to-Speech)按照人类语言功能的不同层次,语音合成可分为三个层次:(1) 从文字到语音的合成(Text-to-Speech)(2) 从概念到语音的合成(Concept-to-Speech)(3) 从意向到语音的合成(Intention-to-Speech):图7.1是文本到语音的转换过程语音辨识:语音辨识技术有三大研究范围:口音独立、连续语音及可辨认字词数量。
口音独立:1)早期只能辨认特定的使用者即特定语者(Speaker Dependent,SD)模式,使用者可针对特定语者辨认词汇(可由使用者自行定义,如人名声控拨号),作简单快速的训练纪录使用者的声音特性来加以辨认。
随着技术的成熟,进入语音适应阶段SA(speaker adaptation),使用者只要对于语音辨识核心,经过一段时间的口音训练后,即可拥有不错的辨识率。
2)非特定语者模式(Speaker Independent,SI),使用者无需训练即可使用,并进行辨认。
任何人皆可随时使用此技术,不限定语者即男性、女性、小孩、老人皆可。
连续语音:1)单字音辨认:为了确保每个字音可以正确地切割出来,必须一个字一个字分开来念,非常不自然,与我们平常说话的连续方式,还是有点不同。
2)整个句子辨识:只要按照你正常说话的速度,直接将要表达的说出来,中间并不需要停顿,这种方式是最直接最自然的,难度也最高,现阶段连续语音的辨识率及正确率,虽然效果还不错但仍需再提高。
然而,中文字有太多的同音字,因此目前所有的中文语音辨识系统,几乎都是以词为依据,来判断正确的同音字。
可辨认词汇数量:内建的词汇数据库的多寡,也直接影响其辨识能力。
因此就语音辨识的词汇数量来说亦可分为三种:1)小词汇量(10-100)2)中词汇量(100-1000)3)无限词汇量(即听写机)图7.2是简化的语音识别原理图,其中实线部分成为训练模块,虚线部分为识别模块。