人工智能复习资料

一、选择填空
1.产生式系统由综合数据库,规则库,控制策略三个部分组成
2.α-β剪枝中,极大节点下界是α,极小节点是β。
3.发生β剪枝的条件是祖先节点β值<=后辈节点的α值。
4.发生α剪枝的条件是后辈节点β值<=祖先节点的α值。
5.在证据理论中,信任函数Bel(A)与似然函数Pl(A)的关系为0<=Bel(A)<=Pl(A)<=1。
6.深度优先算法的节点按深度递减的顺序排列OPEN中的节点。
7.宽度优先算法的节点按深度递增的顺序排列OPEN中的节点。
8.A 算法失败的充分条件是OPEN 表为空。
9.A算法中OPEN中的节点按f值从小到大排序。
10.爬山算法(不可撤回方式)是只考虑局部信息,没有从全局角度考虑最佳选择。f(n)= g(n) 只考虑搜索过的路径已经耗费的费用
11.分支界限算法(动态规划算法):f(n)= h(n)只考虑未来的发展趋势。仅保留queue中公共节点路径中耗散值最小的路径,余者删去,按g 值升序排序。12.回溯策略是试探性地选择一条规则,如发现此规则不合适,则退回去另选其它规则。定义合适的回溯条件①新产生的状态在搜索路径上已经出现过。②深度限制(走到多少层还没有到目标,就限制往回退) ③当前状态无可用规则。
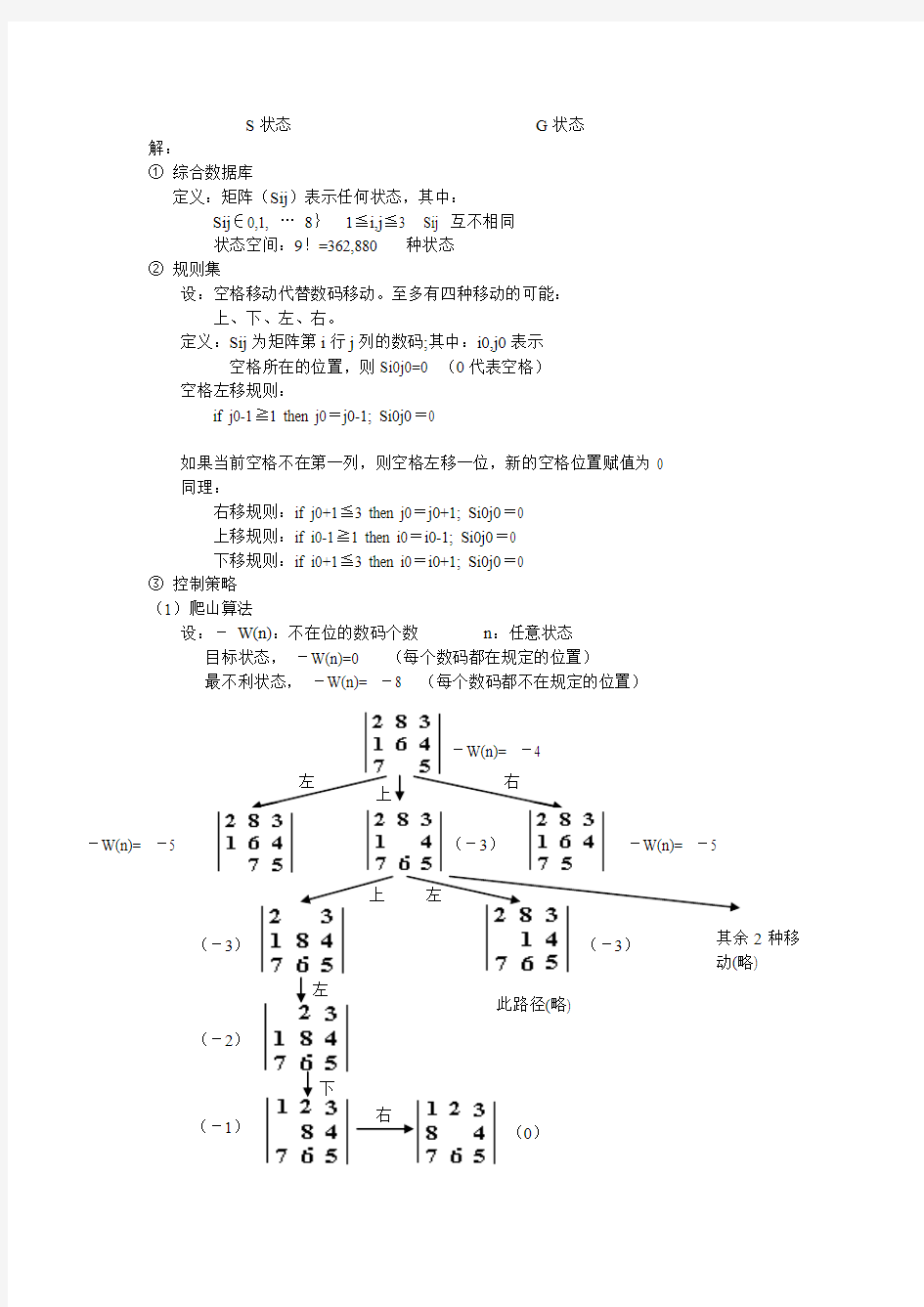
13.A*选中的任何节点都有f(n)<=f*(s) 14.h(n)与h*(n)的关系是h(n)>=h*(n),g(n)与g*(n)的关系是g(n) ≥g*(n) 。 15.求解图的时候,选择一个正确的外向连接符是顺着现有的连接符的箭头方向去找,不能逆着箭头走。 16.根节点:不存在任何父节点的节点。叶节点:不存在任何后继节点的节点。 17.两个置换s1,s2的合成置换用s1s2表示。它是s2作用到s1的项。 18.LS和LN两个参数之间应该满足LS、LN>=0,不独立,LS、LN可以同时=1,LS、LN不能同时>1或<1。 19.语义网络:一般用三元组(对象,属性,值)或(关系,对象1,对象2) 20.反向推理方法:定义:首先提出假设,然后验证假设的真假性,找到假设成立的所有证据或事实。 21.证据A的不确定性范围:-1 ≤CF( A) ≤1。 22.析取范式:仅由有限个简单合取式组成的析取式。 23.合取范式:仅由有限个简单析取式组成的合取式。 24.原子公式:由原子符号与项(为常量、变量和函数)构成的公式为原子公式。 二、产生式系统(第一章) 给定一个初始状态S、一个目标状态G,求从S到G的走步序列。 S 状态 G 状态 解: ① 综合数据库 定义:矩阵(Sij )表示任何状态,其中: Sij ∈0,1, … 8} 1≦i,j ≦3 Sij 互不相同 状态空间:9!=362,880 种状态 ② 规则集 设:空格移动代替数码移动。至多有四种移动的可能: 上、下、左、右。 定义:Sij 为矩阵第i 行j 列的数码;其中:i0,j0表示 空格所在的位置,则Si0j0=0 (0代表空格) 空格左移规则: if j0-1≧1 then j0=j0-1; Si0j0=0 如果当前空格不在第一列,则空格左移一位,新的空格位置赋值为0 同理: 右移规则:if j0+1≦3 then j0=j0+1; Si0j0=0 上移规则:if i0-1≧1 then i0=i0-1; Si0j0=0 下移规则:if i0+1≦3 then i0=i0+1; Si0j0=0 ③ 控制策略 (1)爬山算法 设:- W(n):不在位的数码个数 n :任意状态 目标状态, -W(n)=0 (每个数码都在规定的位置) 最不利状态, -W(n)= -8 (每个数码都不在规定的位置) 左 右 上 -W(n)= -4 -W(n)= -5 -W(n)= -5 (-3) (-3) (-3) 其余2种移动(略) 此路径(略) 上 左 左 (-2) 下 (-1) (0) 右 (2)回溯策略 限定搜索深度为6,移动次序为左上右下。 (3)A 算法 令: g(n)=d(n) 节点深度 h(n)=w(n) 不在位的数码个数(启发函数) 则 f(n)=d(n)+w(n) 深度=1 可用规则:左、上、右 此状态与深度=3 的状态相同 左 深度=4 左 深度=5 可用规则:上、右 右 可用规则:左、右、下 左 与深度=4状 态相同且深 度=6 可用规则:左、下 深度=6 下 限定搜索深度 = 6 规则排列次序: 左移、上移、右移、下移 三、第二章和第四章 (1)超图(与或图)找解图,并计算解图耗散值 2 8 3 1 6 4 7 5 2 8 3 1 4 7 6 5 2 8 3 1 6 4 7 5 2 8 3 1 6 4 7 5 2 3 1 8 4 7 6 5 2 8 3 1 4 7 6 5 2 8 3 1 4 7 6 5 2 8 3 7 1 4 6 5 8 3 2 1 4 7 6 5 2 3 1 8 4 7 6 5 2 3 1 8 4 7 6 5 1 2 3 8 4 7 6 5 1 2 3 8 4 7 6 5 1 2 3 7 8 4 6 5 s(4) A(6) B(4) C(6) D(5) E(5) F(6) G(6) H(7) I(5) J(7) K(5) L(5) M(7) 目标 1 2 3 4 5 6 n 0 n1 n3 n6 n7 n2 n5 n4 n8 n0 n3 n6 n7 n5 n4 n8 解图1 n1 n5 n0 n8 n7 解图2 左图耗散值 ① K(n0,N) = 1+ K(n1,N) =1+1+ K(n3,N) =1+1+2+ K(n5,N)+ K(n6,N) =1+1+2+2+ K(n7,N)+ K(n8,N)+2+ K(n7,N)+ K(n8,N) =1+ 1+ 2+ 2+ 0+ 0+ 2+ 0+ 0 =8 右图耗散值 ② K(n0,N) = 2+ K(n4,N) + K(n5,N) = 2+ 1+K(n5N) + 2+K(n7,N) +K(n8,N) = 2+ 1+ 2+K(n7,N) +K(n8,N) + 2+K(n7,N) +K(n8,N) = 2+ 1+ 2+ 0+ 0+ 2+ 0+ 0 =7 (2)α-β剪枝,并在博弈树上给出是何处发生剪枝的标志,并标明是哪种剪枝,各生成节点的到推值以及选择的走步路径。 (3)语义网络表示 1.书本p137,根据已知规则画出与或图 答案: 有毛发有奶哺乳动物 有羽毛会飞会下蛋 鸟吃肉肉食动物 有蹄 有爪 有犬齿眼盯前方 有蹄动物 嚼反刍动物 黄褐色 身上有暗斑点 金钱豹 黑色条纹 虎 长脖子 长腿 长颈鹿 斑马 不会飞 鸵鸟 会游泳 有黑白两色 企鹅 善飞 信天翁 2.王峰热爱祖国。 答案:(热爱,王峰,祖国) 3、Micheal 是一个雇员,Jack 是他老板,有一天Micheal 这个人kicked 0 5 -3 3 3 -3 0 2 2 -3 0 –2 3 5 4 1 -3 0 6 8 9 -3 答案: event Jack Micheal Kicked Agent is Object boss-of employee boss person 4、李强是某大学计算机系教师,35岁,副教授,该大学位于北京 答案: 李强副教授 计算机系 某大学 Is-a Work-at Part-of 北京 Located-at 教师 A-kind-of 35岁 Age 四、第五章 (1)确定性推理 1、已知:R1:A1→B1 CF (B1,A1)=0.8 R2:A2→B1 CF (B1,A2)=0.5 R3:B1∧A3→B2CF (B2,B1∧A3)=0.8 CF (A1)=CF (A2)=CF (A3)=1; CF (B1)= CF (B2)=0; 计算 :CF (B1)、CF (B2) 解:依规则R1, CF (B1|A1)=CF (B1)+CF (B1,A1)(1-CF (B1))=0.8, 即更新后CF (B1)=0.8 依规则R2: CF (B1|A2)=CF (B1)+CF (B1,A2)(1-CF (B1))=0.9 更新后CF (B1)=0.9 依R3,先计算 CF (B1∧A3)=min (CF (A3),CF (B1))=0.9 由于CF (B1∧A3)<1, CF (B2| B1∧A3)= CF (B2)+ CF (B1∧A3)×CF(B2,B1∧A3) ×(1-CF (B2))=0+0.9×0.8(1-0)=0.72 2、课本p203页 作业5.10 设有以下知识: R1:IF E1 THEN H(0.9); R2:IF E2 THEN H(0.6); R3:IF E3 THEN H(-0.5); R4:IF E4 AND (E5 OR E6) THEN E1(0.8); 已知CF(E2)=0.8,CF(E3)=0.6,CF(E4)=0.5,CF(E5)=0.6,CF(E6)=0.8. 求:CH(H). 解: 12(56)max{(5),(6)}0.8 (4(56))min{(4),(56)}0.5 (1)max{0,(4(56))}(1,4(56))0.50.80.4()max{0,(1)}(,1)0.40.90.36()max{0,(2)}(,2CF E E CF E CF E CF E E E CF E CF E E CF E CF E E E CF E E E E CF H CF E CF H E CF H CF E CF H E ∨==∧∨=∨==∧∨?∧∨=?==?=?==?3121212123)0.80.60.48()max{0,(3)}(,3)0.60.50.3 ()()()()()0.360.480.360.480.6672()()()0.66720.30.3672 CF H CF E CF H E CF H CF H CF H CF H CF H CF H CF H CF H =?==?=?-=-=+-=+-?==+=-= (2)证据理论 1、设U={a,b,c,d},A={a,b},B={a,b,c},m(A)=0.6,m(U)=0.4,U 的其它子集的m 值均为0。 解: Bel(B)=m({a,b,c})+m({a,b})+m({a,c})+m({b,c})+m({a})+m({b}) +m({c})+m(φ)=0.6 Pl(A)=1-Bel({a,b}')=1-Bel({c,d})=1-(m({c,d})+m({c})+m({d})+m(φ))=1 Bel(A)=m({a,b})+m({a})+m({b})+m(φ)=0.6 3、已知:f1(A1) = 0.40,f1(A2)=0.50,|U| = 20,A1→B={b1,b2,b3},(c1,c2,c3)=(0.1,0.2,0.3),A2→B={b1,b2,b3},(c1,c2,c3)=(0.5,0.2,0.1) 求:f1(B) 解:先求:m1({b1},{b2},{b3})=(0.4*0.1,0.4*0.2,0.4*0.3)=(0.04,0.08,0.12); m1(U)=1- [m1({b1})+m1({b2})+m1({b3})]=0.76; m2({b1},{b2},{b3})=(0.5*0.5,0.5*0.2,0.5*0.1)=(0.25,0.10,0.05); m2(U)=1- [m2({b1})+m2({b2})+m2({b3})]=0.70; 求m =m1⊙ m2 1/K=m1({b1})*m2({b1})+ m1({b1})*m2({U})+ m1({b2})*m2({b2})+ m1({b2})*m2({U})+ m1({b3})*m2({b3})+ m1({b3})*m2({U})+ m1({U})*m2({b1})+ m1({U})*m2({b2})+ m1({U})*m2({b3})+ m1({U})*m2({U}) =0.01+0.028+0.008+0.056+0.06+0.084+0.19+0.076+0.038+0.532 =1/1.082 有: m({b1})=K*(m1({b1})*m2({b1})+m1({b1})*m2({U}) +m1({U})*m2({b1})) =1.082*(0.01+0.028+0.19)=0.247 m({b2})=K*(m1({b2})*m2({b2})+m1({b2})*m2({U})+m1({U})*m2({b2})) =1.082*(0.008+0.056+0.076) =0.151 m({b3})=K*(m1({b3})*m2({b3})+m1({b3})*m2({U})+m1({U})* m2({b3})) =1.082*(0.06+0.084+0.038)=0.138 m(U)=1-[ m({b1})+ m({b2})+ m({b3})]=0.464 最后: Bel (B )=m({b1})+ m({b2})+ m({b3})=0.536 P1(B)=1-Bel(~B) 由于基本概率分配函数只定义在B 集合和全集U 之上,所以其它集合的分配函数值为0,即Bel(~B)=0 所以,可得 P1(B)=1-Bel(~B)=1 f1(B)=Bel(B)+(P1(B)-Bel(B))*|B|/|U|=0.536+(1-0.536)*3/20=0.606 五、第三章 (1)基于归结的演绎系统 1、已知前提: (1)能阅读的人是识字的 (2)海豚都不识字 (3)有些海豚是聪明的 求证:有些聪明的东西不会阅读 证明:用谓词形式表达所有前提以及结论。 ① R(x): x 会阅读 ② L(x): x 识字 ③ D(x): x 是海豚 ④ I(x): x 是聪明的 解: ① ② ③ 结论: 利用公式标准化方法求出上式的S 标准形,再写出对应的子句集 求证过程: ))()((x L x R x →? ))(~)((x L x D x →?))()((x I x D x ∧?))(~)((x R x I x ∧?)}()(~),(),(),(~)(~),()({~}{~0z R z I A I A D y L y D x L x R W S ∨∨∨= ⑥R(A) (4),(5) 的归结式 ⑦L (A) (1),(6) 的归结式 ⑧~D (A) (2),(7) 的归结式 ⑨NIL (3),(8) 的归结式 2、证明 R1:所有不贫穷且聪明的人都快乐: R2:那些看书的人是聪明的: R3:李明能看书且不贫穷: R4:快乐的人过着激动人心的生活: 结论李明过着激动人心的生活的否定: 将上述谓词公式转化为子句集并进行归结如下: 由R1可得子句: ①()()() ∨∨ Poor x Smart x Happy x 由R2可得子句: ②()() ∨ read y Smart y 由R3可得子句: ③() read Li ④() Poor Li 由R4可得子句: ⑤()() ∨ Happy z Exciting z 有结论的否定可得子句: ⑥() Exciting Li 根据以上6条子句,归结如下: ⑦() Happy Li⑤⑥Li/z ⑧()() ∨⑦①Li/x Poor Li Smart Li ⑨() Smart Li⑧④ ⑩() read Li⑨②Li/y 11 ⑩③ 由上可得原命题成立。 (2)基于归结的问答系统 ① 如果Peter 去哪儿,则Fido 就去那儿 ② 如果Peter 在学校 问题: Fido 就去那儿? 解:用谓词公式表达所有前提以及结论。 ① ② 结论 子句集: 练习: 1、已知:U={a ,b}; m1({},{a}{b}{a,b})=(0,0.3,0.5,0.2); m2({},{a}{b}{a,b})=(0,0.6,0.3,0.1); 求m=m1⊙m2 2、设有以下知识: R1:IF E1 THEN H ,CF(H,E1)=0.9; R2:IF E2 THEN H ,CF(H,E2)=0.6; R3:IF E3 THEN H ,CF(H,E3)=-0.5; R4:IF E4 AND (E5 OR E6) THEN E1,CF(E1∧(E5 ∨E6))=0.9; 已知CF(E2)=0.8,CF(E3)=0.6,CF(E4)=0.5,CF(E5)=0.6,CF(E6)=0.8,CH(H)=. 求:CH(H). 3、有如下推理规则 R1:IF E1 THEN H(0.9); R2:IF E2 THEN H(0.7); R3:IF E3 THEN H(-0.8); )),(),((x Fido AT x Peter AT x →?),(school Peter AT )},(~),,(),,(),({~y fido AT school Peter AT x Fido AT x Peter AT ∨) ,(),(~y Fido AT y Fido AT ∨),(),(~y Fido AT y Fido AT ∨ R4:IF E4 AND E5 THEN E1(0.7); R5:IF E6 AND (E77 OR E8) THEN E2(1.0); 已知CF(E3)=0.3,CF(E4)=0.9,CF(E5)=0.6,CF(E6)=0.7,CF(E7)=-0.3.CF(E8)=0.8 求:CH(H). 4、请把下列命题用一个语义网络表示出来。 (1)树和草都是植物 (2)树和草都有叶和根 (3)水草是草,且生长在水中。 (4)果树是树,且会结果。 (5)梨树是果树中的一种,它会结梨 5、剪枝 6、画出由A到{T0,T1}的2个解图,并计算解图耗散值。 人工智能的研究方向和应用领域 人工智能(Artificial Intelligence) ,英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。广义的人工智能包括人工智能、人工情感与人工意志三个方面。 一、研究方向 1.问题求解 人工智能的第一个大成就是发展了能够求解难题的下棋(如国际象棋)程序。在下棋程序中应用的某些技术,如向前看几步,并把困难的问题分成一些比较容易的子问题,发展成为搜索和问题归约这样的人工智能基本技术。今天的计算机程序能够下锦标赛水平的各种方盘棋、十五子棋和国际象棋。另一种问题求解程序把各种数学公式符号汇编在一起,其性能达到很高的水平,并正在为许多科学家和工程师所应用。有些程序甚至还能够用经验来改善其性能。 2.逻辑推理与定理证明 逻辑推理是人工智能研究中最持久的子领域之一。其中特别重要的是要找到一些方法,只把注意力集中在一个大型数据库中的有关事实上,留意可信的证明,并在出现新信息时适时修正这些证明。对数学中臆测的定理寻找一个证明或反证,确实称得上是一项智能任务。为此不仅需要有根据假设进行演绎的能力,而且需要某些直觉技巧。 1976年7月,美国的阿佩尔(K.Appel)等人合作解决了长达124年之久的难题--四色定理。他们用三台大型计算机,花去1200小时CPU时间,并对中间结果进行人为反复修改500多处。四色定理的成功证明曾轰动计算机界。 3.自然语言理解 NLP(Natural Language Processing)自然语言处理也是人工智能的早期研究领域之一,已经编写出能够从内部数据库回答用英语提出的问题的程序,这些程序通过阅读文本材料和建立内部数据库,能够把句子从一种语言翻译为另一种语言,执行用英语给出的指令和获取知识等。有些程序甚至能够在一定程度上翻译从话筒输入的口头指令(而不是从键盘打入计算机的指令)。目前语言处理研究的主要课题是:在翻译句子时,以主题和对话情况为基础,注意大量的一般常识--世界知识和期望作用的重要性。 探索大数据和人工智能最全试题 1、2012年7月,为挖掘大数据的价值,阿里巴巴集团在管理层设立()一职,负责全面推进“数据分享平台”战略,并推出大型的数据分享平台。 A首席数据官 B.首席科学家 C.首席执行官 D.首席架构师 2、整个MapReduce的过程大致分为Map、Shuffle、Combine、()? A. Reduce B.Hash C. Clean D. Loading 3、在Spak的软件栈中,用于交互式查询的是 A. SparkSQL B.Mllib C.GraphX D. Spark Streaming 4、在数据量一定的情况下, MapReduce是一个线性可扩展模型,请问服务器数量与处( )理时间是什么关系? A数量越多处理时间越长 B.数量越多处理时间越短 C.数量越小处理时间越短 D.没什么关系 5、下列选项中,不是kafka适合的应用场景是? A.日志收集 B.消息系统 C.业务系统 D.流式处理 6、大数据的多样性使得数据被分为三种数据结构,那么以下不是三种数据结构之一的是 A.结构化数据 B.非结构化数据 C.半结构化数据 D.全结构化数据 7、下列选项中,不是人工智能的算法中的学习方法的是? A.重复学习 B.深度学习 C.迁移学习 D.对抗学习 8、自然语言处理难点目前有四大类,下列选项中不是其中之一的是 A.机器性能 B.语言歧义性 C.知识依赖 D.语境 9、传统的机器学习方法包括监督学习、无监督学习和半监督学习,其中监督学习是学习给定标签的数据集。请问标签为离散的类型,称为分类,标签为连续的类型,称为什么? A.给定标签 B.离散 C.分类 D.回归 10、中国移动自主研发、发布的首个人工智能平台叫做() A.九天 B. OneNET C.移娃 D.大云 11、HDFS中Namenodef的Metadata的作用是? A.描述数据的存储位置等属性 B.存储数据 C.调度数据 D. 12、电信行业的客户关系管理中,客服中心优化可以实现严重问题及时预警,请问是用的什么技术实现的? A大数据技术 B.互联网技术 C.游戏技术 D.影像技术 13、随着闭源软件在数据分析领域的地盘不断缩小,老牌IT厂商正在改变商业模式,向着什么靠拢? A.闭源 人工智能数据库系统优化的捷径 摘要:SQL语句的优化是将性能低下的SQL语句转换成目的相同的性能优异的SQL语句。文中主要介绍了利用人工智能自动SQL优化技术来优化数据库系统,并且简要介绍了几种常见的数据库系统优化方法。人工智能自动SQL优化就是使用人工智能技术,自动对SQL语句进行重写,从而找到性能最好的等效SQL语句。 一数据库性能的优化 一个数据库系统的生命周期可以分成:设计、开发和成品三个阶段。在设计阶段进行数据库性能优化的成本最低,收益最大。在成品阶段进行数据库性能优化的成本最高,收益最小。 数据库的优化通常可以通过对网络、硬件、操作系统、数据库参数和应用程序的优化来进行。最常见的优化手段就是对硬件的升级。根据统计,对网络、硬件、操作系统、数据库参数进行优化所获得的性能提升,全部加起来只占数据库系统性能提升的40%左右,其余的60%系统性能提升来自对应用程序的优化。许多优化专家认为,对应用程序的优化可以得到80%的系统性能的提升。 二应用程序的优化 应用程序的优化通常可分为两个方面:源代码和SQL语句。由于 涉及到对程序逻辑的改变,源代码的优化在时间成本和风险上代价很高,而对数据库系统性能的提升收效有限。 三为什么要优化SQL语句 SQL语句是对数据库进行操作的惟一途径,对数据库系统的性能起着决定性的作用。 SQL语句消耗了70%至90%的数据库资源。 SQL语句独立于程序设计逻辑,对SQL语句进行优化不会影响程序逻辑。 SQL语句有不同的写法,在性能上的差异非常大。 SQL语句易学,但难精通。 优化SQL语句的传统方法是通过手工重写来对SQL语句进行优化。DBA或资深程序员通过对SQL语句执行计划的分析,依靠经验,尝试重写SQL语句,然后对结果和性能进行比较,以试图找到性能较佳的SQL语句。这种传统上的作法无法找出SQL语句的所有可能写法,且依赖于人的经验,非常耗费时间。 四SQL优化技术的发展历程 第一代SQL优化工具是执行计划分析工具。这类工具针对输入的SQL语句,从数据库提取执行计划,并解释执行计划中关键字的含义。 第二代SQL优化工具只能提供增加索引的建议,它通过对输入的SQL语句的执行计划的分析,来产生是否要增加索引的建议。 第三代SQL优化工具不仅分析输入SQL语句的执行计划,还对输入的SQL语句本身进行语法分析,经过分析产生写法上的改进建议。 黑龙江大学计算机科学技术学院 1.智能 智能是一种认识客观事物和运用知识解决问题的综合能力。 2.什么叫知识? 知识是人们在改造客观世界的实践中积累起来的认识和经验 3.确定性推理 指推理所使用的知识和推出的结论都是可以精确表示的,其真值要么为真、要么为假。 4.推理 推理是指按照某种策略从已知事实出发利用知识推出所需结论的过程。 5.不确定性推理 指推理所使用的知识和推出的结论可以是不确定的。所谓不确定性是对非精确性、模糊型和非完备性的统称。 6.人工智能 人工智能就是用人工的方法在机器(计算机)上实现的智能,或称机器智能 7.搜索 是指为了达到某一目标,不断寻找推理线路,以引导和控制推理,使问题得以解决的过程。 8.规划 是指从某个特定问题状态出发,寻找并建立一个操作序列,直到求得目标状态为止的一个行动过程的描述。 9.机器感知 就是要让计算机具有类似于人的感知能力,如视觉、听觉、触觉、嗅觉、味觉10.模式识别 是指让计算机能够对给定的事务进行鉴别,并把它归入与其相同或相似的模式中。 11.机器行为 就是让计算机能够具有像人那样地行动和表达能力,如走、跑、拿、说、唱、写画等。 12.知识表示 是对知识的描述,即用一组符号把知识编码成计算机可以接受的某种结构。 13.事实 是断言一个语言变量的值或断言多个语言变量之间关系的陈述句 14.综合数据库 存放求解问题的各种当前信息 15.规则库 用于存放与求解问题有关的所有规则的集合 16.人工智能有哪些应用? 17.人工智能的研究目标 远期目标 揭示人类智能的根本机理,用智能机器去模拟、延伸和扩展人类的智能 涉及到脑科学、认知科学、计算机科学、系统科学、控制论等多种学科,并依赖于它们的共同发展 近期目标 人工智能与网络安全 【考点解析】 人工智能(Artificial Intelligence) , 英文缩写为AI 。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。 人工智能的应用: ①模式识别:指纹识别、语音识别、光学字符识别、手写识别等 ②机器翻译:语言翻译 ③智能机器人、计算机博弈、智能代理 ④其它:机器证明、数据挖掘、无人驾驶飞机、专家系统等 ●例题1:下列不属于人工智能软件的是:( C ) A、语音汉字输入软件 B、金山译霸 C、在联众网与网友下棋 D、使用OCR汉字识别软件 ●例题2.下列运用了人工智能技术的是(C ) A.播放视频 B.播放音乐 C.手写板输入汉字 D.键盘输入汉字 ●例题3.以下不属于人工智能技术应用的( B ) A.超级国际象棋电脑“深蓝二代” B.office软件 C.医疗专家系统 D.于机器人对话 ●例题4.某公司为了加强考勤管理,购置了指纹打卡机,这体现信息技术的( C ) A.多元性 B.网络化 C.智能化 D.多媒体化 ●例题5. 指纹识别属于人工智能学科中的( B ) A.字迹识别研究范畴 B.模式识别研究范畴 C.语音识别研究范畴 D.字符识别研究范畴 【考点】了解信息的发布与交流的常用方式 【考点解析】 信息发布 根据发布的方式:视觉:报纸、杂志、书籍听觉:广播视听:电影、电视、网络 根据发布主体分成三类:个人信息发布;行业信息发布;官方机构信息发布 因特网上信息发布的常用方式:E-mail(电子邮件) BBS(论坛公告板)QQ(同类的还有MSN等)博客(weblog) 信息发布的效果与以下三个方面有关:发布的时间与地点、媒体的发布速度、信息的保存时间 ●例题6:以下关于电子邮件的说法不正确的是: ( C ) A、电子邮件的英文简称是E-mail。 B、所有的E-mail地址的通用格式是:用户名@邮件服务器名 C、在一台计算机上申请的“电子邮箱”,以后只有通过这台计算机上网才能收信 D、一个人可以申请多个电子邮箱 补充:网络常用术语 站点(网站):是一组网络资源的集合。便于维护和管理 超级链接:用超级链接可以实现从一个网页到另一个目标的连接,这个目标可以是一个网页,也可以是图像、动画、视频,甚至可以是一 个可执行程序 超文本:主要以文字的形式表示信息,建立链接关系主要是在文本间进行防火墙:是指一个或一组系统,用来在两个或多个网络间加强防问控制,限制入侵者进入,从而起以安全防护的作用。 BBS:就是我们平时所说的论坛,我们可以在里面就自己感兴趣的话题发布信息或提出看法 E-mail:就是我们平时所说的电子邮件,其特点P91 ●例题7.下列不属于在因特网上发布信息的是( A ) A.将数据保存在光盘中 B.发送E-mail邮件 C.发表博客文章 D.与同学通过QQ聊天 ●例题8.利用业余时间创作了一段flash动画,想与远方的朋友一起分享,下列可供他发表改作品的途径有( C ) ①在因特网以网页形式发布②在论坛公告板BBS上发布③通过电子邮件发送给朋友④通过固定电话告诉朋友⑤通过网络聊天工具QQ传送 A. ①②③④⑤ B. ①②③④ C. ①②③⑤ D.②③④⑤ 机器学习与数据挖掘姓名:xxx班级:计xxx学号:xxxxx 机器学习与数据挖掘 随着互联网突飞猛进的发展,数据总量呈爆炸式增长,数据量从TB级别升到ZB级别别IDC报告称,未来10年数据总量将会增加50倍,应对如此的数据总量,相应管理数据仓库的服务器将增加10倍。目前主流的软件已经无法在合理的时间内针对如此数量级别的数据进行撷取、管理、处理并整理成能为决策提供帮助的信息。美国政府率先提出并启动了“大数据研究和发展计划”,标志着大数据已上升到国家意志,大数据时代到来。 数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。 机器学习”是人工智能的核心研究领域之一,其最初的研究动机是为了让计算机系统具有人的学习能力以便实现人工智能,因为众所周知,没有学习能力的系统很难被认为是具有智能的。目前被广泛采用的机器学习的定义是“利用经验来改善计算机系统自身的性能”。事实上,由于“经验”在计算机系统中主要是以数据的形式存在的,因此机器学习需要设法对数据进行分析,这就使得它逐渐成为智能数据分析技术的创新源之一,并且为此而受到越来越多的关注。 “数据挖掘”和“知识发现”通常被相提并论,并在许多场合被认为是可以相互替代的术语。对数据挖掘有多种文字不同但含义接近的定义,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程”。其实顾名思义,数据挖掘就是试图从海量数据中找出有用的知识。大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。数据挖掘与机器学习的关系如图一所示: 数据挖掘 数据分析技术数据管理技术 机器学习数据库 图一数据挖掘与机器学习的关系 实际上,机器学习和数据挖掘技术已经开始在多媒体、计算机图形学、计算机网络乃至 数据库技术实现与人工智能融合的方法 发表时间:2019-09-16T15:23:49.090Z 来源:《基层建设》2019年第17期作者:张培颖[导读] 摘要:在现实生活中,数据库技术和人工智能有着紧密的联系,在人们思想地位中,人工技能只是具备单一的理论性,数据库则是大量的应用在实际操作中。 天津中发智能科技有限公司天津 300392摘要:在现实生活中,数据库技术和人工智能有着紧密的联系,在人们思想地位中,人工技能只是具备单一的理论性,数据库则是大量的应用在实际操作中。人工智能在发展初期的时候,就和数据库有着紧密联系,任何一个数据系统都是应用计算机进行操作,人工智能将使得计算机在实际使用中发挥出最大功效,以展现出人工智能和数据库的融合作用。下面就基于作者实际工作经验,简要的分析数据库 技术实现人工智能融合的方向,希望对相关从业人员有所帮助。 关键词:数据库发展;人工智能;融合方法 1 数据库的现阶段发展现状分析 1.1数据库飞速的发展 数据库的先进技术主要是计算机的重要分支点,充分展现出高科技技术重要性,数据库有着突破性的进展,在数据库的形成最初过程中,以网状数据库和关系数据库为主,而这两种数据库的使用还存在着诸多和不足之处,经过发明和研究,人们创造出技术先进、使用性方便的数据库管理系统,可以有效的弥补数据库中存在的不足之处。 在人们的生活、工作过程中,数据库起到重要的作用,在当前社会正处在高科技的发展阶段,应用先进的系统能够对工作负担进行降低,以有效的提升工作的效率,数据库对数值的保存和计算有着绝对的优势,数据库不仅能够长久性的保存相关数值,还能够对近期数值进行准确计算。如果说某单位计算员工的工资,以往的人工计算方式需要计算出勤、迟到、薪酬、奖金,每一项数据都应手动计算,降低工作效率的同时存在数值偏差现象,而数据库的使用不但准确率较高,且计算时间较短,在短时间内计算出准确数值,是数据库存在的优点之一。 1.2 数据库安全使用性能 数据库的使用范围较为广泛,现如今的工作学习中都离不开数据库的应用,为人们提供方便快捷的有利条件。以往的模式中主要以文件管理为主,只是单一的保管文件,并且文件存放比较分散,工作中需要寻找资料时,往往需要大量时间,而数据库避免了这一现象的发生,数据库保存数据较为集中,相关的数据只保存在一个表格当中,工作中可对相应数值一目了然,避免查找的繁琐过程,提高工作效率。数据库还具备一致性与可维护性,保证了数据库的安全性与可靠性,数据库的具有防止数据丢失与越权使用两种性能,由于数据库的存放时间较长,对保存时间没有规定,使用数值不存在限制,提升数据数值的使用性。数据库数值具有一致性的使用特点,任何数值都具有唯一性,减少数值差的存在,为工作提供便利条件,提高工作效率。数据库的最大的优点便是故障修护系统,数据库具有相应的数据库管理系统,可发现数据库的使用故障,并对数据库进行及时修复,防止整体数据库的破坏为工作带来不必要麻烦,数据库的修复系统可在较短时间内进行数据恢复,体现出数据库使用的方便性。 1.3 数据库的种类模式 数据库的种类与数值有着紧密联系,数值是指由组织形成的数据组成,数据分为逻辑结构与物理结构,两者密切配合提升数据库的使用效率。数据的逻辑结构主要以逻辑思维的角度观察数据,对数据进行透彻性分析,发现数值存在的问题,及时进行数据修改,避免工作中产生数据误差现象。 2 人工智能概况 在1956年,麦卡锡等人第一次使用人工智能这一术语,标志着人工智能正式诞生。人工智能是控制论、信息论、系统论、计算机科学、神经生理学、心理学、数学、哲学等学科相互交叉渗透的产物,它与空间技术、能源技术一起被称为世界三大尖端技术。各领域的专家学者将人工智能与本专业技术相结合,取得了一个又一个令人注目的成果。虽然人工智能的发展经历了风风雨雨,但它已取得的成就不得不令人惊叹。人工智能的不断发展,已产生许多分支,模糊逻辑、专家系统、神经网络、遗传算法是其中最为活跃的四大分支。 3 人工智能的实现 为了将人工智能的理论研究成果应用于实际,人们发明了多种方法。目前大部分的人工智能应用系统是在冯?诺依曼结构的通用数字计算机或通用算机上运行求得结果。这种用软件实现的方法灵活性强但速度较慢。从原理上讲,几乎所有的编程语言均可用于解决人工智能算法,但从编程的便捷性和运行效率考虑,最好选用“人工智能语言”。常用的人工智能语言有传统的函数型语言Lisp、逻辑型语言Prolog 及面向对象语言Smalltalk、VC++及VB等。 为了缩短人工智能应用程序的开发周期,人们还研制出了多种专用开发工具,如MathWorks公司推出的高性能数值计算可视化软件Matlab中包含有神经网络工具箱,提供了许多Matlab函数。另外,还有多种专家系统工具用于开发特定领域的专家系统,如INSIGHT、GURU、CLIPS、ART等。这些实用工具为开发人工智能应用程序提供了便利条件。在硬件方面,随着微电子技术的发展,出现了非冯诺依曼结构微处理器,给人工智能信息处理带来了新的生机和活力。DSP是其中的典型产品,它放弃了冯诺依曼结构而采用了哈佛结构,即将程序指令与数据的存储空间分开,各有自己的数据与地址总线,使得处理数据和指令可以同时进行,大大提高了运行速度。在那些因受传统微处理器速度和结构限制而难以实现复杂算法及难以达到要求速度的场合,可考虑选用DSP。高速DSP芯片已被认为是模拟神经特性的理想工具,并可直接用在将来的神经网络计算机中。同时,各大芯片生产厂商已研制出各种专用模糊芯片和神经网络芯片,用专用芯片比用软件方法实现速度快得多,当系统较复杂或速度要求较高时,可选用这些专用芯片,但专用芯片的价格较昂贵。 4 实现数据技术与人工智能结合的重要性 4.1 人工智能系统的应用 人工智能系统是相对人类智能而言,主要是指在机械或电子产品中加入智能设备,使其使用功能有所提升。人工智能主要利用先进的电子技术进行仿生学研究,从整体结构模拟人脑活动。电子计算机是人工智能技术的重要表现,其具有高效、快速的特点,在计算机的使用过程中必须受到人脑的控制,在接收相应的指令后方可进行工作。人工智能是由人造机器产生的,随着人们不断传入新知识,计算机使用范围将更广。 《探索大数据与人工智能》习题库 单选 1、Spark Streaming是什么软件栈中的流计算 A. Spark B. Storm C. Hive D. Flume 2、下列选项中,不是大数据发展趋势的是 A. 大数据分析的革命性方法出现 B. 大数据与与云计算将深度融合 C. 大数据一体机将陆续发布 D. 大数据未来可能会被淘汰 3、2011年5月是哪家全球知名咨询公司在《 Big data: The next frontier for innovation, competition and productivity 》研究报告中指出,数据已经渗透到每一个行业和业务职能之中,逐渐成为重要的生产因素的 A.比尔·恩门 B. 麦肯锡 C. 扎克伯格 D. 乔图斯 4、以下哪个属于大数据在电信行业的数据商业化方面的应用 A.精准广告 B. 网络管理 C. 网络优化 D. 客服中心优化 5、以下哪个不属于大数据在电信行业的应用 A.数据商业化 B. 物流网络 C. 企业运营 D. 客户关系管理 6、2012年7月,为挖掘大数据的价值,阿里巴巴集团在管理层设立()一职,负责全面推进“数据分享平台”战略,并推出大型的数据分享平台。 A.首席数据官 B. 首席科学家 C. 首席执行官 D. 首席架构师 7、下列选项中,不是kafka适合的应用场景是 A.日志收集 B. 消息系统 C. 业务系统 D.流式处理 8、下列选项中,哪个不是HBASE的特点 A.面向行 B. 多版本 C. 扩展性 D. 稀疏性 9、在数据量一定的情况下,MapReduce是一个线性可扩展模型,请问服务器数量与处理时间是什么关系 A.数量越多处理时间越长 B. 数量越多处理时间越短 B.数量越小处理时间越短 D.没什么关系 10、在Spark的软件栈中,用于机器学习的是 A.Spark Streaming B. Mllib C. GraphX 11、Spark是在哪一年开源的 A.1980 B. 2010 C. 1990 D. 2000 12、大数据的多样性使得数据被分为三种数据结构,那么以下不是三种数据结构之一的是 第一章:P23 1.人工智能 人工智能就是用人工的方法在机器(计算机)上实现的智能,或称机器智能 第二章:P51 5.(1)有的人喜欢打篮球,有的人喜欢踢足球,有的人既喜欢打篮球又喜欢踢足球。 定义谓词:LIKE(x,y):x喜欢y。 PLAY(x,y):x打(踢)y。 MAN(x):x是人。 定义个体域:Basketball,Soccer。 ( $x)(MAN(x) → LIKE(x,PLAY(x,Basketball))) ∨( $y)(MAN(y) → LIKE(y,PLAY(y,Soccer))) ∨( $z)(MAN(z) →LIKE(z,PLAY(z,Basketball)) ∧ LIKE(z,PLAY(z,Soccer)) (2)并不是每个人都喜欢花。 定义谓词:LIKE(x,y):x喜欢y。 P(x):x是人 定义个体词:flower ?("x)(P(x) → LIKE(x,flower)) (3)欲穷千里目,更上一层楼。 定义谓词:S(x):x想要看到千里远的地方。 H(x):x要更上一层楼。 ("x)(S(x) → H(x)) 6. 产生式通常用于表示具有因果关系的知识,其基本形式是: P→Q 或者 If P Then Q [Else S] 其中,P是前件,用于指出该产生式是否可用的条件。Q是一组结论或者操作,用于指出当前提P满足时,应该得出的结论或者应该执行的操作。 区别:蕴含式只能表示精确知识;而产生式不仅可以表示精确知识,还可以表示不精确知识。 产生式中前提条件的匹配可以是精确的,也可以是非精确的;而谓词逻辑蕴含式总要求精确匹配。 7.一个产生式系统一般由三部分组成:规则集、全局数据库、控制策略。 步骤:1)初始化全局数据库,把问题的初始已知事实送入全局数据库中 2)若规则库中存在尚未使用的规则,而且它的前提可与全局数据库中的已知事实匹配,则转3),若不存在则转5) 3)执行当前选中的规则,并对该规则做标记,把该规则执行后得到的结论送入全局数据库中。如果该 1.人工智能概念:人造智能,其英文表示是“Artifical Intelligence”,简称AI。 “人工智能”一词目前是指用计算机模拟或实验的智能,因此人工智能又称机器智能。2.框架的概念: 顾名思义,框架(frame)就是一种结构,一种模式,其一般形式是: <框架名> <曹名1><槽值1>|<侧面名11><侧面值111,侧面值112,···> <侧面名12><侧面值121,侧面值122,···> · <曹名2><槽值2>|<侧面名21><侧面值211,侧面值212,···> <侧面名22><侧面值221,侧面值222,···> · <曹名k><槽值k>|<侧面名k1><侧面值k11,侧面值k12,···> <侧面名k2><侧面值k21,侧面值k22,···> · 即一个框架一般有若干个槽,一个槽有一个槽值或者有若干个侧面 3.人工智能实际上是一门综合性的交叉学科和边缘学科。 4.数据挖掘(也称数据开采、数据采掘等)和数据库中的知识发现的本质含义是一样的,只是前者主要流行于统计、数据分析、数据库和信息系统等领域, 后者则主要流行于人工智能和机器学习等领域。 5.PROLOG语言只有三种语句,分别称为事实、规则和问题。 6. PROLOG中称无值的变量为自由变量,有值的变量为约束变量。 7.一个完整的Turbo PROLOG程序一般包括常量段、领域段、数据字段、谓词段、目标段和 子句段等六个部分。(加粗字体为常用部分) 8.在状态图中寻找目标或路径的基本方法就是搜索。 9.搜索方式:树式搜索和线式搜索。 10.树式搜索:形象的讲就是以“画树”的方式进行搜索。即从树根(初始节点)出发,一笔。 一笔地描出一棵树来。准确地讲,树式搜索就是在搜索过程中记录所经过的所 有节点和边。所以,树式搜索所记录的轨迹始终是一棵“树”。 11.有界深度优先搜索:给出了搜索树深度限制,当从初始节点出发沿某一分枝扩展到一限 定深度时,就不能再继续向下扩展,而只能改变方向继续搜索。 12.启发式搜索:利用启发性信息进行制导的搜索。启发性信息就是有利于尽快找到问题之 解的信息. 13.遗传算法(GA):人们从生物界按自然选择和有性繁殖、遗传变异的自然进化现象中得到 启发,而设计出来的一种优化搜索算法。 14.遗传算法的三种运算:选择-复制、交叉和变异。 15.原子公式是谓词公式。 16.P97 辖域、约束变元和自由变元能分清就可以。 17.设A为如下形式的谓词公式:B1∧B2∧···∧Bn其中Bi(i=1,2,····,n)形如 L1∨L2∨···∨Lm,Li(j=1,2,···,m)为原子公式或其否定,则A称为合取范式。18.设A为如下形式的命题公式:B1∨B2∨···∨Bn其中Bi(i=1,2,····,n)形如 L1∧L2∧···∧Lm,Li(j=1,2,···,m)为原子公式或其否定,则A称为析取范式。 (要求会分辨合取范式和析取范式) 19.设L为一个文字,则称L与﹁L为互补文字。 20.设C1,C2是命题逻辑中的两个子句,C1中有文字L1,C2中有文字L2,且L1与L2互补, 论人工智能和数据库技术的融合 沐爱敏合肥工业大学管理学院2010级21班201011211236 摘要:为了促进数据库技术与人工智能的融合和共同发展,从人工智能和数据库不同的研究层次出发,详细地剖析了人工智能与数据库技术之间存在 的紧密联系。 关键词:人工智能数据库技术融合DBMS 1.引言 在以往的研究中,人工智能大多偏重于理论,而数据库偏重于应用。但是,实际上,人工智能从发展初期就与数据库有着非常紧密的联系。任何一个智能系统都要借助于计算机来实现,而在实现智能系统的计算机中,知识库都是以数据库的形式存在的。不仅如此,近几年来,随着数据库在应用中的不断深化,提出DBMS应当能够自动有效的管理超大规模数据库,即vLDB(VeryLargeDataBase),并能够以数据驱动的方式自动为决策者提供决策,也就是使DBMS对数据的管理更加智能化。因此,数据库技术很自然地就同人工智能的某些方面的研究不谋而合,如机器学习、自然语言理解、智能检索等。这就给了我们一些启示,即可以把人工智能领域中的研究成果移植到数据库中,或者把数据库技术引入到人工智能领域,使二者得到完美结合,从而促进二者的共同发展。 2.人工智能的概述 人工智能(AI), 英文单词artilect ,来源于雨果·德·加里斯的著作 2.7解:根据谓词知识表示的步骤求解问题如下: 解法一: (1)本问题涉及的常量定义为: 猴子:Monkey,箱子:Box,香蕉:Banana,位置:a,b,c (2)定义谓词如下: SITE(x,y):表示x在y处; HANG(x,y):表示x悬挂在y处; ON(x,y):表示x站在y上; HOLDS(y,w):表示y手里拿着w。 (3)根据问题的描述将问题的初始状态和目标状态分别用谓词公式表示如下: 问题的初始状态表示: SITE(Monkey,a)∧HANG(Banana,b)∧SITE(Box,c)∧~ON(Monkey,Box)∧~HOLDS(Monkey,Banana) 问题的目标状态表示: SITE(Monkey,b)∧~HANG(Banana,b)∧SITE(Box,b) ∧ON(Monkey,Box)∧HOLDS(Monkey,Banana) 解法二: (1)本问题涉及的常量定义为: 猴子:Monkey,箱子:Box,香蕉:Banana,位置:a,b,c (2)定义谓词如下: SITE(x,y):表示x在y处; ONBOX(x):表示x站在箱子顶上; HOLDS(x):表示x摘到了香蕉。 (3)根据问题的描述将问题的初始状态和目标状态分别用谓词公式表示如下: 问题的初始状态表示: SITE(Monkey,a)∧SITE(Box,c)∧~ONBOX(Monkey)∧~HOLDS(Monkey) 问题的目标状态表示: SITE(Box,b)∧SITE(Monkey,b)∧ONBOX(Monkey)∧HOLDS(Monkey) 从上述两种解法可以看出,只要谓词定义不同,问题的初始状态和目标状态就不同。所以,对于同样的知识,不同的人的表示结果可能不同。 2.8解:本问题的关键就是制定一组操作,将初始状态转换为目标状态。为了用谓词公式表示操作,可将操作分为条件(为完成相应操作所必须具备的条件)和动作两部分。条件易于用谓词公式表示,而动作则可通过执行该动作前后的状态变化表示出来,即由于动作的执行,当前状态中删去了某些谓词公式而又增加一些谓词公式从而得到了新的状态,通过这种不同状态中谓词公式的增、减来描述动作。 定义四个操作的谓词如下,操作的条件和动作可用谓词公式的增、删表示: (1)goto 以下不是大数据特征的是? A.数据体量大 B. 数据种类多 C. 价值密度高 D. 处理速度快 以下不是非结构化数据的项是? A.图片 B.音频 C.数据库二维表数据 D.视频 大数据的多样性使得数据被分为三种数据结构,那么以下不是三种数据结构之一的是? A.结构化数据 B.非结构化数据 C.半结构化数据 D.全结构化数据 电信行业的网络管理和优化包含了两部分的优化,下列选项中不在这两项优化之内的是? A.基础设施建设的优化 B.网络速度的优化 C.并发性的优化 D.网络运营管理及优化 以下哪些属于大数据在电信行业的应用? A.网络管理和优化 B.数据商业化 C.客户关系管理 D.企业运营管理 语音识别产品体系有四部分,下列哪项不是体系之一? A.语音合成 B.语音播放 C.语音识别 D.语义理解 以下哪种学习方法不属于人工智能算法? A.迁移学习 B.对抗学习 C.强化学习 D.自由学习 人工智能通过输入的图片,解析出图片的内容,这种技术叫什么? A.图片识别 B.语音识别 C.自动驾驶 D.消费金融 以下用到语音识别技术的应用包括: A.苹果手机Siri B.微信 C.百度地图 D.word 下列选项属于人工智能的基本概念有: A.机器学习 B.深度学习 C.BP神经网络 D.卷积神经网络 Spark是在哪一年开源的? A.1980 B.2010 C.1990 D.2000 下列选项中,哪项是分布式文件存储系统? A.HDFS B.Flume C.Kafka D.Zookeeper MPP是指? A.大规模并行处理系统 B.受限的分布式计算模型 C.集群计算资源管理框架人工智能地研究方向和应用领域
探索大数据和人工智能最全试题
人工智能数据库系统优化的捷径
人工智能复习试题和答案
人工智能与网络安全(带答案)
人工智能与数据挖掘
数据库技术实现与人工智能融合的方法
探索大数据与人工智能习题库
人工智能-课后作业
人工智能复习资料
论人工智能和数据库技术的融合
人工智能原理与应用 (张仰森 著) 高等教育出版社 课后答案
探索大数据和人工智能-97分