计量地理学复习重点
计量地理学复习资料(整合版)

计量地理学复习资料(整合版)计量地理学是地理学中的一个重要分支,它将统计学和计算机科学与地理学的空间分析和模拟中结合,旨在开发能够理解和解释地理现象的数学模型。
本文档汇总了一些计量地理学的复习资料,涵盖了一些常用的概念、方法和应用,供需要的读者参考。
基础知识地理数据地理数据是计量地理学分析的基础,因此了解地理数据的类型和特征至关重要。
地理数据的主要类型包括矢量数据和栅格数据,矢量数据是基于向量的图形表示,栅格数据则是基于像素的网格表示。
空间分析空间分析是计量地理学的核心任务之一,它分为几个部分,包括空间接近度分析、空间自相关分析和空间回归等。
这些方法可以用来分析地理现象和探索空间模式的存在、性质和结构。
空间统计空间统计是计量地理学应用最广泛的技术之一,它是将统计学和空间分析相结合的一种方法,可以用来研究空间自相关性和空间变异性等相关问题。
空间统计主要包括空间插值、空间自相关分析、克吕金插值、多元回归分析以及地理加权回归等。
相关方法空间权重矩阵空间权重矩阵是计量地理学分析空间模式时最基本的概念。
它描述了某些地理单元之间的空间关系,可以用于识别地理单元之间的相互影响和作用,从而帮助研究者更好地理解地理现象。
空间自相关性空间自相关性是指同一地理单元内的观测结果间或不同地理单元之间的观测结果间的相关性。
空间自相关性可以通过空间权重矩阵来进行计算和分析,也可以通过地理数据的可视化来进行直观的理解。
空间模型空间模型是计量地理学中离不开的一种分析方法,它可以对地理现象进行建模并探索空间结构和空间相关性。
一些常见的空间模型包括OLS回归、空气质量模型和空间蒙特卡罗方法等。
空间数据挖掘空间数据挖掘是计量地理学中基于可视化和数据分析的方法之一,它可以用来从大规模的地理数据中发现有趣的模式、关系和趋势,以便对地理现象做出更好的解释和预测。
应用实例路网分析路网分析是计量地理学中基于GIS数据的常见应用之一,主要包括路径分析、网络可达性分析和路径优化分析等。
计量地理学复习要点

第1章绪论近代地理学有3种主要学派:区域学派, 代表人物是赫特纳、哈特向人地关系学派代表人物是洪堡、李特尔、李希霍芬等。
景观学派代表人物是施吕特尔等。
区域学派的主要观点:地理学的研究对象是区域,研究目标是描述和解释地球表面区域的差异性;在地理学中不存在法则,地理学只能以区域为单元进行类型研究;专论地理学是地理学研究的起点,区域地理学是地理学研究的终点;区域地理的样板,包括区域内的地质、地形、水文、动植物和人类各要素及其相互关系计量运动主要是由美国地理学家发起的,形成了3大学派:①艾奥瓦的经济派代表人物是舍弗尔、麦卡尔蒂。
受杜能、廖什、克里斯塔勒等区位论学者影响很深,极力倡导建立地理学法则,着重探讨经济区位现象间相互内在联系及其组合类型。
②威斯康星的统计派代表人物是威弗尔、罗宾逊、东坎和仇佐里。
以经典著作《计地理学》为代表作,主要特征是发展和应用统计分析方法。
③普林斯顿的社会物理学派代表人物是司徒瓦特(J.Q. Stewart)。
该派把物理学原理应用于社会现象的研究之中,发展了理论地理学中的引力模型、位势模型、空间相互作用模式。
计量地理学的发展阶段第一阶段(20世纪50年代末期到60年代末期)把统计学方法引入地理学研究领域,构造一系列统计量来定量地描述地理要素的分布特征,应用各种概率分布函数、方差等简单的统计特征回归分析方法。
分布中心、区域形状、地理要素分布的集中和离散程度等都有了定量指标,许多地理要素间的相关关系,也可以进行定量地表示。
第二阶段(20世纪60年代末期到70年代末期)多元统计分析方法和电子计算机技术在地理学研究中广泛应用。
以电子计算机技术为手段,许多地理学家熟练地掌握了多元统计方法,具备了分析多因素、复杂结构和动态特征等复杂地理问题的能力。
第三阶段(20世纪70年代末期开始到80年代末期)系统理论、系统分析方法、系统优化方法、系统调控方法等被引进地理学研究领域,促进了运筹学中的规划方法、决策方法、网络分析方法,以及数学物理方法、模糊数学方法、分形几何学方法、非线性分析方法等一系列现代数学方法的形成。
计量地理学复习资料(整合版)

计量地理学复习资料(整合版)计量地理学复习资料⼀、填空题1、近代地理学的发展,曾形成了三种主要学派,即区域学派、⼈地关系学派、景观学派。
2、计量运动,主要是美国地理学家发起的。
3、计量运动的三⼤学派(依阿华的经济派)、(威斯康星的统计派)、(普林斯顿的社会物理学派)。
4、计量地理学的应⽤:相互关系分析、趋势⾯分析、空间相互分析、分布型分析、⽹络分析(总共12点,只要写⼏点,其余⾃⼰看书)5、标准正态分布的偏度系数、峰度系数与0的关系。
偏度系数:g1<0表⽰负偏,即均值在峰值左边;g1>0即正偏,均值在峰值右边,g1=0,对称分布。
峰度系数:g2=0表⽰标准正态分布,g2>0⾼于正态分布,g2<0低于正态分布。
6、锡尔系数越⼤,就表⽰收⼊分配差异越⼤;反之,锡尔系数越⼩,就表⽰收⼊分配越均衡。
7、趋势拟合⽅法:㈠平滑法⒈移动平均法(公式,可能考计算,74页)⒉滑动平均法(同上)⒊指数平滑法(填空,75页的最后⼀段)8、地理数据的统计处理内容包括哪两个⽅⾯: 进⾏统计整理;计算有关统计指标和参数。
9、地理数据的基本特征:⼀、数量化、形式化与逻辑化⼆、不确定性三、多种时空尺度四、多维性10、地理数据采集的渠道来源----书上25页11、填写下图的偏态类型(1)(正态分布);(2)(正偏态);(3)(负偏态)12、判断下列图中平均数、中位数、众数的⼤⼩。
(1)(=Me =Mo );(2)( > Me>Mo );(3)(分布类型、连续区域分布类型)。
14、根据测度标准,可以将数量标志数据划分为_间隔尺度数据_和⽐例尺度数据。
15、地理现象的分布格局,常常⽤地理数据分布的集中化程度和均衡度来描述。
16、地统计学:以区域化变量理论为基础,以变异函数为主要⼯具,研究那些在空间分布上既有随机性⼜有结构性或空间相关和依赖性的⾃然现象的科学。
地统计学的两个最基本函数:协⽅差函数和变异函数。
计量地理学复习资料

计量地理学复习资料第⼀章绪论1、计量地理学的概念2、地理学的发展阶段古代地理学(19世纪以前)近代地理学(19世纪-20世纪50年代)现代地理学(20世纪60年代以来)3、现代地理学发展史上的计量运动⾐阿华的经济学派威斯康星的统计学派普林斯顿的社会物理学派其他……4、计量地理学的发展阶段初期:50年代末-60年代末中期:60年代末-70年代末从70年代末期开始⾄今5、计量地理学的研究对象空间与过程的研究(空间分布与演化过程)⽣态研究(PRED系统)区域研究(地域综合体)6、计量地理学与传统地理学的研究对象有什么区别?传统地理学观察、分类、⽐较、综合、描述计量地理学假说-模式化-校验-解释-结论传统地理学的研究⽅法图⽰区域地理问题——对问题的思考——资料的收集——分类和分析——地理解释——关于问题的结论——⽐较计量地理学的研究⽅法图⽰现实世界的分系统——假说——模型——检验——解释——关于现实世界的结论(可以证明假说的正确与否)——理论——模型7、计量地理学研究的主要内容分布型研究相互关系研究类型研究⽹络分析趋势⾯分析8、计量地理学研究的主要内容空间相互作⽤分析:“地理流”系统仿真研究过程模拟与预测研究空间扩散研究空间⾏为研究地理系统优化调控研究9、计量地理学的研究⽅法⽐较A、传统地理学:常⽤归纳法。
概括来⾃观察。
难以避开观察到的是特殊情况或解释者的个⼈好恶。
B、计量地理学:通过假设予以条理化;经过模式化得出数据予以检验;若成功,建⽴法则和理论,否则重新建⽴假说。
10、计量地理学的研究⽅法计量地理学的研究⽅法有:地理系统分析随机数学⽅法的应⽤地理系统模拟电⼦计算机的应⽤11、计量地理学的发展趋势计量地理学和⽣产实践的进⼀步结合建设新的地理学理论地理信息系统的建⽴计量⽅法的发展第⼆章地理数据系统1、地理数据的类型根据地理数据本⾝性质不同:定性数据和定量数据根据地理数据来源及表征系统的特征不同:社会-经济数据和环境与⾃然资源数据;空间数据:仅表⽰某⼀特定⾓度下的世界,它是指单个地段或群体地区以位置为参照的数据⼀般以坐标表⽰。
计量地理复习资料

计量地理学定义:以数学方法为核心,以计算机方法和现代计算工具为基础,以各种地理现象为研究对象的一门交叉学科。
是数学方法与现代计算理论,计算方法与计算机技术在地理学研究领域内相互结合、相互渗透的产物,随着地理学发展的需要和科学技术的进步而产生和发展的一门学科。
1.计量地理学又称数量地理学或统计地理学或理论地理学,是用数学方法和计算机技术研究地理现象及地理要素的科学,是应用地理学的分支,是数学与地理学相交叉的学科。
2.近代计量地理学三种主要学科:区域学派、人地关系学派和景观学派。
3.计量运动主要有三种学派:依阿华的经济学派、威斯康星的统计派和普林斯顿的社会物理学派。
计量运动推动者:舍弗尔等人对区域学派的批评与否定,拉开了现代地理学发展史上的计量运动的帷幕.主要发起国家:美国美国计量运动的三种学派P3? 衣阿华的经济派。
代表人物是舍弗尔、麦卡尔蒂。
受杜能、廖什、克里斯泰勒等区位论学者影响很深,极力倡导建立地理学法则,着重探讨经济区位现象间相互内在联系及其组合类型。
? 威斯康星的统计派。
代表人物是威弗尔、罗宾逊、东坎和仇佐里,以经典著作《统计地理学》为代表作,主要特征是发展和应用统计分析方法。
? 普林斯顿的社会物理学派。
代表人物是司徒瓦特(J.Q. Stewart)。
该派把物理学原理应用于社会现象的研究之中,发展了理论地理学中的引力模型、位势模型、空间相互作用模式。
4.计量地理学的发展阶段:第一阶段【20世纪50年代末到60年代末期】初期阶段——该阶段把统计学方法引入地理学研究领域。
第二阶段【20世纪60年代末期到70年代末期】中期阶段——多元统计分析方法和电子计算机技术在地理学研究中广泛应用。
第三阶段【20世纪70年代末期开始到80年代末期】成熟与完善阶段——系统理论、系统分析方法、系统优化方法、系统调控方法等被引进地理学研究领域,同时GIS的发展为其提供了先进的技术手段支持。
第四阶段【20世纪90年代初至今】——计算地理:应用计算技术求解地理问题的理论、方法和过程,以及各种模型。
计量地理学复习资料

计量地理学复习资料1.最短途径:指网络分析中求算网络两点间的最短路程距离及其长度,以用于地理网络要素的决策服务。
P292.最优区位:指在给定若干需要服务设施的状况下,根据一定的最优化目的,拟定一种或多个新设施,从而为生产力布局和社会设施布点决策服务的最佳位址。
用途:重要用于找 工厂、设施等布局的最优位置。
3.偏有关分析:指在地理系统中进行多要素间有关分析时,而把其它要素视为常数来专门单独研究其中两个要素之间的互有关系亲密程度的有关分析。
4.逐步回归模型:以已知地理数据序列为基础,根据多元回归分析法和求解求逆紧凑变换法及双检查法而建立的能够反映地理要素之间变化关系的最优回归模型。
5.逐步回归分析:指在多元线性回归分析中,运用求解求逆紧奏变换法和双检查法,来研究和建立最优回归方程的并用于地理分析和地理决策的多元线性回归分析。
它实质上就是多元线性回归分析的基础上派生 一种研究和建立最优多元线性回归方程的算法技巧。
重要含义以下:1)逐步回归分析的理论基础是多元线性回归分析法;2)逐步回归分析的算法技巧是求解求逆紧奏变换法;3)逐步回归分析的办法技巧是双检查法,即引进和剔除检查法;4)逐步回归分析的核心任务是建立最优回归方程;5)逐步回归分析的重要作用是降维。
重要用途:重要用于因果关系分析、聚类分析、区域规划、综合评价等等。
6.马尔可夫分析法:指马尔可夫链的基础上,根据事件的现在概率状况预测其将来各个时期概率变动状况的一种事件发生概率的预测办法。
重要含义有下列几点:1)马尔可夫分析的理论基础是概率论与线性代数的理论和办法2)马尔可夫分析的数据基础是各状态发生的原始数据序列;3)马尔可夫分析的重要办法是正则矩阵的求证和状态概率预测的递推公式的应用;4)马尔可夫分析的核心任务是转移矩阵的求算;5)马尔可夫分析的充要条件是各状态发生的原始数据和转移矩阵的正则化求证;6)马尔可夫分析的最后目的是预测各状态将来若干时段发生的概率。
计量地理学复习资料
计量地理学复习资料一、填空题1、计量运动的三大学派(衣阿华的经济派)、(威斯康星的统计派)、(普林斯顿的社会物理学派)。
2、奥地利学者(贝特朗菲)首次提出系统的概念。
3、聚类分析统计量大致可分为两类(相似系数)、(距离系数)。
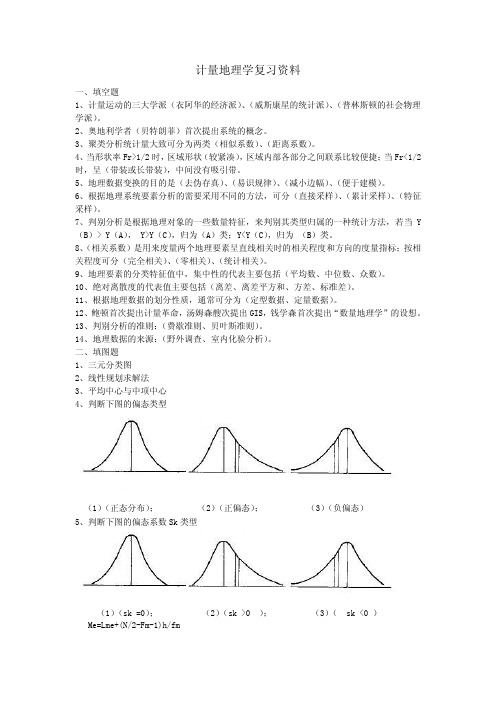
4、当形状率Fr>1/2时,区域形状(较紧凑),区域内部各部分之间联系比较便捷;当Fr<1/2时,呈(带装或长带装),中间没有吸引带。
5、地理数据变换的目的是(去伪存真)、(易识规律)、(减小边幅)、(便于建模)。
6、根据地理系统要素分析的需要采用不同的方法,可分(直接采样)、(累计采样)、(特征采样)。
7、判别分析是根据地理对象的一些数量特征,来判别其类型归属的一种统计方法,若当Y (B)> Y(A), Y>Y(C),归为(A)类;Y<Y(C),归为 (B)类。
8、(相关系数)是用来度量两个地理要素呈直线相关时的相关程度和方向的度量指标;按相关程度可分(完全相关)、(零相关)、(统计相关)。
9、地理要素的分类特征值中,集中性的代表主要包括(平均数、中位数、众数)。
10、绝对离散度的代表值主要包括(离差、离差平方和、方差、标准差)。
11、根据地理数据的划分性质,通常可分为(定型数据、定量数据)。
12、鲍顿首次提出计量革命,汤姆森艘次提出GIS,钱学森首次提出“数量地理学”的设想。
13、判别分析的准则:(费歇准则、贝叶斯准则)。
14、地理数据的来源:(野外调查、室内化验分析)。
二、填图题1、三元分类图2、线性规划求解法3、平均中心与中项中心4、判断下图的偏态类型(1)(正态分布); (2)(正偏态); (3)(负偏态)5、判断下图的偏态系数Sk类型(1)(sk =0); (2)(sk >0 ); (3)( sk <0 ) Me=Lme+(N/2-Fm-1)h/fm6、判断下列图中平均数、中位数、众数的大小。
(1)( =Me =Mo );(2)( > Me>Mo); (3)( <Me<Mo )7、添下表并计算中位数的大小。
计量地理学复习资料

计量地理学复习资料计量地理学是地理学中的一个重要分支,主要研究地理现象的测量与分析方法。
本文将从计量地理学的背景、基本原理和常用方法三个方面进行复习资料的介绍。
一、背景计量地理学的出现是为了解决地理学研究中的测量问题。
地理现象具有多样性和高度复杂性,如何准确测量和分析地理现象成为地理学家面临的挑战。
计量地理学通过引入数学、统计学和地理信息系统等方法,提供了一种科学的手段来量化和分析地理现象。
二、基本原理1. 空间分析原理空间分析是计量地理学的核心内容之一。
地理现象往往有着空间分布的特点,通过空间分析可以揭示地理现象的分布规律和相互关系。
常用的空间分析方法包括空间插值、空间自相关、空间交互作用等。
2. 统计学原理统计学是计量地理学的基础工具之一。
通过统计学的方法,可以对地理现象进行描述、分析和预测。
常用的统计学方法包括描述统计、推断统计和回归分析等。
3. 地理信息系统原理地理信息系统(GIS)在计量地理学中扮演着重要的角色。
GIS是将空间数据与属性数据相结合,进行处理、分析和管理的一种技术系统。
通过GIS,可以对地理现象进行可视化、空间查询和空间分析等。
三、常用方法1. 地理数据的收集和处理地理数据的收集和处理是计量地理学研究的基础。
地理数据可以通过田野调查、遥感影像解译、测量仪器和民众参与等方式获取。
在数据处理过程中,需要进行数据清洗、数据转换和数据标准化等操作,以提高数据的质量和可信度。
2. 空间数据分析空间数据分析是计量地理学的重要内容之一。
常用的空间数据分析方法包括空间差异分析、空间插值、空间自相关和空间回归等。
通过空间数据分析,可以揭示地理现象的空间分布规律,找出影响地理现象的因素,并进行空间预测和决策支持等。
3. 结构方程模型结构方程模型是一种多变量统计分析方法,常用于研究地理现象的复杂关系。
该模型结合了因果关系和测量模型,可以分析地理现象之间的潜在因果关系,并进行参数估计和模型检验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量地理学复习重点文件编码(008-TTIG-UTITD-GKBTT-PUUTI-WYTUI-8256)计量地理学大题:最短路径、最优区位、洛伦茨曲线、回归分析、聚类分析、马尔可夫题型:填空名词简答综合。
大家加油!最后一科考试了干巴爹!第一章1、计量地理学P1:是将数学和电子计算机技术应用于地理学的一门新兴学科,它是随着生产发展的需要和科学技术的进步而产生和发展起来的,反映了地理学朝着定量化方向发展的新趋势。
2、计量地理学的三大学派:P3(1)艾奥瓦的经济派:此学派受经济学影响较深,着重探讨经济区位现象健互相内在联系及其组合类型;(2)威斯康星的统计派:该学派以发展和应用统计分析方法为其主要特征;(3)普林斯顿的社会物理学派:把物理学原理应用于社会现象的研究,发展了理论地理学中的引力模型、位势模型、空间相互作用模式。
3、“新三论”P7:突变论、耗散结构、协同学“老三论”P7:系统论、控制论、信息论第二章1、空间数据P16:对于空间数据的表达,可以将其归纳为点、线、面三种几何实体以及描述它们之间空间联系的拓扑关系。
2、地理数据的基本特征:P19(1)数量化、形式化和逻辑化:数量化、形式化、逻辑化是数学的基本特征;地理数据的数量化、形式化与逻辑化,是对地理问题进行数学描述和定量化研究的前提,是一切数学方法在地理学中应用的先决条件;(2)不确定性:地理系统的复杂性决定了地理数据的不确定性;各种原因所导致的数据误差;(3)多种时空尺度:由于地理学的研究对象具有多种时空尺度,所以描述地理对象的地理数据也具有多种时空尺度的性质;(4)多维性:对于一个地理对象,它的具体意义往往需要从空间、属性、实间三个方面进行综合描述。
3、统计分组:是根据研究目的,按照一定的分组标志将地理数据分成若干组。
步骤:P24①求极差R(全距):R=Xmax -Xmin(一组数据的最大值和最小值)②确定组数n:组数的多少是根据样本容量的多少确定的,一般说,样本容量大,组数可多一些,反之就少。
可用Sturges公式计算:n=1+③计算组距h:即一组两头分界点距离h=R/N④计算组限Yi:即各组分界点的数值。
第一组下限y=Xmin-h;第一组上限=下限+组距⑤计算组中值:m=(上限+下限)/2集中化指数是一个描述地理数据分布的集中化程度的指数。
A——实际数据的累计百分比总和;R——均匀分布时的累计百分比总和;M——集中分布时的累计百分比总和。
集中化指数在[0,1]区间上取值。
4、简述描述地理数据一般水平的指标P25①平均值:指所有数据的和与样本总量的商,并分为分组的平均数和未分组的平均数。
②中位数:指将各个数据从小到大排列,居于中间位置的那个数,且中位数在频数分布图中居于中央,把面积等分为左右两部分,在累计频率图上,累计频率为50%所对应的数值③众数:指数据中出现频数最多的那个数,且在频数分布图上居最高点。
5、描述地理数据分布的离散程度的指标P27①极差:指所有数据中最大值与最小值之差。
②离差:指每一个地理数据与平均值的差,它代表着每一个地理数据与平均值的离散程度。
③离差平方和:指各个地理数据与平均值之差的平方的总和,它从总体上衡量一组地理数据与平均值的离散程度。
④方差:指各个数据分别与其平均数之差的平方的和的平均数。
⑤标准差:指方差的平方根。
(方差与标准差是从平均概况衡量一组地理数据与平均值的离散程度。
)⑥变异系数:表示了地理数据的相对变化(波动)程度6、描述地理数据分布特征的参数:P28(1)偏度系数:它测度了地理数据分布的不对称性情况,刻画了以平均值为中心的偏向情况。
g1<0,表示负偏,即均值在峰值的左边;g1>0,表示正偏,即均值在峰值的右边;g1=0,表示对称分布。
(2)峰度系数:它测度了地理数据在均值附近的集中程度。
标准正态分布的峰度系数g2=0;g2>0,表示地理数据分布的集中程度高于正态分布;g2<0,表示地理数据分布的集中程度低于正态分布。
7、洛伦茨曲线和集中化指数计算P30第三章讲义内容1、点状分布的测度:①最邻近距离的测度:地理事物点状分布的相对位置与其最邻近点之间的距离,是点型配置的重要特征。
顺序法和区域法所求得的最邻近距离的合计是一致的,但更高级位的平均距离是不一致的。
点型分布为随机型或均等型时用区域法,点型分布为凝集型时用顺序法。
②中间位置的测度:中项中心:两条相互垂直的直线的交叉点,这两条直线一般取南北向和东西向,每条直线将点状分布的点子二等分。
平均中心:也称分布重心,其确定方法如下,1任意在分布图上作x轴和y轴,通常这种数轴画在分布点的西侧和南侧。
2确定每一点的x轴和y轴坐标。
3计算x坐标轴和y坐标轴的平均值x,y,这里x,y就是平均中心c的坐标(x,y)③离散程度的测度。
2、网络图的概念:是一些点以及由点连成的直线所组成的图形,与通常所说的几何图形,函数图像完全不同,分为有何图与无何图。
3、运输系统网络的4个特征:①结点的直通性:表现在环中结点与网络中其他环路结点的联结状况,以及运输流在结点上与网络中其他结点的联结状况。
②道路系统的里程:以最小里程为标准,从哪一站出发到各站的里程最少。
③道路系统的运输量(吨公里):以运输量最少作为标准确定从哪一站出发到各站最优。
④考虑中转——运输费用的综合影响把中转因素考虑进去,会造成费用的增加。
第四章1、偏相关系数与复相关系数的区别:(1)偏相关系数:概念:在多要素所构成的地理系统中,先不考虑其他要素的影响,单独研究两个要素之间的相互关系的密切程度时,称为偏相关。
用以度量偏相关程度的统计量,称为偏相关系数。
偏相关系数的性质:①偏相关系数分布的范围在-1—1之间;②偏相关系数的绝对值越大,表示其偏相关程度越大;③偏相关系数的绝对值必小于或最多等于由同一系列资料所求得的复相关系数。
偏相关系数的显着性检验,一般采用t检验法。
(2)几个要素与某一个要素之间的复相关程度,用复相关系数来测定。
复相关系数的性质:①复相关系数介于0到1之间;②复相关系数越大,则表明要素之间的相关程度越密切。
复相关系数为1,表示完全相关。
复相关系数为0,表示完全无关;③复相关系数必大于或至少等于单相关系数的绝对值。
复相关系数的显着性检验,一般采用F检验法。
2、一级偏相关系数的计算P913、回归分析的计算P954、偏回归系数的意义P98:是当其他变量Xj(j不等于i)都固定时,自变量Xi 每变化一个单位而使因变量y平均改变的数值。
5、时间序列的组成成分:P108①长期趋势(T):是时间序列随时间的变化而逐渐增加或减少的长期变化之趋势。
②季节变动(S):是时间序列在一年中或固定时间内,呈现出的固定规则的变动。
③循环变动(C):又称景气循环变动,是指沿着趋势线如钟摆般地循环变动。
④不规则变动(R):是指在时间序列中由于随机因素影响所引起的变动。
6、时间序列的组合模型:P110(1)加法模型:加法模型假定时间序列是基于四种成分相加而成的。
(2)乘法模型:乘法模型假定时间序列是基于四种成分相乘而成的。
7、常用的聚类要素数据处理办法:P124(1)总和标准化法:分别求出各聚类要素所对应的数据的总和,以各要素的数据除以该要素的数据的总和;(2)标准差标准化:得到的数据各要素的平均值为0,标准差为1;(3)极大值标准化:所得的新数据,各要素的极大值为1,其余各数值小于1;(4)极差的标准化:得到的数据,各要素的极大值为1,极小值为0,其余的数值均在0和1之间。
8、常见的距离有P126:绝对值距离、欧式距离、明科夫斯基距离、切比雪夫距离9、主成分分析原理P135:是把原来多个变量划为少数几个综合指标的一种统计分析方法,从数学角度看,这是一种将维处理技术,即用较少的几个综合指标代替原来较多的变量指标,而且使这些较少的综合指标既能尽量多的反映原来较多变量指标所反映的信息。
10、主成分分析的步骤P136(1)计算相关系数矩阵(2)计算特征值与特征向量(3)计算主成分贡献率及累计贡献率(4)计算主成分载荷11、趋势面适度的逐次检验:P143①求出较高次多项式方程的回归平方和与较低次多项式方程的回归平方和之差;②将此差除以回归平方和的自由度之差,得出由于多项式次数增高所产生的回归平方差;③将此均方差除以较高次多项式的剩余均方差,得出相继两个阶次趋势面模型的适度性比较检验值F。
12、马尔克夫预测大题P14613、五种相关分析的原理和概念1相关系数是根据要素之间的样本值计算出来,它随着样本数的多少或取样方式的不同而不同,因此它只是要素之间的样本相关系数,只有通过检验,才能知道它的可信度。
检验是通过在给定的置信水平下,查相关系数检验的临界值表来实现的。
2秩相关系数:又称等级相关系数,或顺序相关系数,是将两要素的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量。
3偏相关系数定义:在多要素所构成的地理系统中,先不考虑其他要素的影响,而单独研究两个要素之间的相互关系的密切程度,这称为偏相关。
用以度量偏相关程度的统计量,称为偏相关系数。
4复相关系数:反映几个要素与某一个要素之间的复相关程度。
14、最短和最远距离聚类法P130第五章:1、确定空间权重矩阵的规则:(1)简单的二进制邻接矩阵:W ij={1 当区域i和j相邻接;0 其他}(2)基于距离的二进制空间权重矩阵:W ij={1 当区域i和j的距离小于d时;0 其他}2、Moran指数和Geary系数是两个用来度量空间自相关的全局指标。
Moran指数反映的是空间邻接或空间邻近的区域单元属性值的相似程度,而Geary系数与Moran指数存在负相关关系。
P1593、Moran指数I的取值一般在-1和1之间,小于0表示负相关,等于0表示不相关,大于0表示正相关;Geary系数C的取值一般在0和2之间,大于1表示负相关,等于1表示不相关,而小于1表示正相关。
4、Moran指数可以用标准化统计量Z来检验n个区域是否存在空间自相关相关关系:当Z值为正且显着是,表明存在正的空间自相关,也就是说相似的观测值(高值或低值)趋于空间集聚;当Z值为负且显着时,表明存在负的空间自相关,相似的观测值趋于分散分布;当Z值为零时,观测值呈独立随机分布。
P1615、全局G统计量的计算公式P163显着的正Gi值表示在该区域单元周围,高观测值得区域单元趋于空间集聚,而显着的负Gi值表示低观测值的区域单元趋于空间集聚,其具有能够探测出区域单元属于高值集聚还是低值集聚的空间分布模式。
局部G统计量不属于LISA,因为局部Gi统计量和全局G统计量没有比例关系。
6、Moran散点图的四个象限:分别对应于区域单元与其邻居之间四种类型的局部空间联系形式。