实验二 编写语法分析程序
【免费下载】语法分析程序

#include <stdio.h> #include <dos.h> #include <stdlib.h> #include <string.h>
char inputstr[50],d[200],e[10];/*数组 inputstr 存输入串,数组 d 存推导式,*/ int strlong=0,Total=0,count=0,n=4;
[实验目的]:
1.了解语法分析的主要任务。
2.熟悉编译程序的编制。
实验二 语法分析程序设计
计算机科学与技术(2)班
[实验内容]:根据某文法,构造一基本递归下降语法分析程序。给出分析过程
中所用的产生式序列。
[实验要求]:
1. 构造一个小语言的文法,例如,Pascal 语言子集的算术表达式文法:
G[<表达式>]:
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根通保据过护生管高产线中工敷资艺设料高技试中术卷资,配料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高与中带资负料荷试下卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并3中试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内 纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
编译原理语法分析实验报告

编译原理语法分析实验报告第一篇:编译原理语法分析实验报告实验2:语法分析1.实验题目和要求题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E→E+T|E-T|TT→T*F|T/F|F F→id|(E)|num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写递归调用程序实现自顶向下的分析。
方法2:编写LL(1)语法分析程序,要求如下。
(1)编程实现算法4.2,为给定文法自动构造预测分析表。
(2)编程实现算法4.1,构造LL(1)预测分析程序。
方法3:编写语法分析程序实现自底向上的分析,要求如下。
(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
方法4:利用YACC自动生成语法分析程序,调用LEX自动生成的词法分析程序。
实现(采用方法1)1.1.步骤:1)对文法消除左递归E→TE'E'→+TE'|-TE'|εT→FT'T'→*FT'|/FT'|εF→id|(E)|num2)画出状态转换图化简得:3)源程序在程序中I表示id N表示num1.2.例子:a)例子1 输入:I+(N*N)输出:b)例子2 输入:I-NN 输出:第二篇:编译原理实验报告编译原理实验报告报告完成日期 2018.5.30一.组内分工与贡献介绍二.系统功能概述;我们使用了自动生成系统来完成我们的实验内容。
我们设计的系统在完成了实验基本要求的前提下,进行了一部分的扩展。
增加了声明变量类型、类型赋值判定和声明的变量被引用时作用域的判断。
从而使得我们的实验结果呈现的更加清晰和易懂。
三.分系统报告;一、词法分析子系统词法的正规式:标识符(|)* 十进制整数0 |(1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)* 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和分隔符 +| * | / | > | < | = |(|)| <=|>=|==;对于标识符和关键字: A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε综上正规文法为: S—〉I1|I2|I3|A4|A5 I1—〉0|A1 A1—〉B1C1|ε C1—〉E1D1|ε D1—〉E1C1|εE1—〉0|1|2|3|4|5|6|7|8|9 B1—〉1|2|3|4|5|6|7|8|9 I2—〉0A2 A2—〉0|B2 B2—〉C2D2 D2—〉F2E2|ε E2—〉F2D2|εC2—〉1|2|3|4|5|6|7 F2—〉0|1|2|3|4|5|6|7 I3—〉0xA3 A3—〉B3C3 B3—〉0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f C3—〉(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)|C3|εA4—〉+ |-| * | / | > | < | = |(|)| <=|>=|==; A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε状态图流程图:词法分析程序的主要数据结构与算法考虑到报告的整洁性和整体观感,此处我们仅展示主要的程序代码和算法,具体的全部代码将在整体的压缩包中一并呈现另外我们考虑到后续实验中,如果在bison语法树生成的时候推不出目标的产生式时,我们设计了报错提示,在这个词的位置出现错误提示,将记录切割出来的词在code.txt中保存,并记录他们的位置。
实验二 语法分析器的设计与实现

实验二语法分析器的设计与实现
一、实验目的
构造一个小语言的语法分析程序。
二、实验要求
输入属性字文件,输出源程序是否符合语法要求的结果。
正确——该程序符合语法要求
错误——指出错误位置
三、实验说明
1、总体说明
构造并存储预测分析表,构造分析器,并能进行出错处理,实现LL(1)分析法。
设计好一个文法,消除文法的左递归性。
将消除了左递归性的文法,构造每个非终结符的FIRST和FOLLOW集合。
根据FIRST和FOLLOW集合构造LL(1)分析表。
然后,利用分析表,根据LL(1)语法分析构造一个分析器。
2、语法描述
文法:E→E+T | T
T→T*F | F
F→( E ) | i
经消去左递归后变成:E→TP
P→+TP | ε
T→FQ
Q→*FQ | ε
F→( E ) | i
3、设计原理
LL(1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a行事的。
对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:
(1)若X = a = ‘#’,则宣布分析成功,停止分析过程。
(2)若X = a ≠‘#’,则把X从STACK栈顶逐出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看分析表M。
②FOLLOW集合的构造算法
四、实验成果提交
1、非终结符的FIRST集合
2、非终结符的FOLLOW集合
3、预测分析表
4、程序流程图
5、源代码
6、程序运行说明及测试数据。
实验二语法分析

实验二、语法分析一、实验目的:设计MiniC的上下文无关文法,利用JavaCC生成调试递归下降分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对递归下降分析法的理解。
二、语法分析器:按照MiniC语言的语法规则检查词法分析输出的记号流是否符合这些规则,并根据这些规则所体现出的语言中的各种语法结构的层次性。
把规则写入到JavaCC的.jjt文件中,可以生成树状的层次结构。
三、JavaCC:在JavaCC的文法规范文件中,不仅可以描述语言的语法规范,而且可以描述词法规范,本次实习中,利用JavaCC以MiniC语言构造一个不含语义分析的编译器前端,包括词法分析、语法分析,并要考虑语法分析中的错误恢复问题。
通过使用JavaCC, 可以体会LL(k)文法的编写特点,掌握编写JavaCC文法规范文件的方法。
内容:利用JavaCC生成一个MiniC的语法分析器;要求:1.用流的形式读入要分析的C语言程序,或者通过命令行输入源程序。
2.具有错误检查的能力,如果有能力可以输出错误所在的行号,并简单提示3.如果输入的源程序符合MiniC的语法规范,输出该程序的层次结构的语法树具体实施步骤如下:1.把MiniC转换为文法如下Procedure()→void main() {WhileStatement()}WhileStatement()→while(Condition()){(WhileStatement()|assign())}assign()→<IDENTIFIER>= <CONSTANT>;expression()→term() (( + | - ) term())term()→unary() (( * | / ) unary())unary()→<CONSTANT>|<IDENTIFIER> | ( expression())Condition()→expression()(< expression()| > expression()| >= expression()| <= expression() )〈运算符〉→+|-|*|/〈关系符〉→<|<=|>|>=|==|!=2.在eclipse环境下完成JavaCC的插件安装后,写一个JavaCC文法规范文件(扩展名为jj)文件见附件wenfa.jjEclipse中文件结构如下:运行结果如下:3.完成的功能包括词法分析,语法分析(输出语法树),能够读文件,也能够把输出的结果保存文件中,可以把树的层次结果输出到文件中。
编译原理-语法分析程序报告

编译原理实验实验二语法分析器实验二:语法分析实验一、实验目的根据给出的文法编制LR(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对LR(1)分析法的理解。
二、实验预习提示1、LR(1)分析法的功能LR(1)分析法的功能是利用LR(1)分析表,对输入符号串自下而上的分析过程。
2、LR(1)分析表的构造及分析过程。
三、实验内容对已给语言文法,构造LR(1)分析表,编制语法分析程序,要求将错误信息输出到语法错误文件中,并输出分析句子的过程(显示栈的内容);实验报告必须包括设计的思路,以及测试报告(输入测试例子,输出结果)。
语法分析器一、功能描述:语法分析器,顾名思义是用来分析语法的。
程序对给定源代码先进行词法分析,再根据给定文法,判断正确性。
此次所写程序是以词法分析器为基础编写的,由于代码量的关系,我们只考虑以下输入为合法:数字自定义变量+ * ()$作为句尾结束符。
其它符号都判定为非法。
二、程序结构描述:词法分析器:class wordtree;类,内容为字典树的创建,插入和搜索。
char gettype(char ch):类型处理代入字串首字母ch,分析字串类型后完整读入字串,输出分析结果。
因读取过程会多读入一个字母,所以函数返回该字母进行下一次分析。
bool isnumber(char str[]):判断是否数字代入完整“数字串”str,判断是否合法数字,若为真返回1,否则返回0。
bool isoperator(char str[]):判断是否关键字代入完整“关键字串”str,搜索字典树判断是否存在,若为存在返回1,否则返回0。
语法分析器:int action(int a,char b):代入当前状态和待插入字符,查找转移状态或归约。
node2 go(int a):代入当前状态,返回归约结果和长度。
void printstack():打印栈。
int push(char b):将符号b插入栈中,并进行归约。
实验二语法分析程序的设计

一、实验目的和要求通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单次序列进行语法检查和结构分析,进一步掌握常用语法分析方法。
选择具有代表性的语法分析方法,如LL1(k)分析方法,递归子程序法,运算符优先数法,LR(k)分析方法之一进行设计;选择对各种常见程序语言都通用的语法结构,如赋值语句(尤指表达式)作为分析对象,并对所选的语法分析方法要比较贴切;先写出BNF定义,然后编写语法分析程序,调试。
(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
二、实验内容和原理A.对表达式,项,因子的BNF定义B.编写程序,自动识别是否为LL1文法,自动消除左递归。
C.输出first集,follow集,select集D.输出给定句型的LL1分析过程三、主要仪器设备pc一台,vc++6.0软件四、操作方法与实验步骤该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
流程图:五、实验结果与分析源程序:#include<stdlib.h>#include<stdio.h>#include<string.h>/*******************************************/int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){int i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}/*******************************************分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;j<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果‘|’后的首符号和左部相同*/ for(j=n+1;j<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果‘|’后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';printf(" count=%d ",count);m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/char grammer(char *t,char *n,char *left,char right[50][50]){char vn[50],vt[50];char s;char p[50][50];int i,j,k;printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的‘^ ’一并并入目串;type=2,源串中的‘^ ’不并入目串*/int i,j;for(i=0;i<=strlen(s)-1;i++){if(type==2&&s[i]=='^');else{for(j=0;;j++){if(j<strlen(d)&&s[i]==d[j])break;if(j==strlen(d)){d[j]=s[i];d[j+1]='\0';break;}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由‘^ ’推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)return(1);for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)return(1);else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/printf("\nerror1!");validity=0;return(0);}for(j=0;j<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为‘^ ’,报错*/printf("\nerror2!");validity=0;return(0);}}}return(1);}void first2(int i){ /*i为符号在所有输入符号中的序号*/ char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])break;if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;k<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&k<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&k==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/{if(p[0]=='^'){if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/ {for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)merge(first[i],first1[m],2);elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/if(k==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;n<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;n<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;j<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;j<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;j<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;j<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;i<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;j<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/ length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/ for(j=0;j<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(k==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;p<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){printf("\n ****************************************");int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n文法有效");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序六、讨论、心得语法分析是编译过程的核心部分,其基本任务是:根据语言的语法规则分析源程序的语法结构,并在分析过程中,对源程序进行语法检查,为语义分析和代码生成做准备。
实验二--语法分析报告程序的设计-

实验二语法分析程序的设计姓名:_ 学号:_ 专业班级一、实验目的通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析中预测分析方法。
二、实验内容设计一个文法的预测分析程序,判断特定表达式的正确性。
三、实验要求1、给出文法如下:G[E]E->T|E+T;T->F|T*F;F->i|(E);2、根据该文法构造相应的LL(1)文法及LL(1)分析表,并为该文法设计预测分析程序,利用C语言或C++语言或Java语言实现;3、利用预测分析程序完成下列功能:1)手工将测试的表达式写入文本文件,每个表达式写一行,用“;”表示结束;2)读入文本文件中的表达式;3)调用实验一中的词法分析程序搜索单词;4)把单词送入预测分析程序,判断表达式是否正确(是否是给出文法的语言),若错误,应给出错误信息;5)完成上述功能,有余力的同学可以进一步完成通过程序实现对非LL(1)文法到LL(1 )文法的自动转换(见实验二附加资料1)。
四、实验环境PC微机DOS操作系统或Windows操作系统Turbo C程序集成环境或Visual C++程序集成环境五、实验步骤1、分析文法,将给出的文法转化为LL(1)文法;2、学习预测分析程序的结构,设计合理的预测分析程序;3、编写测试程序,包括表达式的读入和结果的输出;4、测试程序运行效果,测试数据可以参考下列给出的数据。
六、测试数据/***/static String[] gram = { "E->TA", "A->+TA", "A->@", "T->FB", "B->*FB", "B->@","F->P", "F->(E)" };static Strin g[]TollowE = { ")", "#" };输入数据:编辑一个文本文文件 expression.txt ,在文件中输入如下内容:10; 1+2;(1+2)*3+(5+6*7); ((1+2)*3+4; 1+2+3+(*4+5); (a+b)*(c+d); ((ab3+de4)**5)+1;正确结果:(1) 10; 输出: 正确 (2) 1+2; 输出: 正确(3) (1+2)*3+(5+6*7); 输出: 正确(4)((1+2)*3+4 输出: 错误(5) 1+2+3+(*4+5) 输出: 错误 (6) (a+b)*(c+d) 输出: 正确(7) ((ab3+de4)**5)+1 输出: 错误七、源代码import java.util.*;import java.io.*; public class test2 {static String[] key_word = { "main"."if", "the n", "while", "do","int","else" };static Stri ng[] cal_word = { "+"II IIII /II-,,/ ,"<", ">", "{",")", "[", "]", "==""!=" "!""="">=" "<=""+=""-="给定文法 G[E] : E->T|E+T; T->F|T*F; F->i|(E);followEA = {")","#"}; followT = {"+",")","#" }; followTB = {"+",")","#"}; followF = {"*","+",")","#"}; firstE = { "i", "(" }; firstEA = { "+", "@" }; firstT = { "i", "(" }; firstTB = { "*", "@" }; firstF = { "i", "(" };static Stri ng[][] list = {{"", "i",{ "E", "TA", n ull, null, "TA", n ull, null }, { "A", null, "+TA", n ull, null, "@", "@" }, { "T", "FB", null, null, "FB", n ull, null }, { "B", null, "@", "*FB", n ull, "@", "@" }, { "F", "i", null, null, "(E)", n ull, null } }; public static void sca n( Stri ng in file,Stri ngoutfile,StackvString>[] word, Stack<String>[] expression)throws Exception {java.io.File file = new java.io.File(i nfile); Sca nner in put = new Scann er(file);java.io.Pri ntWriter output = new Prin tWriter(outfile); int count = 0;word[cou nt].push("#"); while (in put.hasNext()) {Stri ng tmp = in put .n ext(); int i = 0;while (i < tmp.le ngth()) {if (tmp.charAt(i) <= 9 && tmp.charAt(i) >= '1') {// 检查十进制数字Stri ng num ="";while (tmp.charAt(i) <= 9 &&tmp.charAt(i)>= '0'){num += tmp.charAt(i); i++;if (i == tmp 」en gth()) break;}output.pri ntln ("< " + 1 + ", " + num + ">"); word[co un t].push("i");expressi on[coun t].push( nu m); }if (i + 2 < tmp.le ngth())〃检查十六进制数字if (tmp.charAt(i) == 'O' &&tmp.charAt(i+ 1) == 'x'){i += 2;Stri ng num =""; while ((tmp.charAt(i)<= 9 && tmp.charAt(i) >= '0') ||static String static String static String static String static String static String static String static String static String(tmp.charAt(i)v='f&&tmp.charAt(i) >= 'a')) {num += tmp.charAt(i);i++;if (i == tmp .len gth()) break;}output.pri ntln ("v " + 3 + ", " + num + ">"); word[co unt].push("i");expressi on[coun t].push( nu m);}if (i + 1 < tmp.le ngth())〃检查八进制数字if (tmp.charAt(i) == '0') {i++;Stri ng num ="";while (tmp.charAt(i) <= '7' &&tmp.charAt(i) '0') {num += tmp.charAt(i);i++;if (i == tmp .len gth()) break;}output.pri ntln ("< " + 2 + ", " + num + ">"); word[co unt].push("i");expressi on[coun t].push( nu m);}//检查关键字和变量if (i < tmp.le ngth()) {if (i < tmp.le ngth() && tmp.charAt(i) >= 'a'&& tmp.charAt(i) <= 'z') { Stri ng tmp_word ="";while (tmp.charAt(i) >= 'a' &&tmp.charAt(i)'z') {tmp_word += tmp.charAt(i);i++;if (i == tmp .len gth()) break;}boolea n is_keyword = false;for (int j = 0; j < key_word .len gth; j++) { if(tmp_word.equals(key_word[j])) { output.pri ntln ("< " +key_word[j] + ">= v=实用文档word[co un t].push(key_word[j]);expressio n[co unt].push(key_word[j]); is_keyword =true;break;}}if (!is_keyword) {output.pri ntl n("v " + 0 + ", " + tmp_word+word[co un t].push("i");expressi on[coun t].push(tmp_word);} _}}//检查运算符以及';'if (i < tmp.le ngth()) {if (i + 1 < tmp.le ngth()) {if (tmp.charAt(i + 1) == '=') {for (int j = 0; j < cal_word .len gth; j++) { if tmp.charAt(i)(cal_word[j].equals(""+ tmp.charAt(i + 1))){ output.pri ntln ("v " +cal_word[j] ++ "->");word[co un t].push(cal_word[j]);expressi on[coun t].push("-");if (word[cou nt].peek() == ";"){ word[co un t].pop();word[cou nt].push("#"); count++;word[cou nt].push("#");}i += 2;break;}}}for (int j = 0; j < cal_word .len gth; j++) {if (cal_word[j].equals("" + tmp.charAt(i)))实用文档{ output.pri ntln ("< " + cal_word[j] + ", " +word[co un t].push(cal_word[j]);expressio n[count].push(cal_word[j]); if (word[count].peek() == ";") { word[co unt].pop(); word[cou nt].push("#");coun t++;word[cou nt].push("#");}i++;break;}}}}}in put.close();output.close();}}public static void main(String[] args) throws Exception { Stri ng in file = "D:/expressio n.txt";Stri ng outfile = "D:/result2.txt";StackvStri ng>[] tmpword = new Stack[20]; StackvString>[] expression = new Stack[20]; for(int i = 0; i < tmpword.length; i++) { tmpword[i] =new StackvStri ng>(); expressi on [i] = newStackvStri ng>();testl.scan(infile, outfile, tmpword, expression); int i = 0;while (tmpword[i].size() > 2){Strin g[] tmp = expressio n[ i].toArray( new Stri ng[0]); printArray(tmp);isLL1(tmpword[i]);i++;public static void prin tArray(Stri ng[] s){for (i nt i = 0; i < s.len gth; i++){System.out.pri nt(s[i]);System.out.pri ntl n();}public static void isLL1(Stack<Stri ng> tmpword){ Stri ng[] in put = tmpword.toArray( new Stri ng[0]); int in putCo unt = 0;StackvStri ng> status = new StackvStri ng>(); status.push(input[ in putCo un t++]); status.push("E"); boolea n flag = true;boolea n result = true;while (flag) {if (isVt(status.peek())){if (status.peek().equals(i nput[ in putCo unt])){ status.pop(); in putCo un t++; } else{flag = false; result = false; }else if (status.peek().equals(" '#")){if (status.peek().equals(i nput[ in putCo un t])) flag =false; else{flag = false; result = false; }public static boolea n isVt(Stri ng s) {//for (int i = 1; i < list[0].le ngth - 1; i++) { if (s.equals(list[0][i])) { return true; } } return false;}public static in t[] in dex In List(Stri ng m, String a) { int i= 0, j = 0;for (i nt c = 1; c < list.le ngth; c++) { if (m.equals(list[c][0])) i = c;for (int c = 1; c < list[0].length ; c++) { if (a.equals(list[0][c])) j = c;}retur n new in t[] { i, j };给定文法的LL (1)形式;flag = false; result = false; } }elseif (list[ in dex In List(status.peek(), in put[ in putCo un t])[0]][i ndex In List(status.peek(), input[inputCount])[1]] != null){ in t[] a = in dex In List(status.peek(), in put[ in putCo un t]); if (list[a[0]][a[1]].e ndsWith("@")) status.pop(); else{ status.pop(); for (i nt i = list[a[0]][a[1]].le ngth() - 1; i >= 0; i--){status.push ("” + list[a[0]][a[1]].charAt(i));else{ if (result)System.out.pri ntln( II else正确"); System.out.pri ntl n(II错误"); 判断是否为VtE->TAA->+TA| £T->FBB->*FB| £F->(E) | i实验结果:10;1+2;己氓(l+2)*3+(5+6*7);((l+2)*3+4;l+2+3+(*4+5); (^+b)*(C+d);((at>3+de4)**5)+l;。
编译原理语法分析实验报告
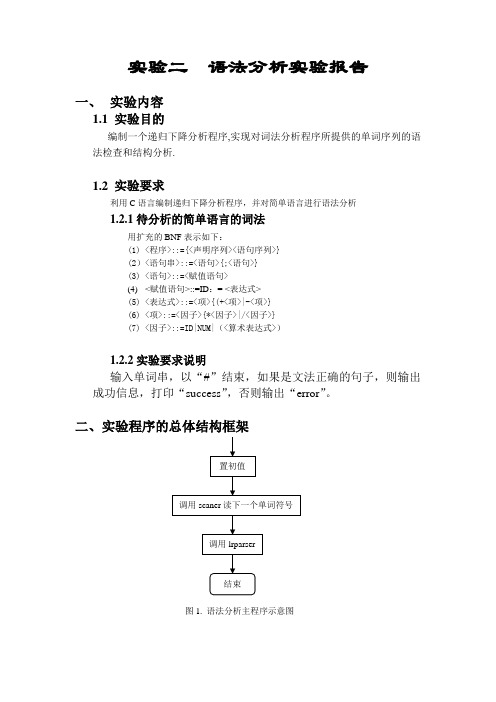
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验二编写语法分析程序
2.1 实验类型
设计型实验,6学时(2学时完成文法改造;2学时完成程序编码;2学时完成程序测试)
2.2 实验目的
通过设计、编写、调试一个递归下降语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,掌握递归下降语法分析方法。
2.3 背景知识
2.3.1 递归下降分析
自顶向下语法分析过程中,如果产生回溯,则分析过程需要穷举所有可能的推导,看是否能推导出待检查的单词序列,导致分析程序时间和空间开销增大,降低分析效率。
而无回溯的自顶向下分析技术可根据输入串的当前单词,选择唯一的产生式构造推导过程,从而提高分析效率。
无回溯的自顶向下分析要求文法是LL(1)文法。
递归下降分析程序的实现思想是:(1) 分析程序由一组子程序组成,每个子程序对应于一个非终结符号。
(2) 每一个子程序的功能:选择正确的产生式右部,扫描相应的单词;产生式右部有非终结符号时,调用该非终结符号对应的子程序来完成。
2.3.2 LL(1)文法
LL(1)文法满足以下三个条件:
(1)文法不含左递归
(2)文法的任何一个非终结符A的各个产生式的右部符号串的FIRST集两两不相交,即:
若有A→α1|α2|…|αn,则
FIRST (a i)∩FIRST (a j) = φ(i ≠j,1≤i,j≤n)
(3)文法的任何一个非终结符A,
若有A→α1|α2|…|αn且存在a i,有ε∈FIRST (αi),则
FIRST (αj)∩FOLLOW (A) = φ(i ≠j,j=1,2,. . .,n )
2.3.3 文法改造
1、消除直接左递归(将左递归改为右递归):
直接左递归形式:U→Ux|y;其中:x,y∈(V N∪V T)* ,y不以U打头。
直接左递归的消除:
U→yU’
U’→xU’|ε
直接左递归的一般形式:U→Ux1|Ux2|…|Ux m|y1|y2|…|y n;其中:x i≠ε ,y i都不以U打头。
一般形式直接左递归的消除:
U→y1U’| y2U’ |…| y n U’
U’→x1U’| x2U’| …| x m U’|ε
2、消除间接左递归:
要求无环路(形如A⇒+ A的推导)和无ε-产生式。
(1)把非终结符按某一顺序排序为A1,A2…An 。
(2)for(i=1;i<=n;i++)
{
for(j=1;j<=i-l;j++)
{
if(Aj→δ1|δ2|…|δk ,Ai→Ajγ)
把Ai→Ajγ改写成
Ai→δ1γ|δ2γ|…|δkγ;
}
消除关于Ai产生式的直接左递归;
}
(3)化简由(2)所得到的文法。
(4)化简改写之后的文法,删除多余产生式。
3、提取左公因子
A→αβ1|αβ2……|αβn |γ1……|γm
改写成:
A→αA’|γ1……|γm
A’→β1|β2……|βn
2.3.4递归下降分析程序的基本架构
定义:
变量:ch,为当前符号;
函数:READ(ch):读输入串下一符号;
对于每个非终结符号U→α 1|α 2|…|α n处理的方法如下:
U()
{
if ch∈FIRST(α1 ) then P(α1) //处理α1的程序部分。
else if ch∈FIRST(α2 ) then P(α2) //处理α2的程序部分。
…
else if ch∈FIRST(αn ) then P(αn)
else if ch∈FOLLOW(U) then return //处理ε产生式情况。
else error
}
对于每个右部α =x1x2…x n的处理架构如下:
P(α )
{
P(x1 ); //处理x1的程序。
P(x2 ); //处理x2的程序。
… … …
P(x n ); //处理x n的程序。
}
对于右部中的每个符号x i;
如果x i为终结符号:
if(ch== a)
READ (ch)
else
error
如果x i为非终结符号,直接调用相应的过程:P (x i)。
2.3.5编写递归下降分析程序一般步骤
1) 改写文法,消除二义性;
2) 消除左递归、提取左因子;
3) 求FIRST集、FOLLOW集;
4) 检查是不是LL(1) 文法,若不是LL(1),说明文法的复杂性超过自顶向下方法的
分析能力(对文法的改造会影响文法的可读性,可以采用超前读一个单词的来处理)。
5) 直接根据产生式设计相应的程序
2.4 实验内容
1、语法规则
TEST语言的语法规则如下:
1) <program>→{<declaration_list><statement_list>}
2) <declaration_list>→<declaration_list><declaration_stat> | ε
3) <declaration_stat>→int ID;
4) <statement_list>→<statement_list><statement>| ε
5) <statement>→<if_stat>|<while_stat>|<for_stat>|<read_stat>
|<write_stat>|< compound_stat > |<expression_stat>
6) <if_stat>→if (<expr>) <statement >| if (<expr>) <statement >else < statement >
7) <while_stat>→while (<expr >) < statement >
8) <for_stat>→for (<expr>;<expr>;<expr>)<statement>
9) <write_stat>→write <expression>;
10) <read_stat>→read ID;
11)<compound_stat>→{<statement_list>}
12)<expression_stat>→< expression >;|;
13)< expression >→ID=<bool_expr>|<bool_expr>
14)<bool_expr>→<additive_expr> |< additive_expr >(>|<|>=|<=|==|!=)< additive_expr >
15)< additive_expr>→< additive_expr>+<term>|< additive_expr>-<term>|< term >
16)< term >→< term >*<factor>|< term >/<factor>|< factor >
17)< factor >→(< expression >)|ID|NUM
2、要求:
根据递归下降分析方法,完成TEST语言的递归下降语法分析程序的构造,主要完成:(1) 改造文法,使之满足无回溯的递归下降分析条件,给出改写后的文法(写入实验报告);说明:
A、规则6能否提取左公因子?如果提取后会有什么后果?分析原因后给出你的处理方案。
B、规则13可以采用采用超前读一个单词来解决,避免对该规则进行改写,保持文法的可读性。
C、红色标注的文法均需要进行改写。
D、对改写后的文法,计算所有右部符号串的FIRST集合;如有ε产生式,计算该产生式左部非终结符的FOLLOW集。
(2) 编写递归下降分析程序;(将<statement>,< expression >的程序流程图写入实验报告)
(3) 使用下述的TEST语言代码测试编写的递归下降分析程序(先使用实验一的词法分析程序进行词法分析,要求标识符类别记为ID,整数记为NUM,其它单词采用单词本身,比如int的类别就是int,,<=的类别就是<+)。
{
int a;
int i;
int b,c;
for (i=1; i <= 10; i=i+1)
{
;
a=a+i
b=b*i;
{
c=a+b;
}
}
if (a>b)
{
write a;
}
else
{
write b;
}
}
write c
}
2.5 实验分析与思考
1、TEST语言语法规则中哪些不满足无回溯的递归下降分析条件?你是怎么处理的?给出你的处理方案。
2、所有文法都可以改写为满足递归下降分析条件的文法吗?如果不能,请给出一个反例。
3、改写文法有什么弊端?。