Eviews操作入门输入数据对数据进行描述统计和画图
实验一EViews软件的基本操作
实验一EViews软件的基本操作【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】一、EViews软件的安装;二、数据的输入、编辑与序列生成;三、图形分析与描述统计分析;四、数据文件的存贮、调用。
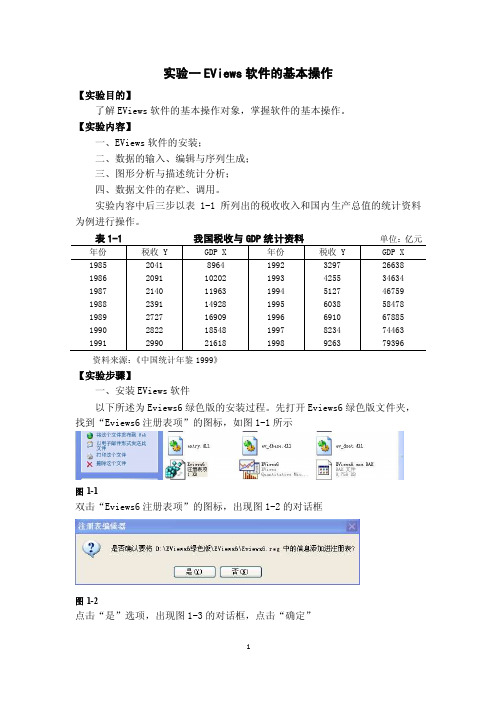
实验内容中后三步以表1-1所列出的税收收入和国内生产总值的统计资料为例进行操作。
单位:亿元资料来源:《中国统计年鉴1999》【实验步骤】一、安装EViews软件以下所述为Eviews6绿色版的安装过程。
先打开Eviews6绿色版文件夹,找到“Eviews6注册表项”的图标,如图1-1所示图1-1双击“Eviews6注册表项”的图标,出现图1-2的对话框图1-2点击“是”选项,出现图1-3的对话框,点击“确定”图1-3接下来双击图1中“Eviews6”的图标,弹出图1-4的窗口,软件运行。
二、数据的输入、编辑与序列生成 (一)创建工作文件 ⒈ 菜单方式启动EViews 软件之后,进入EViews 主窗口(如图1-4所示)。
图1-4 EViews 主窗口在主菜单上依次点击File/New/Workfile ,即选择新建对象的类型为工作文件,将弹出一个对话框(如图1-5所示),选择数据的结构类型(workfiles structure type )工作区域状态栏图1-5数据的结构类型有三种选项:①规则频率的时间数据选择Dated-regular frequency,对话框右边出现图1-5所示的画面,在Frequency的下拉菜单中出现如图1-6的各种选项,选择相应的频率,再在下方的起始时间框输入相应的时间即可。
图1-6其中, Annual——年度 Monthly——月度Semi-annual——半年 Weekly——周Quarterly——季度 Daily——日②截面数据及不规则频率的时间数据选择Unstructured/Undated,出现图1-7的对话框,只需要在右边Observations的空白框中输入数据的个数即可。
Eviews软件使用说明

Eviews软件使用说明Eviews软件使用说明1.引言1.1 背景信息Eviews是一种强大的计量经济学和时间序列分析软件,具有数据管理、统计分析、图形展示等功能。
本文档旨在提供Eviews软件的详细使用说明,帮助用户更好地掌握该软件的功能和操作方法。
2.安装和启动2.1 硬件和软件需求在使用Eviews之前,确认您的计算机符合软件的最低硬件和软件要求,并安装好所需的依赖库和驱动。
2.2 安装Eviews通过Eviews官方网站最新的安装程序,并按照安装向导的提示完成软件的安装。
2.3 启动Eviews双击桌面上的Eviews图标或通过开始菜单中的Eviews快捷方式启动软件。
3.数据导入与管理3.1 导入数据通过Eviews提供的数据导入功能,可以从多种文件格式(如Excel、CSV等)中导入数据。
3.2 数据浏览和编辑在Eviews中,可以方便地浏览和编辑已导入的数据,包括修改列名、调整数据格式等。
3.3 数据变换与处理Eviews提供了多种数据变换和处理的功能,如数据平滑、差分等,以满足用户对数据的需求。
4.统计分析4.1 描述性统计Eviews可以计算出数据集的各种描述性统计量,并相应的报告。
4.2 假设检验通过Eviews提供的假设检验功能,可以对单个变量或多个变量进行各种假设检验,如t检验、F检验等。
4.3 回归分析Eviews拥有强大的回归分析功能,可以进行简单回归、多元回归等各类回归分析,并提供了丰富的回归结果和诊断工具。
5.时间序列分析5.1 时间序列图Eviews可以绘制各种时间序列图形,包括线图、散点图、自相关图等,以帮助用户更好地理解时间序列数据的特征。
5.2 预测模型建立通过Eviews提供的时间序列建模功能,可以建立AR、MA、ARMA等各类时间序列模型,并进行模型的拟合和预测。
5.3 模型诊断与优化Eviews提供了一系列模型诊断与优化工具,如残差分析、模型优化、模型比较等,以帮助用户评估和改进建立的时间序列模型。
EViews基本操作与数据分析

EViews基本操作与数据分析EViews基本操作与数据分析一、EViews的基本操作与数据处理1、建立工作文件(File/New/Workfile)、数据库(Database)、程序(Program)或文本文件(Text File)。
(1)EViews的界面:菜单栏下面的白色空白区域为命令窗口。
(2)打开空表:Quick/Empty Group。
(3)Workfile的界面:c表示截距序列,resid表示残差序列。
2、输入数据(1)数据分为时间序列数据(Dated-regular Frequency,默认选项)、横界面数据(Unstructured/Undated)和面板数据(Balanced Panel),时间序列的日期间隔符号可以是“:”、“.”或“,”。
Q表示季度,M表示月份,W表示周。
(2)EViews也可以直接打开已有文件(Open/EViews Workfile)、外部数据(Foreign Data)、数据库(Database)、程序(Program)或文本文件(T ext File)。
EViews 5.0可以导入其他的外部数据:File/Open/Foreign Data as Workfile。
(3)调用外部数据:File/Import/……。
先建立工作文件,然后才能调用数据,EViews允许调用3种格式的数据:ASCII、Lotus和Excel工作表。
如果原文件已有序列名称,则只需输入序列个数即可。
3、对象(Object)的操作与处理(1)生成新对象(New Object):Equation、Graph、Group、Matrix、Series、Table、Text、V AR等。
(2)对象的编辑:剪切(Cut)、复制(Copy)、粘贴(Paste)、删除(Delete)、合并(Merge)和替代(Replace)等。
(3)对象的命名:对象必须以半角字符命名,不能用中文命名,命名不宜太长。
eviews描述性统计分析表步骤

eviews描述性统计分析表步骤在我们的日常工作中,对于数据分析的结果,常常要用到描述性统计表来分析。
这是一种图表统计表格,通常情况下,描述性统计表使用最多的是 Java编写和使用。
而 Excel是在 Java 开发环境下编写和使用的。
今天就以它为例说明一下描述性统计表表的制作过程。
首先我们要做的就是将所需要进行分析的数据导入 Excel表格,然后根据表格需求进行处理了。
如果数据在这里不能够清晰反映出来,就需要对各个变量进行属性替换或修改了,以方便后续分析。
然后我们要按照表格顺序生成一张统计图表啦!可以看到这些图表的属性包括:性别、年龄、种族、国家/地区(如果有的话)、来源(来自哪里)及工作年限等(需要详细说明),每个图表都包含了一些参数设置或说明。
当然,这些参数可以自定义配置或在统计图表中添加或者修改啊!1.在项目界面中选择表格并创建,然后单击“添加表头”按钮。
选择“列表”,然后点击“数据项”按钮,将“属性”项复制到表中的任何位置。
复制后单击“确定”按钮即可完成一个表头的创建。
如图所示,在窗口中左部有两个小的文本框可选择:“基本信息”和“属性”。
选择“基本信息”后会弹出两个对话框。
左侧“基本信息”框为已经创建好的表的详细信息,右侧的“属性”栏显示了在 Excel中添加表中的其他参数信息啦!如图所示,选中“数据项”后可以看到其主要包含以下参数(默认情况下会使用公式来计算出来):所有表头都是以此公式为基础进行修改的!当需要将表头合并时,在这里我们就使用公式即可啦!2.然后点击“新建表头”按钮。
在“表头”页面中,我们看到里面有一组关于图表数据配置的文档。
在这里,我们想了解一个新表的配置信息。
我们可以选择这组文档,下面有详细的配置说明:我们可以将所有图表进行配置后设置成表格样式(有需要可自行调整)。
接着,我们点击“创建新表头”按钮。
新建的表头文件就会创建了,下面介绍一下创建新表的方法。
先在表格中新建一个新表头,这个表头文件名叫 DB格式,里面包含了很多数据。
Eviews软件基本操作

T l xt x yt l y l 0,1,2,3 T t 1 c xy l T l yt y xt l x l 0,1,2 T t 1 注意与自相关不同,交叉相关不必围绕滞后期对称。交
叉相关图中的虚线是二倍的标准差,近似计算。
第1讲 EViews软件的基本操作
【实验目的】
了解 EViews 软件的基本操作对象,掌握软件 的基本操作。
【实验内容】
一、EViews 软件的安装; 二、数据的输入、编辑与序列生成; 三、序列的统计量、检验和分布 四、图形分析与描述统计分析; 五、数据文件的存贮、调用与转换。
序列的统计量、检验和分布
§1.2 均值、中位数、方差的假设检验
这部分是对序列均值、中位数、方差的假设检验。在序
列对象菜单选择View/tests for descriptive stats/simple hypothesis tests,就会出现下面的序列分布检验对话框:
1. 均值检验
原假设是序列 x 的期望值 m ,备选假设是 ≠m ,即
N
4
意义同S中 ,正态分布的 K 值为3。如果 K 值大于3,
分布的凸起程度大于 正态分布;如果K值小于3,序列分布相 对于正态分布是平坦的。例1.1中X的峰度为2.5,说明X的分 布相对于正态分布是平坦的;而例1.3中GDP增长率的峰度为 2.14 ,说明GDP增长率的分布相对于正态分布也是平坦的。
可以选与如下的理论分布的分位数相比较: Normal(正态)分布:钟形并且对称的分布. Uniform(均匀)分布:矩形密度函数分布. Exponential(指数)分布:联合指数分布是一个有着一条 长右尾的正态分布. Logistic(逻辑)分布:除比正态分布有更长的尾外是一种 近似于正态的对称分布. Extreme value(极值)分布:I型极小值分布是有一条左长 尾的负偏分布,它非常近似于对数正态分布. 可以在工作文件中选择一些序列来与这些典型序列的分 位数相比较,也可以在编辑框中键入序列或组的名称来选择 对照的序列或组,EViews将针对列出的每个序列计算出QQ 图。
EViews 软件的基本操作
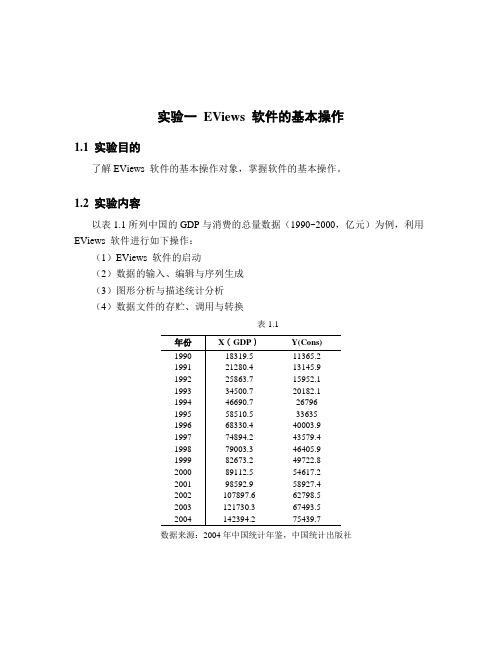
图1.12
其他的函数命令可参阅《EViews使用指南与案例》等书籍。
图1.13
1.3.2.4编辑数组及序列
在工作文件窗口中单击所要选择的变量,按住Ctrl键不放,继续用鼠标选择要展示的变量,选择完以后,单击鼠标右键,在弹出的快捷菜单中点击Open/as Group(如图1.13),则会弹出如图1.14所示的数组窗口,其中变量从左至右按在工作文件窗口中选择变量的顺序来排列。
序列方式:点击Objects \ New object \选Series \输入序列名称\Ok,进入数据编辑窗口,点击Edit+/-打开数据编辑状态,(用户可以根据习惯点击Smpl+/-改变数据按行或列的显示形式,)然后输入数据,方式同上。
1.3.2.3生成序列
利用数学公式生成新序列,也就是利用普通的数学符号对已有序列进行变换。如生成log(Y)、D(Y)、X^2、1/X、时间变量T等序列,在命令窗口中依次键入以下命令即可:
1.3
1.3.1
进入Windows /双击EViews5快捷方式,进入EViews窗口;或点击开始/程序/EViews5/EViews5进入EViews窗口,如图1.1。
图1.1
标题栏:窗口的顶部是标题栏,标题栏的右端有三个按钮:最小化、最大化(或复原)和关闭,点击这三个按钮可以控制窗口的大小或关闭窗口。
图1.2
图1.3创建工作文件窗口在Workfile structure type选项区共有3种类型:
详细的EVIEWS面板数据分析操作

详细的EVIEWS面板数据分析操作引言EVIEWS是一款专业的经济统计软件,广泛应用于经济学和金融领域的数据分析和建模。
EVIEWS提供了丰富的面板数据分析功能,可以帮助用户进行面板数据的处理、描述统计、回归分析等操作。
本文将详细介绍EVIEWS中面板数据分析的操作流程和常用功能。
EVIEWS面板数据的导入首先,我们需要将面板数据导入到EVIEWS中进行分析。
EVIEWS支持多种数据格式的导入,包括Excel、CSV、数据库等。
在导入面板数据时,需要保证数据具有正确的格式,例如面板数据应包含个体(cross-sectional)和时间(time-series)的维度,且面板数据的变量应按照一定的顺序排列。
在导入面板数据后,我们可以利用EVIEWS提供的数据操作命令对数据进行处理和调整。
例如,可以通过group命令将数据按照个体或时间进行分组,通过sort命令对数据进行排序,以便后续的面板数据分析。
面板数据的描述统计分析在面板数据导入并处理完毕后,我们可以进行面板数据的描述统计分析。
EVIEWS提供了丰富的统计功能,可以计算面板数据的平均值、标准差、相关系数等指标。
下面介绍几个常用的描述统计功能:1.summary命令:该命令可以计算面板数据每个变量的平均值、标准差、最大值、最小值等统计指标,并输出到EVIEWS的结果窗口中。
2.correlation命令:该命令可以计算面板数据各变量之间的相关系数矩阵,并输出到结果窗口中。
3.tabulate命令:该命令可以对面板数据进行交叉分组统计,例如计算变量A在变量B的每个取值下的频数和比例。
通过对面板数据进行描述统计分析,可以初步了解数据的分布特征和变量间的关系,为后续的面板数据分析提供基础。
面板数据的回归分析除了描述统计分析,EVIEWS还提供了面板数据的回归分析功能。
通过面板数据回归分析,可以探究变量间的因果关系和影响程度。
下面介绍两个常用的回归分析命令:1.panel least squares(PLS)命令:该命令可以进行面板数据的最小二乘回归分析。
Eviews 基本操作学习( 图示版)

目录目录 (1)1、EViews简介 (3)1.1 什么是EViews (3)1.2 启动和运行EViews (3)1.3 EViews窗口 (3)1.4关闭EViews (4)2、EViews基本操作 (5)2.1工作文件与对象 (5)2.1.1工作文件 (5)2.1.2对象 (7)2.2数据处理 (10)2.2.1数据对象与样本 (10)2.2.2数据的输入和输出 (12)2.3图形与表格 (14)2.3.1图的创建 (14)2.3.2图的修改 (14)2.3.3多个图 (16)2.3.4图的打印和输出 (17)2.3.5表格对象 (18)2.3.6表的输出 (18)2.3.7文本对象 (19)3、基本回归模型 (19)3.1估计和方程对象 (19)3.1.1方程对象 (19)3.1.2在EViews中对方程进行说明 (20)3.1.3在EViews中估计方程 (20)3.2方程输出 (20)3.3方程操作 (22)3.3.1方程视图 (22)3.3.2方程过程 (24)3.3.3缺省方程 (24)4、基本检验 (24)4.1多重共线性的检验 (24)4.2异方差的检验 (25)4.3 自相关的检验 (26)5、时间序列模型 (27)5.1时间序列平稳性的单位根检验 (27)5.1.1单位根的ADF检验 (27)5.1.2Phillips-Perron(PP)检验 (27)5.2协整 (28)6、案例分析 (29)6.1多元线性回归及多重共线性的检验 (29)6.2异方差的检验 (31)6.3自相关的检验 (34)6.4时间序列的单位根和协整检验 (36)1、EViews简介1.1什么是EViewsEViews 是在大型计算机的TSP (Time Series Processor)软件包基础上发展起来的新版本,是一组处理时间序列数据的有效工具,是当今世界上最流行的计量经济学软件之一。
1981年QMS (Quantitative Micro Software) 公司在Micro TSP基础上直接开发成功EViews 并投入使用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在Workfile窗口下,单击Procs/import/read tex-lotus-excel
F1-8文本文件和数据表输入数据
选择需要输入数据的文件。我们选择的数据在移动存储上,如果数据是文本文件格式,点击打开命令,会得到窗口F1-9;如果是数据表文件会得到窗口F1-10。
使用美国三个月期国债利率,时间1954年1月到2007年10月,周数据。利率用百分数表示。周数据输入只要输入1954/1/12007/10/4来表示1954年一月第一周到2007年10月第4周,Eviews会自动匹配相应时间,债券利率命名为tbillrate,数据输入后见图F4-1。
F4-1:建立ARMA模型图1.
选择TBILLRATE可以直接对债券利率预测。
图F4-14:用原始数据输入模型
使用AIC准则建立AR(P)模型定阶的程序:
'subroutine end是子程序,laglength是子程序名称,该子程序调用时需要给出两个量,一个是常数最大滞后长度,一个是对哪个时间序列建立模型。
subroutine laglength(scalar maxlag, series r)
在程序中进行操作后,从模型可以计算出一些数据,或者对原有数据进行了变换,可以从Eviews中输出这些数据。首先选中希望输出的变量名,点击workfile窗口中的proc,选择export从中选择输出数据格式,常用的是最后一个选项保存为文本格式或者EXCEL表格式。见F1-11。如果保存成文本格式,只要直接保存即可。如果保存成EXCEL格式,会弹出窗口F1-12,给出数据在EXCEL表中的排列。可以修改变量排列的顺序和第一个数据保存的位置,然后保存即可。
图F4-3:TBILLRATE样本自相关函数和偏自相关函数图
图F4-4:差分后数据的折线图
图F4-5:r的样本自相关函数和偏自相关函数图
画样本自相关函数图的命令是双击时间序列数据r的名字,点view-correlogram见图F4-6,可以得到样本自相关函数和偏自相关函数的图形和数值,见图F4-5。
图F1-9
F1-9下方的最大的白框中是对数据的预览,可以看到有3列数字,数据按列排列。第一行是变量名,从第二行开始是数据。
我们要作的工作是在左上方填入变量名,名称可以与数据源中的名称不同,变量名用空格隔开。然后是左变中间的白框,填入数据前的说明文字占的行数,默认是1,如本例,如果还有一些其他说明例如数据来自统计局等,可能会有2行说明文字,这时把1修改成2。总之要数据前面的文字部分所占的行数填写在此。
F4-6:画样本自相关函数的命令
从图F4-4可以看出数据围绕一条水平线波动,已经平稳化。并且具有一簇一簇的特征,这种特征叫波动率聚类性,下一章对这种特性建立模型。本章先忽略这一特点。
下面可以对r建立ARMA模型了。点击workfile窗口的object命令,选择equation,输入equation的名称armatemp,得到窗口F4-6。
图F1-13
F1-13中c是Eviews中自动给出的一个量,用来保存模型估计出的未知参数,resid是用来保存模型的残差序列。P是我们数据的数据。
改变样本区间
有时我们会分阶段对数据进行分析,例如希望比较2000年前的数据与2000年后的数据的不同,所以不总是对工作窗口中的所有数据进行分析,这时可以改变样本长度。单击Sample,输入希望的区间,按OK。
周和日:8:10:1997表示1997年8月10号,美式表达日期法。
8:10:1997表示1997年10月8号,欧式表达日期法。
如何选择欧式和美式日期格式呢从Eviews窗口点击Options再点击dates andFrequency conversion,得到窗口F1-5。F1-5的右上角可以选择日期格式。
等价于下面的模型
y ma(1)ma(2) sma(4)
等价于下面的模型
输入模型的表达式后,可以在sample部分修改估计样本的区间。使用2000年12月29号的数据到2007年9月28号的周数据建立模型。根据样本自相关函数建立模型ARMA(5,1),见图F4-7,估计结果见图F4-8:
F4-8:ARMA(5,1)估计结果
输入数据后,首先观察数据的折线图和样本自相关函数图和偏自相关函数图。分别见图F4-2和图F4-3。从图F4-2和图F4-3,数据不频繁穿过某一水平线,样本自相关函数图收敛速度非常慢,都意味着TBILLRATE是非平稳的,因此把数据进行一次差分,然后再观察折线图和样本自相关函数图和偏自相关函数图。
图F4-2:TBILLRATE折线图
图F1-5
假设建立一个月度数据的workfile,填写完后点OK,一个新Workfile就建好了。见图F1-6。保存该workfile,单击Eviews窗口的save命令,选择保存位置即可。
图F1-6
新建立的workfile之后,第二件事就是输入数据。数据输入有多种方法。
1)直接输入数据,见F1-7
改变变量名称
单击需要改变名称的变量选中该变量,变量名变色说明已经选中,把光标放在该变量上右击,选中rename输入希望的名字即可。
改变workfile的区间
有时会发现因为偶然的错误或需要预测,workfile的长度不够用。例如我们想对2004:09到2004:12进行预测,可是一开始设计的区间是到2004:08,因此必须扩展区间。点击Eviews窗口的procs,选择structure/resize current page,见图F1-14
在Eviews窗口下,单击Quick,再单击Empty group(edit series),直接输数值即可。注意在该窗口中命令行有一个Edit+/-,可以点一下Edit+/-就可以变成如图所示的空白格,输完数据后,为了避免不小心改变数据,可以再点一下Edit+/-,这时数据就不能被修改了。
F1-7
滞后运算:price(-1)表示变量名是price的一阶滞后
例如用price表示价格指数,
差分d(price)=price-price(-1)
连续收益率
r=dlog(price)
虚拟变量如果收入超过10000,则赋值为1,
high_inc = income>10000
对计算得到的收益率变量进行描述统计
第一列数据是年份,第二列数据是月份,第三列数据是股票价格,希望读入价格,在右上方colums填入2,如图F1-9,会跳过前面两列数据,只读入第三列数据。按OK数据已经输入该工作文件。
如果数据保存在EXCEL表中,得到图F1-10.需要给出第一个数据在EXCEL表中的位置,通常在B2的位置。然后在左边中间的白框填写变量名,这里填写的变量名是在Eveiws中的名称,可以与数据表的变量名不同。不同变量用空格隔开,输几个变量名,会输入几列相邻排列的数据。
打开Eviews后,第一项任务就是建立一个新Workfile或者打开一个已有的Workfile,单击File,然后光标放在New上,最后单击Workfile。如图F1-2
图F1-2
图F1-2左上角点击向下的三角可以选则数据类型,如同F1-3。数据类型分三类截面数据,时间序列数据和面板数据。
图F1-3
Eviews操作入门输入数据对数据进行描述统计和画图
Eviews操作入门:输入数据,对数据进行描述统计和画图
首先是打开Eviews软件,可以双击桌面上的图标,或者从windows开始菜单中寻找Eviews,打开Eviews后,可以看到下面的窗口如图F1-1。
图F1-1 Eviews窗口
关于Eviews的操作可以点击F1-1的Help,进行自学。
next
'table will make a table to include the results
' first the row the the colum the table's name is laglength
F4-7:建立ARMA模型的窗口
下面是输入模型的几个例子。
例如建立一个AR(1)模型可以如下输入:
r c r(-1)
等价于模型:
或者输入:
rcar(1)
等价于模型:
两种输入方法估计结果的区别是后者的c是r的均值,而前者的c是回归模型的截距项,斜率估计值相同。
建立ARMA(1,1)模型可以如下输入
r c r(-1) ma(1)
'the following for next loop will compute the AIC and BIC
for !i=1 to maxlag
equation eq{!i}.ls r c r(-1 to -!i)
scalar aicl!i=eq{!i}.@aic
scalar bicl!i=eq{!i}.@schwarz
F1-16
F1-17
图F1-17是划折线图的选项,背景是画出的折线图。
Descriptive Statistics/Histogram and Stats做直方图和计算各样本统计量结果如图F1-18。JB检验在图F1-18右下角处,该组数据服从正态分布。
F1-18
EVIEW操作指南:建立ARMA模型
图F4-9:最终ARMA(5,1)模型。
预测2007年9月29号到2007年10月11日的周数据进行样本外预测,选择static forecast,预测值保存在rf中。见图F4-12。预测图形见图F4-13.
图F4-12:预测的设置
图F4-13
因为原始数据是债券利率是非平稳的,因此对差分后的数据建立模型,如果希望直接对债券利率进行预测,可以如F4-14输入模型公式。在这种输入方式下,模型估计后进行预测的窗口见图F4-15。在F4-15中,预测有两个选项一个是TBILLRATE,一个是D(TBILLRATE)。