生物统计学(版)杜荣骞课后习题问题详解统计大数据地收集与整理
生物统计学(第3版)杜荣骞 课后习题答案 第二章 概率和概率分布

第二章概率和概率分布2.1做这样一个试验,取一枚五分硬币,将图案面称为A,文字面称为B。
上抛硬币,观察落下后是A向上还是B向上。
重复10次为一组,记下A向上的次数,共做10组。
再以100次为一组,1 000次为一组,各做10组,分别统计出A的频率,验证2.1.3的内容。
答:在这里用二项分布随机数模拟一个抽样试验,与同学们所做的抽样试验并不冲突。
以变量Y表示图向上的次数,n表示重复的次数,m表示组数,每次落下后图向上的概率φ=1/2。
SAS程序如下,该程序应运行3次,第一次n=10,第二次n=100,第三次n=1000。
options nodate;data value;n=10;m=10;phi=1/2;do i=1 to m;retain seed 3053177;do j=1 to n;y=ranbin(seed,n,phi);output;end;end;data disv;set value;by i;if first.i then sumy=0;sumy+y;meany=sumy/n;py=meany/n;if last.i then output;keep n m phi meany py;run;proc print;title 'binomial distribution: n=10 m=10';run;proc means mean;var meany py;title 'binomial distribution: n=10 m=10';run;以下的三个表是程序运行的结果。
表的第一部分为每一个组之Y的平均结果,包括平均的频数和平均的频率,共10组。
表的第二部分为10组数据的平均数。
从结果中可以看出,随着样本含量的加大,样本的频率围绕0.5做平均幅度越来越小的波动,最后稳定于0.5。
binomial distribution: n=10 m=10OBS N M PHI MEANY PY1 10 10 0.5 5.7 0.572 10 10 0.5 4.5 0.453 10 10 0.5 5.1 0.514 10 10 0.5 6.1 0.615 10 10 0.5 6.1 0.616 10 10 0.5 4.3 0.437 10 10 0.5 5.6 0.568 10 10 0.5 4.7 0.479 10 10 0.5 5.2 0.5210 10 10 0.5 5.6 0.56binomial distribution: n=10 m=10Variable Mean ---------------------- MEANY 5.2900000 PY 0.5290000 ----------------------binomial distribution: n=100 m=10 OBS N M PHI MEANY PY1 100 10 0.5 49.71 0.49712 100 10 0.5 49.58 0.49583 100 10 0.5 50.37 0.50374 100 10 0.5 50.11 0.5011 5 100 10 0.5 49.70 0.49706 100 10 0.5 50.04 0.50047 100 10 0.5 49.20 0.49208 100 10 0.5 49.74 0.49749 100 10 0.5 49.37 0.4937 10 100 10 0.5 49.86 0.4986binomial distribution: n=100 m=10Variable Mean ---------------------- MEANY 49.7680000 PY 0.4976800 ----------------------binomial distribution: n=1000 m=10 OBS N M PHI MEANY PY1 1000 10 0.5 499.278 0.499282 1000 10 0.5 499.679 0.499683 1000 10 0.5 499.108 0.499114 1000 10 0.5 500.046 0.50005 5 1000 10 0.5 499.817 0.49982 6 1000 10 0.5 499.236 0.49924 7 1000 10 0.5 499.531 0.499538 1000 10 0.5 499.936 0.499949 1000 10 0.5 500.011 0.50001 10 1000 10 0.5 500.304 0.50030binomial distribution: n=1000 m=10Variable Mean ---------------------- MEANY 499.6946000 PY 0.4996946 ----------------------2.2 每个人的一对第1号染色体分别来自祖母和外祖母的概率是多少?一位男性的X 染色体来自外祖父的概率是多少?来自祖父的概率呢?答: (1)设A 为一对第1号染色体分别来自祖母和外祖母的事件,则()41211211=⨯⨯⨯=A P(2)设B 为男性的X 染色体来自外祖父的事件,则()21211=⨯=B P(3)设C 为男性的X 染色体来自祖父的事件,则 ()0=C P2.3 假如父母的基因型分别为I A i 和I B i 。
生物统计学课后重点题答案
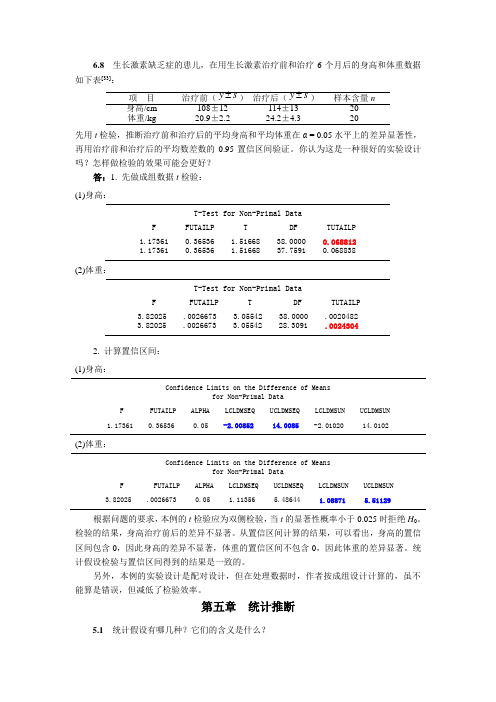
6.8生长激素缺乏症的患儿,在用生长激素治疗前和治疗6个月后的身高和体重数据如下表[33]:y±sy±s身高/cm 108±12 114±13 20体重/kg 20.9±2.2 24.2±4.3 20先用t检验,推断治疗前和治疗后的平均身高和平均体重在α = 0.05水平上的差异显著性,再用治疗前和治疗后的平均数差数的0.95置信区间验证。
你认为这是一种很好的实验设计吗?怎样做检验的效果可能会更好?答:1. 先做成组数据t检验:(1)身高:T-Test for Non-Primal DataF FUTAILP T DF TUTAILP1.17361 0.36536 1.51668 38.0000 0.0688121.17361 0.36536 1.51668 37.7591 0.068838(2)体重:T-Test for Non-Primal DataF FUTAILP T DF TUTAILP3.82025 .0026673 3.05542 38.0000 .00204823.82025 .0026673 3.05542 28.3091 .00243042. 计算置信区间:(1)身高:Confidence Limits on the Difference of Meansfor Non-Primal DataF FUTAILP ALPHA LCLDMSEQ UCLDMSEQ LCLDMSUN UCLDMSUN1.17361 0.36536 0.05 -2.0085214.0085 -2.01020 14.0102(2)体重:Confidence Limits on the Difference of Meansfor Non-Primal DataF FUTAILP ALPHA LCLDMSEQ UCLDMSEQ LCLDMSUN UCLDMSUN3.82025 .0026673 0.05 1.11356 5.48644 1.08871 5.51129根据问题的要求,本例的t检验应为双侧检验,当t的显著性概率小于0.025时拒绝H0。
杜荣骞 生物统计第二版第一章答案

《生物统计学》第一章课后习题参考答案1-2: 分组一:(1)确定组数:极差70-55=15cm ,分16组,组距1cm (2)确定组界,中值,作频数(率)表67.565.5 56.5 62.5 55.5 59.561.554.557.558.5 60.563.564.566.568.5 69.570.5根据频数表计算:()1kii fm x N==∑=(55x1+56x3+…+70x4)/250=15819/250=63.2763.014s ===分组二:(1)确定组数:极差70-55=15cm ,分8组,组距2cm (2)确定组界,中值,作频数(率)表根据频数表计算:()1kii fm x N==∑=(55.5x4+57.5x12+…+69.5x10)/250=15819/250=63.2763.0392===s1-4:证明: ()∑∑∑∑∑∑∑∑-=⎪⎪⎭⎫⎝⎛+⎪⎪⎭⎫⎝⎛-=+-=-nx xn x n x n x x x x x xx x 222222)(2)2()(1-5:证明:①令()()()∑∑∑-=-±='-'±='±='222,,x x C x C x x x C x x C x x 则②令()()∑∑∑-=⎪⎪⎭⎫ ⎝⎛-='-'='='222,,Cx x C x C x x x Cx x Cx x 则1-8:()()()()n m n m s x x n s m s n m+-=-+-+-+222212121111-12:农 大 139:072.065.042.006.92====CV s s x 津 丰: 075.052.027.083.62====CV s s x 东方红3号:050.057.033.039.112====CV s s x东方红3号小麦穗长最整齐。
1-13:放回式抽样抽得的样本中,同一个个体可能被重复多次抽中;而非放回式抽样中,同一个体只会出现一次。
生物统计学(第3版)杜荣骞课后习题答案第六章参数估计

第六章参数估计6.1以每天每千克体重52 μmol 5-羟色胺处理家兔14天后,对血液中血清素含量的影响如下表[9]:y/(μg · L-1)s/(μg · L-1)n对照组 4.20 0.35 125-羟色胺处理组8.49 0.37 9建立对照组和5-羟色胺处理组平均数差的0.95置信限。
答:程序如下:options nodate;data common;alpha=0.05;input n1 m1 s1 n2 m2 s2;dfa=n1-1; dfb=n2-1;vara=s1**2; varb=s2**2;if vara>varb then F=vara/varb;else F=varb/vara;if vara>varb then Futailp=1-probf(F,dfa,dfb);else Futailp=1-probf(F,dfb,dfa);df=n1+n2-2;t=tinv(1-alpha/2,df);d=abs(m1-m2);lcldmseq=d-t*sqrt(((dfa*vara+dfb*varb)/(dfa+dfb))*(1/n1+1/n2));ucldmseq=d+t*sqrt(((dfa*vara+dfb*varb)/(dfa+dfb))*(1/n1+1/n2));k=vara/n1/(vara/n1+varb/n2);df0=1/(k**2/dfa+(1-K)**2/dfb);t0=tinv(1-alpha/2,df0);lcldmsun=d-t0*sqrt(vara/n1+varb/n2);ucldmsun=d+t0*sqrt(vara/n1+varb/n2);cards;12 4.20 0.35 9 8.49 0.37;proc print;id f;var Futailp alpha lcldmseq ucldmseq lcldmsun ucldmsun;title1 'Confidence Limits on the Difference of Means';title2 'for Non-Primal Data';run;结果见下表:Confidence Limits on the Difference of Meansfor Non-Primal DataF FUTAILP ALPHA LCLDMSEQ UCLDMSEQ LCLDMSUN UCLDMSUN1.11755 0.42066 0.05 3.95907 4.62093 3.95336 4.62664首先,方差是具齐性的。
生物统计学杜荣骞第8章答案

第八章单因素方差分析8.1 黄花蒿中所含的青蒿素是当前抗疟首选药物,研究不同播期对黄花蒿种子产量的影响,试验采用完全随机化设计,得到以下结果(kg/小区)[47]:重复播种期2月19日3月9日3月28日4月13日1 0.26 0.14 0.12 0.032 0.49 0.24 0.11 0.023 0.36 0.21 0.15 0.04对上述结果做方差分析。
答:对于方差分析表中各项内容的含义,在“SAS程序及释义”部分已经做了详细解释,这里不再重复。
如果有不明白的地方,请复习“SAS程序及释义”的相关内容。
SAS分析结果指出,不同播种期其产量差异极显著。
多重比较表明,2和3间差异不显著,3和4间差异不显著,1和其他各组间差异都显著。
以上结果可以归纳成下表。
变差来源平方和自由度均方 F P播期间0.185 158 33 3 0.061 719 44 14.99 0.001 2重复间0.032 933 33 8 0.004 116 67总和0.218 091 67 11多重比较:1 2 3 48.2 下表是6种溶液及对照组的雌激素活度鉴定,指标是小鼠子宫重。
对表中的数据做方差分析,若差异是显著的,则需做多重比较。
鼠号溶液种类Ⅰ(ck) ⅡⅢⅣⅤⅥⅦ1 89.9 84.4 64.4 75.2 88.4 56.4 65.62 93.8 116.0 79.8 62.4 90.2 83.2 79.43 88.4 84.0 88.0 62.4 73.2 90.4 65.64 112.6 68.669.4 73.8 87.8 85.670.2答:溶液种类的显著性概率P=0.038 5,P <0.05,不同种类的溶液影响显著。
其中1、2、5、6间差异不显著;2、5、6、3、7、4间差异不显著。
以上结果可以归纳成下表:变差来源平方和自由度均方 F P溶液间 2 419.105 00 6 403.184 17 2.77 0.038 5重复间 3 061.307 50 21 145.776 55总和 5 480.412 50 271(ck) 2 5 6 3 7 48.3 人类绒毛组织培养,通常的方法是,向培养瓶中接入大量组织碎片,加入适当的基质使组织碎片贴壁,经过一段时间,将贴壁的组织块浸入到培养基中。
生物统计学课后习题解答

第一章概论解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。
第二章试验资料的整理与特征数的计算习题2.1 某地100 例30 ~40 岁健康男子血清总胆固醇(mol · L -1 ) 测定结果如下:4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.715.69 4.124.56 4.375.396.30 5.217.22 5.54 3.93 5.21 6.515.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.694.38 4.89 6.255.32 4.50 4.63 3.61 4.44 4.43 4.254.035.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.975.16 5.10 5.85 4.79 5.34 4.24 4.32 4.776.36 6.384.885.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.094.52 4.38 4.31 4.585.726.55 4.76 4.61 4.17 4.034.47 3.40 3.91 2.70 4.60 4.095.96 5.48 4.40 4.555.38 3.89 4.60 4.47 3.64 4.34 5.186.14 3.24 4.90计算平均数、标准差和变异系数。
【答案】=4.7398, s=0.866, CV =18.27 %2.2 试计算下列两个玉米品种10 个果穗长度(cm) 的标准差和变异系数,并解释所得结果。
24 号:19 ,21 ,20 ,20 ,18 ,19 ,22 ,21 ,21 ,19 ;金皇后:16 ,21 ,24 ,15 ,26 ,18 ,20 ,19 ,22 ,19 。
【答案】 1 =20, s 1 =1.247, CV 1 =6.235% ; 2 =20, s 2 =3.400, CV 2 =17.0% 。
生物统计第二章 补充习题及答案

第二章习题及答案(来源:《生物统计学学习指导》李春喜等,科学出版社,2008:p14-15)一、填空1.变量的分布有两个明显的基本特征,即和。
二、判断1.计数资料也称为连续性变异资料。
计量资料也称为不连续性变异资料或间断性变异资料。
()三、选择题(《生物统计学题解及练习》杜荣赛高等教育出版社。
2003.p164)1.下面的变量属于非连续性变量的是( )。
A. 身高B. 体重C. 血型D. 血压2.身高、体重、年龄这一类数据属于()。
A. 离散性数据B. 计数数据C. 连续性数据D. 质量性状资料3.身高、体重、年龄这一类数据属于()。
A. 离散性数据B. 计数数据C. 计量资料D. 质量性状资料4.每十人中男性人数,每一万人中得H1N1流感人数,每亩麦田中杂草株数等,这一类数据属于()。
A. 离散性数据B. 连续性数据C. 计量资料D. 质量性状资料5.每十人中男性人数,每一万人中得H1N1流感人数,每亩麦田中杂草株数等,这一类数据属于()。
A. 计数数据B. 连续性数据C. 计量资料D. 质量性状资料6.频数按其组值的次序排列起来,称为()。
A. 频数排列B. 频数分布C. 组值排列D. 二项分布四、计算题1. 现以50枚受精种蛋孵化出雏鸡的天数为例,说明计数资料的整理。
21 20 20 21 23 22 22 22 21 22 20 23 22 23 22 19 22 2324 22 19 22 21 21 21 22 22 24 22 21 21 22 22 23 22 22小鸡出壳天数在19─24天范围内变动,有6个不同的观察值。
用各个不同观察值进行分组,共分为6组,可得表2-3形式的次数分布表。
表2-3 50枚受精种蛋出雏天数的次数分布表孵化天数划线计数次数(f)19 ║ 220 ║│ 321 ╫╫╫╫1022 ╫╫╫╫╫╫╫╫║║2423 ╫╫║║924 ║ 2合计50从表2-3可以看出:种蛋孵化出雏天数大多集中在21−23天,以22 天的最多,孵化天数较短(19−20天)和较长(24天)的都较少。
生物统计学(第3版)杜荣骞 课后习题答案 第三章 几种常见的概率分布律

第三章 几种常见的概率分布律3.1 有4对相互独立的等位基因自由组合,问有3个显性基因和5个隐性基因的组合有多少种?每种的概率是多少?这一类型总的概率是多少?答:代入二项分布概率函数,这里φ=1/2。
()75218.02565621562121!5!3!83835==⎪⎭⎫⎝⎛=⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛=p结论:共有56种,每种的概率为0.003 906 25(1/256 ),这一类型总的概率为0.218 75。
3.2 5对相互独立的等位基因间自由组合,表型共有多少种?它们的比如何? 答:(1)543223455414143541431041431041435434143⎪⎭⎫ ⎝⎛+⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛+⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛+⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛+⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛+⎪⎭⎫ ⎝⎛=⎪⎭⎫⎝⎛+ 表型共有1+5+10+10+5+1 = 32种。
(2)()()()()()()6976000.0024114165014.00241354143589087.002419104143107263.0024127104143105395.00241815414353237.0024124343554322345541322314==⎪⎭⎫⎝⎛==⨯=⎪⎭⎫⎝⎛⎪⎭⎫ ⎝⎛==⨯=⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛==⨯=⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛==⨯=⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛===⎪⎭⎫⎝⎛=隐隐显隐显隐显隐显显P P P P P P它们的比为:243∶81(×5)∶27(×10)∶9(×10)∶3(×5)∶1 。
3.3 在辐射育种实验中,已知经过处理的单株至少发生一个有利突变的概率是φ,群体中至少出现一株有利突变单株的概率为P a ,问为了至少得到一株有利突变的单株,群体n 应多大?答: 已知φ为单株至少发生一个有利突变的概率,则1―φ为单株不发生一个有利突变的概率为:()()()()()φφφ--=-=--=-1lg 1lg 1lg 1lg 11a a an P n P n P3.4 根据以往的经验,用一般的方法治疗某疾病,其死亡率为40%,治愈率为60%。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章统计数据的收集与整理1.1 算术平均数是怎样计算的?为什么要计算平均数?答:算数平均数由下式计算:n yynii∑==1,含义为将全部观测值相加再被观测值的个数除,所得之商称为算术平均数。
计算算数平均数的目的,是用平均数表示样本数据的集中点,或是说是样本数据的代表。
1.2 既然方差和标准差都是衡量数据变异程度的,有了方差为什么还要计算标准差?答:标准差的单位与数据的原始单位一致,能更直观地反映数据地离散程度。
1.3 标准差是描述数据变异程度的量,变异系数也是描述数据变异程度的量,两者之间有什么不同?答:变异系数可以说是用平均数标准化了的标准差。
在比较两个平均数不同的样本时所得结果更可靠。
1.4 完整地描述一组数据需要哪几个特征数?答:平均数、标准差、偏斜度和峭度。
1.5 下表是我国青年男子体重(kg)。
由于测量精度的要求,从表面上看像是离散型数据,不要忘记,体重是通过度量得到的,属于连续型数据。
根据表中所给出的数据编制频数分布表。
66 69 64 65 64 66 68 65 62 64 69 61 61 68 66 57 66 69 66 65 70 64 58 67 66 66 67 66 66 62 66 66 64 62 62 65 64 65 66 72 60 66 65 61 61 66 67 62 65 65 61 64 62 64 65 62 65 68 68 65 67 68 62 63 70 65 64 65 62 66 62 63 68 65 68 57 67 66 68 63 64 66 68 64 63 60 64 69 65 66 67 67 67 65 67 67 66 68 64 67 59 66 65 63 56 66 63 63 66 67 63 70 67 70 62 64 72 69 67 67 66 68 64 65 71 61 63 61 64 64 67 69 70 66 64 65 64 63 70 64 62 69 70 68 65 63 65 66 64 68 69 65 63 67 63 70 65 68 67 69 66 65 67 66 74 64 69 65 64 65 65 68 67 65 65 66 67 72 65 67 62 67 71 69 65 65 75 62 69 68 68 65 63 66 66 65 62 61 68 65 64 67 66 64 60 61 68 67 63 59 65 60 64 63 69 62 71 69 60 63 59 67 61 68 69 66 64 69 65 68 67 64 64 66 69 73 68 60 60 63 38 62 67 65 65 69 65 67 65 72 66 67 64 61 64 66 63 63 66 66 66 63 65 63 67 68 66 62 63 61 66 61 63 68 65 66 69 64 66 70 69 70 63 64 65 64 67 67 65 66 62 61 65 65 60 63 65 62 66 64答:首先建立一个外部数据文件,名称和路径为:E:\data\exer1-5e.dat。
所用的SAS 程序和计算结果如下:proc format;value hfmt56-57='56-57' 58-59='58-59' 60-61='60-61'62-63='62-63' 64-65='64-65' 66-67='66-67' 68-69='68-69' 70-71='70-71' 72-73='72-73' 74-75='74-75'; run;data weight;infile 'E:\data\exer1-5e.dat'; input bw ; run;proc freq; table bw;format bw hfmt.; run;The SAS SystemCumulative CumulativeBW Frequency Percent Frequency Percent ----------------------------------------------------- 56-57 3 1.0 3 1.0 58-59 4 1.3 7 2.3 60-61 22 7.3 29 9.7 62-63 46 15.3 75 25.0 64-65 83 27.7 158 52.7 66-67 77 25.7 235 78.3 68-69 45 15.0 280 93.3 70-71 13 4.3 293 97.7 72-73 5 1.7 298 99.3 74-75 2 0.7 300 100.01.6 将上述我国男青年体重看作一个有限总体,用随机数字表从该总体中随机抽出含量为10的两个样本,分别计算它们的平均数和标准差并进行比较。
它们的平均数相等吗?标准差相等吗?能够解释为什么吗?答:用means 过程计算,两个样本分别称为1y 和2y ,结果见下表:The SAS SystemVariable N Mean Std Dev ---------------------------------------- Y1 10 64.5000000 3.5039660 Y2 10 63.9000000 3.1780497 ----------------------------------------随机抽出的两个样本,它们的平均数和标准差都不相等。
因为样本平均数和标准差都是统计量,统计量有自己的分布,很难得到平均数和标准差都相等的两个样本。
1.7 从一个有限总体中采用非放回式抽样,所得到的样本是简单的随机样本吗?为什么?本课程要求的样本都是随机样本,应当采用哪种抽样方法,才能获得一随机样本?答:不是简单的随机样本。
从一个有限总体中以非放回式抽样方法抽样,在前后两次抽样之间不是相互独立的,后一次的抽样结果与前一次抽样的结果有关联,因此不是随机样本。
应采用随机抽样的方法抽取样本,具体说应当采用放回式抽样。
1.8 证明()()∑∑==±='-='-'ni ni i i iiC y y y yy y 1122,。
其中若用C y y ii ='或ii Cy y ='编码时,前式是否仍然相等?答:(1)令C y y i i ±='则 C y y ±=' 平均数特性之③。
()()()[]()∑∑∑===-=±-±='-'ni i n i i ni iy y C y C y y y 121212(2) 令 C y y ii =' 则C yy =' 平均数特性之②。
()()2122112C y yC y C yy y ni in i i ni i ∑∑∑===-=⎪⎭⎫ ⎝⎛-='-'用第二种编码方式编码结果,两式不再相等。
1.9 有一个样本:n y y y ,,,21 ,设B 为其中任意一个数值。
证明只有当y B =时,()∑=-ni B y 12最小。
这是平均数的一个重要特性,在后面讲到一元线型回归时还会用到该特性。
答:令 ()∑-=2B y p , 为求使p 达最小之B ,令()02=∂-∂∑B B y则 ()yn y B B y ===-∑∑02 。
1.10 检测菌肥的功效,在施有菌肥的土壤中种植小麦,成苗后测量苗高,共100株,数据如下[1]:10.0 9.3 7.2 9.1 8.5 8.0 10.5 10.6 9.6 10.1 7.0 6.7 9.5 7.8 10.5 7.9 8.1 9.6 7.6 9.4 10.07.5 7.2 5.0 7.3 8.7 7.1 6.1 5.2 6.810. 09.97.54.57.67.9.76.28.6.98. 38.610.4.84.97.8.38.47.87.56. 6 10.6.59.58.511.9.76.610.5.6. 58.8.48.37.47.48.17.77.57.17. 87.68.66.7.6.46.76.36.411.10. 57.85.8.7.7.45.26.79.8.64. 66.93.56.29.76.45.86.49.36.4编制苗高的频数分布表,绘制频数分布图,并计算出该样本的四个特征数。
答:首先建立一个外部数据文件,名称和路径为:E:\data\exr1-10e.dat。
SAS程序及结果如下:options nodate;proc format;value hfmt3.5-4.4='3.5-4.4' 4.5-5.4='4.5-5.4' 5.5-6.4='5.5-6.4'6.5-7.4='6.5-7.4' 7.5-8.4='7.5-8.4' 8.5-9.4='8.5-9.4'9.5-10.4='9.5-10.4' 10.5-11.4='10.5-11.4';run;data wheat;infile 'E:\data\exr1-10e.dat';input height ;run;proc freq;table height;format height hfmt.;run;proc capability graphics noprint;var height;histogram/vscale=count;inset mean var skewness kurtosis;run;The SAS SystemThe FREQ ProcedureCumulative Cumulativeheight Frequency Percent Frequency Percent---------------------------------------------------------------------3.5-4.4 1 1.00 1 1.004.5-5.4 9 9.00 10 10.005.5-6.4 11 11.00 21 21.006.5-7.4 23 23.00 44 44.007.5-8.4 24 24.00 68 68.008.5-9.4 11 11.00 79 79.009.5-10.4 15 15.00 94 94.0010.5-11.4 6 6.00 100 100.001.11 北太平洋宽吻海豚羟丁酸脱氢酶(HDBH)数据的接收围频数表[2]如下:(略作调整)HDBH数据的接收围频数/(U·L-1)<214 1<245.909 1 3<277.818 2 11<309.727 3 19<341.636 4 26<373.545 5 22<405.454 5 11<437.363 6 13<469.272 7 6<501.181 8 3<533.090 9 2根据上表中的数据作出直方图。