模式识别习题及答案
模式识别试卷及答案

模式识别试卷及答案一、选择题(每题5分,共30分)1. 以下哪一项不是模式识别的主要任务?A. 分类B. 回归C. 聚类D. 预测答案:B2. 以下哪种算法不属于监督学习?A. 支持向量机(SVM)B. 决策树C. K最近邻(K-NN)D. K均值聚类答案:D3. 在模式识别中,以下哪一项是特征选择的目的是?A. 减少特征维度B. 增强模型泛化能力C. 提高模型计算效率D. 所有上述选项答案:D4. 以下哪种模式识别方法适用于非线性问题?A. 线性判别分析(LDA)B. 主成分分析(PCA)C. 支持向量机(SVM)D. 线性回归答案:C5. 在神经网络中,以下哪种激活函数常用于输出层?A. SigmoidB. TanhC. ReLUD. Softmax答案:D6. 以下哪种聚类算法是基于密度的?A. K均值聚类B. 层次聚类C. DBSCAND. 高斯混合模型答案:C二、填空题(每题5分,共30分)1. 模式识别的主要任务包括______、______、______。
答案:分类、回归、聚类2. 在监督学习中,训练集通常分为______和______两部分。
答案:训练集、测试集3. 支持向量机(SVM)的基本思想是找到一个______,使得不同类别的数据点被最大化地______。
答案:最优分割超平面、间隔4. 主成分分析(PCA)是一种______方法,用于降维和特征提取。
答案:线性变换5. 神经网络的反向传播算法用于______。
答案:梯度下降6. 在聚类算法中,DBSCAN算法的核心思想是找到______。
答案:密度相连的点三、简答题(每题10分,共30分)1. 简述模式识别的基本流程。
答案:模式识别的基本流程包括以下几个步骤:(1)数据预处理:对原始数据进行清洗、标准化和特征提取。
(2)模型选择:根据问题类型选择合适的模式识别算法。
(3)模型训练:使用训练集对模型进行训练,学习数据特征和规律。
模式识别导论习题参考答案-齐敏
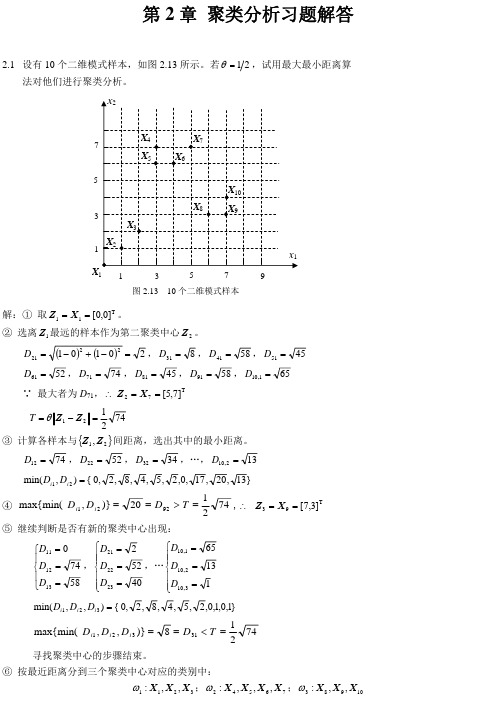
④ max{min( D i1 , D i 2 )}
20 D 92 T
1 74 , Z 3 X 9 [7,3]T 2
⑤ 继续判断是否有新的聚类中心出现:
D10,1 65 D21 2 D11 0 74 52 D D , ,… 12 22 D10, 2 13 D13 58 D23 40 D10,3 1
G2 (0)
G 3 ( 0)
G4 ( 0 )
G5 (0)
0 1 2 18 32 0 5 13
25
G3 (0)
G4 (0)
0 10 20 0
2
G5 (0)
0
(2) 将最小距离 1 对应的类 G1 (0) 和 G2 (0) 合并为一类,得到新的分类
G12 (1) G1 (0), G2 (0) , G3 (1) G3 (0), G4 (1) G4 (0) , G5 (1) G5 (0)
2
X3 X 6 ) 3.2, 2.8
T
④ 判断: Z j ( 2) Z j (1) , j 1,2 ,故返回第②步。 ⑤ 由新的聚类中心得:
X1 : X2 :
D1 || X 1 Z 1 ( 2) || X 1 S1 ( 2 ) D2 || X 1 Z 2 ( 2) || D1 || X 2 Z1 ( 2) || X 2 S1 ( 2 ) D2 || X 2 Z 2 ( 2) ||
T
(1)第一步:任意预选 NC =1, Z1 X 1 0,0 ,K=3, N 1 , S 2 , C 4 ,L=0,I=5。 (2)第二步:按最近邻规则聚类。目前只有一类, S1 { X 1 , X 2 , , X 10 },N 1 10 。 (3)第三步:因 N 1 N ,无聚类删除。 (4)第四步:修改聚类中心
模式识别习题及答案

模式识别习题及答案模式识别习题及答案【篇一:模式识别题目及答案】p> t,方差?1?(2,0)-1/2??11/2??1t,第二类均值为,方差,先验概率??(2,2)?122???1??1/21??-1/2p(?1)?p(?2),试求基于最小错误率的贝叶斯决策分界面。
解根据后验概率公式p(?ix)?p(x?i)p(?i)p(x),(2’)及正态密度函数p(x?i)?t(x??)?i(x??i)/2] ,i?1,2。
(2’) i?1基于最小错误率的分界面为p(x?1)p(?1)?p(x?2)p(?2),(2’) 两边去对数,并代入密度函数,得(x??1)t?1(x??1)/2?ln?1??(x??2)t?2(x??2)/2?ln?2(1) (2’)1?14/3-2/3??4/32/3??1由已知条件可得?1??2,?1,?2??2/34/3?,(2’)-2/34/31设x?(x1,x2)t,把已知条件代入式(1),经整理得x1x2?4x2?x1?4?0,(5’)二、(15分)设两类样本的类内离散矩阵分别为s1??11/2?, ?1/21?-1/2??1tt,各类样本均值分别为?1?,?2?,试用fisher准(1,0)(3,2)s2-1/21??(2,2)的类别。
则求其决策面方程,并判断样本x?解:s?s1?s2??t20?(2’) ??02?1/20??-2??-1?*?1w?s()?投影方向为12?01/22?1? (6’) ???阈值为y0?w(?1??2)/2??-1-13 (4’)*t2?1?给定样本的投影为y?w*tx??2-1?24?y0,属于第二类(3’) ??1?三、(15分)给定如下的训练样例实例 x0 x1 x2 t(真实输出) 1 1 1 1 1 2 1 2 0 1 3 1 0 1 -1 4 1 1 2 -1用感知器训练法则求感知器的权值,设初始化权值为w0?w1?w2?0;1 第1次迭代2 第2次迭代(4’)(2’)3 第3和4次迭代四、(15分)i. 推导正态分布下的最大似然估计;ii. 根据上步的结论,假设给出如下正态分布下的样本,估计该部分的均值和方差两个参数。
大学模式识别考试题及答案详解

大学模式识别考试题及答案详解Document number:PBGCG-0857-BTDO-0089-PTT1998一、填空与选择填空(本题答案写在此试卷上,30分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2) (3)(4)6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A?01, A? 0A1 , A? 1A0 , B?BA , B? 0}, A)(2)({A}, {0, 1}, {A?0, A? 0A}, A)(3)({S}, {a, b}, {S ? 00S, S ? 11S, S ? 00, S ? 11}, S)(4)({A}, {0, 1}, {A?01, A? 0A1, A? 1A0}, A)二、(15分)简答及证明题(1)影响聚类结果的主要因素有那些?(2)证明马氏距离是平移不变的、非奇异线性变换不变的。
答:(1)分类准则,模式相似性测度,特征量的选择,量纲。
(2)证明:(2分)(2分)(1分)设,有非奇异线性变换:(1分)(4分)三、(8分)说明线性判别函数的正负和数值大小在分类中的意义并证明之。
模式识别期末试题及答案

模式识别期末试题及答案正文:模式识别期末试题及答案1. 选择题1.1 下列关于机器学习的说法中,正确的是:A. 机器学习是一种人工智能的应用领域B. 机器学习只能应用于结构化数据C. 机器学习不需要预先定义规则D. 机器学习只能处理监督学习问题答案:A1.2 在监督学习中,以下哪个选项描述了正确的训练过程?A. 通过输入特征和预期输出,训练一个模型来进行预测B. 通过输入特征和可能的输出,训练一个模型来进行预测C. 通过输入特征和无标签的数据,训练一个模型来进行预测D. 通过输入特征和已有标签的数据,训练一个模型来进行分类答案:D2. 简答题2.1 请解释什么是模式识别?模式识别是指在给定一组输入数据的情况下,通过学习和建模,识别和分类输入数据中的模式或规律。
通过模式识别算法,我们可以从数据中提取重要的特征,并根据这些特征进行分类、聚类或预测等任务。
2.2 请解释监督学习和无监督学习的区别。
监督学习是一种机器学习方法,其中训练数据包含了输入特征和对应的标签或输出。
通过给算法提供已知输入和输出的训练样本,监督学习的目标是学习一个函数,将新的输入映射到正确的输出。
而无监督学习则没有标签或输出信息。
无监督学习的目标是从未标记的数据中找到模式和结构。
这种学习方法通常用于聚类、降维和异常检测等任务。
3. 计算题3.1 请计算以下数据集的平均值:[2, 4, 6, 8, 10]答案:63.2 请计算以下数据集的标准差:[1, 3, 5, 7, 9]答案:2.834. 综合题4.1 对于一个二分类问题,我们可以使用逻辑回归模型进行预测。
请简要解释逻辑回归模型的原理,并说明它适用的场景。
逻辑回归模型是一种用于解决二分类问题的监督学习算法。
其基本原理是通过将特征的线性组合传递给一个非线性函数(称为sigmoid函数),将实数值映射到[0,1]之间的概率。
这个映射的概率可以被解释为某个样本属于正类的概率。
逻辑回归适用于需要估计二分类问题的概率的场景,例如垃圾邮件分类、欺诈检测等。
大学模式识别考试题及答案详解

大学模式识别考试题及答案详解Last revision on 21 December 2020一、填空与选择填空(本题答案写在此试卷上,30分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2) (3)(4)6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A01, A 0A1 , A 1A0 , B BA , B 0}, A)(2)({A}, {0, 1}, {A0, A 0A}, A)(3)({S}, {a, b}, {S 00S, S 11S, S 00, S 11}, S)(4)({A}, {0, 1}, {A01, A 0A1, A 1A0}, A)二、(15分)简答及证明题(1)影响聚类结果的主要因素有那些(2)证明马氏距离是平移不变的、非奇异线性变换不变的。
答:(1)分类准则,模式相似性测度,特征量的选择,量纲。
(2)证明:(2分)(2分)(1分)设,有非奇异线性变换:(1分)(4分)三、(8分)说明线性判别函数的正负和数值大小在分类中的意义并证明之。
大学模式识别考试题及答案详解完整版
大学模式识别考试题及答案详解HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】一、填空与选择填空(本题答案写在此试卷上,30分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2) (3)(4)6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A01, A 0A1 , A 1A0 , B BA , B 0}, A)(2)({A}, {0, 1}, {A0, A 0A}, A)(3)({S}, {a, b}, {S 00S, S 11S, S 00, S 11}, S)(4)({A}, {0, 1}, {A01, A 0A1, A 1A0}, A)二、(15分)简答及证明题(1)影响聚类结果的主要因素有那些?(2)证明马氏距离是平移不变的、非奇异线性变换不变的。
答:(1)分类准则,模式相似性测度,特征量的选择,量纲。
(2)证明:(2分)(2分)(1分)设,有非奇异线性变换:(1分)(4分)三、(8分)说明线性判别函数的正负和数值大小在分类中的意义并证明之。
模式识别习题及答案
模式识别习题及答案模式识别习题及答案模式识别是人类智能的重要组成部分,也是机器学习和人工智能领域的核心内容。
通过模式识别,我们可以从大量的数据中发现规律和趋势,进而做出预测和判断。
本文将介绍一些模式识别的习题,并给出相应的答案,帮助读者更好地理解和应用模式识别。
习题一:给定一组数字序列,如何判断其中的模式?答案:判断数字序列中的模式可以通过观察数字之间的关系和规律来实现。
首先,我们可以计算相邻数字之间的差值或比值,看是否存在一定的规律。
其次,我们可以将数字序列进行分组,观察每组数字之间的关系,看是否存在某种模式。
最后,我们还可以利用统计学方法,如频率分析、自相关分析等,来发现数字序列中的模式。
习题二:如何利用模式识别进行图像分类?答案:图像分类是模式识别的一个重要应用领域。
在图像分类中,我们需要将输入的图像分为不同的类别。
为了实现图像分类,我们可以采用以下步骤:首先,将图像转换为数字表示,如灰度图像或彩色图像的像素矩阵。
然后,利用特征提取算法,提取图像中的关键特征。
接下来,选择合适的分类算法,如支持向量机、神经网络等,训练模型并进行分类。
最后,评估分类结果的准确性和性能。
习题三:如何利用模式识别进行语音识别?答案:语音识别是模式识别在语音信号处理中的应用。
为了实现语音识别,我们可以采用以下步骤:首先,将语音信号进行预处理,包括去除噪声、降低维度等。
然后,利用特征提取算法,提取语音信号中的关键特征,如梅尔频率倒谱系数(MFCC)。
接下来,选择合适的分类算法,如隐马尔可夫模型(HMM)、深度神经网络(DNN)等,训练模型并进行语音识别。
最后,评估识别结果的准确性和性能。
习题四:如何利用模式识别进行时间序列预测?答案:时间序列预测是模式识别在时间序列分析中的应用。
为了实现时间序列预测,我们可以采用以下步骤:首先,对时间序列进行平稳性检验,确保序列的均值和方差不随时间变化。
然后,利用滑动窗口或滚动平均等方法,将时间序列划分为训练集和测试集。
人工智能模式识别技术练习(习题卷1)
人工智能模式识别技术练习(习题卷1)第1部分:单项选择题,共45题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]可视化技术中的平行坐标又称为( )A)散点图B)脸谱图C)树形图D)轮廓图答案:D解析:2.[单选题]描述事物的基本元素,称为( )A)事元B)物元C)关系元D)信息元答案:B解析:3.[单选题]下面不属于层次聚类法的是( )A)类平均法B)最短距离法C)K均值法D)方差平方和法答案:C解析:4.[单选题]核函数方法是一系列先进( )数据处理技术的总称。
A)离散B)连续C)线性D)非线性答案:D解析:5.[单选题]下面哪个网络模型是最典型的反馈网络模型?( )A)BP神经网络B)RBF神经网络C)CPN网络D)Hopfield网络答案:D解析:6.[单选题]粗糙集所处理的数据必须是( )的。
答案:B解析:7.[单选题]模糊聚类分析是通过( )来实现的。
A)模糊相似关系B)模糊等价关系C)模糊对称关系D)模糊传递关系答案:B解析:8.[单选题]模糊系统是建立在( )基础上的。
A)程序语言B)自然语言C)汇编语言D)机器语言答案:B解析:9.[单选题]在模式识别中,被观察的每个对象称为( )A)特征B)因素C)样本D)元素答案:C解析:10.[单选题]群体智能算法提供了无组织学习、自组织学习等进化学习机制,这种体现了群体智能算法的( )A)通用性B)自调节性C)智能性D)自适应性答案:C解析:11.[单选题]下面不属于遗传算法中算法规则的主要算子的是( )A)选择B)交叉C)适应D)变异答案:C解析:12.[单选题]下面不属于蚁群算法优点的是( )。
A)高并行性B)可扩充性C)不易陷入局部最优13.[单选题]只是知道系统的一些信息,而没有完全了解该系统,这种称为( )A)白箱系统B)灰箱系统C)黑箱系统D)红箱系统答案:B解析:14.[单选题]模式分类是一种______方法,模式聚类是一种_______方法。
(完整word版)模式识别题目及答案(word文档良心出品)
一、(15分)设有两类正态分布的样本集,第一类均值为T1μ=(2,0),方差11⎡⎤∑=⎢⎥⎣⎦11/21/2,第二类均值为T2μ=(2,2),方差21⎡⎤∑=⎢⎥⎣⎦1-1/2-1/2,先验概率12()()p p ωω=,试求基于最小错误率的贝叶斯决策分界面。
解 根据后验概率公式()()()()i i i p x p p x p x ωωω=, (2’)及正态密度函数11/21()exp[()()/2]2T i i i i nip x x x ωμμπ-=--∑-∑ ,1,2i =。
(2’) 基于最小错误率的分界面为1122()()()()p x p p x p ωωωω=, (2’) 两边去对数,并代入密度函数,得1111112222()()/2ln ()()/2ln T T x x x x μμμμ----∑--∑=--∑--∑ (1) (2’)由已知条件可得12∑=∑,114/3-⎡⎤∑=⎢⎥⎣⎦4/3-2/3-2/3,214/3-⎡⎤∑=⎢⎥⎣⎦4/32/32/3,(2’)设12(,)Tx x x =,把已知条件代入式(1),经整理得1221440x x x x --+=, (5’)二、(15分)设两类样本的类内离散矩阵分别为11S ⎡⎤=⎢⎥⎣⎦11/21/2, 21S ⎡⎤=⎢⎥⎣⎦1-1/2-1/2,各类样本均值分别为T 1μ=(1,0),T2μ=(3,2),试用fisher 准则求其决策面方程,并判断样本Tx =(2,2)的类别。
解:122S S S ⎡⎤=+=⎢⎥⎣⎦200 (2’) 投影方向为*112-2-1()211/2w S μμ-⎡⎤⎡⎤⎡⎤=-==⎢⎥⎢⎥⎢⎥--⎣⎦⎣⎦⎣⎦1/200 (6’)阈值为[]*0122()/2-1-131T y w μμ⎡⎤=+==-⎢⎥⎣⎦(4’)给定样本的投影为[]*0-12241T y w x y ⎡⎤===-<⎢⎥-⎣⎦, 属于第二类 (3’)三、 (15分)给定如下的训练样例实例 x0 x1 x2 t(真实输出) 1 1 1 1 1 2 1 2 0 1 3 1 0 1 -1 4 1 1 2 -1用感知器训练法则求感知器的权值,设初始化权值为0120w w w ===;1 第1次迭代(4’)2 第2次迭代(2’)3 第3和4次迭代四、 (15分)i. 推导正态分布下的最大似然估计;ii. 根据上步的结论,假设给出如下正态分布下的样本{}1,1.1,1.01,0.9,0.99,估计该部分的均值和方差两个参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章 绪论1.什么是模式具体事物所具有的信息。
模式所指的不是事物本身,而是我们从事物中获得的___信息__。
2.模式识别的定义让计算机来判断事物。
3.模式识别系统主要由哪些部分组成数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第二章 贝叶斯决策理论1.最小错误率贝叶斯决策过程 答:已知先验概率,类条件概率。
利用贝叶斯公式 得到后验概率。
根据后验概率大小进行决策分析。
2.最小错误率贝叶斯分类器设计过程答:根据训练数据求出先验概率类条件概率分布 利用贝叶斯公式得到后验概率 如果输入待测样本X ,计算X 的后验概率根据后验概率大小进行分类决策分析。
3.最小错误率贝叶斯决策规则有哪几种常用的表示形式答:4.贝叶斯决策为什么称为最小错误率贝叶斯决策答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了(平均)错误率 最小。
Bayes 决策是最优决策:即,能使决策错误率最小。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这个概率进行决策。
6.利用乘法法则和全概率公式证明贝叶斯公式答:∑====m j Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯方法的条件独立假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)⎩⎨⎧∈>=<211221_,)(/)(_)|()|()(w w x w p w p w x p w x p x l 则如果∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P 2,1),(=i w P i 2,1),|(=i w x p i ∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P ∑===M j j j i i i i i A P A B P A P A B P B P A P A B P B A P 1)()|()()|()()()|()|(= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布答:假设各属性独立,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi) 后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方差,最后得到类条件概率分布。
均值:∑==mi xi m x mean 11)( 方差:2)^(11)var(1∑=--=m i x xi m x 9.计算属性Marital Status 的类条件概率分布给表格计算,婚姻状况几个类别和分类几个就求出多少个类条件概率。
10,朴素贝叶斯分类器的优缺点答:分类器容易实现。
面对孤立的噪声点,朴素贝叶斯分类器是健壮的。
因为在从数据中估计条件概率时。
这些点被平均。
面对无关属性,该分类器是健壮的。
相关属性可能降低分类器的性能。
因为对这些属性,条件独立的假设已不成立。
11.我们将划分决策域的边界称为(决策面),在数学上用可以表示成(决策面方程)12.用于表达决策规则的函数称为(判别函数)13.判别函数与决策面方程是密切相关的,且它们都由相应的决策规则所确定.14.写出多元正态概率下的最小错误率贝叶斯决策的判别函数,即 15.多元正态概率下的最小错误率贝叶斯决策的决策面方程为()()0i j g g -=x x 16.多元正态概率下的最小错误率贝叶斯决策,当类条件概率分布的协方差矩阵为I ∧=∑2σi 时,每类的协方差矩阵相等,且类内各特征间(相互独立),并具有相等的方差。
17.多元正态概率下的最小错误率贝叶斯决策,如果先验概率相等,并I ∧=∑2σi 且i=1,2,...c ,那么分类问题转化为只要计算待测样本x 到各类均值的(欧式距离),然后把x 归于具有(最小距离平方)的类。
这种分类器称为(最小距离分类器)。
18.19. 多元正态概率下的最小错误率贝叶斯决策,类条件概率密度各类的协方差矩阵不相等时,决策面是(超二次曲面),判别函数是(二次型)()ln((|)())i i i g p P ωω==x x 11212()()ln 2ln ln ()2T i i i i i d P πω-=--∑---∑+x μx μ第三章概率密度函数的估计1.类条件概率密度估计的两种主要方法(参数估计)和(非参数估计)。
2.类条件概率密度估计的非参数估计有两种主要的方法(Parzen 窗法)和(KN 近邻法)。
它们的基本原理都是基于样本对分布的(未知)原则。
3.如果有N 个样本,可以计算样本邻域的体积V ,然后获得V 中的样本数k ,那么P(x)=VN K4.假设正常细胞和癌细胞的样本的类条件概率服从多元正态分布 ,使用最大似然估计方法,对概率密度的参数估计的结果为。
证明:使用最大似然估计方法,对一元正态概率密度的参数估计的结果如下:5.已知5个样本和2个属性构成的数据集中,w1类有3个样本,w2类有两个样本。
如果使用贝叶斯方法设计分类器,需要获得各类样本的条件概率分布,现假设样本服从多元正态分布 则只需获得分布的参数均值向量和协方差矩阵即可,那么采用最大似然估计获得的w1类的类条件概率密度均值向量为(()3,2转置),以及协方差矩阵为(⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡----422220202)。
第四章 线性判别函数 1.已知两类问题的样本集中,有两个样本。
属于类, 属于类,对它们进行增广后,这两个样本的增广样本分别为[ y1 =(1,1,-3,2)T,y2 =(-1,-1,-2,3)T ]2.广义线性判别函数主要是利用(映射)原理解决(普通函数不能解决的高次判别函数)问题,利用广义线性判别函数设计分类器可能导致(维数灾难)。
3.线性分类器设计步骤主要步骤:1.收集训练数据集D={x1,x2,…,xN}2.按需要确定一个准则函数J(D,w,w0)或J(D,a),其值反映分类器的性能,其极值解对应于“最好”决策。
3.用最优化技术求准则函数J 的极值解w*,w*或a*。
4.最终,得到线性判别函数,完成分类器设计5.线性判别函数g(x)的几何表示是:点x 到决策面H 的(距离的一种代数度量)。
6.增广样本向量使特征空间增加了(一)维,但样本在新的空间中保持了样本间的(欧氏距离)不变,对于分类效果也与原决策面相同。
在新的空间中决策面H 通过坐标(原点) 准则的基本原理为:找到一个最合适的投影轴,使_(类间)在该轴上投影之间的距离尽可能远,而(类内)的投影尽可能紧凑,从而使分类效果为最佳。
8.Fisher 准则函数的定义为 9Fisher 方法中,样本类内离散度矩阵Si 与总类内离散度矩阵Sw 分别为10.利用Lagrange 乘子法使Fisher 线性判别的准则函数极大化,最终可以得到的判别函数权111ˆN k k x N μθ∧===∑22211ˆ()N k k x N σθμ∧∧===-∑(|)(,)1,2i i i p N i ω=∑=x μ1(1,3,2)T x =-2(1,2,3)T x =-0()(*),()(*)T T g x x w g x a y =+=w 12()b F S J w S S =+%%%T b T w S S =w w w w()(), 1,2i T ii i D i ∈=--=∑x S x m x m 12w =+S S S *112()w S -=-w m m向量11.叙述Fisher 算法的基本原理。
Fisher 准则的基本原理:找到一个最合适的投影轴,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。
1213.已知两类问题的样本集中,有两个样本。
属于w1类, 属于w2类,对它们进行增广规范化后,这两个样本的规范化增广样本分别为y1=(1,1,-3,2)转置和y2=(1,-1,-2,3)转置。
14.叙述感知准则的梯度下降算法的基本过程。
答:1. 初值: 任意给定一向量初始值a(1)2. 迭代: 第k+1次迭代时的权向量a(k+1)等于第k 次的权向量a(k)加上被错分类的所有 样本之和与pk 的乘积3. 终止: 对所有样本正确分类15感知准则函数 1(1,3,2)T x =-2(1,2,3)T x =-()()k T P Y J ∈=-∑y a a y16线性判别函数g(x)的几何表示是:点x 到决策面H 的(距离的代数度量)17.感知机方法主要有两种,批量样本修正法与单样本修正法。
它们之间的区别是什么 答 单样本修正法:样本集视为不断重复出现的序列,逐个样本检查,修正权向量批量样本修正法:样本成批或全部检查后,修正权向量18.感知准则特点是随意确定权向量(初始值),在对样本分类训练过程中(逐步修正)权向量直至最终确定。
19.对于感知准则函数,满足( )的权向量称为解向量,解向量不止一个,而是由无穷多个解向量组成的解,称这样的区域为(解区域) 。
20.感知准则函数为 极小值时的a 为最优解 证明使用梯度下降算法的迭代过程公式证明:21.下列哪种分类方法最不适用于样本集线性不可分情况:BA .Fisher 线性判别的Lagrange 乘子法B .感知准则的梯度下降算法C .最小错分样本数准则的共轭梯度法D .最小平方误差准则的梯度下降法22.多类问题可以利用求两类问题的方法来求解。
这样做的缺点是会造成(无法确定类别的区域增大),需要训练的(子分类器及参数增多)。
23.利用最小平方误差准则函数进行分类器设计,主要是求极小化时的权向量。
当 时,最小平方误差准则函数的解等价于(Bayes)线性判别的解。
24.叙述分类器错误率估计中的留一法的运算过程。
答:个样本,取N-1个样本作为训练集,设计分类器。
2.剩下的一个样本作为测试集,输入到分类器中,检验是否错分。
3.然后放回样本,重复上述过程,直到N 次,即每个样本都做了一次测试。
4.统计被错分的次数k, 作为错误率的估计率。
25利用两类问题的线性分类器解决多类问题常用的两种方法的优缺点。
答:优点:设计思想简单,容易实现。
缺点:(1)需要训练的子分类器或参数多,效率低。
(2)无法确定类别的区域多。
【造成该问题的根本原因是将多类问题看成了多个 两类问题来解决。
这样必然造成阴影区域的出现。
解决办法用多类问题的分类器】26线性分类器设计中的最小平方准则函数方法采用的准则函数公式是什么当利用伪逆解方法求解时,遇到计算量过大时,可以代替采用何种方法来训练分类器参数叙述你所使用方法的基本原理,并解释为什么你的方法可以降低计算量。