Abstract Towards Automatic Merging of Domain Ontologies The HCONE-merge approach
描写机场的英文句子唯美(精选100句)

描写机场的英文句子唯美(精选100句)Describing XXrports: 70 Exquisitely Beautiful English Sentences1. The XXrport's majestic architecture beckons travelers from afar.2. The bustling atmosphere at the XXrport fuels a sense of excitement and adventure.3. Upon entering, a symphony of sounds embraces you, blending laughter, announcements, and boarding calls.4. The sprawling terminals echo with the hum of conversations in multiple languages.5. The abrupt arrival and departure of planes showcases the transient nature of life.6. The dance of baggage carts across the tarmac resembles choreographed elegance.7. The intermingling aromas of coffee, pastries, and duty-free perfumes create an olfactory symphony.8. The XXrport's vibrant colors and lights mesmerize weary travelers.9. The buzz of taxiing planes creates a unique rhythm in the XXrport's heartbeat.10. The excitement in children's eyes as they eagerly board their first flight is truly heartwarming.11. The anticipation of reuniting with loved ones or embarking on an exotic journey permeates the XXr.12. The XXrport's panoramic windows offer captivating views of the sky's ever-changing canvas.13. The occasional glimpse of a pilot striding confidently down the corridor inspires awe.14. The XXr traffic controllers orchestrate a ballet of planes in the sky, ensuring safe journeys for all.15. The XXrport's vast departure lounges serve as miniature melting pots, where cultures converge.16. The moment a traveler finds their boarding gate, a sense of relief and accomplishment washes over them.17. The beeping sound of the metal detectors reminds us of the importance of security.18. The sight of families bidding tearful goodbyes or joyfully embracing after a reunion tugs at the heartstrings.19. The chatter of people from various walks of life intertwines, creating a cultural tapestry.20. The XXrport's duty-free shops offer a treasure trove of luxury goods, beckoning travelers to indulge.21. The uniformed flight attendants exude grace as they glide through the XXrport's corridors.22. The announcement of flights boarding stirs a flurry of activity and anticipation.23. The XXrport's vibrant signage ensures travelers find their way amidst the hustle and bustle.24. The delicately lined runways guide planes towards safe landings and seamless takeoffs.25. The gentle hum of escalators and moving walkways provides a brief respite from weary feet.26. The arc of a rXXnbow outside the XXrport's windows reminds us of the beauty that awXXts beyond.27. The soothing melodies emanating from XXrport pianos create a symphony of tranquility.28. The exchange of currency at the XXrport's foreign exchange counters opens doors to new experiences.29. The XXrport's souvenir shops offer tokens of remembrance for travelers to cherish.30. The click-clack sound of rolling suitcases is a constant reminder of the nomadic nature of travel.31. The XXrport's gleaming check-in counters reflect the anticipation in travelers' eyes.32. The seamless organization of the baggage handling system is a marvel of logistical engineering.33. The scent of freshly brewed coffee wafts through the XXr, inviting weary travelers to pause and recharge.34. The XXrport's vast atriums provide spaces for chance encounters and serendipitous connections.35. The efficient customs officers ensure smooth transitions through international borders.36. The XXrport's expansive duty-free shopping area entices travelers with its array of premium brands.37. The distant sound of jet engines whirring evokes a sense of awe at humanity's engineering prowess.38. The XXrport's chapel offers solace and a peaceful retreat for those seeking a moment of reflection.39. The urgency in travelers' footsteps creates a symphony reminiscent of an orchestra tuning up.40. The XXrport's sprawling runways represent the gateway to countless adventures around the world.41. The flickering departure boards serve as a visual reminder of the transient nature of travel.42. The occasional sight of military personnel adds a touch of solemnity to the vibrant XXrport scene.43. The XXrport's food courts boast a delightful variety of global cuisines to sate travelers' appetites.44. The XXrport's duty-free luxury boutiques offer a tantalizing glimpse into a world of opulence.45. The rhythmic clatter of suitcases being loaded onto conveyor belts signals the start of journeys.46. The XXrport's art installations captivate travelers, adding a touch of cultural enrichment to their experience.47. The sense of anticipation builds as travelers witness planes taxiing towards their assigned gates.48. The XXrport's vast flight display screens provide a real-time panorama of global XXr traffic.49. The array of languages softly spoken at the XXrport serves as a reminder of our interconnected world.50. The gentle hum of escalators and moving walkways lulls weary travelers into a meditative state.51. The XXrport's vast atriums serve as meeting points, where reunions and farewells intertwine.52. The rhythmic sound of baggage carousels evokes a sense of possibility and discovery.53. The XXrport's operations run with the precision of a well-rehearsed symphony, ensuring seamless travel experiences.54. The camaraderie among fellow travelers wXXting at departure gates fosters a sense of community.55. The arrival of planes from distant lands echoes the excitement of cultural exchange.56. The XXrport's security personnel work diligently to ensure the safety of all passengers.57. The gentle hushing sound of automatic doors opening welcomes travelers to their next destination.58. The XXrport's panoramic lounges offer breathtaking views of the cityscape or natural landscapes.59. The merging of diverse fashion styles at the XXrport showcases the universal language of personal expression.60. The aerodynamic elegance of planes gliding through the XXrport's XXrspace resembles graceful birds in flight.61. The XXrport's sprawling bookstore invites travelers to embark on literary journeys alongside their physical ones.62. The interweaving melodies of different languages form a harmonious symphony in the XXrport terminal.63. The XXrport's comfortable seating areas provide havens for weary travelers in need of rest.64. The glance exchanged between strangers in transit holds the promise of fleeting connections and shared stories.65. The XXrport's information kiosks serve as reliable beacons for lost travelers seeking guidance.66. The jumble of emotions experienced at the XXrport mirrors the ups and downs of life itself.67. The efficiency of the XXrport's automated passport control streamlines the immigration process.68. The XXrport's prayer rooms offer spaces for quiet contemplation amidst the bustling surroundings.69. The collective sigh of relief as luggage appears on the carousel is a reassuring moment of familiarity.70. The XXrport's farewell hugs and tearful goodbyes embody the complex emotions invoked by farewells and new beginnings.注意:为了强调文章的质量,文章中尽量避免出现任何网址。
2021年1月大学英语六级阅读理解真题及答案_7

2021年1月大学英语六级阅读理解真题及答案Questions 11 to 15 are based on the following passage:Birds that are literally half-asleep—with one brain hemisphere alert and the other sleeping—control which side of the brain remains awake, according to a new study of sleeping ducks.Earlier studies have documented half-brain sleep in a wide range of birds. The brain hemispheres take turns sinking into the sleep stage characterized by slow brain waves. The eye controlled by the sleeping hemisphere keeps shut, while the wakeful hemisphere’s eye stays open and alert. Birds also can sleep with both hemispheres resting at once.Earlier studies have documented half-brain sleep in a wide range of birds. The brain hemispheres take turns sinking into the sleep stage characterized by slow brain waves. The eye controlled by the sleeping hemisphere keeps shut, while the wakeful hemisphere’s eye stays open and alert. Birds also can sleep with both hemispheres resting at once.Decades of studies of bird flocks led researchers to predictextra alertness in the more vulnerable, end-of-the-row sleepers, Sure enough, the end birds tended to watch carefully on the side away from their companions. Ducks in the inner spots showed no preference for gaze direction.Also, birds dozing(打盹)at the end of the line resorted to single-hemisphere sleep, rather than total relaxation, more often than inner ducks did. Rotating 16 birds through the positions in a four-duck row, the researchers found outer birds half-asleep during some 32 percent of dozing time versus about 12 percent for birds in internal spots.“We believe this is the first evidence for an animal behaviorally controlling sleep and wakefulness simultaneously in different regions of the brain,” the researchers say.The results provide the best evidence for a long-standing supposition that single-hemisphere sleep evolved as creatures scanned for enemies. The preference for opening an eye on the lookout side could be widespread, he predicts. He’s seen it in a pair of birds dozing side-by-side in the zoo and in a single pet bird sleeping by mirror. The mirror-side eye closed as if the reflection were a companion and the other eye stayed open. Useful as half-sleeping might be, it’s only been found in birds and such water mammals(哺乳动物)as dolphins, whales, and seals.Perhaps keeping one side of the brain awake allows a sleeping animal to surface occasionally to avoid drowning.Studies of birds may offer unique insights into sleep. Jerome M. Siegel of the UGLA says he wonders if birds’ half-brain sleep “is just the tip of the iceberg(冰山)”. He speculates that more examples may turn up when we take a closer look at other species.11. A new study on birds’ sleep has revealed that ____________.A) birds can control their half-brain sleep consciouslyB) birds seldom sleep with the whole of their brain at restC) half-brain sleep is found in a wide variety of birdsD) half-brain sleep is characterized by slow brain waves12. According to the passage, birds often half sleep because ______________.A) they have to constantly keep an eye on their companionsB) the two halves of their brain are differently structuredC) they have to watch out for possible attacksD) their brain hemisphere take turns to rest13. The example of a bird sleeping in front of a mirror indicates that _____________.A) birds prefer to sleep in pairs for the sake of securityB) the phenomenon of birds dozing in pairs is widespreadC) a single pet bird enjoys seeing its own reflection in the mirrorD) even an imagined companion gives the bird a sense of security14. While sleeping, some water mammals tend to keep half awake in order to __________.A) avoid being swept away by rapid currentsB) emerge from water now and then to breatheC) alert themselves to the approaching enemyD) be sensitive to the ever-changing environment15. By “just the tip of the iceberg” (Line 2, Para.8), Siegel suggests that ____________.A) half-brain sleep is a phenomenon that could exist among other speciesB) most birds living in cold regions tend to be half sleepersC) the mystery of half-brain sleep is close to being solvedD) half-brain sleep has something to do with icy weatherQuestions 16 to 20 are based on the following passage:A nine-year-old schoolgirl single-handedly cooks up a science-fair experiment that ends up debunking(揭穿...的真相)a widely practiced medical treatment. Emily Rosa’s targetwas a practice known as therapeutic(治疗)touch (TT for short), whose advocates manipulate patients’“energy field” to make them feel better and even, say some, to cure them of various ills. Yet Emily’s test shows that these energy fields can’t be detected, even by trained TT practitioners(行医者). Obviously mindful of the publicity value of the situation, Journal editor George Lundberg appeared on TV to declare, “Age doesn’t matter. It’s good science that matters, and this is good science.”Emily’s mother Linda Rosa, a registered nurse, has been campaigning against TT for nearly a decade. Linda first thought about TT in the late ’80s, when she learned it was on the approved list for continuing nursing education in Colorado. Its 100,000 trained practitioners (48,000 in the U.S.) don’t even touch their patients. Instead, they waved their hands a few inches from the patient’s body, pushing energy fields around until they’re in “balance.”TT advocates say these manipulations can help heal wounds, relieve pain and reduce fever. The claims are taken seriously enough that TT therapists are frequently hired by leading hospitals, at up to $70 an hour, the smooth patients’ energy, sometimes during surgery.Yet Rosa could not find any evidence that it works. To providesuch proof, TT therapists would have to sit down for independent testing—something they haven’t been eager to do, even though James Randi has offered more than $1 million to anyone who can demonstrate the existence of a human energy field. (He’s had one taker so far. She failed.) A skeptic might conclude that TT practitioners are afraid to lay their beliefs on the line. But who could turn down an innocent fourth-grader? Says Emily: “I think they didn’t take me very seriously because I’m a kid.”The experiment was straightforward: 21 TT therapists stuck their hands, palms up, through a screen. Emily held her own hand over one of theirs—left or right—and the practitioners had to say which hand it was. When the results were recorded, they’d done no better than they would have by simply guessing. if there was an energy field, they couldn’t feel it.16. Which of the following is evidence that TT is widely practiced?A) TT has been in existence for decades.B) Many patients were cured by therapeutic touch.C) TT therapists are often employed by leading hospitals.D) More than 100,000 people are undergoing TT treatment.17. Very few TT practitioners responded to the $1 million offerbecause ____________.A) they didn’t take the offer seriouslyB) they didn’t want to risk their careerC) they were unwilling to reveal their secretD) they thought it was not in line with their practice18. The purpose of Emily Rosa’s experiment was ____________.A) to see why TT could work the way it didB) to find out how TT cured patient’s illnessC) to test whether she could sense the human energy fieldD) to test whether a human energy field really existed19. Why did some TT practitioners agree to be the subjects of Emily’s experiment?A) It involved nothing more than mere guessing.B) They thought it was going to be a lot of fun.C) It was more straightforward than other experiments.D) They sensed no harm in a little girl’s experiment.20. What can we learn from the passage?A) Some widely accepted beliefs can be deceiving.B) Solid evidence weighs more than pure theories.C) Little children can be as clever as trained TT practitioners.D) The principle of TT is too profound to understand.Questions 31 to 35 are based on the following passage:What might driving on an automated highway be like? The answer depends on what kind of system is ultimately adopted. Two distinct types are on the drawing board. The first is a special —purpose lane system, in which certain lanes are reserved for automated vehicles. The second is a mixed traffic system: fully automated vehicles would share the road with partially automated or manually driven cars. A special-purpose land system would require more extensive physical modifications to existing highways, but it promises the greatest gains in freeway(高速公路)capacity.Under either scheme, the driver would specify the desired destination, furnishing this information to a computer in the car at the beginning of the trip or perhaps just before reaching the automated highway. If a mixed traffic system was in place, automated driving could begin whenever the driver was on suitably equipped roads. If special-purpose lanes were available, the car could enter them and join existing traffic in two different ways. One method would use a special onramp (入口引道). As the driver approached the point of entry for the highway, devices installed on the roadside would electronically check the vehicle to determine its destinationand to ascertain that it had the proper automation equipment in good working order. Assuming it passed such tests, the driver would then be guided through a gate and toward an automated lane. In this case, the transition from manual to automated control would take place on the entrance ramp. An alternative technique could employ conventional lanes, which would be shared by automated and regular vehicles. The driver would steer onto the highway and move in normal fashion to a “transition” lane. The vehicle would then shift under computer control onto a lane reserved for automated traffic. (The limitation of these lanes to automated traffic would, presumably, be well respected, because all trespassers(非法进入者)could be swiftly identified by authorities.)Either approach to joining, a lane of automated traffic would harmonize the movement of newly entering vehicles with those already traveling. Automatic control here should allow for smooth merging, without the usual uncertainties and potential for accidents. and once a vehicle had settled into automated travel, the drive would be free to release the wheel, open the morning paper or just relax.21. We learn from the first paragraph that two systems of automated highways __________.A) are being plannedB) are being modifiedC) are now in wide useD) are under construction22. A special-purpose lane system is probably advantageous in that ________________.A) it would require only minor changes to existing highwaysB) it would achieve the greatest highway traffic efficiencyC) it has a lane for both automated and partially automated vehiclesD) it offers more lanes for automated vehicles23. Which of the following is true about driving on an automated highway?A) Vehicles traveling on it are assigned different lanes according to their destinations.B) A car can join existing traffic any time in a mixed lane system.C) The driver should inform his car computer of his destination before driving onto it.D) The driver should share the automated lane with those of regular vehicles.24. We know form the passage that a car can enter aspecial-purpose lane __________.A) by smoothly merging with cars on the conventional laneB) by way of a ramp with electronic control devicesC) through a specially guarded gateD) after all trespassers are identified and removed25. When driving in an automated lane, the driver ___________.A) should harmonize with newly entering carsB) doesn’t have to rely on his computer systemC) should watch out for potential accidentsD) doesn’t have to hold not to the steering wheelQuestions 26 to 30 are based on the following passage:Taking charge of yourself involves putting to rest some very prevalent myths. At the top of the list is the notion that intelligence is measured by your ability to solve complex problems; to read, write and compute at certain levels, and to resolve abstract equations quickly. This vision of intelligence asserts formal education and bookish excellence as the true measures of self-fulfillment. It encourages a kind of intellectual prejudice that has brought with it some discouraging results. We have come to believe that someone who has more educational merit badges, who is very good at some formof school discipline is “intelligent.” Yet mental hospitals are filled with patients who have all of the properly lettered certificates. A truer indicator of intelligence is an effective, happy life lived each day and each present moment of every day. If you are happy, if you live each moment for everything it’s worth, then you are an intelligent person. Problem solving is a useful help to your happiness, but if you know that given your inability to resolve a particular concern you can still choose happiness for yourself, or at a minimum refuse to choose unhappiness, then you are intelligent. You are intelligent because you have the ultimate weapon against the big N. B. D —Nervous Break Down.“Intelligent” people do not have N. B. D.’s because they are in charge of themselves. They know how to choose happiness over depression, because they know how to deal with the problems of their lives. You can begin to think of yourself as truly intelligent on the basis of how you choose to feel in the face of trying circumstances. The life struggles are pretty much the same for each of us. Everyone who is involved with other human beings in any social context has similar difficulties. Disagreements, conflicts and compromises are a part of what it means to be human. Similarly, money, growing old, sickness,deaths, natural disasters and accidents are all events which present problems to virtually all human beings. But some people are able to make it, to avoid immobilizing depression and unhappiness despite such occurrences, while others collapse or have an N. B. D. Those who recognize problems as a human condition and don’t measure happiness by an absence of problems are the most intelligent kind of humans we know; also, the most rare.26. According to the author, the conventional notion of intelligence measured in terms of one’s ability to read, write and compute _____________.A) is a widely held but wrong conceptB) will help eliminate intellectual prejudiceC) is the root of all mental distressD) will contribute to one’s self-fulfillment27. It is implied in the passage that holding a university degree _____________.A) may result in one’s inability to solve complex real-life problemsB) does not indicate one’s ability to write properly worded documentsC) may make one mentally sick and physically weakD) does not mean that one is highly intelligent28. The author thinks that an intelligent person knows _____________.A) how to put up with some very prevalent mythsB) how to find the best way to achieve success in lifeC) how to avoid depression and make his life worthwhileD) how to persuade others to compromise29. In the last paragraph, the author tells us that _____________.A) difficulties are but part of everyone’s lifeB) depression and unhappiness are unavoidable in lifeC) everybody should learn to avoid trying circumstancesD) good feelings can contribute to eventual academic excellence30. According to the passage, what kind of people are rare?A) Those who don’t emphasize bookish excellence in their pursuit of happiness.B) Those who are aware of difficulties in life but know how to avoid unhappiness.C) Those who measure happiness by an absence of problems but seldom suffer form N. B. D.’s.D) Those who are able to secure happiness though having tostruggle against trying circumstances.11. A 12. C 13. D 14. B 15. A 16. D 17. B 18. B 19. C 20. C 21. D 22. D 23. B 24. A 25. B 26. D 27. A 28. D 29. B 30. C。
ansys常见警告和错误

ansys常见警告和错误ansys警告和错误2010-05-03 21:471、The value of UY at node 1195 is 449810067.It is greater than the current limit of 1000000.This generally indicates rigid body motion as a result of an unconstrained model. Verify that your model si properly constrained.错误的可能:1).出现了刚体位移,要增加约束2).求解之前先merge或者压缩一下节点3).有没有接触,如果接触定义不当,也会出现这样类似的情况4)材料属性设置不对会出现这种情况,例如密度设置的太离谱;我自己遇到这种情况的解决方案一般是检查没有耦合的结点;我遇到过这种情况最后发现是密度设置离谱了;2、Large negative pivot value...May be because of a bad temperature-dependent material property used in the model.出现这个错误很可能的原因是约束不够!请仔细检查模型!还没碰到过这个问题3、开始求解后出现以下提示,Solid model data is contaminated后来终于找到原因了有限元网格里包含一些未被划分网格的线,一般来说出现在面于面之间有重合的线,导致虽然面被划分了网格,却包含未被划分网格的线。
解决办法,把模型存为.cdb格式(去掉几何信息),然后再读取,就可以求解了命令:cdwrite,db,模型名,cdb听起来不错,不过也没遇到过,一般在划分后用一下NUMMRG 命令,合并元素,以避免这种情况出现4、*** WARNING ***There are 79 small equation solver pivot terms.几个可能:1) 约束不够,但警告有79 个方程出现小主元,这一条可能性较小,但也不妨检查一下。
聚类分析(clusteranalysis)

聚类分析(cluster analysis)medical aircraftClustering analysis refers to the grouping of physical or abstract objects into a class consisting of similar objects. It is an important human behavior. The goal of cluster analysis is to classify data on a similar basis. Clustering comes from many fields, including mathematics, computer science, statistics, biology and economics. In different applications, many clustering techniques have been developed. These techniques are used to describe data, measure the similarity between different data sources, and classify data sources into different clusters.CatalogconceptMainly used in businessOn BiologyGeographicallyIn the insurance businessOn Internet applicationsIn E-commerceMain stepsCluster analysis algorithm conceptMainly used in businessOn BiologyGeographicallyIn the insurance businessOn Internet applicationsIn E-commerceMain stepsClustering analysis algorithmExpand the concept of editing this paragraphThe difference between clustering and classification is that the classes required by clustering are unknown. Clustering is a process of classifying data into different classes or clusters, so objects in the same cluster have great similarity, while objects between different clusters have great dissimilarity. From a statistical point of view, clustering analysis is a way to simplify data through data modeling. Traditional statistical clustering analysis methods include system clustering method, decomposition method, adding method, dynamic clustering method, ordered sample clustering,overlapping clustering and fuzzy clustering, etc.. Cluster analysis tools, such as k- mean and k- center point, have been added to many famous statistical analysis packages, such as SPSS, SAS and so on. From the point of view of machine learning, clusters are equivalent to hidden patterns. Clustering is an unsupervised learning process for searching clusters. Unlike classification, unsupervised learning does not rely on predefined classes or class labeled training instances. Automatic marking is required by clustering learning algorithms, while instances of classification learning or data objects have class tags. Clustering is observational learning, not sample learning. From the point of view of practical application, clustering analysis is one of the main tasks of data mining. Moreover, clustering can be used as an independent tool to obtain the distribution of data, to observe the characteristics of each cluster of data, and to concentrate on the analysis of specific cluster sets. Clustering analysis can also be used as a preprocessing step for other algorithms (such as classification and qualitative inductive algorithms).Edit the main application of this paragraphCommerciallyCluster analysis is used to identify different customer groups and to characterize different customer groups through the purchase model. Cluster analysis is an effective tool for market segmentation. It can also be used to study consumer behavior, to find new potential markets, to select experimental markets, and to be used as a preprocessing of multivariate analysis.On BiologyCluster analysis is used to classify plants and plants and classify genes so as to get an understanding of the inherent structure of the populationGeographicallyClustering can help the similarity of the databases that are observed in the earthIn the insurance businessCluster analysis uses a high average consumption to identify groups of car insurance holders, and identifies a city's property groups based on type of residence, value, locationOn Internet applicationsCluster analysis is used to categorize documents online to fix informationIn E-commerceA clustering analysis is a very important aspect in the construction of Web Data Mining in electronic commerce, through clustering with similar browsing behavior of customers, and analyze the common characteristics of customers, help the users of e-commerce can better understand their customers, provide more suitable services to customers.Edit the main steps of this paragraph1. data preprocessing,2. defines a distance function for measuring similarity between data points,3. clustering or grouping, and4. evaluating output. Data preprocessing includes the selection of number, types and characteristics of the scale, it relies on the feature selection and feature extraction, feature selection important feature, feature extraction feature transformation input for a new character, they are often used to obtain an appropriate feature set to avoid the "cluster dimension disaster" data preprocessing, including outlier removal data, outlier is not dependent on the general data or model data, so the outlier clustering results often leads to a deviation, so in order to get the correct clustering, we must eliminate them. Now that is similar to the definition of a class based, so different data in the same measure of similarity feature space for clustering step is very important, because the diversity of types and characteristics of the scale, the distance measure must be cautious, it often depends on the application, for example,Usually by definition in the feature space distance metric to evaluate the differences of the different objects, many distance are applied in different fields, a simple distance measure, Euclidean distance, are often used to reflect the differences between different data, some of the similarity measure, such as PMC and SMC, to the concept of is used to characterize different data similarity in image clustering, sub image error correction can be used to measure the similarity of two patterns. The data objects are divided into differentclasses is a very important step, data based on different methods are divided into different classes, classification method and hierarchical method are two main methods of clustering analysis, classification methods start from the initial partition and optimization of a clustering criterion. Crisp Clustering, each data it belonged to a separate class; Fuzzy Clustering, each data it could be in any one class, Crisp Clustering and Fuzzy Clusterin are the two main technical classification method, classification method of clustering is divided to produce a series of nested a standard based on the similarity measure, it can or a class separability for merging and splitting is similar between the other clustering methods include density based clustering model, clustering based on Grid Based clustering. To evaluate the quality of clustering results is another important stage, clustering is a management program, there is no objective criteria to evaluate the clustering results, it is a kind of effective evaluation, the index of general geometric properties, including internal separation between class and class coupling, the quality is generally to evaluate the clustering results, effective index in the determination of the number of the class is often played an important role, the best value of effective index is expected to get from the real number, a common class number is decided to select the optimum values for a particular class of effective index, is the the validity of the standard index the real number of this index can, many existing standards for separate data set can be obtained very good results, but for the complex number According to a collection, it usually does not work, for example, for overlapping classes of collections.Edit this section clustering analysis algorithmClustering analysis is an active research field in data mining, and many clustering algorithms are proposed. Traditional clustering algorithms can be divided into five categories: partitioning method, hierarchical method, density based method, grid based method and model-based method. The 1 division method (PAM:PArtitioning method) first create the K partition, K is the number of partition to create; and then use a circular positioning technology through the object from a division to another division to help improve the quality of classification. Including the classification of typical: K-means, k-medoids, CLARA (Clustering LARge Application), CLARANS (Clustering Large Application based upon RANdomized Search). FCM 2 level (hierarchical method) method to create a hierarchical decomposition of the given data set. The method can be divided into two operations: top-down (decomposition) and bottom-up (merging). In order to make up for the shortcomings of decomposition and merging, hierarchical merging is often combined with other clustering methods, such as cyclic localization. This includes the typical methods of BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) method, it firstly set the tree structure to divide the object; then use other methods to optimize the clustering. CURE (Clustering, Using, REprisentatives) method, which uses fixed numbers to represent objects to represent the corresponding clustering, and then shrinks the clusters according to the specified amount (to the clustering center). ROCK method, it uses the connection between clusters to cluster and merge. CHEMALOEN method, it constructs dynamic model in hierarchical clustering. 3 density based method, according to the density to complete the object clustering. It grows continuouslyaccording to the density around the object (such as DBSCAN). The typical density based methods include: DBSCAN(Densit-based Spatial Clustering of Application with Noise): the algorithm by growing enough high density region to clustering; clustering can find arbitrary shape from spatial databases with noise in. This method defines a cluster as a set of point sets of density connectivity. OPTICS (Ordering, Points, To, Identify, the, Clustering, Structure): it does not explicitly generate a cluster, but calculates an enhanced clustering order for automatic interactive clustering analysis.. 4 grid based approach,Firstly, the object space is divided into finite elements to form a grid structure, and then the mesh structure is used to complete the clustering. STING (STatistical, INformation, Grid) is a grid based clustering method that uses the statistical information stored in the grid cell. CLIQUE (Clustering, In, QUEst) and Wave-Cluster are a combination of grid based and density based methods. 5, a model-based approach, which assumes the model of each cluster, and finds data appropriate for the corresponding model. Typical model-based methods include: statistical methods, COBWEB: is a commonly used and simple incremental concept clustering method. Its input object is represented by a symbolic quantity (property - value) pair. A hierarchical cluster is created in the form of a classification tree. CLASSIT is another version of COBWEB. It can incrementally attribute continuous attributes. For each node of each property holds the corresponding continuous normal distribution (mean and variance); and the use of an improved classification ability description method is not like COBWEB (value) and the calculation of discrete attributes but theintegral of the continuous attributes. However, CLASSIT methods also have problems similar to those of COBWEB. Therefore, they are not suitable for clustering large databases. Traditional clustering algorithms have successfully solved the clustering problem of low dimensional data. However, due to the complexity of data in practical applications, the existing algorithms often fail when dealing with many problems, especially for high-dimensional data and large data. Because traditional clustering methods cluster in high-dimensional data sets, there are two main problems. The high dimension data set the existence of a large number of irrelevant attributes makes the possibility of the existence of clusters in all the dimensions of almost zero; to sparse data distribution data of low dimensional space in high dimensional space, which is almost the same distance between the data is a common phenomenon, but the traditional clustering method is based on the distance from the cluster, so high dimensional space based on the distance not to build clusters. High dimensional clustering analysis has become an important research direction of cluster analysis. At the same time, clustering of high-dimensional data is also the difficulty of clustering. With the development of technology makes the data collection becomes more and more easily, cause the database to larger scale and more complex, such as trade transaction data, various types of Web documents, gene expression data, their dimensions (attributes) usually can reach hundreds of thousands or even higher dimensional. However, due to the "dimension effect", many clustering methods that perform well in low dimensional data space can not obtain good clustering results in high-dimensional space. Clustering analysis of high-dimensional data is a very active field in clustering analysis, and it is also a challenging task. Atpresent, cluster analysis of high-dimensional data is widely used in market analysis, information security, finance, entertainment, anti-terrorism and so on.。
研究NLP100篇必读的论文---已整理可直接下载

研究NLP100篇必读的论⽂---已整理可直接下载100篇必读的NLP论⽂⾃⼰汇总的论⽂集,已更新链接:提取码:x7tnThis is a list of 100 important natural language processing (NLP) papers that serious students and researchers working in the field should probably know about and read.这是100篇重要的⾃然语⾔处理(NLP)论⽂的列表,认真的学⽣和研究⼈员在这个领域应该知道和阅读。
This list is compiled by .本榜单由编制。
I welcome any feedback on this list. 我欢迎对这个列表的任何反馈。
This list is originally based on the answers for a Quora question I posted years ago: .这个列表最初是基于我多年前在Quora上发布的⼀个问题的答案:[所有NLP学⽣都应该阅读的最重要的研究论⽂是什么?]( -are-the-most-important-research-paper -which-all-NLP-students-should- definitread)。
I thank all the people who contributed to the original post. 我感谢所有为原创⽂章做出贡献的⼈。
This list is far from complete or objective, and is evolving, as important papers are being published year after year.由于重要的论⽂年复⼀年地发表,这份清单还远远不够完整和客观,⽽且还在不断发展。
CATIA_V5-曲面修补教程R21
新建的Geometrical Set的名称
该选项只对自相交有效
曲面片检查工具Face Checker(2/2)
决定检查对象是曲面(Surface,默认)还是 表面(Face,选中),若为表面,则自动从 曲面内抽取有问题的表面,将其隔离、修复。
曲面连接检查(Surface Connection Checker) (3/3)
7、Transfer︰隔离 Number of anomalies︰错误的数目 Name︰错误的名称,Site指将两个存在缺陷的表面分 成一组 Value︰检测到的数值 Domain︰几个存在缺陷的表面组成的一个域 新建Geometrical Set的默认命名︰ Duplicate faces Duplicate Embedded cases Embedded Multiple connection cases Multiple connection Overlap cases Overlap Boundaries Boundary G0 gaps Distance G1 gaps Tangency
目录
1
1.1 1.2 1.3
修复助手导言 曲面修复的应用 拼合操作的要点 怎样选择拼合距离 工作平台介绍 进入工作平台 用户界面 关于缝合修复的方法 模型分析 曲面片检查器 曲面连接检查器 创建拓扑结构 补救残缺曲面 曲面片光顺 修复“坏”的拓扑结构 校验自由边 完整化拓扑结构 修整自由边 局部连接
merging dist. = 0.001mm merging dist. = 0.01mm merging dist. = 0.1mm
还有,有时候选择精确的公差,连接操作会不成功 (bad topology) 另一方面,如果释放公差太大,某些间隙被隐藏但几何上还是有间隙,这样在以后的处 理中会出麻烦。
木材表面缺陷图像识别的算法研究
木材表面缺陷图像识别的算法研究摘要随着木材加工业的集约化发展,木材产品的生产量持续大幅度增长。
在生产中,对木材表面加工质量高水平的苛求,尤其是一致性的要求,使得传统的人工检测方式已经难以胜任。
为此,本论文基于机器视觉理论对木材表面缺陷识别进行了深入研究。
结合数字图像处理技术和支持向量机模式识别技术,本论文研究了木材表面缺陷图像预处理、特征提取、模式识别问题,研究并改进了用于检测木材表面缺陷的定位和识别等图像处理算法。
图像的预处理是检测的第一步,它对图像缺陷特征的正确提取是非常关键的。
本文针对传统滤波算法在抑制噪声的同时,也会对图像的边缘及细节有比较大的损害,使图像的边沿及细节变模糊的问题,提出了加权有向平滑滤波算法。
并在图像分割上融合了几种分割方法,提出一种改进的基于双正交小波变换的多分辨率图像融合方法和基于融合技术的小波变换和形态学边缘检测算法,优化了分割效果,为后续特征提取打下了很好的基础。
对于木材缺陷的识别,本文从纹理特征(5个灰度共生矩阵参数)和颜色特征(4个颜色矩参数)两个角度来描述缺陷。
根据各参数分布情况,选择标准差较小的参数作为分类器输入特征向量;以及采用主分量分析法进行特征提取,降低纹理特征维数,消除模式特征之间的相关性,突出其差异性,满足识别层的输入要求。
并采用支持向量机分类器进行缺陷的模式识别,达到较高的识别率。
实验结果证明:根据木材表面缺陷图像的纹理特征和颜色特征,运用数字图像处理技术,来解决木材表面缺陷的分割和识别等问题,是行之有效的途径。
关键词:数字图像处理技术;图像分割;特征提取;支持向量机AbstractWith the development of wood industry, the manufacture of wood products is increasing significantly. The demand of a consistent high-quality surface wood product introduces automatic inspection that cannot be easily satisfied by traditional manual inspection. Based on the theory of computer vision, a research on defect distinguish of the wood surface is made in the paper.Image preprocess, feature extraction and pattern recognition of wood surface defect images are also studied by means of digital image processing technique and pattern recognition technology based on SVM(Support Vector Machines). Image processing algorithms are studied and improved to orientate and recognize wood surface defect.Image preprocess is the first step for detection, which is vital to the correct extraction of the defection feature. In the fact of a traditional filtering algorithm can substantially damage the edges and details of the image and blur the image’s edges and details, a weighted and directional smoothing algorithm is proposed in this paper. Merging several image segmentation method , a improved method of image fusion of multi-resolution analysis based on biorthogonal wavelet transform and a edge detection algorithm based on the fusion technology of wavelet transform and morphological edge detection are proposed in the paper. Thus segmentation result is optimized and laying the root for feature extraction of follow up.The defects are described from two aspects based on image characteristic, the texture features(five gray level co-occurrence matrix parameters) and color features (four color moment parameters)to identify the wood defects. According to the distribution of these parameters, the parameters which have small standard deviation are selected as the input eigenvector of the classifiers. And the features are extracted by the principal components analysis which can reduce the texture dimensions and eliminate the relevance between feature modes and highlight their difference to satisfy the input request of the recognition level. Using Support Vector Machines classifier to identify the defects, the correct rates of pattern recognition achieve better level.The experiment results show it is an effective way to solve the segmentation and identification of wood surface defects by texture features and color features of wood surface defect images according to the digital image processing technology,.Keyword:digital image processing technique;image segmentation;feature extraction;SVM (Support Vector Machines)目录第一章绪论 ................................................................................................................... - 1 -1.1 课题的研究背景和意义 ..................................................................................... - 1 -1.1.1 课题的研究背景...................................................................................... - 1 -1.1.2 课题的研究意义...................................................................................... - 1 -1.2 木材表面缺陷检测的研究现状及发展趋势........................................................ - 2 -1.2.1 木材缺陷的常用检测方法 ....................................................................... - 2 -1.2.2 国内外研究现状...................................................................................... - 3 -1.2.3 木材检测技术的发展与展望.................................................................... - 4 -1.3 木材表面缺陷特征及存在形式 .......................................................................... - 5 -1.3.1 木材缺陷种类.......................................................................................... - 5 -1.3.2 木材缺陷对木材质量的影响.................................................................... - 8 -1.4 课题的主要研究内容和创新.............................................................................. - 8 -第二章木材表面缺陷图像的增强预处理...................................................................... - 11 -2.1 图像增强概述.................................................................................................. - 11 -2.2 木材缺陷图像灰度变换 ................................................................................... - 12 -2.2.1 木材缺陷图像灰度化处理 ..................................................................... - 12 -2.2.2 木材缺陷图像灰度变换 ......................................................................... - 13 -2.3 木材缺陷图像平滑 .......................................................................................... - 16 -2.3.1 邻域平滑............................................................................................... - 16 -2.3.2 中值滤波............................................................................................... - 16 -2.3.3 加权有向平滑滤波 ................................................................................ - 17 -2.4 图像锐化 ......................................................................................................... - 21 -2.4.1微分算子................................................................................................ - 22 -2.4.2 Sobel算子.............................................................................................. - 23 -2.4.3拉普拉斯算子 ........................................................................................ - 24 -2.5 本章小结 ......................................................................................................... - 25 -第三章图像分割 .......................................................................................................... - 27 -3.1 基于区域的图像分割....................................................................................... - 27 -3.1.1 并行区域分割技术 ................................................................................ - 27 -3.1.2 串行区域分割技术 ................................................................................ - 29 -3.2基于边缘的图像分割........................................................................................ - 30 -3.2.1 梯度算子............................................................................................... - 31 -3.2.2 Canny边缘检测算子 .............................................................................. - 32 -3.2.3 几种边缘检测算子的比较 ..................................................................... - 33 -3.3 结合特定理论工具的分割技术 ........................................................................ - 33 -3.3.1 基于人工神经网络的分割技术 .............................................................. - 34 -3.3.2 基于小波分析和变换的分割技术 .......................................................... - 34 -3.3.3 基于数学形态学的分割技术.................................................................. - 37 -3.4 本章小结 ......................................................................................................... - 40 -第四章特征提取 .......................................................................................................... - 41 -4.1 纹理特征提取.................................................................................................. - 41 -4.1.1灰度共生矩阵 ........................................................................................ - 41 -4.1.2 Haralick特征 .......................................................................................... - 43 -4.2 色彩特征提取.................................................................................................. - 45 -4.2.1颜色直方图 ............................................................................................ - 46 -4.2.2 颜色矩 .................................................................................................. - 47 -4.3 主成分分析 ..................................................................................................... - 47 -4.3.1主成分分析的原理 ................................................................................. - 48 -4.3.2 主成分分析的基本步骤 ......................................................................... - 49 -4.4 基于主成分分析的算法实现 ........................................................................... - 50 -4.4.1 基于主成分分析的降维算法.................................................................. - 50 -4.4.2 基于主成分分析的降维结果.................................................................. - 51 -4.5 本章小结 ......................................................................................................... - 52 -第五章支持向量机的分类器设计 ................................................................................. - 54 -5.1分类器简介...................................................................................................... - 54 -5.2 SVM算法原理 .................................................................................................. - 54 -5.3 核函数的选择 ................................................................................................. - 57 -5.4 基于SVM的识别结果 ...................................................................................... - 57 -5.4.1 基于纹理特征的木材缺陷图像识别 ..................................................... - 58 -5.4.2 基于主成分分析法的综合纹理特征和颜色特征的木材缺陷图像识别 .. - 59 -5.4.3 三类木材缺陷识别结果 ....................................................................... - 60 -5.5 本章小结 ........................................................................................................ - 61 -第六章总结与展望 ...................................................................................................... - 63 -6.1 总结 ................................................................................................................ - 63 -6.2 展望 ................................................................................................................ - 63 -参考文献 ....................................................................................................................... - 65 -第一章绪论1.1 课题的研究背景和意义1.1.1 课题的研究背景我国是一个木材资源非常匮乏的国家,我国现有森林面积 1.33亿hm2,森林蓄积101.3m3,仅次于俄罗斯、巴西、加拿大、美国,居世界第五位。
a package for automatic evaluation of summaries
a package for automatic evaluation of summaries
随着自然语言处理技术的发展,自动摘要技术越来越成熟。
而对于自动摘要技术的评估,也逐渐引起了研究人员的关注。
近日,一种名为“a package for automatic evaluation of summaries”的自动摘要评估工具包应运而生。
这个工具包的主要目的是为了检查自动摘要系统生成的摘要与原始文本的相似度。
简单来说,就是通过一些定量的指标,来评估自动摘要系统的性能。
这个工具包采用了ROUGE(Recall-Oriented Understudy for Gisting Evaluation)指标,这是目前评估自动摘要系统的最常用指标之一。
ROUGE将生成的摘要与给定的参考摘要进行比较,从而评估出系统的性能水平。
具体来说,ROUGE指标包括ROUGE-N、ROUGE-L和ROUGE-W等几个方面。
其中,ROUGE-N是指在N个连续词语的情况下,生成的摘要与参考摘要的重叠度;ROUGE-L是指生成的摘要与参考摘要的最长公共子序列;ROUGE-W是指在考虑单词位置的情况下,生成的摘要与参考摘要的相似度。
通过ROUGE指标,我们可以更准确地评估自动摘要系统的性能,并为其优化提供参考。
同时,这个工具包也提供了多种语言的支持,能够满足不同语种的需求。
总的来说,“a package for automatic evaluation of summaries”工具包的出现,为自动摘要技术的评估提供了一种便捷、准确的方法。
相信在未来的研究中,这个工具包将会得到更广泛的应用。
- 1 -。
(ARD自动相关确定)automatic relevance determination
AB
9 / 19
Second Level of Interference
In the second level we examine p(ξ, γ|D, H). We write p(ξ, γ|D, H) p(D|w , b, H)p(w , b|ξ, γ, H)p(ξ, γ|H)dwdb
We assume a non-informative prior for the hyperparameters. This can be solved in closed form. Thus no approximation is needed on the second level.
AB
2 / 19
Outline
1 Least Squares Support Vector Machines
2 Bayesian Interference for Model Parameter Selection
3 Experiment
4 Conclusion
AB
3 / 19
Least Squares Support Vector Machines
AB
10 / 19
The Cost Function on the Second Level (1)
Using the previously derived formula, we get p(ξ, γ|D, H) γ nf /2 ξ N/2 exp(I(ωMAP , bMAP )). |H|1/2 (5)
October 24, 2006
AB
Introduction
Automatic Relevance Determination is a classical method based on Bayesian interference. In this presentation we show how it can be applied to Least Squares Support Vector Machines. As a result we get a method for estimating hyperparameters and choosing inputs.
CATIA_破面特征丢失修补教程
1
2 如果选择的错误的方向,稍候就可能出现矛盾。
这种状况发生在减小Merging distance 的时候。
d?
例如,当加进第三个曲面做拼合操作
时,矛盾可能就出现了.
1?
2
? 其他情况: 分不清楚内外侧 ( 著名的莫比乌斯 Moebius type )
3
?
这种状况不可能定义出一致的方向。
怎样选择 Merging Distance (1/2)
4: 丢失元素(Missing element)
3: 病态元素(Invalid element)
完善拓扑(Closing a Topology)
修正拓扑曲面的多余自由边; 在拓扑级,修正间隙; 在拓扑级和几何级两个层面,修正间隙。
修正自由边(Free Sides) (1/3)
一旦创建了拓扑,必须使得它闭合(滴水不漏,保证无缝); 我们说一个曲面是闭合的,是指它能够用来创建成一个实体(几何体); 为此,必须分析和抑制所有的自由边。
将Tangency错误中的Site.33隔离(Transfer) 到“G1 gaps”
曲面连接检查(Surface Connection Checker) (2/3)
1、Search distance︰边界间相邻两点的距离小于给定值时视为一条边界, 即这些边界被合併,值越大需要合併的边越多。
2、Internal deges︰用法同于Face Checker
目录
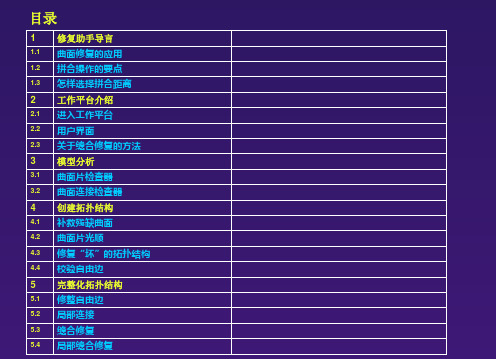
1 修复助手导言 1.1 曲面修复的应用 1.2 拼合操作的要点 1.3 怎样选择拼合距离 2 工作平台介绍 2.1 进入工作平台 2.2 用户界面 2.3 关于缝合修复的方法 3 模型分析 3.1 曲面片检查器 3.2 曲面连接检查器 4 创建拓扑结构 4.1 补救残缺曲面 4.2 曲面片光顺 4.3 修复“坏”的拓扑结构 4.4 校验自由边 5 完整化拓扑结构 5.1 修整自由边 5.2 局部连接 5.3 缝合修复 5.4 局部缝合修复
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Towards Automatic Merging of DomainOntologies: The HCONE-merge approachKonstantinos Kotis, George A. Vouros, Konstantinos StergiouDepartment of Information & Communications Systems Engineering,University of the Aegean,Karlovassi, Samos,83200, GreeceAbstractLatest research efforts on the semi-automatic coordination of ontologies “touch” on the mapping /merging of ontologies using the whole breadth of available knowledge. Addressing this issue, this paper presents the HCONE-merge approach, which is further extended towards automating the merging process. HCONE-merge makes use of the intended informal meaning of concepts by mapping them to WordNet senses using the Latent Semantic Indexing (LSI) method. Based on these mappings and using the reasoning services of Description Logics, HCONE-merge automatically aligns and then merges ontologies. Since the mapping of concepts to their intended meaning is an essential step of the HCONE-merge approach, this paper explores the level of human involvement required for mapping concepts of the source ontologies to their intended meanings. We propose a series of methods for ontology mapping (towards merging) with varying degrees of human involvement and evaluate them experimentally. We conclude that, although an effective fully automated process is not attainable, we can reach a point where ontology merging can be carried out efficiently with minimum human involvement.Keywords: Ontology mapping, Ontology merging, Ontology coordination, Latent Semantic Indexing (LSI), WordNet1. IntroductionOntologies have been realized as the key technology to shaping and exploiting information for the effective management of knowledge and for the evolution of the Semantic Web and its applications. In such a distributed setting, ontologies establish a common vocabulary for community members to interlink, combine, and communicate knowledge shaped through practice and interaction, binding the knowledge processes of creating, importing, capturing, retrieving, and using knowledge. However, it seems that there will always be more than one ontology even for the same domain [22], [23]. In such a setting, where different conceptualizations of the same domain exist, information services must effectively answer queries, bridging the gaps between conceptualisations of the same domain. Towards this target, networks of semantically related information must be created at-request. Therefore, coordination (i.e. mapping, alignment, merging) of ontologies is a major challenge for bridging the gaps between agents (software and human) with different conceptualizations. There are many research works on the mapping and merging of ontologies. These works exploit lexical (or syntactic), structural, semantic (or domain) knowledge and matching heuristics. Recent approaches aim to exploit all these types of knowledge and further capturethe intended meanings of terms by means of heuristic rules (e.g. [5], [7], and [12]). The HCONE-merge approach to ontology merging [8] [9] exploits all the above-mentioned types of knowledge. This approach gives much emphasis on “uncovering” the intended informal meaning of concepts specified in an ontology by mapping them to WordNet senses. WordNet senses realize the informal, human-oriented intended meaning of the corresponding concepts. To compute these mappings, HCONE-merge uses the Latent Semantic Indexing (LSI) method. Exploiting the mappings proposed by LSI, the merging method we introduce translates concept definitions of the source ontologies to a common vocabulary and finally, merges the translated definitions by means of specific merging rules and description logics’ reasoning services.The HCONE-merge approach requires humans to validate the computed intended meaning of every concept in the ontology. Since this process is quite frustrating and error-prone, even for small ontologies, we need to investigate the required human involvement for mapping concepts to their intended meaning efficiently. The ultimate achievement would be to fully automate the mapping of concepts to their intended meaning, and consequently to fully automate merging. Towards this goal, the paper investigates a series of novel techniques and heuristics for ontology mapping and merging, with varying human involvement. The paper concludes that a fully automated ontology merging process is far from realistic, since there must always be a minimum set of human decisions present, something that has been also suggested by other lines of research (e.g. [16] [23]).This paper is structured as follows: Section 2 describes the ontology merging problem. Section 3 provides background information concerning LSI and WordNet and section 4 describes the HCONE-merge approach. Section 5 reports on related work, identifies criteria and compares HCONE-merge with other approaches in terms of the identified criteria. Section 6 describes methods towards automating the process of mapping and merging, and finally, section 7 provides an evaluation of the proposed methods using real-life ontologies and ontologies that have been used by closely related approaches and tools. Section 8 discusses the mapping of domain relations and the influence of these mappings on the computation of concept’s mapping. Section 9 concludes the paper and points out the advantages and disadvantages of the HCONE-merge approach.2. The Ontology Merging Problem (OMP)In order to have a common reference to other approaches, we formulate the ontology merging problem by means of definitions and terms used in [7].An ontology is considered to be a pair O=(S, A), where S is the ontological signature describing the vocabulary (i.e. the terms that lexicalize concepts and relations between concepts) and A is a set of ontological axioms, restricting the intended meaning of the terms included in the signature. In other words, A includes the formal definitions of concepts and relations that are also lexicalized by natural language terms in S. This is a slight variation of the definition given in [7], where S is also equipped with a partial order, based on the inclusion relation between concepts. In our definition, conforming to description logics’ terminological axioms, inclusion relations are ontological axioms included in A. It must be noticed that in this paper we only deal with inclusion and equivalence relations among concepts.Ontology mapping from ontology O1= (S1, A1) to O2= (S2, A2)is considered to be a morphism f:S1 S2of ontological signatures such that A2 f(A1), i.e. all interpretations that satisfy O2’s axioms also satisfy O1’s translated axioms. Consider for instance the ontologiesdepicted in Fig. 1: Given the morphism f such that f(O1-Infrastructure)= O2-Facility and f(O1-Transportation)= O2-Transportation System, it is true that A2 {f(O1-Transportation)f(O1-Infrastructure)}, therefore f is a mapping. Given the morphism f’, such that f’ (O1-Infrastructure) = O2-Transportation System and f’ (O1-Transportation) = O2-Transportation Means, it is not true that A2 {f’ (O1-Transportation) f’(O1-Infrastructure)}, therefore f’ is not a mapping.Fig. 1. Example OntologiesHowever, instead of a function, we may articulate a set of binary relations between the ontological signatures. Such relations can be the inclusion ( ) and the equivalence ( ) relations. For instance, given the ontologies in Fig. 1, we can say that O1-Transportation O2-Transportation System, O1-Installation O2-Facility and O1-Infrastructure O2-Facility. Then we have indicated an alignment of the two ontologies and we can merge them. Based on the alignment, the merged ontology will be ontology O3in Fig. 1. It holds that A3 A2and A3 A1.Looking at Fig. 1 in an other way, we can consider O3to be part of a larger intermediate ontology and define the alignment of ontologies O1 and O2 by means of morphisms f1: S1 S3and f2: S2 S3, i.e. by means of their mapping to the intermediate ontology. Then, the merging of the two ontologies [5] is the minimal union of ontological vocabularies and axioms with respect to the intermediate ontology where ontologies have been mapped. Therefore, the ontologies merging problem (OMP) can be stated as follows: Given two source ontologies O1and O2find an alignment between them by mapping them to an intermediate ontology, and then, get the minimal union of their (translated) vocabularies and axioms with respect to their alignment.3. WordNet and Latent Semantic IndexingBefore proceeding to the description of the HCONE-merge method, let us give a brief overview of WordNet and LSI, which are key-technologies for the realization of the HCONE-merge approach.3.1. WordNetWordNet [13] is a lexicon based on psycho-linguistic theories. It contains information about nouns, verbs, adverbs, and adjectives, organized around the notion of a synset. A synset is a set of words with the same part-of-speech that can be interchanged in a certain context. For example {facility; installation} form a synset because they can be used to refer to the same concept. A synset is often further described by a gloss: e.g. “created to provide a particular service”.Semantic relations among synsets include among others the synonymy, hyper(hyp)onymy, meronymy and antonymy relations. WordNet (version 1.4) contains more than 83.800 words, 63.300 synsets and 87.600 links between concepts.Fig. 2. WordNet information for concept FacilityAs Fig. 2 shows, WordNet provides lexical and semantic information concerning a word. Specifically, concerning the word Facility, Fig. 2 shows the 5 WordNet synsets (senses) ofFacility, and the hyperonyms of the terms that lexicalize each sense. For instance, the first sense of Facility is lexicalized by the synonyms Facility and Installation, and is defined to be something that has been “created to provide a particular service”. Furthermore, the hyperonyms of the terms that lexicalize this sense are: “artifact, artifact”, “object, physical object”, “entity, something”.3.2. LSILatent Semantic Indexing (LSI) [2] is a vector space technique originally proposed for information retrieval and indexing. It assumes that there is an underlying latent semantic space that it estimates by means of statistical techniques using an association matrix (n×m) of term-document data. Latent Semantic Analysis (LSA) computes the arrangement of a k-dimensional semantic space to reflect the major associative patterns in the data. This is done by deriving a set of k uncorrelated indexing factors. These factors may be thought of as artificial concepts whose lexicalization is not important for LSI. Each term and document is represented by its vector of factor values, indicating its strength of association with each of these underlying concepts. In other words, the meaning of each term or document is expressed by k factor values, or equivalently, by the location of a vector in the k-space defined by the factors. Then, a document is the (weighted) sum of its component term vectors. The similarity between two objects (e.g. between two documents) is computed by means of the dot product between the corresponding representation vectors.For the computation of the k factors LSI employs a two-mode factor analysis by decomposing the original association matrix into three other matrices of a very similar form. This is done by a process called “singular value decomposition (SVD)”. This results in a breakdown of the original term-document relationships into linearly independent factors. Some of these factors are not significant and are ignored. The resulting k factors specify the dimensionality of the semantic space.By virtue of dimension reduction from the N terms space to the k factors space, where k<N, terms that did not actually appear in a document may still end up close to the document, if this is consistent with the major patterns of association in the data.When one searches an LSI-indexed database of documents, it provides a query (i.e. a pseudo-document), which is a list of terms. As already pointed, a document is represented by the weighted sum of its component term vectors. The similarity between two documents is computed by means of the dot product between the corresponding representation vectors. Doing so, LSI returns a set of graded documents, according to their similarity to the query. For instance, let us consider a set of 5 documents (described here only by their titles) referring to the baking of bread and pastries.D1:How to Bake Bread Without RecipesD2:The Classic Art of Viennese PastryD3:Numerical Recipes: The Art of Scientific ComputingD4:Breads, Pastries, Pies and Cakes: Quantity Baking RecipesD5:Pastry: A Book of Best French RecipesTo compute the semantic space, the method builds the association matrix that associates terms that occur in documents with the documents themselves. This can be done by considering only the stems of those terms that do not belong in a stop-words list. Doing so, terms such as bake and baking should be considered as the term bake. Given the documents above, this step will produce the following list of terms:T1: bak(e, ing)T2: recipesT3: breadT4: cakeT5: pastr(y, ies)T6: pieHaving obtained the list of terms, the next step involves the construction of the association matrix A1 (Terms×Documents) that contains the frequency of term occurrences within each document. The value of an entry of matrix A1 in Fig.3 specifies the frequency occurrence of a term in a document. In case this value is 0, then the term does not appear in the corresponding document. For instance, the first line of the matrix A1 in Fig. 3 represents the fact that that the term T1 (bak(e, ing)) occurs in documents D1 and D4.Fig. 3. A matrix in LSI method: 2 phases of computationHaving constructed the matrix, one may query using the single keyword “baking”. The query is written in the form of a vector q = (1, 0, 0, 0, 0, 0), where the value 1 in the first position of the vector represents the term baking from the list of the 6 terms identified.LSI, via SVD, computes the decomposition of the association matrix and “identifies” the k significant factors for the representation of terms and documents. Using this vector representation of terms and documents in terms of the k-factors, one can produce the matrix A2shown in Fig. 3that “approximates” A1: A2associates terms with documents semantically. The production of such an approximation is the major strength of LSI, since it is believed that the original term space is unreliable. The approximation expresses what is reliable and important in the underlying use of terms as document referents [2].As it is depicted in Fig. 3, there are no zero values in matrix A2indicating that we can obtain a similarity value for every term in a query. More interesting is the fact that some values are negative, indicating that there is a very large distance between a term and a document. Using matrix A2 to answer the query “baking”, the grades returned are: 0.5181, -0.0332, 0.0233, 0.5064, -0.0069. I.e., both documents D1 and D4 have been rated with a high grade.4. The HCONE-merge method of solving the OMPGiven two source ontologies, the HCONE-merge method finds a semantic morphism between each of these two ontologies and the so-called “hidden intermediate” ontology. As Fig.4 shows, WordNet plays the role of an “intermediate” where concepts of the source ontologies are being mapped through the semantic morphism (s-morphism, symbolized by f s). This morphism is computed by the Latent Semantic Indexing (LSI) method and associates ontology concepts with WordNet senses.Fig. 4. T he HCONE approach towards the OMPIt must be noticed that we do not consider WordNet to include any intermediate ontology, as this would be very restrictive for the specification of the original ontologies (i.e. the method would work only for those ontologies that preserve the inclusion relations among WordNetsenses). Actually, HCONE-merge assumes that the intermediate ontology is “somewhere there” and constructs this ontology while mapping concepts to the WordNet senses.In fact, WordNet can be replaced by any other lexicon, thesaurus or even a collection of documents that describe concepts of the source ontologies. We have used WordNet since it is a well-thought and widely available lexical resource with a large number of entries and semantic relations. We conjecture that any lexical resource that provides concepts’ lexicalisations together with their informal intended meanings can be used as well.The hidden intermediate ontology that it constructed during the mapping includes (a) a vocabulary with the lexicalizations of the specific senses of WordNet synsets corresponding to the ontologies’ concepts, and (b) axioms that are the translated axioms of the source ontologies. As Fig. 4 shows, having found the mappings to the hidden intermediate ontology, and having translated the source ontologies, these have been aligned and are then merged by means of the rename, merge, and classify actions.4.1. Computing the s-morphismAs we have already mentioned, the first step in our approach is the mapping of ontologies O1 and O2to the “hidden intermediate” ontology by means of semantic morphisms (s-morphisms) f1: S1 S3and f2: S2 S3.To compute the s-morphism, HCONE-merge uses the LSI method. In our case, the n×m association matrix comprises the n more frequently occurring terms of the m WordNet senses that the algorithm focuses on (what constitutes the focus of the algorithm is explained in Fig.5).The steps of the algorithm for finding the semantic morphism are shown in Fig. 5:Fig. 5. The algorithm for computing the s-morphismFor example, Fig. 6shows the major steps for the computation of the s-morphism for the concept “Facility” of ontology O2 depicted in Fig. 1. Concept “Facility” is associated with the five WordNet senses whose meanings range from “something created to provide a service” to “a room equipped with washing and toilet facilities” (see Step 1,2,3). These senses constitute the focus of the algorithm for the concept “Facility”. The terms-senses association matrix (according to the Step 4 of the algorithm) for this concept is a 93×5 matrix (93 terms were found after applying filtering techniques to the 5 senses) containing values that correspond to the frequency of the terms’ occurrence is each of the 5 senses within algorithm’s focus. The query string is constructed by the query terms (Step 5 of the algorithm), assigning the value “1” (one) in the corresponding positions of a 93-positions vector that corresponds to the 93 terms of the association matrix. Having all the necessary data, LSI returns (see Step 6) the graded senses in the algorithm’s focus. In this case, as Fig.6 shows, the first sense has the largest grade and is hypothesized to be the one expressing the intended meaning of the concept “Facility” of ontology O2.Fig. 6. A running case for computing the mapping of the concept “Facility”It must be emphasized that although LSI exploits structural information of ontologies and WordNet, it ends up with semantic associations between terms.The algorithm is based on assumptions that influence the mappings produced:Currently, concept names lemmatization and morphological analysis is not sophisticated. The algorithm finds a lexical entry that matches a slight variation of the given concept name. However, in another line of research we produce methods for matching concept names based on a ‘core set’ of characters [24]. It must be noted that for ontologies concerning fine-grained domains, some of the high-technical concepts contained in these ontologies may not have a lexical entry in WordNet. In such a case, as already pointed out, one may use other lexicons, thesauruses, or lexical resources instead of, or in conjunction to WordNet. HCONE-merge is not restricted to the mandatory use of WordNet.Most multi-word terms have no senses in WordNet, thus we can only compute the intended meaning for each component-word of the term. This gives a partial indication of the intended meaning of the whole term. Currently, we assume that a multi-word term lexicalizes a concept that is related to the concepts that correspond to the words comprising it. In general, in case a multi-word term C has no lexical entry in WordNet, then the term C is associated with concepts H n, n=1,2… corresponding to the single words comprising it. Then, C is considered to be mapped to a virtual concept Cw of the hidden intermediate ontology, and each concept H n is considered to be included in the ontological signature of the intermediate ontology. For instance, the concept lexicalized by “Transportation Means” is considered to be related to the concepts lexicalized by “Transportation” and “Means”. Specifically, it is assumed that the concept lexicalised by the right-most word of a multi-word term subsumes the concept lexicalised by the multi-word term [19]. I.e., the concept “Means” subsumes the concept “Transportation Means”. The concepts that are lexicalized by the rest of the words of a multi-word term can be related with this term by any domain relation.For instance, given that “Means”subsumes “TransportationMeans”, and that the domain relation to “Transportation”is “function”, the following axiom holds: TransportationMeans Means function.Transportation.This treatment of multi-word terms is motivated by the need to reduce the problem of mapping these terms to the mapping of single terms. Doing so, we can exploit the translated formal definitions of multi-word terms by means of description logics reasoning services for testing equivalence and subsumption relations between the concepts’ definitions during the mapping and merging of ontologies.In related lines of research, the mapping of multiword terms is addressed mainly by syntactic methods [18] [10]. In [10] for instance, words that lexicalize concepts of the source ontology are matched to words of each term of the target ontology. Every matched pair has a score that represents the ratio of the number of the words matched with regard to the total number of words. Then, for each term, among all its pairs, only the highest graded pair is recorded as matched. Doing so, pairs such as “meeting-place” and “place-of-meeting”, as well as “written-by” and “wrote” can be found.C loser to our work is an additional technique described in [10], described under thetitle “synset matching”. According to this, the meanings of the words found in a multi-word term are represented by means of WordNet synsets. For each word in each term, if this word corresponds to a WordNet entry, then it must belong to one of the corresponding synsets. The two terms which have the largest number of common synsets are recorded as a matched pair. For instance, terms such as “auto-care” and “car-maintenance” can be matched.In contrast to the above-mentioned approaches that involve estimating the similarity among labels using mainly syntactic similarity measures, the treatment ofmulti-word terms in HCONE-merge involves not only syntactic, but also (and mainly) semantic knowledge. Semantic knowledge is captured by means of the s-morphism computed for the component words of a multi-word term, as well as by means of the description logics axioms produced.The performance of the algorithm is related to assumptions concerning the information that has to be used for the computation of (a) the semantic space, and (b) the query terms. This is thoroughly examined in the paragraphs that follow.The implementation of LSI that we are currently using, as pointed out by the developers1, works correctly when the n×m matrix utilized has more than 4 and less than 100 senses (i.e. 4 m 100). In case there are fewer than 4 senses, we extend the semantic space with additional information.The semantic space is constructed by terms in the vicinity of the senses S1, S2,…S m that are in the focus of the algorithm for a concept C. Therefore, we have to decide what constitutes the vicinity of a sense for the calculation of the semantic space. In an analogous way we have to decide what constitutes the vicinity of an ontology concept for the calculation of the query string.Terms that can be included in the semantic space include:Sp1. The term C’ that corresponds to C. C’ is a lexical entry in WordNet that is a linguistic variation of C (as described in Fig. 5).Sp2. Terms that appear in C’ WordNet senses S1, S2,…S m.Sp3. Terms that constitute hyperonyms / hyponyms of each C’ sense.Sp4. Terms that appear in hyper(hyp)onyms of C’ senses.Terms that can be included in the query string include:Q1. The primitive super-concepts of concept C.Q2. Concepts that subsume C and are immediate super-concepts of C.Q3. Concepts that are immediate sub-concepts of C.Q4. Concepts that are related to C via domain specific relations.Q5. The most frequent terms in WordNet senses that have been associated with the concepts directly related to C via inclusion and equivalence relations.The goal is to specify the vicinity of a concept and the vicinity of each sense in a generic and domain-independent way so as to compute valid mappings of concepts to WordNet senses without “distracting” LSI with information that is comprised by terms that are not in the domain of the ontology. Experiments imply that the s-morphism computation algorithm must consider senses and terms that are “close” to the intended meaning of the concepts in the hidden intermediate ontology, otherwise what we may call “semantic noise” can distract computations. Specifically, given terms that are not relevant to the domain of an ontology SVD may compute factors whose meaning do not represent the meaning of terms and documents adequately. However, since SVD computes what is reliable and important in the underlying use of terms as document referents, there must be a large percentage of terms irrelevant to the given ontology. Experiments showed that by reducing the amount of irrelevant information in the semantic space we actually achieved to get more hits. This1 KnownSpace Hydrogen License: This product includes software developed by the Know Space Group for use in the KnownSpace Project ()happens when the semantic space includes Sp4, the query string includes Q5and the WordNet senses that have been associated with the concepts directly related to C do not represent the intended meanings of these concepts. Experiments using various ontologies have shown that we can achieve approximately 70% precision in mapping concepts to WordNet senses, if the vicinity of the senses that are in the focus of the algorithm include information Sp1, Sp2, Sp3, specified above, and the vicinity of the ontology concepts include information Q1, Q2, Q3, and Q4. Q5 can further increase the precision of the method, if the WordNet senses that have been associated with the concepts directly related to C do represent the intended meanings of these concepts.Using the algorithm described in Fig. 5, each ontology concept is associated with a set of graded WordNet senses. The highest graded sense expresses the most possible informal meaning of the corresponding concept. This sense is assumed to express the intended meaning of the concept specification and can be further validated by a human. In case a human indicates a sense to be the most preferable, then this sense is considered to capture the informal intended meaning of the formal ontology concept. Otherwise, the method considers the highest graded sense as the concept’s intended interpretation.4.2. TranslationUsing the intended informal meanings of concepts, the proposed method of mapping/merging ontologies translates the formal definitions of concepts in a common vocabulary and merges the translated definitions using description logics reasoning services.Given all the preferred mappings of concepts to WordNet senses, we have captured the intended meaning of ontology concepts. Using the intended meanings of the formal concepts, we construct an ontology O n=(S n, A n), n=1,2, where, S n includes the lexicalizations of the senses associated to the concepts of the ontology O n=(S n, A n), n=1,2, and A n contains the translated inclusion and equivalence relations between the corresponding concepts. Then, it holds that A n f s(A n) and the ontology O n=(S n, A n) with the corresponding associations from O n to O n, is a model of O n=(S n, A n), n=1,2. These associations define a mapping from O n to O n.4.3. Merging of ontologiesHaving discovered the associations between the ontology concepts and WordNet senses, the algorithm has found a semantic morphism between each of the source ontologies and the hidden intermediate ontology. Moreover, the source ontologies have been aligned. The actual construction of the intermediate ontology with the minimal set of axioms for both source ontologies results in the merging of these ontologies.For instance, as shown in Fig. 5, given the morphisms produced, it holds that:For ontology O1f s(O1-System) = System1,f s(O1-Installation) = Facility1,f s(O1-Infrastructure) = Infrastructure1, andf s(O1-Transportation) = TransportationSystem1For ontology O2f s(O2-Facility) =Facility1,f s(O2-Transportation System) = TransportationSystem1, and。