并行计算课后答案

第三章互连网络
3.1 对于一颗K级二叉树(根为0级,叶为k-1级),共有N=2^k-1个节点,当推广至m-
元树时(即每个非叶节点有m个子节点)时,试写出总节点数N的表达式。
答:
推广至M元树时,k级M元树总结点数N的表达式为:
N=1+m^1+m^2+...+m^(k-1)=(1-m^k)*1/(1-m);
3.2二元胖树如图3.46所示,此时所有非根节点均有2个父节点。如果将图中的每个椭圆均视为单个节点,并且成对节点间的多条边视为一条边,则他实际上就是一个二叉树。试问:如果不管椭圆,只把小方块视为节点,则他从叶到根形成什么样的多级互联网络?
答:8输入的完全混洗三级互联网络。
3.3 四元胖树如图3.47所示,试问:每个内节点有几个子节点和几个父节点?你知道那个机器使用了此种形式的胖树?
答:每个内节点有4个子节点,2个父节点。CM-5使用了此类胖树结构。
3.4 试构造一个N=64的立方环网络,并将其直径和节点度与N=64的超立方比较之,你的结论是什么?
答:A N=64的立方环网络,为4立方环(将4维超立方每个顶点以4面体替代得到),直径d=9,节点度n=4
B N=64的超立方网络,为六维超立方(将一个立方体分为8个小立方,以每个小立方作为简单立方体的节点,互联成6维超立方),直径d=6,节点度n=6
3.5 一个N=2^k个节点的de Bruijin 网络如图3.48。
。。。
试问:该网络的直径和对剖宽度是多少?
答:N=2^k个节点的de Bruijin网络直径d=k 对剖宽带w=2^(k-1)
3.6 一个N=2^n个节点的洗牌交换网络如图3.49所示。试问:此网络节点度==?网络直径==?网络对剖宽度==?
答:N=2^n个节点的洗牌交换网络,网络节点度为=2 ,网络直径=n-1 ,网络对剖宽度=4
3.7 一个N=(k+1)2^k个节点的蝶形网络如图3.50所示。试问:此网络节点度=?网络直径=?网络对剖宽度=?
答:N=(k+1)2^k个节点的蝶形网络,网络节点度=4 ,网络直径=2*k ,网络对剖宽度=2^k
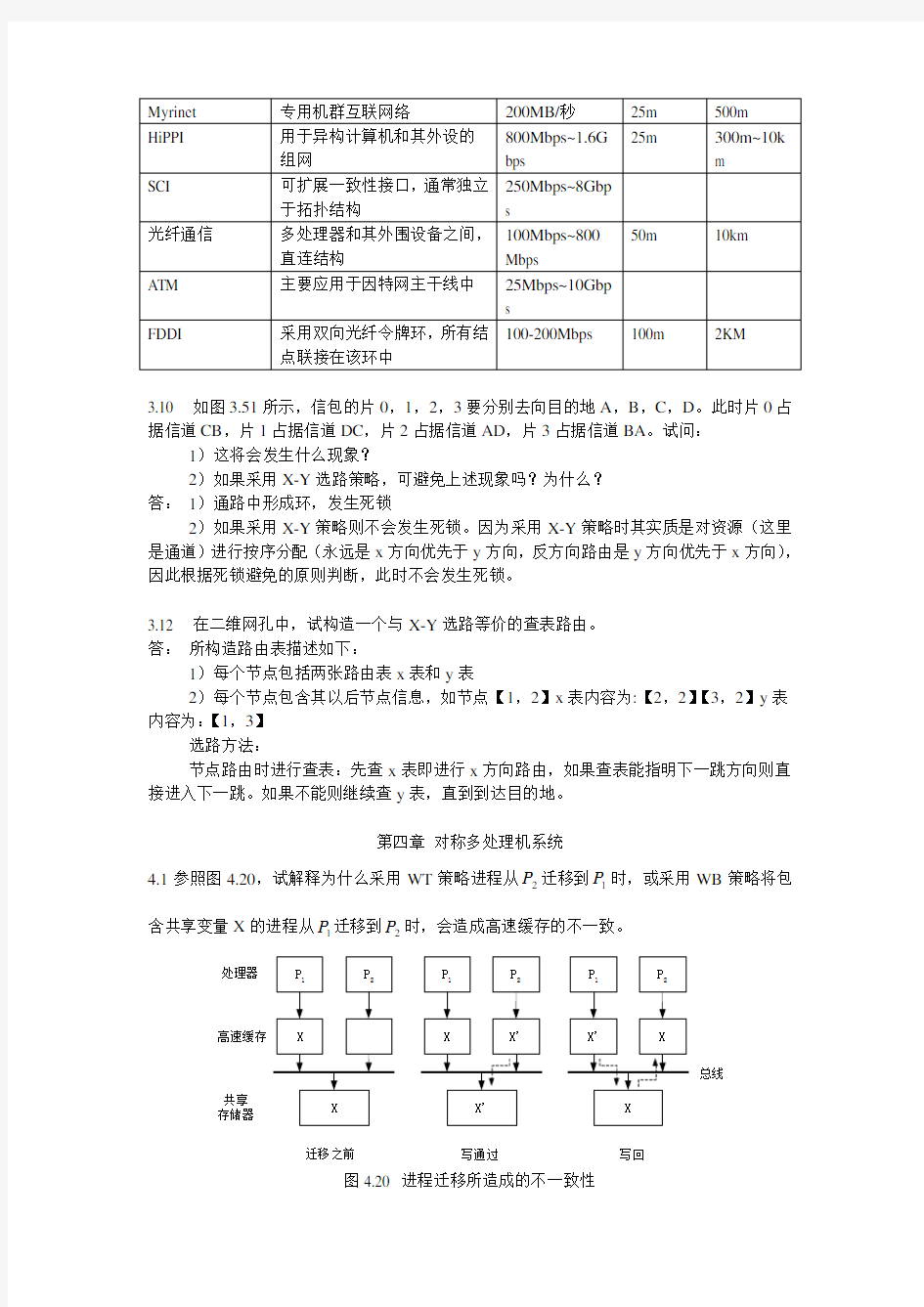
3.9 对于如下列举的网络技术,用体系结构描述,速率范围,电缆长度等填充下表中的各项。(提示:根据讨论的时间年限,每项可能是一个范围)
3.10 如图3.51所示,信包的片0,1,2,3要分别去向目的地A ,B ,C ,D 。此时片0占据信道CB ,片1占据信道DC ,片2占据信道AD ,片3占据信道BA 。试问:
1)这将会发生什么现象?
2)如果采用X-Y 选路策略,可避免上述现象吗?为什么?
答:
1)通路中形成环,发生死锁
2)如果采用X-Y 策略则不会发生死锁。因为采用X-Y 策略时其实质是对资源(这里是通道)进行按序分配(永远是x 方向优先于y 方向,反方向路由是y 方向优先于x 方向),因此根据死锁避免的原则判断,此时不会发生死锁。
3.12 在二维网孔中,试构造一个与X-Y 选路等价的查表路由。
答: 所构造路由表描述如下:
1)每个节点包括两张路由表x 表和y 表
2)每个节点包含其以后节点信息,如节点【1,2
】x 表内容为:【
2,2】【3,2】y 表内容为:【1,3】
选路方法:
节点路由时进行查表:先查x 表即进行x 方向路由,如果查表能指明下一跳方向则直接进入下一跳。如果不能则继续查y 表,直到到达目的地。
第四章 对称多处理机系统
4.1参照图4.20,试解释为什么采用WT 策略进程从2P 迁移到1P 时,或采用WB 策略将包含共享变量X 的进程从1P 迁移到2P 时,会造成高速缓存的不一致。
处理器高速缓存共享
存储器迁移写通写总线
过回之前
图4.20 进程迁移所造成的不一致性
答:采用WT 策略进程从2P 迁移到1P 后,2P 写共享变量X 为X ’,并且更新主存数据为X ’,此时1P 共享变量值仍然为X ,与2P 和主存X ’不一致。采用WB 策略进程从1P 迁移到2P 后,1P 写共享变量X 为X ’,但此时2P 缓存与主存变量值仍然为X ,造车不一致。
4.2参照图4.21所示,试解释为什么:①在采用WT 策略的高速缓存中,当I/O 处理器将一个新的数据'X 写回主存时会造成高速缓存和主存间的不一致;②在采用WB 策略的高速缓存中,当直接从主存输出数据时会造成不一致。
处理器I/O (写直达)总线
存储器存储器存储器输入()
输出()(写回)高速缓存
I/O处理机
图4.21 绕过高速缓存的I/O 操作所造成的不一致性
答:①中I/O 处理器将数据X ’写回主存,因为高速缓存采用WT 策略,此时P1和P2相应的高速缓存值还是X ,所以造成高速缓存与主存不一致。②直接从主存输出数据X ,因为高速缓存采用WB 策略,可能高速缓存中的数据已经被修改过,所以造成不一致。
4.3 试解释采用WB
策略的写更新和写无效协议的一致性维护过程。其中X 为更新前高速
缓存中的拷贝,'
X 为修改后的高速缓存块,I 为无效的高速缓存块。
(b)处理器P 1执行写无效操作后
(c)处理器P 1执行写更新操作后
(a)写操作前答:处理器P1写共享变量X 为X ’,写更新协议如图(c)所示,同时更新其他核中存在高速缓存拷贝的值为X ’;写无效协议如图(b)所示,无效其他核中存在高速缓存拷贝,从而维护了一致性过程。
4.4 两种基于总线的共享内存多处理机分别实现了Illinois MESI 协议和Dragon 协议,对于
下面给定的每个内存存取序列,试比较在这两种多处理机上的执行代价,并就序列及一致性协议的特点来说明为什么有这样的性能差别。序列①r1 w1 r1 w1 r2 w2 r2 w2 r3 w3 r3 w3;序列②r1 r2 r3 w1 w2 w3 r1 r2 r3 w3 w1;序列③r1 r2 r3 r3 w1 w1 w1 w1 w2 w3;所有的存取操作都针对同一个内存位置,r/w 代表读/写,数字代表发出该操作的处理器。假设所有高速缓存在开始时是空的,并且使用下面的性能模型:读/写高速缓存命中,代价1个时钟周期;缺失引起简单的总线事务(如BusUpgr ,BusUpd ),60
个时钟周期;缺失引起整个高速缓存块传输,90时钟周期。假设所有高速缓存是写回式。答:读写命中、总线事务、块传输分别简记为H、B、T。MESI协议:①BTH H H H BTH BH H H BTH BH H H 共5B+12H+3T=582时钟周期②BTH BTH BTH BH BTH BTH BTH BTH H BH BTH 共10B+12H+8T=1330时钟周期③BTH BTH BTH H BH H H H BTH BTH共6B+10H+4T=730时钟周期。Dragon协议:①BTH H H H BTH BTH H BTH BTH BTH H BTH 共7B+12H+7T=882时钟周期②BTH BTH BTH BTH BTH BTH H H H H BTTH BTH 共8B+12H+8T=1212时钟周期③BTH BTH BTH H BTH BTH BTH BTH BTH BTH 共9B+10H+9T=1360时钟周期。由结果得出,①、③序列用MESI 协议时间更少,而②序列用Dragon协议时间更少。综上可知,如果同一块在写操作之后频繁被多个核读操作采用Dragon协议更好一些,因为Dragon协议写操作后会更新其它核副本。如果一个同多次连续对同一块进行写操作MESI协议更有效,因为它不需要更新其它核副本,只需要总线事务无效其它核即可。
4.5考虑以下代码段,说明在顺序一致性模型下,可能的结果是什么?假设在代码开始执行
时,所有变量初始化为0。
a.
P1 P2 P3
A=1 U=A V=B
B=1 W=A
b.
P1 P2 P3 P4
A=1 U=A B=1 W=B
V=B X=A
答:顺序一致性模型性下,保护每个进程都按程序序来发生内存操作,这样会有多种可能结果,这里假设最简单情况,即P1、P2、P3依次进行。则a中U = V = W = 1,b中U=X=W=1,V=0。
4.6参照4.6.1中讨论多级高速缓存包含性的术语,假设L1和L2都是2-路组相联,n2>n1,
b1=b2,且替换策略用FIFO来代替LRU,试问包含性是否还是自然满足?如果替换策略是随机替换呢?
答:如果采用FIFO替换策略包含性自然满足,因为L1和L2都是2路组相联,FIFO保证了L1与L2在发生替换时会换出相同的缓存块,维护了包含性。如果采取随机替换策略,存在L1与L2替换不是相同块的情况,故不满足包含性。
4.7针对以下高速缓存情况,试给出一个使得高速缓存的包含性不满足的内存存取序列?
L1 高速缓存容量32字节,2-路组相联,每个高速缓存块8个字节,使用LRU替换算法;L2 高速缓存容量128字节,4-路组相联,每个高速缓存块8个字节,使用LRU替换算法。
答:假设m1、m2、m3块映射到一级Cache和二级Cache的同一组中,考虑如下内存存取序列R m1,R m2,R m1,R m3,由LRU替换算法知道,当R m3执行后,L1中被替换出的是m2,L2中被替换出的是m1,此时m1块在L1却不在L2中,不满足包含性。
4.8在4.6中关于分事务总线的讨论中,依赖于处理器与高速缓存的接口,下面情况有可能
发生:一个使无效请求紧跟在数据响应之后,使得处理器还没有真正存取这个高速缓存块之前,该高速缓存块就被使无效了。为什么会发生这种情况,如何解决?
答:考虑如下情景:SMP目录一致性协议中,核1读缺失请求数据块A,主存响应请求传送数据块A给核1,同时核2对数据块A进行写操作,到主存中查得核1拥有副本,向核1发使无效请求。如此,一个使无效请求紧跟在数据响应之后。解决方法,可以使每个核真正存取高速缓存块后向主存发回应,然后再允许其它对此块操作的使无效或其它请求。
4.9利用LL-SC操作实现一个Test&Set操作。
答:Test&Set:ll reg1,location /*Load-locked the location to reg1 */
bnz reg1,lock /* if locatin was locked,try again*/
mov reg2,1 /*set reg2 1*/
sc location,reg2 /*store reg2 conditional into location*/
4.10在4.7.4部分描述具有感觉反转的路障算法中,如果将Unlock语句不放在if条件语句
的每个分支中,而是紧接放在计数器增1语句后,会发生什么问题?为什么会发生这个问题?
答:再进入下一个路障时可能会发生计数器重新清0现象,导致无法越过路障。考虑如下情景:第一次进入路障时,最后两个进入路障的进程分别为1、2。假设最后进入路障的进程为2进程,2进程执行共享变量加一操作并解锁。然后2进程执行一条if条件语句,此时由于某种原因换出或睡眠,而此时共享变量的值已经为p。如果1进程此时正执行if条件语句,则清零计数器,设置标志,其它进程越过路障。到目前为止没有出现问题,问题出现在下一次进入路障。进程再一次进入路障,此时会执行共享变量加一操作。如果此时2进程被换入或被唤醒,会重新清零共享变量,使之前到达路障的进程的加一操作无效,导致无法越过路障。
第五章大规模并行处理机系统
5.1简述大规模并行处理机的定义,原理和优点?
答:并行处理机有时也称为阵列处理机,它使用按地址访问的随机存储器,以单指令流多数据流方式工作,主要用于要求大量高速进行向量矩阵运算的应用领域。并行处理机的并行性来源于资源重复,它把大量相同的处理单元(PE)通过互联网络(ICN)连接起来,在统一的控制器(CU)控制下,对各自分配来的数据并行地完成同一条指令所规定的操作。PE是不带指令控制部件的算术逻辑运算单元。并行处理机具有强大的向量运算能力,具有向量化功能的高级语言编译程序有助于提高并行处理机的通用性,减少编译时间。
5.2并行处理机有两种基本结构类型,请问是哪两种?并作简单介绍。
答:采用分布存储器的并行处理结构和采用集中式共享存储器的并行处理结构。分布式存储器的并行处理结构中,每一个处理机都有自己的存储器,只要控制部件将并行处理的程序分配至各处理机,它们便能并行处理,各自从自己的存储器中取得信息。而共享存储多处理机结构中的存储器是集中共享的,由于多个处理机共享,在各处理机访问共享存储器时会发生竞争。因此,需采取措施尽可能避免竞争的发生。
5.3简单说明多计算机系统和多处理机系统的区别。
答:他们虽然都属于多机系统但是他们区别在于:(1)多处理机是多台处理机组成的单机系统,多计算机是多台独立的计算机。(2)多处理机中各处理机逻辑上受同一的OS控制,而多计算机的OS逻辑上独立.(3)多处理机间以单一数据,向量。数组和文件交互作用,多计算机经通道或者通信线路以数据传输的方式进行。(4)多处理机作业,任务,指令,数据各级并行,多计算机多个作业并行。
5.4举例说明MPP的应用领域及其采用的关键技术。
答:全球气候预报,基因工程,飞行动力学,海洋环流,流体动力学,超导建模,量子染色动力学,视觉。采用的关键技术有VLSI,可扩张技术,共享虚拟存储技术。
5.5多处理机的主要特点包括
答:
(1)结构的灵活性。与SIMD计算机相比,多处理机的结构具有较强的通用性,它可以同时对多个数组或多个标量数据进行不同的处理,这要求多处理机能够适应更为多样的算法,具有灵活多变的系统结构。2)程序并行性。并行处理机实现操作一级的并行,其并行性存在于指令内部,主要用来解决数组向量问题;而多处理机的并行性体现在指令外部,即表现在多个任务之间。3)并行任务派生。多处理机是多指令流操作方式,一个程序中就存在多个并发的程序段,需要专门的程序段来表示它们的并发关系以控制它们的并发执行,这称为并行任务派生。
4)进程同步。并行处理机实现操作级的并行,所有处于活动状态的处理单元受一个控制器控制,同时执行共同的指令,工作自然同步;而多处理机实现指令、任务、程序级的并行,在同一时刻,不同的处理机执行着不同的指令,进程之间的数据相关和控制依赖决定了要采取一定的进程同步策略。
5.6在并行多处理机系统中的私有Cache会引起Cache中的内容相互之间以及与共享存储器之间互不相同的问题,即多处理机的Cache一致性问题。请问有哪些原因导致这个问题?答:
1)出现Cache一致性问题的原因主要有三个:共享可写的数据、进程迁移、I/O传输。共享可写数据引起的不一致性。比如P1、P2两台处理机各自的本地高速缓冲存储器C1、C2中都有共享存储器是M中某个数据X的拷贝,当P1把X的值变成X/后,如果P1采用写通过策略,内存中的数据也变为X/,C2中还是X。如果通过写回策略,这是内存中还是X。在这两种情况下都会发生数据不一致性。2)进程迁移引起的数据不一致性。P1中有共享数据X的拷贝,某时刻P1进程把它修改为X/并采用了写回策略,由于某种原因进程从P1迁移到了P2上,它读取数据时得到X,而这个X是“过时”的。3)I/O传输所造成的数据不一致性。假设P1和P2的本地缓存C1、C2中都有某数据X的拷贝,当I/O处理机将一个新的数据X/写入内存时,就导致了内存和Cache之间的数据不一致性。
5.7分别确定在下列两种计算机系统中,计算表达式所需的时间:s=A1*B1+A2*B2+…A4*B4。
a) 有4个处理器的SIMD系统;b) 有4个处理机的MIMD系统。假设访存取指和取数的时间可以忽略不计;加法与乘法分别需要2拍和4拍;在SIMD和MIMD系统中处理器(机)之间每进行一次数据传送的时间为1拍;在SIMD系统中,PE之间采用线性环形互连拓扑,即每个PE与其左右两个相邻的PE直接相连,而在MIMD中每个PE都可以和其它PE有直接的的通路。
答:假设4个PE分别为PE0,PE1,PE2,PE3。利用SIMD计算机计算上述表达式,4个乘法可以同时进行,用时=4个时间单位;然后进行PE0到PE1,PE2到PE3的数据传送,用时=1个时间单位。在PE1和PE3中形成部分和,用时=2个时间单位。接着进行PE1到PE3的部分和传送,用时=1*2=2个时间单位。最后,在PE3中形成最终结果,用时=2个时间单位。因此,利用SIMD计算机计算上述表达式总共用时=4(乘法)+1(传送)+2(加法)+2(传送)+2(加法)=11个时间单位。而利用MIMD计算机计算上述表达式,除了在第二次传送节省1个时间单位以外,其他与SIMD相同。因此用时=4(乘法)+1(传送)+2(加法)+1(传送)+2(加法)=10个时间单位。
5.8假定有一个处理机台数为p 的共享存储器多处理机系统。设m 为典型处理机每条执行执行时间对全局存储器进行访问的平均次数。
设t 为共享存储器的平均存储时间,x 为使用本地存储器的单处理机MIPS 速率,再假定在多处理机上执行n 条指令。
现在假设p=32,m=0.4,t=1μs,要让多处理机的有效性能达到56MIPS ,需要每台处理机的MIPS 效率是多少?
A.2
B.4
C.5.83
D.40
答:B
5.9试在含一个PE 的SISD 机和在含n 个PE 且连接成一线性环的SIMD 机上计算下列求内积
的表达式:其中n=2k
∑=?=n
i i i B A s 1
假设完成每次ADD 操作需要2个单元时间,完成每次MULTIPLY 操作需要4个单位时间,沿双向环在相邻PE 间移数需1个单位时间
(1) SISD 计算机上计算s 需要多少时间
(2) SIMD 计算机上计算s 需要多少时间
(3) SIMD 机计算s 相对于SISD 计算的加速比是多少?
答:
(1) 4n+2(n-1)
(2) 124-++n k
(3)
()n
k n n ++-+23124
5.10如果一台SIMD 计算机和一台流水线处理机具有相同的计算性能,对构成它们的主要部件分别有什么要求?
答:一台具有n 个处理单元的SIMD 计算机与一台具有一条n 级流水线并且时钟周期为前者1/n 的流水线处理机的计算性能相当,两者均是每个时钟周
期产生n 个计算结果。但是,SIMD 计算机需要n 倍的硬件(n 个处理单元),而流水线处理机中流水线部件的时钟速率要求比前者快n 倍,同时还需要存储器的带宽也是前者的n 倍。
第六章 机群系统
6.1 试区分和例示下列关于机群的术语:
1)专用机群和非专用机群;
2)同构机群和异构机群;
3)专用型机群和企业型机群。
答:
1) 根据节点的拥有情况,分为专用机群和非专用机群,在专用机群中所有的资源是共享的,
并行应用可以在整个机群上运行,而在非专用机群中,全局应用通过窃取CPU 时间获得运行,非专用机群中由于存在本地用户和远地用户对处理器的竞争,带来了进程迁移
和负载平衡问题。
2)根据节点的配置分为同构机群和异构机群,同构机群中各节点有相似的的体系,并且使用相同的操作系统,而异构机群中节点可以有不同的体系,运行的操作系统也可以不同。3)专用型机群的特点是紧耦合的、同构的,通过一个前端系统进行集中式管理,常用来代替传统的大型超级计算机系统;而企业型机群是松耦合的,一般由异构节点构成,节点可以有多个属主,机群管理者对节点有有限的管理权。
6.2 试解释和例示一下有关单一系统映像的术语:
1)单一文件层次结构;
2)单一控制点;
3)单一存储空间;
4)单一进程空间;
5)单一输入/输出和网络。
答:
1)用户进入系统后所见的文件系统是一个单一的文件和目录层次结构,该系统透明的将本地磁盘、全局磁盘和其他文件设备结合起来。
2)整个机群可以从一个单一的节点对整个机群或某一单一的节点进行管理和控制。
3)将机群中分布于各个节点的本地存储器实现为一个大的、集中式的存储器。
4)所有的用户进程,不管它们驻留在哪个节点上,都属于一个单一的进程空间,并且共享一个统一的进程识别方案。
5)单一输入/输出意味着任何节点均可访问多个外设。单一网络是任一节点能访问机群中的任一网络连接。
6.3 就Solaris MC系统回答下列问题:
1)Solaris MC 支持习题6.2 中单一系统映像的哪些特征?不支持哪些特征?
2)对那些Solaris MC 支持的特征,解释一下Solaris MC是如何解决的。
答:
1)支持单一文件层次结构、单一进程空间、单一网络和单一I/O空间。不支持单一控制点和单一的存储空间。
2)Solaris使用了一个叫PXFS的全局文件系统GFS。PXFS文件系统的主要特点包括:单一系统映像、一致的语义及高性能。PXFS通过在VFS/vnode接口上截取文件访问操作实现单一系统映像,保证了单一文件层次结构。
Solaris MC提供了一个全局进程标示符pid可定位系统所有进程,一个进程可以迁移到其他节点,但它的宿主节点中总记录有进程的当前位置,它通过在Solaris核心层上面增加一个全局进程以实现单一进程空间,每个节点有一个节点管理程序,每个本地进程有一个虚拟进程对象vproc,vproc保留每个父进程和子进程的信息,实现了全局进程的管理。
单一网络和I/O空间通过一致设备命名技术和单一网络技术实现。
6.4 举例解释并比较以下有关机群作业管理系统的术语:
1)串行作业与并行作业;
2)批处理作业与交互式作业;
3)机群作业和外来作业;
4)专用模式、空间共享模式、时间共享模式;
5)独立调度与组调度。