ADF检验和协整检验的区别 (1)
外商直接投资对广东省经济增长的实证分析

外商直接投资对广东省经济增长的实证分析作者:蒋雨生孟玉基符家维来源:《经济研究导刊》2021年第12期摘要:运用Stata软件,通过ADF、协整和格兰杰因果检验,对广东省FDI与GDP增长之间的关系进行研究。
首先,协整检验发现二者之间存在长期均衡关系。
长期来看,广东省GDP对外商直接投资的弹性是0.9114。
最后,通过格兰杰因果检验发现滞后1期时,外商直接投资是广东省GDP的格兰杰原因;滞后2期则相反,广东省GDP是FDI的格兰杰原因。
随着广东省利用外商直接投资金额的增加,发现广东省在使用外商直接投资的时候还存在区域分布严重不均衡、第二产业占比过高等问题。
因此,今后需要格外注意外商直接投资的区域均衡分布和产业引导问题。
关键词:外商;直接投资;经济增长;协整检验;格兰杰因果中图分类号:F127 文献标志码:A 文章编号:1673-291X(2021)12-0007-03引言研究数据显示,我国吸收外商直接投资连续十几年位于发展中国家第一名,在2017年我国实际使用外商直接投资额达到了3 502.32亿美元。
另外,我国区域经济也呈现出连续增长,这引起了全世界人们的广泛关注。
从我国地理位置来看,东部沿海地区有非常大的地域优势,其中广东省就是东部沿海地区中拥有地理优势的“佼佼者”,而且广东省还拥有着巨大的市场和人力资本,因此近年来,大批外商前往广东进行投资。
因此,本文经过对广东省经济增长与外商直接投资之间的关系进行剖析,希望能够发现它们之间的相互影响机制,为广东省更好地运用外商直接投资,促成经济增长提供有效的对策。
一、广东省外商直接投资的基本情况(一)广东省外商直接投资的总体规模改革开放以来,通过实施一系列积极优惠的战略方针来吸引外商进行投资,使得外商直接投资数额大幅度增加。
广东省在吸引外商投资方面具有特别的优点:地处东部地区,有着得天独厚的地理位置;相对宽松灵活的政策环境;优越的基础设施等等。
2017年广东省FDI比2010年增长了13.06%,比1980年的12 320萬美元增加了18493.08%。
ADF检验和协整检验
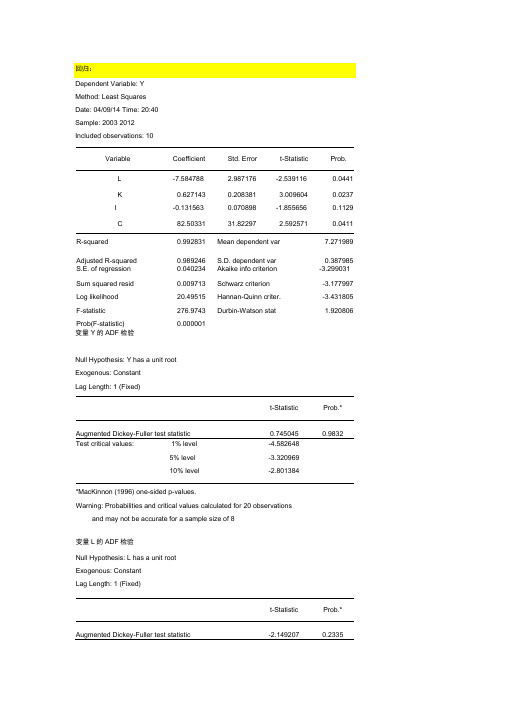
Prob.*
Augmented Dickey-Fuller test statistic
0.745045
0.9832
Test critical values:1%level
5%level
10%level
-4.582648
-3.320969
-2.801384
*MacKinnon (1996) one-sided p-values.
0.387985
S.E. of regression
0.040234
Akaike info criterion
-3.299031
Sum squared resid
0.009713
Schwarz criterion
-3.177997
Log likelihood
20.49515
Hannan-Quinn criter.
Warning: Probabilities and critical values calculated for 20 observations
and may not be accurate for a sample size of8
Sample: 2003 2012
Included observations: 10
Variable
Coefficient
Std. Errort-Statistic
Prob.
L
-7.584788
2.987176-2.539116
0.0441
K
0.627143
0.2083813.009604
0.0237
-1.035819
0.8697
协整检验

伪回归:如果一组非平稳时间序列之间不存在协整关系,则这一组变量构造的回归模型就是伪回归。
残差序列是一个非平稳序列的回归被称为伪回归,这样的一种回归有可能拟合优度、显著性水平等指标都很好,但是由于残差序列是一个非平稳序列,说明了这种回归关系不能够真实的反映因变量和解释变量之间存在的均衡关系,而仅仅是一种数字上的巧合而已。
伪回归的出现说明模型的设定出现了问题,有可能需要增加解释变量或者减少解释变量,抑或是把原方程进行差分,以使残差序列达到平稳。
伪回归是回归方程时间序列数据中涉及的一个概念。
该问题通俗来讲,就是:本来两个变量之间是不存在任何经济关系的,但是因为这两个时间序列数据表现出的变化趋势是一致的,所以,当你对其进行回归时候会得到一个很高的可决系数,让你误以为这一回归关系显著成立。
其实这一回归关系是错的,即伪回归。
要想避免伪回归,应首先对变量进行平稳性检验,接下联进行协整检验。
若变量之间存在协整关系,这一回归才算成立。
负相关negative correlation在回归与相关分析中,因变量值随自变量值的增大(减小)而减小(增大)的现象。
在这种情况下,表示相关程度的相关系数为负值。
相关程度用相关系数r表示,-1≤r<1,r的绝对值越大,表示变量之间的相关程度越高,r为负数时,表示一个变量的增加可能引起另一个变量的减少,此时,叫做负相关。
统计学中常用相关系数r来表示两变量之间的相关关系。
r的值介于-1与1之间,r为正时是正相关,反映当x增加(减少)时,y随之相应增加(减少);呈正相关的两个变量之间的相关系数一定为正值,这个正值越大说明正相关的程度越高。
当这个正值为1时就是完全正相关的情形,如点子排为一条直线,为完全正相关。
正相关虽然意思明确,其实是个模糊的概念,不可以量化,只是定性说法。
如果有明确的关系,例如y=2x,这叫y与x成正比,如果只是大体上,x、y的变化方向一样,例如x上升,y也上升或者x下降,y也下降,那么,这叫正相关。
单位根检验的方法

单位根检验的方法主要有以下几种:
1. ADF检验:即Augmented Dickey-Fuller检验,是对Dickey-Fuller检验的扩展,可以处理含有高阶滞后项的时间序列数据。
它通过在回归模型中加入差分滞后项来控制序列相关的干扰。
2. PP检验:即Phillips-Perron检验,与ADF检验类似,但使用非参数方法来修正序列相关的问题,对小样本性质有一定的改进。
3. KPSS检验:即Kwiatkowski-Phillips-Schmidt-Shin检验,是一种基于平稳序列的检验方法,原假设是序列是平稳的,而备择假设是序列存在单位根。
4. ERS检验:即Elliott-Rothenberg-Stock检验,是一种基于误差修正模型的单位根检验方法,适用于存在长期均衡关系的非平稳时间序列。
5. NP检验:即Nelson-Plosser检验,是一种专门用于检验宏观经济时间序列是否存在单位根的方法。
6. DF-GLS检验:即Dickey-Fuller Generalized Least Squares检验,是一种改进的Dickey-Fuller检验,使用广义最小二乘法来估计模型参数,以提高检验的功效。
7. 霍尔斯检验:即Hall测试,也是一种单位根检验方法,主要用于检测分数整合的存在。
8. 其他检验:还有一些其他的单位根检验方法,如Fisher类型的检验、Maddala-Wu检验等,它们在不同的情况下有各自的适用性和优势。
adf检验通俗解释

adf检验通俗解释
ADF检验,即单位根检验(Augmented Dickey-Fuller Test),是一种经济学时间序列分析中常用的统计方法。
它用来判断一个时间序列数据是否存在单位根,即是否存在趋势。
通俗地说,单位根检验用来判断时间序列数据的变化趋势是否随机性的,或者说是否存在长期趋势。
如果数据存在长期趋势,就不能用简单的方法进行分析和预测,因为数据变化是有规律的。
而单位根检验可以帮助我们识别数据是否存在长期趋势,从而选择合适的模型来进行进一步分析。
ADF检验的思路是将时间序列数据拆分成趋势项、季节项、残差项等不同部分,然后分别对这些部分进行统计检验。
如果残差项(即剔除了趋势项和季节项后的数据)不存在单位根,那么我们可以认为原始数据也不存在单位根,即没有长期趋势。
通过ADF检验,我们可以得到一个统计量,根据这个统计量的显著性水平,来判断时间序列是否存在单位根。
如果统计量的值小于某个阈值,即p值小于显著性水平,那么我们可以拒绝存在单位根的假设,认为数据不存在长期趋势。
总之,ADF检验是一种用来判断时间序列数据是否存在长期趋势的方法,通过检验序列的残差项是否存在单位根,来判断原始数据是否存在单位根。
平稳协整

ADF检验
ADF检验是通过下面三个模型完成的: p 模型(1): ∆ y = δ y + λ ∆y +u
t t −1
∑
j =1
j
t− j
t
模型(2): ∆ y t = α + δ y t − 1 +
∑λ
j =1
p
j
∆ yt − j + ut
模型(3): ∆yt = α + β t + δ yt −1 + ∑ λ j ∆yt − j + ut
平稳、协整、格兰杰因果检验
1、平稳性检验 2、协整检验 3、格兰杰因果检验
1、平稳性检验
通常情况下,我们所说的平稳性是指弱平稳, 即如果一个时间序列的均值和方差在任何时间保 持恒定,并且两个时期t和t+k之间的协方差仅依赖 于两时期之间的距离k,而与计算这些协方差的实 际时期t无关,则该时间序列是平稳的。 常见的时间序列的平稳性检验方法有以下四 种:利用散点图进行平稳性判断、利用样本自相 关函数进行平稳性判断、单位根检验、ADF检验。 下面仅介绍如何利用Eviews进行ADF检验时 间序列的平稳性。
i =1
β i xt−i + u t
则检验对存在格兰杰非因果性的零假设是:
H0 : β1 = β2 =L= βk = 0
要对两个乃至多个时间序列进行格兰杰因 果检验,可以在Eviews6.0软件的主菜单中选 择Quick→Group Statistics→Granger Causality Test命令,在弹出的Series List对 话框中对要进行格兰杰因果检验的序列或者 变量进行设置,确定后在弹出的Lag Specification对话框中进行滞后阶数的设置, 确定后得到格兰杰因果检验结果。 下面我们举一个例子介绍如何利用 Eviews6.0软件进行格兰杰因果检验。
常用的协整检验方法(一)

常用的协整检验方法(一)常用的协整检验方法协整检验在时间序列分析中扮演着重要的角色,它用于检测多个非平稳时间序列之间是否存在长期的关系。
本文将介绍几种常用的协整检验方法,以帮助读者更好地理解和运用这些方法。
1. 单位根检验单位根检验是协整检验的基础,常用的方法有ADF(Augmented Dickey-Fuller)检验和PP(Phillips-Perron)检验。
它们都可以用来判断一个时间序列是否是平稳的。
•ADF检验:基本思想是通过引入滞后差分来构建一个扩展的Dickey-Fuller统计量,然后进行假设检验。
•PP检验:是对ADF检验的改进,它考虑了残差自相关的情况,减少了误检的可能性。
2. Johansen检验Johansen检验是用来检验时间序列之间是否存在协整关系的方法,它基于向量自回归(VAR)模型。
Johansen检验的原假设是存在r个协整关系,其中r是一个确定的非负整数。
Johansen检验有两个主要统计量:Trace统计量和Eigenvalue统计量。
通过比较这两个统计量和对应的临界值,可以判断时间序列之间是否存在协整关系以及协整关系的个数。
3. Engle-Granger检验Engle-Granger检验是一种基于OLS回归的协整检验方法。
它首先通过引入滞后差分将非平稳时间序列转化为平稳序列,然后利用最小二乘法建立回归模型,检验残差是否平稳。
Engle-Granger检验分为两个步骤:回归阶数的确定和残差的平稳性检验。
在回归阶数的确定中,可以采用信息准则(如AIC、BIC)来选择最佳的阶数。
在残差的平稳性检验中,可以使用ADF检验或PP 检验来判断。
4. 可视化方法除了以上的统计方法,还可以运用可视化方法来辅助协整检验。
常用的可视化方法包括散点图、路径图和回归图等。
散点图可以用来观察两个时间序列之间的关系,如果它们呈现出一种趋势性的关系,可能存在协整关系。
路径图可以展示多个时间序列之间的协整关系,有助于形象地理解协整关系的存在和特征。
ADF检验和协整检验的区别

特征根迹统计量(P值)5%临界值λ_max统计量(P值)5%临界值原假设0.786230 43.63(0.02) 40.17 23.14(0.06) 24.16 0个协整向量0.659057 20.49(0.14) 24.28 16.14(0.09) 17.8 至少1个协整向量0.249925 4.35(0.66) 12.32 4.31(0.58) 11.22 至少2个协整向量0.002389 0.0023(0.88) 4.13 0.036(0.88) 4.13 至少3个协整向量正确的计算以1978年为100的定基指数的方法为:如果有以上一年为100的GDP指数,如何计算以某固定年份为100的GDP指数?以北京1978年为100的定基指数计算为例:第一步:(1)将1978年的GDP指数定义为100,这样,1978年定基指数(1978=100)=100.第二步:(2)那么1979年的定基(1978=100)就等于当年的同比指数,即1979年GDP定基指数(1978=100)=1979年GDP指数(以上一年为100)第三步(最关键):1980年GDP指数(1978=100)=1979年GDP指数(1978=100)*1980年GDP指数(以上一年为100)/100。
第四步:自1981年起重复第三步,即以各上年定基指数(1978=100)分别乘以当年同比指数(上年=100的指数)再除以100,就依次可以得到所有年份以1978年为100的定基指数。
EXCEL直接复制第三步的公式就可以计算出来。
本文来自: 人大经济论坛数据交流中心版,详细出处参考:定基指数编辑目录1定基指数与环比指数的关系2定基指数的分类3定基指数与环比指数的区别定基指数即定比指数。
定基指数是指在指数数列中,各期指数都以某—固定时期为基期。
定基指数说明现象在较长时期内的发展变化情况。
定基指数与环比指数的关系编辑定基指数与环比指数可以相互换算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
特征根迹统计量(P值)5%临界值λ_max统计量(P值)5%临界值原假设0.786230 43.63(0.02) 40.17 23.14(0.06) 24.16 0个协整向量0.659057 20.49(0.14) 24.28 16.14(0.09) 17.8 至少1个协整向量0.249925 4.35(0.66) 12.32 4.31(0.58) 11.22 至少2个协整向量0.002389 0.0023(0.88) 4.13 0.036(0.88) 4.13 至少3个协整向量正确的计算以1978年为100的定基指数的方法为:如果有以上一年为100的GDP指数,如何计算以某固定年份为100的GDP指数?以北京1978年为100的定基指数计算为例:第一步:(1)将1978年的GDP指数定义为100,这样,1978年定基指数(1978=100)=100.第二步:(2)那么1979年的定基(1978=100)就等于当年的同比指数,即1979年GDP定基指数(1978=100)=1979年GDP指数(以上一年为100)第三步(最关键):1980年GDP指数(1978=100)=1979年GDP指数(1978=100)*1980年GDP指数(以上一年为100)/100。
第四步:自1981年起重复第三步,即以各上年定基指数(1978=100)分别乘以当年同比指数(上年=100的指数)再除以100,就依次可以得到所有年份以1978年为100的定基指数。
EXCEL直接复制第三步的公式就可以计算出来。
本文来自: 人大经济论坛数据交流中心版,详细出处参考:定基指数编辑目录1定基指数与环比指数的关系2定基指数的分类3定基指数与环比指数的区别定基指数即定比指数。
定基指数是指在指数数列中,各期指数都以某—固定时期为基期。
定基指数说明现象在较长时期内的发展变化情况。
定基指数与环比指数的关系编辑定基指数与环比指数可以相互换算。
定基指数等于相应时期环比指数的连乘积。
这种关系的存在要求在以下条件下:各个指数采用的权数不变,指数值中不出现零和负数的情况。
定基指数的分类编辑1.数量指标定基指数数列2.质量指标定基指数数列定基指数与环比指数的区别编辑环比指数数列和定基指数数列各有不同用途。
若要说明各时期的现象与其前一时期对比变动的情况时,可采用环比指数数列加以分析;而要说明各时期的现象与某一固定时期对比变动情况时,就应采用定基指数数列加以分析。
此经济态势下我们构造了如下的函数:根据上表可知数据是平稳的,通过了单根检验。
对数据做回归的结果如下图:根据上表的各项指标显示出,无论从拟合优度上看,还是从t 检验、F 检验方面观察,计量模型都是不错的。
模型可以用于大略的预测。
可得三者之间的长期关系为:文献[10]庄佳强,需求因素对长期经济增长的影响研究[论文]华中科技大学博士学位论文。
(去掉了)[7][15]林哲,毛中根,中国经济平稳增长的总需求结构分析,学术月刊,2005年5月。
(去掉7)综述林哲(2005)研究表明,中国当前的最终消费需求、投资需求和进出口之间不协调。
这种不协调会带来不利的长期性影响,进而影响到长期供给潜力的实现。
庄佳强(2008)采用比较分析、统计分析、计量分析和数理建模等方法从经验和理论两方面展开论述,得出消费需求和经济长期存在相互反馈效应。
具体内容投资需求对经济的拉动作用在于:短期内投资需求是总需求的组成部分,投资增加使总产出增加;长期内投资的结果是资本存量的增加,即生产能力的增加。
居民消费与政府消费之和组成国内最终消费。
消费对经济增长的拉动作用主要体现在:一消费需求是最总需求的重要组成部分,消费增加使总产出增加;二消费(如教育和医疗保健等方面的支出)对人力资本的创造以及政府提供的生产性公共产品,为长期经济增长提供生产要素,从而推动经济增长。
进出口对于弥补国内需求不足起着非常重要的作用,因为全球化的资源流动促进经济发展[7]。
[1]作者:国家统计局,1978年以来我国经济社会发展的巨大变化[N],人民日报,2013年11月6日。
.cn/news/f53c70b6-43be-48c3-ab4b-ae4148c35c99.html重要符合要求ADF 检验和协整检验(同上)。
GDP 平减指数=现值GDP/实际GDP国内生产总值指数(上年=100)国内生产总值指数是指反映一定时期内国内生产总值变动趋势和程度的相对数,该指标是以上一年为基期计算的指数。
按不变价格计算。
GDP 环比指数:real GDP i / real GDP i-1重要(4)构造计量模型模型中各变量都是加速资本形成的,符合供给约束型经济的逻辑。
A.相关系数。
A.单根检验。
首先对这几个变量取对数,以消除数据存在的异方差。
然后对ln Y I 、ln YG、lnY M 0、ln Y M 1、ln YM 2进行ADF 检验,ADF 检验结果如下图所示: ln Y I 、ln Y G 、ln Y M 0、ln Y M 1、ln YM 2的单根检验结果 变量 差分次数 (c,t,k ) DW 值 ADF 统计值 5%临界值 1%临界值 结论 lnYI1(0,0,1)1.82-2.28-1.97-2.73ln YG 1(0,0,3)1.94-2.64-1.97-2.75lnYM 0 1(0,0,3) 1.94 -2.64 -1.97 -2.75lnYM 11(0,0,1) 1.97 -2.18 -1.97 -2.73lnYM 2 0(0,0,1) 1.97 -2.94 -1.96 -2.72B.协整检验(对lny 、ln Y 、ln Y 、ln Y 、ln Y)特征根迹统计量(p值)5%临界值λ-max统计量(p值)5%临界值原假设0.987433 125.7821(0.00)60.06141 70.02693(0.00)30.43961 0个协整向量0.809372 55.75515(0.0007)40.17493 26.51890(0.0236)24.15921 至少一个协整向量经济基本理论可以直接运用普通最小二乘法回归。
C.回归方程。
回归方程结果如下:重要反复试错,得出各个统计量之间的变动趋同性(相关系数和趋势图)、因果关系(数量方程)。
要注意各统计量之间滞后若干期数据之间的关系,工作量较大,要细心。
孝芳:可能需要做计量模型的节点在第三部分,即各个统计量之间的变动趋同性(相关系数和趋势图)、因果关系(数量方程)。
但是,不一定非做数量模型不可,发现统计规律(相关性)也是很好的。
如果做数量模型,那么,一定把握好逻辑通顺的因果关系,自己能够解释原因和结果,即明确设定解释变量和被解释变量,不能硬凑合。
同时,还要注意,一元模型一般是不可靠的,要考虑直接其他解释变量。
我们虚拟一下吧:假如,我们发现X/Y可能对I/Y有较为显著的解释关系,设前者为x1,后者为y,则有:y=f(x1),但是,这个模型不是很可靠的,因为社会经济中一个原因导致一个结果的是非常罕见的,一般都是多因一果。
因此,就必须考虑假如其他解释变量x2、x3等等,这样,模型的可绝系数才能比较高(可绝系数低的原因就是可能漏掉了重要的解释变量)。
模型做出来之后,可以只分析x1与y的关系,不管x2和x3的事儿,但模型必须涵盖这两个(或更多)解释变量。
其实,最为有意思的在第四部分,发现某种变动的前兆,并尝试解释。
抓紧做,别耽误了学报第二期印刷。
物质角度第一部分A消费率与对国货的内需率的趋势图、与投资率的趋势图、与对国货的外需率的趋势图如下B投资率与国内需求率的趋势图、对国货的外需率的趋势图、对国内的内需率的趋势图、居民消费率的趋势图如下:C净出口率与对国货的外需率的趋势图如下:D国内需求率与投资率的趋势图、与对国货的内需率的趋势图如下:E 对国货的内需率与居民消费率、对国货的外需率、投资率的趋势图如下:F 对国货的外需率与对国货的内需率、居民消费率、投资率、净出口率的趋势图如下:分析重要需求结构总的分析,从分析中可以看出来我国的需求结构失衡,我国主要靠投资和出口拉动经济增长,这是我国在经济发展过程中长期面临的一个重要问题。
因为总需求构成对于宏观经济政策的制定有着重要意义,对经济增长具有重大的拉动作用,而失衡的需求结构既会使得我国宏观经济运行暴露在外部冲击风险之下,也会降低经济运行的内在稳定性。
【来自文献11】 投资需求对经济的拉动作用在于它的两重功能:短期内投资需求是总需求的组成部分,投资增加使总产出增加;长期内投资的结果是资本存量的增加,即生产能力的增加,从而促进经济增长。
居民消费与政府消费之和组成国内最终消费。
消费对经济增长的拉动作用主要通过两个途径来实现:一是消费需求是最终需求,是总需求的重要组成部分,消费增加使总产出增加;二是消费(如教育和医疗保健等方面的支出)对人力资本的创造,以及政府提供的生产性公共产品,为长期经济增长提供生产要素,从而推动经济增长。
进出口对于弥补国内需求不足起着非常重要的作用,国际贸易被公认为是经济增长的引擎,因为全球化的资源流动主导着经济发展。
【来自文献6】货币角度可以从-11-13/7.html物质角度一:Y 与X/Y 的相关系数为0.18,y 与I/Y 的相关系数为0.51,y 与NX/Y 的相关系数为-0.20,y 与G/Y 的相关系数为0.19,y 与C/Y 的相关系数为-0.37,y 与YGI C ++的相关系数为0.42,y 与YMG I C -++的相关系数为-0.30。
X/Y 与I/Y 的相关系数为0.75,X/Y 与NX/Y 的相关系数为0.43,X/Y 与G/Y 的相关系数为0.1,X/Y 与C/Y 的相关系数为-0.65,X/Y 与YGI C ++的相关系数为0.52,X/Y 与YMG I C -++的相关系数为-0.6,I/Y 与NX/Y 的相关系数为-0.14,I/Y 与G/Y的相关系数为0.01,I/Y 与C/Y 相关系数为-0.48,I/Y 与YGI C ++相关系数为0.88,I/Y 与YM G I C -++相关系数为-0.47,NX/Y 与G/Y 的相关系数为0.16,NX/Y 与C/Y的相关系数为-0.24,NX/Y 与YGI C ++的相关系数为-0.25,NX/Y 与Y M G I C -++的相关系数为-0.19,G/Y 与C/Y 的相关系数为-0.07,G/Y 与YGI C ++的相关系数为0.14,G/Y 与Y M G I C -++的相关系数为0.23,C/Y 与YG I C ++的相关系数为-0.035,C/Y与Y M G I C -++的相关系数为0.96,YG I C ++与Y M G I C -++的相关系数为0.006。