什么是二分图
二分图及其应用

求最大匹配举例
①取一个初始匹配M={Bb,Cc,Dd}. ②用标记法从点A开始求得一条增广路:=(AcCe)(左图). ③用调整匹配M:将中属于M的边删去并将其中不属于M的
其它边添加到M中得到比M多一边的新匹配M’(如右图 示). ④因对M’用标记法只能从E或F开始,但都不能求出M’的 任何增广路,故判定M’是一个最大匹配.
13
匈牙利算法:
初始时最大匹配为空 for 二分图左半边的每个点i do 从点i出发寻找增广路径。如果找到,则把它取反
(即增加了总了匹配数)
如果二分图的左半边一共有n个点,那么最多找n 条增广路径。如果图中共有m条边,那么每找一 条增广路径(DFS或BFS)时最多把所有边遍历一 遍,所花时间也就是m。所以总的时间大概就是O (n * m)。
6
例2:工作分配问题
问题 某教研室有4位教师:A,B,C,D. A能教课程5;B能教 1,2;C能教1,4;D能教课程3.能否适当分配他们的任务,使4 位教师担任4门不同课并且不发生安排教师教他不能教的 课的情况?
此问题可归结为二分图的数学模型: G={A,B,C,D},E,{1,2,3,4,5},(X,y)E,如果X能教y.一 个满足要求的工作分配正是一个含有4条边的一个最大匹 配.
for(i=0;i<n;i++) { if(mark1[i]) { if(!v[i].empty()){ memset(mark2,true,sizeof(mark2)); for(j=0;j<v[i].size();j++) { point = v[i][j]; if(!mark2[point]) continue; mark2[point] = false; if(list[point] == -1 || dfs(point)) { list[point] = i; num++; break; } } } mark1[i] = false; } } if(flog || list[0] != -1) cout << num-1 << endl; else cout << num << endl; } int main() { int i,j,s,d; while(cin>>n) { if(n == 0)break; v.clear(); v.resize(n); cin >> m >> edge; for(i=0;i<edge;i++) { cin >> j >> s >> d; v[s].push_back(d); } Solve(); } return 0; }
图论——二分图1:二分图以及判定
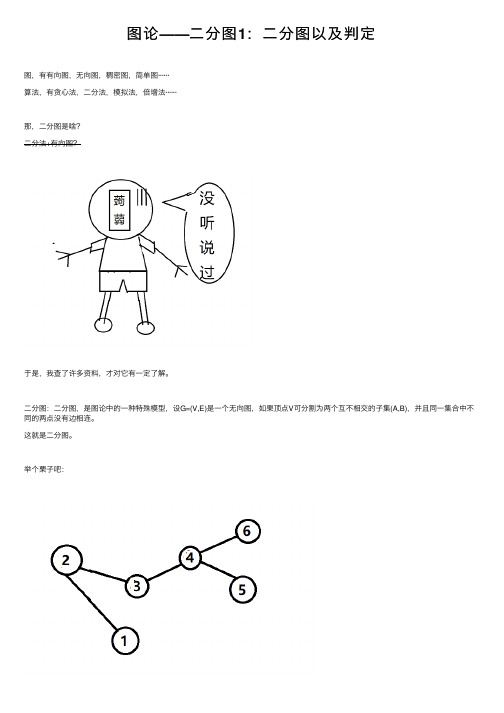
图论——⼆分图1:⼆分图以及判定图,有有向图,⽆向图,稠密图,简单图······算法,有贪⼼法,⼆分法,模拟法,倍增法······那,⼆分图是啥?⼆分法+有向图?于是,我查了许多资料,才对它有⼀定了解。
⼆分图:⼆分图,是图论中的⼀种特殊模型,设G=(V,E)是⼀个⽆向图,如果顶点V可分割为两个互不相交的⼦集(A,B),并且同⼀集合中不同的两点没有边相连。
这就是⼆分图。
举个栗⼦吧:这是不是⼆分图?反正我第⼀次看觉得不是其实,是的,他是⼆分图,尽管看上去是连着的。
若我们将图中的⼀些边转⼀下,变成:这就是⼀个明显的⼆分图。
集合A与B中的点互不相连。
因此,在⼿动判定⼆分图时学会转边!辣魔,⼆分图要⽤计算机判定怎么实现?数竞⼤佬:简单!!!!染⾊⼤法!!!有没有熟悉的感觉0表⽰还未访问,1表⽰在集合A中,2表⽰在集合B中。
col(color)储存颜⾊。
初始化为0.上代码:其实是模板可以记忆。
1 vector <int> v[N];2void dfs(int x,int y){3 col[x]=y;4for (int i=0; i<v[x].size(); i++) {5if (!col[v[x][i]]) dfs(v[x][i],3-y);6if (col[v[x][i]]==col[x]) FLAG=true; //产⽣了冲突7 }8 }9for (i=1; i<=n; i++) col[i]=0; //初始化10for (i=1; i<=n; i++) if (!col[i]) dfs(i,1); //dfs染⾊11if (FLAG) cout<<"NO"; else cout<<"YES";下⼀章我们将讲到⼆分图的匹配,我们明天见。
二分图相关问题

X X S X X
X X X X
X代表攻击范围,S代表骑 士
分析
对棋盘染色,设方格的坐标为(x,y),x和y同奇 偶的方格对应X集合,不同奇偶的对应Y集合。 由于骑士沿着“日”字形路线攻击,所以每个 攻击肯定是处于X集合和Y集合之间,而不可 能在两个集合内部。 显然,转化后变为求二分图的最大独立集
匈牙利算法
简要说明:find函数用于判断从k点开始是否能 够找到一条交错路。对于每个可以与k匹配的 顶点j,假如它未被匹配,交错路就已经找到; 假如j已与某顶点x匹配,那么只需调用find(x) 来求证x是否可以与其它顶点匹配,如果返回 true的话,仍可以使j与k匹配;这就是一次 DFS。每次DFS时,要标记访问到的顶点 (cover[j]=true),以防死循环和重复计算。
例题分析
Hanoi Tower Troubles Again! (OIBH Contest)
ZOJ 1239 题目大意:给定柱子数N,按编号从小到大放球, 要求:如果该球不在最底数,则该球和它下面一个 球的编号之和必须为完全平方数。 问对于给定的N,最多能放多少球上去。 N<=50
例题分析
分析
铺放方法
1.2. .333 444. ..2.
Sample Output 4
分析
最小覆盖是覆盖所有的边,因此泥地对应边 建图方式类似于皇家卫士,也是利用行连通块 和列连通块做点,单位泥地对应二分图中的边 要求放最少的板覆盖全部的泥地,转化为求最 小覆盖
二分图最大独立集
图的独立集:寻找一个点集,其中任意两点在 图中无对应边 一般图的最大独立集是NP完全问题 二分图的最大独立集=图的点数-最大匹配数
二分图最小覆盖
图的覆盖:寻找一个点集,使得图中每一条边 至少有一点在该点集中
二分图概念及性质

⼆分图概念及性质 段段续续的看⼆分图已经有些时⽇了。
现在借着周末整理⼀下这么多天对⼆分图的掌握程度。
也好对⼆分图有个整体的认知。
另外,此⽂只针对与⼆分图的⼀些概念和性质,不涉及求最⼤匹配的算法。
好吧,切⼊正题: ⾸先我们抛开⼆分图严谨准确的定义,从⼀个感性的⾓度来认识⼀下什么是⼆分图。
所谓⼆分图,就是能够把图中的定点分成两个X,Y两部分;并且整个图的边只存在于X与Y之间。
就是说,X与Y的内部是不存在边的,否则的话就不是⼆分图了。
举个例⼦:如果把整个⼈类中的男⼈和⼥⼈看成顶点,⼈与⼈之间的恋爱关系(这⾥只讨论异性之间的正常恋爱,同性恋是不被承认的)为边来建⽴图模型的话。
那么这其实就是⼀个⼆分图,其中的男⼈为X部分,⼥⼈为Y部分。
好了,现在我们给出⼆分图严谨的科学定义: 假设图G=(V,E)是⼀个⽆向图,若顶点集 V 可以分解成两个互不相交的⼦集(A,B),并且图中的所有边(i,j)的端点 i,j 分别属于⼦集 A,B 中的元素,则称图 G 是⼀个⼆分图。
为了更好的叙述下⽂,先让我们清楚⼀个概念: 匹配:⽆公共点的边集合。
(形象点就是 X与Y之间的边的个数) 匹配数:边集中边的个数。
最⼤匹配:匹配数最⼤的匹配。
边独⽴集:指图中边集的⼀个⼦集,且该⼦集中的任意两条边之间没有公共点。
(对⽐匹配的概念我们发现,其实边独⽴集和匹配是⼀个概念) 最⼤边独⽴集:包含边数最多的边独⽴集。
(其实就是最⼤匹配,为了⽅便,以后统称最⼤匹配)图1如图1,如果<1,4>是⼀个合法匹配,那么<1,5>就不是⼀个合法的匹配,因为它们有公共点1 。
同样的如果<2,5>是⼀个合法的匹配,那么<2,6>和<3,5>就不是⼀个合法的匹配。
不难看出,其中最⼤匹配是边集:{1, 4, 5},最⼤匹配数为3 。
独⽴集: 是指图的顶点集的⼀个⼦集,且该⼦集中的任意两个顶点之间不存在边。
二分图概念性质(通俗版)

二分图的定义二分图的定义非常简单,有两组顶点,一组顶点记为L ,另一组记为R ,L 和R 没有公共的元素,并且所有的边都是连接L 和R 中的点的,对于L 和R 本身,它们内部的任何两个点都没有边相连,这样的无向图就叫二分图。
《组合数学》上这样讲解:二分图可描述为:一,顶点的集合;二,将该顶点集分成两部分的一个划分;三,连接一部分的一个顶点与另一部分的一个顶点的边的集合。
二分图是无向图,那么什么样的无向图是二分图呢?有以下定理:定理:无向图G 为二分图的充分必要条件是,G 至少有两个顶点, 且其所有回路的长度均为偶数。
证明:至少两个顶点,这个显然,把这个条件忽略掉,着重考虑回路长度为偶数这一条件。
先证充分性:由于图中可能有回路也可能无回路,无回路的情况应该最简单,自然考虑分类讨论。
于是,分类讨论后,充分性的证明转化成以下两个命题:a)所有无回路的无向图都是二分图;b)所有有回路且回路长度为偶数的无向图都是二分图。
对于a) ,因为无回路无向图总是能把它画成一棵树,所以,这个命题等价于:所有的树都是二分图。
到这里,命题a) 证明显然,因为有一种很简单的从树构造二分图的方法:令树的奇数层的结点为集合L ,令树的偶数层结点为集合R ,这样就从树得到了一个二分图。
再看命题b) ,可以把b) 转化为a) 。
对于图中的每一个回路,我们都从中拿掉一条边,这样可以消灭所有的回路,由a) 知消灭掉所有回路之后的图是二分图。
把此时得到的二分图画成一棵树,拿掉一条边后的回路此时就是树中的一条路径,并且路径的长度为奇数,这就意味着路径的头结点和尾结点所在层数的编号一个是奇数一个是偶数,用上面的从树构造二分图的方法知,头结点和尾结点分别在集合L 中和集合R 中,我们再把拿掉的这条边加上去,只不过是在L 和R 中的两个顶点间连接了一条边,图仍然是原来的二分图。
至此,充分性得证。
再证必要性。
假设二分图中的一条回路是(v0, v1, v2, …, vm, v0) ,由于是二分图,相邻顶点必不属于同一个集合,用L 标记属于集合L 的点,用R 标记属于集合R 的点,不妨假设v0 属于L ,则上面的回路可以标记为L, R, L, R, …, L, R ,由此可见,回路必有偶数个顶点,因此必有偶数条边。
最大二分图匹配(匈牙利算法)

最大二分图匹配(匈牙利算法)二分图指的是这样一种图:其所有的顶点分成两个集合M和N,其中M或N中任意两个在同一集合中的点都不相连。
二分图匹配是指求出一组边,其中的顶点分别在两个集合中,并且任意两条边都没有相同的顶点,这组边叫做二分图的匹配,而所能得到的最大的边的个数,叫做最大匹配。
计算二分图的算法有网络流算法和匈牙利算法(目前就知道这两种),其中匈牙利算法是比较巧妙的,具体过程如下(转自组合数学):令g=(x,*,y)是一个二分图,其中x={x1,x2...},y={y1,y2,....}.令m为g中的任意匹配。
1。
将x的所有不与m的边关联的顶点表上¥,并称所有的顶点为未扫描的。
转到2。
2。
如果在上一步没有新的标记加到x的顶点上,则停,否则,转33。
当存在x被标记但未被扫描的顶点时,选择一个被标记但未被扫描的x的顶点,比如xi,用(xi)标记y 的所有顶点,这些顶点被不属于m且尚未标记的边连到xi。
现在顶点xi 是被扫描的。
如果不存在被标记但未被扫描的顶点,转4。
4。
如果在步骤3没有新的标记被标记到y的顶点上,则停,否则转5。
5。
当存在y被标记但未被扫描的顶点时。
选择y的一个被标记但未被扫描的顶点,比如yj,用(yj)标记x的顶点,这些顶点被属于m且尚未标记的边连到yj。
现在,顶点yj是被扫描的。
如果不存在被标记但未被扫描的顶点则转道2。
由于每一个顶点最多被标记一次且由于每一个顶点最多被扫描一次,本匹配算法在有限步内终止。
代码实现:bfs过程:#include<stdio.h>#include<string.h>main(){bool map[100][300];inti,i1,i2,num,num1,que[300],cou,stu,match1[100],match2[300],pqu e,p1,now,prev[300],n;scanf("%d",&n);for(i=0;i<n;i++){scanf("%d%d",&cou,&stu);memset(map,0,sizeof(map));for(i1=0;i1<cou;i1++){scanf("%d",&num);for(i2=0;i2<num;i2++){scanf("%d",&num1);map[i1][num1-1]=true;}}num=0;memset(match1,int(-1),sizeof(match1)); memset(match2,int(-1),sizeof(match2)); for(i1=0;i1<cou;i1++){p1=0;pque=0;for(i2=0;i2<stu;i2++){if(map[i1][i2]){prev[i2]=-1;que[pque++]=i2;}elseprev[i2]=-2;}while(p1<pque){now=que[p1];if(match2[now]==-1)break;p1++;for(i2=0;i2<stu;i2++){if(prev[i2]==-2&&map[match2[now]][i2]){prev[i2]=now;que[pque++]=i2;}}}if(p1==pque)continue;while(prev[now]>=0){match1[match2[prev[now]]]=now; match2[now]=match2[prev[now]]; now=prev[now];}match2[now]=i1;match1[i1]=now;num++;}if(num==cou)printf("YES\n");elseprintf("NO\n");}}dfs实现过程:#include<stdio.h>#include<string.h>#define MAX 100bool map[MAX][MAX],searched[MAX]; int prev[MAX],m,n;bool dfs(int data){int i,temp;for(i=0;i<m;i++){if(map[data][i]&&!searched[i]){searched[i]=true;temp=prev[i];prev[i]=data;if(temp==-1||dfs(temp))return true;prev[i]=temp;}}return false;}main(){int num,i,k,temp1,temp2,job;while(scanf("%d",&n)!=EOF&&n!=0) {scanf("%d%d",&m,&k);memset(map,0,sizeof(map));memset(prev,int(-1),sizeof(prev)); memset(searched,0,sizeof(searched));for(i=0;i<k;i++){scanf("%d%d%d",&job,&temp1,&temp2); if(temp1!=0&&temp2!=0)map[temp1][temp2]=true;}num=0;for(i=0;i<n;i++){memset(searched,0,sizeof(searched)); dfs(i);}for(i=0;i<m;i++){if(prev[i]!=-1)num++;}printf("%d\n",num);}}。
二分图的讲解

例 3个图的匹配数 依次为3, 3, 4.
4
匹配 (续)
设M为G中一个匹配 vi与vj被M匹配: (vi,vj)M v为M饱和点: M中有边与v关联 v为M非饱和点: M中没有边与v关联 M为完美匹配: G的每个顶点都是M饱和点
例 关于M1, a,b,e,d是饱和点 f,c是非饱和点
M1不是完美匹配
(1)
(2)
(3)
6
Hall定理
定理(Hall定理) 设二分图G=<V1,V2,E>中,|V1||V2|. G中存 在从V1到V2的完备匹配当且仅当V1中任意k 个顶点至少与V2 中的k个顶点相邻(k=1,2,…,|V1|). 由Hall定理不难证明, 上一页图(2)没有完备匹配.
定理 设二部图G=<V1,V2,E>中, 如果存在t1, 使得V1中每个 顶点至少关联 t 条边, 而V2中每个顶点至多关联t条边,则G 中存在V1到V2的完备匹配.
注意: n 阶零图为二分图.
2
二分图的判别法
定理 非平凡无向图G=<V,E>是二分图当且仅当G中 无奇数长度的回路
例 下述各图都是二分图
3
匹配
设G=<V,E>, 匹配(边独立集): 任2条边均不相邻的边子集 极大匹配: 添加任一条边后都不再是匹配的匹配 最大匹配: 边数最多的匹配
匹配数: 最大匹配中的边数, 记为1
M2是完美匹配
M1
M2
5
二分图中的匹配
定义 设G=<V1,V2,E>为二部图, |V1||V2|, M是G中最 大匹配, 若V1中顶点全是M饱和点, 则称M为G中V1 到V2的完全匹配. 当|V1|=|V2|时, 完备匹配变成完美 匹配.
二分图最大匹配及常用建图方法

算法———艺术二分图匹配剖析很多人说,算法是一种艺术。
但是对于初学者的我,对算法认识不是很深刻,但偶尔也能感受到他强大的魅力与活力。
这让我追求算法的脚步不能停止。
下面我通过分析匈牙利算法以及常用建图方式,与大家一起欣赏算法的美。
匈牙利算法匈牙利算法是用来解决最大二分图匹配问题的,所谓二分图即“一组点集可以分为两部分,且每部分内各点互不相连,两部分的点之间可以有边”。
所谓最大二分图匹配即”对于二分图的所有边,寻找一个子集,这个子集满足两个条件,1:任意两条边都不依赖于同一个点。
2:让这个子集里的边在满足条件一的情况下尽量多。
首先可以想到的是,我们可以通过搜索,找出所有的这样的满足上面条件的边集,然后从所有的边集中选出边数最多的那个集合,但是我们可以感觉到这个算法的时间复杂度是边数的指数级函数,因此我们有必要寻找更加高效的方法。
目前比较有效的方法有匈牙利算法和通过添加汇点和源点的网络流算法,对于点的个数都在200 到300 之间的数据,我们是采取匈牙利算法的,因为匈牙利算法实现起来要比网络流简单些。
下面具体说说匈牙利算法:介绍匈牙利之前,先说说“增广轨”。
定义:若P是图G中一条连通两个未匹配顶点的路径,并且属最大匹配边集M的边和不属M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广轨定义总是抽象的下面通过图来理解它。
图中的线段(2->3, 3->1, 1->4)便是上面所说的p路径,我们假定边(1,3)是以匹配的边,(2,3)(1,4)是未匹配的边,则边(4,1)边(1,3)和边(3,2)在路径p上交替的出现啦,那么p就是相对于M的一条增广轨,这样我们就可以用边1,4 和边2,3来替换边1,3 那么以匹配的边集数量就可以加1,。
匈牙利算法就是同过不断的寻找增广轨实现的。
很明显如果二分图的两部分点分别为n 和m,那么最大匹配的数目应该小于等于MIN(n,m); 因此我们可以枚举任第一部分(的二部分也可以)里的每一个点,我们从每个点出发寻找增广轨,最后吧第一部分的点找完以后,就找到了最大匹配的数目,当然我们也可以通过记录找出这些边。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
我们定义匹配点、匹配边、未匹配点、未匹配边,它们的含 义非常显然。例如图3中1,4,5,7为匹配点,其他顶点为未匹 点;1-5、4-7为匹配边,其他边为非匹配边。
最大匹配&完美匹配
最大匹配:一个图所有的匹配中,所匹配的边数最多 的匹配,称为这个图的最大匹配。图4是一个最大匹 配。 完美匹配:如果一个图的某个匹配中,所有的顶点都 是匹配点,那么它就是一个完美匹配。图 4 是一个完 美匹配。显然,完美匹配一定是最大匹配(完美匹配 的任何一个点都已经匹配,添加一条新的匹配边一定 会与已有的匹配边冲突)。但并非每个图都存在完美 匹配。
交替路:图的一条简单路径,满足任意相邻的两条边, 一条在匹配内,一条不在匹配内 。
增广路:从一个未匹配点出发,走交替路, 如果途径另一个未匹配点(出发的点不算), 则这条交替路称为增广路(agumenting path)。 例如,图 5 中的一条增广路如图 6 所示 (图中的匹配点均用红色标出)
/*==================================================*\ | 二分图匹配(匈牙利算法BFS 实现) | INIT: g[][]邻接矩阵; | CALL: res = MaxMatch (); Nx, Ny 初始化!!! | 优点:适用于稀疏二分图,边较少,增广路较短。 | 匈牙利算法的理论复杂度是O(VE) \*==================================================*/ const int MAXN = 1000; int g[MAXN][MAXN], Mx[MAXN], My[MAXN], Nx, Ny; int chk[MAXN], Q[MAXN], prev[MAXN]; int MaxMatch(void) { int res = 0; int qs, qe; memset(Mx, -1, sizeof(Mx)); memset(My, -1, sizeof(My)); memset(chk, -1, sizeof(chk)); for (int i = 0; i < Nx; i++) { if (Mx[i] == -1) {//对于x集合中的每个没有匹配的点i进行一次bfs找 交错轨 qs = qe = 0; Q[qe++] = i; prev[i] = -1; bool flag = 0;//判断是否找到
下面给出此算法的一个例子
:
(1)置M = 空,对x1-x6标记(*)。
(2)找到交替链(x1, y1)(由标记(x1),(*)回溯得),置M = {(x1, y1)}。
(3)找到交替链(x2, y2)(由标记(x2),(*)回溯得),置M = {(x1, y1), (x2, y2)}。
(4)找到交替链(x3, y1, x1, y4)(图中虚线表示非匹配边, 细实线表示交替链中非匹配边,粗实线表示匹配边),因而得 M = {(x2, y2), (x3, y1),(x1, y4)}。
增广路的重要特点:
1. 有奇数条边 ; 2. 起点在二分图的X边,终点在二分图的Y边 ; 3. 路径上的点一定是一个在X边,一个在Y边,交错出现; 4. 整条路径上没有重复的点 ; 5. 起点和终点都是目前还没有配对的点,其他的点都已经出现在匹配 子图中 ;
6. 路径上的所有第奇数条边都是目前还没有进入目前的匹配子图的 边
,而所有第偶数条边都已经进入目前的匹配子图。奇数边比偶数边多一 条边 ;
7. 于是当我们把所有第奇数条边都加到匹配子图并把条偶数条边都删
除,匹配数增加了1。
我们可以通过不停地找增广路来增加匹配中的匹配边和
匹配点。找不到增广路时,达到最大匹配(这是增广路定理
)。匈牙利算法正是这么做的。
匈牙利算法主要思想
则用(yi)去标记X中结点x。
(2),(3)交替执行,直到下述情况之一出现为止 : (I)标记到一个Y中顶点y,它不是M顶点。这 时从y出发循标记回溯,直到(*)标记的X中 顶点x,我们求得一条增广路。设其长度为 2k+1,显然其中k条是匹配边,k+1条是非匹 配边。 (II)步骤(2)或(3)找不到可标记结点,而又不 是情况(I)。
(5)找到交替链(x4, y3)(由标记(x4),(*)回溯得), M = {(x2, y2), (x3, y1),(x1, y4), (x4, y3)}。
(6)找到交替链(x5, y4, x1, y1, x3, y7)因而得 M = {(x2, y2), (x4, y3),(x5, y4), (x1, y1), (x3, y 7)}
即: 初始化匹配子图为空 While 找得到增广路径 Do 把增广路径添加到匹配子图中
匈牙利算法步聚:
(1) 首先用(*)标记X中所有的非M顶点,然后 交替进行步骤(2),(3)。
(2) 选取一个刚标记(用(*)或在步骤(3)中用 (yi)标记)过的X中顶点,例如顶点xi,如 果xi与y为同一非匹配边的两端点,且在本 步骤中y尚未被标记过,则用(xi)去标记Y 中顶点y。重复步骤,直至寻找到Y或者或 者访问完所有与xi相关点。 (3) 选取一个刚标记(在步骤(2)中用(xi)标记) 过的Y中结点,例如yi,如果yi与x为同一匹 配边的两端点,且在本步骤中x尚未被标记过,
二分图及其应用
(Bipartite Graph & Applications)
主要内容:
什么是二分图? 二分图的各种匹配的定义?
如何利用匈牙利算法求最大匹配?
二分图的最小顶点覆盖 DAG图的最小路径覆盖 二分图的最大独立集
什么是二分图?
二分图又称作二部图,是图论中的一种特殊模型。 设 G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的 子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i 和j分别属于这两个不同的顶点集(i in A,j in B),则称图G 为一个二分图。
(4)当(2),(3)步骤中断于情况(I),则将增广 路中非匹配边改为匹配边,原匹配边改为 非匹配边(从而得到一个比原匹配多一条边 的新匹配),回到步骤(1),同时消除一切 现有标记。 (5)对一切可能,(2)和(3)步骤均中断于情况 (II),或步骤(1)无可标记结点,算法终止(算法 找不到交替链).
算法: 从二分图中找出一条路径来, 让路径的起点和终点都是还没有匹 配过的点,并且路径经过的连线是 一条没被匹配、一条已经匹配过交 替出现。 找到这样的路径后,显然路径 里没被匹配的连线比已经匹配了的 连线多一条,于是修改匹配图,把 路径里所有匹配过的连线去掉匹配 关系,把没有匹配的连线变成匹配 的,这样匹配数就比原来多1个。 不断执行上述操作,直到找不 到这样的路径为止。
A
B
什么是二分图?
二分图的一个等价定义:不含有(含奇数条边
的环)的图。图1是一个二分图。为了清晰,我们都 把它画成图2的形式。 无向图G为二分图的充分必要条件是,G至少有 两个顶点,且其所有回路的长度均为偶数
匹配
在图论中一个匹配是一个边的集合,其中任意 两条边都没有公共顶点。例如,图3中红色的边。