hadoop2.2.0分布式配置
使用Hadoop进行分布式数据处理的基本步骤

使用Hadoop进行分布式数据处理的基本步骤随着大数据时代的到来,数据处理变得越来越重要。
在处理海量数据时,传统的单机处理方式已经无法满足需求。
分布式数据处理技术应运而生,而Hadoop作为目前最流行的分布式数据处理框架之一,被广泛应用于各行各业。
本文将介绍使用Hadoop进行分布式数据处理的基本步骤。
1. 数据准备在使用Hadoop进行分布式数据处理之前,首先需要准备好要处理的数据。
这些数据可以是结构化的,也可以是半结构化或非结构化的。
数据可以来自各种来源,如数据库、文本文件、日志文件等。
在准备数据时,需要考虑数据的规模和格式,以便在后续的处理过程中能够顺利进行。
2. Hadoop环境搭建在开始使用Hadoop进行分布式数据处理之前,需要先搭建Hadoop的运行环境。
Hadoop是一个开源的分布式计算框架,可以在多台机器上进行并行计算。
在搭建Hadoop环境时,需要安装Hadoop的核心组件,如Hadoop Distributed File System(HDFS)和MapReduce。
同时,还需要配置Hadoop的相关参数,以适应实际的数据处理需求。
3. 数据上传在搭建好Hadoop环境后,需要将准备好的数据上传到Hadoop集群中。
可以使用Hadoop提供的命令行工具,如Hadoop命令行界面(Hadoop CLI)或Hadoop文件系统(Hadoop File System,HDFS),将数据上传到Hadoop集群的分布式文件系统中。
上传数据时,可以选择将数据分割成多个小文件,以便在后续的并行计算中更高效地处理。
4. 数据分析与处理一旦数据上传到Hadoop集群中,就可以开始进行数据分析与处理了。
Hadoop的核心组件MapReduce提供了一种分布式计算模型,可以将数据分成多个小任务,分配给集群中的不同节点进行并行计算。
在进行数据分析与处理时,可以根据实际需求编写MapReduce程序,定义数据的输入、输出和处理逻辑。
Hadoop应用开发与案例实战课后习题参考答案1-10章全书章节练习题答案题库

习题一、选择题1.下列有关 Hadoop 的说法正确的是( ABCD )。
A .Hadoop 最早起源于 NutchB .Hadoop 中HDFS 的理念来源于谷歌发表的分布式文件系统( GFS )的论文C .Hadoop 中 MapReduce 的思想来源于谷歌分布式计算框架 MapReduce 的论文D.Hadoop 是在分布式服务器集群上存储海量数据并运行分布式分析应用的一个开源的软件框架2.使用 Hadoop 的原因是( ABCD )。
A.方便:Hadoop 运行在由普通商用机器构成的大型集群上或者云计算服务上B.稳健:Hadoop 致力于在普通商用硬件上运行,其架构假设硬件会频繁失效,Hadoop 可以从容地处理大多数此类故障C .可扩展:Hadoop 通过增加集群节点,可以线性地扩展以处理更大的数据集D.简单:Hadoop 允许用户快速编写高效的并行代码3.Hadoop 的作者是( B )。
A .Martin FowlerB .Doug CuttingC .Kent BeckD .Grace Hopper4.以下关于大数据特点的描述中,不正确的是( ABC )。
A .巨大的数据量B .多结构化数据C .增长速度快D .价值密度高二、简答题1.Hadoop 是一个什么样的框架?答:Hadoop 是一款由Apache 基金会开辟的可靠的、可伸缩的分布式计算的开源软件。
它允许使用简单的编程模型在跨计算机集群中对大规模数据集进行分布式处理。
2.Hadoop 的核心组件有哪些?简单介绍每一个组件的作用。
答:核心组件有 HDFS 、MapReduce 、YARN 。
HDFS ( Hadoop Distributed File Sy,st doop 分布式文件系统)是 Hadoop 的核心组件之一,作为最底层的分布式存储服务而存在。
它是一个高度容错的系统,能检测和应对硬件故障,可在低成本的通用硬件上运行。
Hadoop2.0系统中的资源分配与动态监控实践

201数据库技术Database Technology电子技术与软件工程Electronic Technology & Software Engineering1 引言信息化社会中的信息爆炸引发了数据量的大幅增长。
传统数据处理器已经很难快速高效地在经济实用的条件下完成数据实时运算。
服务器联同协作成为大规模数据处理的发展方向。
在此背景之下,大数据运算平台应运而生,其中以Apache 基金会旗下的Hadoop 项目最为知名。
得益于其开源特性,Hadoop 被许多大学、研究所与商业公司广泛采用,在大数据领域已经成为广为接受的基准平台。
与此同时,为了方便使用者更简便快捷的在Hadoop 平台上实现分布式运算,许多分布式运算框架被研发与发行,其中Spark 以其突出的基于内存存取的高性能运算,自推出之时,便成为了学术界与工业界重要的关注与应用对象。
然而,大规模数据集所带来的问题并不止于数据量的大幅增长,数据结构的复杂性与差异性导致各个数据之间运算量差异亦十分明显。
直接的结果就是导致了Spark 工作集的多样化。
不同种类的Spark 工作,其生存周期与资源消耗各不相同。
当大量多种类Spark 工作同时出现在同一个Hadoop 平台上时,运算资源的不当分配极易导致大量微型工作被阻塞,等待资源,直至超时。
当数据量极大,例如运算峰值阶段的平台资源紧张时期,各个Spark 工作会因为资源争抢,导致相互阻塞,数据运算因为各个Spark 工作均无法取得足够资源而停顿,致使整个Hadoop 平台产生系统死锁,工作流停顿。
问题产生的根源是Spark 工作多样性与单一的资源分配规则之间的矛盾。
故而,在Hadoop 平台搭配Spark 框架支持大规模数据运算的实践中,Spark 工作集应该被系统化分类,采用不同的分配原则,避免数据流高峰时刻因资源争抢而导致的相互阻塞。
此外,Hadoop 平台资源高利用率阶段出现性能下降是正常的反应,与工作流完全阻塞相比,两者在短时间内会呈现相同现象,而长时间的人工观测在此情境下并不经济可取。
利用Hadoop实现分布式数据处理的步骤与方法

利用Hadoop实现分布式数据处理的步骤与方法随着数据量的急剧增长和计算任务的复杂化,传统的数据处理方法已经无法满足当今大数据时代的需求。
分布式数据处理技术由此应运而生,它能够将庞大的数据集分解为多个小块,然后在多个计算节点上并行处理,提高数据处理的效率和可靠性。
Hadoop作为目前最流行的分布式数据处理框架之一,具备高可靠性、高扩展性以及良好的容错性,并且能够在廉价的硬件上运行。
下面将介绍使用Hadoop实现分布式数据处理的步骤与方法。
1. 数据准备在开始之前,首先需要准备需要处理的数据集。
这些数据可以是结构化数据、半结构化数据或非结构化数据。
在准备数据时,需要考虑数据的格式、大小以及数据的来源。
可以从本地文件系统、HDFS、数据库或云存储等不同的数据源中获取数据。
确保数据的完整性和正确性非常重要。
2. Hadoop集群搭建接下来,需要搭建一个Hadoop集群来支持分布式数据处理。
Hadoop集群由一个主节点(Master)和多个从节点(Slaves)组成。
主节点负责任务调度、资源管理和数据分发,而从节点负责实际的数据处理任务。
搭建Hadoop集群的过程包括设置主节点和从节点的配置文件、创建HDFS文件系统以及配置各个节点的网络设置等。
可以采用Apache Hadoop的标准发行版或者使用商业发行版(如Cloudera或Hortonworks)来搭建Hadoop集群。
3. 数据分析与计算一旦完成Hadoop集群的搭建,就可以开始进行数据处理了。
Hadoop通过MapReduce模型来实现数据的并行处理。
Map阶段将输入数据分割为若干个小的数据块,并将每个数据块交给不同的计算节点进行处理。
Reduce阶段将Map阶段输出的结果进行合并和汇总。
为了实现数据的分析与计算,需要编写Map和Reduce函数。
Map函数负责将输入数据转换成键值对(Key-Value Pair),而Reduce函数负责对Map函数输出的键值对进行操作。
hadoop环境配置以及hadoop伪分布式安装实训目的

Hadoop环境配置以及Hadoop伪分布式安装是用于学习和实践大数据处理和分析的重要步骤。
下面将详细解释配置Hadoop环境以及安装Hadoop伪分布式的目的。
一、Hadoop环境配置配置Hadoop环境是为了在实际的硬件或虚拟机环境中搭建Hadoop集群,包括安装和配置Hadoop的各个组件,如HDFS(Hadoop分布式文件系统)、MapReduce(一种编程模型和运行环境)等。
这个过程涉及到网络设置、操作系统配置、软件安装和配置等步骤。
通过这个过程,用户可以了解Hadoop的基本架构和工作原理,为后续的学习和实践打下基础。
二、Hadoop伪分布式安装Hadoop伪分布式安装是一种模拟分布式环境的方法,它可以在一台或多台机器上模拟多个节点,从而在单机上测试Hadoop的各个组件。
通过这种方式,用户可以更好地理解Hadoop 如何在多台机器上协同工作,以及如何处理大规模数据。
安装Hadoop伪分布式的主要目的如下:1. 理解Hadoop的工作原理:通过在单机上模拟多个节点,用户可以更好地理解Hadoop如何在多台机器上处理数据,以及如何使用MapReduce模型进行数据处理。
2. 练习Hadoop编程:通过在单机上模拟多个节点,用户可以编写和测试Hadoop的MapReduce程序,并理解这些程序如何在单机上运行,从而更好地理解和学习Hadoop编程模型。
3. 开发和调试Hadoop应用程序:通过在单机上模拟分布式环境,用户可以在没有真实数据的情况下开发和调试Hadoop应用程序,从而提高开发和调试效率。
4. 为真实环境做准备:一旦熟悉了Hadoop的伪分布式环境,用户就可以逐渐将知识应用到真实环境中,例如添加更多的实际节点,并开始处理实际的大规模数据。
总的来说,学习和实践Hadoop环境配置以及Hadoop伪分布式安装,对于学习和实践大数据处理和分析具有重要意义。
它可以帮助用户更好地理解和学习Hadoop的工作原理和编程模型,为将来在实际环境中应用和优化Hadoop打下坚实的基础。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
简述hadoop伪分布式安装配置过程

Hadoop伪分布式安装配置过程在进行Hadoop伪分布式安装配置之前,首先需要确保系统环境符合安装要求。
Hadoop的安装需要在Linux系统下进行,并且需要安装好Java环境。
以下将详细介绍Hadoop伪分布式安装配置的步骤。
一、准备工作1. 确保系统为Linux系统,并且已经安装好Java环境。
2. 下载Hadoop安装包,并解压至指定目录。
二、配置Hadoop环境变量1. 打开.bashrc文件,添加以下内容:```bashexport HADOOP_HOME=/path/to/hadoopexport PATH=$PATH:$HADOOP_HOME/binexport HADOOP_CONF_DIR=/path/to/hadoop/etc/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOME```2. 执行以下命令使环境变量生效:```bashsource ~/.bashrc```三、配置Hadoop1. 编辑hadoop-env.sh文件,设置JAVA_HOME变量:```bashexport JAVA_HOME=/path/to/java```2. 编辑core-site.xml文件,添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```3. 编辑hdfs-site.xml文件,添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```4. 编辑mapred-site.xml.template文件,添加以下内容并保存为mapred-site.xml:```xml<configuration><property><name></name><value>yarn</value></property></configuration>```5. 编辑yarn-site.xml文件,添加以下内容:```xml<configuration><property><name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name> <value>localhost</value></property></configuration>```四、格式化HDFS执行以下命令格式化HDFS:```bashhdfs namenode -format```五、启动Hadoop1. 启动HDFS:```bashstart-dfs.sh```2. 启动YARN:```bashstart-yarn.sh```六、验证Hadoop安装通过浏览器访问xxx,确认Hadoop是否成功启动。
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册
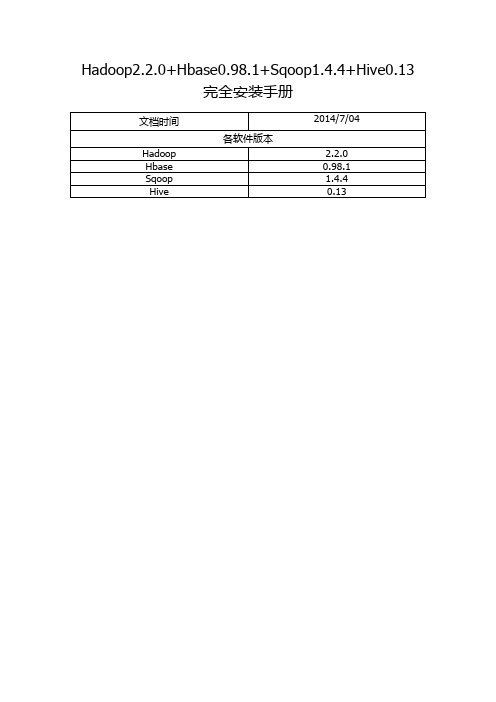
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop2.2.0分布式配置一、系统环境:IP 账号/主机名功能操作系统192.168.25.150 hadoop@hadoopm nm/rm/sm red hat enterprise linux 6.0 192.168.25.151 hadoop@hadoopd1 dn/rm red hat enterprise linux 6.0 192.168.25.152 hadoop@hadoopd2 dn/rm red hat enterprise linux 6.0二、设置HOST:vi /etc/hosts192.168.25.150 hadoopm192.168.25.151 hadoopd1192.168.25.152 hadoopd2注释掉localhost等配置:#127.0.0.1 localhost.localdomain localhost#::1 localhost6.localdomain6 localhost6设置好后,将此文件直接覆盖到其它主机对应的文件。
三、设置静态IP:查看ip:Ifconfig设置静态ip:vi /etc/sysconfig/networkNETWORKING=yesNETWORKING_IPV6=noHOSTNAME= hadoopm #主机名DEVICE=eth0 #网卡标志ONBOOT=yes #是否自动启动BOOTPROTO=static #是否使用静态IPIPADDR=192.168.25.150 #当前机器的IP地址NETMASK=255.255.255.0 #子网掩码GATEWAY=192.168.25.255 #网关也可以单独修改具体网卡的ip配置:vi /etc/sysconfig/network-scripts/ifcfg-ethoDEVICE=eth0 #网卡标志ONBOOT=yes #是否自动启动BOOTPROTO=static #是否使用静态IPIPADDR=192.168.25.150 #当前机器的IP地址NETMASK=255.255.255.0 #子网掩码GATEWAY=192.168.25.255 #网关使配置生效:/etc/init.d/network restart一台机器修改完毕后,其它机器按照此方式修改,注意要调整hostname和ip地址为正在被修改机器的对应信息。
四、JDK环境配置4.1将jdk-7u45-linux-i586.tar.gz拷贝到usr目录下并解压:tar -xzf jdk-7u45-linux-i586.tar.gz配置好后,采用如下命令直接复制到其它机器:scp -r /usr/jdk1.7.0_45 hadoop@192.168.25.151:/usrscp -r /usr/jdk1.7.0_45 hadoop@192.168.25.152:/usr4.2修改环境变量:vi /etc/profile在此文件的最后面加上如下配置(按键i):JAVA_HOME=/usr/jdk1.7.0_45JRE_HOME=/usr/jdk1.7.0_45/jrePATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JAVA_HOMEexport JRE_HOMEexport PATHexport CLASSPATH保存退出(按键esc然后:wq!保存退出或者:q!直接退出不保存),最后运行下面命令,使配置生效:source /etc/profile验证是否成功:java -version配置好后,其它机器也采用一样操作即可。
五、SSH无密码登陆cd /home/hadoop/.ssh #若此目录下没有.ssh目录,可以ssh hadoop@hadoopm下ssh-keygen -t rsacat id_rsa.pub >> authorized_keys启动生效:/etc/init.d/sshd restart按照以上步骤在其它机器上也类似操作。
最后执行完毕后,将三台机器上的此两个文件的三条记录分别合并,合并后,覆盖到三台机器的文件对应位置即可。
(分别将各台机子上的.ssh/id_rsa.pub的内容追加到其他两台的.ssh/authorized_keys) 六、关闭防火墙及SELinuxsetup修改SELinux也可以采用如下方法:vi /etc/selinux/configSELINUX=disable七、安装hadoop7.1将hadoop-2.2.0.tar.gz上传到/home/hadoop目录下cd /home/hadooptar -zxf hadoop-2.2.0.tar.gz7.2创建目录:mkdir dfsmkdir dfs/namemkdir dfs/datamkdir tempmkdir temp/dfsmkdir yarnmkdir yarn/app-logsmkdir yarn/log7.3修改配置文件:cd hadoop-2.2.0/etc/hadoop7.3.1修改core-site.xml:vi core-site.xml<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.defaultFS</name><value>hdfs://hadoopm:9000</value></property><property><name></name><value>hdfs://hadoopm:9000</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/home/hadoop/temp</value><description>Abase for other temporary directories.</description> </property><property><name>hadoop.proxyuser.hduser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hduser.groups</name><value>*</value></property></configuration>7.3.2修改hadoop-env.sh:vi hadoop-env.shexport JAVA_HOME=/usr/jdk1.7.0_457.3.3修改hdfs-site.xml:vi hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration><property><name>node.secondary.http-address</name><value>hadoopm:9001</value></property><property><name>.dir</name><value>file:/home/hadoop/dfs/name</value><description> </description></property><property><name>dfs.datanode.data.dir</name><value>file:/home/hadoop/dfs/data</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><!--property><name>dfs.datanode.du.reserved</name><value>1073741824</value></property><property><name>dfs.block.size</name><value>134217728</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.support.append</name><value>true</value></property><property><name>dfs.datanode.max.xcievers </name><value>4096</value></property--></configuration>7.3.4修改mapred-site.xml:vi mapred-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoopm:10020</value></property><property><name>mapred.job.tracker</name><value>hadoopm:54311</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoopm:19888</value></property></configuration>7.3.5修改slaves:vi slaveshadoopd1hadoopd27.3.6修改yarn-env.sh:yarn-env.shexport JAVA_HOME=/usr/jdk1.7.0_457.3.7修改yarn-site.xml:vi yarn-site.xml<?xml version="1.0"?><!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoopm:8031</value><description>host is the hostname of the resource manager andport is the port on which the NodeManagers contact the Resource Manager.</description></property><property><name>yarn.resourcemanager.scheduler.address</name><value>hadoopm:8030</value><description>host is the hostname of the resourcemanager and port is the porton which the Applications in the cluster talk to the Resource Manager.</description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.Cap acityScheduler</value><description>In case you do not want to use the defaultscheduler</description></property><property><name>yarn.resourcemanager.address</name><value>hadoopm:8032</value><description>the host is the hostname of the ResourceManager and the port is the port onwhich the clients can talk to the Resource Manager. </description> </property><property><name>yarn.resourcemanager.admin.address</name><value>hadoopm:8033</value></property><!--property><name>yarn.resourcemanager.webapp.address</name><value>hadoopm:8088</value></property><property><name>yarn.nodemanager.local-dirs</name><value>/home/hadoop/yarn/node</value><description>the local directories used by the nodemanager</description> </property><property><name>yarn.nodemanager.address</name><value>hadoopm:8994</value><description>the nodemanagers bind to this port</description> </property><property><name>yarn.nodemanager.resource.memory-mb</name><value>200</value><description>the amount of memory on the NodeManager in GB</description> </property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/home/hadoop/yarn/app-logs</value><description>directory on hdfs where the application logs are moved to </description></property><property><name>yarn.nodemanager.log-dirs</name><value>/home/hadoop/yarn/node</value><description>the directories used by Nodemanagers as logdirectories</description></property--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>shuffle service that needs to be set for Map Reduce to run </description></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>7.4拷贝配置文件到其它机器:scp -r /home/hadoop/hadoop-2.2.0 hadoop@192.168.25.151:/home/hadoopscp -r /home/hadoop/dfs hadoop@192.168.25.151:/home/hadoopscp -r /home/hadoop/temp hadoop@192.168.25.151:/home/hadoopscp -r /home/hadoop/yarn hadoop@192.168.25.151:/home/hadoopscp -r /home/hadoop/hadoop-2.2.0 hadoop@192.168.25.152:/home/hadoopscp -r /home/hadoop/dfs hadoop@192.168.25.152:/home/hadoopscp -r /home/hadoop/temp hadoop@192.168.25.152:/home/hadoopscp -r /home/hadoop/yarn hadoop@192.168.25.152:/home/hadoop7.5在hadoopm主服务器上执行hadoop格式化:cd /home/hadoop/hadoop-2.2.0./bin/hdfs namenode –format7.6运行hadoop:./sbin/start-all.sh7.7查看集群状态:./bin/hdfs dfsadmin –report查看文件块组成:./bin/hdfs fsck / -files -blocks查看HDFS:http://192.168.25.150:50070查看RM:http://192.168.25.150:80887.8运行示例程序:先在hdfs上创建一个文件夹./bin/hdfs dfs –mkdir /input./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar randomwriter input。