FameHistory实时数据库
FameView 数据库操作

24.数据库操作24.数据库操作数据库操作序号 内容 页码24.1 数据查询 24-0224.2 曲线查询 24-0524.3 表格显示 24-0824.4 字段列表 24-0924.5 删除数据表内容 24-1124.6 数据库脚本编程 24-1224.7 存储过程脚本编程 24-1324.8 数据库记录平均统计 24-1424.9 把数据库记录导出到Excel中 24-1524.10 使用ADO访问数据库 24-1624.11 数据库转发 24-1724.12 查询数据库某表中最近时间段数据 24-2124.13 获得某字段最近某时间段内统计值 24-2124.1数据查询提供了通过表格查看数据库内容的方法,用“数据查询”组件实现:增加组件对象,在设置对话框中添入数据库的有关信息,如下图所示:执行<数据源>按钮,通过出现的对话框来选择数据源(如FameView Userdata Source):执行<记录表>按钮,出现下面的对话框,其中列出数据源中所有数据表:从中选择要查询的记录集(如demo):此组件主要根据时间字段进行查询,执行<时间字段>按钮,出现下面的对话框,其中列出记录集中所有的字段,从中选择要使用的时间字段(如dt):如果希望把查询结果进行打印或浏览,要先根据数据库利用Crystal水晶星建立报表格式,执行<报表格式>按钮,选择报表格式文件(*.rpt);如果希望把查询结果进行特殊排序,在<排序字段>处添入排序字段的名称及排序方法;根据字段f3按照升序排列:根据字段f3按照降序排列:通过查询对象,可根据对某些字段的过滤实现分组查询:查询对象的格式如下[f为字段名称、n为数值、s为字符串]:数值查询 字符串查询预定义查询 Fn=n//描述 F1='s'//描述手动查询 F1=?//描述 F1='?'//描述手动查询时,会出现输入对话框,提示输入查询内容:用鼠标双击字段列表,会出现选择字段对话框,从中选择需要查询后显示的字段:不需要再选择时间字段,能自动的识别字段的类型,但要正确设定字段内容的字符长度;在查询显示表中,可能不希望直接显示字段的名称,请修改字段描述即可;用“Del”键可以从列表删除选错的字段;画面运行后,执行按钮查询,界面如下:如果不希望执行组件按钮来查询数据,而希望通过其他事件来执行,按照下列步骤来实现:(1)给按钮组件命名:选中组件,点击右键,弹出菜单,选择执行“对象属性”中的“脚本名称”,给对象命名,例如BTNOBJ;(2)隐藏按钮组件:选中组件,点击右键,弹出菜单,选择执行“隐藏对象”,使组件在运行画面显示时不可见:(3)编写脚本,然后被其他事件触发,例如在图标按钮中选择脚本执行,脚本内容如下:UserDbSQLObj.ShowWindow "BTNOBJ"24.2 曲线查询组态系统提供了通过曲线查看数据库内容的方法,用“曲线查询”组件实现;假设要查询的数据表的内容为;F1(罐号) F2(液位) dt(时间)1 10 2006-5-5 1:00:002 10 2006-5-5 1:00:001 100 2006-5-5 2:00:002 200 2006-5-5 2:00:001 110 2006-5-5 3:00:002 220 2006-5-5 3:00:00… … …增加组件对象,在设置对话框中添入数据库的有关信息,如下图所示:通过<数据源>按钮弹出对话框,选择ODBC数据源,如fameView userdata Source;通过<记录表>按钮弹出对话框,选择要查询的数据表,如demo;通过<时间字段>按钮弹出对话框,选择进行查询所依据的时间字段,如dt;在<查询对象>处输入查询内容:查询对象的格式如下[F1为字段名称、n为数值、s为字符串]:数值查询 字符串查询预定义查询 F1=n//描述 F1='s'//描述手动查询 F1=?//描述 F1='?'//描述通过<曲线字段>选择字段,作为曲线字段,并修改曲线的范围,输入曲线的描述;画面运行后,执行按钮查询,界面如下:如果不希望执行组件按钮来查询数据,而希望通过其他事件来执行,按照下列步骤来实现:(1)给按钮组件命名:选中组件,点击右键,弹出菜单,选择执行“对象属性”中的“脚本名称”,给对象命名,例如BTNOBJ;(2)隐藏按钮组件:选中组件,点击右键,弹出菜单,选择执行“隐藏对象”,使组件在运行画面显示时不可见:(3)编写脚本,然后被其他事件触发,例如在图标按钮中选择脚本执行,脚本内容如下:SQLCurveObj.ShowWindow "BTNOBJ"24.3 表格显示组态系统提供了在线显示数据库内容的方法,通过“表格显示”组件实现:此组件可以在画面上以列表的方式直接显示某个数据库的内容,还可以与变量相关联;组态对话框如下:通过<对象名称>为组件命名,否则不能进行脚本操作,如“DBLIST”;执行<数据源>按钮,选择数据库对应的数据源;执行<数据表>按钮,选择要显示的数据表,数据表中的字段数量要小于100:如果希望在列表中只显示数据表中的某部分数据,请<过滤条件>处填写缺省SQL语句,否则显示数据库中的所有记录;如果希望列表中的内容根据某字段进行排序,请输入此排序字段的名称,便实现了按此字段的升序排序,在字段的后面加入DESC,便实现了按此字段的降序排序;用鼠标双击字段列表,会出现选择字段对话框,从中选择需要查询后显示的字段;能自动的识别字段的类型,但要正确设定字段内容的字符长度;在查询显示表中,可能不希望直接显示字段的名称,请修改字段描述即可;用“Del”键可以从列表中删除字段;还提供了3组变量:增加变量、读取变量、修改变量;使系统变量(AI/AO/AR/DI/DO/DR/VA/VD /VT)与数据库之间建立联系;画面运行后,数据库列表界面如下:允许编写脚本操作数据库:要把增加变量组追加至数据库,请使用如下脚本:UserDbListObj.AddNewFromVarValue "DBLIST"要从数据库中读取第10个记录至读取变量组,请使用如下脚本:UserDbListObj.SetVarValueFromField "DBLIST",10要通过修改变量组修改数据库中的第10个记录,请使用如下脚本:UserDbListObj.EditFromVarValue "DBLIST",1024.4字段列表组态系统提供了在线选择数据库中某字段内容的方法,通过“字段列表”组件实现:此组件有以下功能:[1]通过下拉列表或选择框的方式供用户进行数据选择;[2]选择框内容可以数据库中的某个字段的内容,也可是手动输入的内容;[3]选择的内容能够与变量关联;组态对话框如下:缺省列表,手动输入多行文本(用回车换行),作为缺省列表内容;关联数据库,通过设定数据源、数据表、使用字段、过滤条件,能够在画面运行时,把数据库某表中的某字段的部分记录添入到选择框中;过滤条件的格式为SQL查询语句,例如:f2>1000、f2="ABC";对应变量,在画面运行后,当使用选择框选择数据时,能够把所选择的内容对应到变量中:[1].索引变量可以是AO/AR/VA变量,对应的是选择框中当前文本的索引号,以0为基数;[2].数值变量可以是AO/AR/VA变量,对应的是把选择框中当前文本转换为浮点数后的数值;[3].文本变量可以是VT变量, 对应的是选择框中的当前文本;选择<自动排序>,则列表中的内容进行排序处理;选择<下拉选择框>,并选择了<自动更新>时,当下拉列表框时,会自动更新列表中的内容;选择<唯一记录>,可以过滤掉列表中重复的内容;不选择<下拉选择框>,组件显示的界面为:选择<下拉选择框>,组件显示的界面为:允许用脚本更新选择框中的内容:更新数据选择框的内容DataboxObj.Update ObjName,OdbcName,TableName,FieldName,FieldType,Filter例:DataboxObj.Update "AAA","myODBC","myTable","myField",3,"f1>1000"得到当前数据选择框的文本内容n=DataboxObj.GetCurText(ObjName)例:n=DataboxObj.GetCurText("AAA")24.5 删除数据库内容某数据库中存储了大量数据,经过一段时间后,想把某个时间之前的数据删除;本节以例子的方式说明如何通过组态系统删除数据库中的某些数据;假设现有数据库,其ODBC数据源的名称为db1,其中有一个数据表名为T1,其中有一个日期时间字段为F1,根据F1来删除数据;增加2个文本变量(VT):VT1、VT2;在画面中各增加一个日期拾取器和时间拾取器,分别把内容保存在VT1和VT2中;再在画面中增加一个按钮,当执行按钮时,执行脚本来删除选择时间以前的数据;画面的界面如下:如果数据库的类型为Access,则脚本内容如下:'打开DB1,允许通过SQL访问SQLObj.OpenSQLConnect "DB1","",""'得到删除日期、时间s1=RunSys.GetVTtext("VT1",-1)s2=RunSys.GetVTtext("VT2",-1)'组成格式文本"Delete * From T1 Where F1<= #2002-1-1 0:0:0# "s="Delete * From T1 Where F1<= #" : s=s+s1 : s=s+" " : s=s+s2 : s=s+"#"'执行SQL语句,删除数据SQLObj.SQLExecute s'关闭DB1SQLObj.CloseSQLConnect如果数据库的类型为SQL Server,则脚本内容如下:'打开DB1,允许通过SQL访问SQLObj.OpenSQLConnect "DB1","",""'得到删除日期、时间s1=RunSys.GetVTtext("VT1",-1)s2=RunSys.GetVTtext("VT2",-1)'组成格式文本"Delete * From T1 Where F1<= ‘2002-1-1 0:0:0# ’s="Delete * From T1 Where F1<= '" : s=s+s1 : s=s+" " : s=s+s2 : s=s+"'"'执行SQL语句,删除数据SQLObj.SQLExecute sSQLObj.CloseSQLConnect往记录集中加入记录;UserDB.OpenConnect "My Database","",""UserDB.OpenRecordset "t1",2,2,2UserDB.AddNewUserDB.SetFieldValue "f1",7, "AAA"UserDB.SetFieldValue "f2",1,1000UserDB.UpdateUserDB.CloseRecordsetUserDB.CloseConnect得到数据库中字段的值;UserDB.OpenConnect "My Database","",""UserDB.OpenRecordset "t1",2,2,2UserDB.MoveFirstUserDB.Move(10)Value=UserDB.GetFieldValue "f2",1,1000UserDB.CloseRecordsetUserDB.CloseConnect执行SQL语句:SQLObj.OpenSQLConnect "TestDB","",""SQLObj.SQLExecute "DELETE FROM demo"SQLObj.CloseSQLConnect数据查询UserDB.OpenConnect "FameView UserData Source","",""UserDB.SetFilter "f1>=1000"UserDB.OpenRecordset "demo",2,2,2If UserDB.IsEmpty()=0 ThenretValue=UserDB.GetFieldValue("f2",4)End IfUserDB.CloseRecordsetUserDB.CloseConnect通过脚本编程可以执行数据库服务器端的存储过程;假设存储过程内容如下:CREATE PROCEDURE [test](@f1 [real], @f2 [real], @f3 [datetime], @f4 [real] output) AS INSERT INTO [UserDatabase].[dbo].[demo] ( [f1],[f2],[f3])VALUES ( @f1,@f2,@f3)if @@error=0set @f4=12.11elseset @f4=0.12GO过程调用如下:n=StoredProc.OpenConnect("FameView UserData Source","","")If n=1 ThenStoredProc.SetCommandText "test"StoredProc.SetInputParamCount 3StoredProc.SetInputParam 1,"f1",4,1.23StoredProc.SetInputParam 2,"f2",4,2.34StoredProc.SetInputParam 3,"f3",7,"2005-12-11 05:00:00"StoredProc.SetOutputParamCount 1StoredProc.SetOutputParam 1,"f4",4StoredProc.Executem=StoredProc.GetOutputValue(1)RunSys.SetVarValue VA,"%VA1",-1,mStoredProc.CloseConnectEnd If24.8 数据库记录平均统计把某个表中某天的数据求平均,存入另一个表中假设t1和t2有相同的结构,分别有3个字段:字段名称 类型F1 RealF2 RealF3 Datetime针对t1中近30天的数据,把每天的数据求平均,存入t2中,并删除t1中的数据;在SQL Server中编写存储过程test如下:CREATE PROCEDURE [test]asDeclare @n intDeclare @ct datetimeset @n=-30while @n<0beginset @ct=DATEADD(DAY,@n, GETDATE())INSERT INTO t1SELECT AVG(f1) AS f11, AVG(f2) AS F12, @ct AS F13FROM demoWHERE (YEAR(f3) = YEAR(@ct) AND (Month(f3) = MONTH(@ct) AND (Day(f3) = DAY(@ct)set @n=@n+1enddelete from demoGO在组态软件中调用过程的脚本如下:n=StoredProc.OpenConnect("FameView UserData Source","","")If n=1 ThenStoredProc.SetCommandText "test"StoredProc.ExecuteStoredProc.CloseConnectEnd If24.9 把数据库数据导出到把数据库数据导出到Excel Excel Excel中中'允许输入查询的年/月MyYear = InputBox ("请输入查询年份","") MyMonth = InputBox ("请输入查询月份","") MyDay = 1'检查时间是否合法If IsDate (MyMonth & "/" & MyDay & "/" & MyYear) = True Then NOW_DATE = MyYear + "年" + MyMonth + "月" '得到开始时间StartTime = MyMonth & "/" & MyDay & "/" & MyYear & " 00:00:00" '得到结束时间 If MyMonth < 12 Then MyMonth = MyMonth + 1EndTime = MyMonth & "/" & MyDay & "/" & MyYear & " 00:00:00" ElseMyYear = MyYear + 1 MyMonth = 1EndTime = MyMonth & "/" & MyDay & "/" & MyYear & " 00:00:00" End If'打开数据库及数据表demo,dt为时间字段UserDB .OpenConnect "FameView UserData Source","","" UserDB .SetFilter "dt>='"+StartTime+"' And dt<'"+EndTime+"'" UserDB .OpenRecordset "demo",2,2,2 '打开记录集;'检查查询内容是否为空 If UserDB .IsEmpty ()=0 Then '打开Excel文件Set ExcelObj = CreateObject ("Excel.Application") ExcelObj.Visible = TrueExcelFile = "C:\组态系统\ExcelFile\test.xls" ExcelObj.Workbooks.Open ExcelFile ExcelObj.Sheets("Sheet1").Select ExcelObj.Worksheets(1).Select ExcelObj.Cells(1,3) = NOW_DATE '导出记录到Excel中 row=2While UserDB .IsEOF ()=0ExcelObj.Cells(row,1).Value=UserDB .GetFieldValue ("dt",8)ExcelObj.Cells(row,2).Value=UserDB.GetFieldValue("f1",4)ExcelObj.Cells(row,3).Value=UserDB.GetFieldValue("f2",4)row=row+1UserDB.MoveNextWendExcelObj.ActiveWorkbook.SaveAs "C:\组态系统\ExcelFile\"&NOW_DATE&".xls" ExcelObj.QuitSet ExcelObj=NothingEnd If'关闭数据库UserDB.CloseRecordsetUserDB.CloseConnectEnd If数据库24.10 使用ADO访问访问数据库'与数据库(tempdb)建立连接Set conn = CreateObject("ADODB.Connection")strConn="Driver={SQL Server};Server=(local);Database=tempdb;Uid=sa;Pwd=;" conn.Open strConn'打开记录集(t1)Set rs= CreateObject("ADODB.Recordset")strSQL="SELECT * FROM t1"rs.Open strSQL,conn,2,2'添加记录rs.AddNewrs("f1")="222"rs("f2")=222rs.Update'得到记录f1=rs("f1")f2=rs("f2")'关闭连接与记录集rs.Closeconn.CloseSet rs=NothingSet conn=Nothing24.11数据库转发目的和功能:本地计算机(A)和远程计算机(B)同时工作,当A发现B不工作时,A则开始存储数据,或者带标志存储数据;当A发现B恢复工作后,则把存储的数据或带标志的数据补发给B;A补发完成后,把数据进行删除或清除标志;远程计算机(B)的数据库(SQL Server 2000)设置:允许其他计算机访问:设置访问用户ID和口令:设置远程计算机(B),使远程计算机具有启动/工作标志:在本地计算机(A)建立远程计算机工作标志变量:假设远程计算机的IP地址为<192.168.1.208>;增加一个名称为“#IP192.168.1.208”的内部开关变量(VD);远程计算机启动并开始工作后,变量状态为1,否则为0;定制和启动本地计算机的数据库补发功能:定制数据库补发:启动数据库补发任务:使本地计算机的数据库连接,根据远程计算机的状态决定是否存储:使本地计算机的数据库连接,把远程计算机的状态作为标志进行存储:在本地计算机设置数据库补发功能:选择数据库补发功能,执行设置数据补发:出现管理界面:执行<新建>:输入补发名称,执行确定,出现设置界面,组态后的界面如下:选择要使用的转发:24.12查询数据库某表中最近时间段数据查询最近3分钟数据:Select * from demo where dt>DateAdd(MINUTE,-3,GetDate()) 查询最近3小时数据:Select * from demo where dt>DateAdd(HOUR,-3,GetDate()) 查询最近3天数据:Select * from demo where dt>DateAdd(DAY,-3,GetDate())24.13 获得某字段最近某时间段内统计值'[1]得到分钟时间段x=0bValue=RunSys.OpenDatabase(3000)If bValue=1 Thenx=RunSys.GetVarValue(VA,"%VA1",-1)RunSys.CloseDatabaseEnd If'[2]打开数据库Set conn = CreateObject("ADODB.Connection")strConn="Driver={SQL Server};Server=(local);Database=UserDatabase;Uid=;Pwd=;"conn.Open strConnSet rs= CreateObject("ADODB.Recordset")'[3]进行统计查询strSQL="SELECT Avg(f1) as f11 FROM demo where dt>=DateAdd(Minute,-"&CStr(x)&",GetDate())"rs.Open strSQL,conn,2,2If rs.EOF=False Or rs.BOF=False Thenx=rs("f11")End If'[4]关闭数据库rs.Closeconn.CloseSet rs=NothingSet conn=Nothing'[5]取得统计值bValue=RunSys.OpenDatabase(3000)If bValue=1 ThenRunSys.SetVarValue VA,"%VA2",-1,xRunSys.CloseDatabaseEnd If。
盘点市面上主流的时序数据库

盘点市⾯上主流的时序数据库万物互联时代,⼯业物联⽹产⽣的数据量⽐传统的信息化要多数千倍甚⾄数万倍,并且是实时采集、⾼频度、⾼密度,动态数据模型随时可变。
传统数据库在对这些数据进⾏存储、查询、分析等处理操作时捉襟见肘,迫切需要⼀种专门针对时序数据来做优化的数据库系统,即时间序列数据库。
时间序列数据库(Time Series Database)是⽤于存储和管理时间序列数据的专业化数据库,具备写多读少、冷热分明、⾼并发写⼊、⽆事务要求、海量数据持续写⼊等特点,可以基于时间区间聚合分析和⾼效检索,⼴泛应⽤在物联⽹、经济⾦融、环境监控、⼯业制造、农业⽣产、硬件和软件系统监控等场景。
▲DB-Engines最新发布的时序数据库排名表根据国际知名⽹站DB-Engines数据,时序数据库在过去24个⽉内排名⾼居榜⾸,且远⾼于其他类型的数据库,可见业内对时序数据库的需求迫切。
相应的时序数据库产品近年来也快速发展,各⼤互联⽹企业包括⾕歌、阿⾥巴巴、亚马逊都推出⾃⼰的时序数据库,业界使⽤较多的时序数据库主要有如下⼏种:1、InfluxDBInfluxDB是⼀款⽤Go语⾔编写的开源分布式时序、事件和指标数据库,⽆需外部依赖。
该数据库现在主要⽤于存储涉及⼤量的时间戳数据,如DevOps监控数据,APP metrics,loT传感器数据和实时分析数据。
作为⽬前开源排名最⾼的时序数据库,InfluxDB⽀持数据存储策略(RP)和数据归档(CQ),能够实时查询,数据在写⼊时被索引后就能够被⽴即查出,内置HTTP接⼝,安装管理很简单,并且读写数据⾮常⾼效。
2、Kdb+kdb+/q被官⽅称为世界上最快的时间序列数据库,它使⽤统⼀的数据库处理实时数据和历史数据,同时具备CEP(复杂事件处理)引擎、内存数据库、磁盘数据库等功能。
列式存储的特性,使得对于某个列的统计分析操作异常⽅便。
与⼀般数据库或⼤数据平台相⽐,kdb+/q具有更快的速度和更低的总拥有成本,⾮常适合海量数据处理,主要被⽤于海量数据分析、⾼频交易、⼈⼯智能、物联⽹等领域。
力控科技企业级实时历史数据库pSpace V6.0

力控科技企业级实时历史数据库pSpace V6.0对于现代工业企业,如何能使决策者随时查看生产过程数据,以便快速地做出更为灵活的商业决策,是企业信息化建设的关键,企业生产调度管理系统的核心是实时历史数据库,实时历史数据库可用于工厂过程的自动采集、存储和监视,可在线存储每个工艺过程点的多年数据,它提供了清晰、精确的操作情况画面,可以提供批次管理、设备运行管理、工艺曲线、事故诊断等多种调度管理模块,可以说,实时历史数据库对于流程工厂来说就如同飞机上的“黑匣子”,是数字化工厂的关键!力控企业级实时历史数据库pSpace V6.0是一个高性能、高速度、高吞吐能力、可靠性强、跨网络系统的开放式实时数据库系统,产品为完全的分布式结构,可任意组建应用模式;支持C/S和B/S应用;它可以提供丰富的企业级信息系统客户端应用和工具;大容量支持企业级应用,内部实现高数据压缩率,可实现历史数据的海量存储,灵活的扩展结构可满足各种需求,具备广泛的安全性和可跟踪性。
力控pSpace V6.0以优越的性能、先进的架构、开放的接口、及时的服务让企业轻松自如地存储、管理及应用生产过程数据,是您构建企业管控一体化系统、生产调度指挥系统、MES系统、ERP系统等应用系统的基石,它具备以下特点:●强大的I/O能力:写入30万点/秒;读取25万点/秒。
●丰富的设备采集接口:支持主流DCS、PLC、DDC、现场总线、智能仪表等近1000多家设备采集接口,每月增加30个设备采集接口。
●跨平台,多平台支持能力:Windows、Unix、Linux任您选择。
●先进高效的二次压缩技术:一次逻辑压缩,二次物理压缩,数据压缩率高达40:1。
●多级冗余机制:支持多服务器、双接口机、双网、双通道等多种冗余技术。
●开放而丰富的应用接口:DBI API、COM SDK、OLE DB Provider、DAI SDK、OPC、ODBC、REAL-SQL,为您提供灵活可选的二次开发功能。
GE实时数据库简介

• Built-in Data Collection • Fast Read/Write Performance Speeds • High Data Compression • Quick Time to Value • Enhanced Data Security • Robust Redundancy for High Availability • Open & Layered Integration
Proficy Historian includes built-in data collection capabilities and can pture data from multiple sensors and systems. It uses manufacturing standards such as Object Linking and Embedding for Process Control (OPC), which facilitates communications by providing a consistent method of accessing data across devices.
- Fault tolerant architecture - Support for Microsoft Cluster Server - Redundant data collectors - Enhanced data security
• Advanced Data Management
FAME数据库备份指南
FAME 数据库备份指南
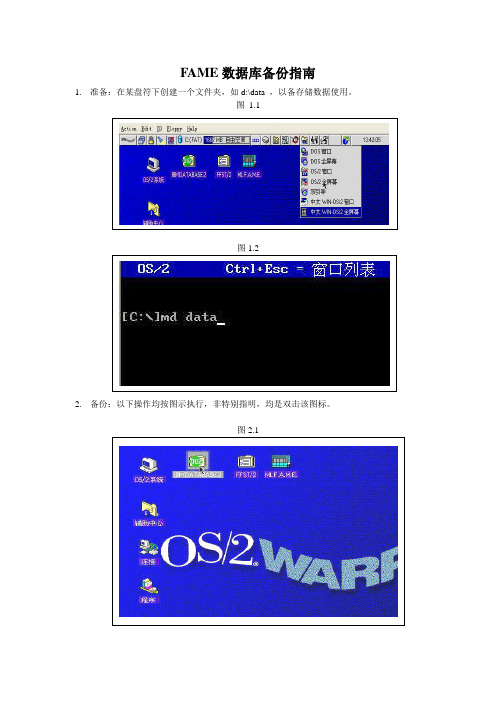
1. 准备:在某盘符下创建一个文件夹,如d:\data ,以备存储数据使用。
图 1.1
图1.2
2. 备份:以下操作均按图示执行,非特别指明,均是双击该图标。
图2.1
图2.3
图2.6
图2.7
在directory 内输入准备时所做的文件夹及其路径,点击apply ,点击ok
3.注册:有时候软件需要您注册,Username:VDB
Passtword:VENUS
4.退出:备份完成后,点击cancel,然后是一路后退,见了yes不点No即可。
5.查实:双击图2.2中的Recovery Job 查看是否成功备份。
6.数据恢复:类同备份过程,在图2.6中选择Back Up……即可,类似在图2.7中的步骤,
注意:在年月日栏内输入“自动生成的文件夹的数字(此文件夹名称自动按备份时的日期和时间生成)”,时间栏输入“文件夹中的文件名称(数字式)”,注意提示格式。
谢谢,澳斯邦工程师王金德
2005-06-21。
美国ICONICS公司实时历史数据库Hyper-Historian简介

ICONICS Overview Presentation
© 2012 ICONICS, Inc
22
支持:选择, 插入, 更新
参数化支持
支持高级数据查询
Time-in-State Time-Weighted Average Best Fit, Integral, Slope, Counter 日期-时间功能
系统配置& 管理
• 手动输入数据 • 操作员信息录入
自动备份 外部存储
标准SQL 查询
实时数据记录
OPC-UA
历史数据存储
磁盘
MergeWorX 数据集成
事件
实时数据
内存 性能运算引擎
存储 & 转发
数据采集器
• OPC DA • OPC UA • OPC XML DA
...
• SNMP • BACnet • Databases
ICONICS Overview Presentation
© 2012 ICONICS, Inc
21
曲线图
•Line •Time Spline •Step Time •XY Plot
环形图
区域图
•Time Area
•Time Spline Area
•Time Step Area
饼图
柱状图
•Bar •Histogram
© 2012 ICONICS, Inc
6
BizViz 客户端
• 生产效率分析 • 企业系统桥接 •报告& 门户
AnalytiX 客户端
• Energy AnalytiX • Facility AnalytiX • 移动 & 无线
第三方解决方案
003-力控企业级实时历史数据库pSpace产品介绍

企业级实时历史数据库
pSpace应用组件
u关系库转储 SQLRouter用于pSpace Server和关系数据库建的数据交互,转储方式灵活, 支持多种表结构,同时提供数据统计转储、在线配置、二次开发接口等高级功能。 u关系库扩展 psSQL为关系库扩展组件,基于标准关系库进行了二次开发,与pSpaceServer 高效交互,提供基于SQL92标准的JDBC和ODBC接口,通过第三方抽取工具即可 实现数据集成。 uOPC数据转发 OPCServer是一个符合OPC 2.0的标准OPC数据服务器,为用户提供完整的工 业访问接口。
曲线、报表、菜单 可视化插件 图形库 参考行业软件设计标 多媒体技术 准 GDI、GDpace可视化界面
企业级实时历史数据库
pSpace可视化界面
upsView 后台脚本支持 面向对象设计的脚本编译环境, “所见即所得”,方便引用方法 和变量; 类“Basic”的语言环境,提供面 向对象编程方式; 脚本类型和触发方式多样,支持 条件动作、数据变化动作、窗口 动作、循环动作等; 脚本支持多种结构,支持数组运 算和FOR循环结构。
企业级实时历史数据库
pSpace可视化界面
upsView 组态开发 提供方便友好的开发环境及面向对象的设计,工程人员可根据这些工 具来搭建自己的监控系统。 数据源级联 工程导入与导出 查找与替换 窗口复制、文件夹管理 文件管理 贝塞尔曲线 多种图元绘图 对象克隆、镜像 标准Windows控件 日期框、下拉框、复选框 鼠标动作、垂直水平填充等 动画连接 智能对象封装 this&parent嵌套 自定义属性方法 画面分层 255图层选择
企业级实时历史数据库
pSpace核心服务器软件
企业级实时历史数据库
historian数据库概念 -回复

historian数据库概念-回复什么是historian数据库概念?Historian数据库是一种专门用于存储和管理历史数据的数据库。
历史数据通常是指过去某个时间段内发生的事件、过程或状态的记录。
在许多行业中,历史数据对于分析和预测具有重要意义。
historian数据库提供了一种有效的方式来存储、查询和分析历史数据,帮助用户更好地了解过去的情况,以便做出更明智的决策。
historian数据库的特点1. 高性能存储:historian数据库使用高效的存储引擎,可以快速写入和读取大量的历史数据。
它可以处理高速数据流,并能够在短时间内保存大量数据。
2. 数据压缩和归档:历史数据通常占用大量的存储空间,因此,historian数据库采用数据压缩和归档技术来减小数据的存储空间。
这样可以节省存储成本,并提高数据访问的效率。
3. 时间序列数据:historian数据库通过时间戳来标记每个数据,以便按时间进行查询和分析。
这对于回溯过去的数据和进行趋势分析非常重要。
4. 数据聚合和挖掘:historian数据库提供了各种聚合和挖掘历史数据的功能,比如统计、计算、分析和预测。
这些功能可以帮助用户更好地理解历史数据,并从中发现有用的信息。
5. 数据保护和复原:historian数据库具有数据保护和复原的特性,以确保数据的完整性和可用性。
它可以防止数据的意外删除或损坏,并提供备份和恢复功能。
historian数据库的应用领域1. 工业自动化:historian数据库广泛应用于工业自动化领域,用于记录生产过程中的各种参数和指标。
通过分析这些历史数据,可以改进生产效率和质量,并提高故障诊断能力。
2. 能源管理:historian数据库可用于监测和优化能源使用情况。
通过对历史数据的分析,可以发现能源浪费的问题,并采取相应的措施来减少能源消耗。
3. 交通监控:通过记录交通流量、车辆速度和道路状况等历史数据,可以为交通监控和规划提供重要参考。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HDTime nStartTime; nStartTime.nSec=1358611200; nStartTime. nMsec=0;
毫秒
距1970-1-1 8:0:0秒数 (2013-1-20 0:0:0)
FameHistory实时数据库
得到某标签某段时间段内的原始记录:
COleDateTime initTime(1970,1,1,8,0,0); COleDateTime startTime(2012,1,1,0,0,0); COleDateTime endTime(2012,2,1,0,0,0); COleDateTimeSpan timeSpan1 = startTime-initTime; COleDateTimeSpan timeSpan2 = endTime-initTime; HDTime nStartTime,nEndTime; nStartTime.nSec=timeSpan1.GetTotalSeconds(); nEndTime.nSec=timeSpan2.GetTotalSeconds(); HDRecord pRecords[50000]; UINT nRecNumCount=50000;
计算公式: (20×5×10000)点 ÷ 200000点/秒=5秒
FameHistory实时数据库
客户端工具
启动或停止服务 查看标签记录值 启动管理工具
FameHistory实时数据库
访问权限
权限 用户 信任
FameHistory实时数据库
实时数据库.历史数据
运行 数据库
SQL Server 数据库
实时数据库 开始时间 StartTime 时间长度 TimeLength Excel报表
实时数据库.Excel报表
Excel文件
打印 浏览 另存
间隔时间 Interval
配置&格式文件 ExcelFile 报表方式 ReportMode 最大: 1024标签 60000条记录
FameHistory实时数据库
每客户端允许32个并发实时数据库连接; 每个连接允许定义60000个标签; 建议单独建立连接,定义注册计算标签和统计标签; 支持Excel编辑;
FameHistory实时数据库
数据采集.计算最小采集频率
计算依据 实时数据库吞吐量=20万点/秒
实施规模: 20个客户端, 每客户端5个连接,每连接1万个标签
感谢支持!
组态软件及资料下载:
有问题吗?
愿意回答您任何问题
switch(pRecords.nTagType){ case 0: byteValue = pRecords.value.nInt8;break case 1: intValue = pRecords.value.nInt16;break; case 2: longValue = pRecords.value.nInt32;break; case 3: fltValue = pRecords.value.nfloat32;break; case 4: dblValue = pRecords.value.nfloat64;break; }
实时数据库 表格查询
实时数据库.表格查询
配置文件 CfgFile
最大: 1000标签 60000条记录
FameHistory实时数据库
实时数据库脚本
FameHistory实时数据库
开发流程: 连接服务器 登陆服务器 得到某标签标识 设置时间段 查询时间段内的原始记录或插值记录 分析记录内容:时间和数值 断开服务器连接
假设10000个标签; 每分钟存储1次 无压缩,存储3年
估算: 10000 ×(60 × 24) ×(365 × 3) ÷ 100000
约占用160G硬盘空间
目前单个硬盘最大3TB; 服务器可以并联多个硬盘; NTFS分区最大256TB;
FameHistory实时数据库
支持定制安装; 必须须安装服务器和客户端选项; 数据存储目录缺省位于安装目录下,也可定位于其他目录下; 缺省TCP端口5678,除非必要不要修改; 合理并正确设置:内存缓冲区、文件大小、文件个数; 正式运行时,须安装为服务运行方式; 演示版本或测试阶段,可不安装为服务运行方式,而用手动方式启动;
FameHistory实时数据库
并发连接:32个 每连接:6万个变量
运行 数据库 实时数据库 连接 TCP连接方式 缺省端口:5678 实时数据库 服务+数据
Tag 1 Tag 2 Tag 3 …… Tag1000000 …… Tag5000000
结构图
周期|变化触发
应用程序 (分析、检索)
存档曲线查询 Excel报表 关系数据库
访问接口(API)
主要任务: - 查询某标签某时间段的记录
FameHistory实时数据库
连接及登录实时数据库: HDHANDLE hServer=NULL; int32 nRealdbRet=nt_connect(" 192.168.1.10 ",5678,&hServer,6); if(nRealdbRet==0){ nRealdbRet=sc_login(hServer, " admin", “admin"); } …… nt_disconnect(hServer);
FameHistory实时数据库
稳定、实时、并发、海量、高速
数据库(Database)
数据库分类
关系型数据库
关系数据库,典型存储模式:
不适应海量快速存储
关系:处理永久稳定的数据(保证数据完整性、一致性); 横表存储,适合报表分析; 提供索引,实现快速查询; 因为索引,导致大批量数据存储缓慢; 单客户连接,不支持并发存储; 数据无压缩,占用大量硬盘空间; 经验数据: 数据库连接, 800条/秒 1万点DOC历史数据库, 5000条/分钟 假设有100000个变量, 需要每秒存储1次! 可能吗?!
开始安装
32位系统:512M 64位系统:1024M 32位系统:1280M 64位系统:2560M
根据估算所占用硬盘空间 N=M÷M1
FameHistory实时数据库
移植&备份
FameHistory实时数据库
存储方式
(.\Data子目录)
FameHistory实时ቤተ መጻሕፍቲ ባይዱ据库
标签概念
实时数据库 计算 标签 运 行 数 据 库 后台 计算
FameHistory实时数据库
计算标签
计算标签
普通标签
计算公式
‘TAG1’*10
计算周期
FameHistory实时数据库
数据采集.实时数据库连接
实时数据库
普通标签 统计标签 计算标签 册 普通 标签 存 储 统计 标签 后台 统计 计算 标签 后台 计算
运 行 数 据 库
变量名称
注
变量数值
普通标签 定时触发 变化触发 激活条件
访问接口(API)
FameHistory实时数据库
得到标签标识(TagId):
访问接口(API)
UINT nTagId=0; int32 nRet=pt_query_tagid(hServer, " TAG1",&nTagId);
FameHistory实时数据库
实时数据库时间表示方式:
访问接口(API)
FameHistory实时数据库
存储模式:
能够实现海量快速存储
实时,处理实时变化数据,保证数据实时性、真实性; 竖表存储,适合单变量快速查询(变量曲线); ID号索引,能快速存储; 支持并发,能实现大批量数据存储; 无损、有损和二级压缩,普通硬盘能存储几年数据 不易报表分析查询; 单机测试数据: 普通计算机,2G内存,Windows XP(SP3) 1个单独连接:60000个标签/秒 4个并发连接:240000个标签/秒
访问接口(API)
UINT nRet= ar_query_raw_records(hServer,tagId, &nStartTime,&nEndTime, &nRecordCount,pRecords);
FameHistory实时数据库
得到某标签某段时间段内的插值记录:
COleDateTime initTime(1970,1,1,8,0,0); COleDateTime startTime(2012,1,1,0,0,0); COleDateTime endTime(2012,2,1,0,0,0); long Interval=60; COleDateTimeSpan timeSpan1 = startTime-initTime; COleDateTimeSpan timeSpan2 = endTime-initTime; HDTime nStartTime,nEndTime; nStartTime. nSec=timeSpan1.GetTotalSeconds(); nEndTime. nSec=timeSpan2.GetTotalSeconds(); HDRecord pRecords[50000]; UINT nRecNumCount=0; HDRecord pErrorCodes[50000]; for(UINT i=nStartTime;i<50000;i++){ pRecords[i].nSec=nStartTime.nSec+Interval*i; if(pRecords[i].nSec>nEndTime.nSec) break; nRecNumCount++; }
客户数(Cnts)
USB加密狗