语料库整理要求及方法
语料的采集与整理

一般小说
L Fiction: Mystery
侦探小说
M Fiction: Science
科幻小说
N Fiction: Adventure
历险小说
P Fiction: Romance
爱情小说
R Humor
幽默
No. of texts
44 27 17 17 36 48 75 30
80 29 24 6 29 29 9
随机取样
科学取样
Population
Sample
Random sampling
系统抽样
科学取样
Systematic sampling
科学取样
分层抽样
Population
Sample
30-49
18-29
65+ 50-64
Proportional allocation
Even allocation
语料的整理
整理的目的
我们喜欢CORPUS LINGUI STICS.
语料的整理
语料整理的几个主要方面:
段落相关(回车符等)问题; 空格相关问题; 字符相关问题。
谢谢
结束语
谢谢大家聆听!!!
15
宗教
E Skill and hobbies
技术、商贸
F Popular lore
通俗社会生活
G Belles-lettres
传记和杂文
H Miscellaneous: Government & 其他:报告及公
house organs
文等
J Learned
学术、科技
K Fiction: General
语料的采集与整理
词典编纂的语料库方法

词典编纂的语料库方法
词典编纂的语料库方法是指利用语料库来为建立、修订或扩充词典提供证据和信息的方法。
主要包括四个步骤: (1) 语料整理:先统计语料中的单词出现的频率,以及不同语料中单词的出现情况; (2) 选择词汇:根据语料库中的统计结果,选择满足一定频率和出现范围的单词作为词汇; (3) 检查词汇:检查选择出来的词汇,看有没有重复的或是有歧义的,如果有,就将其删除; (4) 写入词典:将检查过后的词汇写入词典中,并根据语料库中的统计结果加以补充。
语料库管理与维护的注意事项

语料库管理与维护的注意事项
语料库管理与维护是确保机器学习和自然语言处理模型有效和高效运行的关键环节。
以下是一些注意事项,可供参考:
1.数据质量:确保语料库的数据质量是非常重要的。
数据应该准确、完整且有代表性。
定期进行数据清洗和验证,排除错误和冗余的数据。
2.数据安全和隐私:对于涉及个人信息的语料库,需要严格遵守数据隐私法规和道德准则。
确保数据的存储和处理过程中的安全性和保密性。
3.版权和许可:确保所使用的语料库符合版权和许可规定。
获取数据时,需要遵循合法的渠道和规定,避免侵权行为。
4.维护和更新:语料库需要定期进行维护和更新。
删除过时或不再可靠的数据,添加新的数据以保持语料库的时效性和准确性。
5.多样性和代表性:确保语料库具有多样性和代表性,涵盖不同领域、话题和语言风格,以提高模型的泛化能力。
6.文档化和标注:对于语料库的使用和维护,建议编写文档记录重要信息,如数据来源、处理流程、标注方法等,以便于日后追溯和共享。
7.特殊处理:在处理特定领域或特定任务的语料库时,可能需要进行额外的处理和清洗,以适应所需的模型训练或应用。
8.数据备份:定期进行数据备份,确保数据的安全和可靠性。
避免数据丢失或损坏导致的影响。
9.数据共享和合作:如果允许,可以考虑与其他研究者或组织合作,共享语料库,促进数据资源的互相利用和提高。
总之,语料库管理与维护是一个细致而复杂的过程,需要关注数据质量、安全性、版权许可、维护更新和多样性等方面。
遵循合法合规的原则,保证数据的准确性和有效性,将有助于提高机器学习和自然语言处理模型的性能和应用效果。
现代汉语语料库加工规范

现代汉语语料库加工规范——词语切分与词性标注1999年3月版北京大学计算语言学研究所1999年3月14日⒈ 前言北大计算语言学研究所从1992年开始进行汉语语料库的多级加工研究。
第一步是对原始语料进行切分和词性标注。
1994年制订了《现代汉语文本切分与词性标注规范V1.0》。
几年来已完成了约60万字语料的切分与标注,并在短语自动识别、树库构建等方向上进行了探索。
在积累了长期的实践经验之后,最近又进行了《人民日报》语料加工的实验。
为了保证大规模语料加工这一项重要的语言工程的顺利进行,北大计算语言学研究所于1998年10月制订了《现代汉语文本切分与词性标注规范V2.0》(征求意见稿)。
因这次加工的任务超出词语切分与词性标注的范围,故将新版的规范改名为《现代汉语语料库加工规范》。
制订《现代汉语语料库加工规范》的基本思路如下:⑴ ⑴ 词语的切分规范尽可能同中国国家标准GB13715“信息处理用现代汉语分词规范” (以下简称为“分词规范”)保持一致。
由于现在词语切分与词性标注是结合起来进行的,而且又有了一部《现代汉语语法信息词典》(以下有时简称“语法信息词典”或“语法词典”)可作为词语切分与词性标注的基本参照,这就有必要对“分词规范”作必要的调整和补充。
⑵ ⑵ 小标记集。
词性标注除了使用《现代汉语语法信息词典》中的26个词类标记(名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w)外,增加了以下3类标记:①专有名词的分类标记,即人名nr,地名ns,团体机关单位名称nt,其他专有名词nz;②语素的子类标记,即名语素Ng,动语素Vg,形容语素Ag,时语素Tg,副语素Dg等;③动词和形容词的子类标记,即名动词vn(具有名词特性的动词),名形词an(具有名词特性的形容词),副动词vd(具有副词特性的动词),副形词ad(具有副词特性的形容词)。
自然语言处理中的语料库处理技术

自然语言处理中的语料库处理技术自然语言处理(NLP)是一门涉及计算机科学与语言学知识的交叉学科,其中语料库处理技术是NLP的基础。
本文将介绍自然语言处理中的语料库处理技术,包括语料库的概念、语料库的采集及处理方法和语料库在自然语言处理中的应用。
一、语料库的概念语料库,也称为文本库、语料库或语料库,是存储自然语言文本集合的一个大型电子数据库。
语料库是NLP技术中的重要组成部分,包括人类日常语言使用的各种语言样本,如文本、语音、视频和图像等。
语料库处理技术是将语言样本数字化,并提取其中有关语言规则和习惯用法的信息,从而使计算机能够理解、分析和生成人类语言。
二、语料库的采集及处理方法语料库的采集包括手动采集和自动采集两种方法。
手动采集需要人工花费大量时间和精力从各类来源收集语料库,如书籍、期刊、报纸、网站和社交媒体等。
而自动采集是利用网络爬虫技术自动收集语料库,如谷歌搜索引擎和互联网档案馆等。
语料库的处理包括清理、标注和分析三个阶段。
清理是指去除语料库中的噪声,如广告、表情符号和非文本元素等。
标注是将语料库中的文本与语言学特征进行关联,如词性、句法分析和情感分析等。
分析是对标注后的语料库进行统计学分析,以提取其中的隐含信息,比如频率分布、共现模式和词汇关系等。
三、语料库在自然语言处理中的应用语料库处理技术在NLP中的应用广泛,包括机器翻译、信息检索、命名实体识别和自动摘要等。
在机器翻译中,语料库被用于对源语言和目标语言间的对应关系进行学习和生成翻译模型。
在信息检索中,语料库被用于提供查询和文本之间的匹配关系,从而提高检索的准确性和效率。
在命名实体识别中,语料库被用于识别文本中的人名、地名和组织名等实体,并提供上下文语境分析的支持。
在自动摘要中,语料库被用于提取文章中的有意义的信息并进行压缩,以便于快速了解文章主题和内容要点。
总之,语料库处理技术对自然语言处理的发展起到了极为关键的作用。
通过语料库的采集、处理和应用,计算机可以更加准确、快速地处理和理解人类语言,从而开拓了各种智能系统和应用的新层面。
英汉双语平行语料库人工对齐方法说明
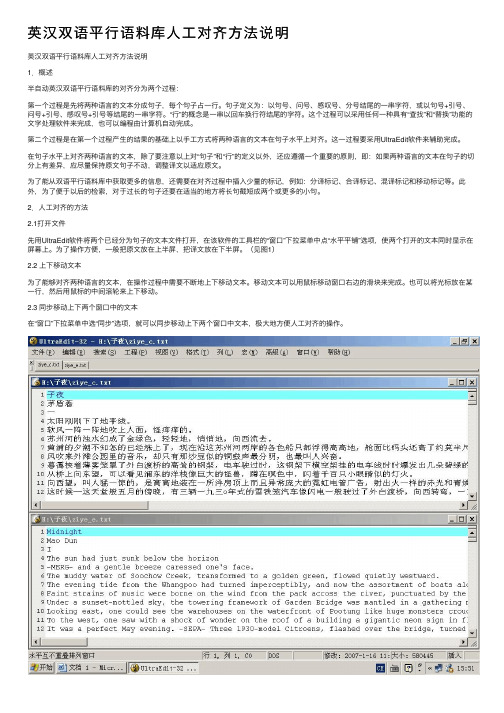
英汉双语平⾏语料库⼈⼯对齐⽅法说明英汉双语平⾏语料库⼈⼯对齐⽅法说明1.概述半⾃动英汉双语平⾏语料库的对齐分为两个过程:第⼀个过程是先将两种语⾔的⽂本分成句⼦,每个句⼦占⼀⾏。
句⼦定义为:以句号、问号、感叹号、分号结尾的⼀串字符,或以句号+引号、问号+引号、感叹号+引号等结尾的⼀串字符。
“⾏”的概念是⼀串以回车换⾏符结尾的字符。
这个过程可以采⽤任何⼀种具有“查找”和“替换”功能的⽂字处理软件来完成,也可以编程由计算机⾃动完成。
第⼆个过程是在第⼀个过程产⽣的结果的基础上以⼿⼯⽅式将两种语⾔的⽂本在句⼦⽔平上对齐。
这⼀过程要采⽤UltraEdit软件来辅助完成。
在句⼦⽔平上对齐两种语⾔的⽂本,除了要注意以上对“句⼦”和“⾏”的定义以外,还应遵循⼀个重要的原则,即:如果两种语⾔的⽂本在句⼦的切分上有差异,应尽量保持原⽂句⼦不动,调整译⽂以适应原⽂。
为了能从双语平⾏语料库中获取更多的信息,还需要在对齐过程中插⼊少量的标记,例如:分译标记、合译标记、混译标记和移动标记等。
此外,为了便于以后的检索,对于过长的句⼦还要在适当的地⽅将长句截短成两个或更多的⼩句。
2.⼈⼯对齐的⽅法2.1打开⽂件先⽤UltraEdit软件将两个已经分为句⼦的⽂本⽂件打开,在该软件的⼯具栏的“窗⼝”下拉菜单中点“⽔平平铺”选项,使两个打开的⽂本同时显⽰在屏幕上。
为了操作⽅便,⼀般把原⽂放在上半屏,把译⽂放在下半屏。
(见图1)2.2 上下移动⽂本为了能够对齐两种语⾔的⽂本,在操作过程中需要不断地上下移动⽂本。
移动⽂本可以⽤⿏标移动窗⼝右边的滑块来完成。
也可以将光标放在某⼀⾏,然后⽤⿏标的中间滚轮来上下移动。
2.3 同步移动上下两个窗⼝中的⽂本在“窗⼝”下拉菜单中选“同步”选项,就可以同步移动上下两个窗⼝中⽂本,极⼤地⽅便⼈⼯对齐的操作。
图1:⽤UltraEdit同时打开两种语⾔的⽂本。
2.4 译⽂句⼦的合并如上所述,对齐的原则是尽量保持原⽂不变。
语言文字整理方案

语言文字整理方案背景传达清晰、准确和有条理的信息对于有效沟通至关重要。
语言文字整理方案旨在帮助组织和个人有效管理和处理各种语言文字资料,提高工作效率和准确性。
方案概述语言文字整理方案的核心目标是整理和统一语言文字的使用,并确保内容准确、通顺、一致。
以下是实施该方案的关键步骤:1. 词汇统一使用统一的字词和术语是确保信息传达一致性的重要因素。
在整理语言文字资料时,需要制定统一的词汇表,并进行清晰的定义和说明。
所有相关人员都应遵循这个词汇表,在其工作中使用统一的术语和词汇。
2. 文风规范统一的文风可以增强信息的可读性和专业性。
在整理语言文字时,需要明确和执行一套统一的文风规范,包括句子结构、用词准确性、段落组织等。
这有助于提供清晰、简洁和专业的文字资料。
3. 格式一致统一的格式能够使文档更易于阅读和理解。
在整理语言文字资料时,需要制定一套统一的格式指南,并明确包括字体、字号、标题层次、段落间距等要素。
所有文档和资料都应符合这些格式规范。
4. 校对审查校对审查是确保语言文字准确无误的关键环节。
在整理语言文字资料后,需要进行仔细的校对审查,以纠正任何拼写、语法和语义方面的错误。
这可以通过专业校对人员、自动校对工具或协作审核来完成。
5. 建立语言文字库建立一个语言文字库可以提供对重要术语和表达的集中管理和访问。
该语言文字库可以包括词汇表、术语表、例句集等。
这有助于保证使用准确的词汇和表达方式,并避免在日常工作中重复劳动。
实施步骤为了成功实施语言文字整理方案,以下是推荐的步骤:1. 确定需求:了解组织或个人对语言文字整理的具体需求和目标。
2. 制定计划:制定详细的语言文字整理计划,明确步骤、时间表和责任人。
3. 培训与指导:为相关人员提供必要的培训和指导,以了解方案的目标和执行步骤。
4. 实施方案:按计划开始实施语言文字整理方案,并监督执行过程。
5. 收集反馈:定期收集相关人员的反馈,并根据需要进行调整和改进。
语言学中语料库建设与分析的使用教程

语言学中语料库建设与分析的使用教程语料库是语言学研究中非常重要的资源和工具,它是基于大规模的语言数据收集而建立的。
通过分析语料库,我们可以获得关于人类语言特征和规律的有力证据。
本文将介绍语料库的建设过程以及如何使用语料库进行语言学分析。
一、语料库建设1.确定研究对象和目标:首先需要明确研究的语言对象,是某种自然语言、特定领域的语言还是特殊类型的语言文本。
确定研究目标是什么,比如分析词汇使用、句法结构、语义关系等。
2.收集语料:语料可以通过各种途径获得,比如从书籍、报纸、杂志、互联网等获取文本数据。
保证语料的丰富性和多样性非常重要,这样才能更好地反映真实语言的特征。
3.清洗和整理语料:获得语料后,需要进行清洗和整理,去除冗余信息,确保语料的质量和一致性。
清洗后的语料应该是可读、可搜索和可分析的。
4.标注和注释:为了更好地分析语料,我们需要对语料进行标注和注释,比如词性标注、句法分析、语义角色标注等。
这样可以使得语料更加结构化,方便后续的语言学分析工作。
二、语料库分析1.词频统计分析:使用语料库可以对词汇进行频率统计,从而了解某种语言的常用词汇和词汇使用的变化。
可以计算词频、词形等指标,还可以利用词云图等可视化方式呈现词汇分布。
2.语义关系分析:通过语料库可以分析词汇之间的语义关系,比如同义词、反义词、上位词等。
可以通过共现分析、关键词共现网络等方法进行语义关系的挖掘和识别。
这种分析可以帮助我们更深入地理解词汇的用法和语义内涵。
3.句法分析:语料库可以进行句法分析,以了解句子的结构和成分之间的关系。
可以使用依存句法分析、成分句法分析等方法,进一步研究句子的组成和句法规律。
4.语言变异与变化分析:通过分析语料库可以揭示语言的变异与变化规律,比如不同地区、社会群体、年代之间的语言差异。
可以进行方言分析、历时比较研究等,了解语言变异的原因和机制。
5.语域分析:语料库可以用于分析特定领域的语言使用,比如科技领域、医学领域、法律领域等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、需整理的多是ppt语料,也有些word文档的语料(见Boston Consulting-需做库-12.10文件夹)。
整理要求如下:
1、利用Align Assist工具将ppt中原文译文提取出来,并根据中英文内容一句句对齐。
如图:
2、利用Align Assist工具对ppt中的内容进行提取时,软件会遗漏部分内容。
因此需要在对齐之后将软件自动提取后遗漏的句对逐句复制补充进去。
3、对齐完成后,将对齐结果分别保存为tmx格式及aares格式,tmx为最终需要的语料格式,但无法修改且预览不便。
aares为临时语料文件,可修改,可即时预览。
因此,请大家对齐时两种格式都保存下来。
保存方法见第二部分。
二、整理方法:
1、安装Align Assist语料对齐工具(安装程序见AlignAssist_Setup_1.5.1文件夹)。
双击AlignAssist_Setup_1.5.1.exe的程序进行安装。
语言选择为english。
2、双击运行。
将要对齐的原文文件和译文文件分别添加进去。
注意原文和译文语言方向。
根据文件夹要求确定英文、中文何为原文,何为译文。
例:project1-中到英,则中文文件为source file,英文文件为target file。
源文本和译文本添加完成后,点击Align。
进入如下界面。
3、注意split、merge、delete、swap的用法。
(1)split:将一句话断开为两句
随意举例:将第六句原文“当前全球经济正经历深度调整,各国需联手培育新的经济增长点和竞争优势。
”断为:“当前全球经济正经历深度调整,”及“各国需联手培育新的经济增长点和竞争优势。
”选中第六句原文,边框变黑。
单击上方菜单split。
进入下图界面。
将第二小句内容剪切粘贴到cell 2部分,然后单击ok。
即分句完成。
(2)merge:将同侧两句话合为一句
随意举例:再将上面分开的两个小短句合为一句。
选中要合并的句子。
背景色变蓝。
单击菜单栏merge,及合并成功。
(3)delete:删除句子,可一次删掉同侧多句话,也可删左右两侧多句话。
通过拖击鼠标选中要删除的句子,按下菜单栏delete。
(4)swap:同侧上下两句话替换位置。
拖击鼠标选中要替换位置的两句话。
点击菜单栏swap。
即完成替换。
4、可通过键盘、鼠标对原文、译文内容进行编辑、复制、剪切、粘贴等操作。
撤销上一步操作即点击Actions-Undo。
5、对齐完成后,保存内容,选择Save。
Save Immediate Results保存可编辑的aares临时语料文件。
Save TMX Memory保存tmx语料文件。
两种格式都要保存。
6、如果此次对齐工作只做了一半,只保存aares临时语料文件,有时间再做时,再打开。
单击File,选择Open。
找到aares文件保存位置,打开重新进入对齐界面。