语料库课程(一)笔记
专业的语料库使用技巧

专业的语料库使用技巧语料库是在语言学和应用语言学研究中非常重要的工具。
它是大规模文本的集合,可以用来研究语言的使用情况和规律。
对于语言学研究者、翻译人员、教师和学生来说,掌握语料库的使用技巧是必不可少的。
本文将介绍一些专业的语料库使用技巧,帮助读者更好地利用语料库进行学习和研究。
一、选择合适的语料库选择合适的语料库是使用语料库的第一步。
不同的语料库有不同的特点和用途,因此我们需要根据具体的需求选择合适的语料库。
常见的语料库包括:1. 综合性语料库:这些语料库收录了各种类型的文本,涵盖了不同的话题和领域。
例如,BNC(British National Corpus)是一个英语综合性语料库,适合于对英语的整体使用情况进行研究。
2. 学科专业语料库:这些语料库针对特定学科的使用情况进行了收集和整理。
例如,法律语料库和医学语料库分别用于研究法律和医学领域的语言使用。
3. 历时语料库:这些语料库收录了不同时期的文本,可以用来研究语言的演变。
例如,COHA(Corpus of Historical American English)是一个用来研究美国英语历史演变的语料库。
二、设置搜索条件在使用语料库进行检索时,我们需要设置适当的搜索条件,以便找到所需的文本。
以下是一些常用的搜索条件:1. 词汇:我们可以输入一个或多个词汇,以搜索包含这些词汇的文本。
还可以设置搜索词的位置(如句首、句中、句末)和词性(如名词、动词、形容词等)。
2. 短语:除了单个词汇,我们还可以搜索特定的短语。
短语搜索可以通过添加引号来实现,以确保搜索结果仅包含完整的短语。
3. 上下文:为了更精确地定位所需的文本,我们可以指定搜索词的上下文。
上下文可以是一个特定的句子、段落或文档。
4. 语言特征:语料库通常提供一些基于语言特征的搜索选项,如词频、词汇搭配、句法关系等。
这些选项可以帮助我们更深入地了解和研究语言的使用。
三、分析搜索结果搜索结果的分析是使用语料库的关键步骤之一。
北京外国语大学语料库语言学考博参考书目导师笔记重点
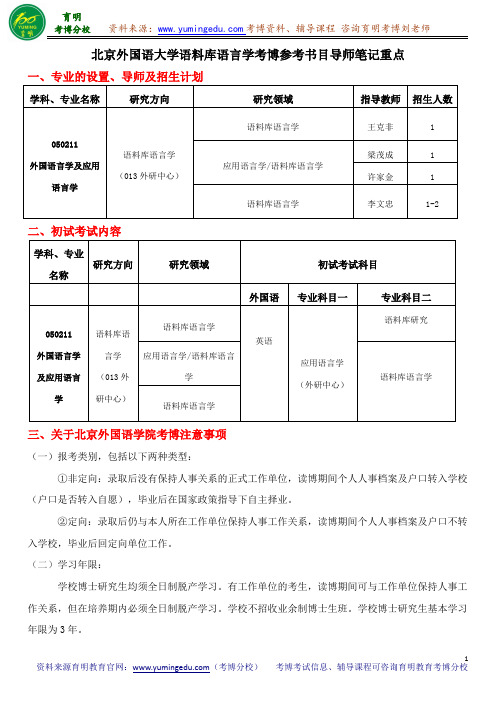
学科、专业 研究方向
名称
研究领域
初试考试科目
外国语 专业科目一
专业科目二
050211
语料库语
语料库语言学
外国语言学
言学 应用语言学/语料库语言
及应用语言 (013 外
学
学
研中心)
语料库语言学
英语
应用语言学 (外研中心)
语料库研究 语料库语言学
三、关于北京外国语学院考博注意事项
(一)报考类别,包括以下两种类型: ①非定向:录取后没有保持人事关系的正式工作单位,读博期间个人人事档案及户口转入学校
第二阶段:专题整理和讲解 在第一阶段的基础上,由专业课老师带领整理重要常考的学科专题,进行各个知识模块的深化和 凝练。以专题为突破口夯实并灵活运用理论知识。 第三阶段:时事热点和出题人的论著 对出题老师的研究重点,最新论文成果和重要的上课的笔记课件进行讲解。对本专业时政热点话 题进行分析,预测有可能出现的题型和考察角度。 第四阶段:历年真题演练和讲解 对历年真题进行最深入的剖析:分析真题来源、真题难度、真题的关联性,总结各题型的解题思 路、答题方法和技巧。全面提升学员的答题能力,把前面几个阶段掌握的理论知识转化为分数。 第五阶段:模拟练习及绝密押题 就最新的理论前沿和学科热点结合现实的热点进行拔高应用性讲解。开展高强度模拟考试,教会 考生怎么破题,怎么安排结构,怎么突出创新点等答题技巧。结合最新的内部出题信息和导师信息进 行高命中押题。
5、经济上要有一定的支撑。包括人际关系费用,找该校的对口复习资料费用,报辅导班的费用, 考试费等等,该花的最好不要省,只要是对考博成功有利的。因为这些钱对于博士生出来后的待遇来 说太微不足道了。 (二)专业课如何复习
对待专业课的认识,有些考生以为自己学了这么多年本专业,甚至发表了不少文章,专业课应该 没问题了,从而放松了对自己专业课复习的要求。其实现在博士录取时,各个环节都不能放松。即使 及格了,如果成绩较低,总分排名靠居后,也会影响导师对自己的印象。提高专业课的复习效率,育 明考博告诉大家可以分为以下两个阶段:
语料库课程(一)笔记解析
基本观点
词汇中心教学法坚持以词项(lexis)单词短 语结构为基本单位的语言观;重视频率在大缸 设计及教学中的作用;词汇中心教学法本质上 采取的是交际法,它强调将词项置于真实语言 素材中,并贯穿于真实任务中加以学习。同时 提倡学生自主的发现式学习。
Step1 打开Sub-corpus creator,导入seccel(只能导入 单个文件夹),显示文本文件,勾选case sensitive(区 分大小写),file contains “T1=”,获得男生/女生文本,保 存生成子库。
Step2 用PowerConc对两个子库进行比较。
2 趋势
small & specific
标记(mark-up)与标注
Sinclair和他的clean text policy (Sinclair认为语料库语言学应摒弃旧理论一切重来)
语料库语言学界对标注的态度(大部分研究者认为应该标 注),世界最大的语料库Bank of English可以进行词类检 索。
标注的主题
1. 人工标注 (Brown语料库) 2. 机器标注(准确率97-98%)
Step1:新建文件夹1:observeText 新建文件夹2:referenceCorpus
Step2:安装PowerGREP Step3: 设置PowerGREP (preferencegeneral,勾选1、2空格)
Step4: 格式转换(UTF-8转换成ANSI):
1) 找到04Academic,单击右键,出现search with PowerGREP(若有子文件,选第search subfolders)
语言学习观:行为主义 (行为主义)
语料库笔记

语料库简单DIY 第一讲语料库--语料库语言学的工具主讲叶城日本国立广岛大学综合科学研究中心计算机辅助语言教学博士一年联系方式: QQ 47354211 E-mail: sery2004@在语言学QQ群里面混迹了多年,经常潜水走马观花似的看着群里面的朋友们针对语料库提出各种各样的问题和困惑,总结起来,大家的问题无非离不开对于语料库的理解,应用,以及研究。
不过,因为群里面的朋友大多数都是文科的文学,语言学,以及对外汉语专业。
对于计算机辅助语言研究,语料库语言学等概念接触的机会并不是很多。
加上群里的女性朋友居多,她们对于电脑操作系统本身的使用都存在诸多头疼的问题,就更不要提数据量超大的语料数据库了。
本人不是计算机专业的毕业生,本科是日语专业,硕士是比较语言学,博士是计算机辅助对日汉语教学。
所以对于语料库本身的程序和数据库,认识只是停留在应用和架设阶段,实在说不清楚里面很多细节的问题,也请朋友们原谅。
我有说的不对的地方,欢迎来信或者QQ群里直接批判,我一定虚心接受。
谢谢!首先,我们来个扫盲活动,把对于语料库的认识梳理清楚。
第一个内容:语料库是干嘛的?CORPUS =The body of written or spoken material upon which a linguistic analysis is based .这里的CORPUS就是我们说的语料库,它实际上也等于CORPSE或者Dead Body。
就是死尸的意思。
好奇怪,这里怎么搞个死尸进来呢?其实这个概念是在构造主义时期1956年由英国的语言学会提出来的。
他们认为,人类研究语言的时候,需要诸多实体例子,这样的例子最好是最纯净的,最朴实的,甚至是最低俗低劣但是最普及的。
并且我们需要一个庞大的地方放置我们日常的言行,报纸杂志上刊登的新闻,以及各种各样的文学体裁等等。
而放置这些语言信息的地方,则被称为没有活力没有变化没有生机勃勃,像停尸房一样的地方----语料库。
语料库语言学

4. Extraction of multiword units or clusters of items in a text.
Chapter II: Analyzing Corpus Data
Word Lists 词表
定义:根据单词或 词组在语篇中出现 的频率大小而排列 形成的列表。
Lemma:词目,词元 SAY: say, says,said, saying 在ELT中的应用
Historical corpora(历史语料库): texts from different periods of time, allow for the study of language change when compared with corpora from other periods. Monitor corpora(监控语料库):focus on current changes in the language. Parallel corpora(平行语料库):texts in at least two languages that have either been directly translated, or produced in different languages for the same purpose.
Technical: a large collection of written or spoken language ,that is used for studying the language.语料 库,语料汇编
What is corpus linguistics?
• Corpus linguistics :the study of machine-readable spoken and written language samples that have been assembled in a principled way for the purpose of linguistics research. It is concerned with language use in real contexts.
50-语料库语言学

中国海洋大学本科生课程大纲课程属性:公共基础/通识教育/学科基础/专业知识/工作技能,课程性质:必修、选修一、课程介绍1.课程描述(中英文):语料库语言学(Corpus Linguistics)是基于大规模语料进行语言研究的学科。
本课程针对英语系本科生开设。
课程内容包括:语料库语言学的基本情况、发展历程、主要流派及理论模型、语料库在各类研究中的应用等。
通过课程学习,要求学生掌握语料库语言学的基本理论及研究方法,从而初步形成利用语料库探索语言学及相关领域的科研能力。
Corpus linguistics probes into linguistic problems by analyzing a large quantity of real-life language data. This course is intended for the undergraduate English majors. The course covers the basic topics of corpus linguistics, including an overview of the field, its history, major theoretical schools, research methods as well as its application in other branches of linguistics. After taking the course, students are expected to acquire a basic understanding of the fundamental theories and methods of corpus linguistics and are able to design and conduct simple corpus based linguistic studies.2.设计思路:- 1 -本课程将介绍语料库语言学的整体情况及理论基础。
语料库基础知识

/yingyong/courses/corpusbase.htm语料库研究与应用综述语料库研究与应用综述 一 概述 语料库通常指为语言研究收集的、用电子形式保存的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。
经过科学选材和标注、具有适当规模的语料库能够反映和记录语言的实际使用情况。
人们通过语料库观察和把握语言事实,分析和研究语言系统的规律。
语料库已经成为语言学理论研究、应用研究和语言工程不可缺少的基础资源。
语料库有多种类型,确定类型的主要依据是它的研究目的和用途,这一点往往能够体现在语料采集的原则和方式上。
有人曾经把语料库分成四种类型:(1)异质的(Heterogeneous ):没有特定的语料收集原则,广泛收集并原样存储各种语料;(2)同质的(Homogeneous ):只收集同一类内容的语料;(3)系统的(Systematic ):根据预先确定的原则和比例收集语料,使语料具有平衡性和系统性,能够代表某一范围内的语言事实;(4)专用的(Specialized ):只收集用于某一特定用途的语料。
除此之外,按照语料的语种,语料库也可以分成单语的(Monolingual )、双语的(Bilingual )和多语的(Multilingual )。
按照语料的采集单位,语料库又可以分为语篇的、语句的、短语的。
双语和多语语料库按照语料的组织形式,还可以分为平行(对齐)语料库和比较语料库,前者的语料构成译文关系,多用于机器翻译、双语词典编撰等应用领域,后者将表述同样内容的不同语言文本收集到一起,多用于语言对比研究。
语料库建设中涉及的主要问题包括:(1) 设计和规划:主要考虑语料库的用途、类型、规模、实现手段、质量保证、可扩展性等。
(2) 语料的采集:主要考虑语料获取、数据格式、字符编码、语料分类、文本描述,以及各类语料的比例以保持平衡性等。
(3) 语料的加工:包括标注项目(词语单位、词性、句法、语义、语体、篇章结构等)标记集、标注规范和加工方式。
Chapter 1b

对于语言学的研究可以追溯到古希腊时期。
公元前五到四世纪,希腊著名哲学家苏格拉底、伯拉图、亚里斯多德在他们的研究中对语言的研究就站和大地位。
伯拉图的一篇《对话》,《克雷特里斯》(Cratylus)讨论到词为什么具有意义。
克雷特里斯认为:一个对象的名称是由于它的性质而产生的所以语言自然而然地具有意义。
赫莫吉尼斯:反对这种观点,认为名称之所以能指称生物是由于惯例的原因,也就是语言使用者达成的协议。
然后苏格拉底论述两种观点的有缺点。
他说,一个句子分成两部分,名词部分和动词部分。
亚里斯多德是古希腊最著名的哲学家、思想家。
他在《解释篇》、《修辞学》、《诗学》等著作中讨论了有关语言的问题。
他认为:由于形成于惯例,因为名称没有天然产生之理。
语言的词汇只是这些思想的标记。
他进一步讨论名词部分和动词部分,指出名词没有时间成分,而动词有时间成分。
斯多噶派是盛行于公元前四世纪的一批哲学家和逻辑学家。
(他是亚里斯多德的反对者)他们区分了五大词类:名词、动词、连词、冠词和关系代词。
提出“白板说”“自然说”。
亚历山大大帝建立了两个殖民地:埃及亚历山大、土耳其帕加马,亚里斯多德将自己的藏书都赠给了亚历山大,许多学者来此定居从事科学研究成了有名的亚历山大学派、帕加马学派。
辩论的开始围绕:自然界是如何构成的,自然界的运动情况如何反映到人类语言之中?(公元300--146)斯拉克思《语法科学》总结了亚历山大派的语法研究工作,在第一部中进行了语音研究语法部分他认为词汇分8种。
名词、动词、冠词、代词、介词、副词、连词,分词。
文艺复兴前只是对古希腊和拉丁语的研究,14,15 世纪开始将语言学范围扩大。
开始对希伯来语阿拉伯语的研究。
因为《圣经》原文是希伯来语。
古罗马与古希腊来往已久,公元前三世纪罗马帝国征服希腊城之后,希腊科学文化直接影响罗马的发展。
罗马帝国西部拉丁语是官方语言,东部希腊语事官方语言。
希腊的文化科学乘机而入。
著名语言学家瓦罗将语言研究分为三大部分:词源学、形态学、句法学。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
标注必须基于科学、合理的分类体系 1. 与研究目的相关 2. 分类的穷尽性 3. 各子类不应该相互重叠 4. 关于“其他”类(应该是最小类)
标注的常见类型
标注集/赋码集(tagset)是标注中所使用的代 码集,是对分类体系的操作化。 Tagset: A collection of tags (or coldes) in a tagging scheme. Caution: A tagset usually adheres to a particular decriptive …
理据
我们对真实世界的理解表达为知识 知识表现为不同的语义场 语义场表现为各种词语场 各种词语场实现为各个词群(单词或短语) 特定话题触发独特词群 具有特定话题的文本包含独特词群,该词群一 般不在其它话题中出现
因此
某个特定话题的文本包含的独特词群具有异常 高频 参照语料库代表了某一类型语言运用的常态 对比两个词表,可以提取那些超常高频的词群
8.2上午
(二)李文中 主题词分析
分析文本时注意备份,把需分析的语料放入 新建的文件夹中。 练习:使用语料: 04Academic/4Genres_RAW/Four_Genres/01 _General_corpora/Data
1. 创建2个对比文件夹,用PowerGREP转换 格式,并把text放入这2个文件夹
比什么:条件控制
控制相似变量 突出差异焦点
描述
观察文本 具有明确主题的完整文本或一致主题的文本集 参照语料库 具有足够的代表性 足够大 同质语料
主题词表 观察文本 参照语料库
8.2上午
(三)
许家金
语料库三大功能 1. concordance 索引 2. N-gram 词表 3. 主题词表
Words cluster as people do
e.g. Search: no attempt 用法 Regex: \bno\b\s\battempts?(ed/ing)\b 观察collocation and co-occurrence 作业:hair: 单数与复数的隐喻 body metaphor
8.1下午
(三)梁茂成 语料库的标注
标注与干净文本原则 标注的常见类型 词性标注 手工标注
标注与干净文本原则
标注(annotation): The process of applying additional information to corpus data. 标记(mark-up)与标注
④ context
二、为什么要研究语料库语言学 1)使语言学研究更具科学性 2)可验证,不是玩具 3)大数据,更具说服力 4)enables you to look at a lot of language at once
8.1上午
(二)李文中
Brown-Raw 语料库范例 Span 跨距 (KWIC,一般左5右5) 检索排序(sort),以necessarily为例,观 察得出结论:经常与not连用。 Why concordancing? 上下看强形式搭配,左右看综合分析用法。 基本概念 type (独特词形),token,KW/SW/Node word span (一个span可视作一个mini text) collocates (观察从collocationcolligationsemantic meaning) cotext, context, co-occurrence(同现),recurrence(复现)
What and how
教什么 怎么教
词汇中心教学法
The Lexical Approach 许家金,2009,词汇中心教学法的交际观:理 论溯源与反思,《中国外语教育》(4):3845.
基本观点
词汇中心教学法坚持以词项(lexis)单词短 语结构为基本单位的语言观;重视频率在大缸 设计及教学中的作用;词汇中心教学法本质上 采取的是交际法,它强调将词项置于真实语言 素材中,并贯穿于真实任务中加以学习。同时 提倡学生自主的发现式学习。
8.2上午 (一)梁茂成
手工标注
word_Pos
1)自动标注 TreeTagger
word-Pos_Lemma(原形)
2) 手工标注: BFSU Qualitative Coder
语料库的手工标注
BFSU Qualitative Coder 1.1 1)根据codelist,修改制定需要的mycodelist 2)打开BFSU Qualitative Colder 3) 打开需标注的.txt文档,导入mycodelist,进 行手工标注 4)BFSU中可做统计(点statistics,跳出网页) 5)保存为.txt文档后,用powerconc检索分析, 如:检索<LIT> free hand</LIT>
Step2 用PowerConc对两个子库进行比较。
2 趋势 small & specific contrastive studies 3 建库准备 建库原则,文本收集,文本分类,文本处理, 标记(外部信息),标注(annotating notes, 语言学标注) e.g. <Year>1990</Year><Sex>Male</sex>
词性标注
常见的词性标注工具 (POS-tagger) ANSI符号,_, / 1)Brill Tagger, 最早的词性标注,基于规则的 2)ClAWS,130多个代码,准确,但付费, Lancaster大学开发。 3)TreeTagger, 30多个代码,准确率高,免费, 能对多语言进行标注。
④ versions of corpora: RAW, POS, with metadata
2. 批量文件名修改 SuperbBatchRenamer
insert replace
e.g.replace:空格1不填,空格2填 ST$,出现从1开始排序的新文件名。
3. 文本清理,元信息标记、语言学标记
基本观点
然而,由于过分依赖频率信息,语言观和语言 教学完全基于词项,将词汇中心教学法嫁接于 任务型教学且缺乏创新,归纳式的自主。。。
实例演示
新闻英语教学设计 以新闻英语常用动词教学设计为例 powerConc with China Daily Political new 2011
得出结论: reporting verbs: said told added
Aspects of LT methodology
语言观 语言学习观 教学实施方案
两大教学法之一:听说法
语言观:结构主义 (音标、词汇等构成的) 语言学习观:行为主义 (行为主义) 教学实施方案:句型操练
两大教学法之二:交际法
语言观:功能主义 语言学习观:交际与互动 教学实施方案:任务教学、小组活动
8.1下午
(一)李文中
1. 标注信息的添加与使用
e.g. 用PowerConc检索 dataleanerseccl 问题:男生与女生在口语中使用情态动词有无差异 Step1 打开Sub-corpus creator,导入seccel(只能导入 单个文件夹),显示文本文件,勾选case sensitive(区 分大小写),file contains “T1=”,获得男生/女生文本,保 存生成子库。
Step1:新建文件夹1:observeText 新建文件夹2:referenceCorpus Step2:安装PowerGREP Step3: 设置PowerGREP (preferencegeneral,勾选1、2空格)
Step4: 格式转换(UTF-8转换成ANSI):
1) 找到04Academic,单击右键,出现search with PowerGREP(若有子文件,选第search subfolders) 2) Action type collect data, 并勾选Dot matches newlines 3) search:输入 (^\A.*?\z) ,需在英语状态下输入。 collect:输入 $1($指向括号,1代表第一个括号)
4) Target file creation 选择 save one file for each searched file Target file location 选择刚才新建文件夹referencecorpus Target file text encoding 选择 Windows936,即ANSI Back file naming style 选择 no backups 5) 点击 collect 6) 回到新建文件夹referencecorpus查看,已有ANSI文档生成。
Step5 主题词表生成
1) 从referencecorpus中拷贝Text10到observeText文件夹中。 到此为止,人为做成两个用于练习的对比语料库。 2)生成主题词表
2)生成主题词表
① 打开PowerConc, 导入referencecorpus进行N-gram统计, 结果save到PowerConc根目录下,命名为 academicOnewordlist. ② 打开academicOnewordlist, 删除前4行,保存。 ③ 再打开PowerConc,导入observetext,N-gram,count, 出结果后,点击keyness,出现load Ref.wordlist,导入 academicOnewordlist, count ④自设主题词临界值,如前20词,按照by value进行比较。
语料库在外语教学研究中 的应用研修班