《探究影响酶活性的条件》实验设计
探究影响酶活性的条件教案

探究影响酶活性的条件教案一、教学目标1. 理解酶的概念和特性2. 掌握影响酶活性的因素3. 能够设计实验探究影响酶活性的条件4. 培养学生的实验操作能力和科学思维二、教学内容1. 酶的概念和特性2. 影响酶活性的因素3. 实验设计原则4. 实验操作步骤5. 数据处理与分析三、教学方法1. 讲授法:讲解酶的概念、特性和影响酶活性的因素2. 实验法:学生分组进行实验,探究影响酶活性的条件3. 讨论法:学生分组讨论实验结果,分析影响酶活性的因素4. 引导法:教师引导学生思考和解决问题,提高学生的科学思维能力四、教学准备1. 实验室仪器和设备:试管、烧杯、滴定管、显微镜等2. 实验材料:酶溶液、底物、缓冲液、指示剂等3. 教学课件和教案五、教学过程1. 导入:通过问题引导学生思考酶的活性和影响因素2. 讲解:讲解酶的概念、特性和影响酶活性的因素3. 实验设计:引导学生设计实验,探究影响酶活性的条件4. 实验操作:学生分组进行实验,教师巡回指导5. 数据处理与分析:学生分组讨论实验结果,分析影响酶活性的因素6. 总结与评价:教师总结实验结果,评价学生的实验操作和分析能力六、教学评估1. 实验报告:评估学生对实验原理、操作步骤和数据处理的理解与应用。
2. 小组讨论:观察学生在小组讨论中的参与程度、合作能力和问题解决能力。
3. 口头报告:评估学生对实验结果的口头表述和分析能力。
七、安全与环保1. 实验室安全:指导学生正确处理化学品,避免意外伤害。
2. 环保意识:教育学生在实验过程中注意节约使用试剂,减少废弃物产生。
八、拓展活动1. 文献调研:要求学生查阅相关文献,了解酶活性研究的最新进展。
2. 案例分析:提供一些实际案例,让学生分析其中的酶活性影响因素。
九、教学反思1. 教师评估:总结教学过程中的成功与不足,提出改进措施。
2. 学生反馈:收集学生的意见和建议,以提高教学效果。
十、课后作业1. 实验报告:要求学生完成实验报告,详细记录实验过程和结果。
探究《影响酶活性的条件》教学设计 (2)

探究《影响酶活性的条件》教学设计 (2)课时安排:本节课时为一节实验课,预计课时为1小时。
教学目标:1. 了解影响酶活性的条件;2. 探究不同条件下酶的活性变化。
前置知识:学生已经学习过酶的相关知识,包括酶的定义、结构、功能和酶的活性。
教学准备:实验材料:生物素、过氧化氢溶液、非生物素生物素酶液、酶底物和酶反应助剂;实验仪器:试管、滴管、管盖和显色液。
教学过程:一、引入(5分钟)1. 引出本课的主题,酶是一种具有特异性的生物催化剂,能够加速化学反应的速度。
2. 回顾之前学过的酶的知识。
二、实验操作(30分钟)1. 分组进行实验操作。
2. 分组根据老师提供的实验材料和仪器进行实验。
a) 将生物素、非生物素生物素酶液和酶底物分装在不同的试管中;b) 在不同实验条件下,观察酶的活性变化,可以通过观察溶液的颜色变化来判断。
3. 注意实验操作的规范和安全。
三、结果分析(15分钟)1. 组内成员讨论实验结果,对不同实验条件下酶活性的变化进行归纳总结。
2. 学生离散活动,回答以下问题:a) 在实验过程中哪些因素会影响酶的活性?b) 酶活性随温度、pH值的变化趋势是怎样的?c) 为什么高温和极端的酸碱条件会影响酶的活性?四、讨论与总结(10分钟)1. 学生就以上问题展开讨论,老师引导学生总结出影响酶活性的条件。
2. 老师进行总结,强调酶活性受到温度和pH值的影响,同时解释高温和极端酸碱条件对酶的活性影响原因。
五、作业布置(5分钟)1. 提问学生根据实验结果和理论知识,解释为什么生物体的酶在特定条件下能发挥更好的催化作用。
2. 提醒学生复习和整理本节课的知识点,为下节课的学习做好准备。
教学延伸:1. 可以引导学生进行进一步的实验设计,探究酶活性在其他条件下的变化,如酶浓度、底物浓度等。
2. 可以结合实际生活中的例子,让学生了解酶活性和反应条件的关系,如食物加工、烹饪等。
3. 可以进行课堂小测、讨论或小组展示等形式评价学生的学习情况。
探究酶活性的实验设计

探究酶活性的实验设计酶活性是指酶在一定条件下催化反应的能力,影响酶活性的因素有很多,如温度、pH值、底物浓度等。
本文将探究酶活性的实验设计,通过实验方法和步骤的讲解,展示如何准确、科学地研究酶活性。
一、实验目的探究不同条件下酶活性的变化规律,分析影响酶活性的因素。
二、实验材料和设备1. 反应物料:酶溶液、底物溶液2. 实验器材:试管、移液管、计时器、恒温水浴、pH计、离心机等三、实验步骤1. 准备工作:a. 将酶溶液和底物溶液置于恒温水浴中,使其温度稳定在实验需要的温度(如37°C)。
b. 准备一系列不同pH值的缓冲液,确保在实验中能控制pH值。
c. 测量底物的浓度,并调整为实验所需的浓度。
2. 温度对酶活性的影响实验设计:a. 取若干试管,并标记好温度,如20°C、30°C、40°C等。
b. 向每个试管中加入相等体积的酶溶液和底物溶液。
c. 将试管放入恒温水浴中,分别加热或冷却到所标注的温度并保持一段时间。
d. 在预定时间间隔内,取出试管,通过添加某种试剂停止反应,并用比色法或浊度计等设备测定产物的生成量。
3. pH值对酶活性的影响实验设计:a. 取若干试管,并加入等体积的酶溶液和底物溶液。
b. 分别向每个试管中加入不同pH值的缓冲液,如pH=5、pH=7、pH=9等。
c. 将试管放置于恒温水浴中,保持一定时间。
d. 在适当时间内,用某种试剂停止反应,并通过测定反应产物的生成量来研究酶活性的变化。
4. 底物浓度对酶活性的影响实验设计:a. 在试管中加入等体积的酶溶液,且底物浓度分别设为1mol/L、0.5mol/L、0.2mol/L等。
b. 将试管放于恒温水浴中,反应一定时间。
c. 使用某种试剂停止反应,并测定生成的产物浓度。
d. 通过产物浓度的变化,探究底物浓度对酶活性的影响。
四、数据处理和分析1. 温度对酶活性的影响:a. 绘制反应速率随温度变化的曲线图,分析酶活性与温度的关系。
《探究影响酶活性的条件》实验设计

《探究影响酶活性的条件》实验设计一、设计思路:创设情境,利用多媒体展示普通洗衣粉和加酶洗衣粉的洗衣效果。
普通洗衣粉不易清除衣物上的奶渍、血渍,但加酶洗衣粉可以。
加酶洗衣粉包装袋上印有的用法就有这样一条:洗涤前先将衣物浸于加有适量洗衣粉的水内一段时间,使用温水效果最佳,切勿用60℃以上的热水。
如果我们洗衣服时使用了0℃的冷水或60℃以上的热水,效果如何?再加入其它物质会不会有影响呢?二、内容分析:本实验是“降低化学反应活化能的酶”一节中的内容。
上节课学习了酶的作用与本质。
知道了酶大部分是蛋白质,外界条件变化会使蛋白质变性使酶失去活性。
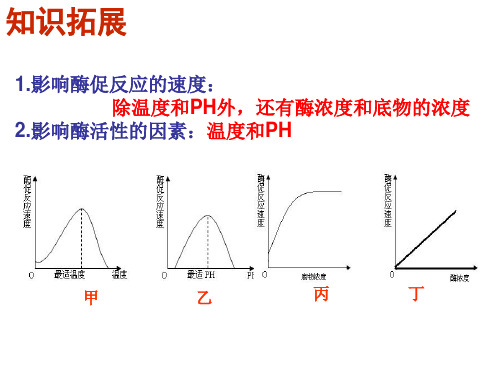
根据这一特性利用课余时间让每组学生设计实验,然后再按设计的方案分组进行实验,探究在酸性、碱性、高温、低温条件下对酶活性的影响,最后对实验结果进行分析讨论,由学生自己总结得出结论:温度和pH都对酶活性有显著的影响。
三、教学目标:(一) 知识目标1、学会控制自变量,观察和检测因变量的变化及设置对照实验和重复实验。
2、概述温度和pH影响酶的活性。
(二) 能力目标1、学会用准确的语言阐述实验探究的过程和结果。
2、提高学生观察、分析、判断的思维能力,提高学生的实验操作能力和分享信息、分享实验成果的能力。
(三) 情感态度与价值观目标1、体验科学探究过程,领悟科学探究方法。
2、通过实验探究影响酶活性的条件,培养学生的探索精神、创新精神和合作精神。
四、教学重点:1、学会控制自变量,观察和检测因变量的变化及设置对照实验和重复实验。
2、学会用准确的语言阐明实验探究的结果。
五、教学难点:确定和控制对照实验中的自变量和无关变量,观察和检测因变量的变化。
六、教学方法:实验探究法、讨论法七、材料与仪器:质量分数为3%的可溶性淀粉溶液,质量分数为2%的α—淀粉酶溶液,新鲜的质量分数为20%的肝脏研磨液,体积分数为3%的过氧化氢溶液,碘液,5%的盐酸溶液,5%的NaOH 溶液,蒸馏水,热水、冰块。
试管6只,量筒(5ml),大、小烧杯,滴管,试管夹,酒精灯,三脚架,石棉网,温度计,pH试纸,火柴。
8实验设计探究影响酶活性的条件

实验设计8“影响酶活性的条件”的实验探究
目的要求:通过比较过氧化氢在不同温度和PH值条件下分解的快慢,了解过氧化氢酶起作用的外部条件
实验材料:唾液淀粉酶溶液、新鲜的质量分数为20%的肝脏(如猪肝、鸡肝)研磨液。
新配制的体积分数为3%的过氧化氢溶液,质量分数为3%的可溶性淀粉溶液。
量筒、试管、滴管、试管架、火柴、酒精灯、试管夹、小烧杯、大烧杯、三脚架、
石棉网、温度计、PH试纸
实验原理:通过不同温度、PH值下酶催化相应物质反应的快慢的对比试验,来说明酶活性的最适条件。
探究一:温度影响酶的活性
酶的选择;反应试剂的选择
鉴定试剂的选择
鉴定原理:
变量控制:自变量因变量
方法步骤:按照表格中的步骤完成下面实验操作并记录实验结果
实验结论:
探究二:pH对酶活性的影响
酶的选择;反应试剂的选择
鉴定试剂的选择
鉴定原理:
变量控制:自变量因变量
方法步骤:
实验结论:。
说明……………………………………………………………………………………………………
在设计酶需要适宜的温度和pH的实验中,每一组实验都必须事先将底物、酶液分别处理到各自所需要控制的温度和pH,使反应一开始便达到预设温度和pH,减小实验误差。
实验7---探究影响酶活性的条件

(2)实验结果: 1号试管不变蓝,2、3号试管变蓝 (3)实验结论 酶的催化作用需要适宜的温度条件,温度过高 和过低的都将影响酶的活性。
2、pH对酶活性的影响
取3只洁净试管编号1—3,按下面步骤操作。
项目 1
注入H2O2酶溶液
试管1
1mL
试管2
1mL
试管3
1mL
2 3
4 5
注入蒸馏水
注入氢氧化钠溶液 注入盐酸 注入H2O2溶液
5、设计并进行实验
(二)实验步骤
1、温度对酶活性的影响 (1)试验流程: 取6只试管,编号,并加入相应物质
将6至试管分三组分别放入相应温度的水槽中并维持 5分钟。
分别将淀粉酶溶液注入相同温度下的淀粉溶液中,摇 匀,维持各自温度5分钟 向混合液中各滴入1滴碘液,摇匀 观察并记录试管中溶液颜色的变化情况
1mL
—— —— 2mL
——
1mL —— 2mL
——
—— 1mL 2mL
6
7 8
பைடு நூலகம்
震荡3支试管
实验结果 实验结论
+
有大量气泡 产生
+
无大量气 泡产生
+
无量气泡产生
过养化氢在强酸和强碱环境中不起作用, 在中性环境中能催化过养化氢快速分解
三、实验总结
1、设计思路:
底物+t1(或 pH1)+酶液 底物+t2(或pH2)+酶液 … …. … 检测 底物分解速度或产 物的形成速度
一、实验原理
1、
斐林试剂
砖红色沉淀
加热
2、
二、实验操作步骤
(1)探究过程。 1、提出问题:温度或pH会影响酶的活性吗? 2、作出假设:由于多数酶是蛋白质,具有一定的结构和功能, 其结构会因外界温度,pH等的变化而改变,今儿影响催化活性
影响酶活性的条件教学设计

影响酶活性的条件教学设计教学目标:1.了解酶的定义和作用。
2.理解影响酶活性的条件。
3.掌握常见影响酶活性的条件对酶活性的影响。
教学重点:1.影响酶活性的条件。
2.影响条件对酶活性的影响机制。
教学准备:1.实验器材:试管、酶溶液、底物、酶抑制剂、缓冲溶液等。
2.实验方法:测定酶活性的方法。
教学过程:一、导入(5分钟)1.引入酶的概念和作用,激发学生对酶的兴趣。
2.提问:你们知道什么是酶?酶在生物体内的作用是什么?3.让学生分享自己的答案,并解答学生的问题。
二、理论讲解(15分钟)1.解释酶的定义和作用。
2.介绍影响酶活性的常见条件,包括温度、pH值、底物浓度、酶抑制剂等。
3.分析这些条件对酶活性的影响机制。
三、实验演示(30分钟)1.示范温度对酶活性的影响:将酶溶液放置在不同温度下,分别测定酶活性。
2.示范pH值对酶活性的影响:将酶溶液分别置于不同酸碱性条件下,测定酶活性。
3.示范底物浓度对酶活性的影响:将酶溶液与不同浓度的底物反应,测定酶活性。
4.示范酶抑制剂对酶活性的影响:将酶抑制剂加入酶反应体系中,测定酶活性的变化。
5.让学生观察实验现象,描述不同条件下酶活性的变化。
四、实验探究(40分钟)1.划分小组,每组选定一个影响酶活性的条件进行实验探究。
2.让学生根据实验结果,总结该条件对酶活性的影响规律。
3.学生之间展示实验结果和总结,进行交流和讨论。
4.教师在小组之间巡视,提问和指导学生。
五、总结与评价(10分钟)1.让学生分享他们的实验结果和总结。
2.与学生一起总结酶活性受影响的条件,并思考原因。
3.提问:你认为影响酶活性的条件对生物体有何作用?4.教师对学生的实验过程、总结和表现进行评价和点评。
教学扩展:1.邀请相关专家进行讲座,进一步拓宽学生对酶活性的理解。
2.带学生进行更复杂的酶活性测定实验,如双底物反应等。
3.鼓励学生阅读相关文献,了解最新的酶活性研究成果。
教学反思:1.本教学设计通过理论讲解和实验探究相结合的方式,帮助学生更深入地理解酶活性受影响的条件。
探究影响酶活性的因素实验设计
探究实验的一般程序:
提出问题:温度影响酶的活性吗?
步骤;
作出假设:温度1.影分组响编酶号活性
2.分组处理(注意控制变量)
设计实验:设计3量.实放,在验相相步同同并骤条适,件宜预下的期进条实行件(验,常结同用时果词等:)等。
4.观察指标(要具体,可操作)
进行实验:
设计原则: 对照和单一变量原则。科学性原则,
建议:
用淀粉酶探究温度对酶活性的影响,用过氧化
氢酶探究PH对酶活性的影响?
一、探究温度对淀粉酶活性的影响
试管
淀粉溶液 温度
淀粉酶溶液 碘液
1 2mL 37℃温水 1mL 1滴
2 2mL 0℃ 1mL 1滴
3 2mL 100 ℃ 1mL 1滴
结果现象 不变蓝 变蓝 变蓝
1.实验步骤:
1.取6支试管分别编号为:A、A’、B、B’、C、 C’。
分析结果得出结可论重:复原则
表达和交流: 预测结果:
探究:影响酶活性的条件
实验材料:
2%淀粉酶溶液、20%肝脏研磨液、3%可溶性 淀粉溶液、体积分数为30%的过氧化氢溶液、5% HCl、5% NaOH、热水、蒸馏水、冰块、碘液、斐 林试剂
实验用具:
试管、量筒、小烧杯、大烧杯、滴管、试管夹、 酒精灯、三角架、石棉网、温度计、PH试纸、火柴
毕希纳
酵母细胞中的某些物质能在酵母细胞破碎后继续起催化 作用,就像在活酵母细胞中一样
萨姆纳
酶是蛋白质
切赫、奥特曼
少数RNA也 具有催化功能
总结:
酶的特性:
1具有高效性 比较过氧化氢酶和Fe3+的催化效率
2具有专一性 淀粉酶对淀粉和蔗糖的水解作用
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《探究影响酶活性的条件》实验设计一、设计思路:
创设情境,利用多媒体展示普通洗衣粉和加酶洗衣粉的洗衣效果。
普通洗衣粉不易清除衣物上的奶渍、血渍,但加酶洗衣粉可以。
加酶洗衣粉包装袋上印有的用法就有这样一条:洗涤前先将衣物浸于加有适量洗衣粉的水一段时间,使用温水效果最佳,切勿用60℃以上的热水。
如果我们洗衣服时使用了0℃的冷水或60℃以上的热水,效果如何?再加入其它物质会不会有影响呢?
二、容分析:
本实验是“降低化学反应活化能的酶”一节中的容。
上节课学习了酶的作用与本质。
知道了酶大部分是蛋白质,外界条件变化会使蛋白质变性使酶失去活性。
根据这一特性利用课余时间让每组学生设计实验,然后再按设计的方案分组进行实验,探究在酸性、碱性、高温、低温条件下对酶活性的影响,最后对实验结果进行分析讨论,由学生自己总结得出结论:温度和pH都对酶活性有显著的影响。
三、教学目标:
(一) 知识目标
1、学会控制自变量,观察和检测因变量的变化及设置对照实验和重复实验。
2、概述温度和pH影响酶的活性。
(二) 能力目标
1、学会用准确的语言阐述实验探究的过程和结果。
2、提高学生观察、分析、判断的思维能力,提高学生的实验操作能力和分享信息、
分享实验成果的能力。
(三) 情感态度与价值观目标
1、体验科学探究过程,领悟科学探究方法。
2、通过实验探究影响酶活性的条件,培养学生的探索精神、创新精神和合作精神。
四、教学重点:
1、学会控制自变量,观察和检测因变量的变化及设置对照实验和重复实验。
2、学会用准确的语言阐明实验探究的结果。
五、教学难点:
确定和控制对照实验中的自变量和无关变量,观察和检测因变量的变化。
六、教学方法:实验探究法、讨论法
七、材料与仪器:
质量分数为3%的可溶性淀粉溶液,质量分数为2%的α—淀粉酶溶液,新鲜的质量分数为20%的肝脏研磨液,体积分数为3%的过氧化氢溶液,碘液,5%的盐酸溶液,5%的NaOH 溶液,蒸馏水,热水、冰块。
试管6只,量筒(5ml ),大、小烧杯,滴管,试管夹,酒精灯,三脚架,石棉网,温度计,pH 试纸,火柴。
八、教学流程图:
九、教学过程:
程序
教师组织与指导 学生活动 设计意图
创设情境导入新课 利用多媒体展示普通洗衣粉和加酶洗衣粉的洗衣效果。
然后拿出加酶洗衣粉一袋,请位同学阅读它使用的注意事项。
引导学生推测:温度对于洗衣粉里酶发挥它的作用是有影响的。
一同学阅读之后提出加酶洗衣粉的使用要控制好温度。
学生思考回答。
从学生熟悉的生活情境入手,引导学生思考影响酶活
性的条件,激
十、板书设计
探究影响酶活性的条件
实验原理
实验重点:
1、学会控制自变量,观察和检测因变量的变化及设置对照实验和重复实验。
2、学会用准确的语言阐明实验探究的结果。
实验难点:确定和控制对照实验中的自变量和无关变量,观察和检测因变量的变化。
实验方法:探究法、讨论法
材料与仪器:(略)
实验流程图:(略)
实验过程:(略)
实验结论:每种酶都有发挥自己活性的最适温度和最适pH,当温度过高或者过低,酶的活性都会下降,高温可以使酶永久失活,过酸或者是过碱,酶的活性也会下降。
十一、教学反思
1、通过本次实验使学生充分体会什么是自变量、因变量、无关变量以及是对照实验,有利于引导学生学会确认和控制变量,有助于培养学生的科学探究能力。
2、本次实验注重科学探究的过程,在教师的引导下学生通过讨论完善了实验设计方案,实验过程规操作,仔细观察实验现象,认真记录,充分体现了学生的主体性。
3.在本次探究的过程中对学生的能力提出了较高的要求,教师在巡视时要及时帮助学生解决探究实验过程中遇到的问题。