编译原理陈意云_课后答案2解析
编译原理陈意云课后答案.ppt

5
3.2
• 考虑文法 S -> aSbS|bSaS|ε (a) 为句子abab构造两个不同的最左推导, 以说明此文法二义 (b) 为abab构造对应的最右推导 (c) 为abab构造对应的分析树 (d) 这个文法产生的语言是什么
2019/3/22
luanj@
6
3.2 (续)
luanj@ 9
2019/3/22
3.4 (续)
• 该文法没有体现运算符 |、*、() 、并置的优 先级,因而是二义的。
R=>R|R=> a|R =>a|R*=>a|b* R=>R*=>R|R*=>a|R*=>a|b*
• E -> E’|’T | T T -> TF | F F -> F* | (E) | a | b
• (1) S=>aSbS=>abS=>abaSbS=>ababS=>abab (2) S=>aSbS=>abSaSbS=>abaSbS=>ababS=>abab • S=>aSbS=>aSb=>abSaSb=> abSab =>abab (2)
S a S ε b a S ε (1) 描述的语言是a,b数目相等的串 S b S ε S
S
( L S a L , ( L S a
2019/3/22 luanj@ 3
) S L , ) S a
3.1 (续) - (a,((a,a),(a,a)))
S =>(L) =>(L,S) =>(S,S) =>(a,S) =>(a,(L)) =>(a,(L,S)) =>(a,(S,S)) =>(a,((L),S)) =>(a,((L,S),S)) =>(a,((S,S),S)) =>(a,((a,S),S)) =>(a,((a,a),S)) =>(a,((a,a),(L))) =>(a,((a,a),(L,S))) =>(a,((a,a),(S,S))) =>(a,((a,a),(a,S))) =>(a,((a,a),(a,a))) S =>(L) =>(L,S) =>(L,(L)) =>(L,(L,S)) =>(L,(L,(L))) =>(L,(L,(L,S))) =>(L,(L,(L,a))) =>(L,(L,(S,a))) =>(L,(L,(a,a))) =>(L,(S,(a,a))) =>(L,((L),(a,a))) =>(L,((L,S),(a,a))) =>(L,((L,a),(a,a))) =>(L,((S,a),(a,a))) =>(L,((a,a),(a,a))) =>(S,((a,a),(a,a))) =>(a,((a,a),(a,a)))
编译原理第二版课后习答案教学文稿

编译原理第二版课后习答案《编译原理》课后习题答案第一章第 1 章引论第 1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第 2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
编译原理陈意云版答案

编译原理陈意云版答案一. 引言编译原理是计算机科学中的一门重要课程,它研究的是将高级语言源代码转换为机器能够理解和执行的目标代码的方法和技术。
编译原理的学习对于理解计算机系统的运行原理和提高程序开发效率具有重要意义。
本文将以陈意云版的答案作为参考,向大家介绍编译原理的相关知识。
二. 词法分析词法分析是编译的第一个阶段,它将源代码分解成一个个单词(Token)。
在陈意云版中,常用的词法分析方法有正则表达式和有限自动机。
正则表达式可以方便地描述语言的词法规则,而有限自动机可以用于实现对输入的扫描和匹配。
词法分析器还可以将未识别的字符输入报告为错误。
三. 语法分析语法分析是编译的第二个阶段,它将词法分析器产生的Token序列转化为语法树。
在陈意云版中,常用的语法分析方法是上下文无关文法和递归下降分析。
上下文无关文法用于描述语言的语法规则,而递归下降分析是一种自顶向下的语法分析方法。
语法分析器还可以检查语法错误,并生成错误报告。
四. 语义分析语义分析是编译的第三个阶段,它对语法树进行语义检查和语义处理。
在陈意云版中,常用的语义分析方法有类型检查和符号表管理。
类型检查用于检查表达式和语句中的类型错误,而符号表管理用于管理变量和函数的定义和引用。
语义分析器还可以生成中间代码。
五. 中间代码生成中间代码生成是编译的第四个阶段,它将源代码转化为一种中间形式的代码。
在陈意云版中,常用的中间代码形式有三地址码和虚拟机代码。
中间代码是一种介于源代码和目标代码之间的形式,它可以方便地进行优化和生成目标代码。
六. 代码优化代码优化是编译的第五个阶段,它对中间代码进行优化,以提高程序的执行效率和减少代码的大小。
在陈意云版中,常用的代码优化技术有常量传播、公共子表达式消除和循环优化等。
代码优化器可以根据优化规则对中间代码进行优化,并生成优化后的中间代码。
七. 目标代码生成目标代码生成是编译的最后一个阶段,它将中间代码转化为目标代码。
编译原理教程课后习题答案第二章
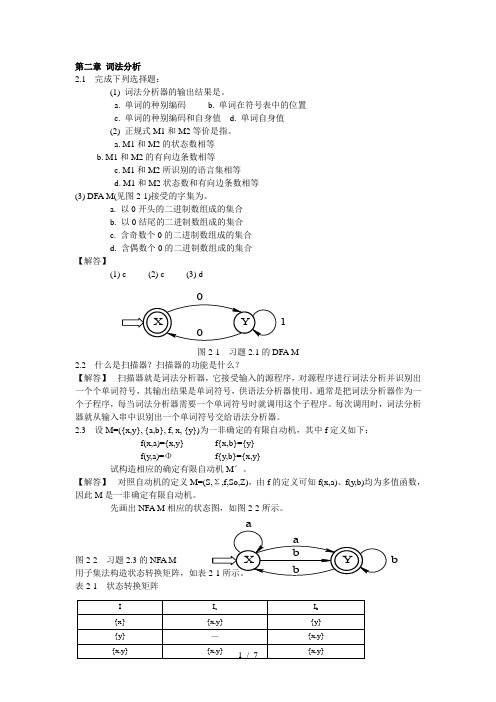
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
编译原理陈意云_课后答案2.

2021/4/13
luanj@
22
3.15
• (a) 用3.1的文法构造(a,(a,a))的最右推导, 说出每个右句型的句柄
• (b) 给出对应(a)的最右推导的移进-归约分 析器的步骤
• (c) 对照(b)的移进-归约,给出自下而上构 造分析树的步骤。
2021/4/13
➢ 期望的是: if expr then if expr then matched_stmt else if expr then matched_stmt else stmt
2021/4/13
luanj@
13
3.5 (续)
• 一种推导,和期望的不一样
➢ stmt
=> matched_stmt => if expr then matched_stmt else stmt => if expr then if expr then matched_stmt else stmt else stmt => if expr then if expr then matched_stmt else if expr then stmt else stmt => if expr then if expr then matched_stmt else if expr then matched_stmt else stmt
2021/4/13
luanj@
S
( L) L,S
S ( L)
aL
,
S
S
( L)
( L) L , S
L , SS
a
S
aa
4
a
3.1 (续)
• 描述的语言: 括号匹配的串,串中的各项由”,”隔开,
《编译原理》课后习题答案第二章

有代表性的符号串:a,a0,aa,a00,a0a,aa0
习题2
3.(1)E T T/F F/F (E)/F (E+T)/F (T+T)/F (F+F)/F (i+i)/i
(2)E E+T E+T+T E+T*F+F E+T*F+i E+T*T*F+i
M:M(0,a)=1 M(0,b)=2
M(1,a)=1 M(1,b)=4
M(2,a)=1 M(2,b)=3
M(3,a)=3 M(3,b)=2
M(4,a)=0 M(4,b)=5
M(5,a)=5 M(5,b)=1
化简:
1.分化
① {0,1} {2,3,4,5}
② {0,1} {2,4} {3,5}
2.合并
=M(M(D,1),1011)
=M(M(C,1),011)
=M(M(F,0),11)
=M(M(E,1),1)
=M(C,1)
=F
∴DFA D能接受字符串0011011
8.解:将状态转换图列表,即:
由左图可知,该状态转换图直接对应的是确定有穷状态自动机DFA
DFA D=({0,1,2,3,4,5},{a,b},M,0,{0,1})
A::=bc|bAc
(2)Z::=AB
A::=ab|aAb
B::=b|Bb
7. 解:题中要求文法是:
Z::=1|3|5|7|9|Z1|Z3|Z5|Z7|Z9|A1|A3|A5|A7|A9
A::=2|4|6|8|A0|A2|A4|A6|A8|Z0|Z2|Z4|Z6|Z8
编译原理第二章习题答案解析

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。
编译原理第二章-课后题答案

第二章3.何谓“标志符”,何谓“名字”,两者的区别是什么答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=86.令文法G6为N-〉D|NDD-〉0|1|2|3|4|5|6|7|8|9(1)G6的语言L(G6)是什么(2)给出句子0127、34、568的最左推导和最右推导。
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}}(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 0127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127(其他略)7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-NN->ABC|CC->1|3|5|7|9A->C|2|4|6|8B->BB|0|A|ε[注]:可以有其他答案。
[常见的错误]:N->2N+1原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为E->T|E+T|E-TT->F|T*F|T/FF->(E)|i(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
(2)给出i+i+i、i+i*i和i-i-i的语法树,并给出短语,简单短语和句柄。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
23
3.15 (续) (a) (b)
S =>(L) =>(L,S) =>(L,(L)) =>(L,(L,S)) =>(L,(L,a)) =>(L,(S,a)) =>(L,(a,a)) =>(S,(a,a)) =>(a,(a,a))
栈
$
• 下面文法是否LL(1)文法?说明理由 S -> AB|PQx A -> xy B -> bc P -> dP|ε Q -> aQ|ε
2018/10/21
luanj@
21
3.11 (续)
• 不是LL(1)文法 • LL(1)文法:对于产生式A->α|β (1) FIRST ( ) FIRST ( )
• (1) S=>aSbS=>abS=>abaSbS=>ababS=>abab (2) S=>aSbS=>abSaSbS=>abaSbS=>ababS=>abab • S=>aSbS=>aSb=>abSaSb=> abSab =>abab (2)
S a S ε b a S ε (1) 描述的语言是a,b数目相等的串 S b S ε S
2018/10/21 luanj@ 14
3.5 (续)
• 另一种推导
stmt => if expr then stmt => if expr then matched_stmt => if expr then if expr then matched_stmt else stmt => if expr then if expr then matched_stmt else matched_stmt => if expr then if expr then matched_stmt else if expr then matched_stmt else stmt if expr then if expr then matched_stmt else if expr then matched_stmt else stmt
a S
b S ε (2) a
b
S ε
S
ε
2018/10/21
luanj@
7
3.4
• 文法 R->R’|’R | RR | R* | (R) | a | b 产生字母表(a, b)上所有不含ε的正规式 该文法是二义的 (a) 证明该文法产生字母表{a,b}上的所有正 规式 (b) 为该文法写一个等价的非二义文法。 (c) 按照上面的两个文法构造ab|b*a的分析 树
S ( L S a L S L , ) S
(
L
, (
)
S L , ) S
(
L S
L
,
)
S a
L S a
a
2018/10/21
luanj@
4
a
3.1 (续)
• 描述的语言: 括号匹配的串,串中的各项由”,”隔开, 项可以是括号匹配的子串或a
2018/10/21
luanj@
luanj@ 9
2018/10/21
3.4 (续)
• 该文法没有体现运算符 |、*、() 、并置的优 先级,因而是二义的。
R=>R|R=> a|R =>a|R*=>a|b* R=>R*=>R|R*=>a|R*=>a|b*
• E -> E’|’T | T T -> TF | F F -> F* | (E) | a | b
S
( L S a L , ( L S a
2018/10/21 luanj@ 3
) S L , ) S a
3.1 (续) - (a,((a,a),(a,a)))
S =>(L) =>(L,S) =>(S,S) =>(a,S) =>(a,(L)) =>(a,(L,S)) =>(a,(S,S)) =>(a,((L),S)) =>(a,((L,S),S)) =>(a,((S,S),S)) =>(a,((a,S),S)) =>(a,((a,a),S)) =>(a,((a,a),(L))) =>(a,((a,a),(L,S))) =>(a,((a,a),(S,S))) =>(a,((a,a),(a,S))) =>(a,((a,a),(a,a))) S =>(L) =>(L,S) =>(L,(L)) =>(L,(L,S)) =>(L,(L,(L))) =>(L,(L,(L,S))) =>(L,(L,(L,a))) =>(L,(L,(S,a))) =>(L,(L,(a,a))) =>(L,(S,(a,a))) =>(L,((L),(a,a))) =>(L,((L,S),(a,a))) =>(L,((L,a),(a,a))) =>(L,((S,a),(a,a))) =>(L,((a,a),(a,a))) =>(S,((a,a),(a,a))) =>(a,((a,a),(a,a)))
5
3.2
• 考虑文法 S -> aSbS|bSaS|ε (a) 为句子abab构造两个不同的最左推导, 以说明此文法二义 (b) 为abab构造对应的最右推导 (c) 为abab构造对应的分析树 (d) 这个文法产生的语言是什么
2018/10/21
luanj@
6
3.2 (续)
2018/10/21 luanj@ 15
3.8(a)
• 消除3.1的左递归
2018/10/21
luanj@
16
3.8(a) (续)
• S -> (L)|a L -> L,S|S • 只有直接左递归 S -> (L)|a L -> SL’ L’-> ,SL’|ε
2018/10/21 luanj@ 8
3.4 (续)
• 证明该文法产生字母表{a,b}上的所有正规式 证明: 1)该文法产生的串是字母表{a,b}上的正规式 R->a和R->b产生a,b,而a,b是{a,b}上的符号,因此是正规式。 若R1,R2产生正规式α,β 则: R->R1R2产生正规式αβ R->R1|R2产生正规式α|β R->R1* 产生正规式α* R->(R1)产生正规式 (α) 2)字母表{a,b}上的所有正规式都可由此文法产生 字母表{a,b}上的任一正规式(其中α,β 为正规式)必为以下形式之一: αβ ,可由R->RR产生 α|β ,可由R->R|R产生 α*,可由R->R*产生 (α),可由R->(R)产生 a,可由R->a产生 b,可由R->b产生 因而,该文法产生字母表{a,b}上的所有正规式
期望的是: if expr then if expr then matched_stmt else if expr then matched_stmt else stmt
2018/10/21
luanj@
13
3.5 (续)
• 一种推导,和期望的不一样
stmt => matched_stmt => if expr then matched_stmt else stmt => if expr then if expr then matched_stmt else stmt else stmt => if expr then if expr then matched_stmt else if expr then stmt else stmt => if expr then if expr then matched_stmt else if expr then matched_stmt else stmt if expr then if expr then matched_stmt else if expr then matched_stmt else stmt
2018/10/21
luanj@
19
3.10 (续)
int D T
D -> TL
real
D -> TL
id
,
$
T -> int
T -> real
L
R
2018/10/21
L -> idR R -> ε
20
R -> ,idR
luanj@
3.11
$( $(a $(S
输入
(a,(a,a))$ a,(a,a))$ ,(a,a))$ (a,a))$
动作
移进
移进 归约:S->a 归约:L->S
$(L
$(L, $(L,( $(L,(a
,(a,a))$
(a,a))$ a,a))$ ,a))$
luanj@
2018/10/21 luanj@ 2
3.1 (续) - (a,(a,a))
S =>(L) S =>(L) =>(L,S) =>(L,S) =>(S,S) =>(L,(L)) =>(a,S) =>(L,(L,S)) =>(a,(L)) =>(L,(L,a)) =>(a,(L,S)) =>(L,(S,a)) =>(a,(S,S)) =>(L,(a,a)) =>(a,(a,S)) =>(S,(a,a)) =>(a,(a,a)) =>(a,(a,a))
(2)若 * ,那么FIRST ( ) FOLLOW ( )