因子分析和聚类分析实例解译
调研中的因子分析与聚类分析应用

调研中的因子分析与聚类分析应用在现代社会中,随着数据的快速增长和信息的爆炸式增加,如何从海量数据中提取有价值的信息成为一项重要的任务。
因子分析和聚类分析是两种常用的数据分析方法,它们可以帮助研究者对数据进行分类和理解,从而提炼出重要的因素和模式。
本文将分别对因子分析和聚类分析的应用进行探讨,并分析其在调研中的实际应用价值。
因子分析是一种用于研究变量之间关联性的统计方法。
它的目的是通过将变量聚集成更少的无关因子,以便提供更简化的数据分析结果。
在调研中,因子分析可以帮助我们发现隐藏在数据背后的潜在特征和结构,并从中找出一些重要的因素。
以市场调研为例,我们可以通过因子分析来确定顾客的消费行为和购买偏好。
通过对大量数据进行因子分析,我们可以得到一些关键因素,比如消费者的品牌偏好、价格敏感度、购买意愿等。
这些因素可以帮助企业更好地了解消费者,并制定相应的市场策略。
聚类分析是一种基于相似性度量的数据分析方法,它可以将相似的对象分为一组,同时将不相似的对象分到不同的组。
在调研中,聚类分析可以帮助我们对调查样本进行分类,从而揭示出不同类别的特点和差异。
举个例子,假设我们进行了一项关于消费者购买习惯的调研,通过聚类分析,我们可以将消费者分为不同的群组,比如高消费群体、低消费群体、品牌忠诚群体等。
这些群体的特点和差异可以帮助企业更好地了解不同消费者群体的需求,并针对性地制定营销策略。
因子分析和聚类分析在调研中具有很强的补充性。
通过因子分析,我们可以挖掘数据背后的因素和结构,发现其中的规律和模式。
而通过聚类分析,我们可以将样本进行分类,找到样本之间的相似性和差异性。
两者结合起来可以帮助我们更全面地理解和解释数据。
当然,在使用因子分析和聚类分析时,也需要注意一些问题。
选择合适的变量和样本是非常关键的。
我们需要确保选取的变量具有一定的相关性,同时样本的大小和代表性也会影响到分析结果的准确性和可靠性。
在解释结果时,需要进行充分的解读和分析,而不仅仅依赖于统计结果。
聚类和因子分析

一种是输出树形图(Dendrogram)
树形图以树的形式展现聚类分析的每一次合并过程, SPSS首先将各类之间的距离换到 0~25之间,然后再近似 地表示在图上。树形图可以粗略地表现聚类的过程。选中 Dendrogram项,即可输出树形图。
一种是输出冰柱图(Icicle)
冰柱图通过表格中的“X”符号显示,其样子很像冬天房 屋下的冰柱。SPSS默认输出聚类全过程的冰柱图(ALL clusters)。 选择Specified range of clusters项,并输入从第 几类开始显示 (Start:),到第几类结束显示(Stop),中间 几个几类(By:),则可以指定显示聚类中某一阶段的冰柱 图。如果选择None则不输出冰柱图。
在Measure框中选择计算样本距离的方法,选项如下: interval适合于连续性变量,系统提供8种方法供用户 选择 1 Euclidean distance,欧氏距离。 2 Squared Euclidean distance(系统默认方式),欧氏距 离平方。 3 Cosine:变量矢量的余弦,这是模型相似性的度量。 4 Pearson correlation:相关系数距离,适用于R型聚类。 5 Chebychev,Chebychev距离。 6 Block:City-Block或Manhattan距离。 7 Minkowski,Minkowski距离。 8 Customized, 362.1 1,156.1 1,440.0
绢云绿泥片岩
褐铁矿化片岩 绢云绿泥片岩 绢云绿泥片岩 绢云绿泥片岩
17
18 19 20 21
0.31
0.45 0.56 0.95 0.27
18.7
92.7 102.4 100.4 67.0
因子分析、聚类分析

主轴和主成分
正如二维椭圆有两个主轴, 正如二维椭圆有两个主轴 , 三维椭球 有三个主轴一样, 有几个变量, 有三个主轴一样 , 有几个变量 , 就有 几个主轴。 几个主轴。 和二维情况类似, 和二维情况类似 , 高维椭球的主轴也 是互相垂直的。 是互相垂直的。 这些互相正交的新变量是原先变量的 线 性 组 合 , 叫 做 主 成 分 (principal component)。 。
hi =
∑a
j =1
ij
成绩数据( 成绩数据(student.txt) )
100个学生的数学、物理、化学、语文、历史、 个学生的数学、物理、化学、语文、历史、 个学生的数学 英语的成绩如下表(部分) 英语的成绩如下表(部分)。
SPSS数据形式 数据形式
目前的问题是, 目前的问题是,能否把这个数据的 6 个变量用一两个综合变量来表示 呢? 这一两个综合变量包含有多少原来 的信息呢? 的信息呢? 能否利用找到的综合变量来对学生 排序或据此进行其他分析呢? 排序或据此进行其他分析呢?
空间的点
例中数据点是六维的; 例中数据点是六维的;即每个观测 值是6维空间中的一个点 维空间中的一个点。 值是 维空间中的一个点 。 希望把 6维空间用低维空间表示。 维空间用低维空间表示。 维空间用低维空间表示 先假定只有二维,即只有两个变量, 先假定只有二维,即只有两个变量, 由横坐标和纵坐标所代表; 由横坐标和纵坐标所代表; 每个观测值都有相应于这两个坐标 轴的两个坐标值; 轴的两个坐标值;
1 2 3
p
x2 = a21 f1 + a22 f 2 + ......a2 k f k + µ2 ..................................................... x p = a p1 f1 + a p 2 f 2 + ......a pk f k + µ p 用矩阵表示为X = AF + ε
聚类分析、对应分析、因子分析、主成分分析spss操作入门

Within-group linkage:组内平均连接法
• • • •
•
Байду номын сангаас
以两类个体两两之间距离的平均数作为类间距离。 d (d1 d 2 d 3 d 9 ) 9
将两类个体合并为一类后,以合并后类中所有个体之间的 平均距离作为类间距离。 d (d1 d 2 d 3 d 4 d 5 d 6 ) 6
输出结果
当采用“特征根大于1”的 方法提取因子时,所有变 量的共同度过均较高,各 变量的丢失信息较少,效 果理想。
此操作目的在于检验原始变量之 间是否存在一定线性关系,若线性 关系不显著,则不适合做因子分析
20
输出结果
看correlation矩阵,若对角线上元素的值较接近1,其 他大多数元素的绝对值均较小,说明变量之间相关性较 强,适合做因子分析。
因子 编号 特征 根值 方差 贡献率 累积方差 贡献率
23
软件操作
Method:因子旋转的方法,Varimax—方差最大 法, Quartimax— 四次方最大法, Equamax— 等量 最大法, Display:输出与因子旋转相关的信息,Rotated solution— 旋 转 后 的 因 子 载 荷 矩 阵 , Loading plot(s)—旋转后的因子载荷散点图
聚类输出结果
初始类中心情况 中心点偏移情况
最终类中心情况
最终类成员情况
15
基本介绍: 一种数据简化的技术; 将原有变量中的信息重叠部分提取并综合成因子,实现减少变量个数的目的; 提取出来的因子能够反映原来众多变量的主要信息; 原始的变量是可观测的显在变量,而提取因子是不可观测的潜在变量;
使用SPSS软件进行因子分析和聚类分析的方法

使用SPSS软件进行因子分析和聚类分析的方法一、方法原理1.因子分析(FactorAnalysis)因子分析是从多个变量指标中选择出少数几个综合变量指标的一种降维的多元统计方法。
我们在多元分析中处理的是多指标的问题,观察指标的增加是为了使研究过程趋于完整,但由于指标太多,使得分析的复杂性增加;同时在实际工作中,指标间经常具备一定的相关性,使得观测数据所放映的信息有重叠,故人们希望用较少的指标代替原来较多的指标,但依然能放映原有的全部信息,于是就产生了因子分析方法。
2.聚类分析(ClusterAnlysis)聚类分析是根据事物本身特性来研究个体分类的统计方法,是按照物以类聚的原则来研究的事物分类。
3.市场细分方法的流程图二、实证分析已调查35个城市的总人口、生产总值、消费总额、人均年工资、年度储蓄总额、年度财政总收入等数据,试对上述城市进行分类研究。
1.因子分析:·选用Analyze→DataReduction→Factor……·引入因子分析的6个变量(总人口、生产总值、消费总额、人均年工资、年度总储蓄额、年度财政总收入)·提取公因子的方法(Method):主成分分析法·提取(Extract)可选:提取特征值大于1的因子·旋转(Rotation)的方法:方差最大正交旋转·因子得分(FactorScores):作为新变量存入表 1 方差解释表(Total Variance Explained)表 2 旋转后的因子负荷矩阵(Rotated Component Matrix)2.聚类分析:·选用Analyze→Classify→K-MeansCluster……·引入聚类分析的2个变量(即上面的2个公因子)·聚类的数目(NumberofClusters):3类·聚类方法(Method):仅分类·储存新变量(SaveNewVariables):聚类成员表 3 各类数量分布表(Number of Cases in each Cluster)3.均值多重比较:·选用Analyze→CompareMeans→One-WayANOVA……·将2个因子移入因变量,3个类移入“Factor”·多重比较方法(MultipleComparisons):邓肯法Duncan 表 4 3个类对于因子1的重视程度比较表 5 3个类对于因子2的重视程度比较4.综合。
实验 聚类分析与因子分析

实验聚类分析一、实验目的学习利用SPSS进行聚类分析。
二、实验内容及实验步骤(一)系统聚类法(Hierarchical Cluster过程)实验内容:29名儿童的血红蛋白(g/100ml)与微量元素(μg/100ml)测定结果如下表。
由于微量元素的测定成本高、耗时长,故希望通过聚类分析(即R型指标聚类)筛选代表性指标,以便更经济快捷地评价儿童的营养状态。
编号N0. 钙X1镁X2铁X3锰X4铜X5血红蛋白X61 2 3 4 5 6 7 8 910111213141516171819202122232425262728 54.8972.4953.8164.7458.8043.6754.8986.1260.3554.0461.2360.1769.6972.2855.1370.0863.0548.7552.2852.2149.7161.0253.6850.2265.3456.3966.1273.8930.8642.6152.8639.1837.6726.1830.8643.7938.2034.2337.3533.6740.0140.1233.0236.8135.0730.5327.1436.1825.4329.2728.7929.1729.9929.2931.9332.94448.70467.30425.61469.80456.55395.78448.70440.13394.40405.60446.00383.20416.70430.80445.80409.80384.10342.90326.29388.54331.10258.94292.80292.60312.80283.00344.20312.500.0120.0080.0040.0050.0120.0010.0120.0170.0010.0080.0220.0010.0120.0000.0120.0120.0000.0180.0040.0240.0120.0160.0480.0060.0060.0160.0000.0641.0101.6401.2201.2201.0100.5941.0101.7701.1401.3001.3800.9141.3501.2000.9181.1900.8530.9240.8171.0200.8971.1901.3201.0401.0301.3500.6891.15013.5013.0013.7514.0014.2512.7512.5012.2512.0011.7511.5011.2511.0010.7510.5010.2510.009.759.509.259.008.758.508.258.007.807.507.2529 47.31 28.55 294.70 0.005 0.838 7.00实验步骤:1.建立数据文件。
兰大管理学院因子聚类案例分析

基于因子分析与聚类分析的辽宁省区域经济综合评价姓名:专业:学号:基于因子分析与聚类分析的辽宁省区域经济综合评价(兰州大学管理学院信息管理与信息系统)摘要:以2010年辽宁省经济数据为基础,采用因子分析与聚类分析相结合的方法对辽宁省区域经济的发展现状进行了实证分析与综合评估。
本研究结果可为下一步辽宁省政府出台政策以提振区域经济发展及平衡地区差异提供决策参考。
关键词:区域经济;因子分析;聚类分析;在辽宁省现辖的14 个城市中,区域经济发展存在着很大的差距。
本文采用因子分析与聚类分析相结合的方法,对辽宁省区域经济的发展状况进行综合评价,旨在为辽宁经济的可持续发展提供决策参考。
1.方法原理因子分析是一种主要用于数据化简和降维的多元统计分析方法。
它将相关性较强的几个变量归在同一个类中,每一类赋予新的名称,成为一个因子,反映事物的一个方面,或者说一个维度。
这样少数的几个因子就能够代表数据的基本结构,反映信息的本质特征。
更可以进一步从原始观测量的信息推出因子的值,然后用这些因子代替原来的变量进行其他统计分析。
聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类的分析技术。
系统聚类法是聚类分析诸方法中用的最多的一种,其基本思想是:开始将n 个样品各自作为一类,并规定样品之间的距离和类与类之间的距离,然后将距离最近的两类合并成一个新类,计算新类与其他类的距离;重复进行两个最近类的合并,每次减少一类,直至所有的样品合并为一类。
2.实证分析2.1样本数据的选取本文选取以下9 项指标:X1:年平均人口(万人),X2:地区生产总值(万元),X3:人均地区生产总值(元),X4:地方财政一般预算内收入(万元),X5:全社会固定资产投资总额(万元),X6:社会消费品零售总额(万元),X7:当年实际使用外资金额(万美元),X8:城镇居民人均可支配收入(元),X9:农民家庭人均收入(元)。
原始数据如下表1所示:2.2样本数据的处理考虑到各指标数据的差异以及使得分析结果更加有效,首先将样本数据进行标准化处理,处理后的数据消除了量纲之间的差异(表2所示)。
聚类分析实例讲解
聚类分析一、分析背景Chrysler公司为了赢得市场竞争地位,决定推出新产品Viper,该种产品的目标客户是雅皮士阶层。
为了进一步了解这种人群的心理特征,定位自己的产品,吸引目标客户,Chrysler公司进行了一次市场调研。
研究者使用九点量表测量400名被试者对30项陈述的态度,从而了解这些目标客户的心理特征。
调研还询问被试者对Dodge Viper型汽车的态度来测量标准变量,标准变量的测量通过九点量表来测试消费者对“我愿意购买Chrysler公司生产的Dodge Viper型汽车”的态度。
本次分析的目的是:通过聚类分析,将原始变量分别聚成三类和四类,比较两种方法的效果。
同时,比较使用原始变量得到的聚类结果和使用因子得分得到的聚类结果,看哪一种方法能更好地解释数据。
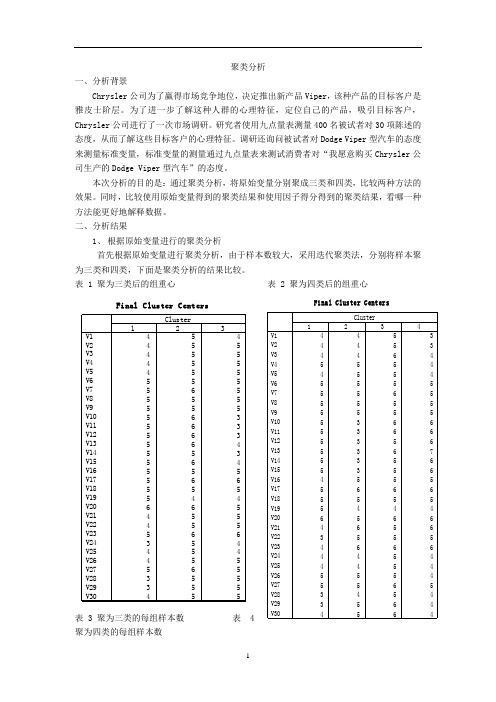
二、分析结果1、根据原始变量进行的聚类分析首先根据原始变量进行聚类分析,由于样本数较大,采用迭代聚类法,分别将样本聚为三类和四类,下面是聚类分析的结果比较。
表 1 聚为三类后的组重心表 2 聚为四类后的组重心表 3 聚为三类的每组样本数表聚为四类的每组样本数表5 聚为三类后组重心之间的距离 表 6 聚为四类后组重心之间的距离由方差分析的结果(结果略)可知,在聚为三类和四类的分析中,V8,V9,V18,V19,V20和V27的组间差异均大于0.05,结果不显著。
2、 根据因子得分进行的聚类分析以下是根据因子得分,采用迭代法将样本聚为三类和四类的结果:表7 聚为三类后的组重心-.45298 .16364 .29950 .36038 -.22794 -.15239 .28739 -.32881 .00765 .25444 .70915 -.87203 .52946 -.29355 -.26021 .18363 .11953 -.28471 .00228 .20936 -.18616 .56772-.64844.01414消费因子 时尚因子 社会因子 爱国因子 期望因子 偏好因子 个性因子 家庭因子12 3 Cluster表 8 聚为三类时的样本数 137.000 123.000 140.000 400.000 .0001 2 3ClusterValidMissing以下是根据因子得分聚为四类的结果:从以上用因子得分的结果可以看出,聚为三类和四类时八个因子的组间差异都很显著。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
地球化学数据因子分析和聚类分析实例解译编写人:刘红杰QQ:498236930内蒙古第三地质矿产勘查开发院第*节元素组合(元素的共生组合特征)及分类特征元素组合是元素亲合性在地质体内的具体表现,而元素亲合性又与地质环境有关[16]。
确定成矿及伴生元素的组合特征是确定成矿最佳地球化学标志元素组合的前提,为了研究本区元素的共生组合规律和区域成矿的特点,我们对全区的样品进行了相关分析,聚类分析和因子分析。
具体结果如下:一、相关分析作为地质作用的微观结果,地球化学信息必然与地质信息相关连。
相关分析是一种简单而直接的研究元素亲合性的方法。
本次研究对所测13个元素进行了相关分析,用新疆金维软件计算了各元素之间的相关系数,计算之前首先对原始数据进行标准化,计算结果见表1。
表1 阿尔山市三十公里等三幅1:5万化探相关系数矩阵Pb Mn Cu Sn Mo Ag Zn Co W As Bi Hg AuPb 1 0.2786 0.0813 0.1417 0.191 0.358 0.4656 -0.0455 0.1938 0.047 0.1198 0.0616 0.0054 Mn 1 0.1315 0.1385 0.0768 0.195 0.4076 0.2994 0.098 0.0991 0.0339 0.0751 0.0012 Cu 1 -0.0189 0.0198 0.2198 0.2738 0.4897 -0.0296 0.0644 0.0413 0.0192 0.1754 Sn 1 0.2043 0.133 0.1401 -0.0795 0.3298 0.046 0.1488 0.0452 -0.0166 Mo 1 0.1883 0.067 -0.0397 0.2436 0.201 0.2649 0.1648 0.0788 Ag 1 0.2594 -0.0032 0.1693 0.1534 0.2909 0.2333 0.1169 Zn 1 0.2384 0.1364 0.0191 0.0784 0.0269 0.007 Co 1 -0.1361 0.0544 -0.0401 -0.0383 -0.0113 W 1 0.1694 0.1807 0.0779 0.0145 As 1 0.0331 0.0308 0.0638 Bi 1 0.7183 -0.0082 Hg 1 0.0275 Au 1由表1可知:Pb与Zn、Ag、Mn呈正强相关;W与Mo、Sn呈明显正相关. Bi与Mo、Ag 元素之间呈正相关, Hg、Bi元素呈显著正相关。
Co与Cu、Zn、Mn之间相关性也较好.二、聚类分析聚类分析以变量之间的相似程度为基础,将变量分成不同级别的类或点群,直观地对变量进行分类。
据元素聚类谱系图(图)可见R=0.2783为界可分六簇。
第一簇Pb、Zn、Mn、Ag:为一组低中温、中高温元素组合,Pb与Zn密切相关,反映Pb、Zn、Mn、Ag元素的富集主要与中低温热液成矿作用有关,组合异常的出现是测区寻找Pb、Zn多金属矿床的重要地球化学找矿标志。
第二簇W、Sn、Mo:亲酸性岩高中温元素组合说明区内中酸性岩浆活动频繁,该类元素组合异常的出现可作为钼多金属矿的找矿标志。
第三簇Bi、Hg:铋是方铅矿的重要载体矿物,高温成因的方铅矿中铋和银的含量都比较高。
汞与断裂构造有关。
也可作为寻找铅银矿的前缘指示元素,同时,也反映出Pb、Zn 多金属的成矿与中酸性含矿岩浆热液沿构造充填作用有关。
第四簇Cu、Co:铜、钴谱系图上为相关性好,与其它元素相关性差,其富集主要与中基性火山岩有关,在构造有利部位Cu、Co有富集成矿的可能。
第五簇As与Pb、Zn、Mn、As和W、Sn、Mo有一定的相关性,反映其成因复杂,高温和中温热液阶段均有富集。
第六簇Au:金与其它元素相关性差,说明Au元素为独立成矿期。
谱 系 图三、因子分析因子分析实际上是一种降维分析,是将存在复杂关系的较多变量依据某种内在联系生成几种新的变量一、AP4聚类分析AP4----点群分析成果(R型聚类分析)元素名称:Pb Mn Cu Sn Mo Ag Zn Co W As Bi Hg Au原始数据做标准化变换!样品数(N): 501变量数(M): 13相关对连结表1. Pb --- Zn 0.65032. Pb --- Ag 0.49053. Pb --- Mn 0.50094. Cu --- Co 0.40165. Pb --- Cu 0.36066. Mo --- As 0.33777. Sn --- Bi 0.3038 8. Sn --- Mo 0.30259. Sn --- W 0.3013 10. Pb --- Sn 0.324111. Hg --- Au 0.1258 12. Pb --- Hg 0.0461AP4聚类分析据元素聚类谱系图(图)可见R=0.2938为界了可分四组,第一组元素为Pb、Zn、Ag、Mn、Cu、Co、Sn、Bi八种元素。
具中、高温气成~热液元素组合特征。
第二组元素为Mo、As、W三种元素。
Mo、(As)、W与酸性岩有关,说明区内后期酸性岩浆岩发育。
为Pb、Zn 等元素富集成矿提供了热源。
第三组元素为Hg元素与区内成矿元素Pb、Zn呈负相关性。
第四组为Au元素与区内所分析元素除Mo、Hg外均呈负相关性。
第一组八种元素可分为四个亚组:第一亚组Pb、Zn、Ag、Mn元素组合:铅锌银是区内的主要成矿富集元素,相关系数最大(0.6503),说明密切程度最高。
锰是主要的伴生元素。
从元素特性分析,Pb、Zn、Ag、均在气成~热液作用阶段析出,在空间上与碳酸盐地层有密切关系。
区内已所发现的含铅锌银矿体为矽卡岩,将说明了区内矿产与碳酸盐地层有关第二亚组Cu、Co元素组合:铜、钴在谱系图上呈相关组合元素,其元素特性不具相关性,铜与热液活动有关,在还原条件下富集。
钴在区内黑色粘土中富集。
第三亚组Sn元素:锡与酸性岩具有密切的成矿专属性,花岗岩中Sn十分明显的集中在黑云母中,说明区内后期酸性岩发育。
第四亚组Bi元素:方铅矿是铋的重要载体矿物(查光片报告),高温成因的方铅矿中秘和银的含量都比较高。
铋与铅银关系密切,是寻找铅银矿的重要指示元素。
AP4---因子分析元素名称: Pb Mn Cu Sn Mo Ag Zn Co W As Bi Hg Au铅 锰 铜 锡 钼 银 锌 钴 钨 砷 铋 汞 金变量数(M): 13 样品数(N): 501累积因子方差贡献百分比(%): 85.0初始因子载荷矩 F01 F02 F03 F04 F05 F06 F07 F08 F09 F10 F11 F12 F13 Pb 0.6279 -0.4648 -0.2039 -0.1982 0.1585 -0.1675 0.0260 0.0341 -0.3034 0.1296 -0.2410 -0.1257 -0.2667 Mn 0.6459 -0.3270 0.2586 0.3490 0.0753 0.1069 0.0472 0.1606 0.1577 -0.1264 0.2127 -0.3932 0.0372 Cu 0.6367 0.2022 0.3231 -0.2124 -0.2118 0.0435 -0.1997 -0.3955 0.0478 -0.0553 -0.3312 -0.1283 0.1721 Sn 0.3457 0.3786 -0.3608 0.1005 -0.2193 0.2929 0.6564 0.0612 0.0022 -0.0716 -0.1499 -0.0274 0.0044 Mo 0.2747 0.4779 -0.2746 0.0688 0.3757 -0.5666 -0.0540 0.1342 0.0205 -0.3526 -0.0684 -0.0162 0.0562 Ag 0.6603 -0.2297 0.0134 -0.2303 -0.0487 -0.2615 0.1701 -0.1375 0.5211 0.0659 0.0988 0.2053 -0.1084 Zn 0.7181 -0.4571 -0.1454 -0.0417 0.0484 0.0251 0.0360 0.1374 -0.2434 0.0214 0.0822 0.2383 0.3258 Co 0.4551 0.1609 0.6503 0.3567 -0.0397 0.0820 0.0297 -0.0332 -0.2227 -0.2363 0.0357 0.2548 -0.1869 W 0.4273 0.1076 -0.4126 0.1482 0.1582 0.5340 -0.4395 0.1748 0.2111 -0.0507 -0.1170 0.1093 -0.0833 As 0.4311 0.5316 0.0950 0.4174 0.1895 -0.1400 -0.0175 0.0094 -0.0197 0.5386 0.0274 -0.0040 0.0341 Bi 0.4929 0.4283 -0.3017 -0.3960 -0.1964 0.0720 -0.1397 -0.1929 -0.2083 -0.0294 0.4116 -0.0754 -0.0772 Hg 0.1318 0.2961 0.4353 -0.5865 -0.1176 0.0211 -0.0164 0.5814 0.0381 0.0704 -0.0457 -0.0167 0.0029 Au -0.0800 0.0810 0.2286 -0.3696 0.7791 0.3245 0.2124 -0.1949 0.0017 -0.0061 0.0461 -0.0029 0.02466No. 特征值 公因子方差 累积因子方差贡献百分比 选择主因子号公因子方差1 3.2057 1.0000 24.6595 0.74622 1.5950 1.0000 36.9288 0.75793 1.3746 1.0000 47.5030 0.83894 1.2367 1.0000 57.0161 0.97165 0.9916 1.0000 64.6435 0.86726 0.9396 1.0000 71.8716 0.66057 0.7661 1.0000 77.7647 0.77068 0.6880 1.0000 83.0567 0.79349 0.5898 1.0000 87.5938 0.920310 0.5244 1.0000 91.6275 0.707611 0.4460 1.0000 95.0582 0.774712 0.3697 1.0000 97.9017 0.991213 0.2728 1.0000 100.0000 0.9972主因子方差贡献F1 F2 F3 F4 F5 F6 F7 F82.3043 1.3910 1.6564 1.2835 1.0060 1.0874 1.0603 1.00867AP11 点群分析成果(R型聚类分析)元素名称:Pb Mn Cu Sn Mo Ag Zn Co W As Bi Hg Au原始数据做标准化变换!样品数(N): 272变量数(M): 13相关对连结表1. Mn --- Zn 0.54732. Pb --- Mn 0.54543. Cu --- Co 0.53464. Cu --- Sn 0.33115. Ag --- Bi 0.31796. Mo --- As 0.29667. Cu --- Ag 0.27328. Pb --- Cu 0.28609. Pb --- Mo 0.2080 10. Pb --- W 0.1743 11. Hg --- Au 0.0139 12. Pb --- Hg -.10458初始因子载荷矩阵F01 F02 F03 F04 F05 F06 F07 F08 F09 F10 F11 F12 F13Pb 0.5046 -0.2883 -0.5823 0.0322 0.2533 -0.0765 0.0243 -0.2066 0.0129 0.1152 0.1667 -0.4091 0.0174 Mn 0.6477 -0.5066 -0.1840 0.0226 0.0892 -0.0102 -0.0958 0.0269 0.0063 -0.3138 -0.3552 0.0711 -0.2043 Cu 0.6746 0.2152 0.3980 -0.2486 -0.2626 0.0496 0.0112 0.0693 -0.2104 0.1141 0.2398 -0.0774 -0.2852 Sn 0.5422 0.3490 0.1992 -0.0045 0.0496 0.0687 -0.5052 -0.4888 -0.0842 -0.1195 0.0112 0.0750 0.1267 Mo 0.2550 0.3060 -0.1283 0.6647 0.3075 -0.0126 0.0114 0.1913 -0.4582 0.1626 -0.1092 0.0575 0.0095 Ag 0.4446 0.3902 -0.2914 0.0567 -0.2181 -0.5522 -0.0589 0.2954 0.1144 -0.2602 0.1736 0.0473 0.0750 Zn 0.6485 -0.4371 -0.2356 -0.1490 0.0854 0.1586 0.1688 0.0141 0.0054 0.1559 0.2328 0.4004 0.1039 Co 0.5583 -0.3805 0.4968 -0.0727 -0.2873 0.0377 0.0367 0.2447 -0.1138 0.0192 -0.1574 -0.1999 0.2611 W 0.2491 0.3386 -0.2620 0.1305 -0.5561 0.0859 0.5254 -0.3365 -0.0383 -0.0372 -0.1682 0.0127 0.0219 As 0.3753 0.2658 0.3225 0.3644 0.3649 0.3953 0.2509 0.0914 0.3276 -0.2447 0.1360 -0.0728 0.0067 Bi 0.4737 0.5182 -0.0926 -0.3517 0.2165 -0.0221 -0.0377 0.1242 0.3159 0.3447 -0.3030 0.0087 -0.0011 Hg -0.1277 0.3152 -0.2464 -0.6715 0.3129 0.2106 0.1591 0.1144 -0.3395 -0.2635 -0.0159 -0.0440 0.0717 Au -0.0602 0.0952 -0.5108 0.1095 -0.4524 0.5459 -0.3739 0.2566 0.0558 0.0076 0.0317 -0.0437 0.0005 No. 特征值 公因子方差 累积因子方差贡献百分比 选择主因子号公因子方差1 2.8653 1.0000 22.0406 0.79112 1.6518 1.0000 34.7469 0.72853 1.4774 1.0000 46.1116 0.79794 1.2723 1.0000 55.8987 0.95685 1.1674 1.0000 64.8785 0.74836 0.8512 1.0000 71.4264 0.881297 0.8040 1.0000 77.6114 0.75048 0.6870 1.0000 82.8961 0.85379 0.6145 1.0000 87.6231 0.968210 0.5074 1.0000 91.5264 0.809011 0.4725 1.0000 95.1611 0.689512 0.3993 1.0000 98.2324 0.808013 0.2298 1.0000 100.0000 0.9939 选择主因子个数: 8正交因子载荷矩阵F01 F02 F03 F04 F05 F06 F07 F08Pb 0.8363 -0.7048 2.6933 1.7520 -0.2382 -0.7766 -0.4479 -0.5366Mn 0.7821 -0.4954 0.3399 0.0536 -0.5249 -0.4259 0.1339 1.9168Cu 0.0436 -0.0880 0.4956 -0.9080 -0.6651 -0.5469 -0.3615 -0.2308Sn 0.0851 -0.1204 -0.0321 -0.3648 5.5866 0.1813 -0.5447 -0.3431Mo 0.0767 1.3564 -0.6268 -0.5782 -0.1874 1.3619 -0.2886 -0.5319Ag 0.0932 -0.3869 -0.6088 -0.2205 0.9258 1.1830 -0.3824 -0.5061Zn 0.7952 2.7702 0.7367 0.1916 -0.4998 2.0052 -0.6003 -0.3821Co 0.2237 0.1346 -0.1973 -0.0016 -0.5256 -0.2198 -0.7262 1.558410W 0.0293 -0.4067 -0.4535 0.7300 -0.4483 -0.2286 -0.4111 -0.4273 As 0.0136 -0.9676 -0.4704 0.2134 -0.2452 -0.0696 -0.5204 -0.5963 Bi 0.0949 -1.0007 -0.0932 -0.5190 -0.1635 -0.4789 -0.7711 -0.5326 Hg -0.0355 -0.6448 -0.4987 0.2722 -0.7516 -0.1263 -0.5068 -0.1443 Au 0.0169 -0.2698 -0.5330 -0.7968 -0.3375 -0.5716 -0.3824 0.7142主因子方差贡献F1 F2 F3 F4 F5 F6 F7 F82.0288 1.2879 1.6966 1.3279 1.0092 1.2063 1.0363 1.183611。