第四章 统计学 数据的概括性度量
【统计学】4.数据的概括性度量

【统计学】4.数据的概括性度量【统计学】4.数据的概括性度量4.1 集中趋势的度量4.2 离散程度的度量4.3 偏态与峰态的度量学习⽬标1.集中趋势各测度值的计算⽅法2.集中趋势各测度值的特点及应⽤场合3.离散程度各测度值的计算⽅法4.离散程度各测度值的特点及应⽤场合5.偏态与峰态的测度⽅法6.⽤excel 计算描述统计量并进⾏统计4.1 集中趋势的度量集中趋势(central tendency )1.⼀组数据向其中⼼值靠拢的倾向和程度,反映了⼀组数据中⼼点位置所在2.测度集中趋势就是寻找数据⽔平的代表值或中⼼值3.不同类型的数据不同的集中趋势测度值4.低层次数据的测度值适⽤于⾼层次的测量数据,但⾼层次的数据的测度值并不适⽤于低层次的测量数据4.1.1 分类数据:众数众数(mode )1.⼀组数据中出现次数最多的变量值2.⼀般仅适合数据量较多时使⽤3.不受极端值得影响4.⼀组数据可能没有众数或有⼏个众数(众数可能不唯⼀也可能不存在)5.主要⽤于分类数据(分类数据只对应分类的频数),也可⽤于顺序数据和数值型数据4.1.2 顺序数据:中位数和分位数中位数(median )1.⼀组数据排序后处于中间位置上的值2.中位数不受极端值的影响3.中位数主要⽤于顺序数据,也可⽤于数值型数据,但不适⽤于分类数据中位数(位置和数值的确定)排序位置确定n +12数值确定M e =x (n +12),n 为奇数12[x (n2)+x (n2+1)],n 为偶数因此中位数不⼀定是原数据中的某个变量值四分位数(quartile)1.排序后处于25%和75%位置上的值2.不受极端值的影响3.计算公式Q L 位置=n4,Q U 位置=3n4,4.如果是在0.25或0.75的位置上,则四分位数等于该位置的下侧值加上按⽐例分摊位置两侧数值的差值(加权平均数概念){{4.1.3 数值型数据:平均数平均数(mean )1.也称为均值2.集中趋势的最常⽤测度值3.⼀组数据的均衡点所在4.体现了数据的必然性5.易受极端值的影响6.有简单平均数和加权平均数之分7.根据总体数据计算,称为平均数,即为µ,根据样本数据计算的,称为样本平均数,即为x 简单平均数(算数平均数)设⼀组数据为:x 1,x 2,...x n (总体数据x N )样本平均数¯x =x 1+x 2+...+x n n =∑n i =1x i n 总体平均数µ=x 1+x 2+...+x N N =∑Ni =1x iN加权平均数(Weighted mean )设各组的组中值为:M 1,M 2,...,M k 相应的频数为:f 1,f 2,...f k 样本加权平均¯x =M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑k i =1M i f in总体加权平均µ=M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑⼏何平均数(geometric mean )1. n 个变量值乘积的n 次⽅根2. 适⽤于对⽐率数据的平均3. 主要⽤于计算平均增长率4. 计算公式为G =nx 1×x 2×...×x n =nn∏i =1xi4.1.4众数、中位数和平均数的⽐较1. 众数不受极端值影响具有不唯⼀性数据量较⼤时众数才有意义数据分布偏斜程度较⼤且有明显峰值时应⽤2. 中位数不受极端值影响数据分布偏斜程度较⼤时应⽤3. 平均数利⽤了全部数据信息,数学性质优良易受极端值影响数据对称分布或接近对称分布时应⽤4.2 离散程度的度量离中趋势1.数据分布的⼀个重要特征2.反映各变量值远离其中⼼值的程度(离散程度)3.从另⼀个侧⾯说明了集中趋势测度值的代表程度4.不同类型的数据有不同的离散程度测度值4.2.1 分类数据:异众⽐率异众⽐率(variation ratio )1. 对分类数据离散程度的测度2. ⾮众数组的频数占总频数的⽐例3. 计算公式v r =∑f i −f m ∑f i=1−f m∑f i4.⽤于衡量众数是否具有代表性4.2.2 顺序数据:四分位差四分位差(quartile deviation )1. 对顺序数据离散程度的测度2. 也称为内距或四分间距3. 上四分位数与下四分位数之差Q d =Q U −Q L4. 反映了中间50%数据的离散程度5. 不受极端值影响√√6. ⽤于衡量中位数是否具有代表性4.2.3 数值型数据:⽅差和标准差极差(range)1. ⼀组数值型数据的最⼤值和最⼩值之差2. 离散程度的最简单测度值3. 易受极端值影响4. 未考虑数据的分布,数据利⽤率低5. 计算公式为R=max(x i)−min(x i)标准差(mean deviation)1. 各变量值与其平均数离差绝对值的平均数2. 能全⾯反映⼀组数据的离散程度3. 数学性质差,实际应⽤较少4. 计算公式未分组数据M d=∑n i=1|x i−¯x|n组距分组数据Md=∑k i=1|M i−¯x|fin⽅差和标准差(variance and standard deviation)1. 各变量与其平均数离差平⽅的平均数2. 数据离散程度的最常⽤测度值3. 反映了各变量与均值的平均差异4. 根据总体数据计算的,称为总体⽅差(标准差)σ2(σ)根据样本数据计算的,称为样本⽅差(标准差)s2(s)⽅差的计算公式未分组数据s2=∑n i=1(x i−¯x)2n−1组距分组数据s2=∑k i=1(M i−¯x)2fin−1标准差的计算公式未分组数据s=∑n i=1(x i−¯x)2n−1组距分组数据s=∑k i=1(M i−¯x)2fin−1为什么是除以n-1⽽不是n?⾃由度(degree of freedom)1. ⾃由度是指数据个数与附加给独⽴观测值的约束或限制的个数之差2. 从字⾯涵义看,⾃由度是指⼀组数据中可以⾃由取值的个数3. 当样本数据的个数为n时,若样本平均数确定后,则附加给n个观测值的约束个数就是1个,因此只有n-1个数据可以⾃由取值,其中必有⼀个数据不能⾃由取值。
统计学第五版课后答案(贾俊平)

第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学第4章学习指导
第4章(数据的概括性度量)学习指导数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。
掌握计算、特点及其应用场合。
主要内容学习要点2.1 集中趋势的度量众数▶概念:众数。
▶众数的特点。
中位数和分位数▶概念:中位数,四分位数。
▶中位数和四分位数的特点。
▶中位数和四分位数的计算。
平均数▶概念:平均数,简单平均数,加权平均数,调和平均数,几何平均数。
▶简单平均数和加权平均数的计算。
▶用Excel中的统计函数计算平均数。
▶几何平均数的计算和应用场合。
众数、中位数和平均数的比较▶众数、中位数和平均数在分布上的关系。
▶众数、中位数和平均数的特点及应用场合。
异众比率▶概念:异众比率异众比率的计算和应用场合。
2.2离散程度的度量四分位差(内距)概念:四分位差。
四分位差的计算。
用Excel中的统计函数计算四分位差。
方差和标准差概念:极差,平均差,方差,标准差。
样本方差和标准差的计算。
用Excel计算标准差。
离散系数概念:离散系数。
离散系数的计算。
离散系数的用途。
2.3偏态与峰态的度量偏态及其测度概念:偏态,偏态系数。
用Excel计算偏态系数。
偏态系数数值的意义。
峰态及其测度概念:峰态,峰态系数。
用Excel计算峰态系数。
峰态系数数值的意义。
Excel统计函数的应用。
一)判断题1,各变量值与其平均数的离差之和为最小值。
( )2.当各组的变量值所出现的频率相等时,加权算术平均数中的权数就失去作用,因而,加权算术平均数也就等于简单算术平均数( )3.比较两总体的平均数的代表性,离散系数较小的总体,平均数代表性亦小。
( )4,平均数与次数和的乘积等于各变量值与次数乘积的和。
( )5.若两总体的平均数不同,而标准差相同,则离散系数也相同。
( )6.并非任意一个变量数列都可以计算其算术平均数、中位数和众数。
贾俊平《统计学》考研真题(含复试)与典型习题详解(数据的概括性度量)【圣才出品】

2.统计学期中考试非常简单,为了评估简单程度,教师记录了 9 名学生交上考试试卷
的时间如下(分钟)
33 29
45 60 42 19 52 38 36[东北财经大学
2012 研]
(1)这些数据的极差为( )。
A.3.00
B.-3.00
C.41.00
D.-41.00
【答案】C
【解析】数据按从小到大排序结果如下:
A.0.38
B.0.40
C.0.54
D.2.48
【答案】A
【解析】离散系数也称为变异系数,它是一组数据的标准差与其相应的平均数之比。其
计算公式为: vs
s x
。得到 vs
22.85 0.38 。 12.45
9.已知某工厂生产的某零件的平均厚度是 2 厘米,标准差是 0.25 厘米。如果已知该 厂生产的零件厚度为正态分布,可以判断厚度在 1.5 厘米到 2.5 厘米之间的零件大约占 ( )。[浙江工商大学 2011 研]
圣才电子书 十万种考研考证电子书、题库视频学习平台
5.随机变量 X 的方差为 2,随机变量 Y=2X,那么 y 的方差是( )。[中央财经大学 2011 研]
A.1 B.2 C.4 D.8 【答案】D
【解析】Var(cX ) c2Var(X ) 22 2 8
7.设 X1,X2,…,X n 为随机样本,则哪个统计量能较好地反映样本值的分散程度( )。
[中山大学 2012 研] A.样本平均 B.样本中位数 C.样子书
【答案】C
十万种考研考证电子书、题库视频学习平台
【解析】集中趋势是指 一 组 数 据 向 某 一 中 心 值 靠 拢 的 程 度 ,它 反 映 了 一 组 数 据 中 心
第四章数据的概括性度量

第四章数据的概括性度量一、填空题1.一组数据向某一中心值靠拢的倾向反映了数据的———————。
2. ————是一组数据中出现次数最多的变量值。
3.一组数据排序后处于中间位置上的变量值称——————。
4.不受极端值影响的集中趋势度量指标有————、————和————。
5.一组数据的最大值与最小值之差称————。
6. —————是一组数据的标准差与其相应的平均数之比。
7.数据分布的不对称性是——————。
8.数据分布的平峰或尖峰程度称——————9.计算比率的平均数一般用—————,它实际上是各变量值对数的—————。
二、单项选择题1.对于对称分布的数据,众数、中位数和平均数的关系是:A.众数>中位数>平均数B.众数=中位数=平均数C.平均数>中位数>众数D.中位数>众数>平均数2.可以计算平均数的数据类型有:A.分类型数据B.顺序型数据C.数据型数据D.所有数据类型3.顺序数据的集中趋势测度指标有:A.众数B.中位数C.四分位差D.标准分数4.数据型数据的离散程度测度方法中,受极端变量值影响最大的是:A.极差B.方差C.均方差D.平均差5.当偏态系数为正数时,说明数据的分布是:A.正态分布B.左偏分布C.右偏分布D.双峰分布三、多项选择题1.数据的分布特征可以从哪几个方面测度和描述:A.集中趋势B.分布的偏态C.分布的峰态D.离散程度E.长期趋势2.受极端变量值影响的集中趋势度量指标是A.众数B.中位数C.算术平均数D.调和平均数E.几何平均数3.加权算术平均数大小的影响因素有:A.变量值B.样本容量C.权数D.分组的组数E.数据的类型4.数据型数据离散程度的测度指标有:A.异众比率B.极差C.标准差D.四分位数E.离散系数5.离散系数的主要作用是:A.说明数据的集中趋势B.比较不同计量单位数据的离散程度C.说明数据的偏态程度D.比较不同变量值水平数据的离散程度E.说明数据的峰态程度四、简答题1.什么是数据的集中趋势?反映数据集中趋势的指标有哪些?2.什么是数据的离散程度?常用的测度离散程度的指标有哪些?3.怎样理解平均数在统计学中的地位4.简述众数、中位数和均值的特点和应用场合。
统计学第四章习题答案 贾俊平
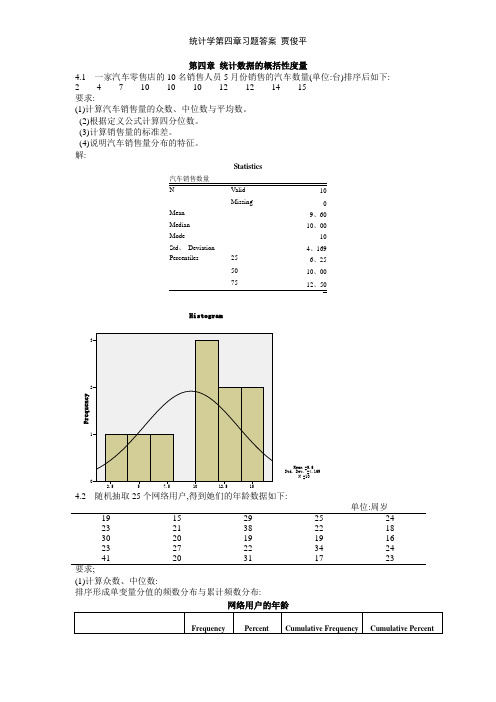
第四章 统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下: 2 4 7 10 10 10 12 12 14 15 要求:(1)计算汽车销售量的众数、中位数与平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量 10 Missing0 Mean 9、60 Median 10、00Mode10 Std 、 Deviation 4、169 Percentiles25 6、25 50 10、00 75单位:周岁19 15 29 25 24 23 21 38 22 18 30 20 19 19 16 23 27 22 34 24 41 20 3117 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布与累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6、25,因此Q1=19,Q3位置=3×25/4=18、75,因此Q3=27,或者,由于25与27都只有一个,因此Q3也可等于25+0、75×2=26、5。
(3)计算平均数与标准差;Mean=24、00;Std、Deviation=6、652(4)计算偏态系数与峰态系数:Skewness=1、080;Kurtosis=0、773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6、652、呈右偏分布。
如需瞧清楚分布形态,需要进行分组。
1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4、3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图::一种就是所有颐客都进入一个等待队列:另—种就是顾客在三千业务窗口处列队3排等待。
统计学各章计算题公式及解题方法

统计学各章计算题公式及解题方法第四章数据的概括性度量1.组距式数值型数据众数的计算:确定众数组后代入公式计算:下限公式:;上限公式:,其中,L为众数所在组下限,U为众数所在组上限,为众数所在组次数与前一组次数之差,为众数所在组次数与后一组次数之差,d为众数所在组组距2.中位数位置的确定:未分组数据为;组距分组数据为3.未分组数据中位数计算公式:4.单变量数列的中位数:先计算各组的累积次数(或累积频率)—根据位置公式确定中位数所在的组—对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在该组内均匀分布)5.组距式数列的中位数计算公式:下限公式:;上限公式:,其中,为中位数所在组的频数,为中位数所在组前一组的累积频数,为中位数所在组后一组的累积频数6.四分位数位置的确定:未分组数据:;组距分组数据:7.简单均值:8.加权均值:,其中,为各组组中值统计学各章计算题公式及解题方法9.几何均值(用于计算平均发展速度):10.四分位差(用于衡量中位数的代表性):11.异众比率(用于衡量众数的代表性):12.极差:未分组数据:;组距分组数据:13.平均差(离散程度):未分组数据:;组距分组数据:14.总体方差:未分组数据:;分组数据:15.总体标准差:未分组数据:;分组数据:16.样本方差:未分组数据:;分组数据:17.样本标准差:未分组数据:;分组数据:18.标准分数:19.离散系数:第七章参数估计1.的估计值:置信水平α90%0。
1 0。
05 1。
654 95%0。
05 0.025 1。
9699%0.01 0。
005 2。
58统计学各章计算题公式及解题方法2.不同情况下总体均值的区间估计:总体分布样本量σ已知σ未知大样本(n≥30)正态分布小样本(n〈30)非正态分布大样本(n≥30)其中,查p448 ,查找时需查n—1的数值3.大样本总体比例的区间估计:4.总体方差在置信水平下的置信区间为:5.估计总体均值的样本量:,其中,E为估计误差6.重复抽样或无限总体抽样条件下的样本量:,其中π为总体比例第八章假设检验1.总体均值的检验(已知或未知的大样本)[总体服从正态分布,不服从正态分布的用正态分布近似]假设双侧检验左侧检验右侧检验假设形式已知统计量未知拒绝域值决策,拒绝2.总体均值检验(未知,小样本,总体正态分布)假设双侧检验左侧检验右侧检验假设形式统计学各章计算题公式及解题方法已知统计量未知拒绝域值决策,拒绝注:已知的拒绝域同大样本3.一个总体比例的检验(两类结果,总体服从二项分布,可用正态分布近似)(其中为假设的总体比例)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝4.总体方差的检验(检验)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝5.统计量的参考数值0。
贾俊平《统计学》(第7版)考点归纳和课后习题详解(含考研真题)-第四章至第六章【圣才出品】

第4章数据的概括性度量4.1考点归纳【知识框架】【考点提示】(1)集中趋势、离散趋势的度量指标,包括每个指标的含义、计算公式、特点、意义、适用范围(选择题、简答题、计算题考点);(2)众数、中位数和平均数三个指标的特点和应用场合,偏态分布下三个指标的关系(选择题、简答题、计算题考点);(3)分布形状的测度指标:偏态系数和峰态系数的数值含义(选择题、简答题考点)。
(4)标准分数的计算公式及应用(选择题、简答题、计算题考点);(5)经验法则、切比雪夫不等式的具体应用(选择题考点)。
【核心考点】考点一:集中趋势的度量表4-1集中趋势度量指标【注意】不同偏态程度的分布中集中趋势度量指标的关系:①对称分布中,众数、中位数和平均数相等;②左偏分布中,数据存在极小值,拉动平均数向极小值一方靠,而众数和中位数不受极值的影响,有_x<M e<M o;③右偏分布中,数据存在极大值,必然拉动平均数向极大值一方靠,因此M o<M e<_x。
【知识拓展】不同的教材分位数的计算公式不同,除了表中的计算公式,一种比较精确的计算公式:下四分位数Q L的位置=(n+1)/4,上四分位数Q U的位置=(3n+1)/4。
【真题精选】假定标志值所对应的权数都缩小1/10,则算术平均数()。
[浙江财经大学2019研]A.不变B.无法判断C.缩小百分之一D.扩大十倍【答案】A【解析】假设标志值为x,其对应的权数为f,则算术平均数为_x=∑xf/∑f;若各权数都缩小1/10,则新的算术平均数为110110xf xf x x f f '===∑∑∑∑考点二:离散程度的度量数据的离散程度反映了各变量值远离其中心值的程度,离散程度越小,代表性就越好。
表4-2离散程度的度量指标【注意】①表中方差和标准差的计算公式均为样本数据的方差和标准差。
若为总体数据,则分母应为n。
②标准差系数,也称变异系数或离散系数。
③表中平均差、样本方差、样本标准差仅给出了未分组数据的计算公式,分组数据的计算公式实质是等于未分组数据的计算公式,会运用即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、作用 •使不能直接对比的现象找到共同的比 较基础; •用来进行宏观经济管理和评价经济活 动的状况。
三、相对指标的基本表现形式 有名数 用双重计量单位表示的复名数 无名数 用倍数、系数、成数、﹪、‰等表示 分母 为1 分母为 1.00 分母 为10 分母 为100 分母为 1000
统计学认为,数据的分布特征,可以从三个方面 进行测度和描述: 一是数据的分布中心在哪里?越靠近中心数据越 密集,我们把这种特征称谓集中趋势,中心值可 以代表数据的一般水平; 二是一般数据偏离其中心程度有多大?我们把数 据分布偏远离其中心值的程度称谓离中趋势,离 散值可以代表数据的变异程度; 三是分布的偏态和峰度,她们也反映数据分布形 状的差异。
5 42
原始数据: 25
分类数据的众数 (例题分析)
不同品牌饮料的频数分布 饮料品牌 频数 比例 百分比 (%)
解:这里的变量为“
饮料品牌”,这是个 分类变量,不同类型 的饮料就是变量值 所 调 查 的 50 人 中 , 购买碳酸饮料的人数 最 多 , 为 15 人 , 占 总 被调查人数的 30% ,因 此众数为“可口可乐 ”这一品牌,即
本章教学重点与难点
重点
1.集中趋势、离散程度的各测度值的特点 2.集中趋势、离散程度的应用场合,计算方法
难点
利用Excel计算数据的描述统计量并进行分析
统计分析方法概述 (补充内容)
统计分析方法一般根据统计数据的维 度,可以分为单变量数据分析方法、 双变量数据分析方法和多变量变量数 据分析方法。另外,截面数据和时序 数据的分析方法也有所不同。根据以 上综述,可将统计分析方法分为如下 几种类型:
集中趋势(central tendency)
1. 一组数据向其中心值靠拢的倾向和程度
2. 测度集中趋势就是寻找数据水平的代表值或中心值
3. 不同类型的数据用不同的集中趋势测度值
4. 低层次数据的测度值适用于高层次的测量数据,但 高层次数据的测度值并不适用于低层次的测量数据
分类数据:众数
众数(mode)
说 明
⒈为无名数; ⒉同一总体各组的结构相对数之和为1; ⒊用来分析现象总体的内部构成状况。
2、比例相对数
比例 总体中某一部分数值 100 ﹪ 相对数 总体中另一部分数值
例:我国某年国民收入使用额为19715亿元,其中 消费额为12945亿元,积累额为6770亿元。则
积累额与消费额 6770 17 100 ﹪ 1 : 2或 51.52 ﹪ 12945 33 的比率
(2)有名数 的强度相对数
为用双重计量单位表示的复名数, 反映的是一种依存性的比例关系或 协调关系,可用来反映经济效益、 经济实力、现象的密集程度等。
例:某地区某年末现有总人口为100万人,医院 床位总数为24700张。则该地区
每千人口拥有 24700 张 24.7张 千人 (正指标) 千人 的医院床位数 1000
果汁 矿泉水 绿茶 其他 碳酸饮料 合计
6 10 11 8 15 50
0.12 0.20 0.22 0.16 0.30 1
12 20 22 16 30 100
Mo=碳酸饮料
顺序数据的众数 (例题分析)
甲城市家庭对住房状况评价的频数分布 回答类别 甲城市 户数 (户) 百分比 (%)
解:这里的数据为顺 序数据。变量为“回 答类别” 甲城市中对住房 表示不满意的户数最 多 , 为 108 户 , 因 此 众数为“不满意”这 一类别,即
1、按反映的基本内容不同 总体单位总数 总体所包含的总体单位的数
量
总体各单位某一数量标志 总体标志总量 的标志值总和
注意:一个总体中只有一个单位总数,但可 以有多个标志总量,它们由总体单位的数量 标志值汇总而来。
2、按反映的时间状况不同
时期指标
表明现象总体在一段时期内发展过 程的总量,如在某一段时期内的出
甲公司商品销售额 5.4 1.5 是乙公司的倍数 3.6
说 明 ⒈为无名数,一般用倍数、百分数表示; ⒉用来说明现象发展的不均衡程度。
4、动态相对数(纵向对比)
是同类指标数值在不同时间 动态相对数 上的对比
动态 某指标报告期数值 100 ﹪ 相对数 该指标基期数值
说 明
⒈为无名数;
(四)双变量数据的因果关系分析方法(回归分 析,第十一章) 1.数值型数据的回归分析 2.数值型数据和属性数据的回归分析
(五)单变量时间序列数据的分析方法(第13章) 1.时间序列的描述性分析 2.时间序列的平稳性分析 3.平稳性序列的预测 4.有趋势序列的预测 5.复合型序列的分析
数据分布的特征
集中趋势 (位置) 离中趋势 (分散程度) 偏态和峰态 (形状)
数据分布特征的测度
数据特征的测度
集中趋势
众 数 中位数 平均数
离散程度
异众比率
分布的形状
偏 态
四分位差 方差和标准差 离散系数
峰 态
补充:指标的类型
总量指标
反映现象在一定时间、地点、 一、概念 条件下的总体规模或水平的 综合指标,即数量指标,也 称为绝对数。
t1时段
t2时段
t3时段
四、总量指标的计量单位 自然单位 如:台、件 大 差 实物单位 度量衡单位 如:米、平方米 适 综 如:标准吨 标准实物单位 用 合
范 围 能 力 小 强
劳动单位 如:工日、工时 价值单位 如:元
多个单位的结合运用:
复合单位 双重单位 多重单位
(如:人· 次、吨· 公里) (如:人/平方公里)
1. 一组数据中出现次数最多的变量值
2. 适合于数据量较多时使用 3. 不受极端值的影响 4. 一组数据可能没有众数或有几个众数 5. 主要用于分类数据,也可用于顺序数据和 数值型数据
众数(不惟一性)
无众数
原始数据: 10
一个众数
5
9
12
6
8
原始数据: 6
多于一个众数
5 8
9 28
8 36
5 42
生人数、死亡人数
具有可加性、数值大小与时期长短有 直接关系、需要连续登记汇总 时点指标 表明现象总体在某一时刻(瞬间) 的数量状况,如在某一时点的总
人口数
不具有可加性、数值大小与时期长短没 有直接关系、由一次性登记调查得到
关于一个人口总体的总量指标
时 出生人数 期 指 死亡人数 标 时 人口总数 点 指 t 标
⒉用来反映现象的数量在时间上的变动程度。
5、强度相对数
某一总量指标数值 的总量指标数值 相对数 另一有联系而性质不同
(1)无名数 的强度相对数
强度
一般用﹪、‰表示。
例:某年某地区年平均人口数为100万人,在该 年度内出生的人口数为8600人。则该地区
8600 1000 ‰ 8.6‰ 6 出生率 110 人口
计划完成程度 相对数
1、结构相对数
结构 总体部分数值 100 ﹪ 相对数 总体全部数值
例:我国某年国民收入使用额为19715亿元,其中 消费额为12945亿元,积累额为6770亿元。则
消费额占国民收入 12945 100 ﹪ 65.7﹪ 19715 使用额的比率 积累额占国民收入 6770 100 ﹪ 34.3 ﹪ 19715 使用额的比率
例3:己知某厂2000年的计划规定产品成本比上年降 低5%,实际降低6﹪。则
计划完成 1 6 ﹪ 100 ﹪ 98.95 ﹪ 即实际比计划单位 1 5 ﹪ 程度 成本下降了1.05%.
4.1
4.1.1 4.1.2 4.1.3 4.1.4
集中趋势的度量
分类数据:众数 顺序数据:中位数和分位数 数值型数据:平均数 众数、中位数和平均数的比较
每所医院床位 1 106 40.5人 张 负担的人口数 24700
(逆指标)
强度:人均GDP、人均粮食产量、资金利润率 密度:人口密度、商业网点密度、医疗网密度 普遍程度:电话普及率(2005年全国电话普及 率57部/百人)、私人汽车普及率
注意:强度相对数虽有“平均”的含 义,但它不是同质总体的标志总量与 总体单位数之比,所以不是平均数。
6、计划完成程度相对数
正指标:≥1,完成或超额完 成计划;
逆指标:≤1,完成或超额完 成计划;
计划完成程度 实际完成数 100 ﹪ 计划任务数 相对数
A.计划任务数表现为绝对数(平均数)时 直接应用上述公式:
例1:己知某厂2000年的计划产品产量为10万吨,实 际产量为12万吨。则:
计划完成 12 100 ﹪ 120 ﹪ 10 程度
非常不满意 不满意 一般 满意 非常满意
合计
24 108 93 45 30
300
8 36 31 15 10
100.0
Mo=不满意
数值型数据的众数 (例题分析)
例 某种商品的价格情况
价格 (元) 销售数量 (千克) 2.00 20 2.40 60 3.00 140 4.00 80 300 合计
第 4 章
4.1 4.2 4.3
数据的概括性度量
集中趋势的度量 离散程度的度量 偏态与峰态的度量
学习目标
1.集中趋势各测度值的计算方法 2.集中趋势各测度值的特点及应用场合 3.离散程度各测度值的计算方法 4.离散程度各测度值的特点及应用场合 5.偏态与峰态的测度方法 6.用Excel计算描述统计量并进行分析
(六)双变量时间序列数据的相关和回归方法 1.平稳序列的的相关和回归 2.非平稳序列的的相关和回归
(七)统计指数分析方法(第14章) (八)多变量数据分析方法 1.判别分析 2.因子分析 3.聚类分析