正则表达式快速记忆法
正则表达式快速入门

教程精选:正则表达式快速入门作者:开心石头出处:天极网责任编辑:wenwu[ 2005-12-02 11:06 ]【导读】正则表达式是从左向右去匹配目标字符串的一组模式。
大多数字符在模式中表示它们自身并匹配目标中相应的字符正则表达式广泛出现在UNIX/Linux相关的各种领域和多种编程语言里。
从常见的shell命令到大名鼎鼎的Perl语言再到当前非常流行的PHP,它都扮演着一个重要的角色。
甚至windows的命令行控制台也支持正则表达式。
如果你是一个Linux服务器管理员,你经常会在一些服务器的设置脚本里看到它。
可以说,它是学好Linux/UNIX必需掌握的一个知识点,否则你连Linux的启动脚本都读不懂。
偏偏它又的确有点晦涩难懂,而且相关的资料又大部分是英文,更为它的学习增加了几多困难。
即使有些中文的翻译资料,不同的译者对一些术语的译法也五花八门,读着让人平添困惑。
为此,我决定为它写一个简明教程,尽量可以覆盖正则表达式涉及到的各主要概念。
我并不想把本文写成一本详细的正则表达式语法手册,事实上,这些手册已经存在了,不过读起来比较难懂。
我希望的是在完成本教程后,你可以比较轻松的读懂各种工具的正则表达式语法手册并可以迅速上手,不过要用好正则表达式,可不是一篇短短的教程可以解决的,那是无数实践练习的结果。
但是,本文的最后一部分对于正则表达式的编写提出了一些原则性的建议,学习一下这些正则表达式应用先驱者的经验会让我们在今后的实践中少走一些弯路。
正则表达式是英文“regular expressions”的译文,它的产生据说可以追溯到“神经网络”等比较高深的理论。
那么什么是正则表达式呢?正则表达式是从左向右去匹配目标字符串的一组模式。
大多数字符在模式中表示它们自身并匹配目标中相应的字符。
举个最简单的例子,模式“The quick brown fox”匹配了目标字符串中与其完全相同的一部分。
前面已经提过,正则表达式被许多植根于UNIX/Linux的工具采用,可是这些工具的正则表达式语法并不完全相同,它们中的一些对正则表达式语法的扩展并不被其它工具识别,这也为正则表达式的使用增加了难度。
55分钟学会正则表达式

55 分钟学会正则表达式正则表达式(“regexes”)即增强查找/字符串替换操作。
当在文本编辑器中编辑文字时,正则表达式经常用 于: 检查文本是否包含一个给定的模式 查找任何匹配的模式 从文本中拉取信息(比如截断) 修改文本和文本编辑器一样,绝大多数高级编程语言支持正则表达式。
在本文中,“文本”仅仅是一个字符串变量,但 是有效的操作却是一致的。
某些编程语言(Perl,JavaScript)甚至为正则表达式提供专用的语法。
但是正则表达式是什么? 一个正则表达式仅仅为一个字符串。
它没有长度限制,但是通常该字符串很短。
下面看几个例子: I had a \S+ day today [A-Za-z0-9\-_]{3,16} \d\d\d\d-\d\d-\d\d v(\d+)(\.\d+)* TotalMessages="(.*?)" <[^<>]>这个字符串实际上是一个极小的计算程序,并且正则表达式是一门语法小而简洁,领域特定的编程语言。
牢 记以下几点,它们不该在学习过程中让你感到惊讶: 每个正则表达式都能分解成一串指令。
“找到这个,再找到那个,然后找到其中一个...” 一个正则表达式拥有输入(文本)和输出(模式匹配,和有些时候的自定义文本)。
存在语法错误——不是每个字符串都是合法的正则表达式! 语法有些怪异,也可以说是恐怖。
一个正则表达式有时候可以被编译以便更快运行。
正则实现一直有着显著的改变。
对于本文,我所关注的是那些几乎每个正则表达式都实现了的核心语法。
练习 获取一个支持正则的文本编辑器。
我推荐 Notepad++。
下载一篇很长的散文故事比如 Gutenberg 出版社出版的 H. G. Wells 的《时光机器》然后打开它。
下载一部字典,比如这个,解压然后打开。
一切准备就绪,稍后开始练习。
提示: 正则表达式与文件通配符语法完全不兼容,比如*.xml。
C#正则表达式基础知识(经典归纳简单易懂)

正则表达式基础知识目录前言 (4)System.Text.RegularExpressions命名空间 (4)Regex类 (5)RegexOption枚举 (5)构造函数 (5)IsMatch()方法 (6)Match()方法 (6)使用Match对象 (6)MatchObj.Success (6)MatchObj.Value (7)MatchObj.ToString() (7)MatchObj.Length (7)MatchObj.Index (7)MatchObj.Groups (7)使用Group对象 (7)GroupObj.Success (7)GroupObj.Value (8)GroupObj.ToString() (8)GroupObj.Length (8)GroupObj.Index (8)GroupObj.Captures (8)MatchObj.NextMatch() (8)MatchObj.Result (string) (8)特殊的Replacement字符串 (9)MatchObj.Synchronized() (9)MatchObj.Captures (9)Matchs()方法 (10)Replace()方法 (10)Split()方法 (11)正则表达式缓存 (11)辅助函数 (12)Regex.Escape(string) (12)Regex.Unescape(string) (12)Regex.Empty (12)pileToA ssembly(...).. (12)基本语法 (13)字符匹配语法 (13)重复匹配语法 (13)字符定位语法 (14)转义匹配语法 (14)其它匹配语法 (15)语法示例 (16)(1)“@”符号 (16)(2)基本的语法字符 (16)(3)定位字符 (17)(4)重复描述字符 (19)(5)择一匹配 (20)(6)特殊字符的匹配 (21)(7)组与非捕获组 (21)(8)贪婪与非贪婪 (23)(9)回溯与非回溯 (24)(10)正向预搜索、反向预搜索 (24)(11)十六进制字符范围 (26)(12)对[0,100]的比较完备的匹配 (26)(13)精确匹配有时候是困难的 (27)前言正则表达式(Regular Expression)是强大、便捷、高效的文本处理工具。
正则表达式记忆口诀

正则表达式记忆⼝诀正则其实也势利,削尖头来把钱揣;(指开始符号^和结尾符号$)特殊符号认不了,弄个倒杠来引路;(指\. \*等特殊符号)倒杠后⾯跟⼩w,数字字母来表⽰;(\w跟数字字母;\d跟数字)倒杠后⾯跟⼩d,只有数字来表⽰;倒杠后⾯跟⼩a,报警符号嘀⼀声;倒杠后⾯跟⼩b,单词分界或退格;倒杠后⾯跟⼩t,制表符号很明了;倒杠后⾯跟⼩r,回车符号知道了;倒杠后⾯跟⼩s,空格符号很重要;⼩写跟罢跟⼤写,多得实在不得了;倒杠后⾯跟⼤W,字母数字靠边站;倒杠后⾯跟⼤S,空⽩也就靠边站;倒杠后⾯跟⼤D,数字从此靠边站;倒框后⾯跟⼤B,不含开头和结尾;单个字符要重复,三个符号来帮忙;(* + ?)0 星加1 到⽆穷,问号只管0 和1;(*表0-n;+表1-n;?表0-1次重复)花括号⾥学问多,重复操作能⼒强;({n} {n,} {n,m})若要重复字符串,园括把它括起来;((abc){3} 表⽰字符串“abc”重复3次)特殊集合⾃定义,中括号来帮你忙;转义符号⾏不通,⼀个⼀个来排队;实在多得排不下,横杠请来帮个忙;([1-5])尖头放进中括号,反义定义威⼒⼤;([^a]指除“a”外的任意字符)1竖作⽤可不⼩,两边正则互替换;(键盘上与“\”是同⼀个键)1竖能⽤很多次,复杂定义很⽅便;园括号,⽤途多;反向引⽤指定组,数字排符对应它;(“\b(\w+)\b\s+\1\b”中的数字“1”引⽤前⾯的“(\w+)”)⽀持组名⾃定义,问号加上尖括号;(“(?<Word>\w+)”中把“\w+”定义为组,组名为“Word”)园括号,⽤途多,位置指定全靠它;问号等号字符串,定位字符串前⾯;(“\b\w+(?=ing\b)”定位“ing”前⾯的字符串)若要定位串后⾯,中间插个⼩于号;(“(?<=\bsub)\w+\b”定位“sub”后⾯的字符串)问号加个惊叹号,后⾯跟串字符串;PHPer都知道,!是取反的意思;后⾯不跟这⼀串,统统符合来报到;(“\w*d(?!og)\w*”,“dog”不符合,“do”符合)问号⼩于惊叹号,后⾯跟串字符串;前⾯不放这⼀串,统统符合来报到;点号星号很贪婪,加个问号不贪婪;加号问号有保底,⾄少重复⼀次多;两个问号⽼规矩,0次1次团团转;花括号后跟个?,贪婪变成不贪婪;还有很多装不下,等着以后来增加。
正则表达式完全学习手册

正则表达式完全学习手册:菜鸟入门指导正则表达式能够很恐怖,真得很恐怖。
幸运的是,一旦记住每一个符号所表达的意思,恐惧就会快速消退。
若是你对正则表达式一无所知,正如文章题目,那你又就有很多东西要学了。
下面让咱们马上开始吧。
第一节:基础学习想要高效地学习和掌握正则表达式的关键是花一天的时刻记居处有符号。
这可能是我所能提供的最好的建议。
坐下来,做些记忆卡片,然跋文住它们。
以下为最多见的一些符号:. - 匹配任意字符,换行符除外(如果dotall 为false)。
* - 该符号前面的字符,匹配0 次或多次。
+ - 该符号前面的字符,匹配1次或多次? - 该符号前面的字符是可选的。
匹配0 次或1 次。
\d - 匹配任何单个数字。
\w - 匹配任何一个字符(包括字母数字以及下划线)。
[XYZ] - 匹配字符组中的任意一个字符,即X、Y、Z 中的任意一个。
[XYZ]+ - 匹配字符组中的一个或多个字符。
$ - 匹配字符串结束的位置。
^ - 匹配字符串开始的位置。
[^a-z] - 当出现在字符类中时,^ 表示 NOT(非);对于该示例,表示匹配任何非小写字母。
很闷吧,不过仍是记住它们,记住以后你会明白益处的。
工具你以为一个表达式是正确的,超级正确,但就是无法取得想要的结果,这时你可能会产生将头发拔光的冲动。
去下载桌面应用程序吧,那个对你是必不可少的,而且玩起来超级有趣的。
它提供实时检查,还有一个侧边栏,里面包括了每一个字符的概念和用户,超级详细。
第二节:正则表达式傻瓜教程:抓屏视频下一步是学习如何真正地利用这些符号。
若是视频是你的偏好,那你走运了。
这里有五个课程的视频教程,超级适合你:“”。
(Jeffery Way:在这一系列视频教程中,我将交给你如安在JavaScript和PHP中高效的利用正则表达式。
我会假设你是从零开始。
)第三节:正则表达式和 JavaScript本节为最后一节,咱们来看看JavaScript 方式如何利用正则表达式。
js正则相关知识点专题
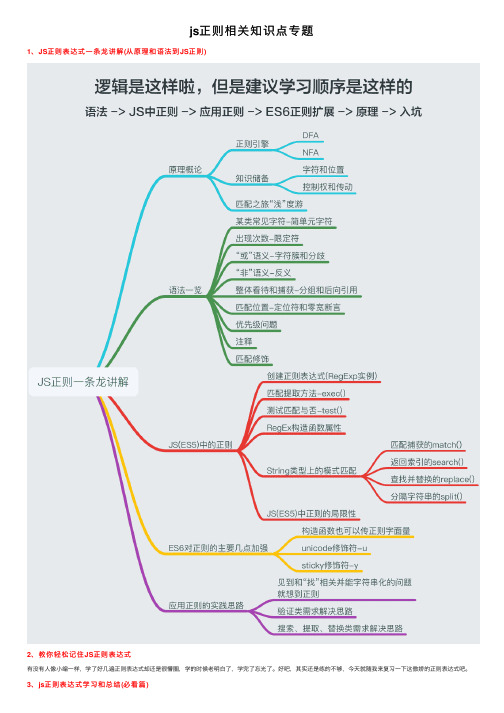
js正则相关知识点专题1、JS正则表达式⼀条龙讲解(从原理和语法到JS正则)2、教你轻松记住JS正则表达式有没有⼈像⼩编⼀样,学了好⼏遍正则表达式却还是很懵圈,学的时候⽼明⽩了,学完了忘光了。
好吧,其实还是练的不够,今天就随我来复习⼀下这傲娇的正则表达式吧。
3、js正则表达式学习和总结(必看篇)正则表达式是⼀种⽂本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。
模式描述在搜索⽂本时要匹配的⼀个或多个字符串。
RegExp 对象表⽰正则表达式,它是对字符串执⾏模式匹配的强⼤⼯具。
正则表达式是⼀种查找以及字符串替换操作。
4、15个常⽤的javaScript正则表达式(收藏)这篇内容给⼤家总结了15个常⽤的javaScript正则表达式,涵盖了经常⽤到的所有内容。
5、JS基础教程—正则表达式⽰例本⽂给⼤家分享js基础之正则表达式知识,以及在正则表达式中() [] {}所代表的意思6、JS正则表达式⼤全(整理详细且实⽤)vaScript动态正则表达式问题请问正则表达式可以动态⽣成吗?例如JavaScript中:var str = "strTemp";要⽣成:var re = /strTemp/;如果是字符连接:var re = "/" + str + "/"即可7、⽤js实现过滤script的正则function stripscript(s) {return s.replace(/<script.*?>.*?<\/script>/ig, '');}/之间的内容/ 是js正则语句的书写开始与结束.*?是贪婪的匹配,如果不是贪婪的就是.*匹配任何字符,但⽤贪婪的就是不包含>的内容/ig 是不区分⼤⼩写和全局替换8、JS正则表达式的验证//说明:除“XXX XX,XXX XX,XXX.00”格式外//为上⾯提供各个JS验证⽅法提供.trim()属性String.prototype.trim=function(){return this.replace(/(^\s*)|(\s*$)/g, "");}10、JS利⽤正则配合replace替换指定字符替换指定字符的⽅法有很多,在本⽂为⼤家详细介绍下,JS利⽤正则配合replace是如何做到的,喜欢的朋友可以参考下11、最常⽤的15个前端表单验证JS正则表达式在表单验证中,使⽤正则表达式来验证正确与否是⼀个很频繁的操作,本⽂收集整理了15个常⽤的JavaScript正则表达式,其中包括⽤户名、密码强度、整数、数字、电⼦邮件地址(Email)、⼿机号码、⾝份证号、URL地址、 IPv4地址、⼗六进制颜⾊、⽇期、 QQ号码、微信号、车牌号、中⽂正则。
正则表达式学习笔记(1)
正则表达式学习笔记(1)正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
列目录时,dir *.txt或ls *.txt中的*.txt就不是一个正则表达式,因为这里*与正则式的*的含义是不同的。
为便于理解和记忆,先从一些概念入手,所有特殊字符或字符组合有一个总表在后面,最后一些例子供理解相应的概念。
正则表达式是由普通字符(例如字符 a 到z)以及特殊字符(称为元字符)组成的文字模式。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
可以通过在一对分隔符之间放入表达式模式的各种组件来构造一个正则表达式,即/expression/普通字符由所有那些未显式指定为元字符的打印和非打印字符组成。
这包括所有的大写和小写字母字符,所有数字,所有标点符号以及一些符号。
非打印字符特殊字符所谓特殊字符,就是一些有特殊含义的字符,如上面说的"*.txt"中的*,简单的说就是表示任何字符串的意思。
如果要查找文件名中有*的文件,则需要对*进行转义,即在其前加一个\。
ls \*.txt。
正则表达式有以下特殊字符。
构造正则表达式的方法和创建数学表达式的方法一样。
也就是用多种元字符与操作符将小的表达式结合在一起来创建更大的表达式。
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
限定符限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
有*或+或?或{n}或{n,}或{n,m}共6种。
*、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
正则表达式的限定符有:定位符用来描述字符串或单词的边界,^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界。
正则表达式记忆方法
正则表达式记忆方法宝子!今天咱来唠唠正则表达式咋记。
正则表达式刚瞅的时候,就像一堆乱码似的,可吓人了。
咱先从那些基本的元字符开始哈。
像那个“.”,你就把它想成是个“小百搭”,它能匹配除了换行符之外的任何单个字符呢。
就好像是一个啥都能接的小助手,特别好记。
还有那个“*”,这就像是个贪心鬼。
它表示前面的字符可以出现零次或者多次。
你就想象它是个小馋猫,能把前面的字符吃好多好多遍,也可以一口都不吃。
比如说“a*”,那就是可以有好多好多的“a”,也可以一个“a”都没有。
“+”这个呢,和“*”有点像,但它至少得出现一次。
就好比是个有点小傲娇的家伙,必须得有,不能没有。
“a+”就是至少有一个“a”。
再来说说那些字符类。
“[]”里面放的就是一群字符,它表示匹配其中的任意一个字符。
你可以把它想象成是个小盒子,里面装着各种小宝贝,只要是盒子里的,都能被选中。
比如说“[abc]”,那就是“a”或者“b”或者“c”都能匹配到。
还有那个“^”,在方括号里面的时候,它就变成了“反着来”的意思。
比如说“[^abc]”,就是除了“a”“b”“c”之外的任何字符。
这就像一个叛逆的小娃娃,专门和里面的字符对着干。
要是说匹配数字呢,“\d”就很好记啦,你就想成是“digit(数字)”的缩写,它就是专门匹配数字的。
那要是想匹配非数字呢,“\D”就闪亮登场啦,它和“\d”就是相反的。
对于字母和数字的组合,“\w”就像是个小收纳盒,它能匹配字母、数字或者下划线。
你就想象它把这些都打包在一起了。
“\W”呢,自然就是和它相反的啦。
宝子,你看这么想的话,正则表达式是不是就没那么可怕啦?其实就把它当成是一群有个性的小卡通人物,每个都有自己独特的本事,记起来就容易多啦。
咱多玩几次,多试几次,慢慢就熟练掌握这个正则表达式的小世界啦。
正则表达式入门教程
正则表达式入门教程以下内容经正则表达式学习网授权≈正则表达式是什么?≈在使用电脑进行各种文字处理的时候,我们有时需要查找和匹配一些特殊的字符串,如邮箱地址、验证用户输入的密码是否包含了大小写字母和数字,查找HTML源文档中的所有web地址等等,这时我们就可以使用到正则表达式。
正则表达式本身是一个“字符串”,通过这个“字符串”去描述字符组成规则。
如abbb、abbbb、abbbbb这三个字符串包都是以a字母开头a后面有一个b字母,而且b字母重复了3到5次。
用正则表达式来描述就是ab{3,5},b{3,5}表示b字符重复3到5次。
如果我们想匹配ababab这样的字符串,ab重复了3次,用正则表达式表示就是(ab){3},圆括号()是正则表达式中的分组。
大家如果想亲自感受正则表达式的使用效果,可以打开正则表达式测试系统。
如以上实例所展示的,正则表达式为人们提供了一种简单易用的字符处理工具。
它在目前主流的文字处理软件中都提供了良好的支持(不仅是编程软件,还有文字处理软件Uedit32、EditPlus,网页采集软件火车头等等),它具有很强的通用性,学好它,我们可以达一变应万变的效果。
≈正则表达式详解≈像{},()这种在正则表达式中,具有特殊含义的字符称为元字符(metacharacter)。
元字符是组成正则表达式的基本元素,在正则表达式经常使用的元字符不是很多,概念容易理解。
大家只要花30来分钟学完我们的教程基本上就可以完全掌握。
为了您能更快速的掌握正则表达式,我们为您推荐一款方便的正则表达式在线测试工具“RegExr”,(RegExr由免费提供)。
保留字符匹配字符本身匹配字符数量匹配字符位置分组匹配表达式选项保留字符(返回目录)在正则表达式中,有一些字符在正则表达式中具有特殊含义被称保留字符,如*表示前一个元素可以重复零次或多次,要匹配“*”字符本身使用\*,半角句号.匹配除了换行符外的所有字符,要匹配“.”使用\.。
正则表达式快速学习方法(注释加亮版)
正则表达式使用详解(加亮注释版)1、入门简介简单的说,正则表达式是一种可以用于模式匹配和替换的强有力的工具。
我们可以在几乎所有的基于UNI X系统的工具中找到正则表达式的身影,例如,vi编辑器,Perl或PHP脚本语言,以及awk或sed shell程序等。
此外,象JavaScript这种客户端的脚本语言也提供了对正则表达式的支持。
由此可见,正则表达式已经超出了某种语言或某个系统的局限,成为人们广为接受的概念和功能。
正则表达式可以让用户通过使用一系列的特殊字符构建匹配模式,然后把匹配模式与数据文件、程序输入以及W EB页面的表单输入等目标对象进行比较,根据比较对象中是否包含匹配模式,执行相应的程序。
举例来说,正则表达式的一个最为普遍的应用就是用于验证用户在线输入的邮件地址的格式是否正确。
如果通过正则表达式验证用户邮件地址的格式正确,用户所填写的表单信息将会被正常处理;反之,如果用户输入的邮件地址与正则表达的模式不匹配,将会弹出提示信息,要求用户重新输入正确的邮件地址。
由此可见正则表达式在WEB应用的逻辑判断中具有举足轻重的作用。
2、基本语法匹配数目:”+”;”*”;”?”;匹配内容:”/s”;”/S”;”/d”; ”/w”;”/W”;”[]”;“|”;[^]匹配位置:”^”;”$”;”/b”;”/B”在对正则表达式的功能和作用有了初步的了解之后,我们就来具体看一下正则表达式的语法格式。
正则表达式的形式一般如下:/love/其中位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式。
用户只要把希望查找匹配对象的模式内容放入“/”定界符之间即可。
为了能够使用户更加灵活的定制模式内容,正则表达式提供了专门的“元字符”。
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
较为常用的元字符包括:“+”,“*”,以及“?”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
要想学会正则表达式,理解元字符是一个必须攻克的难关。
不用刻意记
.:匹配任何单个字符。
例如正则表达式“b.g”能匹配如下字符串:“big”、“bug”、“bg”,但是不匹配“buug”,“b..g”可以匹配“buug”。
[ ] :匹配括号中的任何一个字符。
例如正则表达式“b[aui]g”匹配bug、big和bag,但是不匹配beg、baug。
可以在括号中使用连字符“-”来指定字符的区间来简化表示,例如正则表达式[0-9]可以匹配任何数字字符,这样正则表达式“a[0-9]c”等价于“a[0123456789]c”就可以匹配“a0c”、“a1c”、“a2c”等字符串;还可以制定多个区间,例如“[A-Za-z]”可以匹配任何大小写字母,“[A-Za-z0-9]”可以匹配任何的大小写字母或者数字。
( ) :将()之间括起来的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域,这个元字符在字符串提取的时候非常有用。
把一些字符表示为一个整体。
改变优先级、定义提取组两个作用。
| :将两个匹配条件进行逻辑“或”运算。
'z|food'能匹配"z"或"food"。
'(z|f)ood'则匹配"zood"或"food"。
*:匹配0至多个在它之前的子表达式,和通配符*没关系。
例如正则表达式“zo*”能匹配“z”、“zo”以及“zoo”;因此“.*”意味着能够匹配任意字符串。
"z(b|c)*"→zb、zbc、zcb、zccc、zbbbccc。
"z(ab)*"能匹配z、zab、zabab(用括号改变优先级)。
+ :匹配前面的子表达式一次或多次,和*对比(0到多次)。
例如正则表达式9+匹配9、99、999等。
“zo+”能匹配“zo”以及“zoo”,不能匹配"z"。
? :匹配前面的子表达式零次或一次。
例如,"do(es)?"可以匹配"do"或"does"。
一般用来匹配“可选部分”。
{n} :匹配确定的n次。
"zo{2}"→zoo。
例如,“e{2}”不能匹配“bed”中的“e”,但是能匹配“seed”中的两个“e”。
{n,} :至少匹配n次。
例如,“e{2,}”不能匹配“bed”中的“e”,但能匹配“seeeeeeeed”中的所有“e”。
{n,m}:最少匹配n次且最多匹配m次。
“e{1,3}”将匹配“seeeeeeeed”中的前三个“e”
^(shift+6):匹配一行的开始。
例如正则表达式“^regex”能够匹配字符串“regex我会用”的开始,但是不能匹配“我会用regex”。
^另外一种意思:非!(暂时不用理解)
$ :匹配行结束符。
例如正则表达式“浮云$”能够匹配字符串“一切都是浮云”的末尾,但是不能匹配字符串“浮云呀”。