麦克风阵列语音识别方案_木瓜电子
《2024年基于麦克风阵列的语音增强研究》范文

《基于麦克风阵列的语音增强研究》篇一一、引言随着人们对音频质量要求的不断提高,语音增强技术逐渐成为音频处理领域的研究热点。
麦克风阵列技术作为一种有效的语音增强手段,通过多个麦克风的协同作用,可以实现对声源的定位、语音信号的分离以及语音增强的功能。
本文旨在研究基于麦克风阵列的语音增强技术,以期在复杂环境中实现高保真的语音识别与通讯。
二、麦克风阵列基本原理麦克风阵列是由多个麦克风按照一定规则排列而成的阵列系统。
其基本原理是通过不同麦克风接收到的信号之间的相位差和幅度差,结合阵列几何结构,实现对声源的定位和信号的分离。
麦克风阵列技术广泛应用于语音识别、语音增强、声源定位等领域。
三、基于麦克风阵列的语音增强方法基于麦克风阵列的语音增强方法主要包括声源定位、信号分离和后处理三个步骤。
1. 声源定位:通过多个麦克风的信号到达时间差和幅度差等信息,估计出声源的方向和距离。
声源定位是后续信号分离的基础。
2. 信号分离:在确定了声源位置后,采用适当的信号处理算法,如盲源分离、基于高阶统计的分离方法等,从混合信号中提取出目标语音信号。
这一步骤中,针对噪声环境和不同背景下的分离效果尤为关键。
3. 后处理:通过语音增益调整、噪声抑制等后处理技术,进一步提高语音信号的质量。
后处理环节可以有效消除背景噪声、回声等干扰因素,使语音信号更加清晰。
四、研究现状与挑战目前,基于麦克风阵列的语音增强技术在理论研究和实际应用方面都取得了显著的成果。
然而,在实际应用中仍面临诸多挑战。
如:如何提高声源定位的准确性、如何有效分离混合信号中的目标语音、如何处理不同环境下的噪声干扰等。
此外,随着人工智能和深度学习技术的发展,如何将先进的算法应用于麦克风阵列技术,提高语音增强的效果和效率,也是当前研究的重点。
五、研究方法与实验结果为了解决上述问题,本文采用深度学习算法与麦克风阵列技术相结合的方法进行语音增强研究。
首先,通过构建神经网络模型,实现对声源的精准定位和混合信号的有效分离;其次,利用深度学习算法对后处理环节进行优化,进一步提高语音质量;最后,通过实验验证了该方法的可行性和有效性。
XMOS的麦克风阵列语音识别方案

ARM ETH
+
IIS
DSP IIS
AMP + ADC
WIFI ETH USB
XMOS
传统MCU麦克风数量4个为极限
无法准确定位声源和接口单一 ARM+DSP加长开发流程和成本增加
实现可达16个PDM/I2S数字麦克风接口 麦克风阵列定位和跟踪说话人位置 多种DSP音频处理算法,远场拾音,噪音回音 消除,获取纯净声源 单芯片处理,可固化高性能音频处理算法, 减短软硬件设计周期、降低硬件成本
IIS/ PDM IIS
本地离线方案
XMOS MCU
IIS/ PDM
IIS
8个数字或者模拟麦克风
8个数字或者模拟麦克风
灵活多种麦克风的阵元,精度更高 可选云端联网,本地离线方式
多种阵列阵型,灵活适应产品结构 单处理器解决,简洁的硬件和降成
主控资源介绍
xCORE logical core
USB 2.0
SRAM USB 2.0
xCORE logical core
SRAM
OTP
xCORE logical core
OTP
FLASH
SRAM
RGMII
xTIME scheduler
麦克风阵列方案对比
其他的方案 我们的方案
PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS
消除设备本身发出的音频回声干扰
多声源定位
给出多个目标说话人的方位信息
波束形成
将录音波束聚焦至目标说话人方位,抑制其他方位的声音
声源分离
对同时出现的多个声源进行分离,分别进行语音识别
麦克风阵列在语音识别中的应用

麦克风阵列在语音识别中的应用
随着人工智能技术的不断发展,语音识别技术逐渐走进人们的生活。
而在语音识别技术中,麦克风阵列的应用起到了重要的作用。
本文将介绍麦克风阵列在语音识别中的应用,并从多个方面阐述其重要性。
一、麦克风阵列介绍
麦克风阵列是由多个麦克风组成的一种变体形式,它可以将多个麦克风的输入信号进行数字信号处理和分析,并从中提取出任意方向的声音信号。
麦克风阵列通常由四个或更多麦克风组成,这些麦克风通常围绕着一个中心点布置,以形成一个可控制的虚拟听取器。
二、麦克风阵列在语音识别中的应用
1. 声纹识别
麦克风阵列可以用于声纹识别中,通过对人声信号进行分析和处理,从而实现语音识别。
在声纹识别中,麦克风阵列可以提高识别准确性和抗干扰能力,从而更好地识别人的声音特征。
2. 环境噪声抑制
麦克风阵列可以有效地抑制周围环境中的噪声,比如电视声、交通噪声等,从而提高语音识别的精确性和准确性。
麦克风阵列能够精确分析和抑制噪声,使得语音信号更加清晰,使得语音识别更准确。
3. 清晰度提升
麦克风阵列可以通过将多个麦克风的输入信号组合起来,从而使得语音信号更加清晰,更容易被识别。
麦克风阵列可以通过深度学习等技术,将多个麦克风的输入信号进行分析和处理,从而提升语音识别的清晰度和准确性。
三、总结
麦克风阵列在语音识别技术中发挥着重要作用,能够提高识别准确性和抗干扰能力,从而更好地识别人的声音特征。
麦克风阵列还能有效地抑制环境噪声,提高语音识别的精确性和准确性,从而使得语音识别更加优秀。
随着人工智能技术的发展,麦克风阵列技术将会在语音识别中扮演更加重要的作用。
【用户手册】PXVF3000-KIT XMOS麦克风阵列评估板_v1
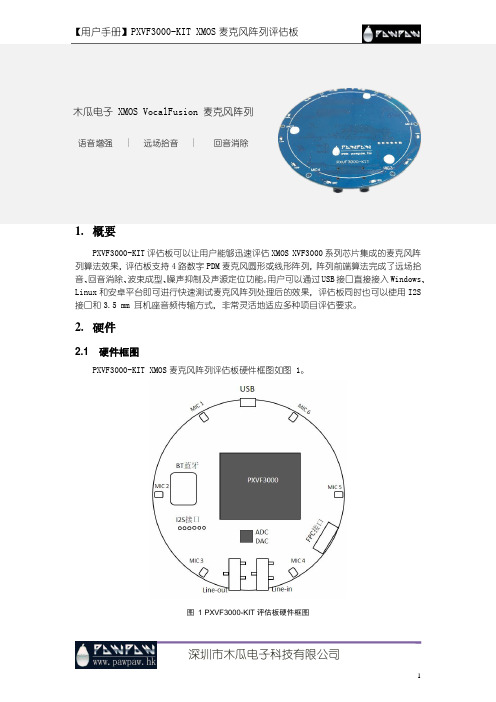
木瓜电子 XMOS VocalFusion 麦克风阵列语音增强 | 远场拾音 | 回音消除1.概要PXVF3000-KIT评估板可以让用户能够迅速评估XMOS XVF3000系列芯片集成的麦克风阵列算法效果,评估板支持4路数字PDM麦克风圆形或线形阵列,阵列前端算法完成了远场拾音、回音消除、波束成型、噪声抑制及声源定位功能。
用户可以通过USB接口直接接入Windows、Linux和安卓平台即可进行快速测试麦克风阵列处理后的效果,评估板同时也可以使用I2S 接口和3.5 mm 耳机座音频传输方式,非常灵活地适应多种项目评估要求。
2.硬件2.1 硬件框图PXVF3000-KIT XMOS麦克风阵列评估板硬件框图如图 1。
图 1 PXVF3000-KIT评估板硬件框图硬件框图包含如下内容:USB:♦USB提供设备5V电源供应♦USB Audio Class 2.0/1.0(UAC 2.0/ UAC 1.0)传输音频信号♦USB DFU PXVF3000-KIT评估板固件更新♦USB HID 指令/控制传输MIC:♦Invensence ICS-41350 PDM 麦克风♦MIC 1~6 圆形均匀分布,半径43mmPXVF3000:♦核心板,完成远程拾音、回音消除、波束成型等语音前端算法硬件模组BT蓝牙:蓝牙模块将PXVF3000的输入输出音频信号无线传输ADC/DAC:♦DAC负责PXVF3000的数字转模拟信号播放输出♦ADC可以使用模拟信号转换数字信号输入,作为PXVF3000的回音消除参考信号FPC接口:实现线形(长条形)麦克风阵列扩展,其他麦克风阵列阵型调整性扩展I2S接口:I2S数据接口兼容主从模式输入输出PXVF3000声音信号Line-out:3.5mm耳机座子立体声输出PXVF3000声音信号Line-in:3.5mm耳机座子Mono通道输入给PXVF3000作为参考信号3.评估板快速使用PXVF3000-KIT评估板出厂默认使用圆形4路麦克风阵列,分别是使用MIC 1、MIC 3、MIC 4和MIC6组成的矩形阵列如图 2。
《2024年基于麦克风阵列的语音增强研究》范文

《基于麦克风阵列的语音增强研究》篇一一、引言随着智能设备的广泛应用,语音交互技术在日常生活与工作场景中越来越重要。
其中,麦克风阵列技术的出现与进步为语音增强提供了新的解决方案。
麦克风阵列通过多个麦克风的协同工作,能够有效地提高语音信号的接收质量,降低环境噪声的干扰。
本文将基于麦克风阵列的语音增强技术进行深入研究,探讨其原理、应用及未来发展趋势。
二、麦克风阵列技术原理麦克风阵列是由多个麦克风组成的系统,通过信号处理技术对多个麦克风的信号进行加权、合并和滤波等操作,以实现语音信号的增强。
其基本原理包括声源定位、波束形成以及干扰噪声的抑制等。
声源定位技术是指确定声音来源方向的技术,是麦克风阵列的关键技术之一。
通过计算声波到达各个麦克风的传播时间差、强度差等信息,可以估算出声源的方向和位置。
波束形成技术则是根据声源定位的结果,将多个麦克风的信号进行加权合并,形成一个指向声源方向的波束,从而提高对声源方向上语音信号的接收灵敏度。
而干扰噪声的抑制则是通过滤波、降噪等技术降低环境中的噪声干扰,提高语音信号的信噪比。
三、基于麦克风阵列的语音增强技术基于麦克风阵列的语音增强技术主要包括以下几种:1. 波束形成算法:通过声源定位技术确定声源方向后,采用波束形成算法将多个麦克风的信号进行加权合并,形成一个指向声源方向的波束,从而提高对声源方向上语音信号的接收质量。
2. 噪声抑制技术:通过滤波、降噪等技术降低环境中的噪声干扰,提高语音信号的信噪比。
其中,基于麦克风阵列的噪声抑制技术可以更好地适应不同环境下的噪声干扰。
3. 回声消除技术:在语音通信过程中,由于各种原因可能会产生回声干扰。
基于麦克风阵列的回声消除技术可以通过多个麦克风的协同工作,实时检测并消除回声干扰,提高语音通信的质量。
四、应用领域基于麦克风阵列的语音增强技术在多个领域得到了广泛应用:1. 智能音箱:智能音箱通过多个麦克风的协同工作,实现远距离、高灵敏度的语音识别与交互。
《2024年基于麦克风阵列的语音增强研究》范文

《基于麦克风阵列的语音增强研究》篇一一、引言随着人工智能技术的快速发展,语音识别和语音交互技术已成为人们日常生活和工作中不可或缺的一部分。
然而,在复杂多变的实际环境中,语音信号常常受到各种噪声的干扰,导致语音质量下降,进而影响语音识别的准确性和语音交互的体验。
因此,如何有效地进行语音增强,提高语音信号的信噪比(SNR),成为了一个重要的研究课题。
麦克风阵列技术因其能够通过多个麦克风的协同作用,实现空间滤波和声源定位,为语音增强提供了新的解决方案。
本文将基于麦克风阵列的语音增强研究进行深入探讨。
二、麦克风阵列技术概述麦克风阵列是由多个麦克风按照一定规则排列组成的系统,可以实现对声源的空间定位和信号处理。
通过分析不同麦克风接收到的声波的时间差、相位差和幅度差等信息,可以确定声源的位置,并利用空间滤波技术对声源信号进行增强。
麦克风阵列技术广泛应用于语音识别、语音交互、音频监控等领域。
三、基于麦克风阵列的语音增强方法1. 波束形成技术波束形成是麦克风阵列中常用的语音增强技术。
通过加权求和多个麦克风的信号,使得阵列在特定方向上的响应得到增强,同时在其他方向上的响应得到抑制,从而达到提高信噪比的目的。
2. 盲源分离技术盲源分离技术是一种基于计算声学的语音增强方法。
通过分析多个麦克风接收到的混合信号,将声源信号从混合信号中分离出来,从而实现语音增强。
该技术可以有效地处理多个声源同时发声的情况。
3. 联合去噪与去混响技术在实际环境中,除了噪声干扰外,声源信号还可能受到房间混响的影响。
联合去噪与去混响技术将去噪和去混响结合起来,同时对噪声和混响进行抑制,进一步提高语音增强的效果。
四、实验与分析为了验证基于麦克风阵列的语音增强方法的有效性,我们进行了多组实验。
实验结果表明,采用波束形成技术的麦克风阵列可以有效地提高信噪比,降低背景噪声对语音识别的影响。
盲源分离技术可以有效地处理多个声源同时发声的情况,提高语音识别的准确性。
《2024年度基于麦克风阵列的语音增强研究》范文

《基于麦克风阵列的语音增强研究》篇一一、引言随着科技的快速发展,语音技术已逐渐成为人们日常生活中不可或缺的一部分。
其中,语音增强作为提高语音质量的重要手段,对于提升语音系统的性能至关重要。
麦克风阵列技术作为语音增强的有效手段之一,其应用范围广泛,包括智能语音助手、会议系统、安全监控等。
本文将重点研究基于麦克风阵列的语音增强技术,探讨其原理、方法及实际应用。
二、麦克风阵列技术原理麦克风阵列是指将多个麦克风按照一定的几何布局组合在一起,形成一个具有特定功能的系统。
其基本原理是通过多个麦克风的信号采集和空间滤波,提高目标语音的信噪比,从而实现语音增强。
麦克风阵列的布局、阵元间距、阵元数量等因素都会影响其性能。
三、基于麦克风阵列的语音增强方法1. 波束形成技术波束形成是麦克风阵列中常用的语音增强技术。
它通过调整各个麦克风的权重和相位,使得在特定方向上的声音信号得到加强,而其他方向的噪声信号得到抑制。
常见的波束形成方法包括延迟求和波束形成、最小方差无畸变响应波束形成等。
2. 空间滤波技术空间滤波技术利用麦克风阵列的多个麦克风的信号差异,对噪声进行空间滤波。
通过估计噪声的空间分布,对噪声进行抑制,从而提高语音质量。
常见的空间滤波方法包括多通道盲源分离、空间协方差矩阵等。
3. 麦克风阵列与深度学习的结合近年来,深度学习在语音增强领域取得了显著的成果。
将深度学习与麦克风阵列技术相结合,可以实现更高效的语音增强。
例如,利用深度神经网络对麦克风阵列的信号进行特征提取和分类,进一步提高语音识别的准确率。
四、实际应用及效果分析1. 智能语音助手在智能语音助手中,麦克风阵列技术可以有效地提高语音识别的准确率。
通过波束形成和空间滤波技术,抑制环境噪声,提高目标语音的信噪比,从而使得语音助手在嘈杂环境下也能准确地识别用户的指令。
2. 会议系统在会议系统中,麦克风阵列技术可以提高会议音频的质量。
通过优化麦克风阵列的布局和调整波束形成的方向,使得会议参与者的声音得到加强,而其他方向的噪声得到抑制。
PXUA216MB-DL2-M 16路麦克风阵列采集环境搭建步骤

PXUA216MB-DL2-M 评估板初次使用的时候,在Windows系统测试需要安装USB声卡驱动,设置好Windows的USB 声卡环境后,便可使用Audacity进行录音测试。
1.1 USB声卡驱动木瓜电子的资料包会提供多个版本的Windows ASIO USB声卡驱动,这些驱动都是免费公版驱动,里面有限制商业化的Bug,但是可以测试使用,产品如需商业化,用户可以自行咨询Thesycon购买。
驱动名称如下:♦USB-Audio-Class-2.0-Evaluation-Driver-for-Windows_3.34.0♦USB-Audio-Class-2.0-Evaluation-Driver-for-Windows_3.20.0♦USB-Audio-Class-2.0-Evaluation-Driver-for-Windows_4.11.0推荐使用USB-Audio-Class-2.0-Evaluation-Driver-for-Windows_3.34.0,在Windows安装步骤:1.首次点击安装USB-Audio-Class-2.0-Evaluation-Driver-for-Windows_3.34.0为解压文件,需要进入目录如下:..\Thesycon\TUSBAudio_v3.34.0\EvaluationKit\DriverPackages\XMOS_EVAL_KITS _DEMO\DriverSetup\release。
确认USB 已经连接上后,在该目录下点击setup.exe 进行驱动安装;2.在PC设备管理器看到XMOS USB 2.0 Audio Devices ->XMOS XS1-U8A MFA则说明驱动安装成功。
3.如显示Pawpaw Microphone Array UAC2.0 和问号,说明驱动还没安装正确,需详细确认一下驱动安装步骤。
1.2 环境设置设置XMOS-XS1-U8 DJ的录制和播放声卡属性,在<高级>栏目把<默认格式>统一设置为16KHz 16bit的音频格式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
麦克风组合阵型灵活多种
可组合圆型、方型、线型等不同的阵列形状
音频数据传输方式灵活多种
可选择WiFi、ETH和USB接云端进行语音识别
高性能单芯片处理
单芯片2000MIPS速度,处理算法,通讯接口、命令控制
软件功能
多通道回声消除
消除设备本身发出的音频回声干扰
远场条件下纯自然声音操控方式 语音唤醒、语音操作、语音交互
快速直达您想看的频道或节目 语音搜索电影、电视节目等内容
应用场景举例——智能电视
麦克风阵列效果
小牧,央视一台
回声消除
噪声抑制 小牧,央视一台
电视回声,环境噪声消除 语音唤醒,定位目标声音,提高指向性
远场拾音,增益目标声源 多目标声源定位和波束形成,聚焦和增益多声源
xCORE logical core
xCORE logical core
xCORE logical core
xCORE logical core xCORE logical core
OTP
USB 2.0
SRAM USB 2.0 RGMII
xTIME scheduler
xCORE logical core SRAM
智能电视
智能家居
安防控制
应用场景举例——智能电视
传统方案
复杂的TV频道选项系统 不智能的遥控器界面操作 需要长时间繁琐操作才能完成搜索 操作,基本个别产品使用语音遥控 器,也深受操作方式不自然、遥控 器电量消耗过快等因素的困扰
难用的节目内容搜索方式
应用场景举例——智能电视
麦克风阵列方案
小牧,我要看央视一台
OTP
FLASH
SRAM
与传统方案对比
其他的方案 我们的方案
PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS PDM/IIS
ARM ETH
+
IIS
DSP IIS
AMP + ADC
WIFI ETH USB
XMOS
传统MCU麦克风数量4个为极限
xTIME scheduler
32个1bit端口任意配置组合的串行时序 4bit,8bit,16bit,32bit端口配置并行端口
xCONNECT switch
PLL
xCONNECT switch
xCORE logical core
xCORE logical core
快速通讯
xCORE logical core xCORE logical 单芯片可以实现16个核心 每个核并行运行,16核累加速度为2000MIPS
I/O pins Hardware Response Ports
灵活引脚
Hardware Response Ports
xCORE logical core xCORE logical core xCORE logical core xCORE logical core
c
xCORE logical core xCORE logical core
JTAG RGMII
每个核心之间的通讯通过通道通讯 通道通讯可以单指令、高实时完成传输 512KB RAM,每个核共同使用 USB PHY,集成USB 2.0收发器 千兆以太网控制器 20个timer,用于延时、中断、时序
无法准确定位声源和接口单一 ARM+DSP加长开发流程和成本增加
实现可达16个PDM/I2S数字麦克风接口 麦克风阵列定位和跟踪说话人位置 多种DSP音频处理算法,远场拾音,噪音回音 消除,获取纯净声源 单芯片处理,可固化高性能音频处理算法, 减短软硬件设计周期、降低硬件成本
硬件功能
麦克风阵元数量灵活多种
应用场景举例——会议系统
方案对比
传统的多个节点麦克风
可以自动聚焦单个或者多个目标音源 消除噪音、回声和背景声等干扰声音 定位和增益发言人声音,转录成文字 声源分离和说话人识别,可身份识别
需要手动操作及繁冗的安装
使用不方便,发言人声音参杂
应用场景举例——家庭管家
声控玩游戏
声控播放
家庭管家 聊天 声音识别操控家电 用声音聊天、播放音乐、玩游戏 声控调温
多声源定位
给出多个目标说话人的方位信息
波束形成
将录音波束聚焦至目标说话人方位,抑制其他方位的声音
声源分离
对同时出现的多个声源进行分离,分别进行语音识别
多通道语音增强
将多路信息组合为一路信号,抑制环境噪声、增强语音信号
语音唤醒/打断
通过呼唤“名字”开启交互过程
应用场景
会议讨论系统 车载系统 游戏娱乐
IIS/ PDM IIS
本地离线方案
XMOS MCU
IIS/ PDM
IIS
多个数字或者模拟麦克风
多个数字或者模拟麦克风
灵活多种麦克风的阵元,精度更高
多种阵列阵型,灵活适应产品结构 单处理器解决,简洁的硬件和降成
可选云端联网,本地离线方式
主控资源介绍
xCORE logical core
麦克风阵列
语音识别
麦克风阵列具有优异的拾音性能
就知道是你的声音
在混响的环境 在5米远的距离
在嘈杂的人群
利用多路麦克风阵列,使用先进的声音处理算法技术 解决复杂声学下的远场拾音问题,让声音更加纯净
麦克风阵列方案框架
云端联网方案
云服务器 语音识别系统 FLASH ET H US Wi B Fi XMOS MCU