无损压缩算法的比较和分析
几个常用快速无损压缩算法性能比较
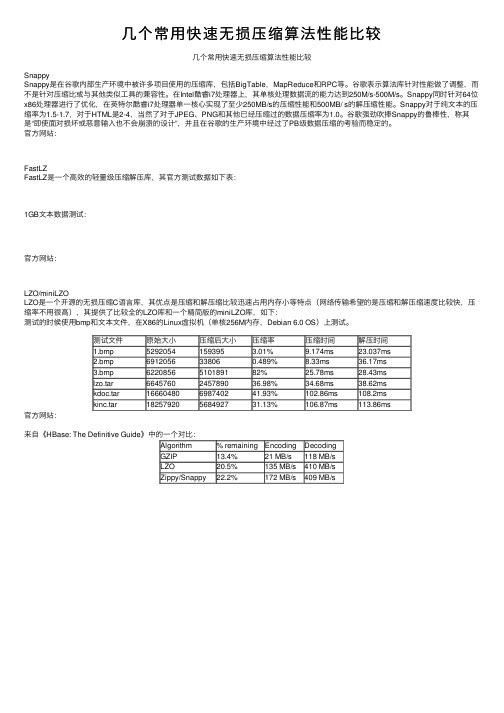
⼏个常⽤快速⽆损压缩算法性能⽐较⼏个常⽤快速⽆损压缩算法性能⽐较SnappySnappy是在⾕歌内部⽣产环境中被许多项⽬使⽤的压缩库,包括BigTable,MapReduce和RPC等。
⾕歌表⽰算法库针对性能做了调整,⽽不是针对压缩⽐或与其他类似⼯具的兼容性。
在Intel酷睿i7处理器上,其单核处理数据流的能⼒达到250M/s-500M/s。
Snappy同时针对64位x86处理器进⾏了优化,在英特尔酷睿i7处理器单⼀核⼼实现了⾄少250MB/s的压缩性能和500MB/ s的解压缩性能。
Snappy对于纯⽂本的压缩率为1.5-1.7,对于HTML是2-4,当然了对于JPEG、PNG和其他已经压缩过的数据压缩率为1.0。
⾕歌强劲吹捧Snappy的鲁棒性,称其是“即使⾯对损坏或恶意输⼊也不会崩溃的设计”,并且在⾕歌的⽣产环境中经过了PB级数据压缩的考验⽽稳定的。
官⽅⽹站:FastLZFastLZ是⼀个⾼效的轻量级压缩解压库,其官⽅测试数据如下表:1GB⽂本数据测试:官⽅⽹站:LZO/miniLZOLZO是⼀个开源的⽆损压缩C语⾔库,其优点是压缩和解压缩⽐较迅速占⽤内存⼩等特点(⽹络传输希望的是压缩和解压缩速度⽐较快,压缩率不⽤很⾼),其提供了⽐较全的LZO库和⼀个精简版的miniLZO库,如下:测试的时候使⽤bmp和⽂本⽂件,在X86的Linux虚拟机(单核256M内存,Debian 6.0 OS)上测试。
测试⽂件原始⼤⼩压缩后⼤⼩压缩率压缩时间解压时间1.bmp 5292054 159395 3.01%9.174ms23.037ms2.bmp 6912056 33806 0.489%8.33ms36.17ms3.bmp 6220856 5101891 82%25.78ms28.43mslzo.tar6645760 2457890 36.98%34.68ms38.62mskdoc.tar16660480698740241.93%102.86ms108.2mskinc.tar182579205684927 31.13% 106.87ms113.86ms官⽅⽹站:来⾃《HBase: The Definitive Guide》中的⼀个对⽐:Algorithm% remaining Encoding DecodingGZIP13.4%21 MB/s118 MB/sLZO20.5%135 MB/s410 MB/sZippy/Snappy22.2%172 MB/s409 MB/s。
无损压缩方法

无损压缩方法
1.压缩算法:无损压缩的核心是使用压缩算法来减小文件的大小,常见的无损压缩算法有LZ77、LZ78、LZW等。
这些算法通过识别和消除文件中的冗余信息来实现压缩,而不会改变文件的原始内容。
2.压缩工具:无损压缩通常需要使用特定的压缩工具来进行操作。
常见的无损压缩工具有WinRAR、7Zip、Zip等。
这些工具提供了对各种文件类型的无损压缩功能,并支持将压缩文件解压缩回原始文件。
3.图像无损压缩:在数字图像中,无损压缩可以去除图像中的冗余信息以减小文件大小,而不会损坏图像质量。
常见的图像无损压缩格式有PNG、GIF、TIFF等。
这些格式通过使用压缩算法对图像数据进行编码和压缩,以实现高质量的图像显示同时减小文件大小。
4.音频无损压缩:无损压缩也可应用于音频文件。
常见的音频无损压缩格式有FLAC、ALAC、APE等。
这些格式使用特定的压缩算法来压缩音频数据,减小文件大小,同时保持音频的原始质量。
无损压缩算法的比较和分析

无损压缩算法的比较和分析无损压缩算法是一种将文件或数据压缩成较小体积,而又能保持原始数据完整性的技术。
在实际应用中,有多种无损压缩算法可供选择,每种算法都有其独特的优点和适用场景。
以下是对三种常见的无损压缩算法,LZ77、LZ78和LZW算法,的比较和分析。
1.LZ77算法LZ77算法是一种基于滑动窗口的算法,通过将数据中的重复片段替换为指向该片段的指针,来实现数据压缩。
该算法具有简单高效的特点,适用于具有较多重复片段的数据。
LZ77算法在处理图片、视频等文件时表现出色,能够对重复的像素块进行有效压缩,但对于无重复的文件压缩效果较差。
2.LZ78算法LZ78算法是一种基于前缀编码的算法,通过构建一个字典来记录文件中的重复字串,并用索引指向字典中的相应位置,从而实现数据压缩。
与LZ77算法相比,LZ78算法在处理无重复文件时表现更好,由于引入了字典的概念,能够较好地处理无重复字串的情况。
然而,LZ78算法的压缩率相对较低,在对具有大量重复片段的文件进行压缩时,效果不如LZ77算法。
3.LZW算法LZW算法是一种基于字典的算法,与LZ78算法类似,通过构建字典来实现数据压缩。
LZW算法利用一个初始字典来存储单个字符,并逐渐增加字典的大小,以适应不同长度的字串。
该算法具有较好的压缩率和广泛的应用领域,可适用于文本、图像、音频等各类型文件的压缩。
然而,LZW算法的缺点是需要事先构建和传递字典,增加了存储和传输的复杂性。
综上所述,无损压缩算法的选择应考虑文件的特点和需求。
对于具有大量重复片段的文件,LZ77算法能够实现较好的压缩效果;对于无重复文件,LZ78算法表现更佳;而LZW算法则具有较好的通用性,适用于各类型文件的压缩。
当然,还有其他无损压缩算法可供选择,如Huffman编码、Arithmetic编码等,根据实际情况选用最适合的算法能够达到更好的压缩效果。
无损压缩算法范文

无损压缩算法范文无损压缩算法是一种用于压缩数字数据的算法,旨在通过减少数据的冗余和不必要的信息来减小数据的大小,同时保持压缩后的数据与原始数据之间的精确度。
相比于有损压缩算法,无损压缩算法能够保留所有原始数据的信息,适用于一些对数据准确性要求较高的场景,如图像、音频和视频等领域。
下面将介绍几种常见的无损压缩算法:1. 霍夫曼编码(Huffman Coding)霍夫曼编码是一种通过构建变长编码表来减少数据大小的算法。
它通过统计输入数据中各个符号的出现频率,然后根据频率构建一颗哈夫曼树,将出现频率高的符号用较短的编码表示,而出现频率低的符号用较长的编码表示。
这样,原始数据中出现频率较高的符号可以用更少的比特位来表示,从而降低数据的大小。
2. 预测编码(Predictive Coding)预测编码是一种基于数据之间的相关性来减小数据大小的算法。
它通过分析数据之间的关系,利用预测模型来计算数据的预测值,并将预测值与实际值之间的差异进行编码。
由于预测值一般会比实际值较接近,所以差异较小,可以用较少的位数来表示。
预测编码常用于图像和音频等数据的压缩。
3. 字典编码(Dictionary Coding)字典编码是一种基于数据中重复模式的算法。
它通过构建一个字典,将重复出现的模式映射为短的编码。
然后,将原始数据中的模式用对应的编码表示。
字典编码常用于文本和压缩文件等类型的数据压缩。
4. 差分编码(Differential Coding)差分编码是一种基于数据差异的算法。
它通过计算数据之间的差异,并将差异进行编码。
相比于直接编码原始数据,差分编码可以更有效地表示数据变化的程度。
差分编码常用于时序数据压缩,如音频和视频的编码。
除了上述提到的算法,还有许多其他的无损压缩算法,每种算法都有其适用的场景和特点。
压缩算法的选择通常要根据数据的类型、压缩速度和解压速度等因素进行评估。
对于不同类型的数据,可能会选择不同的无损压缩算法或者组合多种算法来达到更好的压缩效果。
无损压缩算法及其应用实现

无损压缩算法及其应用实现随着计算机技术的飞速发展,数据处理已经成为了现代社会的重要组成部分。
随着每天产生的数据量不断增加,传统的存储方法已经显得力不从心。
同时,网络传输的速度也给压缩技术带来了巨大的挑战。
因此,如何实现高效的数据压缩已经成为了一个热门话题。
无损压缩算法因为其不会改变源文件数据,而且解压出来的数据和原文件相同,被广泛应用于数据压缩中。
本文将着重介绍无损压缩算法的原理和应用实现,并探讨它的优缺点。
一、无损压缩算法原理无损压缩算法,通常是为了在保证数据质量不变的情况下实现数据压缩。
它的原理是利用多种技术,对数据的冗余部分进行处理,并通过一系列的算法实现数据的快速压缩和还原。
无损压缩算法的主要处理过程包括:去重、编码和压缩三个环节。
1. 去重在去重环节中,无损压缩算法会利用一些算法来查找源文件中的重复部分,并将其提取出来。
这些重复部分会被记录下来,并在编码和压缩环节中被适当地处理。
这样就能避免对源文件进行重复的压缩操作,从而实现了更加高效的数据压缩。
2. 编码在编码环节中,无损压缩算法使用了一些熵编码技术来提高压缩效率。
这些编码技术旨在利用数据的统计特性来构建一种适当的编码方式,从而实现高效的数据压缩。
在编码过程中,数据会被转换为一个或多个用于描述数据的符号,并通过一个编码表映射到一个最小位数的编码串中。
这些编码串就是用来表示源数据的压缩数据。
3. 压缩在压缩环节中,无损压缩算法会使用一些压缩技术来进一步压缩压缩数据。
这些技术通常包括哈夫曼编码、算术编码和字典压缩,等等。
这些技术的主要目的是使压缩数据尽可能地短,从而实现更加高效的数据压缩。
当需要还原数据时,压缩数据会通过相反的方式进行解压,并还原为源数据。
二、无损压缩算法的应用实现目前,无损压缩算法已成为了数据处理中不可或缺的一部分。
它广泛应用于网络传输、文件存储、图像和音频处理等领域。
下面,我们着重探讨一下无损压缩算法在不同应用场景的实现方法。
音频信号压缩与解压缩算法的研究和发展

音频信号压缩与解压缩算法的研究和发展概述:随着数字技术的不断发展,人们对音频信号的需求也变得越来越高。
然而,音频信号的传输、存储和处理需要消耗大量的资源和带宽。
为了解决这一问题,音频信号压缩与解压缩算法应运而生。
本文将讨论音频信号压缩与解压缩算法的研究和发展,重点介绍目前主流的压缩算法以及未来的发展趋势。
一、音频信号压缩算法的研究与发展1. 无损压缩算法无损压缩算法是指通过压缩算法将原始音频信号压缩存储,然后再通过解压缩算法还原成与原信号完全相同的数据,没有任何损失。
目前,最常用的无损压缩算法包括无损预测编码、霍夫曼编码和算术编码等。
这些算法通过对音频信号中的冗余信息进行处理,有效地减小了文件的大小。
2. 有损压缩算法有损压缩算法是指通过压缩算法将原始音频信号压缩存储,然后再通过解压缩算法将压缩后的数据还原成类似原信号的近似数据,但有部分细节损失。
有损压缩算法可以更进一步地减小文件的大小,但会对音频信号的质量产生一定的影响。
目前,最常用的有损压缩算法包括MP3、AAC和FLAC等。
这些算法通常利用人类听觉系统对音频信号的特点进行分析,然后根据重要性对信号进行有选择性地舍弃或近似表示。
二、音频信号解压缩算法的研究与发展1. 无损解压缩算法无损解压缩算法是将经过无损压缩算法压缩后的音频信号数据进行还原的算法。
这些算法通常根据压缩时采用的压缩算法进行逆向操作,恢复出与原始音频信号完全相同的数据。
无损解压缩算法的优点是数据完整性得以保持,但由于无损压缩算法对数据的压缩率有限,解压缩后的数据仍然较大。
2. 有损解压缩算法有损解压缩算法是将经过有损压缩算法压缩后的音频信号进行还原的算法。
这些算法通常根据压缩时采用的压缩算法进行逆向操作,恢复出类似原始音频信号的近似数据。
有损解压缩算法的缺点是对数据进行了近似处理,因此解压缩后的数据与原始信号存在细微的差异,主要体现在音质和细节上。
三、当前主流压缩算法及其特点1. MP3MP3(MPEG Audio Layer 3)是一种有损压缩算法,具有较高的压缩率和广泛的应用范围。
多媒体数据处理中几种无损压缩算法的比较概要

119摘要:为了使大容量的多媒体数据在网络上有效的传输,必须对多媒体数据进行压缩。
对多媒体数据压缩中的几种无损压缩方法进行了比较,并对每种方法用一个例子说明。
关键词:数据压缩;霍夫曼树;LZW;二叉树引言随着网络发展的速度越来越快,视频,音频的广泛应用使得大数据量的传输显得尤为重要,如何更快、更多、更好地传输与存储数据成为数据信息处理的首要问题。
在压缩算法中分为无损压缩和有损压缩。
相对于有损压缩来说,无损压缩的占用空间大,压缩比不高,但是它100%的保存了原始信息,没有任何信号丢失并且音质高,不受信号源的影响,这点是有损压缩不可比拟的。
而且随着时间的推移,限制无损格式的种种因素将逐渐被消除,比如说硬盘容量的急剧增长以及低廉的价格使得无损压缩格式的前景无比光明。
1、无损压缩的原理以及几种常见算法本质上压缩数据是因为数据自身具有冗余性。
数据压缩是利用各种算法将数据冗余压缩到最小,并尽可能地减少失真,从而提高传输效率和节约存储空间。
常见的无损压缩算法有,游长编码;香浓-凡诺算法;霍夫曼算法;LZW算法;下面详细介绍这些算法或编码步骤,并比较其优缺点。
2、游长编码也叫行程编码,它是数据压缩中最简单的一种方法。
它的思想是:将图像一行中颜色值相同的相邻象素用一个计数值和该颜色值来代替。
例如:aabbbccccdddddeeeeee对其进行游长编码可得2a3b4c5d6e,可见其效率很高。
但它有两个致命缺点。
一:如果图象中每两个相邻点的颜色都不同,用这种算法不但不能压缩,反而数据量会增加,例如对abcdeabcde进行编码得1a2b3c4d5e1a2b3c4d5e,可见数据量反而增加了1倍。
二:容错性差。
还是以aabbbccccdddddeeeeee为例,如果在第二位a出错,例如丢失了a,那么编码后结果为1a3b4c5d6e,虽然只有一位发生了错误,但是在恢复数据时,将和原始数据完全不同。
所以说游长编码在要压缩信息源中的符号形成连续出现片段时才有效,并且它不是一种自适应的编码方式。
常用图像压缩算法对比分析

常用图像压缩算法对比分析1. 引言图像压缩是一种将图像数据进行有损或无损压缩的方法,旨在减少图像数据的存储空间和传输带宽需求,同时尽可能保持原始图像的质量。
随着数字图像的广泛应用,图像压缩算法成为了计算机科学领域的重要研究领域。
本文将对目前常用的图像压缩算法进行比较和分析。
2. JPEG压缩算法JPEG(Joint Photographic Experts Group)是一种广泛使用的无损压缩算法,适用于彩色图像。
该算法通过对图像在频域上的离散余弦变换(DCT)进行分析,将高频成分进行舍弃,从而实现图像的压缩。
JPEG算法可以选择不同的压缩比,从而平衡图像质量和压缩率。
3. PNG压缩算法PNG(Portable Network Graphics)是一种无损压缩算法,适用于压缩有颜色索引的图像。
该算法基于LZ77压缩算法和哈夫曼编码,将图像中的相似数据进行压缩存储。
相比于JPEG算法,PNG 算法可以实现更好的图像质量,但压缩率较低。
4. GIF压缩算法GIF(Graphics Interchange Format)是一种无损压缩算法,适用于压缩简单的图像,如卡通图像或图形。
该算法基于LZW压缩算法,通过建立字典来实现图像的压缩存储。
GIF算法在保持图像质量的同时,能够实现较高的压缩率。
5. WEBP压缩算法WEBP是一种无损压缩算法,由Google开发,适用于网络上的图像传输。
该算法结合了有损压缩和无损压缩的特点,可以根据需要选择不同的压缩模式。
相比于JPEG和PNG算法,WEBP算法可以实现更好的压缩率和图像质量,但对浏览器的兼容性有一定要求。
6. 对比分析从图像质量、压缩率和兼容性等方面对比分析上述四种常用图像压缩算法。
- 图像质量:JPEG算法在高压缩比下会引入一定的失真,适合于要求相对较低的图像质量;PNG和GIF算法在无损压缩的情况下能够保持较好的图像质量;WEBP算法在高压缩比下相对其他算法都具有更好的图像质量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Adaptive-Huffman-Coding 自适应霍夫曼编码
压缩比:1.79
分析:
霍夫曼算法需要有关信息源的先验统计知识,而这样的信息通常很难获得,即使能够获得这些统计数字,符号表的传输仍然是一笔相当大的开销。
自适应压缩算法能够解决上述问题,统计数字是随着数据流的到达而动态地收集和更新的。
概率再不是基于先验知识而是基于到目前为止实际收到的数据。
随着接收到的符号的概率分布的改变,符号将会被赋予新的码字,这在统计数字快速变化的多媒体数据中尤为适用。
Lempel-Ziv-Welch 基于字典的编码
压缩比:1.86
分析:
LZW算法利用了一种自适应的,基于字典的压缩技术。
和变长编码方式不同,LZW使用定长的码字(本次实验使用12位定长码字)来表示通常会在一起出现的符号/字符的变长的字符串。
LZW编码器和解码器会在接受数据是动态的创建字典,编码器和解码器也会产生相同的字典。
编码器的动作有时会先于解码器发生。
因为这是一个顺序过程,所以从某种意义上说,这是可以预见的。
算术编码(arithmetic coding)
压缩比:2
分析:
算术编码是一种更现代化的编码方法,在实际中不赫夫曼编码更有效。
算术编码把整个信息看作一个单元,在实际中,输入数据通常被分割成块以免错误传播。
算术编码将整个要编码的数据映射到一个位于[0,1)的实数区间中。
并且输出一个小于1同时大于0的小数来表示全部数据。
利用这种方法算术编码可以让压缩率无限的接近数据的熵值,从而获得理论上的最高压缩率。
比较分析:
一般来说,算术编码的性能优于赫夫曼编码,因为前者将整个消息看作一个单元,而后者受到了必须为每一个符号分配整数位的限制。
但是,算术编码要求进行无限精度的实数运算,这在仅能进行有限精度运算的计算机系统是无法进行的。
随着研究的深入,有学者提出了一种基于整数运算的算术编码实现算法。
在编码和解码的过程还需要不时的调整区间大小,以免精度不足,加大了实现的难度。
在3种无损压缩算法中,LZW算法相对来说,实现最为简单,但其压缩效果要在数据源足够大的时候,才能显现出来。