spss的数据分析报告
关于某公司474名职工综合状况的统计分析报告
一、数据介绍:
本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职
工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),j obcat(职务等级),salbegin (起始工资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>), minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。以了解该公司职工上述方面的综合状况,并分析个变量的分
布特点及相互间的关系。
二、数据分析
1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够了解变量的取值状
况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统
计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6% 和54.4%,该公司职工男女数量差距不大,男性略多于女性。
其次对原有数据中的受教育程度进行频数分析,结果如下表:
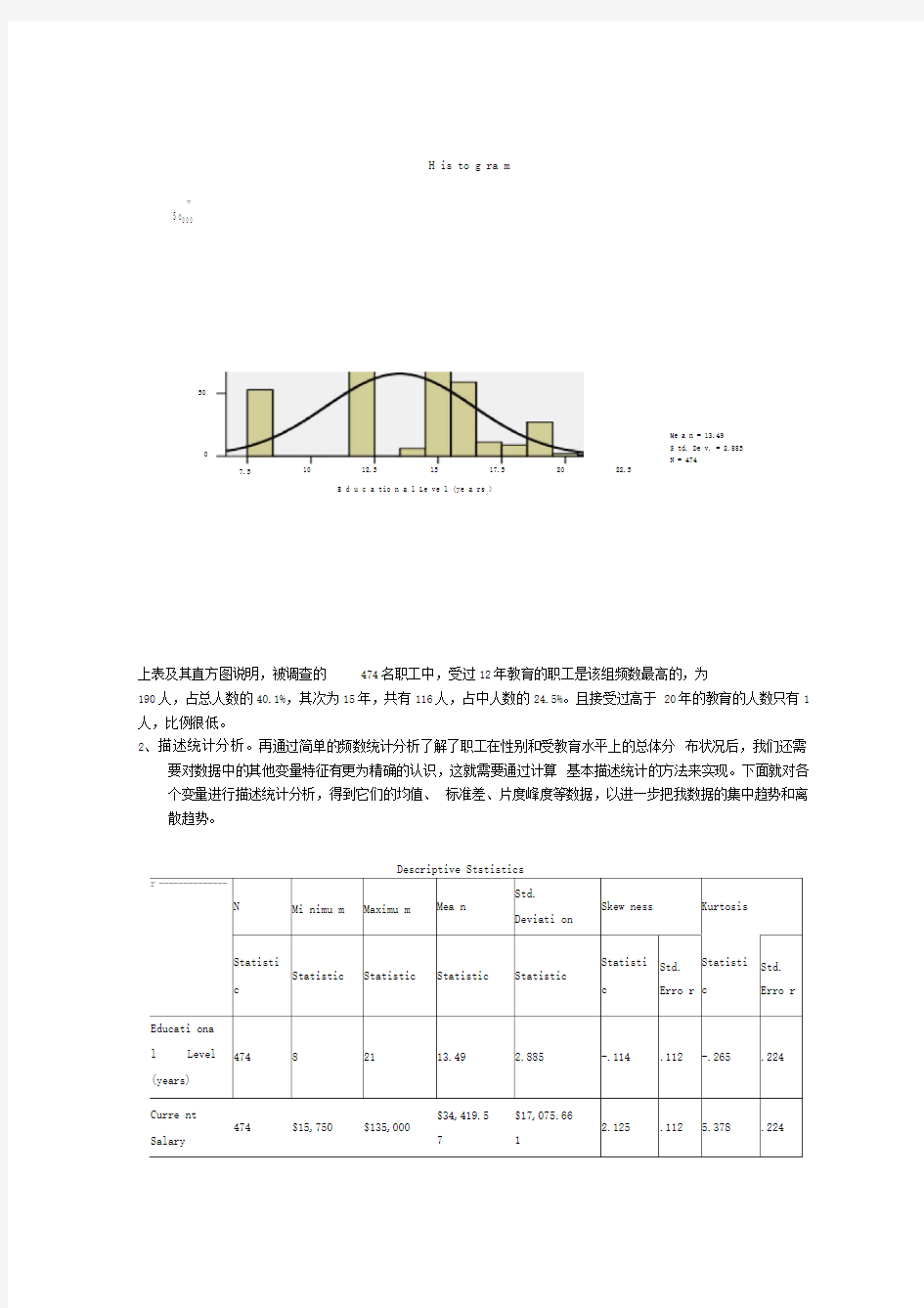
H is to g ra m
上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为
190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。
2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需
要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。
r --------------
N Mi nimu m Maximu m Mea n
Std.
Deviati on
Skew ness Kurtosis Statisti
c Statistic Statistic Statistic Statistic
Statisti
c
Std.
Erro r
Statisti
c
Std.
Erro r
Educati ona
l Level
(years)
474 8 21 13.49 2.885 -.114 .112 -.265 .224 Curre nt
Salary
474 $15,750 $135,000
$34,419.5
7
$17,075.66
1
2.125 .112 5.378 .224 o o o 05 o
Me a n = 13.49
S td. De v. = 2.885
N = 474
22.5
50
7.5 10 12.5 15 17.5 20
E d u c a tio n a l Le ve l (ye a rs )
如表所示,以起始工资为例读取分析结果,474名职工的起始工资最小值为$ 9000 ,最大
值为$ 79980,平均起始工资为$ 17016,标准差为$ 7870.638 ,偏度系数和峰度系数分别为 2.853和12.390。其他数据依此读取,则该表表明474名职工的受教育水平、起始工资、现工资、先前工作经验、现在工作经验的详细分布状况。
3、Exploratory data analysis 。
(1) 交叉分析。
通过频数分析能够掌握单个变量的数据分布情况,但是在实际分析中,不仅要了解单个变量
的分布特征,还要分析多个变量不同取值下的分布,掌握多个变量的联合分布特征,进而分
析变量之间的相互影响和关系。就本数据而言,需要了解现工资与性别、年龄、受教育水平、起始工资、本单位工作经历、以前工作经历、职务等级的交叉分析。现以现工资与职务等级
的列联表分析为例,读取数据(下面数据分析表为截取的一部分):
Current Salary * Employment Category Crosstabulation
C u rre nt S a la ry
上联表及Bar Chart 涉及两个变量,即现工资与职务级别的二维交叉,反映了在不同的职务 级别下现工资的分布情况。上表中,职务级别成为行向量,现工资称为列向量。 (2) 单因素方差分析。
单因素分析用来研究一个控制变量的不同水平是否对观测变量产生了显著影响。下面我 们把受教育水平和起始工资作为控制变量,
现工资为观测变量,通过单因素方差分析方法研
究受教育水平和起始工资对现工资的影响进行分析。分析结果如下:
AN0VA
Sum of Squares
df
Mean Square F Sig. Betw een Groups 1E+011 89 1370635995
33.040
.000
Within Groups 2E+010 384
41484093.53
Total
1E+011
473
上表是起始工资对现工资的单因素方差分析结果。可以看出:
F 统计量的观测值为 33.040,
对应的概率P 值近似等于0,如果显著性水平为 0.05,由于概率值 P 小于显著性水平 q ,则 应拒绝原假设,认为不同的起始工资对现工资产生了显著影响。
ANOVA
Sum of Squares
df
Mean Square F Sig. Betw een Groups 9E+010
9 9850392785
92.779
.000
Within Groups
5E+010
464
106170173.2
ent C ategory
C le ric a l C u s to d ia l Ma n a g e r
Bar C h a rt
00000 00000000050
0 5 0 0 0 0 0 0
E m p lo ym
同理,上表是受教育水平对现工资影响的单因素分析结果,其结果亦为拒绝原假设,所以不
同的受教育水平对现工资产生显著影响。
4、相关分析。相关分析是分析客观事物之间关系的数量分析法,明确客观事物之间有怎样的关系对理解和运用相关分析是极其重要的。
函数关系是指两事物之间的一种—对应的关系,即当一个变量X取一定值时,另一
个变量函数Y可以根据确定的函数取一定的值。另一种普遍存在的关系是统计关系。统计关系是指两事物之间的一种非—对应的关系,即当一个变量X取一定值时,另一个变量
Y无法根据确定的函数取一定的值。统计关系可分为线性关系和非线性关系。
事物之间的函数关系比较容易分析和测度,而事物之间的统计关系却不像函数关系那样
直接,但确实普遍存在,并且有的关系强有的关系弱,程度各有差异。如何测度事物之间的
统计关系的强弱是人们关注的问题。相关分析正是一种简单易行的测度事物之间统计关系的有效工具。
**. Correlation is significant at the 0.01 level (2-tailed).
* Correlation is significant at the 0.05 level (2-tailed).
上表是对本次分析数据中,现工资、起始工资、本单位工作时间、以前工作时间、年龄五个
变量间的相关分析,表中相关系数旁边有两个星号(** )的,表示显著性水平为0.01时,
仍拒绝原假设。一个星号(* )表示显著性水平为0.05是仍拒绝原假设。先以现工资这一变量与其他变量的相关性为例分析,由上表可知,现工资与起始工资的相关性最大,相关系数
为0.880,而与在本单位的工作时间相关性最小,相关系数为0.084。
5、参数检验。