试验二线性回归分析的SPSS操作
SPSS回归分析过程详解

线性回归的假设检验
01
线性回归的假设检验主要包括拟合优度检验和参数显著性 检验。
02
拟合优度检验用于检验模型是否能够很好地拟合数据,常 用的方法有R方、调整R方等。
1 2
完整性
确保数据集中的所有变量都有值,避免缺失数据 对分析结果的影响。
准确性
核实数据是否准确无误,避免误差和异常值对回 归分析的干扰。
3
异常值处理
识别并处理异常值,可以使用标准化得分等方法。
模型选择与适用性
明确研究目的
根据研究目的选择合适的回归模型,如线性回 归、逻辑回归等。
考虑自变量和因变量的关系
数据来源
某地区不同年龄段人群的身高 和体重数据
模型选择
多项式回归模型,考虑X和Y之 间的非线性关系
结果解释
根据分析结果,得出年龄与体 重之间的非线性关系,并给出 相应的预测和建议。
05 多元回归分析
多元回归模型
线性回归模型
多元回归分析中最常用的模型,其中因变量与多个自变量之间存 在线性关系。
非线性回归模型
常见的非线性回归模型
对数回归、幂回归、多项式回归、逻辑回归等
非线性回归的假设检验
线性回归的假设检验
H0:b1=0,H1:b1≠0
非线性回归的假设检验
H0:f(X)=Y,H1:f(X)≠Y
检验方法
残差图、残差的正态性检验、异方差性检验等
非线性回归的评估指标
判定系数R²
SPSS实验8-二项Logistic回归分析
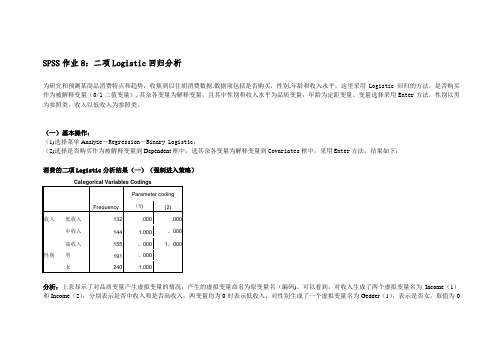
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。
线性回归—SPSS操作

线性回归—SPSS操作线性回归是一种用于研究自变量和因变量之间的关系的常用统计方法。
在进行线性回归分析时,我们通常假设误差项是同方差的,即误差项的方差在不同的自变量取值下是相等的。
然而,在实际应用中,误差项的方差可能会随着自变量的变化而发生变化,这就是异方差性问题。
异方差性可能导致对模型的预测能力下降,因此在进行线性回归分析时,需要进行异方差的诊断检验和修补。
在SPSS中,我们可以使用几种方法进行异方差性的诊断检验和修补。
第一种方法是绘制残差图,通过观察残差图的模式来判断是否存在异方差性。
具体的步骤如下:1. 首先,进行线性回归分析,在"Regression"菜单下选择"Linear"。
2. 在"Residuals"选项中,选择"Save standardized residuals",将标准化残差保存。
3. 完成线性回归分析后,在输出结果的"Residuals Statistics"中可以看到标准化残差,将其保存。
4. 在菜单栏中选择"Graphs",然后选择"Legacy Dialogs",再选择"Scatter/Dot"。
5. 在"Simple Scatter"选项中,将保存的标准化残差添加到"Y-Axis",将自变量添加到"X-Axis"。
6.点击"OK"生成残差图。
观察残差图,如果残差随着自变量的变化而出现明显的模式,如呈现"漏斗"形状,则表明存在异方差性。
第二种方法是利用Levene检验进行异方差性的检验。
具体步骤如下:1. 进行线性回归分析,在"Regression"菜单下选择"Linear"。
SPSS 统计分析多元线性回归分析方法操作与及分析

SPSS 统计分析多元线性回归分析方法操作与及分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals (残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表Variables Entered/Removed aModel Variables Entered VariablesRemoved Method1 城市人口密度(人/平方公里) . Stepwise (Criteria: Probability-of-F-t o-enter <= .050, Probability-of-F-t o-remove >= .100 ).2 城市居民人均可支配收入(元) . Stepwise (Criteria: Probability-of-F-t o-enter <= .050, Probability-of-F-t o-remove >= .100 ).该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
SPSS多元线性回归分析实例操作步骤-spss做多元线性回归
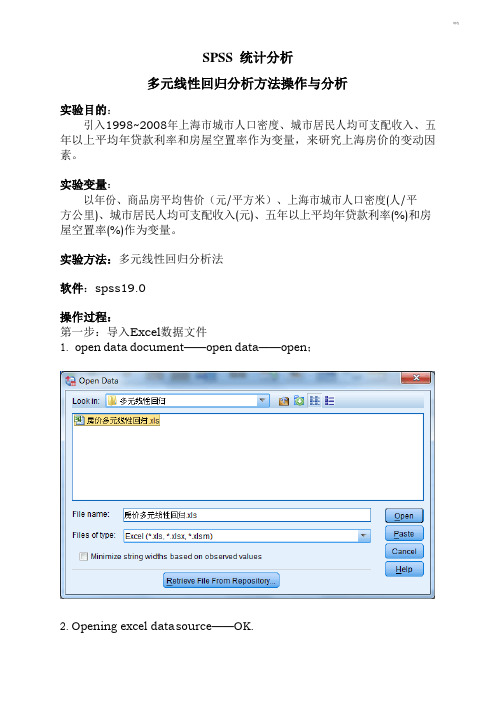
SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2.Opening excel data s ource——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear,Depende n(t因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics 默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDN T(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plo t(s标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.a. Predictors: (Constant), 城市人口密度 (人/平方公里)b. Predictors: (Constant), 城市人口密度 (人/平方公里), 城市居民人均可支配收入(元)c. Dependent Variable: 商品房平均售价(元/平方米)Variables Entered/Removed aModel 1Variables Entered 城市人口密度 (人/平方公里)Variables Removed2城市居民人均可支配收入(元)Method. Stepwise (Criteria: Probability-of-F-to-enter <= .050,Probability-of-F-to-remove >= .100).. Stepwise (Criteria: Probability-of-F-to-enter <= .050,Probability-of-F-to-remove >= .100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型的拟合情况。
SPSS—回归—多元线性回归结果分析(二)

SPSS—回归—多元线性回归结果分析(二)2011-10-27 14:44,最近一直很忙,公司的潮起潮落,就好比人生的跌岩起伏,眼看着一步步走向衰弱,却无能为力,也许要学习“步步惊心”里面“四阿哥”的座右铭:“行到水穷处”,”坐看云起时“。
接着上一期的“多元线性回归解析”里面的内容,上一次,没有写结果分析,这次补上,结果分析如下所示:结果分析1:由于开始选择的是“逐步”法,逐步法是“向前”和“向后”的结合体,从结果可以看出,最先进入“线性回归模型”的是“price in thousands"建立了模型1,紧随其后的是“Wheelbase"建立了模型2,所以,模型中有此方法有个概率值,当小于等于0.05时,进入“线性回归模型”(最先进入模型的,相关性最强,关系最为密切)当大于等 0.1时,从“线性模型中”剔除结果分析:1:从“模型汇总”中可以看出,有两个模型,(模型1和模型2)从R2 拟合优度来看,模型2的拟合优度明显比模型1要好一些(0.422>0.300)2:从“Anova"表中,可以看出“模型2”中的“回归平方和”为115.311,“残差平方和”为153.072,由于总平方和= 回归平方和+残差平方和,由于残差平方和(即指随即误差,不可解释的误差)由于“回归平方和”跟“残差平方和”几乎接近,所有,此线性回归模型只解释了总平方和的一半,3:根据后面的“F统计量”的概率值为0.00,由于0.00<0.01,随着“自变量”的引入,其显著性概率值均远小于 0.01,所以可以显著地拒绝总体回归系数为0的原假设,通过ANOVA方差分析表可以看出“销售量”与“价格”和“轴距”之间存在着线性关系,至于线性关系的强弱,需要进一步进行分析。
结果分析:1:从“已排除的变量”表中,可以看出:“模型2”中各变量的T检的概率值都大于“0.05”所以,不能够引入“线性回归模型”必须剔除。
SPSS专题2 回归分析(线性回归、Logistic回归、对数线性模型)

19
Correlation s lif e_ expectanc y _ f emale(y ear) .503** .000 164 1.000 . 192 .676**
cleanwateraccess_rura... life_expectancy_femal... Die before 5 per 1000
Model 1 2
R .930
a
R Square .866 .879
Model 1
df 1 54 55 2 53 55
Regres sion Residual Total Regres sion Residual Total
Mean Square 54229.658 155.861 27534.985 142.946
2
回归分析 • 一旦建立了回归模型 • 可以对各种变量的关系有了进一步的定量理解 • 还可以利用该模型(函数)通过自变量对因变量做 预测。 • 这里所说的预测,是用已知的自变量的值通过模型 对未知的因变量值进行估计;它并不一定涉及时间 先后的概念。
3
例1 有50个从初中升到高中的学生.为了比较初三的成绩是否和高中的成绩 相关,得到了他们在初三和高一的各科平均成绩(数据:highschool.sav)
50名同学初三和高一成绩的散点图
100
90
80
70
60
高 一成 绩
50
40 40
从这张图可以看出什么呢?
50 60 70 80 90 100 110
4
初三成绩
还有定性变量 • 该数据中,除了初三和高一的成绩之外,还有 一个定性变量 • 它是学生在高一时的家庭收入状况;它有三个 水平:低、中、高,分别在数据中用1、2、3 表示。
SPSS的线性回归分析分析

SPSS的线性回归分析分析SPSS是一款广泛用于统计分析的软件,其中包括了许多功能强大的工具。
其中之一就是线性回归分析,它是一种常用的统计方法,用于研究一个或多个自变量对一个因变量的影响程度和方向。
线性回归分析是一种用于解释因变量与自变量之间关系的统计技术。
它主要基于最小二乘法来评估自变量与因变量之间的关系,并估计出最合适的回归系数。
在SPSS中,线性回归分析可以通过几个简单的步骤来完成。
首先,需要加载数据集。
可以选择已有的数据集,也可以导入新的数据。
在SPSS的数据视图中,可以看到所有变量的列表。
接下来,选择“回归”选项。
在“分析”菜单下,选择“回归”子菜单中的“线性”。
在弹出的对话框中,将因变量拖放到“因变量”框中。
然后,将自变量拖放到“独立变量”框中。
可以选择一个或多个自变量。
在“统计”选项中,可以选择输出哪些统计结果。
常见的选项包括回归系数、R方、调整R方、标准误差等。
在“图形”选项中,可以选择是否绘制残差图、分布图等。
点击“确定”后,SPSS将生成线性回归分析的结果。
线性回归结果包括多个重要指标,其中最重要的是回归系数和R方。
回归系数用于衡量自变量对因变量的影响程度和方向,其值表示每个自变量单位变化对因变量的估计影响量。
R方则反映了自变量对因变量变异的解释程度,其值介于0和1之间,越接近1表示自变量对因变量的解释程度越高。
除了回归系数和R方外,还有其他一些统计指标可以用于判断模型质量。
例如,标准误差可以用来衡量回归方程的精确度。
调整R方可以解决R方对自变量数量的偏向问题。
此外,SPSS还提供了多种工具来检验回归方程的显著性。
例如,可以通过F检验来判断整个回归方程是否显著。
此外,还可以使用t检验来判断每个自变量的回归系数是否显著。
在进行线性回归分析时,还需要注意一些统计前提条件。
例如,线性回归要求因变量与自变量之间的关系是线性的。
此外,还需要注意是否存在多重共线性,即自变量之间存在高度相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《管理定量分析与软件应用》实验教学指导书刘远编著浙江师范大学文科综合实验教学中心目录《管理定量分析与软件应用》课程实验教学大纲 (1)实验一中英文科技论文检索 (4)实验二线性回归分析的SPSS操作 (9)实验三层次分析法的软件实现 (15)实验四运输问题的软件实现 (20)实验五风险决策的Excel实现 (25)实验六ABC分类法的Excel实现 (29)实验七使用WinQSB解决存储论问题 (33)实验八库存管理的Excel实现 (38)《管理定量分析与软件应用》课程实验教学大纲课程类别:管理类课程编号:0110100009总课时:34总学分:2课程负责人:刘远任课教师:刘远一、课程简介、目的与任务《管理定量分析与软件应用》为经济与管理学院工商管理专业的专业核心必修课程。
本课程侧重于企业管理领域内的定量分析方法的原理研究和实践运用。
在对主要数学理论和应用技术综合整理的基础上,结合企业管理的实际需求,对定量分析方法的各种应用思路和应用案例进行讲述和讨论,使学生提高已掌握的各种定量分析方法的综合应用能力,了解前沿的定量分析方法(包括多元线性回归、线性规划、不确定性决策、层次分析法、运输问题等)的基本原理和实施手段,掌握定量分析技术的学习方法。
二、课程的地位和作用课程的授课对象为工商管理专业大三的学生,主要教授一些常用的管理定量分析方法,辅以计算机软件进行求解。
一方面,本课程对学生之前学习的数学类课程(如微积分、统计学、线性代数)和计算机类课程(如Office、C语言等)是一种传承和延伸;另一方面,本课程也为学生们一年后的本科毕业论文写作提供强有力的理论支持。
本门课程的上机实验主要依托于学院文科综合实验室资源,结合课程中关键问题开设上机实验课,使学生们能够熟练地利用计算机软件(如Excel、SPSS、Win QSB、Lingo等)对相应的管理问题进行仿真求解,提高学生软件操作能力,增强学生对管理定量方法的兴趣。
1三、课程的基本要求由《管理定量分析与软件应用》课程讲授教师负责,由实验室人员配合指导。
指导教师应在每次实验前讲清实验目的、实验要求、相关知识等,指导学生在规定的时间内完成相关课程实验。
同学们按要求(必要时分组)进行实验,在实验过程中务必要在老师的指导下逐步操作,多练习、多操作、多思考,举一反三,及时记录实验过程数据与发现的问题并进行探索求证。
课后认真总结实验,记录在分析问题、解决问题的过程及心得体会,写出实验报告。
四、实验环境及设备、材料要求硬件设备:多媒体系统、50台左右联网计算机(32位Windows系统,)软件要求:安装Office2003、SPSS16、Lingo11和WinQSB软件五、实验内容安排本指导书结合《定理管理分析与软件应用》课程中涉及的关键问题,每隔1~2周理论传授后进行一次上机实验。
实验报告书共分为8个上机实验,其中必修实验5个,选修实验3个。
主要框架如表1所示,其中实验1~实验5为必修内容,实验6~实验8为选修内容。
2表1实验内容安排表六、实验考核实验课程后,学生需要按照教师要求独立完成课后习题,并认真填写实验报告,上交习题最终结果和关键步骤的软件输出。
结合实验内容,总结手动计算和软件仿真之间的优劣,以实验心得和未来可能应用为主题撰写心得体会,以供任课教师测试考核。
3实验一中英文科技论文检索一、实验目的1.掌握科技论文的基本检索方法2.熟练使用主流检索平台下载高水平论文3.了解科技论文的基本构成二、实验预习内容浙师大图书馆网页及其基本功能三、实验内容1.下载主流的科技论文阅读软件PDF和CAJ登陆网站http://10.1.136.55/help/ruanjian.htm,下载Adobe Reader8.0和中国知网CNKI期刊全文阅读器7.0。
2.进入浙师大图书馆,选择“数字资源页面”浙师大图书馆网址:/,数字资源页面网址:http://10.1.136.55/elec/ListShow/example.asp。
4““3.选择“中文数据库”,进入“中国学术期刊全文数据库”主流的3种中文数据库为“中国学术期刊全文数据库”、万方数据资源”和“维普中文科技期刊全文数据库”。
使用方法大同小异,接下来操作以“中国学术期刊全文数据库”为例。
4.中国学术期刊全文数据库”检索中文高水平文献1)中文期刊论文检索在“中国知网”主页选择“期刊”,点击进入。
2)选择学科领域,输入论文检索条件网页左侧选择“学科领域”,勾选与所需文献类似的专业文献;在对话框中选择论文检索条件,如“主题、作者、期刊”等;选择论文起止年限(一般选择近5-10年)和论文类型(SCI期刊、Ei期刊或核心期刊)。
如需输入多个检索条件(例如:主题+作者+单位),可以选择“高级检索”,输入对应信息。
不输入对应信息,默认为全部信息。
53)选择感兴趣的文献,下载存盘尽量选择高水平文献资料,可以参考论文“被引”和“下载”次数。
如果文献数量较多,在“来源类别”中尽量选择“中文社会科学引文索引”。
6“选择论文,点击下载存盘(CAJ 或者 PDF 格式)5.中国学术期刊全文数据库”检索中文高水平学位论文 在“中国知网”首页选择“博硕”,论文检索方法与期刊论文类似。
6.在“Web of Science 数据库”检索并下载高水平英文文献在“数字资源”页面进入“Web of Science 数据库”7.输入检索条件,选择论文时间范围在检索框中就“主题、题目、作者”等信息输入检索条件,确定论文时间范 围。
78.选择合适文献,下载全文确定与自己研究相近的“研究领域”和“研究方向”;尽量选择高“被引频次”的文献,可以选择“被引频次”降序排列。
选择所需文献,点击“全文”即可下载。
四、实验作业1.请在“中国期刊全文数据库”中,以“决策”为主题,搜索作者“王正新”、单位“浙江师范大学”的文章,列出题目和期刊。
2.请在“中国期刊全文数据库”中,搜索作者“段文奇”、单位“浙江师范大学”的文章,列出“被引频次”最高的题目、期刊及其被引频次。
3.请在“中国期刊全文数据库”中,搜索到作者“李辉”、单位“哈尔滨工业大学”的博士学位论文,列出题目及被引频次。
4.在在“Web of Science数据库”中,以“conflict analysis”为主题,以“Hipel”为作者,搜索2005-2014年度的论文,并列举出“被引频率”前3的论文题目、期刊及其被引频次。
8实验二线性回归分析的SPSS操作一、实验目的1.掌握SPSS软件的安装和常用的使用方法2.熟悉SPSS软件的界面组成3.学会使用SPSS得到线性回归模型并对其进行分析二、实验预习内容1.线性回归拟合的基本原理2.模型误差分析方法3.运用回归模型进行点预测三、实验内容1.安装、破解并汉化SPSS从任课教师处下载SPSS安装包,解压缩、安装(点击)、破解并汉化(将regedit.exe复制到SPSS安装目录,双击后点击patch it!完成注册;双击cn.exe,选择SPSS安装目录,应用汉化补丁)。
2.输入基本数据选择,以列为输入数据。
在“variable view”中输入数列名称(y,x1,x2等),在“data view”输入具体数据。
注:可以从Excel中拷贝。
3.形成散点图点击“图表-交叉图表-散点图”,选择“X轴”和“Y轴”,点击“确定”即可。
如果线性较差,一元线性回归计算时注意变量转换,多元线性回归计算时重点关注该变量,如果模型不能通过检验,可以考虑剔除该变量。
4.得到线性回归模型1)选择“回归分析-线性”。
2)输入自变量和因变量。
3)在“统计”选项中选择需要的检验类别。
一元线性回归多元线性回归4)测算常数项和自变量系数。
Coefficients表格,,B列下面对应数字。
5.模型检验1)相关系数检验(拟合优度检验,R检验);Model Summary表中,,如果大于R0.05(n-m),即通过R检验,n为样本数,m为自变量数。
2)回归方程的显著性检验(F检验);ANOV A表中,,如果大于F0.05(m-1,n-m),即通过F检验。
简便方法,sig下数字,如果小于0.05,即通过F检验。
3)回归系数的显著性检验(t检验);Coefficients表格,,如果t列下数据的绝对值大于tα(n-m),即通过t检验。
简便方法,sig下数字,如果小于0.05,即通过t检验。
如果某变量t检验不通过,则剔掉该变量,重新构建回归模型。
4)残差的自相关检验(DW检验)Model Summary 表中,,根据 n 和 m 数值,查 DW 检验表,可得d L, d U。
通过检验标准如下:检验无结论4-d u ﹤DW ﹤4- d L检验无结论若 DW 没通过,可采用“逐步回归”方法调整模型,方法略。
6. 时间序列的点预测根据新出现的自变量 x ,预测对应因变量 y 。
四、实验作业1. 1978-2010 年间,我国 GDP 数据、居民人均消费和总人口数据如下,请 将国民总支出(亿元)作为因变量 y ,GDP (亿元)为自变量 x ,构建一元线性回归模型 y = ax + b 亿元,请预测201119859016.010*******12198610275.2107507497198712058.6109300565198815042.8111026714198916992.3112704788199018667.8114333833199121781.5115823932199226923.51171711116199335333.91185171393199448197.91198501833199560793.71211212355199671176.61223892789199778973.01236263002199884402.31247613159199989677.11257863346200099214.612674336322001109655.212762738872002120332.712845341442003135822.812922744752004159878.312998850322005184937.413075655732006216314.413144862632007265810.313212972552008314045.413280283492009340902.813345090982010401202.013409199682.目前,我国国民收入实现了快速增长,民航业蓬勃发展,为了对民航业务量做出准确地评估和预测,民航客运量的变化趋势及成因成为航空公司关心的主要问题。
影响我国民航客运量的因素,不仅有经济因素、政治因素,还有天气因素、季节因素,这些因素对我国民航客运量的变化影响程度各有不同,而这些因素的不同组合也会产生不同的效果。