eviews阿尔蒙多项式法
用加法乘法方式引入虚拟变量 阿尔蒙多项式法估计有限分布滞后模型

《计量经济学》上机指导手册三目录§3.1 实验介绍 (2)3.1.1 上机实验名称 (2)3.1.2 实验目的 (2)3.1.3 实验要求 (2)3.1.4 数据资料 (2)§3.2 用加法和乘法加入虚拟变量 (4)3.2.1 用加法方式引入虚拟变量 (4)3.2.2 用乘法方式引入虚拟变量 (6)§3.3 阿尔蒙多项式法估计有限分布滞后模型 (9)3.3.1 参数估计(方法一) (15)3.3.2 参数估计(方法二) (15)3.3.3 还原模型 (17)§3.4 Granger因果检验.............................................................................................. 错误!未定义书签。
3.4.1 序列平稳性检验及调整........................................................................ 错误!未定义书签。
3.4.2 Granger因果检验 ................................................................................... 错误!未定义书签。
§3.1 实验介绍3.1.1 上机实验名称用加法和乘法引入虚拟变量阿尔蒙多项式估计有限分布滞后模型Granger因果检验3.1.2 实验目的通过对用加法和乘法引入虚拟变量、阿尔蒙多项式估计有限分布滞后模型、Granger因果检验的练习,掌握经典单方程模型中一些专门问题的理解及软件操作。
3.1.3 实验要求根据实验数据,完成实验报告。
对于已经完成的工作,请自我测评。
将完成要求的标题标成蓝色,未完成的标成红色。
例如:3.1.4 数据资料(1)《14-15-1 EViews上机数据3.xls》中《Dummy Variable》(2)《14-15-1 EViews上机数据3.xls》中《Almon》(3)《14-15-1 EViews上机数据3.xls》中《Granger Test》§3.2 用加法和乘法加入虚拟变量根据1965年-1970年美国制造业的利润和销售额季度数据(见《14-15-1 EViews上机数据3.xls》中《Dummy Variable》),判断利润是否除了与销售额有关,还与季度因素有关。
滞后变量讲义

滞后解释变量X
t
,最大限度地节省了自由度,
i
解决了滞后期长度k难以确定的问题;
二是由于滞后一期的被解释变量Yt
1与X
的线性
t
相关程度小于X的各期滞后值之间的相关程度,
从而缓解了多重共线性。
柯伊克变换的缺点:
一是模型存在随机误差项vt的一阶自相关性;
二是随机解释变量Yt1与随机项vt相关,即 Cov(Yt1,vt ) 0.
四、分布滞后模型的估计
1.经验权数法 所谓经验权数法,是根据实际经济问题的特点 及经验判断,对滞后变量赋予一定的权数,利用这 些权数构成各期滞后变量的线性组合,以形成新的 变量,再应用最小二乘法进行估计。
根据滞后结构的特点,经常使用的权数类型有:
(1)递减型:即各期权值是递减的,此时假定随着 时间的推移,解释变量的影响将逐期降低。例如, 消费函数模型
是相同的。
3.柯依克(Koyck)方法
柯依克方法是将无限分布滞后模型转换为自 回归模型,然后进行估计。
对于无限分布滞后模型
Yt 0 X t 1X t1 ut (1)
柯依克假定βi具有相同的符号,并且按几何级数 递减:
i 0i , i=0,1,2,
(2)
其中λ是一个介于0和1之间的常数,λ值的大小
三、滞后变量模型估计时存在的问题
(1)多重共线性问题; (2)自由度问题; (3)滞后长度难以确定。
处理方法:
对于有限分布滞后模型,其基本思想是设法有目 的地减少需要直接估计的模型参数个数,以缓解 多重共线性,保证自由度。
对于无限分布滞后模型,主要是通过适当的模型 变换,使其转化为只需估计有限个参数的自回归 模型。
(2)用OLS估计模型
计量经济学解题整理
'
'
②代入公式 S
E (Y0 )
' 2 X 0 (X ' X )X 0 求出 Y 均值的标准差
③把结果代入均值的置信区间公式 Y 0 t a / 2 S
E (Y0 )
即可得到置信区间
三:多元线性回归模型
1.参数估计的普通最小二乘估计
(1)在命令窗口中输入 data x1 x2 y,录入数据
RSS 2 RSS1
(8)给定一个显著性水平 a,F 的临界值为 Fa ( 观察值个数) (9)若 F> Fa (
nc nc k 1, k 1 )(c 为去除的 2 2
nc nc k 1, k 1 ),则拒绝无异方差性假设,模型存在异方差性。 2 2
(三)White 检验 (1)用 OLS 方法求得原模型的估计结果
Y 的个别值的预测置信区间为 Y 0 t a / 2 S ,其中 S 为 Y 的个别值预测的标准差为
Y0 Y0 ' S 2 [1 X 0 ( X ' X ) X 0 ] Y0
①在 Equation 框中,点击“Forecast”,弹出 Forecast 话框,S.E.一栏为预测值的标准 差,命名为 yczbzc,点击 OK,即可在 Workfile 界面看到一个名为 yczbzc 的序列。
(2)被解释变量 Y 均值区间预测公式
(3)进行计算时, Y f 可以在前面点预测序列 yf2 中找到; t a / 2 可以查 t 分布表得到;样本 数 n 为已知; X ew/Descriptive Statistics/Common Sample,得描述统计结果,其中:Mean 为均值,Std.Dev 为标准差) ;由 总体方差的无偏估计式 方法二:
eviews操作及案例-简版
■ 成本分析和预测
■ 蒙特卡罗模拟
■ 经济模型的估计和仿真 ■ 利率与外汇预测
EViews 引入了流行的对象概念,操作灵活简便,可采用多种操作方式进行各种计量分
析和统计分析,数据管理简单方便。其主要功能有:
(1)采用统一的方式管理数据,通过对象、视图和过程实现对数据的各种操作;
(2)输入、扩展和修改时间序列数据或截面数据,依据已有序列按任意复杂的公式生
实验七 ___________________________________________________________67
1
FuRretAlphlreorridrguehctpesrdordewsuitectrhivopenedrpbrmyioshEsiicbooitnneoodfmtewhtitreihccosoutIpynprsiteirgthumttiesosiowfonnSe.r.WUFE.
第一部分 EViews 基本操作
第一章 预 备 知识
一、什么是 EViews
EViews (Econometric Views)软件是 QMS(Quantitative Micro Software)公司开发的、基
于 Windows 平台下的应用软件,其前身是 DOS 操作系统下的 TSP 软件。EViews 具有现代
自 结合课程论文,自拟上机内容(不低于 定 10 学时上机)。
FuRretAlphlreorridrguehctpesrdordewsuitectrhivopenedrpbrmyioshEsiicbooitnneoodfmtewhtitreihccosoutIpynprsiteirgthumttiesosiowfonnSe.r.WUFE.
滞后变量回归模型-阿尔蒙多项式变换

滞后变量模型的应用
为了考察时间滞后影响,现给出2003年到2015年四川省房地产业固定资产投资与销售额的统计数据1如下表所示:
1、设定模型,做局部调整假设:
(0<1)
则原模型变换为
1来源于国家统计局网站地区数据
利用Eviews软件对上述模型进行估计,结果如下:
即
(3.954) (9.456)
F=637.837 DW=1.846
从回归结果可以求得原模型的回归系数:,
,,所以理想的固定投资函数为:
2、设定模型,做自适应预期假定:
其中,0<<1。
于是,原模型变换为:
其中,。
由于该模型存在解释变量与滞后被解释变量同期相关的问题,不能直接进行OLS估计,故采用工具变量法进行估计。
即估计结果如下:
(3.954) (9.456)
F=637.837
3、假设房地产业固定资产投资受当期和前三期销售影响显著,利用阿尔蒙多项式变换估计以下有限分布滞后模型:
a+
利用阿尔蒙变换,令,原模型变换为
a++
利用Eviews软件估计结果如下:
164.5781+
(1.408)(0.902)(0.605)
F=373.251 DW=3.081
4、设定模型ln,做局部调整——自适应预期综合模型进行估计:
0.139+
(3.495)(2.282)(1.378)
F=525.009 DW=1.65
该模型通过t检验、F检验都显著,拟合优度较高,且不存在一阶、二阶自相关。
该模型也较好地解释了房地产业固定资产投资与销售额之间的关系。
用加法乘法方式引入虚拟变量 阿尔蒙多项式法估计有限分布滞后模型

《计量经济学》上机指导手册三目录§3.1 实验介绍 (2)3.1.1 上机实验名称 (2)3.1.2 实验目的 (2)3.1.3 实验要求 (2)3.1.4 数据资料 (2)§3.2 用加法和乘法加入虚拟变量 (3)3.2.1 用加法方式引入虚拟变量 (3)3.2.2 用乘法方式引入虚拟变量 (5)§3.3 阿尔蒙多项式法估计有限分布滞后模型 (7)3.3.1 参数估计(方法一) (7)3.3.2 参数估计(方法二) (8)3.3.3 还原模型 (9)§3.4 Granger因果检验............................................................................. 错误!未定义书签。
3.4.1 序列平稳性检验及调整........................................................... 错误!未定义书签。
3.4.2 Granger因果检验...................................................................... 错误!未定义书签。
§3.1 实验介绍3.1.1 上机实验名称用加法和乘法引入虚拟变量阿尔蒙多项式估计有限分布滞后模型Granger因果检验3.1.2 实验目的通过对用加法和乘法引入虚拟变量、阿尔蒙多项式估计有限分布滞后模型、Granger因果检验的练习,掌握经典单方程模型中一些专门问题的理解及软件操作。
3.1.3 实验要求根据实验数据,完成实验报告。
对于已经完成的工作,请自我测评。
将完成要求的标题标成蓝色,未完成的标成红色。
例如:3.1.4 数据资料(1)《14-15-1 EViews上机数据 3.xls》中《Dummy Variable》(2)《14-15-1 EViews上机数据 3.xls》中《Almon》(3)《14-15-1 EViews上机数据 3.xls》中《Granger Test》§3.2 用加法和乘法加入虚拟变量根据1965年-1970年美国制造业的利润和销售额季度数据(见《14-15-1 EViews 上机数据 3.xls》中《Dummy Variable》),判断利润是否除了与销售额有关,还与季度因素有关。
Eviews_教程

Eviews 教程(案例介绍)一、单方程计量经济模型参数估计与统计检验例1 为了研究税收(T )发展状况,选择国内生产总值(GDP )、财政支出(GE )为影响因素,建立计量经济模型分析因素之间的经济关系。
选取下表的有关统计数据,模型如下:t t t t GE GDP T μβββ+++=210税收收入等有关统计数据 单位:亿元借助该财政收入模型案例,采用Eviews6.0估计模型中参数,并进行相关的统计检验,确定最终模型。
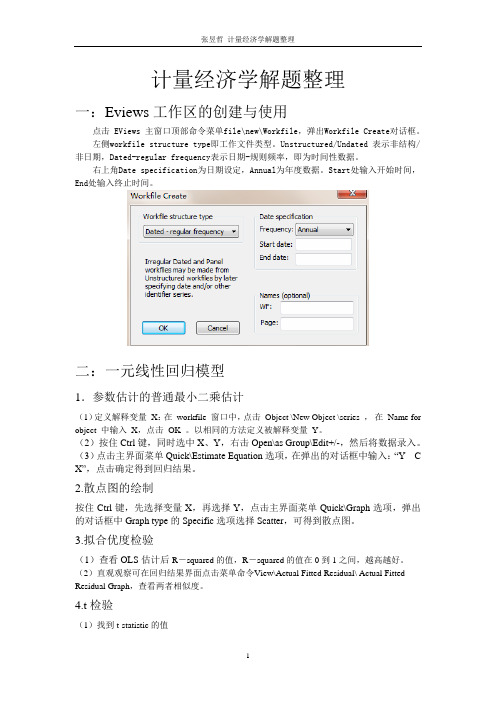
Eviews软件模型分析过程如下:1.创建工作文件启动Eviews软件,在主菜单上依次单击File→New→Workfile,选择数据类型(时间序列或非时间序列),并输入样本区间和工作文件名,创建工作文件的子窗口如图1-1所示。
图1-1 创建工作文件2.建立变量组Eviews软件建立变量组可采用三种途径:(1)在主菜单上依次单击Quick→Empty Group,在数据编辑窗口中单击Edit+/-,并按上行健↑,这样可依次输入变量名;(2)在主菜单上依次单击Objects→New Objects,在对话框中选择“Group”并定义文件名,在数据编辑窗口中首先按上行健↑,这样可依次输入变量名;(3)在主菜单上Eviews命令框中直接输入命令:Data T GDP GT CPI(命令及变量名之间用空格分隔),将直接出现已定义变量名称的数据编辑窗口。
图1-2 数据编辑窗口3.输入经济变量的样本数据在图1-2所示的数据编辑窗口中,在“NA”的位置可输入各经济变量的样本数据,输入样本数据后及时予以保存。
样本数据也可以从有关Office软件的各类表格中进行数据的复制;也可以通过Eviews 软件本身生产新的变量数据序列,如在主菜单上依次单击Quick→Generate Series、或者在工作文件(Workfile)窗口中单击Generate,在弹出窗口中输入方程式,如图1-3所示。
图1-3 生产新变量数据序列4.估计模型参数在主菜单上依次单击Quick→Estimate Equation,弹出对话框,在“Specification”选项卡中输入模型中被解释变量、常数项、解释变量序列,并选择估计方法及样本区间,如图1-4所示,估计结果如图1-5。
第三讲eviews多元线性回归模型ppt课件

“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
3.2 多元线性回归模型的检验
3.2.1 拟合优度检验
拟合优度是指样本回归直线与观测值之间的拟合程度。 1.多重决定系数
总离差平方和=残差平方和+ 回归平方和 自由度: (n-1)= (n-k-1)+ k ESS:由回归直线(即解释变量)所解释的部分,表示x对y的线性影响。 RSS:是未被回归直线解释的部分,由解释变量x对y影响以外的因素而造成的。
507.7
613.9
563.4
501.5
781.5
541.8
611.1
1222.1
793.2
660.8
792.7580.8Fra bibliotek612.7
890.8
1121.0
1094.2
1253.0
家庭收入 x 1027.2 1045.2 1225.8 1312.2 1316.4 1442.4 1641.0 1768.8 1981.2 1998.6 2196.0 2105.4 2147.4 2154.0 2231.4 2611.8 3143.4 3624.6
“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
多重决定系数或决定系数是指解释变差占总变差的比重,用来表述解 释变量对被解释变量的解释程度:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
eviews阿尔蒙多项式法,也称为Almon polynomial method,是一种在计量经济学中常
用的时间序列分析方法之一。
该方法用于处理具有滞后效应的自变量对因变量的影响。
具体而言,Almon polynomial method将自变量的滞后效应建模为一个多项式函数。
这
个多项式函数可以用来拟合不同滞后期的影响,并且可以根据数据的特征进行调整。
在EViews软件中,可以使用Almon多项式法进行时间序列回归分析。
通过指定滞后
期数和多项式度数,可以估计出各个滞后期对应的权重系数,进而得到回归方程。
需要注意的是,Almon多项式法适用于具有滞后效应的数据分析,但并不适用于所有
情况。
在使用该方法时,需要考虑数据的特点和目标研究问题的要求,以便选择适当
的模型和方法进行分析。