Evaluating Passage Retrieval Approaches for Question Answering
提高学习策略的计划英语

提高学习策略的计划英语## Plan to Enhance Learning Strategies ##。
Mind Mapping.Mind mapping is a visual learning strategy that helps learners organize information into a logical and hierarchical structure. This technique can be used to understand complex concepts, connect different ideas, and enhance memory.Active Recall.Active recall is a learning strategy that involves retrieving information from memory without looking back at notes. It promotes long-term retention and forces learners to engage with the material more deeply. Flashcards and spaced repetition algorithms can be used to facilitate active recall.Spaced Repetition.Spaced repetition is a technique that involves distributing study sessions over time in increasing intervals. This approach improves memory and helps learners retain information for longer periods. Applications like Anki and SuperMemo employ spaced repetition algorithms.Metacognition.Metacognition is the ability of learners to reflect on their learning process and adjust their strategies accordingly. It involves planning, monitoring, and evaluating one's learning. Regular self-reflection and evaluation can help learners identify areas for improvement and develop more effective learning habits.Interleaving.Interleaving is a learning strategy that involves alternating between different subjects or concepts during a study session. This approach helps learners buildconnections between different areas and promotes deeper understanding. It prevents boredom and improves retention compared to studying each subject separately.Retrieval Practice.Retrieval practice is a method of actively retrieving information from memory, usually through self-testing or quizzes. This process strengthens memories and enhances long-term retention. Practice tests and mock exams can be used to implement retrieval practice.## 中文回答, ##。
2015届高考英语典型试题精粹 专题十六 七选五

专题十六七选五高考精萃Passage 1(2014·北京卷)Evaluating Sources of Health InformationMaking good choices about your own health requires reasonable evaluation. A key first step in bettering your evaluation ability is to look carefully at your sources of health information. Reasonable evaluation includes knowing where and how to find relevant information, how to separate fact from opinion, how to recognize poor reasoning, and how to analyze information and the reliability of sources. __1__Go to the original source. Media reports often simplify the results of medical research. Find out for yourself what a study really reported, and determine whether it was based on good science. Think about the type of study. __2__Watch for misleading language. Some studies will fi nd that a behavior “contributes to” or is “associated with” an outcome; this does not mean that a certain course must lead to a certain result. __3__ Carefully read or listen to information in order to fully understand it.Use your common sense. If a report seems too good to be true, probably it is. Be especially careful of information contained in advertisements. __4__ Evaluate “scientific” statements carefully, and be aware of quackery(江湖骗术).__5__ Friends and family members can be a great source of ideas and inspiration, but each of us needs to find a healthy lifestyle that works for us.Developing the ability to evaluate reasonably and independently about health problems will serve you well throughout your life.A.Make choices that are right for you.B.The goal of an ad is to sell you something.C.Be sure to work through the critical questions.D.And examine the findings of the original research.E.Distinguish between research reports and public health advice.F.Be aware that information may also be incorrectly explained by an author's point of view.G.The following suggestions can help you sort through the health information you receive from common sources.答案与解析本文为说明文。
新版雅思阅读技巧和方法

雅思阅读考试方法与技巧
Hale Waihona Puke 2 Skimming Skimming involves reading quickly through a text to get an overall idea of its contents. Features of the text that can help you include the following: (a) Title (b) Sub-title(s) (c) Details about the author
雅思阅读考试方法与技巧
雅思文章虽然长度惊人,但题目所涉及信 息量的排列是有规律的,读任何文章都必 须掌握其中的必然因素,如人文科学中的 时间、地点、学者观点,自然科学文章中 的现象、发生的原因、科学发展的趋势等, 这些文章类型与基本结构对考生都是非常 重要的。雅思基本文章类型及出处主要为: 1. 关于欧洲及世界社会发展、经济状况、 科学动向以及文化交流的文章
雅思阅读考试方法与技巧 -田杨
雅思阅读考试方法与技巧
Chapter One READING STRATEGIES AND SKILLS This course will give you the opportunity to develop and practice reading strategies and skills which can be applied to all forms of IELTS tests. The strategies and skills you will practice are as follows:
雅思阅读考试方法与技巧
Chapter Two 阅读篇 一、雅思阅读考试概述(学术类) IELTS学术类阅读由3篇独立的文章组成,文章长 度一般在800~1200词之间。3篇文章包括有8种 左右的题型,共有40道题目。 雅思的每篇文章前都会提示考生须用20分钟完成 试题,3篇文章共需1个小时。因此提高阅读速度 或者掌握必要技巧,以在规定时间内完成试题是 成功与否的关键。
QA Passage Retrieval

Fuzzy relation matching for passage retrieval Extracting and paring relation paths
Generating dependency trees for question or candidate sentences using Minipar. – In a dependency tree, each node represents a word or a chunked phrase – Links between nodes represent the dependency relaБайду номын сангаасions
To determine the relevance of a sentence given another sentence (or question) in terms of dependency relations – Two paths from two sentences are determined as paired corresponding paths if their nodes at both ends are matched.
–
Example
No. 14
Fuzzy relation matching for passage retrieval Measuring path matching score
To measure the matching score of the paths extracted from the sentence according to those from the question. – Example
Introduction
2020智慧树知道网课《英语学术论文写作》课后章节测试满分答案
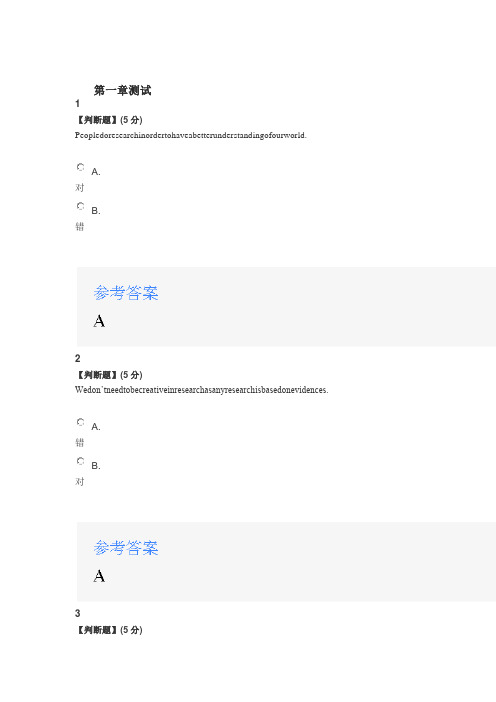
第一章测试1【判断题】(5分) Peopledoresearchinordertohaveabetterunderstandingofourworld.A.对B.错2【判断题】(5分)Wedon’tneedtobecreativeinresearchasanyresearchisbasedonevidences.A.错B.对3【判断题】(5分)Goodresearchquestionsareimportantinresearch.A.错B.对4【判断题】(5分) Literaturereviewisneededinsomeresearchpapers.A.对B.错5【判断题】(5分) Agoodresearchpaperneedscarefulrevisingandproofreading.A.错B.对6【判断题】(5分) Unintentionalplagiarismcanbeexcusedasitisnotcommitteddeliberately.A.对B.错7【判断题】(5分) Academicfalsificationisonecommontypeofacademicdishonesty.A.对B.错8【多选题】(5分) Whatroledoesaliteraturereviewplayinaresearchpaper?A.Itenhancesthecredibilityofyourpaper.B.Itprovestheexistenceofaresearchgap.C.Itsynthesizestheexistingstudiesinyourarea.D.Itprovidesevidencesforyourargument.9【单选题】(5分) WhichofthefollowingisNOTanessentialstepinaresearchpaperwriting?A.ChoosingatopicB.ConsultinginstructorsC.LocatingsourcesD.OutliningthePaper10【多选题】(5分) Whichofthefollowingmayleadtoacademicdishonesty?A.AcademicplagiarismB.AcademicpromotionC.AcademicinterestD.Academicfabrication第二章测试1【多选题】(5分)Inchoosingaresearchtopic,whichofthefollowingdoweneedtoconsider?A.PublicationpossibilitiesB.AcademicimportanceC.OurresearchinterestD.Ourmanageability2【判断题】(5分)Tocheckthevalidityofaresearchtopic,weneedtobecriticalenough.A.对B.错3【判断题】(5分) Itisanactofplagiarismifonesimplyparaphrasesabookforaresearchpaper.A.对B.错4【判断题】(5分) StudentsshouldbebraveenoughtotrychallengingissuesfortheirBAtheses.A.对B.错5【判断题】(5分) Carefulreadingofliterarytextisimportantinliterarystudies.A.对B.错6【判断题】(5分) Literarytheoriestakepriorityoverliterarytextsinliteraryanalysis.A.错B.对7【判断题】(5分) ICstudycanbechallengingbutinterestingandpracticalinlife.A.错B.对8【判断题】(5分) Expertssharesimilarunderstandingsoverthestandardsoftranslation.A.错B.对9【判断题】(5分) Translationstrategiesandtranslationtechniquesaredifferentconceptsintranslation.A.对B.错10【判断题】(5分) Sociolinguisticsisoneofthebranchesofappliedlinguistics.A.对B.错第三章测试1【判断题】(5分) Aworkingbibliographyincludesthesourceswehavesofarcollectedforaresearchproject.A.对B.错2【判断题】(5分) Knowingwhatsourcesyouneedisofvitalimportanceinevaluatingyoursources.A.错B.对3【判断题】(5分) Sourcesfromleadingscholarscanbeveryusefultoyourresearch.A.错B.对4【判断题】(5分)Inreadingsources,weneedtobecriticalandformourpersonalresponses.A.对B.错5【判断题】(5分) Theplanforanempiricalresearchshouldcoveritspurpose,method,subjects,andprocedure.A.错B.对6【判断题】(5分) Itiswisefortheobservernottotakepartintheactivityobservedatalltime.A.错B.对7【多选题】(5分)InBooleanLogic,ifonewantstosearchonlyforsourcesrelevantwithcomputervirus,thesearchformul ashouldbe_______.A.computernotvirusB.computernearvirusC.computerorvirusD.computerandvirus8【多选题】(5分) Theannotationofasourceinanannotatedbibliographymayhaveyour____:A.reflectionofthesourceB.adaptationofthesourceC.summaryofthesourceD.assessmentofthesource9【单选题】(5分)Inaquestionnaireentitled“ASurveyontheThirdYearEnglishMajors’EnglishVocabularyinXXUniv ersity”,the“thethirdyearEnglishmajors”shouldbe:A.ThetimeofthesurveyB.ThesubjectofthesurveyC.ThecontentofthesurveyD.Themodeofthesurvey10【单选题】(5分)Inanexperimententitled“AStudyontheEffectsofWriting-after-ReadingActivityonEnglishMajors EnglishVocabulary”,students’languageproficiencyshouldbe:A.IrrelevantvariableB.dependentvariableC.Independentvariable第四章测试1【判断题】(5分)Aresearchproposalshouldbepersuasiveinnature.A.错B.对2【判断题】(5分) Wecanaskforsuggestionsfromtheexpertsforourresearchinourproposal.A.错B.对3【判断题】(5分) Weneedtoputforwardourresearchquestionsinourresearchproposals.A.错B.对4【判断题】(5分) Aresearchproposaldemonstratesthesignificanceofourproposedresearch.A.错B.对5【判断题】(5分) Theliteraturereviewsectioninaproposalprovestheexistenceofaresearchgap.A.对B.错6【判断题】(5分)The“ApplicationoftheResearch”tellshowyourresearchwillbenefitinpractice.A.对B.错7【判断题】(5分)A“PreliminaryBibliography”isalistofthesourcesyouhavecitedinyourproposal.A.错B.对8【判断题】(5分) Thesignificanceofyourresearchemphasizespossibleresearchcontributions.A.对B.错9【判断题】(5分)Simpleasitis,aBAthesisproposalincludesalltheelementsinagrantresearchproposal.A.错B.对10【多选题】(5分)WhichofthefollowingisNOTincludedinthree-moveschemeoftheproposalsummary?A.researchneedB.potentialcontributionsC.possiblelimitationsD.researchmethod第五章测试1【判断题】(5分) Theuseofsignalphrasesincitationcanenhancethefluencyofwriting.A.对B.错2【判断题】(5分) Theintegrationofthesourcesmustfitourwritinginstructureandgrammar.A.错B.对3【判断题】(5分) Researchlimitationisacompulsoryelementinallresearchpapers.A.错B.对4【判断题】(5分) CARSModelisapatternforintroductionwritinginresearchpapers.A.对B.错5【判断题】(5分)Inrevising,weneedtofocusontheerrorslikegrammarandspelling.A.错B.对6【判断题】(5分) Aliteraturereviewmainlypresentsasummaryofeachsourceinchronologicalorder.A.错B.对7【单选题】(5分) Characteristicsofacademicwritingincludesallthefollowingexcept________.A.thefirst-personviewB.aformaltoneC.aclearfocusD.precisewordchoice8【单选题】(5分) Itisessentialtoalwaysacknowledgethesourceofborrowedideasinyourpaper.Todootherwiseisconsi dered_________.A.IgnoranceB.CarelessnessC.Plagiarism9【单选题】(5分)Whichofthefollowingarefeaturesofagoodtitle?A.ClearB.AlloftheaboveC.Attractive.D.Direct10【单选题】(5分)Abstractscanbedividedintotwotypes accordingto their_________.A.functionsB.length第六章测试1【判断题】(5分)MLAin-textcitationrequiresthattheauthorinformationshouldbeputeitherinthetextofthepaperorint heparentheticalcitation.A.错B.对2【判断题】(5分)InMLAdocumentation,parentheticalcitationinthetextofthepapermustalwaysincludetheauthor’sn ameandthework’stitle.A.错B.对3【判断题】(5分)MLAworkscitedlistisorganizedalphabeticallybytheauthor’slastnames(orbytitleforaworkwithnoa uthor).A.错B.对4【判断题】(5分)Whenawork’sauthorisunknown,theworkislistedunder“Anonymous”inthelistofMLAworkscited.A.错B.对5【单选题】(5分)Lee(2007)stated,“Theabilitytothinkcriticallyisneededinthisrevolutionaryageoftechnologicalcha nge”(p.82).Thein-textcitationusedhereis__________.A.integratedB.non-integrated6【多选题】(5分)WhatarethefunctionsofAPAdocumentation?A.Tociteothers’ideasandinformationusedwithinyourpaperB.TodemonstratethetypeofresearchconductedC.ToindicatethesourcesintheReferenceslist7【单选题】(5分)Writethelistofworkscited,usingtheAPAformat.Aparaphraseofanideafrompage121ofWritingSpace:TheComputer;Hypertext,andtheHistoryofWr iting,byJayDavidBolter.This1991bookwaspublishedbyLawrenceErlbaumAssociatesofHillsdale, NewJersey.Whichofthefollowingiscorrectfortheauthor’sname?A.Bolter,J.DB.J.D.BolterC.Jay,D.BolterD.Bolter,JayDavid【单选题】(5分)Writethelistofworkscited,usingtheAPAformat.Aquotationfrompage78ofanarticlebyBartKoskoandSatornIsakafromtheJuly1993issueofScientifi cAmerican,amonthlypublication.Thearticleisentitled"FuzzyLogic"andappearsonpages76to81in volume239,ofthejournal. Whichofthefollowingisthecorrectformatforthevolumeandpagernumber?A.ScientificAmerican,239,78B.ScientificAmerican,239,76-81C.ScientificAmerican,239:76-81D.ScientificAmerican,239,76-81.9【多选题】(5分)Bohren,M.A.,G.J.Hofmeyr,C.Sakala,R.K.Fukuzawa,andA.Cuthbert.(2017).Continuoussupportf orwomenduringchildbirth.CochraneDatabaseofSystematicReviews,2017(7).https:///10.1 002/14651858.CD003766.pub6Errorsmadeinthisentryinclude_________.A.authors’namesB.issuenumberC.theword“and”D.doinumber10【单选题】(5分)Perrey,S.(2017).Doweperformbetterwhenweincreaseredbloodcells?TheLancetHaematology,17, 2352-3026.https:///10.1016/S2352-3026(17)30123-0.RetrievedAugust23,2018.Whatinfo rmationisNOTneededinthisentry?A.ThedateofretrievalB.ThepagerangeC.Thedoinumber。
电子信息工程专业英语

The ability to analyze, evaluate, and apply information critically This investments distinguishing fact from opinion, identifying biases, and evaluating the reliability of sources
02
Electronic Information Engineering English Vocabulary
Vocabulary of electronic components
Inductor
A component used to store magnetic energy, commonly represented by the symbol L.
Professional course design and learning content
Professional courses: Typical courses in Electronic Information Engineering include analog electronics, digital electronics, microelectronics, semiconductors, optoelectronics, telecommunications, signal processing, image processing, and more
Connecting multiple devices enables the exchange and forwarding of data frames.
文献检索流程英语
文献检索流程英语Searching for literature is a crucial step in any research process, as it lays the foundation for understanding previous studies, identifying gaps in knowledge, and building upon existing research. The process of literature retrieval involves various steps and strategies to ensure that relevant and reliable sources are identified and accessed. In this article, we will explore the essential steps involved in literature retrieval, including defining research questions, selecting appropriate databases, conducting effective searches, evaluating sources, and managing references.The first step in the literature retrieval process is defining research questions or topics. This step is crucial as it helps researchers narrow downtheir focus and identify specific keywords or phrases to use in their search queries. Research questions should be clear, specific, and relevant to the topic under investigation. By defining research questions, researchers can better understand the scope of their study and identify key concepts and variables to search for in the literature.Once research questions are defined, the next step is selecting appropriate databases for literature search. There are numerous databases available to researchers, each specializing in specific disciplines or types of literature. Common databases include PubMed, Scopus, Web of Science, and Google Scholar. Researchers should select databases based on the relevance of their research topic and the type of literature they are seeking. It is essential to explore multiple databases to ensure comprehensive coverage of relevant sources.After selecting databases, researchers can begin conducting searches using keywords and Boolean operators to refine their search results. Keywords should be carefully selected based on the research questions and key concepts identified earlier. Boolean operators such as "AND," "OR," and "NOT" can be used to combine or exclude keywords to narrow down search results. Researchers should alsoconsider using truncation and wildcard symbols to capture variations of keywords and expand search results.Once search results are retrieved, researchers should evaluate the relevance and reliability of sources to determine their suitability for inclusion in the study. Evaluation criteria may include the author's credibility, publication date, research methodology, and relevance to the research questions. Researchers should critically assess sources to ensure that they are current, peer-reviewed, and contribute valuable insights to the study. It is essential to prioritize high-quality sources that align with the research objectives and methodology.In addition to evaluating sources, researchers should also manage references effectively to organize and cite sources in their research. Reference management tools such as EndNote, Mendeley, and Zotero can help researchers store, organize, and format citations in various citation styles. These tools enable researchers to create bibliographies, cite sources in manuscripts, and track references throughout the research process. By managing references efficiently, researchers can maintain accuracy and consistency in citing sources and avoid plagiarism.In conclusion, the literature retrieval process is a critical component of the research process that requires careful planning, organization, and evaluation of sources. By defining research questions, selecting appropriate databases, conducting effective searches, evaluating sources, and managing references, researchers can access relevant and reliable literature to support their study. By following these steps and strategies, researchers can enhance the quality and credibility of their research and contribute valuable insights to the academic community.。
dense passage retrieval实践
dense passage retrieval实践Dense passage retrieval (DPR) is a method used in information retrieval tasks, specifically in question-answering systems, to efficiently retrieve relevant passages of text from a large corpus. This approach aims to improve the accuracy and speed of retrieving information by using dense vector representations of passages and questions.To implement DPR in practice, several steps need to be taken:1. Data Preprocessing: The first step is to preprocess the data, which involves cleaning and tokenizing the text. This can include removing punctuation, converting to lowercase, and splitting the text into smaller units such as sentences or paragraphs.2. Passage Indexing: In order to retrieve passages efficiently, an index needs to be created. This can be done using techniques like FAISS (Facebook AI Similarity Search) or Annoy (Approximate Nearest Neighbors Oh Yeah). These libraries can efficiently index dense vectors and perform fast similarity searches. Each passage in the corpus is encoded into a dense vector representation using a pre-trained encoder model like BERT or RoBERTa.3. Query Preprocessing: Similar to the data preprocessing step, the query (question) needs to be cleaned and tokenized to prepare it for similarity matching against the passages. The query is also encoded into a dense vector using the same encoder model used for passage encoding.4. Passage Retrieval: Once the query is encoded, the next step is toretrieve the most relevant passages from the index. This is done by computing the cosine similarity between the query vector and all passage vectors in the index. The passages with the highest similarity scores are selected as the relevant passages.5. Post-processing and Ranking: The retrieved passages can be further refined or ranked based on additional criteria. This can include using language models to score the relevance or coherence of the passages, or applying natural language understanding techniques to match the query more accurately to the passages.6. Answer Extraction: Finally, the retrieved passages can be used for answer extraction. This can be done using various methods, such as using named entity recognition models to identify entities in the passages and matching them with the query, or using extractive summarization techniques to extract the most relevant information from the passages.Overall, implementing dense passage retrieval involves data preprocessing, passage indexing, query preprocessing, passage retrieval, post-processing and ranking, and answer extraction. By leveraging dense vector representations and efficient indexing techniques, DPR can significantly improve the accuracy and efficiency of retrieving relevant passages in question-answering systems.。
Evaluating a Decision-Theoretic Approach to Tailored Example Selection
Evaluating a Decision-Theoretic Approach to Tailored Example SelectionKasia Muldner 1 and Cristina Conati 1,21 University of British Columbia Department of Computer Science Vancouver, B.C., Canada {kmuldner, conati}@cs.ubc.ca2 University of Trento Department of Information and Communication TechnologyPovo, Trento, ItalyAbstractWe present the formal evaluation of a frameworkthat helps students learn from analogical problemsolving, i.e., from problem-solving activities thatinvolve worked-out examples. The framework in-corporates an innovative example-selectionmechanism, which tailors the choice of example toa given student so as to trigger studying behaviorsthat are known to foster learning. This involves atwo-phase process based on 1) a probabilistic usermodel and 2) a decision-theoretic mechanism thatselects the example with the highest overall utilityfor learning and problem-solving success. We de-scribe this example-selection process and presentempirical findings from its evaluation.1IntroductionAlthough examples play a key role in cognitive skill acqui-sition (e.g., [Atkinson et al., 2002]), research demonstrates that students have varying degrees of proficiency for using examples effectively (e.g., [Chi et al., 1989; VanLehn, 1998; VanLehn, 1999]). Thus, there has been substantial interest in the Intelligent Tutoring Systems (ITS) commu-nity in exploring how to devise adaptive support to help all students benefit from example-based activities (e.g., [Conati and VanLehn, 2000; Weber, 1996]). In this paper, we de-scribe the empirical evaluation of the Example Analogy (EA)-Coach, a computational framework that provides adaptive support for a specific type of example-based learn-ing known as analogical problem solving (APS) (i.e., using examples to aid problem solving).The EA-Coach’s general approach for supporting APS consists of providing students with adaptively-selected ex-amples that encourage studying behaviors (i.e. meta-cognitive skills) known to trigger learning, including:1)min-analogy: solving the problem on one’s own asmuch as possible instead of by copying from examples(e.g., [VanLehn, 1998]);2)Explanation-Based Learning of Correctness (EBLC): aform of self-explanation (the process of explaining and clarifying instructional material to oneself [Chi et al., 1989]) that can be used for learning new domain prin-ciples by relying on, for instance, commonsense oroverly-general knowledge, to explain how an example solution step is derived [VanLehn, 1999].Min-analogy and EBLC are beneficial for learning be-cause they allow students to (i) discover and fill their knowledge gaps and (ii) strengthen their knowledge through practise. Unfortunately, some students prefer more shallow processes which hinder learning, such as copying as much as possible from examples without any proactive reasoning on the underlying domain principles (e.g., [VanLehn, 1998; VanLehn, 1999].To find examples that best trigger the effective APS be-haviors for each student, the EA-Coach takes into account: i) student characteristics, including domain knowledge and pre-existing tendencies for min-analogy and EBCL, and ii) the similarity between a problem and candidate example. In particular, the Coach relies on the assumption that certain types of differences between a problem and example may actually be beneficial in helping students learn from APS, because they promote the necessary APS meta-cognitive skills. This is one of the novel aspects of our approach, and in this paper we present an empirical evaluation of the EA-Coach that validates it.A key challenge in our approach is how to balance learn-ing with problem-solving success. Examples that are not highly similar to the target problem may discourage shallow APS behaviors, such as pure copying. However, they may also hinder students from producing a problem solution, because they do not provide enough scaffolding for students who lack the necessary domain knowledge. Our solution to this challenge includes (i) incorporating relevant factors (student characteristics, problem/example similarity) into a probabilistic user model, which the framework uses to pre-dict how a student will solve the problem and learn in the presence of a candidate example; (ii) using a decision-theoretic process to select the example that has the highest overall utility in terms of both learning and problem-solving success. The findings from our evaluation show that this selection mechanism successfully finds examples that re-duce copying and trigger EBLC while still allowing for suc-cessful problem solving.There are a number of ITS that, like the EA-Coach, select examples for APS, but they do not consider the impact of problem/example differences on a student’s knowledge and/or meta-cognitive behaviors. ELM-PE [Weber, 1996]helps students with LISP programming by choosing exam-ples that are as similar as possible to the target problem. AMBRE [Nogry et al ., 2004] supports the solution of alge-bra problems by choosing structurally-appropriate exam-ples. However, it is not clear from the paper what “structur-ally appropriate” means. Like the EA-Coach, several ITS rely on a decision-theoretic approach for action selection, but these do not take into account a student’s meta-cognitive skills, nor they include the use of examples [Murray et al., 2004; Mayo and Mitrovic, 2001]. Finally, some systems perform analogical reasoning in non-pedagogical contexts (e.g., [Veloso and Carbonell, 1993]), and so do not incorpo-rate factors needed to support human learning.In the remainder of the paper, we first describe the exam-ple-selection process. We then present the results from an evaluation of the framework and discuss how they support the EA-Coach’s goal of balancing learning and problem- solving success.ExampleA person pulls a 9kg crate up a rampinclined 30o CCW from the horizontal. The pulling force is applied at an angle of 30 o CCW from the horizontal, with a magnitude of 100N. Find the magnitude of the normal force exerted on the crate.We answer this question using Newton’s Second Law.We choose the crate as the body. A normal force acts on the crate. It’s oriented 120o CCW from the horizontalA workman pulls a 50kg. block along the floor. He pulls it with amagnitude of 120N, applied at an angle of 25 o CCW from thehorizontal. What is the magnitude of the normal force on the block?Figure 2: Sample Classification of Problem/Example Relations2 The EA-Coach Example-Selection ProcessThe EA-Coach includes an interface that allows students to solve problems in the domain of Newtonian physics and ask for an example when needed (Fig. 1). For more details on the interface design see [Conati et al., in press]. As stated in the introduction, the EA-Coach example-selection mecha-nism aims to choose an example that meets two goals: 1) helps a student solve the problem (problem-solving success goal ) and 2) triggers learning by encouraging the effective APS behaviors of min-analogy and EBLC (learning goal ). For each example stored in the EA-Coach knowledge base, this involves a two-phase process, supported by the EA-Coach user model: simulation and utility calculation . The general principles underlying this process were described in [Conati et al., in press]. Here, we summarize the corre-sponding computational mechanisms and provide an illus-trative example because the selection process is the target of the evaluation described in a later section.2.1 Phase 1: The Simulation via the User ModelThe simulation phase corresponds to generating a prediction of how a student will solve a problem given a candidate example, and what she will learn from doing so. To generate this prediction, the framework relies on our classification of various relations between the problem and candidate exam-ple, and their impact on APS behaviors. Since an under-standing of this classification/impact is needed for subse-quent discussion, we begin by describing it.Two corresponding steps in a problem/example pair are defined to be structurally identical if they are generated by the same rule, and structurally different otherwise. For in-stance, Fig. 2 shows corresponding fragments of the solu-tions for the problem/example pair in Fig. 1, which include two structurally-identical pairs of steps: Pstep n /Estep n de-rived from the rule stating that a normal force exists (rule normal, Fig. 2), and Pstep n+1/Estep n+1 derived from the rule stating the normal force direction (rule normal-dir, Fig. 2). Two structurally-identical steps may be superficially dif-ferent. We further classify these differences as trivial or non-trivial. While a formal definition of these terms is given in [Conati et al., in press], for the present discussion, it suf-fices to say that what distinguishes them is the type of trans-fer from example to problem that they allow. Trivial super-ficial differences allow example steps to be copied, because these differences can be resolved by simply substituting the example-specific constants with ones needed for the prob-lem solution. This is possible because the constant corre-sponding to the difference appears in the example/problem solutions and specifications, which provides a guide for its substitution [Anderson, 1993] (as is the case for Pstep n /Estep n , Fig. 2). In contrast, non-trivial differences require more in-depth reasoning such as EBLC to be re-solved. This is because the example constant corresponding to the difference is missing from the problem/example specifications, making it less obvious what it should be re-placed with (as is the case for Pstep n+1/Estep n+1, Fig. 2). The classification of the various differences forms the ba-sis of several key assumptions embedded into the simula-tion’s operation. If two corresponding problem/example steps (Pstep and Estep respectively) are structurally differ-ent, the student cannot rely on the example to derive Pstep , i.e. the transfer of this step is blocked. This hinders problem solving if the student lacks the knowledge to generate Pstep [Novick, 1995]. In contrast, superficial differences betweenstructurally-identical steps do not block transfer of the ex-ample solution, because the two steps are generated by the same rule. Although cognitive science does not provide clear answers regarding how superficial differences impact APS behaviors, we propose that the type of superficial dif-ference has the following impact. Because trivial differences are easily resolved, they encourage copying for students with poor domain knowledge and APS meta-cognitive skills. In contrast, non-trivial differences encourage min-analogy and EBLC because they do not allow the problem solution to be generated by simple constant replacement from the example. We now illustrate how these assumptions are integrated into the EA-Coach simulation process.Simulation via the EA-Coach User ModelTo simulate how the examples in the EA-Coach knowledge base will impact students’ APS behaviors, the framework relies on its user model, which corresponds to a dynamic Bayesian network. This network is automatically created when a student opens a problem and includes as its back-bone nodes and links representing how the various problem solution steps (Rectangular nodes in Fig. 3) can be derived from domain rules (Round nodes in Fig. 3) and other steps. For instance, the simplified fragment of the user model in Fig. 3, slice t (pre-simulation slice) shows how the solution steps Pstep n and Pstep n+1 in Fig. 2 are derived from the cor-responding rules normal and normal-dir. In addition, the network contains nodes to model the student’s APS ten-dency for min-analogy and EBLC (MinAnalogyTend and EBLCTend in slice t, Fig. 3)1.To simulate the impact of a candidate example, a special ‘simulation’ slice is added to the model (slice t+1, Fig. 3, assuming that the candidate example is the one in Fig. 2). This slice contains all the nodes in the pre-simulation slice, as well as additional nodes that are included for each prob-lem-solving action being simulated and account for the can-didate example’s impact on APS. These include:-Similarity, encoding the similarity between a problem so-lution step and the corresponding example step (if any).1 Unless otherwise specified, all nodes have Boolean values -Copy, encoding the probability that the student will gener-ate the problem step by copying the corresponding exam-ple solution step.-EBLC, encoding the probability that the student will infer the corresponding rule from the example via EBLC. During the simulation phase, the only form of direct evi-dence for the user model corresponds to the similarity be-tween the problem and candidate example. This similarity is automatically assessed by the framework via the comparison of its internal representation of the problem and example solutions and their specifications. The similarity node’s value for each problem step is set based on the definitions presented above, to either: None (structural difference), Trivial or Non-trivial. Similarity nodes are instrumental in allowing the framework to generate a fine-grained predic-tion of copying and EBLC reasoning, which in turns im-pacts its prediction of learning and problem-solving success, as we now illustrate.Prediction of Copying episodes. For a given problem solu-tion step, the corresponding copy node encodes the model’s prediction of whether the student will generate this step by copying from the example. To generate this prediction, the model takes into account: 1) the student’s min-analogy ten-dency and 2) whether the similarity between the problem and example allows the step to be generated by copying. The impact of these factors is shown in Fig. 3. The probabil-ity that the student will generate Pstep n by copying is high (see ‘Copy n‘ node in slice t+1), because the prob-lem/example similarity allows for it (‘Similarity n’=Trivial, slice t+1) and the student has a tendency to copy (indicated in slice t by the low probability of the ‘MinAnalogyTend’ node). In contrast, the probability that the student will gen-erate the step Pstep n+1 by copying is very low (see node ‘Copy n+1’ in slice t+1) because the non-trivial difference (‘Similarity n+1’=Non-trivial, slice t+1) between the problem step and corresponding example step blocks copying. Prediction of EBLC episodes. For a given problem rule, the corresponding EBLC node encodes the model’s predic-tion that the student will infer the corresponding rule from the example via EBLC. To generate this prediction, the model takes into account 1) the student’s EBLC tendency, 2) her knowledge of the rule (in that students who already know a rule do not need to learn it) 3) the probability that she will copy the step, and 4) the problem/example similar-ity. The last factor is taken into account by including an EBLC node only if the example solution contains the corre-sponding rule (i.e., the example is structurally identical with respect to this rule). The impact of the first 3 factors is shown in Fig. 3. The model predicts that the student is not likely to reason via EBLC to derive Pstep n (see node ‘EBLC n,’ in slice t+1) because of the high probability that she will copy the step (see node ‘Copy n’) and the moderate probability of her having tendency for EBLC (see node EBLCTend in slice t). In contrast, a low probability of copy-ing (e.g., node ‘Copy n+1’, slice t+1) increases the probability for EBLC reasoning (see node ‘EBLC n+1’ in slice t+1), but the increase is mediated by the probability that the student has a tendency for EBLC, which in this case is moderate.Prediction of Learning & Problem-Solving Success. The model’s prediction of EBLC and copying behaviors influ-ences its prediction of learning and problem-solving suc-cess. Learning is predicted to occur if the probability of a rule being known is low in the pre-simulation slice and the simulation predicts that the student will reason via EBLC to learn the rule (e.g., rule normal-dir , Fig. 3). The probabili-ties corresponding to the Pstep nodes in the simulation slice represent the model’s prediction of whether the student will generate the corresponding problem solution steps. For a given step, this is predicted to occur if either 1) the student can generate the prerequisite steps and derive the given step from a domain rule (e.g. Pstep n+1, Fig. 3) or 2) generate the step by copying from the example (e.g., Pstep n , Fig. 3).Figure 4: Fragment of the EA Utility Model2.2 Phase 2: The Utility CalculationThe outcome of the simulation is used by the framework to assign a utility to a candidate example, quantifying its abil-ity to meet the learning and problem-solving success objec-tives. To calculate this utility, the framework relies on a decision-theoretic approach that uses the probabilities of rule and Pstep nodes in the user model as inputs to the multi-attribute linearly-additive utility model shown in Fig. 4. The expected utility (EU) of an example for learning an individual rule in the problem solution corresponds to the sum of the probability P of each outcome (value) for the corresponding rule node multiplied by the utility U of that outcome:))(())(())(())(()(i i i i i Rule known U Rule known P Rule known U Rule known P Rule EU ¬⋅¬+⋅=Since in our model, U (known (Rule i ))=1 and U (¬known (Rule i ))=0, the expected utility of a rule corresponds to the probability that the rule is known. The overall learning util-ity of an example is the weighted sum of the expected learn-ing utilities for all the rules in the user model:∑⋅nii i w Rule EU )(Given that we consider all the rules to have equal impor-tance, all weights w are assigned an equal value (i.e., 1/n , where n is the number of rules in the user model). A similar approach is used to obtain the problem-solving success util-ity, which in conjunction with the learning utility quantifies a candidate example’s overall utility.The simulation and utility calculation phases are repeated for each example in the EA-Coach’s knowledge base. The example with the highest overall utility is presented to the student.3 Evaluation of the EA-CoachAs we pointed out earlier, one of the challenges for the EA-Coach example-selection mechanism is to choose examples that are different enough to trigger learning by encouraging effective APS behaviors (learning goal ), but at the same time similar enough to help the student generate the problem solution (problem-solving success goal ). To verify how well the two-phase process described in the previous section meets these goals, we ran a study that compared it with the standard approach taken by ITS that support APS, i.e., se-lecting the most similar example. Here, we provide an over-view of the study methodology and present the key results.3.1 Study DesignThe study involved 16 university students. We used a within-subject design, where each participant 1) completed a pencil and paper physics pre-test, 2) was introduced to the EA-Coach interface (training phase), 3) solved two New-ton’s Second Law problems (e.g., of the type in Fig. 1) us-ing the EA-Coach, (experimental phase) and 4) completed a pencil and paper physics post-test. We chose a within-subject design because it increases the experiment’s power by accounting for the variability between subjects, arising from differences in, for instance, expertise, APS tendencies, verbosity (which impacts verbal expression of EBLC).Prior to the experimental phase, each subject’s pre-test data was used to initialize the priors for the rule nodes in the user model’s Bayesian network. Since we did not have in-formation regarding students’ min-analogy and EBLC ten-dencies, the priors for these nodes were set to 0.5. During the experimental phase, for each problem, subjects had ac-cess to one example. For one of the problems, the example was selected by the EA-Coach (adaptive-selection condi-tion ), while for the other (static-selection condition ), an ex-ample most similar to the target problem was provided. To account for carry-over effects, the orders of the prob-lems/selection conditions were counterbalanced. For both conditions, subjects were given 60 minutes to solve the problem, and the EA-Coach provided immediate feedback for correctness on their problem-solving entries, realized by coloring the entries red or green. All actions in the interface were logged. To capture subjects’ reasoning, we used the think-aloud method, by having subjects verbalize their thoughts [Chi et al ., 1989] and videotaped all sessions.3.2 Data AnalysisThe primary analysis used was univariate ANOVA, per-formed separately for the dependent variables of interest (discussed below). For the analysis, the within-subject selec-tion factor (adaptive vs. static ) was considered in combina-tion with the two between-subject factors resulting from the counterbalancing of selection and problem types. The re-sults from the ANOVA analysis are based on the data from the 14 subjects who used an example in both conditions (2 subjects used an example in only one condition: one subject used the example only in the static condition, another sub-ject used the example only in the adaptive condition).3.3Results: Learning GoalTo assess how well the EA-Coach adaptively-selected ex-amples satisfied the learning goal as compared to the stati-cally-selected ones, we followed the approach advocated in [Chi et al., 1989]. This approach involves analyzing stu-dents’ behaviors that are known to impact learning, i.e., copying and self-explanation via EBLC in our case. Al-though this approach makes the analysis challenging be-cause it requires that students’ reasoning is captured and analyzed, it has the advantage of providing in-depth insight into the EA-Coach selection mechanism’s impact. For this part of the analysis, univariate ANOVAs were performed separately for the dependent variables copy and EBLC rates. Copy Rate. To identify copy events, we looked for in-stances when students: 1) accessed a step in the example solution (as identified by the verbal protocols and/or via the analysis of mouse movements over the example) and 2) generated the corresponding step in their problem solution with no changes or minor changes (e.g., order of equation terms, constant substitutions). Students copied significantly less from the adaptively-selected examples, as compared to the statically-selected examples (F(1,14)=7.2, p=0.023; on average, 5.9 vs. 8.1 respectively).EBLC rate. To identify EBLC episodes, we analyzed the verbal protocol data. Since EBLC is a form of self-explanation, to get an indication of how selection impacted explanation rate in general, we relied on the definition in [Chi et al., 1989] to first identify instances of self-explanation. Students expressed significantly more self-explanations while generating the problem solution in the adaptive selection condition, as compared to in the static condition (F(1, 10)=6.4, p=0.03; on average, 4.07 vs. 2.57 respectively). We then identified those self-explanations that were based on EBLC (i.e., involved learning a rule via com-monsense and/or overly-general reasoning, as opposed to explaining a solution step using existing domain knowl-edge). Students generated significantly more EBLC expla-nations in the adaptive than the static condition (F(1, 10)=12.8, p=0.005; on average, 2.92 vs. 1.14 respectively). Pre/Post Test Differences. With the analysis presented above, we evaluated how the EA-Coach selection mecha-nism impacts learning by analyzing how effectively it trig-gers APS behaviors that foster it. Another way to measure learning is via pre/post test differences. In general, students improved significantly from pre to post test (on average, from 21.7 to 29.4; 2-tailed t(15)=6.13, p<0.001). However, because there was overlap between the two problems in terms of domain principles, the within-subject design makes it difficult to attribute learning to a particular selection con-dition. One way this could be accomplished is to 1) isolate rules that only appeared in one selection condition and that a given student did not know (as assessed from pre-test); 2) determine how many of these rules the student showed gains on from pre to post test. Unfortunately, this left us with very sparse data making formal statistical analysis infeasible. However, we found encouraging trends: there was a higher percentage of rules learned given each student’s learning opportunities in the adaptive condition, as compared to the static one (on average, 77% vs. 52% respectively). Discussion. As far as the learning goal is concerned, the evaluation showed that the EA-Coach’s adaptively-selected examples encouraged students to engage in the effective APS behaviors (min-analogy, EBLC) better than statically-selected examples: students copied less and self-explained more when given adaptively-selected examples. This sup-ports our assumption that certain superficial differences encourage effective APS behaviors. The statically-selected examples were highly similar to the target problem and thus made it possible to correctly copy much of their solutions, which students took advantage of. Conversely, by blocking the option to correctly copy most of their solution, the adap-tively-selected examples provided an incentive for students to infer via EBLC the principles needed to generate the problem solution.3.4Results: Problem-Solving Success GoalThe problem-solving success goal is fulfilled if students generate the problem solution. To evaluate if the adaptive example-selection process met this goal, we checked how successful students were in terms of generating a solution to each problem. In the static condition, all 16 students gener-ated a correct problem solution, while in the adaptive condi-tion, 14 students did so (the other 2 students generated a partial solution; both used the example in both conditions). This difference between conditions, however, is not statisti-cally significant (sign test, p=0.5), indicating that overall, both statically and adaptively selected examples helped stu-dents generate the problem solution.We also performed univariate ANOVAs on the dependent variables error rate and task time to analyze how the adap-tively-selected examples affected the problem solving proc-ess, in addition to the problem solving result. Students took significantly longer to generate the problem solution in the adaptive than in the static selection condition (F(1, 10) =31.6, p<0.001; on average, 42min., 23sec. vs. 25min., 35sec. respectively). Similarly, students made significantly more errors while generating the problem solution in the adaptive than in the static selection condition (F(1, 10)=11.5, p=0.007; on average, 22.35 vs. 7.57 respectively). Discussion. As stated above,the problem-solving success goal is satisfied if the student generates the problem solu-tion, and is not a function of performance (time, error rates) while doing so. The fact that students took longer/made more errors in the adaptive condition is not a negative find-ing from a pedagogical standpoint, because these are by-products of learning. Specifically, learning takes time and may require multiple attempts before the relevant pieces of knowledge are inferred/correctly applied, as we saw in our study and as is backed up by cognitive science findings (e.g., [Chi, 2000]).However, as we pointed out above, 2 students generated a correct but incomplete solution in the adaptive selection condition. To understand why this happened, we analyzed these students’ interaction with the system in detail. Both of them received an example with non-trivial superficial dif-。
信息的获取与处理英语作文
信息的获取与处理英语作文Information Retrieval and Processing。
In today's digital age, information retrieval and processing have become an essential part of our daily lives. With the advent of the internet, we have access to an endless amount of information at our fingertips. However, with so much information available, it can be overwhelmingto know where to start and how to process it effectively.The first step in information retrieval is to identify the source of the information. This can be done by conducting a search on the internet, visiting a library, or consulting with an expert in the field. Once the source of the information has been identified, the next step is to evaluate its credibility. It is important to ensure thatthe information is reliable, accurate, and unbiased.After evaluating the credibility of the information,the next step is to process it effectively. This involvesreading, analyzing, and synthesizing the information to gain a deeper understanding of the topic. It is important to take notes and organize the information in a way that is easy to understand and remember.One effective way to process information is to use the SQ3R method. This method involves five steps: survey, question, read, recite, and review. The first step is to survey the material by scanning the headings and subheadings to get an overall idea of the content. The next step is to formulate questions based on the material to help focus the reading. The third step is to read the material carefully, taking notes and highlighting important information. The fourth step is to recite the informationin your own words to help reinforce the learning. The final step is to review the material to ensure a thorough understanding.In addition to processing information effectively, itis also important to use it ethically. This involves giving credit to the original source of the information and avoiding plagiarism. It is important to cite sourcesproperly and to use quotation marks when quoting directly from a source.In conclusion, information retrieval and processing are essential skills in today's digital age. By identifying credible sources, processing information effectively, and using it ethically, we can gain a deeper understanding of the world around us and make informed decisions.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Research Memorandum CS-03-06:Evaluating Passage Retrieval Approaches for Question AnsweringIan Roberts and Robert GaizauskasDepartment of Computer Science,University of Sheffield,UK{i.roberts,r.gaizauskas}@AbstractAutomatic open domain question answering(QA) has been the focus of much recent research,stimu-lated by the introduction of a QA track in TREC in1999.Many QA systems have been developed and most follow the same broad pattern of oper-ation:first an information retrieval(IR)system, often passage-based,is used tofind passages from a large document collection which are likely to con-tain answers,and then these passages are analysed in detail to extract answers from them.Most re-search to date has focused on this second stage, with relatively little detailed investigation into as-pects of IR component performance which impact on overall QA system performance.In this paper, we(a)introduce two new metrics,coverage and answer redundancy,which we believe capture as-pects of IR performance specifically relevant to QA more appropriately than do the traditional recall and precision measures,and(b)demonstrate their use in evaluating a variety of passage retrieval ap-proaches using questions from TREC-9and TREC 2001.1IntroductionThe question answering(QA)evaluations in the Text REtrieval Conferences of1999–2002,have en-couraged wide interest in the QA problem.A re-view of the proceedings papers for TREC2001(in particular[10])shows that the majority of systems entered in this evaluation operate using a broadly similar architecture.First,an information retrieval (IR)system is used to retrieve those documents or passages from the full collection which are be-lieved to contain an answer to the question.In many cases,the question words are simply used as-is to form the retrieval system query,though a few systems make use of more advanced query pro-cessing techniques.Then,these retrieved passages are subjected to more detailed analysis,which may involve pattern matching or linguistic processing, in order to extract an answer to the question.The main differences between the competing systems lie in the details of this second stage.There are several reasons for this two-stage ar-chitecture.Foremost is the relative efficiency of IR systems in comparison with the more com-plex and unoptimized natural language processing (NLP)techniques used in answer extraction.Most answer extraction components of QA systems sim-ply could not be run in any reasonable time over document collections of the size of the TREC col-lection.This is due in part to more extensive pro-cessing,which may include part-of-speech tagging or semantic tagging or shallow parsing,but also be-cause few NLP researchers have spent time separat-ing“index-time”from“search-time”functionality and devising data structures to optimize the latter (though see[5,6]for exceptions).Another rea-son for separating retrieval and answer extraction is that IR researchers have spent decades designing systems to achieve the best possible performance, in terms of precision and recall,in returning rel-evant documents from large text collections.To most NLP researchers it has seemed self-evident that one should take advantage of this work.Given this two-stage architecture,most of the at-tention of the QA community has focused on the answer extraction component of QA systems.The first stage IR component is simply treated as a 1black-box and relatively little work has been done to investigate in detail the effect that the quality of the IR stage has on systems’performance.Clearly, however,the second stage process can only deter-mine an answer to a question if the passages re-trieved by thefirst stage contain the necessary in-formation.Furthermore,since,as Light et.al.[4] have shown,question answering systems tend to perform better for questions for which there are multiple answer occurrences in the document col-lection,an IR component that returns many occur-rences of the answer in its top ranked documents is likely to be of more use in a QA system than one which returns few.QA systems such as the one developed by Microsoft Research[1]exploit this ef-fect by searching for answers on the Web,where there is much greater answer redundancy than in the(relatively)small TREC collection.In this paper,we concentrate on analyzing the performance of several different approaches to the information retrieval stage of QA,using metrics which aim to capture aspects of performance rel-evant to question answering.More specifically,we concentrate on investigating several different ap-proaches to passage retrieval(PR).For a typical TREC question,such as Where is the Taj Ma-hal?,only a small section of a document will be required to determine the answer.Indeed,supply-ing a QA system with the full text of the docu-ment may in fact be counter-productive,as there will be many more opportunities for the system to become distracted from the correct answer by surrounding“noise”.Therefore using an IR stage which supplies the QA system with limited-length “best”passages is an approach which many QA researchers have adopted,and is the approach we investigate here.Given significant variation in doc-ument length across the TREC collection,passage retrieval approaches have the additional benefit of permitting processing-bound answer extraction components to examine passages further down the passage ranking than would be possible were full documents to be used.Deciding to adopt a passage retrieval approach, as opposed to a document retrieval approach,is still indeterminate in several regards.Different ap-proaches to passage retrieval assume different no-tions of passage.Well-known distinctions[2]are between semantic,discourse and window-based no-tions of passage,in which passage boundaries areseen as marked by topic shifts,discourse markers, such as paragraph indicators,orfixed byte spans, respectively.Furthermore,regardless of which no-tion of passage one adopts,a number of additional choices must be made in deciding how best to im-plement passage retrieval for QA.For instance,do we divide documents into passages prior to index-ing,and make the passage the unit of retrieval,or dynamically at search time after ranking the doc-ument collection overall?These two approaches might lead to significantly different rankings of the same passages,and this difference could have im-portant implications for QA.In the following paper we investigate a number of different approaches to passage retrieval for QA us-ing two new metrics which we believe are more help-ful in capturing aspects of IR system performance of relevance in the QA setting than the conventional metrics of recall and precision.This work is by no means exhaustive in terms of the PR approaches considered,and does not aim to be.Its central contribution is to introduce measures by which one can assess passage retrieval for question answering and to initiate debate about which approaches to PR may be best for QA.2Metrics for evaluating IR performance for QAIn the context of the QA task,the traditional IR performance measures of recall and precision demonstrate shortcomings that prompt us to de-fine two new measures.Let Q be the question set,D the document(or passage)collection,A D,q the subset of D which contains correct answers for q∈Q,and R S D,q,n be the n top-ranked documents(or passages)in D re-trieved by a retrieval system S given question q.The coverage of a retrieval system S for a ques-tion set Q and document collection D at rank n is defined as:coverage S(Q,D,n)≡|{q∈Q|R S D,q,n∩A D,q=∅}||Q|2The coverage gives the proportion of the question set for which a correct answer can be found within the top n passages retrieved for each question.The answer redundancy gives the average number,per question,of passages within the top n ranks re-trieved which contain a correct answer.In this framework,precision is defined as:precision S(Q,D,n)≡q∈Q|R S D,q,n∩A D,q||Q|and recall as:recall S(Q,D,n)≡q∈Q|R S D,q,n∩A D,q||Q|That is,the precision of a system for a given question set and document collection at rank n is the average proportion of the n returned documents or passages that contain a correct answer.Recall is the average proportion of answer bearing docu-ments that are present in the top n returned docu-ments or passages.In a QA context these global measures are not as helpful as coverage and re-dundancy.For example,suppose n=100and |Q|=100.An IR system S1returning passages containing100correct answers in the top100ranks for a single question in|Q|but0correct answers for all other questions receives the same precision score as a system S2returning exactly one correct answer bearing passage for each of the100questions in|Q|. However,S1when coupled to an answer extraction component of a QA system could answer at most one question correctly,while the S2-based system could potentially answer all100questions correctly. Precision cannot capture this distinction,which is crucial for QA;coverage,on the other hand,cap-tures exactly this distinction,in this case giving S1 a score of1and S2a score of100.Recall is not as unhelpful as precision,and in-deed one could argue that is more useful than re-dundancy as a measure,because it reveals to what extent the returned document set approaches the maximum redundancy obtainable,i.e.the extent to which all possible answering bearing passages are being returned.Redundancy,on the other hand,tells one only how many answering bearing passages per question are being returned on aver-age.However,redundancy gives a neat measure ofhow many chances per question on average an an-swer extraction component has tofind an answer,which is intuitively of interest in QA system devel-opment.More importantly,redundancy,being anabsolute measure,can be compared across ques-tion and documents sets to give a measure of howdifficult a specific QA task is.Furthermore,whatanswer redundancy misses,as compared to recall, can easily be captured by defining a notion of actualredundancy as q∈Q|A D,q|/|Q|.This is the maxi-mum answer redundancy any system could achieve. Comparing answer redundancy with actual redun-dancy captures the information that recall supplies, while giving overall information about the nature of the challenge presented by a specific question and document set which recall does not capture.To obtain values for any of these measures,wemustfirst decide what it means for an answer tobe correct.In TREC,an answer is correct if it is a valid response to the question and if the document from which the answer is drawn provides evidence for the answer.This reflects the fact that an aver-age user of a QA system does not trust the system absolutely,so an answer would only be accepted by the user if they could,in principle,verify it by reference to the original document.A candidate answer which is a valid response to the question, but which could not have been determined from the source document,is considered unsupported.Any other candidate answer is considered incorrect.The judgment of an answer’s correctness or otherwise is determined by a human assessor.While this kind of manual evaluation is feasiblefor a one-offevaluation such as TREC,a similarprocess is not reasonable for repeated experiments on the retrieval system.An assessor would have to examine every passage retrieved to determine whether it(a)contained an answer to the ques-tion and(b)supported that answer.With poten-tially hundreds of passages to examine per question and hundreds of questions in the test set,this adds up to several hundred thousand passages per run. Also,since human judgments are inherently subjec-tive,the same set of answers to the same questions, based on the same documents,will be scored dif-ferently by different assessors,so the results will not be repeatable.Clearly,an automatic method of assessment is needed.Voorhees and Tice[11]describe a possible so-lution to this problem.For the TREC collection, 3NIST have created regular expression patterns,in-tended to match strings which answer each ques-tion,and a set of relevance judgments,assembled from the combined results of all participating sys-tems,that indicate which documents provide sup-porting evidence for answers to each question.For our purposes,a passage is considered to contain a correct answer to a question if some substring of the passage matches one of the regular expressions for the question,and the document from which the passage was drawn is judged to be relevant.13Alternative Approaches to Passage RetrievalFor the TREC-9QA track our QA system[8], which adopts the two stage model for QA intro-duced in section1,employed Okapi[7]as the IR component.For the reasons outlined in section1 we wanted to use a passage-based approach and so relied upon Okapi’s native support for paragraph-based passage retrieval.While using the native passage retrieval support of an IR engine such as Okapi was convenient,we became aware that the technique used by the engine might not be the most suitable for the question answering application.For example,Okapi will never retrieve more than one passage from the same source document,though it is quite possible that several such passages may be relevant to the question.There are essentially two ways to address this issue:1.Pre-process the document collection,breakingdocuments into their component passages be-fore indexing.The retrieval system then treats each passage as a document in its own right.2.Retrieve full documents from the retrieval sys-tem,then break each document into its compo-nent passages and perform a second retrieval run tofind the best passages across the re-trieved document set.With this context in mind,and keeping open the possibility that full document-based ranking mayApproach4This approach is like approach3,ex-cept that the second retrieval stage is limitedto retrieve at most one passage from each orig-inal document.Thus,only one passage perdocument is returned,as in approach2,butthe ranking is determined by the passage scorerather than the full document score.This sim-ulates the Okapi approach,and is included pri-marily as a control,as non-Okapi-based toolswere used to implement approaches1–4(seenext section).Thus,to summarize,only approach1does index-time passaging,the other four approaches dosearch-time passaging.The differences betweenthem are to do with whether the original rank-ing resulting from the initial query should guidethe subsequent passage ranking(approach2)or not(approaches3and4and Okapi)and whether onepassage per document(Okapi,approaches2and4)or multiple passages per document(approaches1and3)should be returned.Clearly these variations do not exhaust the spaceof possible approaches to passage retrieval.How-ever,they provide an initial set to explore to see ifsignificant differences in results begin to emerge.4ImplementationTo run Okapi we simply downloaded the publiclyavailable version2and used it as is.To investigate the other approaches we usedLemur3as the underlying retrieval engine.Lemurhas native support for the TREC document for-mat,and supports vector-space,probabilistic andlanguage modelling retrieval approaches against asingle index.To keep experiments with Lemur ascomparable as possible to those with Okapi we re-port here only the results of using the probabilisticapproach(BM25term weighting)within Lemur,asthis is the model used in Okapi.We did inves-tigate the other approaches supported by Lemur,but these had little significant effect.To carry out passaging,a Perl program was writ-ten to read the source documents and split theminto passages one paragraph in length.The lineoffsets of the passages within the original source4These results were obtained on a dual processor Ultra-SPARC,running Solaris8,with2GB of main memory.551020305010020048.7860.0266.6369.7674.5178.7982.04Approach 145.8955.3963.7367.2172.3176.2579.72Approach 340.7952.2660.3765.4769.0674.3977.87Table 1:Results of passage retrieval experiments –coverage5102030501002000.8771.414 1.9192.226 2.6443.118 3.426Approach 10.7711.171 1.657 1.9332.312 2.7733.126Approach 30.7061.1271.6071.9062.3122.7523.017Table 2:Results of passage retrieval experiments –answer redundancyRank% c o v e r a g eOkapiApproach 1Approach 2Approach 3Approach 4Rank12345A n s w e r r e d u n d a n c yOkapiApproach 1Approach 2Approach 3Approach 4Figure 1:Results of passage retrieval experiments6for any of the other documents.In view of this,the experiments detailed below are based only on docu-ments from one source.We chose the AP newswire, as72%(863)of the1193test questions have at least one relevant document from this collection (i.e.a correct judgment with an AP document as the justification).The“next best”collection,in this sense,is the Los Angeles Times,for which only 53%of the questions have a relevant document.5 Each of thefive approaches was evaluated by us-ing each question in the question set as a query and returning the top200passages.For approaches which involved a two step process using Lemur(ap-proaches2,3and4),200documents were retrieved in step one,then passaging was carried out and200 passages were returned in step two in the manner of the specific approach.6To inform our analysis of the results,we also cal-culated the actual redundancy,as defined in section 2,as follows.For each question we used the hu-man assessors’judgments to pull out from the AP collection the documents identified as relevant to that question.For each of these documents we then split it into paragraphs,tested each of the NIST-supplied Perl patterns against each paragraph,and counted how many paragraphs matched at least one pattern.Actual redundancy for each ques-tion is then the total of these counts over all docu-ments identified as answer bearing.Overall actual redundancy is the average of these redundancies per question.Note that this is still an estimate(a lower bound)of true redundancy because the as-sessors only confirm those documents as containing answers if they have been proposed by some ing this approach we determined that the actual redundancy is14.3.This is the highest an-swer redundancy score a system could achieve un-der our scoring system,if it retrieved every pattern-matching paragraph from every relevant document in the AP collection.Tables1and2,and the correspondingfigure1, show the results of the experiments.We see that•for search-time passaging approaches,thefi-nal passage ranking should be guided by the ranking of full documents resulting from the initial query or by the ranking obtained in the secondary passage retrieval stage.To evaluate the utility of these approaches for question answering we have introduced two new metrics,coverage and answer redundancy which capture what proportion of the question set has at least one answer returned in the top n passages and the average number of repetitions of the answer in the top n passages,respectively.These metrics,we believe,are intuitive measures of the suitability of a passage retrieval approach for QA.Applying these metrics to assessfive approaches to passage retrieval in one specific experiment us-ing TREC QA data,we determined that the best-performing passage retrieval approach was one that first does full document retrieval,then splits the top retrieved documents into passages and performs a second passage retrieval operation against this pas-sage set,returning the passages in the rank order determined by the second retrieval operation.This approach obtains both better coverage and answer redundancy scores beyond about rank100.A number of further questions immediately sug-gest themselves.Our experiment was restricted to the top200ranks.While the scores for the ap-proaches appear to be diverging at this point,fur-ther experimentation at lower ranks should be car-ried out to confirm this.Of particular interest are the points at which coverage reaches100%and an-swer redundancy approaches actual redundancy. One would like to see higher coverage and re-dundancy at higher ranks.Can this be achieved using other passage retrieval approaches not ex-plored here?Or,are current performance levels un-surpassable,given an approach which uses the raw question words as the query to the retrieval sys-tem?Various approaches to query“enhancement”need to be considered.While higher coverage and answer redundancy would appear to be inherently good for QA sys-tems,there may a critical tradeoffbetween specific values for coverage and redundancy and the rank at which are these are obtained.For example,a QA system may do better with the top50passages than with the top100,even though the top100have higher coverage and redundancy,simply because ofthe“noise”introduced by a further50passages. The interaction between coverage and redundancy at certain ranks and the answer extraction capabil-ities of QA systems needs to be investigated. References[1] E.Brill,J.Lin,M.Banko,S.Dumais,and A.Ng.Data-intensive question answering.In[9],pp.393–400.[2]J.P.Callan.Passage-level evidence in documentretrieval.In Proc.of the17th ACM SIGIR con-ference,pp.302-310,1994.[3]W.B.Cavnar.N-gram based textfiltering forTREC-2.In NIST Special Publication500-215:The Second Text REtrieval Conference(TREC-2),pp.171–179,1993.[4]M.Light,G.S.Mann,E.Riloff,and E.Breck.Analyses for elucidating current question answer-ing technology.Natural Language Engineering,7(4):325–342,2001.[5] ward and J.Thomas.From informa-tion retrieval to information extraction.InProc.of the ACL Workshop on Recent Ad-vances in Natural Language Processing andInformation Retrieval,2000.Available at:/html/highlight.html.[6] D.Molla Aliod,J.Berri,and M.Hess.A realworld implementation of answer extraction.InProc.of the9th Int.Conference on Database andExpert Systems Applications Workshop“NaturalLanguage and Information Systems”(NLIS’98),pp.143–148,1998.[7]S. E.Robertson,S.Walker,S.Jones,M.M.Hancock-Beaulieu,and M.Gatford.Okapi atTREC-3.In NIST Special Publication500-225:The Third Text REtrieval Conference(TREC-3),pp.109–126,1994.[8]S.Scott and R.Gaizauskas.University of SheffieldTREC-9Q&A System.In Proc.of The NinthText REtrieval Conference(TREC9),pp.635–644.NIST Special Publication500-249,2000.[9] E.Voorhees and D.Harman,editors.NIST SpecialPublication500-250:The Tenth Text REtrievalConference(TREC2001),2001.[10] E.M.Voorhees.Overview of the TREC-2001question answering track.In[9].[11] E.M.Voorhees and D.M.Tice.Building a ques-tion answering test collection.In Proc.of the23rdACM SIGIR conference,pp.200–207,2000.8。