计量经济学实验一
计量经济学实验一 一元回归模型
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】【例1】建立我国税收预测模型。
表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
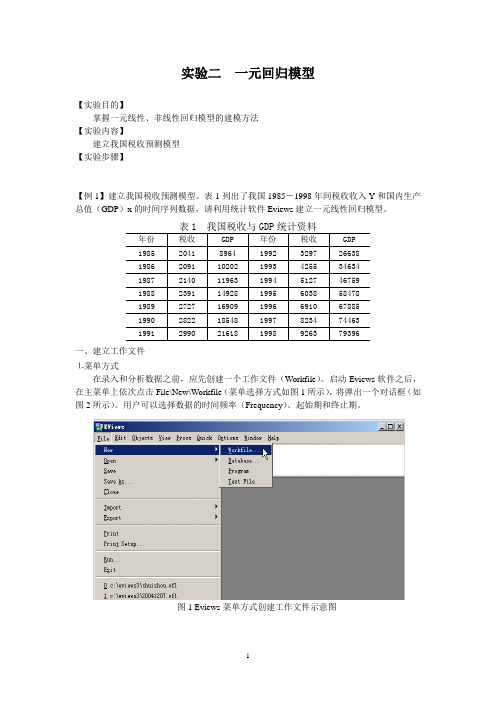
一、建立工作文件⒈菜单方式在录入和分析数据之前,应先创建一个工作文件(Workfile)。
启动Eviews软件之后,在主菜单上依次点击File\New\Workfile(菜单选择方式如图1所示),将弹出一个对话框(如图2所示)。
用户可以选择数据的时间频率(Frequency)、起始期和终止期。
图1 Eviews菜单方式创建工作文件示意图图2 工作文件定义对话框本例中选择时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期85和98。
然后点击OK,在Eviews软件的主显示窗口将显示相应的工作文件窗口(如图3所示)。
图3 Eviews工作文件窗口一个新建的工作文件窗口内只有2个对象(Object),分别为c(系数向量)和resid(残差)。
它们当前的取值分别是0和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据,也可以用相同的方法查看工作文件窗口中其它对象的数值。
⒉命令方式还可以用输入命令的方式建立工作文件。
在Eviews软件的命令窗口中直接键入CREATE命令,其格式为:CREATE 时间频率类型起始期终止期本例应为:CREATE A 85 98二、输入数据在Eviews软件的命令窗口中键入数据输入/编辑命令:DA TA Y X此时将显示一个数组窗口(如图4所示),即可以输入每个变量的数值图4 Eviews数组窗口三、图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,以便合理地确定模型的数学形式。
⒈趋势图分析命令格式:PLOT 变量1 变量2 ……变量K作用:⑴分析经济变量的发展变化趋势⑵观察是否存在异常值本例为:PLOT Y X⒉相关图分析命令格式:SCAT 变量1 变量2作用:⑴观察变量之间的相关程度⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线说明:⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析⑶通过改变图形的类型,可以将趋势图转变为相关图本例为:SCA T Y X图5 税收与GDP趋势图图5、图6分别是我国税收与GDP时间序列趋势图和相关图分析结果。
计量经济学实验报告

计量经济学实验报告实验报告实验课程名称:计量经济学实验案例1:近年来,中国旅游业⼀直保持⾼速发展,旅游业作为国民经济新的增长点,在整个社会经济发展中的作⽤⽇益显现。
中国的旅游业分为国内旅游和⼊境旅游两⼤市场,⼊境旅游外汇收⼊年均增长22.6%,与此同时国内旅游也迅速增长。
改⾰开放20多年来,特别是进⼊90年代后,中国的国内旅游收⼊年均增长14.4%,远⾼于同期GDP 9.76%的增长率。
为了规划中国未来旅游产业的发展,需要定量地分析影响中国旅游市场发展的主要因素。
解题过程:⾸先,通过Eviews,得出回归模型:Y=-274.377+0.013X2+5.438X3+3.272X4+12.986X5-563.108X6tc=-0.208 t2=1.031 t3=3.940 t4=3.465 t5=3.108 t6=-1.753R^2=0.995 F=173.354 DW=2.311从估计结果来看,模型可能存在多重共线性。
因为在OLS下,R^2^2与F值较⼤,⽽各参数估计量的t检验值较⼩,说明各解释变量对Y的联合线性作⽤显著,但各个解释变量存在共线性从⽽使得它们对Y的独⽴作⽤不能分辨,故t检验不显著。
应⽤Eviews,写下命令:cor X2 X3 X4 X5 X6。
得到相关系数矩阵。
可以从中看出五个经济变量之间两两简单相关系数⼤都在0.80以上,甚⾄有的在0.96以上。
表明模型存在着严重的多重共线性。
从⽽为了消除多重共线性,这⾥采⽤逐步回归法。
第⼀步,⽤每个解释变量分别对被解释变量做简单回归。
得:Y=-3462+0.0842X2 t=8.666 R^2=0.903 F=75Y=-2934+9.052X3 t=13 R^2=0.956 F=173Y=640+11.667X4 t=5.196 R^2=0.771 F=27Y=-2265+34.332X5 t=6.46 R^2=0.839 F=42Y=-10897+2014X6 t=8.749 R^2=0.905 F=77根据R^2统计量的⼤⼩排序,可见重要程度依次为X3, X6, X2, X5, X4。
计量经济学实验操作指导(完整版)--李子奈

计量经济学试验(完整版)——李子奈目录实验一一元线性回归 (5)一实验目的 (5)二实验要求 (5)三实验原理 (5)四预备知识 (5)五实验内容 (5)六实验步骤 (5)1.建立工作文件并录入数据 (5)2.数据的描述性统计和图形统计: (7)3.设定模型,用最小二乘法估计参数: (8)4.模型检验: (8)5.应用:回归预测: (9)实验二可化为线性的非线性回归模型估计、受约束回归检验及参数稳定性检验 (12)一实验目的: (12)二实验要求 (12)三实验原理 (12)四预备知识 (12)五实验内容 (12)六实验步骤 (13)实验三多元线性回归 (15)一实验目的 (15)三实验原理 (15)四预备知识 (15)五实验内容 (15)六实验步骤 (15)6.1 建立工作文件并录入全部数据 (15)6.2 建立二元线性回归模型 (16)6.3 结果的分析与检验 (16)6.4 参数的置信区间 (17)6.5 回归预测 (17)6.6 置信区间的预测 (19)实验四异方差性 (21)一实验目的 (21)二实验要求 (21)三实验原理 (21)四预备知识 (21)五实验内容 (21)六实验步骤 (21)6.1 建立对象: (21)6.2 用普通最小二乘法建立线性模型 (22)6.3 检验模型的异方差性 (22)6.4 异方差性的修正 (25)实验五自相关性 (29)一实验目地 (29)二实验要求 (29)三实验原理 (29)四预备知识 (29)五实验内容 (29)六实验步骤 (29)6.1 建立Workfile和对象 (30)6.2 参数估计、检验模型的自相关性 (30)6.3 使用广义最小二乘法估计模型 (34)6.4 采用差分形式作为新数据,估计模型并检验相关性 (36)实验六多元线性回归和多重共线性 (38)一实验目的 (38)二实验要求 (38)三实验原理 (38)四预备知识 (38)五实验内容 (38)六实验步骤 (38)6.1 建立工作文件并录入数据 (38)6.2 用OLS估计模型 (38)6.3 多重共线性模型的识别 (39)6.4 多重共线性模型的修正 (40)实验七分布滞后模型与自回归模型及格兰杰因果关系检验 (43)一实验目的 (43)二实验要求 (43)三实验原理 (43)四预备知识 (43)五实验内容 (43)六实验步骤 (43)6.1 建立工作文件并录入数据 (43)6.2 使用4期滞后2次多项式估计模型 (44)6.3 格兰杰因果关系检验 (46)实验八联立方程计量经济学模型 (50)一实验目的 (50)二实验要求 (50)三实验原理 (50)四预备知识 (50)五实验内容 (50)六实验步骤 (51)6.1 分析联立方程模型。
计量经济学实验报告(一)

计量经济学实验报告(一)
一、实验背景
计量经济学实验是一种采用经济理论和方法来设计实验的经济研究方法。
经济实验的主要目的是检验经济理论,比如检验假设和改进预测。
它还可以用于定性评价和定量评价政策方案和市场动态,以及验证行为经济学理论。
二、实验内容
本次实验通过一组独立的在线调查来研究人们对收入分配政策的态度。
调查中,受访者被要求就14种不同的收入分配政策支持、反对和中立做出反应。
这14种收入分配政策包括财政公平政策、税收和补贴政策、劳动力市场政策和参与机会政策等。
以及根据态度的强度来改变互动形式,不同类型的回答有不同的加分,比如更强烈的支持会比中立的有更多分数。
三、实验结果
实验结果显示,在14种收入分配政策中,受访者大部分表示支持或者反对。
最受支持的是劳动力市场政策,而最受反对的是税收和补贴政策。
同时,实验还发现,这14种收入分配政策受实验者支持或反对的原因大部分是经济实惠:如果一个政策能够为普通大众带来经济实惠,这个政策很可能受到受访者的支持。
此外,一些政策因其有助于实现平等收入而受到支持。
四、实验结论
本次实验结论清楚地表明,受访者支持或反对收入分配政策跟经济实惠有关。
当人们普遍受益于收入分配政策时,他们很可能支持这种政策。
另外,实验还发现,有些政策受支持的原因还在于它们有助于实现平等收入的目的。
本次实验不仅对计量经济学的理论和方法提供了有价值的信息,而且还为构建经济实证提供了重要的参考意见。
可以认为,经过本次实验的进一步检验和优化,可以发现更详细、更准确的数据,以便进一步检验和发展计量经济学的理论与方法。
计量经济学实验报告完成

实验一:Eviews入门一、实验目的:熟悉Eviews基本操作二、实验内容1.对数据序列做散点图,时间序列图2.对组对象的建立和作图3.利用已有序列生成新序列4.对数据序列做描述统计分析三、实验过程记录1.数据散点图2.对组对象的建立和作图obs Y X1981 585.0000 636.82001982 576.0000 659.25001983 615.0000 685.92001984 726.0000 834.15001985 992.0000 1075.2601986 1170.000 1293.2401987 1282.000 1437.090 1988 1648.000 1723.440 1989 1812.000 1975.640 1990 1936.000 2181.650 1991 2167.000 2485.460 1992 2509.000 3008.970 1993 3530.000 4277.380 1994 4669.000 5868.480 1995 5868.000 7171.910 1996 6763.000 8158.740 1997 6820.000 8438.890 1998 6866.000 8773.1003.利用已有序列生成新序列Modified: 1981 1998 // y2=y^21981 342225 1990 37480961982 331776 1991 46958891983 378225 1992 62950811984 527076 1993 124609001985 984064 1994 217995611986 136**** **** 344334241987 1643524 1996 457381691988 2715904 1997 465124001989 3283344 1998 47141956 4. 对数据序列做描述分析XMean 3371.411Median 2078.645Maximum 8773.100Minimum 636.8200Std. Dev. 2951.449Skewness 0.834886Kurtosis 2.102850Jarque-Bera 2.694765Probability 0.259920Sum 60685.39Sum Sq. Dev. 1.48E+08Observations 18四、实验体会 Ⅰ、感悟1. 实验过程开始比较难但是随着实验一步一步的进行和练度的上升感觉越来越简单,速度也越来越快 2. 经过实验一的基本操作使得后续实验更加容易 3. 最开始一定要掌握基础操作否则实验无法继续Ⅱ、建议1. 基础操作讲解应该更详细,而且正式,不要太快,否则很多同学都学不会后续实验无法继续进行 2. 实验指导可不可以加入视频教程实验二:线性回归模型的参数估计、假设检验及点预测一、 实验目的:全过程体验Economictrics 中线性回归模型的估计方法 二、 实验内容(a )1. 研究的问题:居民可支配收入X 与年均消费性支出Y 之间的关系2. 数学模型设定i X Y μββ++=103. 散点观察Y Mean 2807.444 Median 1874.000 Maximum 6866.000 Minimum576.0000 Std. Dev. 2333.000 Skewness 0.809287 Kurtosis2.088648Jarque-Bera 2.587760 Probability0.274205Sum50534.00 Sum Sq. Dev.92529116Observations18分析:存在比较明显的线性关系 4. 参数估计及分析Variable Coefficient Std. Error t-Statistic Prob.C 135.3063 24.74086 5.468940 0.0000 X0.6917540.02467128.03936 0.0000R-squared0.978835 F-statistic 786.2057 Adjusted R-squared 0.977590 Prob(F-statistic)0.000000分析:由表可知,0β=135.3063 1β=0.691754。
计量经济学实验一

《计量经济学》综合实验一系金融系专业经融工程姓名程若宸学号20141206031035实验地点:B楼305实验日期:216.9.30实验题目:研究中国汽车市场未来发展趋势实验类型:基本操作训练。
实验目的:掌握简单线性回归模型的Eviews操作实验内容:第三章的“引子”中分析了,经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”等变量,2011年全国各省市区的有关数据见附件:1)建立百户拥有家用汽车量计量经济模型?2)估计参数并写出回归分析结果报告?3)对模型进行经济意义上的检验,统计意义上的检验?评分标准:操作步骤正确,回归结果正确,结果分析准确到位,符合实际。
实验步骤:Dependent Variable: YMethod: Least SquaresDate: 09/30/16 Time: 11:27Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.C 246.8540 51.97500 4.749476 0.0001X2 5.996865 1.406058 4.265020 0.0002X3 -0.524027 0.179280 -2.922950 0.0069X4 -2.265680 0.518837 -4.366842 0.0002R-squared 0.666062 Mean dependent var 16.77355Adjusted R-squared 0.628957 S.D. dependent var 8.252535S.E. of regression 5.026889 Akaike info criterion 6.187394Sum squared resid 682.2795 Schwarz criterion 6.372424Log likelihood -91.90460 Hannan-Quinn criter. 6.247709F-statistic 17.95108 Durbin-Watson stat 1.206953Prob(F-statistic) 0.000001Y i=246.85+6.00x2−0.52x3−2.27x3(51.98) (1.41) (0.18) (0.52)t= (4.75) (4.27) (-2.92) (-4.37)R2=0.666R2=0.629F=17.951 n=31模型检验1.经济意义检验模型估计结果的数据说明理论分析与经验判断相一致2.统计检验(1)拟合优度:R2=0.666修正的可决系数为R2=0.629说明模型对样本拟和(2)F检验:实验感悟:成绩:评阅人:附件:表3.6 2011年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2012.中国统计出版社。
计量经济学综合实验报告
1、用Eviews创建变量LE、NI,输入样本数据,、打开Eviews工作文件,建立新的文件夹,在命令框中输入“data le ni”回车 ,从数据表中粘贴数据到Eviews数据表中即可;
2、估计河南省农村居民消费支出LE依可支配收入NI的一元回归模型
下图就是河南省农村居民消费支出LE和可支配收入NI的一元线性回归结果:
6、对ce为被解释变量,di为解释变量模型输出结果进行经济理论检验,拟合优度检验和t检验;
1经济意义检验:所估计参数β1=,β2=,说明可支配收入增加1元,平均说来可导致城市居民消费支出增加元;
2拟合优度检验:通过以上的回归数据可知,可决系数为,说明所建模型整体上对样本数据拟合度不是太好;
3t检验:针对H1:β1=0和H2:β2=0,由上回归结果可以看出,估计的回归系数B1的标准误差和t值分别为:SEβ1=,tβ1=: β2的标准误差和t值分别为SEβ2= tβ2=. 取a=0,05,查t分布表得自由度为n-2=18-2=16的临界值为= 19,tβ1=<= 19,不拒绝H1, tβ2=>= 19,拒绝H2.这表明,城市居民可支配收入对其消费水平有很大影响;
但两者的之一比例均大于,可见用凯恩斯的绝对收入假说解释现阶段河南省居民消费规律是合理的;
实验二 截面数据一元线性回归模型
异方差性
实验目的和要求
1、掌握一元线性回归估计方程的异方差性检验方法;
2、掌握一元线性回归估计方程的异方差性纠正方法;
3、在老师的指导下独立完成实验,并得到正确结果;
实验内容
1、估计河南省城市居民消费支出CE依可支配收入DI的一元线性回归模型和农村居民生活消费支出LE与纯收入NI的一元线性回归模型;
城市居民:
计量经济学实验
实验一 Eviews的认识与一元线性回归模型——我国城市居民家庭消费函数一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
计量经济学实验报告1(共6篇)
篇一:计量经济学实验报告 (1)计量经济学实验基于eviews的中国能源消费影响因素分析学院:班级:学号:姓名:基于e views的中国能源消费影响因素分析一、背景资料能源消费是指生产和生活所消耗的能源。
能源消费按人平均的占有量是衡量一个国家经济发展和人民生活水平的重要标志。
能源是支持经济增长的重要物质基础和生产要素。
能源消费量的不断增长,是现代化建设的重要条件。
我国能源工业的迅速发展和改革开放政策的实施,促使能源产品特别是石油作为一种国际性的特殊商品进入世界能源市场。
随着国民经济的发展和人口的增长,我国能源的供需矛盾日益紧张。
同时,煤炭、石油等常规能源的大量使用和核能的发展,又会造成环境的污染和生态平衡的破坏。
可以看出,它不仅是一个重大的技术、经济问题,而且以成为一个严重的政治问题。
在20世纪的最后二十年里,中国国内生产总值(gdp)翻了两番,但是能源消费仅翻了一番,平均的能源消费弹性仅为0.5左右。
然而自2002年进入新一轮的高速增长周期后,中国能源强度却不断上升,经济发展开始频频受到能源瓶颈问题的困扰。
鉴于此,研究能源问题不仅具有必要性和紧迫性,更具有很大的现实意义。
由于我国目前面临的所谓“能源危机”,主要是由于需求过大引起的,而我国作为世界上最大的发展中国家,人口众多,所需能源不可能完全依赖进口,所以,研究能源的需求显得更加重要。
二、影响因素设定根据西方经济学消费需求理论可知,影响消费需求的因素有:商品的价格、消费者收入水平、相关商品的价格、商品供给、消费者偏好以及消费者对商品价格的预期等。
对于相关商品价格的替代效应,我们认为其只存在能源品种内部之间,而消费者偏好及消费者对商品价格的预期数据差别较大,不容易进行搜集整理在此暂不涉及。
另外,发展经济学认为,来自知识、人力资本的积累水平所体现的技术进步不仅可以带动劳动产出的增长,而且会通过外部效应可以提高劳动力、自然资源、物质资本与生产要素的生产效率,消除其中收益递减的内在联系,带来递增的规模收益。
《计量经济学》上机实验参考答案
《计量经济学》上机实验参考答案实验一:线性回归模型的估计、检验和预测(3 课时)实验设备:个人计算机,计量经济学软件Eviews,外围设备如U 盘。
实验目的:(1)熟悉Eviews 软件基本使用功能;(2)掌握一元线性回归模型的估计、检验和预测方法;正态性检验;(3)掌握多元线性回归模型的估计、检验和预测方法;(4)掌握多元非线性回归模型的估计方法;(5)掌握模型参数的线性约束检验与参数的稳定性检验。
实验方法与原理:Eviews 软件使用,普通最小二乘法(OLS),拟合优度评价、t 检验、F 检验、J-B 检验、预测原理。
实验要求:(1)熟悉和掌握描述统计和线性回归分析;(2)选择方程进行一元线性回归;(3)选择方程进行多元线性回归;(4)进行经济意义检验、拟合优度评价、参数显著性检验和回归方程显著性检验;(5)掌握被解释变量的点预测和区间预测;(6)估计对数模型、半对数模型、倒数模型、多项式模型模型等非线性回归模型。
实验内容与数据1(第2 章思考与练习:三、简答、分析与计算题第12 小题):12. 表1 数据是从某个行业的5 个不同的工厂收集的,请回答以下问题:ˆˆˆˆ(1)估计这个行业的线性总成本函数:yˆt= b0 + b1 x t ;(2)b0 和b1 的经济含义是什么?;(3)估计产量为10 时的总成本。
表1 某行业成本与产量数据参考答案:(1)总成本函数(标准格式):yˆt = 26.27679 + 4.25899xts = (3.211966) (0.367954)t = (8.180904) (11.57462)R 2 = 0.978098 S.E = 2.462819 DW =1.404274 F =133.9719ˆˆ(2) b0 =26.27679 为固定成本,即产量为0 时的成本;b1 =4.25899 为边际成本,即产量每增加1 单位时,总成本增加了4.25899 单位。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2017—2018第二学期
计量经济学实验报告
实验(一):一元回归模型实验
学号:姓名:
专业:经济学类选课班级: A01 实验日期:2018/05/07 实验地点: 0502
1、家庭消费支出(Y )、可支配收入(2X )、个人个财富(2X )设定模型如下:
i i i i X X Y μβββ+++=22110 回归分析结果为:
LS // Dependent Variable is Y Date: 18/4/02 Time: 15:18 Sample: 1 10
Included observations: 10
Variable Coefficient Std. Error T-Statistic Prob. C 24.4070
6.9973 ___3.4881_____ 0.0101
2X - 0.3401 0.4785 ___-_0.7108____ 0.5002 2X 0.0823 0.0458 1.7969 0.1152 R-squared ___0.9615_____ Mean dependent var
111.1256
Adjusted R-squared
0.9504
S.D. dependent var 31.4289
S.E. of regression ___6.5436____ Akaike info criterion
4.1338
Sum squared resid 342.5486 Schwartz criterion 4.2246 Log likelihood
- 31.8585 F-statistic 87.3339
Durbin-Watson stat
2.4382
Prob(F-statistic)
0.0001
补齐表中划线部分的数据(保留四位小数);并写出回归分析报告。
2、根据有关资料完成下列问题: LS // Dependent Variable is Y Date: 11/12/02 Time: 10:18 Sample: 1978 1997 Included observations: 20
Variable Coefficient Std. Error T-Statistic Prob. C 858.3108
67.12015 _____12.7877___
0.0000
X 0.100031 _____0.0022___ 46.04788 0.0000
R-squared __0.9916__ Mean dependent var 3081.157
Adjusted R-squared
0.991115 S.D. dependent var 2212.591
S.E. of regression __202.9982_ Akaike info criterion
10.77510
Sum squared resid 782956.8 Schwartz criterion 10.87467 Log likelihood
- 134.1298
F-statistic ___21230.46934_____
Durbin-Watson stat 0.859457 Prob(F-statistic) 0.000000
(其中:X —国民生产总值;Y —财政收入)
(1) 补齐表中的数据(保留四位小数),并写出回归分析报告;
(2)解释模型中回归系数估计值的经济含义;
答:C=858.3108表示当国民生产总值等于0时,财政收入等于858.3108。
X= 0.100031
表示国民生产总值对财政收入的边际效应为0.100031,即国民生产总值增加1元时,财政收入的增加0.100031元。
(3)检验模型的显著性。
101.2)18(025.0 t
3、 假定有如下回归结果,
t t X Y 4795.09611.2ˆ-
= 其中Y = 我国的茶消费量(每天每人消费的杯数) X = 茶的零售价格(元/公斤) t 表示时间
(1) 这是一个时间数列回归还是横截面序列回归?
答:这是一个时间数列回归.
(2) 画出回归线。
(3)如何解释截距项的意义,它有经济含义吗?
答:当茶的零售价格为0时,我国茶消费量为每天每人2.9611杯。
没有,
因为在现实生活中茶的零售价格不可能为0. (4)如何解释斜率?
答:茶叶的价格每增加1元/公斤则我国茶消费量为每天每人0.4795杯。
(5)你能求出真实的总体回归函数吗?
答:不能,因为总体的真实值是要对每一个人进行调查,而现实生活中由于各种因素比如:财力的影响,我们只能进行抽样调查。
从而得到的是样本回归数据。
无法得到真实的总体回归函数。
4、利用下表给出的我国人均消费支出与人均可支配收入数据回答下列问题: (1) 这是一个时间数列回归还是横截面序列回归? 答:这是一个横截面序列回归。
(2) 建立回归方程;
(3) 如何解释斜率?
答:人均可支配收入对人均消费性支出的边际效应为0.794257,即当人均可支配收入增加1元,人均消费性支出增加0.794257元。
(4) 对参数进行显著性检验。
(5) 如果某人可支配收入是1000元,求出该人的消费支出的点预测值。
(6) 求出该人消费支出95℅置信水平的区间预测
1998年我国城镇居民人均可支配收入与人均消费性支出 单位:元
5、为了解释牙买加对进口的需求,J.Gafar 根据19年的数据得到下面的回归结果:
t t t X X Y 2110.020.09.58ˆ
-+-=
se = (0.0092) (0.084) R 2=0.96 2R =0.96
其中:Y=进口量(百万美元),X1=个人消费支出(美元/年),X2=进口价格/国内价格。
(1)解释截距项,及X1和X2系数的意义;
(2)Y的总离差中被回归方程解释的部分,未被回归方程解释的部分;(3)对回归方程进行显著性检验,并解释检验结果;
(4)对参数进行显著性检验,并解释检验结果。