stata空间计量计算空间矩阵乘自变量
【最新】空间计量代码
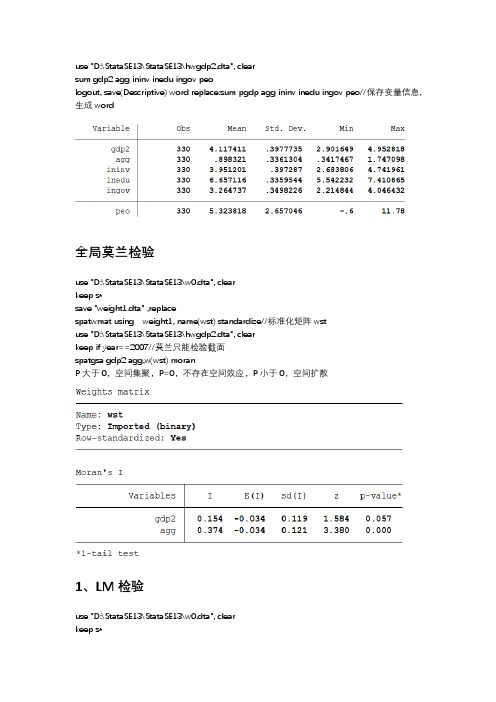
use "D:\StataSE13\StataSE13\hwgdp2.dta", clearsum gdp2 agg ininv inedu ingov peologout, save(Descriptive) word replace:sum pgdp agg ininv inedu ingov peo//保存变量信息,生成word全局莫兰检验use "D:\StataSE13\StataSE13\w0.dta", clearkeep s*save "weight1.dta" ,replacespatwmat using weight1, name(wst) standardize//标准化矩阵wstuse "D:\StataSE13\StataSE13\hwgdp2.dta", clearkeep if year==2007//莫兰只能检验截面spatgsa gdp2 agg,w(wst) moranP大于0,空间集聚,P=0,不存在空间效应,P小于0,空间扩散1、LM检验use "D:\StataSE13\StataSE13\w0.dta", clearkeep s*save "weight1.dta" ,replacespatwmat using weight1, name(wst) standardizeuse "D:\StataSE13\StataSE13\hwgdp2.dta", clearxtset id yearspwmatrix import using weight1.dta,wname(w6) dta xtw(11)qui reg gdp2 agg ininv inedu ingov peo//一般面板回归,但是不显示spatdiag,weights(w6)P=0,接受空间误差P≠0,拒绝空间滞后2、LR检验本文只检验SEM和SDMqui xsmle gdp2 agg ininv inedu ingov peo, wmat(wst) model(sdm) fe type(ind) nsim(500) nolog effectsestest store sdmqui xsmle gdp2 agg ininv inedu ingov peo , emat(wst) model(sem) fe type(ind) nsim(500) nolog effectsestest store semlrtest sdm semP=0,选择杜宾3、Hausman检验qui xsmle gdp2 agg ininv inedu ingov peo, wmat(wst) model(sdm) fe type(ind) nsim(500) nolog effectsest.est sto fequi xsmle gdp2 agg ininv inedu ingov peo, wmat(wst) model(sdm) re type(ind) nsim(500) nolog effectsestest sto re负数,则个体固定效应,故用fe。
空间溢出效应stata代码

空间溢出效应stata代码
空间溢出效应是指统计模型中的一个常见问题,通常发生在空
间数据分析中。
在Stata中,你可以使用空间计量模型来检测和处
理空间溢出效应。
以下是一个简单的示例Stata代码来运行空间自
回归模型(Spatial Autoregressive Model)来处理空间溢出效应: stata.
导入数据。
use "你的数据文件路径/文件名.dta", clear.
安装空间统计分析工具包。
ssc install spreg.
运行空间自回归模型。
spreg dependent_variable independent_variables,
model(lag)。
在这个代码中,你需要将"你的数据文件路径/文件名.dta"替换
为你实际的数据文件路径和文件名,以及将dependent_variable和independent_variables替换为你实际的因变量和自变量。
运行这
段代码将会使用空间自回归模型来检测和处理空间溢出效应。
除了空间自回归模型,你还可以尝试使用其他的空间计量模型,比如空间误差模型(Spatial Error Model)和空间滞后模型(Spatial Lag Model)来处理空间溢出效应。
你也可以考虑使用空
间权重矩阵来探索空间溢出效应的模式和影响。
总之,处理空间溢出效应需要综合考虑空间统计模型和空间权
重矩阵等工具,以便全面地理解和处理空间数据分析中的空间溢出
效应问题。
将空间权重矩阵扩大的stata代码

标题:将空间权重矩阵扩大的stata代码一、介绍空间权重矩阵是空间统计分析的重要工具,用来衡量地理空间单位之间的空间连接关系。
在进行空间计量分析时,常常需要对空间权重矩阵进行扩大,以满足实际研究需求。
本文将介绍如何使用stata代码来扩大空间权重矩阵。
二、准备工作在使用stata代码进行空间权重矩阵扩大之前,首先需要准备好相关的数据和软件环境。
确保已经安装好stata软件,并且具有要分析的空间权重矩阵数据。
三、导入数据在stata中,需要使用"import delimited"命令来导入空间权重矩阵数据。
假设要导入的数据文件名为"spatial_weights.csv",则可以使用以下命令导入数据:```import delimited "spatial_weights.csv", clear```四、扩大空间权重矩阵使用stata代码来扩大空间权重矩阵的方法比较简单,只需要使用"gen"命令来生成新的空间权重矩阵即可。
假设要将原始的空间权重矩阵扩大10倍,可以使用以下命令:```gen new_weight = old_weight * 10```这里的"old_weight"是原始的空间权重矩阵数据,"new_weight"是经过扩大后的新空间权重矩阵数据。
根据实际需求,可以将10修改为其他倍数。
五、保存数据扩大空间权重矩阵后,需要将结果保存到新的数据文件中。
可以使用"export delimited"命令来保存数据,例如:```export delimited "new_spatial_weights.csv", replace```这样就将扩大后的空间权重矩阵数据保存到了新的文件"new_spatial_weights.csv"中。
面板空间计量之Stata应用

面板空间计量之Stata应用:学习笔记【同舟共济】更新于2016年4月20日说明目前,在空间计量方面,Stata官方命令语句数量有限且较为零散,尚未形成系统的空间计量工具包。
因此,个人建议空间计量的初学者转向Matlab软件,James P. LeSage、J. P. Elhorst、Donald J. Lacombe等学者所开发的空间计量工具包,其功能相对更加完善,操作起来也比较方便。
本人已经习惯了使用stata,初次自学空间计量方面的操作,参考help文件及相关文献,在学习过程中做了简要总结,仅供初学者交流学习。
其中若有不当之处,敬请批评指正,谢谢!E-mail: ares0825@【Stata】Abd Elmessih Shehata (Econpapers)URL: /RAS/psh494.htmFederico Belotti (Econpapers)URL: /RAS/pbe427.htmP. Wilner Jeanty (Econpapers)URL:/RAS/pje95.htmMaurizio PisatiURL:/people/maurizio-pisatiYihua Yu (Econpapers)URL:/RAS/pyu79.htm目录第一章Stata空间计量命令语句安装 1 第二章中国31省市自治区(不含港澳台、附属岛屿)shp制作 3 第三章Stata空间权重制作8 第四章Stata 空间相关性检验27 第五章Stata 空间面板数据回归39面板空间计量之Stata应用:学习笔记第一章Stata空间计量命令包安装更新于2016-03-151.空间计量-Stata命令包Archive of user-written Stata packagesURL: /statistics/stata-blog/stata-programming/ssc_stata_package_list.php图1 Stata用户自拟命令语句列表另外,在IDEAS(URL: https:///)中可以查询相关命令,顺便推荐几个论坛,大家可以经常逛逛:Stata官方论坛URL: /UCLA-Idre论坛URL: /stat/stata/Stata Daily URL: /index/2.安装单击图1左侧红色框内命令名称,即可下载对应的压缩包,安装过程参考非官方命令手动安装说明(URL:/thread-2420580-1-1.html);单击图1右侧蓝色框内的各命令所对应的描述性语句,即可看到该命令的详细说明及应用举例。
stata空间权重矩阵进行标准化

stata空间权重矩阵进行标准化摘要:I.引言- 介绍Stata软件- 介绍空间权重矩阵II.Stata中空间权重矩阵的标准化- 标准化定义- 为什么要进行标准化- 如何进行标准化III.实例分析- 假设数据- 标准化过程- 结果分析IV.结论- 总结标准化的重要性- 建议进一步学习正文:I.引言Stata是一款广泛应用于计量经济学、社会科学、生物统计学等领域的软件,其具有强大的数据处理和分析功能。
在空间数据分析中,空间权重矩阵是一个重要的工具,它可以描述不同区域之间的空间关系。
然而,在使用空间权重矩阵时,我们需要考虑到其缩放问题,即不同的空间权重矩阵可能会导致不同的分析结果。
因此,对空间权重矩阵进行标准化是非常必要的。
II.Stata中空间权重矩阵的标准化标准化是指将一个变量或矩阵的值映射到一定范围内的过程。
在Stata 中,对空间权重矩阵进行标准化可以消除缩放问题,从而保证分析结果的准确性。
首先,我们需要明确为什么要进行标准化。
在Stata中,空间权重矩阵的缩放问题可能会导致以下问题:- 矩阵元素值的范围不同,导致矩阵的缩放不同;- 矩阵的缩放不同,导致空间关系的描述不准确;- 空间关系的描述不准确,导致分析结果的误差。
因此,为了保证分析结果的准确性,我们需要对空间权重矩阵进行标准化。
那么,如何进行标准化呢?在Stata中,我们可以使用spwmatrix命令来生成空间权重矩阵,并通过命令选项来对矩阵进行标准化。
具体来说,我们可以使用以下命令:```spwmatrix standard, standard_method( queen )```其中,`standard_method`表示标准化方法,`queen`表示采用Queen法生成空间权重矩阵。
通过这个命令,我们可以得到一个标准化的空间权重矩阵。
III.实例分析为了更好地理解如何对空间权重矩阵进行标准化,我们来看一个实例。
假设我们有一组数据,描述了不同区域之间的贸易关系。
Stata空间计量命令汇总及具体操作方法指南

Stata空间计量命令汇总及具体操作方法指南空间计量经济学创造性地处理了经典计量方法在面对空间数据时的缺陷,考察了数据在地理观测值之间的关联。
近年来在人文社会科学空间转向的大背景下,空间计量已成为空间综合人文学和社会科学研究的基础理论与方法,尤其在区域经济、房地产、环境、人口、旅游、地理、政治等领域,空间计量成为开展定量研究的必备技能。
1、空间计量建模步骤空间统计分析:构建空间权重矩阵后,进行探索性空间统计分析:包括空间相关性检验(全局空间自相关和局部空间自相关等);空间计量分析:空间计量模型的回归与检验(SAR,SEM,SAC 等模型估计和检验等)。
空间滞后模型(Spatial Lag Model,SLM)主要是探讨各变量在一地区是否有扩散现象(溢出效应)。
其模型表达式为:参数反映了自变量对因变量的影响,空间滞后因变量是一内生变量,反映了空间距离对区域行为的作用。
区域行为受到文化环境及与空间距离有关的迁移成本的影响,具有很强的地域性(Anselin et al.,1996)。
由于SLM模型与时间序列中自回归模型相类似,因此SLM也被称作空间自回归模型(Spatial Autoregressive Model,SAR)。
空间误差模型(Spatial Error Model,SEM)存在于扰动误差项之中的空间依赖作用,度量了邻近地区关于因变量的误差冲击对本地区观察值的影响程度。
由于SEM模型与时间序列中的序列相关问题类似,也被称为空间自相关模型(Spatial Autocorrelation Model,SAC)。
估计技术:鉴于空间回归模型由于自变量的内生性,对于上述两种模型的估计如果仍采用OLS,系数估计值会有偏或者无效,需要通过IV、ML或GLS、GMM等其他方法来进行估计。
Anselin (1988)建议采用极大似然法估计空间滞后模型(SLM)和空间误差模型(SEM)的参数。
空间自相关检验与SLM、SEM的选择:判断地区间创新产出行为的空间相关性是否存在,以及SLM和SEM那个模型更恰当,一般可通过包括Moran’s I检验、两个拉格朗日乘数(Lagrange Multiplier)形式LMERR、LMLAG及其稳健(Robust)的R-LMERR、R-LMLAG)等形式来实现。
利用STATA创建空间权重矩阵与空间杜宾模型计算----命令

** 创建空间权重矩阵介绍*设置默认路径cd C:\Users\xiubo\Desktop\F182013.v4\F101994\sheng** 创建新文件*shp2dta:reads a shape (.shp) and dbase (.dbf) file from disk and converts them into Stata datasets.*shp2dta: 读取CHN_adm1 文件*CHN_adm1:为已有的地图文件*database (chinaprovince) :表示创建一个名称为“chinaprovince ”的dBase数据集*database(filename) :Specifies filename of new dBase dataset*coordinates(coord) :创建一个名称为“coord”的坐标系数据集*coordinates(filename) :Specifies filename of new coordinates dataset*gencentroids(stub) :Creates centroid variables*genid(newvarname) :Creates unique id variable for database.dtashp2dta using CHN_adm1,database (chinaprovince) coordinates(coord) genid(id) gencentroids(c)** 绘制2016 年中國GDP分布圖*spmap:Visualization of spatial data*clnumber(#):number of classes*id(idvar):base map polygon identifier( 识别符,声明变量名,一般以字母或下划线开头,包含数字、字母、下划线)*_2016GDP:变量*coord: 之前创建的坐标系数据集spmap _2016GDP using coord, id(id) clnumber(5)*更改变量名rename x_c longituderename y_c latitude** 生成距离矩阵*spmat: 用于定义与管理空间权重矩阵*Spatial-weighting matrices are stored in spatial-weighting matrix objects (spmat objects).*spmat objects contain additional information about the data used in constructing spatial-weighting matrices.*spmat objects are used in fitting spatial models; see spreg (if installed) and spivreg (if installed).*idistance:( 产生距离矩阵)create an spmat object containing an inverse-distance matrix W*或contiguity:create an spmat object containing a contiguity matrix W*idistance_jingdu: 命名名称为“idistance_jingdu ”的距離矩陣*longitude: 使用经度*latitude: 使用纬度*id(id): 使用id*dfunction(function[, miles]):( 设置计算距离方法)specify the distance function.*function may be one of euclidean (default), dhaversine, rhaversine, or the Minkowski distanceof order p, where p is an integer greater than or equal to 1.*normalize(row): (行标准化)specifies one of the three available normalization techniques: row, minmax, and spectral.*In a row-normalized matrix, each element in row i is divided by the sum of row i's elements.*In a minmax-normalized matrix, each element is divided by the minimum of the largest rowsum and column sum of the matrix.*In a spectral-normalized matrix, each element is divided by the modulus of the largest eigenvalue of the matrix.spmat idistance idistance_jingdu longitude latitude, id(id) dfunction(euclidean) normalize(row)** 保存stata 可读文件idistance_jingdu.spmatspmat save idistance_jingdu using idistance_jingdu.spmat** 将刚刚保存的idistance_jingdu.spmat 文件转化为txt 文件spmat export idistance_jingdu using idistance_jingdu.txt** 生成相邻矩阵spmat contiguity contiguity_jingdu using coord, id(id) normalize(row)spmat save contiguity_jingdu using contiguity_jingdu.spmatspmat export contiguity_jingdu using contiguity_jingdu.txt** 计算Moran’s I*安装spatwmat*spatwmat: 用于定义空间权重矩阵*spatwmat:imports or generates the spatial weights matrices required by spatgsa, spatlsa, spatdiag, and spatreg.*As an option, spatwmat also generates the eigenvalues matrix required by spatreg.*name(W): 读取空间权重矩阵W*name(W): 使用生成的空间权重矩阵W*xcoord:x 坐标*ycoord:y 坐标*band(0 8): 宽窗介绍*band(numlist) is required if option using filename is not specified.*It specifies the lower and upper bounds of the distance band within which location pairs mustbe considered "neighbors" (i.e., spatially contiguous)*and, therefore, assigned a nonzero spatial weight.*binary:requests that a binary weights matrix be generated. To this aim, all nonzero spatial weights are set to 1.spatwmat, name(W) xcoord(longitude) ycoord(latitude) band(0 8)*安装绘制Moran ’s I 工具:splagvar*splagvar --- Generates spatially lagged variables, constructs the Moran scatter plot,*and calculates global Moran's I statistics.*_2016GDP:使用变量_2016GDP*wname(W): 使用空间权重矩阵W*indicate the name of the spatial weights matrix to be used*wfrom(Stata):indicate source of the spatial weights matrix*wfrom(Stata | Mata) indicates whether the spatial weights matrix is a Stata matrix loaded inmemory or a Mata file located in the working directory.*If the spatial weights matrix had been created using spwmatrix it should exist as a Stata matrixor as a Mata file.*moran(_2016GDP): 计算变量_2016GDP 的Moran's I 值*plot(_2016GDP): 构建变量_2016GDPMoran 散点图splagvar _2016GDP, wname(W) wfrom(Stata) moran(_2016GDP) plot(_2016GDP)=============================================================================== ** 使用距离矩阵计算空间计量模型*设置默认路径cd 软件学习软件资料\stata\stata 指导书籍命令陈强高级计量经济学及stata 应用(第二版)全部数据*使用product.dta 数据集(陈强的高级计量经济学及其stata 应用P594)*将数据集product.dta 存入当前工作路径use product.dta , clear*创建新变量,对原有部分变量取对数gen lngsp=log(gsp)gen lnpcap=log(pcap)gen lnpc=log(pc)gen lnemp=log(emp)*将空间权重矩阵usaww.spat 存入当前工作路径spmat use usaww using usaww.spmat*使用聚类稳健的标准误估计随机效应的SDM 模型xsmle lngsp lnpcap lnpc lnemp unemp,wmat(usaww) model(sdm)robust nolog*使用选择项durbin(lnemp) ,不选择不显著的变量,使用聚类稳健的标准误估计随机效应的SDM 模型xsmle lngsp lnpcap lnpc lnemp unemp,wmat(usaww) model(sdm) durbin(lnemp) robust nolognoeffects*使用选择项durbin(lnemp) ,不选择不显著的变量,使用聚类稳健的标准误估计固定效应的SDM 模型xsmle lngsp lnpcap lnpc lnemp unemp,wmat(usaww) model(sdm) durbin(lnemp) robust nolognoeffects fe*存储随机效应和固定效应结果qui xsmle lngsp lnpcap lnpc lnemp unemp,wmat(usaww) model(sdm) durbin(lnemp) r2 nolog noeffects reest sto requi xsmle lngsp lnpcap lnpc lnemp unemp,wmat(usaww) model(sdm) durbin(lnemp) r2 nolog noeffects feest sto fe*esttab: 将保存的结果汇总到一张表格中*b(fmt):specify format for point estimates*beta[(fmt)]:display beta coefficients instead of point est's*se[(fmt)]:display standard errors instead of t statistics*star( * 0.1 ** 0.05 *** 0.01): 标记不同显著性水平对应的P 值*r2|ar2|pr2[(fmt)]:display (adjusted, pseudo) R-squared*p[(fmt)]:display p-values instead of t statistics*label:make use of variable labels*title(string):specify a title for the tableesttab fe re , b se r2 star( * 0.1 ** 0.05 *** 0.01)*hausman 检验*进行hausman 检验前,回归中没有使用稳健标准误(没用“r”),*是因为传统的豪斯曼检验建立在同方差的前提下*constant:include estimated intercepts in comparison; default is to exclude*df(#):use # degrees of freedom*sigmamore:base both (co)variance matrices on disturbance variance estimate from efficient estimator*sigmaless:base both (co)variance matrices on disturbance variance estimate from consistent estimatorhausman fe re** 有时我们还会得到负的chi2 值,即chi2<0,表明模型不能满足Hausman 检验的渐近假设。
空间计量与stata命令分解

空间相关来源
4.溢出效应(spillover effect)
溢出效应是指经济活动和过程中的外部性对未参与 经济活动和过程其中的周围个体的影响。 散发有毒气体 的植物会对周围的植物产生有害的影响, 屋主拥有一座漂 亮花园也显然对周围邻居有正效应。 同样不断加强的贸 易往来所带来的经济利益对地区性国家多边联盟的形成 具有正的溢出效应。
时,可以证明
不为零。我们把这
种空间相关性的来源称为测量性误差。这一 来源说明,当我们处理带有空间特性的数据
时,无论经济理论是否明确显示空间相关性
,我们都应该在设定模型形式时候对空间相 关性给予足够重视和相应考虑。
11
概述
空间统计学VS空间计量经济学
首先,空间统计学的理论是空间计量经济学发展的基 础。正如计量经济学其他分支的发展都广泛借助统计学 的理论,空间计量经济学也尽可能吸收一切可以利用的 现存有关空间统计的理论。
wij (xi xj )2
C
i1 j1
nn
n
1 I
2
wij (xi x)2
15
空间自相关
二元相关(0-1相关)
例1.1.1. 在地图上的 个子区域中,如果 和 具有相
邻的边界(boundary),则定义 W n ,ij 1 ,否则
。 W n,ij 0
16
空间权重矩阵
0 1 1 1 0 0
1
0
1
0
0
0
1 1 0 0 1 1
Wij
1
0
0
0
1
0
0 0 1 1 0 1
9
空间相关来源
5.测量误差 A,B,C三处的观测本来是相互独立的,但
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
stata空间计量计算空间矩阵乘自变量
本篇文章介绍如何在Stata软件中进行空间计量计算,重点是对空间矩阵乘自变量的操作。
首先需要了解何为空间计量,即考虑空间依赖性的变量之间的关系,这种依赖性通常表现为空间自相关性。
在进行空间计量分析时,需要将空间自相关性纳入模型中,使用空间权重矩阵来表示变量之间的空间联系。
然后,可以使用空间矩阵乘自变量的方法计算空间自相关性对模型的影响。
具体操作如下:
1. 准备空间权重矩阵:在Stata中,可以使用spatialweight 命令来生成空间权重矩阵,该命令可以根据不同的空间连接方式生成不同的权重矩阵,例如queen连接、rook连接等。
2. 载入数据:使用命令use读取数据文件。
3. 进行空间计量回归:使用命令spreg进行空间计量回归,将空间权重矩阵和自变量作为参数输入。
在进行回归分析时,可以使用OLS(ordinary least squares)或GM(generalized method of moments)方法,其中GM方法可以纠正空间自相关性引起的异方差性问题。
4. 计算空间矩阵乘自变量:使用命令spmatmul将空间权重矩阵乘以自变量,得到空间矩阵乘自变量的结果。
该结果可以用于分析空间自相关性对模型的影响,例如用于进行空间误差分解等。
总之,Stata软件提供了丰富的空间计量分析工具,可以方便
地进行空间矩阵乘自变量等计算操作,帮助研究者更好地理解空间
依赖性对变量关系的影响。