清华svm 模式识别课件
合集下载
模式识别 张学工

Xuegong Zhang, Tsinghua University
2
张学工《模式识别》教学课件
10.1.2
测试错误率
独立的测试集
ˆ
k N
N:测试集样本数;k:测试集错分样本数 最大似然估计
Xuegong Zhang, Tsinghua University
3
张学工《模式识别》教学课件
10.1.3 交叉验证
张学工《模式识别》教学课件
第十章 模式识别系统的评价
Xuegong Zhang, Tsinghua University
1
张学工《模式识别》教学课件
10.1 监督模式识别方法的错误率估计
10.1.1 训练错误率
几个同义词: 训练错误率(Training Error Rate 或简称作 Training Error) 视在错误率(Apparent Error) 重代入错误率(re-substitution error) 经验风险 偏乐观 经验风险与期望风险的关系: 《统计学习理论》
紧致性(compactness)或一致性(homogeneity)
连接性(separation)
Xuegong Zhang, Tsinghua University
12
张学工《模式识别》教学课件
Silhouette 值:同时反映类内距离和类间距离的指标
Dunn 指数(Dunn Index)
Xuegong Zhang, Tsinghua University
7
张学工《模式识别》教学课件
10.2.2 用扰动重采样估计 SVM 错误率的置信区间
Bo Jiang, Xuegong Zhang and Tianxi Cai, Estimating the confidence interval for prediction errors of support vector machine classifiers. Journal of Machine Learning Research, 9:521-540, 2008
SVMPPT课件

VC维:所谓VC维是对函数类的一种度量,可
以简单的理解为问题的复杂程度,VC维越高, 一个问题就越复杂。正是因为SVM关注的是VC 维,后面我们可以看到,SVM解决问题的时候, 和样本的维数是无关的(甚至样本是上万维的 都可以,这使得SVM很适合用来解决像文本分 类这样的问题,当然,有这样的能力也因为引 入了核函数)。
11
SVM简介
置信风险:与两个量有关,一是样本数
量,显然给定的样本数量越大,我们的 学习结果越有可能正确,此时置信风险 越小;二是分类函数的VC维,显然VC维 越大,推广能力越差,置信风险会变大。
12
SVM简介
泛化误差界的公式为:
R(w)≤Remp(w)+Ф(n/h) 公式中R(w)就是真实风险,Remp(w)表示 经验风险,Ф(n/h)表示置信风险。此时 目标就从经验风险最小化变为了寻求经 验风险与置信风险的和最小,即结构风 险最小。
4
SVM简介
支持向量机方法是建立在统计学习理论 的VC 维理论和结构风险最小原理基础上 的,根据有限的样本信息在模型的复杂 性(即对特定训练样本的学习精度, Accuracy)和学习能力(即无错误地识 别任意样本的能力)之间寻求最佳折衷, 以期获得最好的推广能力(或称泛化能 力)。
5
SVM简介
10
SVM简介
泛化误差界:为了解决刚才的问题,统计学
提出了泛化误差界的概念。就是指真实风险应 该由两部分内容刻画,一是经验风险,代表了 分类器在给定样本上的误差;二是置信风险, 代表了我们在多大程度上可以信任分类器在未 知样本上分类的结果。很显然,第二部分是没 有办法精确计算的,因此只能给出一个估计的 区间,也使得整个误差只能计算上界,而无法 计算准确的值(所以叫做泛化误差界,而不叫 泛化误差)。
以简单的理解为问题的复杂程度,VC维越高, 一个问题就越复杂。正是因为SVM关注的是VC 维,后面我们可以看到,SVM解决问题的时候, 和样本的维数是无关的(甚至样本是上万维的 都可以,这使得SVM很适合用来解决像文本分 类这样的问题,当然,有这样的能力也因为引 入了核函数)。
11
SVM简介
置信风险:与两个量有关,一是样本数
量,显然给定的样本数量越大,我们的 学习结果越有可能正确,此时置信风险 越小;二是分类函数的VC维,显然VC维 越大,推广能力越差,置信风险会变大。
12
SVM简介
泛化误差界的公式为:
R(w)≤Remp(w)+Ф(n/h) 公式中R(w)就是真实风险,Remp(w)表示 经验风险,Ф(n/h)表示置信风险。此时 目标就从经验风险最小化变为了寻求经 验风险与置信风险的和最小,即结构风 险最小。
4
SVM简介
支持向量机方法是建立在统计学习理论 的VC 维理论和结构风险最小原理基础上 的,根据有限的样本信息在模型的复杂 性(即对特定训练样本的学习精度, Accuracy)和学习能力(即无错误地识 别任意样本的能力)之间寻求最佳折衷, 以期获得最好的推广能力(或称泛化能 力)。
5
SVM简介
10
SVM简介
泛化误差界:为了解决刚才的问题,统计学
提出了泛化误差界的概念。就是指真实风险应 该由两部分内容刻画,一是经验风险,代表了 分类器在给定样本上的误差;二是置信风险, 代表了我们在多大程度上可以信任分类器在未 知样本上分类的结果。很显然,第二部分是没 有办法精确计算的,因此只能给出一个估计的 区间,也使得整个误差只能计算上界,而无法 计算准确的值(所以叫做泛化误差界,而不叫 泛化误差)。
清华大学模式识别讲义06-2
n
1 n ∑αiα j yi y j (xi ⋅ x j ) 2 i , j =1
n f ( x ) = sgn ∑ α i* y i ( x i ⋅ x ) + b * i =1
K ( x i , x j ) = (Φ ( x i ) ⋅ Φ ( x j ))
只要一个核函数 K (xi , x j ) 满足Mercer条 件,它就是某个空间的内积, 如: 得到优化问题:
2
Xuegong Zhang Tsinghua University
3
Xuegong Zhang Tsinghua University
4
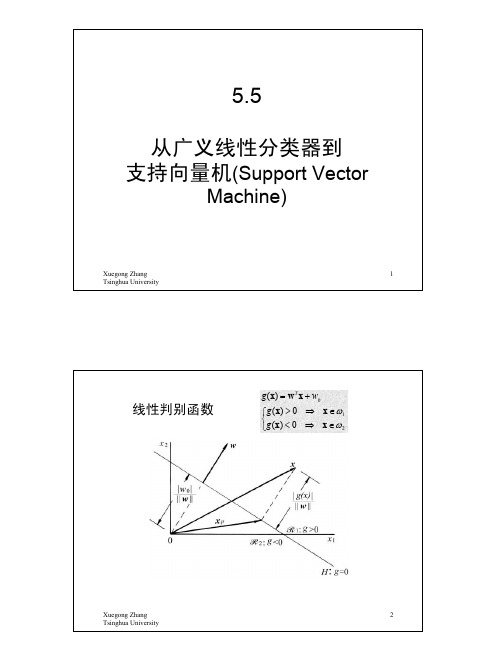
最优分类面(Optimal Hyperplane)
假定训练数据 ( x1 , y1 ), L , ( xl , y l ) , x ∈ R n , y ∈ {+1,−1} 可以被一个超平面 ( w ⋅ x ) − b = 0 分开。 如果这个向量集合被超平面没有错误地分开,并且 离超平面最近的向量与超平面之间的距离 (称作间隔 margin ) 是最大的,则我们说这个向量集合被这个 最 优超平面(或最大间隔超平面)分开。 决策函数为
min R( w) = ∫ L(y , f (x, w))dF (x, y )
23
Xuegong Zhang Tsinghua University
经验风险最小化(ERM - Empirical Risk Minimization)
1 n min Remp ( w) = ∑ L(y i , f (x i , w)) n i =1
Xuegong Zhang Tsinghua University
f ( x) = sgn{( w ⋅ x) − b}
机器学习SVMPPT课件

代入(1,0),(0,1)验证f0 wT (1,1);b 0
f2
第16页/共48页
f0(x) (1,1)x 0
f1(x) (1,1)x 1 0 f2(x) (1,1)x 1 0
如果w相同,则分类面是平行 的,b是一个偏移量
线性SVM
线性分类器学习:从给定的训练样本确定wT和b这两个参数。
第14页/共48页
线性SVM
分类面:把一个空间按照类别切分两部分的平面,在二维空 间中,分类面相当于一条直线,三维空间中相当于一个平面, 高维空间为超平面
线性分类面函数形式为:
f (x) wT x b
wT,b是分类面函数参数,x是输入的样本, wT权向量,b是偏移量
第15页/共48页
线性SVM
• 大量训练样本下可以取得好的效果,速度很快
• 人工神经网络ANN
SVM案例:手写体数字识别例子
• 贝尔实验室对美国邮政手写数字库进行的实验 • 该数据共包含7291个训练样本,2007个测试数据,
输入数据的维数为16x16维
分类器/学习方法 人工表现 决策树C4.5 三层神经网络 SVM
DeepLearning
(1, 0)T
几何解释:线性分类器的作用就是把输入样本在法向量 上投影变成一维变量,然后给一个阈值来分类
线性SVM
表示 +1 表示 -1
x
w x + b>0
f
yest
f(x,w,b) = sign(w x + b)
如何分类这些数据?
第18页/共48页 w x + b<0
线性SVM
表示 +1 表示 -1
L(w,b, ) 0; L(w,b, ) 0
模式识别清华 课件第一章

模式识别※第一章绪论§课前索引§1.1 模式识别和模式的概念§1.2 模式的描述方法§1.3 模式识别系统§1.4 有关模式识别的若干问题§1.5 本书内容及宗旨§本章小节§本章习题※第二章贝叶斯决策理论与统计判别方法§课前索引§2.1 引言§2.2 几种常用的决策规则§2.3 正态分布时的统计决策§本章小节§本章习题※第三章非参数判别分类方法§课前索引§3.1引言§3.2线性分类器§3.3 非线性判别函数§3.4 近邻法§3.5 支持向量机§本章小结§本章习题※第四章描述量选择及特征的组合优化§课前索引§4.1 基本概念§4.2 类别可分离性判据§4.3 按距离度量的特征提取方法§4.4 按概率距离判据的特征提取方法§4.5 基于熵函数的可分性判据§4.6 基于Karhunen-Loeve变换的特征提取§4.7 特征提取方法小结§4.8 特征选择§本章小节§本章习题※第五章非监督学习法§课前索引§5.1 引言§5.2 单峰子类的分离方法§5.3 聚类方法§5.4 非监督学习方法中的一些问题§本章小节§本章习题※第六章人工神经元网络§课前索引§6.1 引言§6.2 Hopfield模型§6.3 Boltzmann机§6.4 前馈网络§6.5 人工神经网络中的非监督学习方法§6.6 小结§本章习题第一章绪论本章要点、难点本章是这门课的绪言,重点是要弄清“模式识别”的名词含义,从而弄清这门课能获得哪方面的知识,学了以后会解决哪些问题。
清华大学模式识别课件-07_近邻法

(6 20)
因为 P 与
P 2 i | x 有关,若寻求 P 与 P* 的关系,首先可以寻求 P 2 i | x 与 P* 的关
i 1 i 1
系。现利用式(6-18),式(6-20)的结果来推导,有
P | x P
2 2 i 1 i
c
m
| x P i | x 1 P e | x
以上两式对我们的启发是:对已知的 P m | x 而言,
*
P | x 的最小值对应着 P 的最大值。
2 i 1 i
c
如能求出 P 的最大值,就把贝叶斯错误率 P 和最近邻法错误率 P 联系起来了。 若记
P | x P
2 2 i 1 i
c
m
| x P 2 i | x
x's
p x' dx'
N
(6 8)
P x1 , x2 , …,x N 1 Ps
当 N→∞时,这一概率趋于零。由于 s 可以任意小,所以 N→∞时, x' 落在以 x 为中心无限小区域
中的概率趋于 1。就是说 x' 以概率为 1 收敛于 x,从而
N
lim p x' | x x' - x
(6 9)
现在来计算条件错误概率 PN e | x, x' 。当我们说有 N 个独立抽取并有类别标记的样本时,意 思是说有 N 对随机变量 x1 , 1 , x2 , 2 , …, x N , N ,其中 xi 是独立抽取的样本,i 是 xi 的类别 标记,且 i 是 c 个类别状态 1 , 2 …,c 之一。现在假定抽取一对 x, ,并假定标以 ' 的 x' 是 x 的最近邻。由于抽出 x' 时,它的类别状态和 x 无关。因此有
清华大学模式识别课件-06_SVM课件

N 1 T min ( w, ) w w C i w , 2 i 1
subject to
di ( w T xi b) 1 -i for i 1, 2,..., N
: upper bound of misclassification error
i 1 i
' i 1
gi ( w) 0 if w is feasible
f ( w' ) f ( w)
w
'
is optimal solution of (P)
15
Strong Duality
Strong Duality: the condition
max min ( w, ) min max ( w, )
Decision surface:
wT x b 0
wT xi b 0 for di 1 wT xi b 0 for di 1
5
Decision surface (line)
figure copied from reference [4]
6
Measure of distance
( w, ) f ( w ) i g i ( w )
i lution of (P)
' N i 1 ' i ' N i 1
Proof:
' N i 1
f ( w ) i gi (w ) f ( w ) gi (w ) f ( w) i' gi (w)
i 1 N
primal problem dual function dual problem
min L( w)
subject to
di ( w T xi b) 1 -i for i 1, 2,..., N
: upper bound of misclassification error
i 1 i
' i 1
gi ( w) 0 if w is feasible
f ( w' ) f ( w)
w
'
is optimal solution of (P)
15
Strong Duality
Strong Duality: the condition
max min ( w, ) min max ( w, )
Decision surface:
wT x b 0
wT xi b 0 for di 1 wT xi b 0 for di 1
5
Decision surface (line)
figure copied from reference [4]
6
Measure of distance
( w, ) f ( w ) i g i ( w )
i lution of (P)
' N i 1 ' i ' N i 1
Proof:
' N i 1
f ( w ) i gi (w ) f ( w ) gi (w ) f ( w) i' gi (w)
i 1 N
primal problem dual function dual problem
min L( w)
模式识别的概念过程与应用PPT课件

红苹果
橙子 2.00
1.50
x1
0.60
0.80
1.00
1.20
1.40
模式识别 – 绪论
特征的分布
x2 3.00 2.50
红苹果
绿苹果
橙子 2.00
1.50
x1
0.60
0.80
1.00
1.20
1.40
模式识别 – 绪论
五、模式识别系统
待识模式 数据采集及预 处理
训练模式
数据采集及预 处理
特征提取与选 择
安全领域:生理特征鉴别(Biometrics),网 上电子商务的身份确认,对公安对象的刑侦和 鉴别;
模式识别 – 绪论
二、模式识别的应用
军事领域:巡航导弹的景物识别,战斗单元的 敌我识别;
办公自动化:文字识别技术和声音识别技术; 数据挖掘:数据分析; 网络应用:文本分类。
ቤተ መጻሕፍቲ ባይዱ
模式识别 – 绪论
《模式分类》,机械工业出版社,Richard O.
Duda
《模式识别》(第二版),清华大学出版社,边
肇祺,张学工;
特征提取与选 择
识别结果 模式分类
分类 训练
分类器设计
模式识别 – 绪论
六、模式识别问题的描述
给定一个训练样本的特征矢量集合:
D x 1 ,x 2 , ,x n ,x i R d
分别属于c个类别:
1,2, ,c
设计出一个分类器,能够对未知类别样本x进行分类
ygx ,R d 1 , ,c
模式识别 – 绪论
模式识别 – 绪论
第一章 绪论
模式识别 – 绪论
一、模式识别的概念
什么是模式识别? 模式识别研究的内容?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
N
ξi ≥ 0, for all i
C : tradeoff between complexity of the machine
and the number of nonseparable points
24
Dual Problem
Given the training sample {( xi , di )}iN 1 , find the Lagrange multipliers {αi }iN 1 that = = maximize the objective function 1 N N Q (α ) = ∑αi − ∑∑αiα j di d j xiT x j 2 i =1 j =1 i =1 subject to the constraints (1) ∑αi di = 0
wT w = (∑ α i di xi )T (∑ α i di xi ) = ∑∑ α iα j di d j xiT x j
i =1 i =1
N
N
N
N
N
i =1 j =1
N
α i di wT xi = ∑ α i di (∑ α j d j x j )T xi = ∑∑ α i diα j d j xiT x j ∑
⇒
Φ (w ',α ) ≤ Φ (w ',α ' ) ≤ Φ (w,α ' )
why we find a saddle point
Theorem:
( w' , α ' ) is a saddle point of if
Φ ( w, α ) = f ( w ) − ∑ α i g i ( w )
i =1 N
N
∑α d
i i=1
N
i
=0 for i = 1, 2,..., N
(2)α i ≥ 0
H (i, j )
20
Some discussions
1. Q(α ) depends only on the input patterns in the form of a set of dot products, {xiT x j }(N, j ) =1 i 2. support vectors determine the hyperplane
w = ∑ α i di xi
i =1
N
∑α d
i =1 i
N
i
=0
18
Solve the dual problem (ctd.)
N 1 T J ( w , b, α ) = w w − ∑ α i [di ( w T xi + b) − 1] 2 i =1
∑α d
i =1 i
N
i
=0
N N N 1 T = w w − ∑ α i di wT xi − b∑ α i di + ∑ α i 2 i =1 i =1 i =1
N 1 T Φ ( w, α ) = J ( w , b, α ) = w w − ∑ α i [di ( w T xi + b) − 1] 2 i =1
dual function:
Q(α ) = min J ( w, b, α )
w ,b
∂J ( w, b, α ) =0 ∂w ∂J ( w, b, α ) =0 ∂b
α ≥0 α ≥0
i =1 N
min L( w)
w
min max Φ ( w, α )
w
α ≥0
Q(α ) = min Φ ( w, α )
w
max Q(α )
α ≥0
max min Φ ( w, α )
α ≥0
w
we prefer to solve the dual problem!
17
Solve the dual problem
T
N i =1
(P)
for d = +1 i for d = −1 i
di ( w xi + b) ≥ 1 for i = 1, 2,..., N
gi (w)=di ( w xi + b) − 1 ≥ 0 for i = 1, 2,..., N 10
T
Φ ( w, α )
Lagrange function
wo Decomposition of x: x = x p + r wo
T g ( x) = wo x + bo = r wo
⇒
g ( x) r= wo
7
Linear classfication
Training sample set T = {(xi , d i )}iN 1 =
⎧ d i = + 1, positive patterns ⎨ ⎩ d i = − 1, negative patterns
α
w w
α
holds if and only if there exists a pair ( w' , α ' ) satisfies the saddle-point condition for Φ Proof: (omitted)
“Stephen G.Nash & Ariela Sofer Linear and Nonlinear Programming” pp468
' ' ' i =1 i =1 ' i ' i =1 N N N
let α = 0
∑ α gi ( w ) ≤ 0
i =1 ' i '
N
N
α i' gi ( w' ) = 0 ∑
i =1
N
consider the second inequality
f ( w ) ≤ f ( w) − ∑ α i' gi ( w)
' ' i =1 ' i ' i =1
N
N
let
' ' α1 = α1' + 1, α 2 = α 2 ,...α N = α N
g i ( w' ) ≥ 0
14
w
'
is a feasible solution of (P)
why we find a saddle point (ctd.)
f ( w ) − ∑ α i gi (w ) ≤ f ( w ) − ∑ α gi (w ) ≤ f ( w) − ∑ α i' gi (w)
Margin of separation
2 ρ = 2r = wo
9
Optimization problem
Training sample set T = {(xi , d i )}
1 T min f ( w ) = w w 2
subject to ⎧ wT x + b ≥ +1 ⎨ T i ⎩ w x + b ≤ −1 i
max min Φ ( w, α ) = Φ ( w' , α ' ) = min max Φ ( w, α )
α
w w
α
16
Dual Problem
primal function primal problem dual function dual problem
L( w) = max Φ ( w, α ) = max[ f ( w) − ∑ α i gi ( w)]
Optimal Separating hyperplane
3
Optimal Hyperplane
4
Linear classfication
Training sample set T = {(xi , d i )}iN 1 =
⎧ d i = + 1, positive patterns ⎨ ⎩ d i = − 1, negative patterns
i =1 i =1 j =1 i =1 j =1
19
N
N
N
Dual Problem
We may now state the dual problem:
Given the training sample {( xi , di )}iN 1 , find the Lagrange multipliers {α i }iN 1 that = = maximize the objective function 1 N N Q (α ) = ∑ α i − ∑∑ α iα j di d j xiT x j 2 i =1 j =1 i =1 subject to the constraints (1)
' i =1
gi ( w) ≥ 0 if w is feasible
f ( w' ) ≤ f ( w)
w
'
is optimal solution of (P)
15
Strong Duality
Strong Duality: the condition
max min Φ ( w, α ) = min max Φ ( w, α )
Support Vector Machine
张长水 清华大学自动化系
1
Outline
Linearly separable patterns Linearly non-separable patterns Nonlinear case Some examples
2
Linearly separable case
∑ α g (w) = 0
i =1 i i
_ _ T _