模式识别-第二章聚类分析
模式识别聚类分析

x1 ,
(
( x1
x2旳值。可用下列递推
k ) xi ) /( N1(k ) 1)
x(k 1) 2
(k)
x2
(k)
(x2
xi
)
/(
N
(k 2
)
1)
x1 (k ) , x2 (k )是第k步对分时两类均值,
x1(k 1) , x2(k 1)是下一次对分时把xi从G1(k )
划到G2(k)时的两类均值
所以x1 Z1(1)
再继续进行第二,第三次迭代… 计算出 E(2) , E(3) , …
次数 1 2 3 4 5 6 7 8 9
10 11
G1 G2
x21 x20 x18 x14 x15 x19
x11 x13 x12 x17 x16
E值 56.6 79.16 90.90 102.61 120.11 137.15 154.10 176.15 195.26 213.07 212.01
Ni为第i类的样本数.
离差平方和增量:设样本已提成ωp,ωq两类, 若把ωp,ωq合为ωr类,则定义离差平方:
Dp2q Sr (S p Sq )
其中S p , Sq分别为 p类于q类的离差平方和, S r为 r 类的离差平方和
增量愈小,合并愈合理。
聚类准则
Jw Min
类内距离越小越好 类间距离越大越好
体积与长,宽,高有关;比重与材料,纹理,颜 色有关。这里低、中、高三层特征都有了。
措施旳有效性
特征选用不当 特征过少 特征过多 量纲问题
主要聚类分析技术
谱系法(系统聚类,层次聚类法) 基于目旳函数旳聚类法(动态聚类) 图论聚类法 模糊聚类分析法
2.2模式相同度度量
五 模式识别——聚类

——聚类分析
田玉刚
信息工程学院
主要内容
数据预处理 距离与相似系数
算法分析
实例分析
2018年12月10日
第2页
聚类分析又称群分析,它是研究(样本/样品/模式)分类问题的一
种多元统计方法,所谓类,通俗地说,就是指相似元素的集合。严格的 数学定义是较麻烦的,在不同问题中类的定义是不同的。
2018年12月10日
第10
数据预处理
5、中心标准化
中心标准化是将原始数据矩阵中的元素减去该列的的平 均值,其商即为标准化数据矩阵的元素
6、对数标准化 对数标准化是将原始数据矩阵中的元素取常用对数后作 为标准化数据矩阵的元素
2018年12月10日
第11
数据预处理
由上述标准化方法可知,中心标准化法(方法 5 )和对数标准化法 (方法6)达不到无量纲目的。一个好的变换方法,应在实现无量纲的同 时,保持原有各指标的分辨率,即变异性的大小。现将方法1(标准差)、 方法2 (极大值) 、方法3 (极差)和方法4 (均值)变换后数据的特 征列于表1。
要求一个向量的n个分量是不相关的且具有相同的方差,或者说各坐标对
欧氏距离的贡献是同等的且变差大小也是相同的,这时使用欧氏距离才 合适,效果也较好,否则就有可能不能如实反映情况,甚至导致错误结
论。因ቤተ መጻሕፍቲ ባይዱ一个合理的做法,就是对坐标加权,这就产生了“统计距离”。
2018年12月10日
第18
距离与相似系数
比如设
2018年12月10日
第30
算法分析-层次聚类
2018年12月10日
第31
算法分析-层次聚类
模式识别导论习题参考答案-齐敏
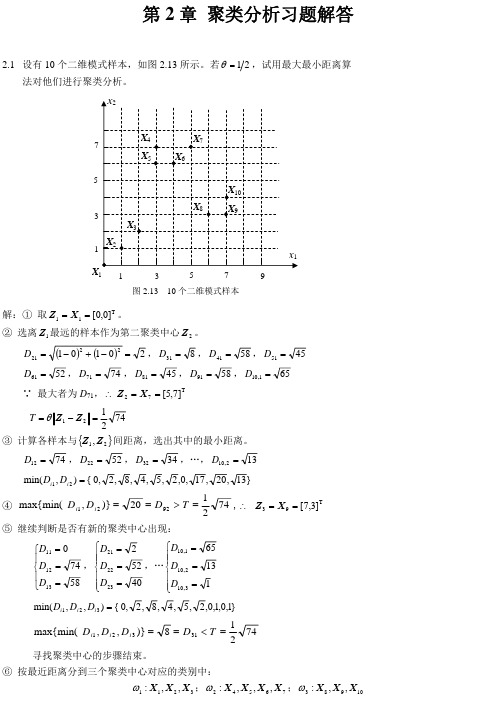
④ max{min( D i1 , D i 2 )}
20 D 92 T
1 74 , Z 3 X 9 [7,3]T 2
⑤ 继续判断是否有新的聚类中心出现:
D10,1 65 D21 2 D11 0 74 52 D D , ,… 12 22 D10, 2 13 D13 58 D23 40 D10,3 1
G2 (0)
G 3 ( 0)
G4 ( 0 )
G5 (0)
0 1 2 18 32 0 5 13
25
G3 (0)
G4 (0)
0 10 20 0
2
G5 (0)
0
(2) 将最小距离 1 对应的类 G1 (0) 和 G2 (0) 合并为一类,得到新的分类
G12 (1) G1 (0), G2 (0) , G3 (1) G3 (0), G4 (1) G4 (0) , G5 (1) G5 (0)
2
X3 X 6 ) 3.2, 2.8
T
④ 判断: Z j ( 2) Z j (1) , j 1,2 ,故返回第②步。 ⑤ 由新的聚类中心得:
X1 : X2 :
D1 || X 1 Z 1 ( 2) || X 1 S1 ( 2 ) D2 || X 1 Z 2 ( 2) || D1 || X 2 Z1 ( 2) || X 2 S1 ( 2 ) D2 || X 2 Z 2 ( 2) ||
T
(1)第一步:任意预选 NC =1, Z1 X 1 0,0 ,K=3, N 1 , S 2 , C 4 ,L=0,I=5。 (2)第二步:按最近邻规则聚类。目前只有一类, S1 { X 1 , X 2 , , X 10 },N 1 10 。 (3)第三步:因 N 1 N ,无聚类删除。 (4)第四步:修改聚类中心
第二章距离分类器和聚类分析
第二章 距离分类器和聚类分析2.1 距离分类器一、模式的距离度量通过特征抽取,我们以特征空间中的一个点来表示输入的模式,属于同一个类别的样本所对应的点在模式空间中聚集在一定的区域,而其它类别的样本点则聚集在其它区域,则就启发我们利用点与点之间距离远近作为设计分类器的基准。
这种思路就是我们这一章所要介绍的距离分类器的基础。
下面先看一个简单的距离分类器的例子。
例2.1作为度量两点之间相似性的距离,欧式距离只是其中的一种,当类别的样本分布情况不同时,应该采用不同的距离定义来度量。
设,X Y 为空间中的两个点,两点之间的距离(),d X Y ,更一般的称为是范数X Y -,一个矢量自身的范数X 为矢量的长度。
作为距离函数应该满足下述三个条件: a) 对称性:()(),,d d =X Y Y X ;b) 非负性:(),0d ≥X Y ,(),0d =X Y 当且仅当=X Y ; c) 三角不等式:()()(),,,d d d ≤+X Y X Z Y Z 。
满足上述条件的距离函数很多,下面介绍几种常用的距离定义: 设()12,,,Tn x x x =X ,()12,,,Tn y y y =Y 为n 维空间中的两点1、 欧几里德距离:(Eucidean Distance)()()1221,ni i i d x y =⎡⎤=-⎢⎥⎣⎦∑X Y2、 街市距离:(Manhattan Distance)()1,ni i i d x y ==-∑X Y3、 明氏距离:(Minkowski Distance)()11,mnm i i i d x y =⎡⎤=-⎢⎥⎣⎦∑X Y当2m =时为欧氏距离,当1m =时为街市距离。
4、 角度相似函数:(Angle Distance)(),T d ⋅=X YX Y X Y1nTi i i x y =⋅=∑X Y 为矢量X 和Y 之间的内积,(),d X Y 为矢量X 与Y 之间夹角的余弦。
模式识别中的聚类分析方法

模式识别中的聚类分析方法聚类分析是一种常用的机器学习方法,用于将大量数据分为不同的类别或群组,并在其中寻找共性和差异性。
在模式识别中,聚类分析可以帮助我们理解数据集中不同对象之间的关系,以及它们之间的相似性和差异性。
本文将介绍聚类分析的基本概念、算法和应用,以及一些实用的技巧和方法,以帮助读者更好地理解和应用这一方法。
一、聚类分析的基础概念在聚类分析中,我们通常会面对一个数据点集合,其特征被表示为$n$个$d$维向量$x_{i}=(x_{i1},x_{i2},…,x_{id})$。
聚类分析的目标是将这些数据点划分为$k$个不同的类别或群组$G_{1},G_{2},…,G_{k}$,并使得同一类别中的数据点相似性较高,不同类别之间的相似性较低。
为了完成这个任务,我们需要先定义一个相似性度量方法,用于计算数据点之间的距离或相似度。
常用的相似性度量方法包括欧式距离、余弦相似度、Jaccard相似度和曼哈顿距离等,具体选择哪一种方法取决于我们要研究的数据类型和应用要求。
定义了相似性度量方法后,我们可以使用聚类算法将数据点分成不同的类别。
聚类算法的主要分类包括层次聚类和基于中心点的聚类。
层次聚类是通过自下而上的方法将数据点归属到不同的类别中,以便于构建聚类树或聚类图。
基于中心点的聚类则是通过不断地计算每个数据点离其所属类别的中心点的距离来更新类别簇,直到收敛为止。
通常来说,基于中心点的聚类算法更快且更易于应用,因此被广泛应用于实际问题中。
二、聚类分析的主要算法1. K-means 聚类算法K-means 聚类算法是一种基于中心点的聚类算法,其核心思想是通过不断更新每个数据点所属的类别,同时更新该类别的中心点,直到找到最优的聚类结果。
具体而言,K-means 聚类算法首先需要预设$k$个初始的聚类中心点,然后计算每个数据点与这$k$个聚类中心的距离,并将其分配到最近的一个聚类中心点所代表的类别中。
完成初始聚类后,算法会重新计算每个类别的中心点,并根据新的中心点重新分配所有数据点,直到所有数据点都不再变换为止。
模式识别--聚类分析

Sub-optimal Clustering
• A clustering is a set of clusters • Important distinction between hierarchical and partitional sets of clusters • Partitional Clustering (flat)
– A division data objects into non-overlapping subsets (clusters) such that each data object is in exactly one subset
3 2.5 2
Original Points
1.5
y
1 0.5 0 -2
-1.5
-1
-0.5
00Leabharlann 511.52
x
3
3
2.5
2.5
2
2
1.5
1.5
y
1
y
1 0.5 0.5 0 0 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 -2
-1.5
-1
-0.5
0
0.5
1
1.5
2
x
x
Optimal Clustering
9 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10
Update the cluster means
4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10
2011/5/12
樊明锁
聚类分析
14
Two different K-means Clusterings
模式识别 第二章 聚类分析

现金识别例子
100元A面第1个样本第10点和20点的距离 X: (75, 76,101, 83,102, 96, 91, 82) Y: (70, 74, 90, 76, 99, 96, 90, 86) X-Y: 5, 2, 11, 7, 3, 0, 1, -4
Eucliden=15.000000 Manhattan=33.000000 Chebyshev=11.000000 Minkowski=11.039449——m=8
其中马式矩阵为100圆A面的,上面是各面到 100圆A面的均值点的平均马式距离。
现金识别例子——100圆A面的传感器1 到其它各面传感器1的街坊距离
2.2 模式相似性测度
二、相似测度
测度基础:以两矢量的方向是否相近作为考虑的基 础,矢量长度并不不重要。设 1.角度相似系数(夹角余弦) (2-2-11)
变得很费力。因此可使用聚类分析的方法将数据分
成几组可判断的聚类m(m<<N)来处理,每一个
类可当作独立实体来对待。从这个角度看,数据被
压缩了。
17
第二章 聚类分析 聚类应用的四个基本方向
二、假说生成
在这种情况下,为了推导出数据性质的一些假
说,对数据集进行聚类分析。因此,这里使用聚类 作为建立假说的方法,然后用其他数据集验证这些 假说。
现金识别例子
SW的逆矩阵为: 0.3 -0.0 0.1 -0.1 -0.1 -0.1 -0.2 0.2 -0.0 0.3 -0.1 -0.1 0.1 -0.6 0.3 0.2 0.1 -0.1 0.3 -0.1 -0.0 -0.2 -0.3 0.4 -0.1 -0.1 -0.1 0.2 0.1 0.3 -0.1 -0.2 -0.1 0.1 -0.0 0.1 0.7 -0.7 -0.4 0.2 -0.1 -0.6 -0.2 0.3 -0.7 2.2 -0.0 -1.0 -0.2 0.3 -0.3 -0.1 -0.4 -0.0 1.2 -0.5 0.2 0.2 0.4 -0.2 0.2 -1.0 -0.5 1.0
模式识别-聚类分析

定义5:若将集合S任意分成两类S1,S2,这两类的距离D(S1,S2)
满足 D(S1 , S 2 ) h ,称S对于阈值h组成一类
2.3 类的定义与类间距离
2.3.1 类的定义
类的划分具有人为规定性,这反映在定义的选取及参 数的选择上。
一个分类结果的优劣最后只能根据实际来评价,因此 较多地利用研究对象的知识才能选择适当的类的定义, 从而使分类结果更符合实际。
1 m Vy ( yi y )( yi y ) ' m 1 i 1 1 m ( Axi Ax )( Axi Ax ) ' m 1 i 1 1 m A( xi x )( xi x ) ' A ' m 1 i 1 1 m A[ ( xi x )( xi x ) '] A ' AVx A ' m 1 i 1
设n维矢量 xi , x j 是矢量集 {x1 , x2 ,, xm } 中的两
d ( xi , x j ) ( xi x j )'V 1 ( xi x j ) 1 m V ( xi x )(xi x )' m 1 i 1 1 m x xi m i 1
(2)
(3) (4)
(5)
x'y 1 1 Tanimoto测度 s( x , y ) x ' x y ' y x ' y 3 3 1 5 x'y 1 s( x , y ) Rao测度 n 6 a e 11 1 简单匹配测度 m( x , y ) n 6 3 2x ' y 2 1 m( x , y ) Dice系数 x 'x y' y 33 3 x'y 1 m( x , y ) Kulzinsky系数 x ' x y ' y 2x ' y 4
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.2 模式相似性的测度和 聚类准则
2.2.2 聚类准则 • 聚类准则函数法
– 一种聚类准则函数J的定义
• J代表了属于c个聚类类别的全部模式样本与其 相应类别模式均值之间的误差平方和。 • 对于不同的聚类形式,J值是不同的。 • 目的:求取使J值达到最小的聚类形式。
2.3 基于试探的聚类搜索算法
• 距离值大,通常可考虑分为不同类
– 聚类域中的样本数目
• 样本数目少且聚类中心距离远,可考虑是否为噪声
– 聚类域内样本的距离方差
• 方差过大的样本可考虑是否属于这一类
• 讨论:模式聚类目前还没有一种通用的放之四 海而皆准的准则,往往需要根据实际应用来选 择合适的方法。
作业
• • 画出ISODATA算法的流程框图 试用ISODATA算法对如下模式分布进 行聚类分析:
2.5.1 K-均值算法
• 思想:基于使聚类性能指标最小化,所 用的聚类准则函数是聚类集中每一个样 本点到该类中心的距离平方之和,并使 其最小化。 • 算法
2.5.1 K-均值算法
• [举例]
– 对如图模式 样本用K-均 值算法进行 分类
2.5.1 K-均值算法
• 讨论
– K-均值算法的结果和效率受如下选择的影响:
• 作业
(选k=2, z1(1)=x1, z2(1)=x10, 用K-均值算法 进行聚类分析)
计算机编程
• 编写K-均值聚类算法程序,对下图所示 数据进行聚类分析(选k=2):
2.5.2 ISODATA算法
• 与K-均值算法的比较
– K-均值算法通常适合于分类数目已知的聚 类,而ISODATA算法则更加灵活; – 从算法角度看, ISODATA算法与K-均值算 法相似,聚类中心都是通过样本均值的迭 代运算来决定的; – ISODATA算法加入了一些试探步骤,并且 可以结合成人机交互的结构,使其能利用 中间结果所取得的经验更好地进行分类。
– 一般化的明氏距离 – 角度相似性函数
• 特点:反映了几何上相似形的特征,对于坐标系的旋转、 放大和缩小等变化是不变的。 • 当特征的取值仅为(0,1)两个值时的特例
量纲对分类的影响(图例)
2.2 模式相似性的测度和 聚类准则
2.2.2 聚类准则 有了模式的相似性测度,还需要一种基 于数值的聚类准则,能将相似的模式样 本分在同一类,相异的模式样本分在不 同的类。 • 试探方法 • 聚类准则函数法
– 连续量的量化:用连续量来度量的特性,如长度、 重量、面积等等,仅需取其量化值; – 量级的数量化:度量时不需要详尽的数值,而是相 应地划分成一些有次序的量化等级的值。
• 病人的病程
– 名义尺度:指定性的指标,即特征度量时没有数量 关系,也没有明显的次序关系,如黑色和白色的关 系,男性和女性的关系等,都可将它们分别用“0” 和“1”来表示。
2.3.1 按最近邻规则的简单试探法 • 算法 • 讨论
– 这种方法的优点:计算简单,若模式样本 的集合分布的先验知识已知,则可通过选 取正确的阈值和起始点,以及确定样本的 选取次序等获得较好的聚类结果。
2.3 基于试探的聚类搜索算法
2.3.1 按最近邻规则的简单试探法 • 讨论(续)
– 在实际中,对于高维模式样本很难获得准确的先 验知识,因此只能选用不同的阈值和起始点来试 探,所以这种方法在很大程度上依赖于以下因素:
• 超过2个状态时,可用多个数值表示。
2.2 模式相似性的测度和 聚类准则
2.2.1 相似性测度
• 目的:为了能将模式集划分成不同的类别,必须定义 一种相似性的测度,来度量同一类样本间的类似性和 不属于同一类样本间的差异性。 – 欧氏距离
• 量纲对分类的影响(下页图例)
– 马氏距离
• 特点:排除了模式样本之间的相关性 • 问题:协方差矩阵在实际应用举例]
– 系统聚类的 树状表示
作业
• • 画出给定迭代次数为n的系统聚类法的 算法流程框图 对如下5个6维模式样本,用最小聚类 准则进行系统聚类分析:
x1: 0, 1, 3, 1, 3, 4 x2: 3, 3, 3, 1, 2, 1 x3: 1, 0, 0, 0, 1, 1 x4: 2, 1, 0, 2, 2, 1 x5: 0, 0, 1, 0, 1, 0
2.5.2 ISODATA算法
• 基本步骤和思路
(1) 选择某些初始值。可选不同的参数指标,也 可在迭代过程中人为修改,以将N个模式样本 按指标分配到各个聚类中心中去。 (2) 计算各类中诸样本的距离指标函数。 (3)~(5)按给定的要求,将前一次获得的聚类集 进行分裂和合并处理((4)为分裂处理, (5)为合并处理),从而获得新的聚类中心。 (6) 重新进行迭代运算,计算各项指标,判断聚 类结果是否符合要求。经过多次迭代后,若 结果收敛,则运算结束。
– 若向量点的分布是一群一群的,同一群样本密集 (距离很近),不同群样本距离很远,则很容易 聚类; – 若样本集的向量分布聚成一团,不同群的样本混 在一起,则很难分类; – 对具体对象做聚类分析的关键是选取合适的特征。 特征选取得好,向量分布容易区分,选取得不好, 向量分布很难分开。
2.1 聚类分析的相关概念
2.5 动态聚类法
• 基本思想
– 首先选择若干个样本点作为聚类中心,再按某种聚 类准则(通常采用最小距离准则)使样本点向各中 心聚集,从而得到初始聚类; – 然后判断初始分类是否合理,若不合理,则修改分 类; – 如此反复进行修改聚类的迭代算法,直至合理为止。
• K-均值算法 • ISODATA算法(迭代自组织数据分析算法)
2.1 聚类分析的相关概念
• 模式相似/分类的依据
把整个模式样本集的特征向量看成是分布在 特征空间中的一些点,点与点之间的距离即 可作为模式相似性的测量依据。
聚类分析是按不同对象之间的差异,根据距 离函数的规律(大小)进行模式分类的。
2.1 聚类分析的相关概念
• 聚类分析的有效性
聚类分析方法是否有效,与模式特征向量的 分布形式有很大关系。
– – – – – 最短距离法 最长距离法 中间距离法 重心法 类平均距离法
2.4 系统聚类法
• [举例]
– 设有6个五维模式样本如下,按最小距离准 则进行聚类分析:
x1: x2: x3: x4: x5: x6: 0, 3, 1, 2, 0 1, 3, 0, 1, 0 3, 3, 0, 0, 1 1, 1, 0, 2, 0 3, 2, 1, 2, 1 4, 1, 1, 1, 0
2.5.2 ISODATA算法
• 算法
• [举例]
– 对如图模 式样本用 ISODATA 算法进行 分类
2.6 聚类结果的评价
• 迅速评价聚类结果,在上述迭代运算中是很重 要的,特别是具有高维特征向量的模式,不能 直接看清聚类效果,因此,可考虑用以下几个 指标来评价聚类效果:
– 聚类中心之间的距离
• • • • 第一个聚类中心的位置 待分类模式样本的排列次序 距离阈值T的大小 样本分布的几何性质
2.3 基于试探的聚类搜索算法
2.3.1 按最近邻规则的简单试探法 • 讨论(续)
– 距离阈值T对聚类结果的影响
2.3 基于试探的聚类搜索算法
2.3.2 最大最小距离算法
• 基本思想:以试探类间欧氏距离为最大 作为预选出聚类中心的条件。
• 降维方法
– 结论:若rij->1,则表明第i维特征与第j维特征所反 映的特征规律接近,因此可以略去其中的一个特 征,或将它们合并为一个特征,从而使维数降低 一维。
2.1 聚类分析的相关概念
• 模式对象特征测量的数字化 计算机只能处理离散的数值,因此根据识别 对象的不同,要进行不同的数据化处理。
2.2 模式相似性的测度和 聚类准则
2.2.2 聚类准则 • 聚类准则函数法
– 依据:由于聚类是将样本进行分类以使类别间可 分离性为最大,因此聚类准则应是反映类别间相 似性或分离性的函数; – 由于类别是由一个个样本组成的,因此一般来说 类别的可分离性和样本的可分离性是直接相关的; – 可以定义聚类准则函数为模式样本集{x}和模式类 别{Sj, j=1,2,…,c}的函数,从而使聚类分析转化为 寻找准则函数极值的最优化问题。
• 两类模式分类的实例:一摊黑白围棋子
– 选颜色作为特征进行分类,用“1”代表白, “0”代表黑,则很容易分类; – 选大小作为特征进行分类,则白子和黑子 的特征相同,不能分类(把白子和黑子分 开)。
2.1 聚类分析的相关概念
• 特征选择的维数
在特征选择中往往会选择一些多余的特征,它增加了 维数,从而增加了聚类分析的复杂度,但对模式分类 却没有提供多少有用的信息。在这种情况下,需要去 掉相关程度过高的特征(进行降维处理)。
2.2 模式相似性的测度和 聚类准则
2.2.2 聚类准则 • 试探方法 凭直观感觉或经验,针对实际问题定义一种 相似性测度的阈值,然后按最近邻规则指定 某些模式样本属于某一个聚类类别。
– 例如对欧氏距离,它反映了样本间的近邻性,但 将一个样本分到不同类别中的哪一个时,还必须 规定一个距离测度的阈值作为聚类的判别准则。
• • • • 所选聚类的数目 聚类中心的初始分布 模式样本的几何性质 读入次序
– 在实际应用中,需要试探不同的K值和选择不同的 聚类中心的起始值。 – 如果模式样本可以形成若干个相距较远的孤立的 区域分布,一般都能得到较好的收敛效果。 – K-均值算法比较适合于分类数目已知的情况。
2.5.1 K-均值算法
{x1(0, 0), x2(3,8), x3(2,2), x4(1,1), x5(5,3), x6(4,8), x7(6,3), x8(5,4), x9(6,4), x10(7,5)}
计算机编程
• 编写ISODATA聚类算法程序,对如下数 据进行聚类分析: {x1(0, 0), x2(3,8), x3(2,2), x4(1,1), x5(5,3), x6(4,8), x7(6,3), x8(5,4), x9(6,4), x10(7,5)}