基于MATLAB的BP神经网络的数字图像识别
基于MATLAB的BP神经网络实现研究

Mirc mp tr pi t n o. 2 N . ,0 6 co o ue l ai sV i2 , o 8 2 0 Ap c o
的 工 具 箱 。 在 神 经 网 络 工 具 箱 中 , 提供 了许 多 有 关 神 经 网 如 它 络 设 计 、 练 和仿 真 的 函数 。 户 只要 根据 自己 的需 要 调 用 相 训 用
图 1 三层 B P网 络 结 构 图
隐 层 输 入 层
输 出层
B 网 络 由正 向 传 播 和 反 向 传 播 组 成 , 正 向 传 播 阶 段 , P 在
和 仿 真 的 函数 和 方 便 、 友好 的 图形 用 户 界 面来 实现 B 网络 , 可 实 时 将 仿 真 结 果 可视 化 , 而 使 应 用B 网络 来 解 决许 多领 域 的 P 还 从 P
实际问题 变得非常方便和有效 。
关 ■ 词 :P 神 经 网 络 I B MATL ABI 真 仿 中 圈 分 类 号 : P13 T 8 文献标识码 : A
每一层神 经元 的状 态只影 响下一层神 经元 的状态 , 若在 输 出 层得不到期望的输 出值 , 则进行 误差的反 向传播 阶段 。 其具体
的学习过程和步骤如 下:
关 的程 序 , 而 免除 了编 写复杂 而庞 大 的算 法程 序 的困扰 。 从
20 0 4年 , MATL AB 的最 新 版本 产 品 MATL 7发 布 。 AB MAT — L 7在 编 程 和 代 码 效 率 、 图 和 可 视 化 、 学 运 算 、 据 读 AB 绘 数 数 写 等 方 面 都 有 了很 大 的 改 进 。
引言
人 工 神 经 网络 ( ric l ua Newok A A t ia Nerl t r , NN) f i 的理 论
用matlab实现数字图像处理几个简单例子

实验报告实验一图像的傅里叶变换(旋转性质)实验二图像的代数运算实验三filter2实现均值滤波实验四图像的缩放朱锦璐04085122实验一图像的傅里叶变换(旋转性质)一、实验内容对图(1.1)的图像做旋转,观察原图的傅里叶频谱和旋转后的傅里叶频谱的对应关系。
图(1.1)二、实验原理首先借助极坐标变换x=rcosθ,y=rsinθ,u=wcosϕ,v=wsinϕ,,将f(x,y)和F(u,v)转换为f(r,θ)和F(w,ϕ).f(x,y) <=> F(u,v)f(rcosθ,rsinθ)<=> F(wcosϕ,wsinϕ)经过变换得f( r,θ+θ。
)<=>F(w,ϕ+θ。
)上式表明,对f(x,y)旋转一个角度θ。
对应于将其傅里叶变换F(u,v)也旋转相同的角度θ。
F(u,v)到f(x,y)也是一样。
三、实验方法及程序选取一幅图像,进行离散傅里叶变换,在对其进行一定角度的旋转,进行离散傅里叶变换。
>> I=zeros(256,256); %构造原始图像I(88:168,120:136)=1; %图像范围256*256,前一值是纵向比,后一值是横向比figure(1);imshow(I); %求原始图像的傅里叶频谱J=fft2(I);F=abs(J);J1=fftshift(F);figure(2)imshow(J1,[5 50])J=imrotate(I,45,'bilinear','crop'); %将图像逆时针旋转45°figure(3);imshow(J) %求旋转后的图像的傅里叶频谱J1=fft2(J);F=abs(J1);J2=fftshift(F);figure(4)imshow(J2,[5 50])四、实验结果与分析实验结果如下图所示(1.2)原图像(1.3)傅里叶频谱(1.4)旋转45°后的图像(1.5)旋转后的傅里叶频谱以下为放大的图(1.6)原图像(1.7)傅里叶频谱(1.8)旋转45°后的图像(1.9)旋转后的傅里叶频谱由实验结果可知1、从旋转性质来考虑,图(1.8)是图(1.6)逆时针旋转45°后的图像,对比图(1.7)和图(1.9)可知,频域图像也逆时针旋转了45°2、从尺寸变换性质来考虑,如图(1.6)和图(1.7)、图(1.8)和图(1.9)可知,原图像和其傅里叶变换后的图像角度相差90°,由此可知,时域中的信号被压缩,到频域中的信号就被拉伸。
基于数字图像识别的算法设计

基于数字图像识别的算法设计作者:吴元林金秀章来源:《电子世界》2013年第17期【摘要】本文以数字识别系统的基本流程为主线,从数据的提取与预处理、特征的提取与选择,到分类器的设计等部分都进行了较为详尽的分析与研究。
着重研究了几个主要的用于分类的算法如最小距离法、近邻法、K-近邻法和BP神经网络,并通过MATLAB仿真实验分析了不同算法的识别率。
为工程应用提供了可靠的理论依据和实际的使用经验。
【关键词】最小距离法;近邻法;K-近邻法;BP神经网络1.引言模式识别是人类的一项基本智能,人们每时每刻都在进行着“模式识别”。
随着计算机技术的普及和发展,让计算机拥有识别能力收到越来越多的研究学者的重视,也是人工智能和机器人技术发展的前提。
模式识别是指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分[1]。
生活中最简单的事物无过于简单的数字0-9,同时,数字在各个方向领域应用广泛,如:车牌识别,邮政编码识别等。
因此,数字字符识别是一项有实际应用的课题。
2.数字识别基本步骤数字识别是通过读取所需识别的数字图片的特征值输入到某个已经定义好的识别算法中进行识别,并输出识别结果,其基本步骤如图2-1所示。
如图2-1所示,数字识别步骤主要有:数据提取、数据预处理、特征值提取和选择以及分类器和分类决策。
下面分别对这几个步骤进行分析。
2.1 数据提取本文所处理的为0-9的灰度图片,总共有400组图片,分为0-9的数字十组,每组40个,分为30个训练样本和10个测试样本。
本文借助matlab软件自带的imread函数和dir函数对“数字”文件夹下的所有图片进行读取,获得一个包含图片数据的36*20*40*10的四维数组。
每幅图片的数据为36*20的数据矩阵。
2.2 预处理图像预处理要根据实际图像进行相应操作,以便使处理时间和正确率两者结合起来。
MATLAB程序代码 bp神经网络通用代码

实用标准文案MATLAB程序代码--bp神经网络通用代码matlab通用神经网络代码学习了一段时间的神经网络,总结了一些经验,在这愿意和大家分享一下,希望对大家有帮助,也希望大家可以把其他神经网络的通用代码在这一起分享感应器神经网络、线性网络、BP神经网络、径向基函数网络%通用感应器神经网络。
P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1 50];%输入向量T=[1 1 0 0 1];%期望输出plotpv(P,T);%描绘输入点图像net=newp([-40 1;-1 50],1);%生成网络,其中参数分别为输入向量的范围和神经元感应器数量hold onlinehandle=plotpc(net.iw{1},net.b{1});net.adaptparam.passes=3;for a=1:25%训练次数[net,Y,E]=adapt(net,P,T);linehandle=plotpc(net.iw{1},net.b{1},linehandle);drawnow;end%通用newlin程序%通用线性网络进行预测time=0:0.025:5;T=sin(time*4*pi);Q=length(T);P=zeros(5,Q);%P中存储信号T的前5(可变,根据需要而定)次值,作为网络输入。
精彩文档.实用标准文案P(1,2:Q)=T(1,1:(Q-1));P(2,3:Q)=T(1,1:(Q-2));P(3,4:Q)=T(1,1:(Q-3));P(4,5:Q)=T(1,1:(Q-4));P(5,6:Q)=T(1,1:(Q-5));plot(time,T)%绘制信号T曲线xlabel('时间');ylabel('目标信号');title('待预测信号');net=newlind(P,T);%根据输入和期望输出直接生成线性网络a=sim(net,P);%网络测试figure(2)plot(time,a,time,T,'+')xlabel('时间');ylabel('输出-目标+');title('输出信号和目标信号');e=T-a;figure(3)plot(time,e)hold onplot([min(time) max(time)],[0 0],'r:')%可用plot(x,zeros(size(x)),'r:')代替hold offxlabel('时间');ylabel('误差');精彩文档.实用标准文案title('误差信号');%通用BP神经网络P=[-1 -1 2 2;0 5 0 5];t=[-1 -1 1 1];net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingd');%输入参数依次为:'样本P范围',[各层神经元数目],{各层传递函数},'训练函数'%训练函数traingd--梯度下降法,有7个训练参数.%训练函数traingdm--有动量的梯度下降法,附加1个训练参数mc(动量因子,缺省为0.9)%训练函数traingda--有自适应lr的梯度下降法,附加3个训练参数:lr_inc(学习率增长比,缺省为1.05;% lr_dec(学习率下降比,缺省为0.7);max_perf_inc(表现函数增加最大比,缺省为1.04)%训练函数traingdx--有动量的梯度下降法中赋以自适应lr的方法,附加traingdm和traingda的4个附加参数%训练函数trainrp--弹性梯度下降法,可以消除输入数值很大或很小时的误差,附加4个训练参数:% delt_inc(权值变化增加量,缺省为1.2);delt_dec(权值变化减小量,缺省为0.5);% delta0(初始权值变化,缺省为0.07);deltamax(权值变化最大值,缺省为50.0)% 适合大型网络%训练函数traincgf--Fletcher-Reeves共轭梯度法;训练函数traincgp--Polak-Ribiere共轭梯度法;%训练函数traincgb--Powell-Beale共轭梯度法%共轭梯度法占用存储空间小,附加1训练参数searchFcn(一维线性搜索方法,缺省为srchcha);缺少1个训练参数lr %训练函数trainscg--量化共轭梯度法,与其他共轭梯度法相比,节约时间.适合大型网络% 附加2个训练参数:sigma(因为二次求导对权值调整的影响参数,缺省为5.0e-5);% lambda(Hessian阵不确定性调节参数,缺省为5.0e-7)% 缺少1个训练参数:lr精彩文档.实用标准文案%训练函数trainbfg--BFGS拟牛顿回退法,收敛速度快,但需要更多内存,与共轭梯度法训练参数相同,适合小网络%训练函数trainoss--一步正割的BP训练法,解决了BFGS消耗内存的问题,与共轭梯度法训练参数相同%训练函数trainlm--Levenberg-Marquardt训练法,用于内存充足的中小型网络net=init(net);net.trainparam.epochs=300; %最大训练次数(前缺省为10,自trainrp后,缺省为100)net.trainparam.lr=0.05; %学习率(缺省为0.01)net.trainparam.show=50; %限时训练迭代过程(NaN表示不显示,缺省为25)net.trainparam.goal=1e-5; %训练要求精度(缺省为0)%net.trainparam.max_fail 最大失败次数(缺省为5)%net.trainparam.min_grad 最小梯度要求(前缺省为1e-10,自trainrp后,缺省为1e-6)%net.trainparam.time 最大训练时间(缺省为inf)[net,tr]=train(net,P,t); %网络训练a=sim(net,P) %网络仿真%通用径向基函数网络——%其在逼近能力,分类能力,学习速度方面均优于BP神经网络%在径向基网络中,径向基层的散步常数是spread的选取是关键%spread越大,需要的神经元越少,但精度会相应下降,spread的缺省值为1%可以通过net=newrbe(P,T,spread)生成网络,且误差为0%可以通过net=newrb(P,T,goal,spread)生成网络,神经元由1开始增加,直到达到训练精度或神经元数目最多为止%GRNN网络,迅速生成广义回归神经网络(GRNN)P=[4 5 6];T=[1.5 3.6 6.7];精彩文档.实用标准文案net=newgrnn(P,T);%仿真验证p=4.5;v=sim(net,p)%PNN网络,概率神经网络P=[0 0 ;1 1;0 3;1 4;3 1;4 1;4 3]';Tc=[1 1 2 2 3 3 3];%将期望输出通过ind2vec()转换,并设计、验证网络T=ind2vec(Tc);net=newpnn(P,T);Y=sim(net,P);Yc=vec2ind(Y)%尝试用其他的输入向量验证网络P2=[1 4;0 1;5 2]';Y=sim(net,P2);Yc=vec2ind(Y)%应用newrb()函数构建径向基网络,对一系列数据点进行函数逼近P=-1:0.1:1;T=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...0.1336 -0.2013 -0.4344 -0.500 -0.3930 -0.1647 -0.0988...0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201];%绘制训练用样本的数据点plot(P,T,'r*');title('训练样本');精彩文档.实用标准文案xlabel('输入向量P');ylabel('目标向量T');%设计一个径向基函数网络,网络有两层,隐层为径向基神经元,输出层为线性神经元%绘制隐层神经元径向基传递函数的曲线p=-3:.1:3;a=radbas(p);plot(p,a)title('径向基传递函数')xlabel('输入向量p')%隐层神经元的权值、阈值与径向基函数的位置和宽度有关,只要隐层神经元数目、权值、阈值正确,可逼近任意函数%例如a2=radbas(p-1.5);a3=radbas(p+2);a4=a+a2*1.5+a3*0.5;plot(p,a,'b',p,a2,'g',p,a3,'r',p,a4,'m--')title('径向基传递函数权值之和')xlabel('输入p');ylabel('输出a');%应用newrb()函数构建径向基网络的时候,可以预先设定均方差精度eg以及散布常数sceg=0.02;sc=1; %其值的选取与最终网络的效果有很大关系,过小造成过适性,过大造成重叠性net=newrb(P,T,eg,sc);%网络测试精彩文档.实用标准文案plot(P,T,'*')xlabel('输入');X=-1:.01:1;Y=sim(net,X);hold onplot(X,Y);hold offlegend('目标','输出')%应用grnn进行函数逼近P=[1 2 3 4 5 6 7 8];T=[0 1 2 3 2 1 2 1];plot(P,T,'.','markersize',30)axis([0 9 -1 4])title('待逼近函数')xlabel('P')ylabel('T')%网络设计%对于离散数据点,散布常数spread选取比输入向量之间的距离稍小一些spread=0.7;net=newgrnn(P,T,spread);%网络测试A=sim(net,P);hold onoutputline=plot(P,A,'o','markersize',10,'color',[1 0 0]);精彩文档.实用标准文案title('检测网络')xlabel('P')ylabel('T和A')%应用pnn进行变量的分类P=[1 2;2 2;1 1]; %输入向量Tc=[1 2 3]; %P对应的三个期望输出%绘制出输入向量及其相对应的类别plot(P(1,:),P(2,:),'.','markersize',30)for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Tc(i)))endaxis([0 3 0 3]);title('三向量及其类别')xlabel('P(1,:)')ylabel('P(2,:)')%网络设计T=ind2vec(Tc);spread=1;net=newgrnn(P,T,speard);%网络测试A=sim(net,P);Ac=vec2ind(A);%绘制输入向量及其相应的网络输出plot(P(1,:),P(2,:),'.','markersize',30)精彩文档.实用标准文案for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Ac(i)))endaxis([0 3 0 3]);title('网络测试结果')xlabel('P(1,:)')ylabel('P(2,:)')P=[13, 0, 1.119, 1, 26.3;22, 0, 1.135, 1, 26.3;-15, 0, 0.9017, 1, 20.4;-30, 0, 0.9172, 1, 26.7;24,0,1.238,0.9704,28.2;3,24,1.119,1,26.3;0,52,1.089,1,26.3;0,-73,1.0889,1,26.3;1,28,0.8748,1,2 6.3;-1,-39,1.1168,1,26.7;-2, 0, 1.495, 1, 26.3;0, -1, 1.438, 1, 26.3;4, 1,0.4964,0.9021, 26.3;3, -1, 0.5533, 1.2357, 26.7;-5, 0, 1.7368, 1, 26.7;1, 0, 1.1045, 0.0202,26.3;-2, 0, 1.1168, 1.3764, 26.7;-3, -1, 1.1655, 1.4418,27.5;3, 2, 1.0875, 0.748, 27.5;-3, 0, 1.1068, 2.2092, 26.3;4, 1, 0.9017, 1, 13.7;3, 2, 0.9017, 1, 14.9;-3, 1, 0.9172, 1, 13.7;-2, 0, 1.0198, 1.0809, 16.1;0, 1, 0.9172, 1, 13.7]T=[1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1 ];%期望输出plotpv(P,T);%描绘输入点图像精彩文档.。
matlab数字图像处理实验报告

《数字图像处理实验报告》实验一图像的增强一.实验目的1.熟悉图像在MATLAB下的读写、输出;2.熟悉直方图;3.熟悉图像的线性指数等;4.熟悉图像的算术运算和几何变换。
二.实验仪器计算机、MATLAB软件三.实验原理图像增强是指根据特定的需要突出图像中的重要信息,同时减弱或去除不需要的信息。
从不同的途径获取的图像,通过进行适当的增强处理,可以将原本模糊不清甚至根本无法分辨的原始图像处理成清晰的富含大量有用信息的可使用图像。
其基本原理是:对一幅图像的灰度直方图,经过一定的变换之后,使其成为均匀或基本均匀的,即使得分布在每一个灰度等级上的像素个数.f=H等或基本相等。
此方法是典刑的图像空间域技术处理,但是由于灰度直方图只是近似的概率密度函数,因此,当用离散的灰度等级做变换时,很难得到完全平坦均匀的结果。
频率域增强技术频率域增强是首先将图像从空间与变换到频域,然后进行各种各样的处理,再将所得到的结果进行反变换,从而达到图像处理的目的。
常用的变换方法有傅里叶变换、DCT变换、沃尔什-哈达玛变换、小波变换等。
假定原图像为f(x,y),经傅立叶变换为F(u,v)。
频率域增强就是选择合适的滤波器H(u,v)对F(u,v)的频谱成分进行处理,然后经逆傅立叶变换得到增强的图像。
四.实验内容及步骤1.图像在MATLAB下的读写、输出;实验过程:>> I = imread('F:\image\');figure;imshow(I);title('Original Image');text(size(I,2),size(I,1)+15, ...'', ...'FontSize',7,'HorizontalAlignment','right');Warning: Image is too big to fit on screen; displaying at 25% > In imuitools\private\initSize at 86In imshow at 1962.给定函数的累积直方图。
BP神经网络matlab教程
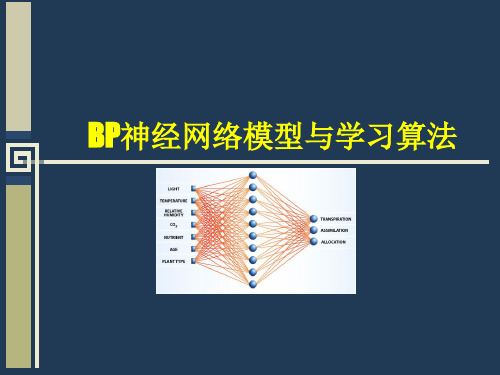
w
N 1 ho
w o (k )hoh (k )
N ho
2.4.2 BP网络的标准学习算法
第七步,利用隐含层各神经元的 h (k )和 输入层各神经元的输入修正连接权。
e e hih (k ) wih (k ) h (k ) xi (k ) wih hih (k ) wih w
p
i 1
h 1,2,
o 1,2,
,p
q
yio (k ) whohoh (k ) bo
o 1,2,
yoo (k ) f( yio (k ))
h 1
q
2.4.2 BP网络的标准学习算法
第四步,利用网络期望输出和实际输出, 计算误差函数对输出层的各神经元的偏导 o (k ) 数 。 ( w ho (k ) b ) e e yio yi (k )
输入样本---输入层---各隐层---输出层
判断是否转入反向传播阶段:
若输出层的实际输出与期望的输出(教师信号)不 符
误差反传
误差以某种形式在各层表示----修正各层单元 的权值
网络输出的误差减少到可接受的程度 进行到预先设定的学习次数为止
2.4.2 BP网络的标准学习算法
网络结构 输入层有n个神经元,隐含层有p个神经元, 输出层有q个神经元 变量定义 x x1, x2 , , xn 输入向量; 隐含层输入向量; hi hi1 , hi2 , , hi p 隐含层输出向量; ho ho1 , ho2 , , ho p 输出层输入向量; yi yi1 , yi2 , , yiq 输出层输出向量; yo yo1 , yo2 , , yoq 期望输出向量; d o d1 , d 2 , , d q
PSO优化的BP神经网络(Matlab版)

PSO优化的BP神经⽹络(Matlab版)前⾔:最近接触到⼀些神经⽹络的东西,看到很多⼈使⽤PSO(粒⼦群优化算法)优化BP神经⽹络中的权值和偏置,经过⼀段时间的研究,写了⼀些代码,能够跑通,嫌弃速度慢的可以改⼀下训练次数或者适应度函数。
在我的理解⾥,PSO优化BP的初始权值w和偏置b,有点像数据迁徙,等于⽤粒⼦去尝试作为⽹络的参数,然后训练⽹络的阈值,所以总是会看到PSO优化了权值和阈值的说法,(⼀开始我是没有想通为什么能够优化阈值的),下⾯是我的代码实现过程,关于BP和PSO的原理就不⼀⼀赘述了,⽹上有很多⼤佬解释的很详细了……⾸先是利⽤BP作为适应度函数function [error] = BP_fit(gbest,input_num,hidden_num,output_num,net,inputn,outputn)%BP_fit 此函数为PSO的适应度函数% gbest:最优粒⼦% input_num:输⼊节点数⽬;% output_num:输出层节点数⽬;% hidden_num:隐含层节点数⽬;% net:⽹络;% inputn:⽹络训练输⼊数据;% outputn:⽹络训练输出数据;% error : ⽹络输出误差,即PSO适应度函数值w1 = gbest(1:input_num * hidden_num);B1 = gbest(input_num * hidden_num + 1:input_num * hidden_num + hidden_num);w2 = gbest(input_num * hidden_num + hidden_num + 1:input_num * hidden_num...+ hidden_num + hidden_num * output_num);B2 = gbest(input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:...input_num * hidden_num + hidden_num + hidden_num * output_num + output_num);net.iw{1,1} = reshape(w1,hidden_num,input_num);net.lw{2,1} = reshape(w2,output_num,hidden_num);net.b{1} = reshape(B1,hidden_num,1);net.b{2} = B2';%建⽴BP⽹络net.trainParam.epochs = 200;net.trainParam.lr = 0.05;net.trainParam.goal = 0.000001;net.trainParam.show = 100;net.trainParam.showWindow = 0;net = train(net,inputn,outputn);ty = sim(net,inputn);error = sum(sum(abs((ty - outputn))));end 然后是PSO部分:%%基于多域PSO_RBF的6R机械臂逆运动学求解的研究clear;close;clc;%定义BP参数:% input_num:输⼊层节点数;% output_num:输出层节点数;% hidden_num:隐含层节点数;% inputn:⽹络输⼊;% outputn:⽹络输出;%定义PSO参数:% max_iters:算法最⼤迭代次数% w:粒⼦更新权值% c1,c2:为粒⼦群更新学习率% m:粒⼦长度,为BP中初始W、b的长度总和% n:粒⼦群规模% gbest:到达最优位置的粒⼦format longinput_num = 3;output_num = 3;hidden_num = 25;max_iters =10;m = 500; %种群规模n = input_num * hidden_num + hidden_num + hidden_num * output_num + output_num; %个体长度w = 0.1;c1 = 2;c2 = 2;%加载⽹络输⼊(空间任意点)和输出(对应关节⾓的值)load('pfile_i2.mat')load('pfile_o2.mat')% inputs_1 = angle_2';inputs_1 = inputs_2';outputs_1 = outputs_2';train_x = inputs_1(:,1:490);% train_y = outputs_1(4:5,1:490);train_y = outputs_1(1:3,1:490);test_x = inputs_1(:,491:500);test_y = outputs_1(1:3,491:500);% test_y = outputs_1(4:5,491:500);[inputn,inputps] = mapminmax(train_x);[outputn,outputps] = mapminmax(train_y);net = newff(inputn,outputn,25);%设置粒⼦的最⼩位置与最⼤位置% w1阈值设定for i = 1:input_num * hidden_numMinX(i) = -0.01*ones(1);MaxX(i) = 3.8*ones(1);end% B1阈值设定for i = input_num * hidden_num + 1:input_num * hidden_num + hidden_numMinX(i) = 1*ones(1);MaxX(i) = 8*ones(1);end% w2阈值设定for i = input_num * hidden_num + hidden_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_numMinX(i) = -0.01*ones(1);MaxX(i) = 3.8*ones(1);end% B2阈值设定for i = input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_num + output_num MinX(i) = 1*ones(1);MaxX(i) = 8*ones(1);end%%初始化位置参数%产⽣初始粒⼦位置pop = rands(m,n);%初始化速度和适应度函数值V = 0.15 * rands(m,n);BsJ = 0;%对初始粒⼦进⾏限制处理,将粒⼦筛选到⾃定义范围内for i = 1:mfor j = 1:input_num * hidden_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num + 1:input_num * hidden_num + hidden_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num + hidden_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_num + output_num if pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendend%评估初始粒⼦for s = 1:mindivi = pop(s,:);fitness = BP_fit(indivi,input_num,hidden_num,output_num,net,inputn,outputn);BsJ = fitness; %调⽤适应度函数,更新每个粒⼦当前位置Error(s,:) = BsJ; %储存每个粒⼦的位置,即BP的最终误差end[OderEr,IndexEr] = sort(Error);%将Error数组按升序排列Errorleast = OderEr(1); %记录全局最⼩值for i = 1:m %记录到达当前全局最优位置的粒⼦if Error(i) == Errorleastgbest = pop(i,:);break;endendibest = pop; %当前粒⼦群中最优的个体,因为是初始粒⼦,所以最优个体还是个体本⾝for kg = 1:max_iters %迭代次数for s = 1:m%个体有52%的可能性变异for j = 1:n %粒⼦长度for i = 1:m %种群规模,变异是针对某个粒⼦的某⼀个值的变异if rand(1)<0.04pop(i,j) = rands(1);endendend%r1,r2为粒⼦群算法参数r1 = rand(1);r2 = rand(1);%个体位置和速度更新V(s,:) = w * V(s,:) + c1 * r1 * (ibest(s,:)-pop(s,:)) + c2 * r2 * (gbest(1,:)-pop(s,:));pop(s,:) = pop(s,:) + 0.3 * V(s,:);%对更新的位置进⾏判断,超过设定的范围就处理下。
MATLAB在图像识别与处理中的应用案例

MATLAB在图像识别与处理中的应用案例图像识别与处理是计算机视觉领域的重要研究方向,它的应用广泛涉及到人脸识别、目标检测、医学图像处理等众多领域。
而MATLAB作为一种强大的工具箱,提供了丰富的图像处理与机器学习算法,成为学术界和工业界广泛使用的工具。
本文将通过几个应用案例,介绍MATLAB在图像识别与处理中的典型应用。
一、人脸识别人脸识别是近年来备受关注的研究领域,它在安防、刑侦、身份验证等方面发挥着重要作用。
而MATLAB提供了强大的图像处理和模式识别算法,可以帮助实现人脸识别功能。
其中,主成分分析(PCA)和线性判别分析(LDA)是常用的人脸识别算法之一。
以PCA为例,其主要思想是通过降维技术将高维图像数据映射到低维空间,然后利用训练样本的统计特性建立模型,并通过计算待识别人脸与模型之间的距离来进行识别。
通过MATLAB的图像处理工具箱,可以提取图像的特征,进而进行人脸识别。
此外,MATLAB还提供了许多其他的人脸识别算法,如基于支持向量机(SVM)和卷积神经网络(CNN)等,可以根据具体需求选择适合的算法。
二、目标检测目标检测是计算机视觉中另一个重要的研究领域,其在自动驾驶、智能监控等方面有着广泛的应用。
而MATLAB提供了强大的图像处理和深度学习工具箱,可以帮助实现目标检测功能。
其中,基于特征的方法和基于深度学习的方法是目标检测的两种常用方法。
基于特征的方法中,常用的算法有Haar特征和HOG(方向梯度直方图)特征。
MATLAB提供了相应的函数和工具箱,可以方便地提取图像的特征,并结合分类器进行目标检测。
基于深度学习的方法中,常用的算法有Fast R-CNN、YOLO (You Only Look Once)和SSD(Single Shot MultiBox Detector)等。
通过MATLAB的深度学习工具箱,可以进行模型训练和预测,实现准确高效的目标检测。
三、医学图像处理医学图像处理是医学影像学领域的核心技术之一,对于疾病的诊断和治疗具有重要意义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于MATLAB BP神经网络的数字图像识别 基于MATLAB BP神经网络的数字图像识别 【摘要】 随着现代社会的发展,信息的形式和数量正在迅猛增长。其中很大一部分是图像,图像可以把事物生动的呈现在我们面前,让我们更直观地接受信息。同时,计算机已经作为一种人们普遍使用的工具为人们的生产生活服务。如今我们也可以把这些技术应用在交通领域。作为智能交通系统(InteUigent Traffic System,简称ITS)中的一个重要组成部分的车牌识别技术,当然就是其中的重点研究对象。车辆牌照识别(License P1ate Recognition,简称LPR),是一种关于计算机的包括图像处理、数学技术、数据库、信息技术以及智能技术于一体的综合技术。用MATLAB做车牌识别比用其他工具有许多优势,因为MATLAB在图像的灰度化、二值化、滤波等方面都有很大优势,所以,本次实验我们利用MATLAB的这些优点来对车牌进行识别。 【关键词】BP神经网络;图像识别;字符识别;特征提取;车牌;Matlab 一 课题研究背景
(一) 图像识别的提出及应用 随着信息化时代的不断发展,人们越来越多地使用信息化的手段来解决各种问题——办公自动化、先进制造业、电子商务等利用计算机技术而产生的新兴行业正不断靠近我们的生活。在信息社会中,我们每天都接触大量的数据——工作数据、个人数据、无意间获得的数据等——在这些数据中,有些数据需要我们人工处理,而有些则可以利用计算机快速准确的完成——字符识别就是其中的一个范畴。 字符识别是一种图像识别技术,他的输入是一张带有某种字符的图片,而输出则是计算机中对于图片中字符的反应结果。所以,可以广泛的应用于各种领域:如,车牌检测、手写识别、自动阅读器、机器视觉……在生活生产的各个方面都起到了非常重要的作用。 (二)图像识别技术的发展趋势 虽然图像识别技术还不是非常成熟,但现其已经有了很多可喜的成果,比如图像模式识别,图像文字识别。并且其还在飞速的发展着,图像识别的应用正朝着不同的领域渗透着,像计算机图像生成,图像传输与图像通信,高清晰度电视,机器人视觉及图像测量,办公室自动化,像跟踪及光学制导 ,医用图像处理与材料分析中的图像分析系统,遥感图像处理和空间探测,图像变形技术等等。从所列举的图像技术的多方面应用及其理论基础可以看出,它们无一不涉及高科技的前沿课题,充分说明了图像技术是前沿性与基础性的有机统一。 可以预计21世纪,图像技术将经历一个飞跃发展的成熟阶段,为深入人民生活创造新的文化环境,成为提高生产的自动化、智能化水平的基础科学之一。图像技术的基础性研究,特别是结合人工智能与视觉处理的新算法,从更高水平提取图像信息的丰富内涵,成为人类运算量最大、直观性最强,与现实世界直接联系的视觉和“形象思维”这一智能的模拟和复现,是一个很难而重要的任务。“图像技术”这一上世纪后期诞生的高科技之花,其前途是不可限量的。 随着21世纪经济全球化和信息时代的发展,作为信息来源的自动检测、图像识别技术越来越受到人们的重视。近年来计算机的飞速发展和数字图像处理技术的日趋成熟,为传统的交通管理带来了巨大转变。图像处理技术发展相当快,而其中对汽车牌照等相关信息的自动采集和管理对于交通车辆管理、园区车辆管理、停车场管理、交警稽查等方面有着十分重要的意义,成为信息处理技术的一项重要研究课题。汽车牌照自动识别系统就是在这样的背景与目的下进行研究开发的。车辆牌照识别(License Plate Recognition,
LPR)技术作为交通管理自动化的重要手段之一,其任务是分析、处理汽车监控图像,自动识别汽车牌照号码,并进行相关智能化数据库管理。 (三)图像识别的机理 图像识别是人工智能的一个重要领域。为了编制模拟人类图像识别活动的计算机程序,人们提出了不同的图像识别模型。例如模板匹配模型。这种模型认为,识别某个图像,必须在过去的经验中有这个图像的记忆模式,又叫模板。当前的刺激如果能与大脑中的模板相匹配,这个图像也就被识别了。例如有一个字母A,如果在脑中有个A模板,字母A的大小、方位、形状都与这个A模板完全一致,字母A就被识别了。这个模型简单明了,也容易得到实际应用。但这种模型强调图像必须与脑中的模板完全符合才能加以识别,而事实上人不仅能识别与脑中的模板完全一致的图像,也能识别与模板不完全一致的图像。例如,人们不仅能识别某一个具体的字母A,也能识别印刷体的、手写体的、方向不正、大小不同的各种字母A。同时,人能识别的图像是大量的,如果所识别的每一个图像在脑中都有一个相应的模板,也是不可能的。为了解决模板匹配模型存在的问题,格式塔心理学家又提出了一个原型匹配模型。这种模型认为,在长时记忆中存储的并不是所要识别的无数个模板,而是图像的某些“相似性”。从图像中抽象出来的“相似性”就可作为原型,拿它来检验所要识别的图像。如果能找到一个相似的原型,这个图像也就被识别了。这种模型从神经上和记忆探寻的过程上来看,都比模板匹配模型更适宜,而且还能说明对一些不规则的,但某些方面与原型相似的图像的识别。但是,这种模型没有说明人是怎样对相似的“刺激”进行辨别和加工的,它也难以在计算机程序中得到实现。因此又有人提出了一个更复杂的模型,即“泛魔”识别模型。 所谓泛魔,即这个模型把图像识别过程分为不同的层次,每一层次都有承担不同职责的特征分析机制称作一种"小魔鬼",由于有许许多多这样的机制在起作用,因此叫做“泛魔”识别模型。这一模型的特点在于它的层次的划分。 自20世纪60年代初期出现第一代产品开始,经过30多年的不断发展改进,字符识别技术的研究已经取得了令人瞩目的成果。目前印刷体的识别技术已经达到较高水平。识别范围也从原来指定的印刷体数字、英文字母和部分符号,发展成为可以自动进行版面分析、表格识别,实现混合文字、多字体、多字号、横竖混排识别的强大的计算机信息快速录入工具。对印刷体汉字的识别率达到98%以上,即使对印刷质量较差的文字其识别率也达到95%以上。 (四)本文的研究内容 本文将以车牌作为研究对象,从数字、字母、汉字开始逐步提高识别的范围,针对图片中的字符提出一套切实可行的识别算法,并且在试验中不断改进。在开发期间,以功能强大的Matlab作为编程平台,利用一些行之有效的技术提高识别算法的性能,从而完成相应的识别软件。 二 算法分析与设计 (一)特征分析 中国汽车牌照中使用的字符集包括59个汉字、25个大写英文字母(字母不包含I)和10个阿拉伯数(0-9),三种类型共94个,且都是印刷体,结构固定、笔画规范。牌照在图像中占有的高度从20个像素到50个像素不等。对于国内牌照来说,一般的车辆正面牌照中水平排列着7个字符,其标准车牌样式:XlX2·X3X4X5X6X7;X1是各省,直辖市的简称:如“苏” 、“桂”,或者特种车辆类型如“警”;X2是英文字母,表示各省的不同地区;X3从是英文字母或阿拉伯数字; X3X4X5X6X7均是阿拉伯数字。 (二)技术路线 1 原理分析 由于车辆牌照是机动车唯一的管理标识符号,在交通管理中具有不可替代的作用,因此车辆牌照识别系统应具有很高的识别正确率,对环境光照条件、拍摄位置和车辆行驶速度等因素的影响应有较大的容阈,并且要求满足实时性要求。
图2-1 牌照识别系统原理图 该系统是计算机图像处理与字符识别技术在智能化交通管理系统中的应用,它主要由牌照图像的采集和预处理、牌照区域的定位和提取、牌照字符的分割和识别等几个部分组成,如图1所示。其基本工作过程如下: (1)当行驶的车辆经过时,触发埋设在固定位置的传感器,系统被唤醒处于工作状态;一旦连接摄像头光快门的光电传感器被触发,设置在车辆前方、后方和侧面的相机同时拍摄下车辆图像; (2)由摄像机或CCD摄像头拍摄的含有车辆牌照的图像通视频卡输入计算机进行预处理,图像预处理包括图像转换、图像增强、滤波和水平矫正等; (3)由检索模块进行牌照搜索与检测,定位并分割出包含牌照字符号码的矩形区域; (4)对牌照字符进行二值化并分割出单个字符,经归一化后输入字符识别系统进行识别。 2 总体设计方案 车辆牌照识别整个系统主要是由车牌定位和字符识别两部分组成,其中车牌定位又可以分为图像预处理及边缘提取模块和牌照的定位及分割模块;字符识别可以分为字符分割与特征提取和单个字符识别两个模块。 为了用于牌照的分割和牌照字符的识别,原始图像应具有适当的亮度,较大的对比度和清晰可辩的牌照图像。但由于该系统的摄像部分工作于开放的户外环境,加之车辆牌照的整洁度、自然光照条件、拍摄时摄像机与牌照的距离和角度以及车辆行驶速度等因素的影响,
区域搜索与分割 字符分割 归一化 字符特征提取 单字识别 图像输入 预处理 牌照图像可能出现模糊、歪斜和缺损等严重缺陷,因此需要对原始图像进行识别前的预处理。 牌照的定位和分割是牌照识别系统的关键技术之一,其主要目的是在经图像预处理后的原始灰度图像中确定牌照的具体位置,并将包含牌照字符的一块子图像从整个图像中分割出来,供字符识别子系统识别之用,分割的准确与否直接关系到整个牌照字符识别系统的识别率。 由于拍摄时的光照条件、牌照的整洁程度的影响,和摄像机的焦距调整、镜头的光学畸变所产生的噪声都会不同程度地造成牌照字符的边界模糊、细节不清、笔划断开或粗细不均,加上牌照上的污斑等缺陷,致使字符提取困难,进而影响字符识别的准确性。因此,需要对字符在识别之前再进行一次针对性的处理。 车牌识别的最终目的就是对车牌上的文字进行识别。主要应用的为模板匹配方法。 因为系统运行的过程中,主要进行的都是图像处理,在这个过程中要进行大量的数据处理,所以处理器和内存要求比较高,CPU要求主频在600HZ及以上,内存在128MB及以上。系统可以运行于Windows98、Windows2000或者Windows XP操作系统下,程序调试时使用matlab。 三 具体技术路线 (1)图像预处理及边缘提取 在车牌自动识别系统中,车辆图像是通过图像采集卡将运动的车辆图像抓拍下来,并以位图的格式存放到系统内存中,这时的车辆数字图像虽然没有被人为损伤过,但在实际道路上行驶的车辆常会因为各种各样的原因使得所拍摄的车辆图像效果不理想,如外界光线对车牌的不均匀反射、极强阳光形成的车牌处阴影、摄像机快门值设置过大而引起的车辆图像拖影、摄像头聚焦或后背焦没有调整到位而形成的车辆图像不清晰、由于视频传输线而引起的图像质量下降、所拍摄图像中存在的噪声干扰、所安装的车牌不规范或车辆行驶变形等,这些都给车牌的模糊识别增加了难度。图像预处理技术可最大限度提高车牌正确识别率,这些图像预处理包括图像灰度化、平滑、倾斜校正、灰度修正等。