SPS回归分析
简单易懂的SPSS回归分析基础教程

简单易懂的SPSS回归分析基础教程章节一:SPSS回归分析基础概述SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)回归分析是一种常用的统计方法,用于研究自变量对因变量的影响程度以及变量之间的关系。
本章将介绍SPSS回归分析的基本概念和目的,以及相关的统计指标。
SPSS回归分析的目的是建立一个数学模型,描述自变量与因变量之间的关系。
通过这个模型,我们可以预测因变量的变化,以及各个自变量对因变量的贡献程度。
回归分析包括简单回归分析和多元回归分析,本教程主要讲解简单回归分析。
在SPSS回归分析中,我们需要了解一些统计指标。
其中,相关系数(correlation coefficient)用于衡量自变量与因变量之间的线性关系强度。
回归系数(regression coefficient)描述自变量对因变量的影响程度,可用于建立回归方程。
残差(residual)表示实际观测值与回归模型预测值之间的差异。
下面我们将详细介绍SPSS回归分析的步骤。
章节二:数据准备和导入在进行SPSS回归分析之前,我们需要准备好数据集,并将数据导入SPSS软件。
首先,我们需要确定因变量和自变量的测量水平。
因变量可以是连续型数据,如身高、体重等,也可以是分类数据,如满意度水平等。
自变量可以是任何与因变量相关的变量,包括连续型、分类型或二元变量。
其次,我们需要收集足够的样本量,以获取准确和可靠的结果。
在选择样本时,应该遵循随机抽样的原则,以保证样本的代表性。
最后,我们将数据导入SPSS软件。
通过依次点击“File”、“Open”、“Data”,选择数据文件,并设置变量类型、名称和标签等信息。
完成数据导入后,我们就可以开始进行回归分析了。
章节三:简单回归分析步骤简单回归分析是一种研究一个自变量与一个因变量之间关系的方法。
下面将介绍简单回归分析的步骤。
第一步,我们需要确定自变量和因变量。
spss回归分析

第八章回归分析回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。
回归分析就是用于说明这种依存变化的数学关系。
第一节Linear过程8.1.1 主要功能调用此过程可完成二元或多元的线性回归分析。
在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。
8.1.2 实例操作[例8.1]某医师测得10名3岁儿童的身高(cm)、体重(kg)和体表面积(cm2)资料如下。
试用多元回归方法确定以身高、体重为自变量,体表面积为应变量的回归方程。
8.1.2.1 数据准备激活数据管理窗口,定义变量名:体表面积为Y,保留3位小数;身高、体重分别为X1、X2,1位小数。
输入原始数据,结果如图8.1所示。
图8.1 原始数据的输入8.1.2.2 统计分析激活Statistics菜单选Regression中的Linear...项,弹出Linear Regression对话框(如图8.2示)。
从对话框左侧的变量列表中选y,点击 钮使之进入Dependent框,选x1、x2,点击 钮使之进入Indepentdent(s)框;在Method处下拉菜单,共有5个选项:Enter(全部入选法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)。
本例选用Enter法。
点击OK钮即完成分析。
图8.2 线性回归分析对话框用户还可点击Statistics...钮选择是否作变量的描述性统计、回归方程应变量的可信区间估计等分析;点击Plots...钮选择是否作变量分布图(本例要求对标准化Y预测值作变量分布图);点击Save...钮选择对回归分析的有关结果是否作保存(本例要求对根据所确定的回归方程求得的未校正Y预测值和标准化Y预测值作保存);点击Options...钮选择变量入选与剔除的α、β值和缺失值的处理方法。
spss多元回归分析结果解读

spss多元回归分析结果解读
多元回归分析是一种有益的研究方法,用于研究一个自变量对一种可能多个因素的因变量的影响。
它可以帮助研究人员在复杂的环境中有效地研究变量间的关系,为研究者提供有用的信息。
本文将对SPSS中多元回归分析结果作出解释。
多元回归分析结果包括模型概览、系数表和诊断统计量等。
从模型概览中,可以查看回归的R平方,它代表模型对因变量的解释能力。
另外,如果均方根误差
很小,也可以推断模型具有很好的预测能力。
在系数表中,可以查看每个自变量对因变量的贡献,去查看比较有重要性的变量及它们的系数值。
其中,系数值大小代表着自变量对因变量的影响程度,正负系数代表自变量与因变量之间的负相关或正相关性。
根据系数值,可以得出相关结论,即哪些变量对因变量的影响有重要性,而哪些变量的影响力不大。
此外,诊断统计量给出了模型建立的质量评估。
比如偏差平方,它衡量误差值之平方和占比。
如果拟合度评估值很低,则说明模型效果不佳;如果整个模型的F 值比较大,则说明当前模型是可行的;此外,残差正态分布检验用于判断回归残差是否符合正态分布,如果P值少于0.05,则拒绝原假设(即回归残差不符合正态
分布)。
综上所述,可见多元回归分析可以帮助我们了解自变量和因变量之间的关系,识别影响重要性的变量,并检验模型的统计学合理性以及预测准确性,给出更有用的信息指导研究与决策。
SPSS-回归分析

SPSS-回归分析回归分析(⼀元线性回归分析、多元线性回归分析、⾮线性回归分析、曲线估计、时间序列的曲线估计、含虚拟⾃变量的回归分析以及逻辑回归分析)回归分析中,⼀般⾸先绘制⾃变量和因变量间的散点图,然后通过数据在散点图中的分布特点选择所要进⾏回归分析的类型,是使⽤线性回归分析还是某种⾮线性的回归分析。
回归分析与相关分析对⽐:在回归分析中,变量y称为因变量,处于被解释的特殊地位;;⽽在相关分析中,变量y与变量x处于平等的地位。
在回归分析中,因变量y是随机变量,⾃变量x可以是随机变量,也可以是⾮随机的确定变量;⽽在相关分析中,变量x和变量y都是随机变量。
相关分析是测定变量之间的关系密切程度,所使⽤的⼯具是相关系数;⽽回归分析则是侧重于考察变量之间的数量变化规律。
统计检验概念:为了确定从样本(sample)统计结果推论⾄总体时所犯错的概率。
F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。
统计显著性(sig)就是出现⽬前样本这结果的机率。
标准差表⽰数据的离散程度,标准误表⽰抽样误差的⼤⼩。
统计检验的分类:拟合优度检验:检验样本数据聚集在样本回归直线周围的密集程度,从⽽判断回归⽅程对样本数据的代表程度。
回归⽅程的拟合优度检验⼀般⽤判定系数R2实现。
回归⽅程的显著性检验(F检验):是对因变量与所有⾃变量之间的线性关系是否显著的⼀种假设检验。
回归⽅程的显著性检验⼀般采⽤F 检验。
回归系数的显著性检验(t检验): 根据样本估计的结果对总体回归系数的有关假设进⾏检验。
1.⼀元线性回归分析定义:在排除其他影响因素或假定其他影响因素确定的条件下,分析某⼀个因素(⾃变量)是如何影响另⼀事物(因变量)的过程。
SPSS操作2.多元线性回归分析定义:研究在线性相关条件下,两个或两个以上⾃变量对⼀个因变量的数量变化关系。
表现这⼀数量关系的数学公式,称为多元线性回归模型。
SPSS操作3.⾮线性回归分析定义:研究在⾮线性相关条件下,⾃变量对因变量的数量变化关系⾮线性回归问题⼤多数可以化为线性回归问题来求解,也就是通过对⾮线性回归模型进⾏适当的变量变换,使其化为线性模型来求解。
SPSS中logistics回归分析哑变量设置及结果解读
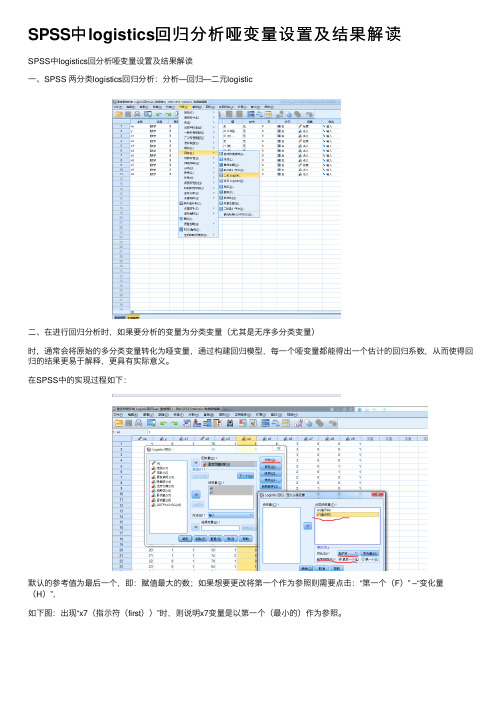
SPSS中logistics回归分析哑变量设置及结果解读
SPSS中logistics回分析哑变量设置及结果解读
⼀、SPSS 两分类logistics回归分析:分析—回归—⼆元logistic
⼆、在进⾏回归分析时,如果要分析的变量为分类变量(尤其是⽆序多分类变量)
时,通常会将原始的多分类变量转化为哑变量,通过构建回归模型,每⼀个哑变量都能得出⼀个估计的回归系数,从⽽使得回归的结果更易于解释,更具有实际意义。
在SPSS中的实现过程如下:
默认的参考值为最后⼀个,即:赋值最⼤的数;如果想要更改将第⼀个作为参照则需要点击:“第⼀个(F)” –“变化量(H)”,
如下图:出现“x7(指⽰符(first))”时,则说明x7变量是以第⼀个(最⼩的)作为参照。
三、结果:
在输出结果中有“分类变量编码”,即展⽰了分类变量设置为哑变量的编码;
最后结果中,需对照“分类变量编码”进⾏结果解释,在“⽅程中变量” 的“铂种类(1)”则代表的是“顺铂”相对于“其他”的OR值是0.483;“铂种类(2)”则代表的是“奥沙利铂”相对于“其他”的OR值是0.852;…… “肝功能(1)”则代表肝功能异常相对于正常
的OR是3.634。
spss二元logistic回归分析结果解读

spss二元logistic回归分析结果解读二元logistic回归分析是一种被广泛应用于多元研究中的统计分析方法,它可以帮助研究者了解因变量与自变量之间的关系,探索如何调节自变量,以达到改变因变量的目的。
本文主要就二元logistic回归分析结果如何解释进行讨论,旨在帮助读者更好地理解并解读此类分析结果。
一、二元logistic回归分析概述二元logistic回归分析是一种常见的回归分析模型,它可以用来预测一个特定的结果,或者说一个事件的发生可能性,以及它的发生概率有多大。
它比较适合于研究两个变量之间的关系,一个变量是被解释变量,另一个变量是解释变量,被解释变量只有两种可能的结果,比如两个不同的类别。
二元logistic回归分析的基本思想是利用自变量来预测因变量,它通过计算自变量之间的相关性,来预测因变量的发生可能性,比如我们可以利用自变量,如性别、年龄等,来预测一个人是否会患上某种疾病。
二元logistic回归分析结果分析二元logistic回归分析的结果可以分为三类,分别是系数、截距和拟合指数。
1、系数系数指的是每个自变量变化时,因变量变化的程度,系数的正负可以表示因变量变化的方向,正数表示因变量随自变量变化而增大,负数表示因变量随自变量变化而减小。
系数的大小可以表示因变量变化的幅度,数值越大,表明因变量变化的越明显。
2、截距截距表示自变量为0时因变量的值,即任何自变量都不存在的情况下,因变量的值。
它的大小可以反映因变量变化的数量级,它的正负可以表示因变量变化的方向,正数表示因变量变化而增大,负数表示因变量变化而减小。
3、拟合指数拟合指数是一种衡量模型准确度的指标,其数值越大,表明模型越准确。
一般来说,当拟合指数大于0.6时,可以认为模型较准确。
三、典型二元logistic回归分析结果解读1、系数如果某个自变量的系数为正,表示随着自变量增加,因变量也随之增加;如果系数为负,表示随着自变量增加,因变量会减小。
偏最小二乘回归分析spss
偏最小二乘回归分析spss
偏最小二乘回归分析是一种常用的统计模型,它是一种属于近似回归的一类,它的主要目的是确定拟合曲线或函数,从而得到最佳的模型参数。
本文以SPSS软件为例,将对偏最小二乘回归分析的基本原理和程序进行详细说明,以供有兴趣者参考。
一、偏最小二乘回归分析的基本原理
偏最小二乘回归(PPLS),又称最小二乘偏差(MSD)回归,是一种统计分析方法,是一种从给定的观测值中找到最接近的拟合函数的近似回归方法,它被广泛应用于寻找展示数据之间关系的曲线和函数。
最小二乘回归分析的基本原理是:通过最小化方差的偏差函数使拟合曲线或函数最接近观测值,从而找到最佳模型参数。
二、SPSS偏最小二乘回归分析程序
1.开SPSS软件并进入数据窗口,在此窗口中导入数据。
2.择“分析”菜单,然后点击“回归”,再点击“偏最小二乘法”,将其所属的类型设置为“偏最小二乘回归分析”。
3.定自变量和因变量,然后点击“设置”按钮。
4.设置弹出窗口中,可以设置回归模型中的参数,比如是否包含常量项和拟合性选项等。
5.击“OK”按钮,拟合曲线形即被确定,接着软件会计算拟合曲线及回归系数,并给出回归分析结果。
6.入到回归结果窗口,可以看到模型拟合度的评价指标及拟合曲线的统计量,如:平均残差、方差膨胀因子等。
结论
本文以SPSS软件为例,介绍了偏最小二乘回归分析的基本原理及使用程序,从而使读者能够快速掌握偏最小二乘回归分析的知识,并能够有效地使用SPSS软件。
然而,偏最小二乘回归分析仅仅是一种统计模型,它不能够代表所有统计问题,因此,在具体应用中还需要结合实际情况,合理选择不同的模型,使用不同的统计工具,以得到更加有效的统计分析结果。
SPSS多元线性回归结果分析
SPSS多元线性回归结果分析输出下⾯三张表第⼀张R⽅是拟合优度对总回归⽅程进⾏F检验。
显著性是sig。
结果的统计学意义,是结果真实程度(能够代表总体)的⼀种估计⽅法。
专业上,p 值为结果可信程度的⼀个递减指标,p 值越⼤,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。
p 值是将观察结果认为有效即具有总体代表性的犯错概率。
如 p=0.05 提⽰样本中变量关联有 5% 的可能是由于偶然性造成的。
即假设总体中任意变量间均⽆关联,我们重复类似实验,会发现约 20 个实验中有⼀个实验,我们所研究的变量关联将等于或强于我们的实验结果。
(这并不是说如变量间存在关联,我们可得到 5% 或 95% 次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效⼒有关。
)在许多研究领域,0.05 的 p 值通常被认为是可接受错误的边界⽔平。
F检验:对于多元线性回归模型,在对每个回归系数进⾏显著性检验之前,应该对回归模型的整体做显著性检验。
这就是F检验。
当检验被解释变量y t与⼀组解释变量x1, x2 , ... , x k -1是否存在回归关系时,给出的零假设与备择假设分别是H0:b1 = b2 = ... = b k-1 = 0 ,H1:b i, i = 1, ..., k -1不全为零。
⾸先要构造F统计量。
由(3.36)式知总平⽅和(SST)可分解为回归平⽅和(SSR)与残差平⽅和(SSE)两部分。
与这种分解相对应,相应⾃由度也可以被分解为两部分。
SST具有T - 1个⾃由度。
这是因为在T个变差 ( y t -), t = 1, ..., T,中存在⼀个约束条件,即 = 0。
由于回归函数中含有k个参数,⽽这k个参数受⼀个约束条件制约,所以SSR具有k -1个⾃由度。
因为SSE中含有T个残差,= y t -, t = 1, 2, ..., T,这些残差值被k个参数所约束,所以SSE具有T - k个⾃由度。
多元回归分析SPSS案例
多元回归分析SPSS案例
一、案例背景
一所大学学术部门进行了一项有关学生毕业的调查,主要是为了探讨
学生毕业的影响因素,通过这个调查,大学试图及早发现潜在的学术发展
问题,从而改善学术教育和服务质量。
调查采用SPSS软件分析,将来自
一所大学学生的有关信息作为研究目标,本研究的研究对象为大学学生。
二、研究目的
1、探索影响大学生毕业的主要因素;
2、研究各变量对大学生毕业的影响程度;
3、提出适合大学学生的毕业提升策略。
三、研究变量
本研究采用多元线性回归分析方法,研究变量有:(1)身体健康程
度(即体检结果);(2)现金流(即家庭收入);(3)家庭教育水平;(4)学习成绩;(5)家庭状况,即与家庭成员的关系;(6)个人情感
状况;(7)考试作弊。
四、研究方法
1、获取研究数据:
通过与学校协商,确定调查对象,以及采集问卷的方法(如发放问卷、网络调查等),以获取有关学生毕业的数据;
2、数据处理:
清洗数据,将数据分类进行处理,去除无关信息;
3、多元回归分析:
计算自变量与因变量之间的线性关系,分析变量间关系,建立多元回归模型;。
spss二元logistic回归分析结果解读
spss的二元logistic回归
SPSS(Statistical Product and Service Solutions)是一款数据统计与分析软件。
SPSS软件可以提供全面高级的统计分析,方便易用可快速操作,可缩小数据科学与数据理解之间的差距;在具体的应用方向方面,SPSS提供了高级统计分析、大量机器学习算法、文本分析等功能,具备开源可扩展性,可与大数据的集成,并能够无缝部署到应用程序中。
Logistic回归:主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
OR(OddsRatio):比值比,优势比。
二元logistic回归是研究二分类反应变量和多个解释变量间回归关系的统计学分析方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
I 目录 摘要............................................................... II Abstract.......................................................... III 第1章 绪论........................................................ 1 1.1 研究背景 ................................................... 1 1.2 研究现状 ................................................... 1 1.3 研究目的及意义 ............................................. 2 1.4 研究思路及方法 ............................................. 2 第2章 应用方法简介................................................ 3 2.1 回归分析 ................................................... 3 2.1.1 多元线性回归分析原理................................. 3 2.2 因子分析 ................................................... 3 2.2.1 因子分析的基本原理..................................... 4 2.2.2 因子分析的步骤......................................... 5 2.3 K中心聚类分析原理.......................................... 8 第3章 数据及指标的选取............................................ 8 3.1 建立评价指标体系 ............................................ 8 3.2 建立数据体系 ................................................ 9 第4章 上市公司股票实证分析....................................... 10 4.1 回归分析的结果分析 ......................................... 10 4.2 因子分析的结果分析 ........................................ 11 4.2.1 因子分析的适宜性检验.................................. 12 4.2.2 公因子的提取.......................................... 13 4.2.3 求因子载荷阵并确定各因子的性质........................ 14 4.2.4 各公共因子的得分以及赋权.............................. 15 4.2.5 因子分析各股票得分排名................................ 16 4.3 K均值聚类结果分析........................................ 19 结论............................................................... 21 参考文献........................................................... 24 致 谢.............................................................. 25 附录............................................................... 26 II
摘要 近几年,随着金融市场的不断发展和完善,金融业也出现欣欣向荣的景象,尤其是在2014年提出的“新常态”的经济环境下,金融业的发展又面临着新的机遇。新常态的典型特征就是经济增速放缓,GDP已经处于中高速,其实是一个中速的区间,我们从2012年3月份GDP跌破8%以后到现在为止2014年已经两年半的时间在8%以下运行,这就成为一种新常态。 本文从金融业上市公司的研究现状、 研究目的及意义入手, 基于金融业上市公司的财务指标及股票的经济指标,选取并筛选主要的分析指标,运用实证分析来评价各个上市公司以及银行、证券、保险行业的发展情况,最后总结出发展前景好的行业与有投资价值的上市公司,为投资者的理性投资提供相应的理论依据。 因此,分析金融业经济环境现状,是否具有投资可行性,以及各股的发展潜力,对于理性投资者有着重要意义。本文在写作前查阅了大量有关金融业上市公司的资料,大量、全面的引用了证券之星所公开的2014年第三季度金融业上市公司的相关数据,对金融业上市公司股票进行描述,然后通过选取10个指标以回归分析、因子分析和K均值聚类为主体方法,利用SPSS软件,对金融业上市公司现状进行打分、排名、分类以及评价,并且给出相应的是否具有可投资性的相关政策建议,为我国投资者能更理性的决定投资方案提供理论依据。
关键字:金融业 财务指标 回归分析 因子分析 K均值聚类分析 III
Abstract In recent years, with the continuous development and improvement of financial markets, the financial sector also appears thriving scene, especially made in 2014 under the "new normal" economic environment, the development of the financial industry is faced with new opportunities. A typical feature is the new normal economic slowdown, GDP has been in the high-speed, in fact, is a medium speed range, from March 2012 after GDP fell below 8% in 2014 up to now has been two and a half hours in 8% less to run, which has become a new norm. This paper studies the financial industry from the current situation of listed companies, the purpose and significance of the start, based on the economic indicators of the financial sector and financial indicators listed company stocks, selected and screened for the main analysis indicators, using empirical analysis to evaluate various listed companies as well as banks, securities , the development of the insurance industry, and concluded that the development prospects of the industry and have good investment value of listed companies, provide the theoretical basis for rational investment investors. Therefore, analysis of the economic state of the financial industry environment, whether the investment feasibility, and development potential of each stock, has an important significance for rational investors. Check out this article before writing a lot about financial information of listed companies, a large, comprehensive data cited in the third quarter 2014 financial securities listed companies disclosed Star, shares of listed companies in the financial sector are described, and then By selecting 10 indicators regression analysis, factor analysis and K-means clustering as the main method using SPSS software, the status of listed companies in the financial sector scoring, ranking, classification and evaluation, and whether to give the appropriate investment of relevant policy recommendations, provide a theoretical basis for our investors to more rational decisions investment programs.