根据代码 详细分析JM8.6
jmert汇总报告解读

jmert汇总报告解读JMert汇总报告是一份关于JMeter进行性能测试的报告,提供了对系统性能的评估和分析。
在报告中,包含了测试结果、性能指标、问题分析以及建议等内容。
下面是对JMert汇总报告的解读。
图表分析部分显示了JMert测试的相关数据。
通过对比不同场景下的响应时间、吞吐量和并发用户数等指标,可以发现系统在不同负载情况下的性能表现。
例如,在高负载情况下,响应时间可能会出现明显延迟,吞吐量也会相应下降。
这些数据可以帮助我们判断系统在不同压力下的性能状况,并对系统进行优化和改进。
性能指标部分给出了系统的一些关键指标,如平均响应时间、最大并发用户数、成功率等。
通过对这些指标的分析,可以对系统的整体性能有一个直观的了解。
如果响应时间较长或者成功率较低,可能存在性能问题,需要进一步调查和解决。
问题分析部分列出了系统在测试中出现的一些问题和异常情况。
例如,可能会出现HTTP500错误、数据库连接超时等问题。
这些问题需要进行深入分析,并找出问题的根本原因。
通常,可以通过查看系统日志、定位性能瓶颈、进行代码优化等方法来解决这些问题。
建议部分给出了一些建议和改进措施,以提升系统性能。
例如,优化数据库查询、增加服务器的内存和处理器等。
这些建议可以作为系统优化和改进的参考,帮助提高系统的性能和用户体验。
总结部分对测试结果进行了总结和评价。
根据各项指标的表现,可以得出系统在不同负载情况下的性能状况以及存在的问题和改进空间。
同时,也对JMert工具测试的有效性和准确性进行了评估。
综上所述,JMert汇总报告的解读主要包括对测试结果和指标的分析、问题的定位和解决、以及对系统改进和优化的建议等内容。
通过对报告的解读,可以更好地了解系统的性能状况,找出问题并进行优化,从而提升系统的性能和用户体验。
java8 lambda运用 源码

一、概述Java语言的不断发展壮大使得其在软件开发行业拥有了极大的影响力。
随着技术的不断升级,Java在不断推出新的版本来跟进市场需求。
其中,Java8版本的特性lambda表达式的引入,使得开发者们能够更加便捷地编写简洁的代码,提高了程序的可读性和效率。
本文将深入探讨Java8中lambda表达式的运用,并结合源码进行分析。
二、lambda表达式简介1. Lambda表达式的定义和语法Lambda表达式是Java 8引入的一种新的语法特性,使得函数式编程能够更加方便和简洁。
lambda表达式可以被理解为一种匿名函数,它没有名称,但具有参数列表、函数体和可能的异常列表。
lambda表达式的语法如下:(参数列表) -> {表达式}或(参数列表) -> 单个表达式或(参数列表) -> {语句块}2. Lambda表达式的特点- 精简的语法:lambda表达式大大简化了匿名类的语法,使得代码变得更加简洁。
- 函数式接口支持:lambda表达式需要与函数式接口搭配使用,可以通过函数式接口实现对lambda表达式的调用。
- 支持并行操作:lambda表达式可以支持并行操作,使得多核处理器的性能得到充分利用。
三、Lambda表达式在Java8中的应用1. 集合框架的forEach方法在Java8中,集合框架新增了forEach方法,可以使用lambda表达式遍历集合元素,如下所示:```javaList<String> list = new ArrayList<>();list.add("Java");list.add("Python");list.forEach(str -> System.out.println(str));```上述代码使用lambda表达式遍历了List集合中的元素,并分别打印出来。
通过lambda表达式,只需要一行代码就能完成对集合元素的遍历操作。
...存在方块效应,新的视频编码标准h.264中亦是如此。产生...

引言在已有的基于块的视频编解码系统中,当码率较低时都存在方块效应,新的视频编码标准H.264中亦是如此。
产生这种方块效应的主要原因有两个:一是由于对变换后的残差系数进行的基于块的整数变换后,以大的量化步长对变换系数进行量化会使得解码后的重建图像的方块边缘出现不连续;二是在运动补偿中插值运算引起的误差使得编解码器反变换后的重建图像会出现方块效应。
如果不进行处理,方块效应还会随着重构帧积累下去,从而严重地影响图像的质量和压缩效率。
为了解决这一问题,H.264中的去方块滤波技术采用较为复杂的自适应滤波器来有效地去除这种方块效应。
因此,如何在实时视频解码中优化去方块滤波算法,降低计算复杂度,提高重建图像质量,就成了H.264解码的一个关键问题。
1 H.264的去方块滤波1.1 滤波原理大的量化步长会造成相对较大的量化误差,这就可能将原来相邻块“接壤”处像素间灰度的连续化变成了“台阶”变化,主观上就有”伪边缘”的方块效应。
去方块效应的方法就是在保持图像总能量不变的条件下,把这些台阶状的阶跃灰度变化重新复原成台阶很小或者近似连续的灰度变化,同时还必须尽量减少对真实图像边缘的损伤。
1.2 自适应滤波过程在H.264中,去方块滤波器是按照16×16像素的宏块为单位顺序进行的,在宏块中按照每个4×4子块之间的边缘以先垂直后水平的顺序进行,从而对整个重建图像中的所有边缘(图像边缘除外)进行滤波。
具体的边缘示意图如图1所示。
对于16×16像素的亮度宏块,共有4条垂直边缘,4条水平边缘,每条边缘又分为16条像素边缘。
而对应8×8像素的色度宏块有垂直边缘和水平边缘各2条,每条边缘分为8条像素边缘。
像素边缘是进行滤波的基本单元。
1.2.1 滤波器在两个层次上的自适应性H.264中的去方块滤波所以有较好的滤波效果,是由于它在以下两个层次上的自适应性。
1) 滤波器在4×4子块级别的自适应性滤波是基于各个子块中的像素边缘进行的,通过对每一条像素边缘定义一个参数BS(边缘强度)来自适应地调节滤波的强弱和涉及的像素点。
学会使用代码分析工具优化性能

学会使用代码分析工具优化性能代码分析工具是一种帮助程序员识别和解决性能问题的强大工具,通过查找代码中的潜在性能问题和优化建议,可以帮助开发者优化代码的执行效率和资源利用率。
下面将介绍几种常用的代码分析工具,并讨论如何使用它们来优化性能。
一、静态代码分析工具静态代码分析工具是指在不运行代码的情况下,通过对代码进行分析来检测潜在的问题。
这些工具通常可以检测到一些常见的性能问题,如死循环、内存泄漏、资源未释放等。
1. FindBugsFindBugs是一个开源的静态代码分析工具,可以检测Java代码中的各种潜在问题。
通过扫描字节码文件,FindBugs可以发现各种编码错误、性能问题和错误使用API等。
使用FindBugs优化性能的关键在于理解它的警告和建议。
找到潜在的性能问题后,可以根据其建议进行代码修复。
例如,可以使用更高效的数据结构替代效率低下的数据结构,优化算法以减少时间复杂度等。
2. PMDPMD是又一个广泛使用的Java源代码静态分析工具。
它可以找出一些常见的编码错误、潜在的性能问题和未经优化的代码,帮助开发者编写更高质量的代码。
使用PMD优化性能的关键是理解其规则,并使用合适的规则集来检测问题。
PMD提供了一系列的规则集,可以根据项目需要进行配置。
通常,可以使用与性能相关的规则集,如代码复杂度、潜在的性能问题等。
二、动态代码分析工具动态代码分析工具是指在运行时检测代码性能的工具。
这些工具可以提供更详细的性能数据,并帮助开发者找到代码瓶颈。
1. VisualVMVisualVM是一个功能强大的Java性能调优工具,可以监控应用程序的性能并提供实时的运行时数据。
它可以监测CPU使用率、内存使用、线程情况等,并提供了各种命令行和图形界面的功能。
使用VisualVM优化性能的关键在于分析工具提供的运行时数据。
可以通过查看CPU使用率和内存使用情况来找到潜在的性能问题;通过线程分析功能可以找到线程竞争和死锁等问题;通过堆快照功能可以查看对象的占用情况,并发现内存泄漏等。
java8学习之groupingBy源码分析
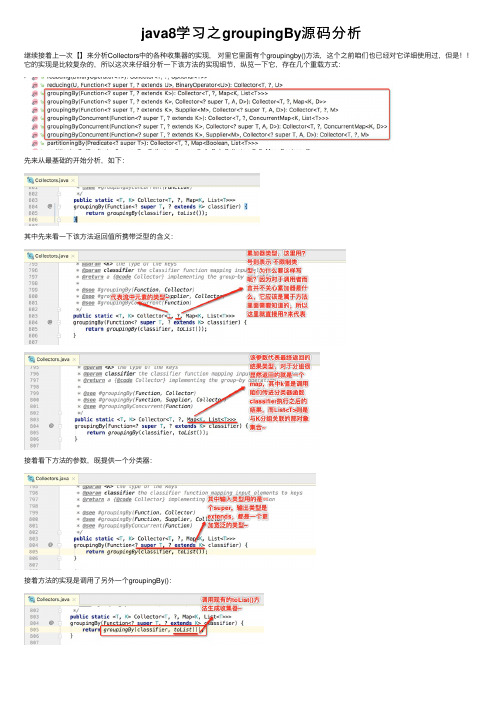
java8学习之groupingBy源码分析继续接着上⼀次【】来分析Collectors中的各种收集器的实现,对⾥它⾥⾯有个groupingby()⽅法,这个之前咱们也已经对它详细使⽤过,但是!!它的实现是⽐较复杂的,所以这次来仔细分析⼀下该⽅法的实现细节,纵览⼀下它,存在⼏个重载⽅式:先来从最基础的开始分析,如下:其中先来看⼀下该⽅法返回值所携带泛型的含义:接着看下⽅法的参数,既提供⼀个分类器:接着⽅法的实现是调⽤了另外⼀个groupingBy():那像这种有下游收集器的⽅法实现的⼀个⼤致思路是怎样的呢?downstream既然已经是⼀个收集器了,所以就会有收集器的那⼏个重要的⽅法,⽽还有⼀个分类器参数,其实就是将这个分类器应⽤到这个下游收集器当中,使得收集器进⾏了⼀系列的转换,⽽最终转换成的收集器则就是⽅法要返回的收集器啦,所以但凡⽅法中带有⼀个收集器然后⼜返回⼀个收集器其构造思路都类似。
⽬前这个groupingBy()有四个泛型了,下⾯先来对每个泛型有个认知:接着再来看这个⽅法的具体实现,发现⼜调⽤了另外⼀个groupingBy()⽅法,如下:⽽可以看到第⼆个参数实例化了⼀个HashMap对象,先不去看它所调⽤的另外⼀个重载groupingBy()⽅法的定义,从这个字⾯就能知道第⼆个参数肯定是做为最终的结果容器对象,所以说如果咱们在使⽤时是使⽤了第⼀个最简单的groupingBy()来对数据进⾏分组,最终返回的肯定是HashMap对象,⽽如果咱们想⾃⼰定义最终返回的类型⽐如:TreeMap,那这时就得使⽤最复杂的最后⼀个groupingBy()⽅法啦,所以下⾯将焦点转移到这个最复杂⽅法上⾯,先来贴出这个⽅法的实现先来感受⼀下其复杂性:public static <T, K, D, A, M extends Map<K, D>>Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,Supplier<M> mapFactory,Collector<? super T, A, D> downstream) {Supplier<A> downstreamSupplier = downstream.supplier();BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");A container = puteIfAbsent(key, k -> downstreamSupplier.get());downstreamAccumulator.accept(container, t);};BinaryOperator<Map<K, A>> merger = Collectors.<K, A, Map<K, A>>mapMerger(biner());@SuppressWarnings("unchecked")Supplier<Map<K, A>> mangledFactory = (Supplier<Map<K, A>>) mapFactory;if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_ID);}else {@SuppressWarnings("unchecked")Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();Function<Map<K, A>, M> finisher = intermediate -> {intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));@SuppressWarnings("unchecked")M castResult = (M) intermediate;return castResult;};return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_NOID);}}艾玛~~先不看实现,看到泛型的定义就⽴马蒙圈,确实够复杂的,所以接下来准备⼀⾏⾏代码来理解它的具体实现,先来看⼀下它的参数定义:⽽对于第⼆个groupingBy()⽅法在调⽤这个groupingBy()时,对于这个mapFactory传递的是:接着简单的看⼀下它的javadoc:上⾯这句话说的就是这个参数:其中可以发现,因为要带排序功能,所以得⽤TreeMap,所以此时调⽤的groupingBy就是⽤的第三个最复杂的,因为⾃由的来决定最终返回的结果容器。
16位取高8位 java代码

16位取高8位 java代码在Java编程中,经常需要对数据进行处理和转化。
在这个过程中,我们可能会需要把16位数据中的高八位提取出来。
这个过程看起来比较简单,但是对于新手来说,可能还需要一些指导和解释。
下面就来一步步地讲解如何在Java中实现16位取高8位的功能吧。
一、什么是16位取高8位?在计算机中,二进制数是按位存储的。
比如,十进制的数字25在计算机中对应的二进制数,是11001。
这就是指十六进制,也就是16位数字,其中高八位指的是二进制数的前八位。
因此,“16位取高8位”就是从16位的二进制数(或十六进制数)中,将高八位提取出来,以便进行进一步的操作和计算。
二、Java代码实现在Java中,16位取高8位可以通过位运算和类型转换来实现。
具体代码如下:public class Main {public static void main(String[] args) {int num = 0x1234; //16位的数字int highNum = (num >> 8) & 0xFF; //取高8位System.out.println(highNum); //输出高8位}}代码解析:1.首先,定义一个int类型的变量num,赋值为0x1234。
这个数字是16位的,其中“0x”表示这是一个十六进制的数字。
2.然后,通过位运算和类型转换,提取出num的高八位。
3.代码中,使用了位运算符“>>”来将num向右移动8位。
这个操作是将num的低8位“剪掉”,只留下高8位。
4.接着,使用位运算符“&”和0xFF来将高8位转换成一个byte 类型的数值。
这是因为8位二进制数是可以表示为256种可能的情况,也就是0~255之间的整数。
因此,通过&0xFF运算,可以将高8位转换成0~255之间的整数。
5.最后,将高8位输出,以便查看结果。
三、代码输出结果在代码执行后,我们可以看到输出结果为18。
linux 定位导致内存溢出的java代码
linux 定位导致内存溢出的java代码如果您在使用Java编程时遇到了内存溢出的问题,那么可能是因为您的代码中存在内存泄漏或者是资源没有被正确释放。
在Linux 系统中,您可以使用一些工具来定位这些问题。
以下是一些可能导致内存溢出的Java代码,以及如何使用Linux工具来找到并解决这些问题:1. 对象没有正确释放如果您的代码中存在对象没有正确释放的情况,那么可能会导致内存泄漏。
您可以使用jmap命令来查看Java堆内存的使用情况,以及哪些对象占用了大量的内存。
例如,您可以使用以下命令来生成一个Java堆内存转储文件:jmap -dump:format=b,file=heapdump.bin <pid>然后,您可以使用jhat命令来分析这个文件,并查找可能存在内存泄漏的对象。
例如,您可以使用以下命令来启动一个本地的Web 服务器,并使用浏览器访问http://localhost:7000/来访问分析结果:jhat -port 7000 heapdump.bin2. 大量的字符串拼接如果您的代码中有大量的字符串拼接,那么可能会导致内存溢出。
您可以使用jstat命令来查看Java进程中的类加载、垃圾回收等信息。
例如,您可以使用以下命令来查看Java进程的垃圾回收情况:jstat -gc <pid>如果您发现Eden区和Survivor区的空间占用率很高,那么可能是因为有大量的字符串被创建和销毁。
您可以考虑使用StringBuilder来优化字符串拼接操作。
3. 大量的文件操作如果您的代码中有大量的文件操作,那么可能会导致内存溢出。
您可以使用vmstat命令来查看Linux系统的内存、CPU等信息。
例如,您可以使用以下命令来查看系统的内存使用情况:vmstat 1如果您发现系统的内存使用率很高,那么可能是因为您的代码中有大量的文件操作。
您可以考虑使用内存映射文件等技术来优化文件操作。
如何进行代码性能分析和优化
如何进行代码性能分析和优化代码性能分析和优化是软件开发中非常重要的一环。
通过对代码的性能进行分析和优化,可以提高程序的运行效率,减少资源的消耗,提升用户体验。
本文将介绍如何进行代码性能分析和优化的一些常用方法和技巧。
一、性能分析工具的选择在进行代码性能分析之前,我们首先需要选择合适的性能分析工具。
常用的性能分析工具有:1. Profiler:Profiler是一种用于监测程序运行时性能的工具。
它可以分析程序的运行时间、函数调用次数、内存使用情况等信息,并生成相应的报告。
常见的Profiler工具有Visual Studio Profiler、Xcode Instruments等。
2. Benchmark工具:Benchmark工具可以用来测试程序的性能。
它可以模拟实际使用场景,对程序进行压力测试,从而找出性能瓶颈。
常见的Benchmark工具有JMH(Java Microbenchmark Harness)等。
3. 静态分析工具:静态分析工具可以在不运行程序的情况下,对代码进行分析,找出潜在的性能问题。
常见的静态分析工具有SonarQube、PMD等。
二、性能分析的步骤进行代码性能分析和优化的一般步骤如下:1. 确定性能指标:首先,我们需要明确性能指标,例如程序的运行时间、内存使用情况等。
根据不同的应用场景和需求,可以确定不同的性能指标。
2. 进行性能测试:接下来,我们需要对程序进行性能测试,以收集性能数据。
可以使用Profiler工具或Benchmark工具进行性能测试,并记录测试结果。
3. 分析性能数据:在收集到性能数据后,我们需要对数据进行分析,找出性能瓶颈。
可以通过查看Profiler生成的报告,分析函数调用次数、运行时间等信息,找出耗时较长的函数。
4. 优化性能瓶颈:根据性能分析的结果,我们可以对性能瓶颈进行优化。
可以从算法优化、数据结构优化、并发优化等方面入手,找出性能瓶颈的原因,并进行相应的优化。
a算法求解八数码问题 实验报告
题目: a算法求解八数码问题实验报告目录1. 实验目的2. 实验设计3. 实验过程4. 实验结果5. 实验分析6. 实验总结1. 实验目的本实验旨在通过实验验证a算法在求解八数码问题时的效果,并对其进行分析和总结。
2. 实验设计a算法是一种启发式搜索算法,主要用于在图形搜索和有向图中找到最短路径。
在本实验中,我们将使用a算法来解决八数码问题,即在3x3的九宫格中,给定一个初始状态和一个目标状态,通过移动数字的方式将初始状态转变为目标状态。
具体的实验设计如下:1) 实验工具:我们将使用编程语言来实现a算法,并结合九宫格的数据结构来解决八数码问题。
2) 实验流程:我们将设计一个初始状态和一个目标状态,然后通过a 算法来求解初始状态到目标状态的最短路径。
在求解的过程中,我们将记录下每一步的状态变化和移动路径。
3. 实验过程我们在编程语言中实现了a算法,并用于求解八数码问题。
具体的实验过程如下:1) 初始状态和目标状态的设计:我们设计了一个初始状态和一个目标状态,分别为:初始状态:1 2 34 5 67 8 0目标状态:1 2 38 0 42) a算法求解:我们通过a算法来求解初始状态到目标状态的最短路径,并记录下每一步的状态变化和移动路径。
3) 实验结果在实验中,我们成功求解出了初始状态到目标状态的最短路径,并记录下了每一步的状态变化和移动路径。
具体的实验结果如下:初始状态:1 2 34 5 67 8 0目标状态:1 2 38 0 47 6 5求解路径:1. 上移1 2 37 8 62. 左移1 2 3 4 0 5 7 8 63. 下移1 2 3 4 8 5 7 0 64. 右移1 2 3 4 8 5 0 7 65. 上移1 2 3 0 8 5 4 7 61 2 38 0 54 7 67. 下移1 2 38 7 54 0 68. 右移1 2 38 7 54 6 0共计8步,成功从初始状态到目标状态的最短路径。
JM代码阅读笔记之一
2007-11-6:JM 文档描述研究(一)I RC 问题是在2.6节中描述的,这些符号的含义是什么?1)有关字母含义的说明j th picture in the i th GOP :表示第i 个GOP 的第j 幅图像。
bpp :就是每个像素的bits 数。
Bits per pixel(?).1) 图像数据i i i i i i i i N j f j R j b j V j V otheri N V V ,...,3,2)1()1()1()(1)(0)1(11=---+-=⎩⎨⎧==-- 以上公式含义说明:若为第1个GOP 图像组的第一个图像,那么,此时虚存为0,容易理解;若为某个GOP 图像组的第一个图像,那么,此时的虚存为上一个GOP 的虚存。
对于不是第一个图像的情况,此时的虚存为上一个图像编码时占据的虚存。
II 请教个问题:对于GOP 图像序列,若编码第i 个GOP 的第j 个图像时,此时在虚存中保留着上一个GOP 的所有图像数据?解答:IGOP 就是第一frame 为IDR,然后其余frame 按照预设的frame 类型序列编码,直到该周期结束;接着开始下一个GOP ,但此时第一frame 图像不是IDR,因此,它要保留前一个GOP 中的信息(至少是部分信息)。
2007-11-6:JM 文档描述研究(二)I 总体而言,JM 模型主要的数据结构、文件内容、函数功能、软件架构和核心算法是怎样的?JM 模型主要的描述和说明文档有哪些?JMII 请教:1) jm 中InputParameters 中成员IntraBottom 什么含义?2) 数组存储的数据用作什么?LevelScale4x4LumaLevelScale4x4ChromaLevelScale8x8LumaInvLevelScale4x4LumaInvLevelScale4x4ChromaInvLevelScale8x8Luma3)下面代码来自函数void init_poc()if (input->BRefPictures == 1){img->offset_for_non_ref_pic = 0;img->offset_for_ref_frame[0] = 2;}else{img->offset_for_non_ref_pic = -2*(input->successive_Bframe);img->offset_for_ref_frame[0] = 2*(input->successive_Bframe+1);}它的实现原理是什么?解答:当输入参数表明B 参考图像可以用作参考frame时,不存在非参考图像的问题,因此,所谓的偏移为0;否则,就存在偏移。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
L1 = 0.1;L2 = 0.3;L3 = 0.6;}else if (img->width == 352) 如果是cif格式门限L1 L2 L3取值如下{L1 = 0.2;L2 = 0.6;L3 = 1.2;}else 其他格式取值{L1 = 0.6;L2 = 1.4;L3 = 2.4;}根据bpp门限求出对应的初始Qpif (input->SeinitialQP==0){if(bpp<= L1)qp = 35;elseif(bpp<=L2)qp = 25;elseif(bpp<=L3)qp = 20;elseqp =10;input->SeinitialQP = qp;}作者: kingdexing 时间: 2008-9-17 18:44有空还会继续写,不会排版请见谅!作者: kingdexing 时间: 2008-9-17 20:31rc_init_GOP目的就是求出GOP的QP初始值void rc_init_GOP(int np, int nb)输入未编码的p数目np 未编码的b数目nb{if(R<0)当然R<0说明流量小于了编码位数Overum=TRUE;OverBits=-R;/*initialize the lower bound and the upper bound for the target bits of each frame, HRD consideration*/考虑到hrd(假设参考解码)来决定R中可用位数的上限和下限LowerBound=(long)(R+bit_rate/frame_rate);UpperBound1=(long)(R+InitialDelayOffset);/*compute the total number of bits for the current GOP*/ 计算当前gop的可用位AllocatedBits = (int) floor((1 + np + nb) * bit_rate / frame_rate + 0.5);np nb未编码的p b桢按当前流量流出的位数R +=AllocatedBits; R表示当前gop可用位数考虑gop的桢数算出流量和以前R相加因为以前R<0可能存在,说明上1个gop还有未流出的数据必须降低当前gop目标位数Np = np;Nb = nb;OverDuantQp=(int)(8*OverBits/AllocatedBits+0.5);原因就是R<0未流出的量求出修正OverDuantQp 8*Tr(i-1,Ngop)/Tr(i,0)上次剩余的位数处以当前分配的位数 GOPOverdue=FALSE; 用来控制gop是否迟到,过期可能由于网络原因有些gop阻塞了后来才收到/*field coding*/img->IFLAG=1; 场TotalPFrame=np;P桢数目等于未编码的np数目,因为调用此函数 gop内搜有图像都未编码img->NumberofGOP++;gop数目加1if(img->NumberofGOP==1)第1个GOP取由bpp初始设定的QP值{MyInitialQp=input->SeinitialQP;PreviousQp2=MyInitialQp-1; //recent change -0;QPLastGOP=MyInitialQp;}else{其他GOP的Qp计算公式如下QP=SumPqp/Np-8*Tr(i-1,Ngop)/Tr(i,0)-min{2,Ngop/15}=img->TotalQpforPPicture/img->NumberofPPicture-OverDuantQp-min{2,Ngop/15}/*adaptive field/frame coding*/自适应桢场编码if((input->;PicInterlace==ADAPTIVE_CODING)\||(input->MbInterlace))如何是图像自适应桢场编码,或者宏块是场模式或者宏块是桢场自适应模式{if (img->FieldFrame == 1)如果是幀编码 TotalQpforPPicture加上桢的FrameQPBuffer TotalQpforPPicture表示所有P图像的QP和{img->TotalQpforPPicture += FrameQPBuffer;QPLastPFrame = FrameQPBuffer;}else 场编码{img->TotalQpforPPicture += FieldQPBuffer;QPLastPFrame = FieldQPBuffer;}}/*compute the average QP of P frames in the previous GOP*/计算之前GOP所有P图像中的QP平均值 NumberofPPicture表示P图像数目PAverageQp=(int)(1.0*img->TotalQpforPPicture/img->NumberofPPicture+0.5);GOPDquant=(int)(0.5+1.0*(np+nb+1)/15);对应min{2,Ngop/15}if(GOPDquant>2)GOPDquant=2;PAverageQp-=GOPDquant;if (PAverageQp > (QPLastPFrame - 2)) 为了图像相关性考虑如果平均的QP大于之前P图像的QP-2,减少PAverageQpPAverageQp--;PAverageQp = MAX(QPLastGOP-2, PAverageQp);限定范围在上个GOP的QP值+-2范围内PAverageQp = MIN(QPLastGOP+2, PAverageQp);PAverageQp = MIN(RC_MAX_QUANT, PAverageQp);限定范围在0-51PAverageQp = MAX(RC_MIN_QUANT, PAverageQp);MyInitialQp=PAverageQp;QPLastGOP = MyInitialQp;更新上一个gop的QPPm_Qp=PAverageQp;PAveFrameQP=PAverageQp;PreviousQp1=PreviousQp2;PreviousQp2=MyInitialQp-1;}img->TotalQpforPPicture=0;清TotalQpforPPicture为当前GOP重新QP重新累加用img->NumberofPPicture=0; 当前GOP还没编码编码的P图像数目 NumberofPPicture为0NumberofBFrames=0; 当前GOP还没编码编码的B图像数目 NumberofPPicture为0}作者: kingdexing 时间: 2008-9-18 10:07初始化图像层输入fieldpic=0场编码图像 1 桢编码图像 topfield 1 是顶场void rc_init_pict(int fieldpic,int topfield,int targetcomputation)targetcomputation是否计算目标缓冲等级为1表示计算{int i;/*compute the total number of basic units in a frame*/计算1桢中BU(基本单元)的数目,用1桢中总宏块数目除BU中宏块数 这里说下图像img->BasicUnit和输入参数 input->basicunit区别毕竟在在场模式和桢场自适应模式img->BasicUnit=input->basicunit*2;只有桢模式img->BasicUnit=input->basicunit;也就是说在场模式和桢场自适应模式中BU中宏块数目是2倍只有在桢模式中BU宏块数目if(input->MbInterlace)在场模式和桢场自适应模式TotalNumberofBasicUnit=img->Frame_Total_Number_MB/img->BasicUnit;img->NumberofCodedMacroBlocks=0;当前图像还未编码 所以编码的宏块数目为0/*Normally, the bandwith for the VBR case is estimated bya congestion control algorithm. A bandwidth curve can be predefined if we only want totest the proposed algorithm*/这里为了做VBR(变速率)逻辑测试 定义个带宽的曲线设置 当第59个已编码P图像时候速率 上升到1.5倍 当第60个P图像速率恢复以前 if(input->channel_type==1){if(img->NumberofCodedPFrame==58)bit_rate *=1.5;else if(img->NumberofCodedPFrame==59)PreviousBit_Rate=bit_rate;}/*predefine a target buffer level for each frame*/为每桢图像 预先设置目标缓冲水平if((fieldpic||topfield)&&targetcomputation){switch (img->type){case P_SLICE:P图像因为带宽是实时变化地,所以R中可用位数必须1个图像1个图像地更新按照原理公式Tr(i,j)=Tr(i,j-1)+ (u(i,j)-u(i,j-1))*(Ngop-j)/Fr-b(i,j-1) i代表第i个gop j代表第j个图像Tr是gop中可分配的位元,u是带宽,Fr桢速率,b是已编码产生的位数上面公式这样理解,当前图像可用的位数,等于上一个图像可用位数减去带宽变化和上个图像产生的编码位数/*Since the available bandwidth may vary at any time, the total number ofbits is updated picture by picture*/if(PreviousBit_Rate!=bit_rate)R +=(int) floor((bit_rate-PreviousBit_Rate)*(Np+Nb)/frame_rate+0.5); 是 (u(i,j)-u(i,j-1))*(Ngop-j)/Fr/* predefine the target buffer level for each picture.frame layer rate control*/设定桢层速率控制为每个图像设定缓冲水平TargetBufferLevelTbl(i,2)=Bc(i,2) Bc(i,2)是第i个gop第1个P图像编码完毕后实际缓冲占有率TBL(i,j+1)=TBL(i,j)-Tbl(i,2)/Np-1+AWp(i,j)*(L+1)*u(i,j)/Fr*AWp(i,j)*AWb(i,j)*L-u(i,j)/Fr AWp AWb为了计算复杂度的权if(img->BasicUnit==img->Frame_Total_Number_MB)如果BU内宏块数目等于桢中宏块数目{if(img->NumberofPPicture==1)已经编码一个P图像目标缓冲水平等于当前缓冲占有率 Tbl(i,2)=Bc(i,2){因为起始CurrentBufferFullness=0 GOPTargetBufferLevel=0 更新 CurrentBufferFullness += nbits - bit_rate/frame_rate;编码位数减去流出其实也可以CurrentBufferFullness=BufferSize/8 GOPTargetBufferLevel=BufferSize/8 在带宽波动的情况下留点裕度这样可以保证流体流动通信模型(fluid flow traffic model)HRD缓存是不会向上或者向下溢出的TargetBufferLevel=CurrentBufferFullness;DeltaP=(CurrentBufferFullness-GOPTargetBufferLevel)/(TotalPFrame-1); 这里DeltaP=-Tbl(i,2)/Np-1 GOPTargetBufferLevel=0不考虑了 TargetBufferLevel -=DeltaP; TBL(i,j)-DeltaP}else if(img->NumberofPPicture>1)TargetBufferLevel -=DeltaP; TBL(i,j)-DeltaP}/*basic unit layer rate control*/else{if(img->NumberofCodedPFrame>0)已编码P图像的数目大于0{/*adaptive frame/filed coding*/if(((input->;PicInterlace==ADAPTIVE_CODING)||(input->MbInterlace))\&&(img->FieldControl==1))在图像桢场自适应和宏块场编码或宏块桢场自适应且FieldControl=1场编码情况一句话宏块场编码情况{ TotalNumberofBasicUnit是图像中BU数目注意这里的图像即可以指场图像也可以指桢图像for(i=0;i<TotalNumberofBasicUnit;i++)FCBUPFMAD是之前场控制编码mad,FCBUCFMAD是当前场控制编码madFCBUPFMAD=FCBUCFMAD; 更新之前场控制编码mad,因为该图像已经编码完毕}else{for(i=0;i<TotalNumberofBasicUnit;i++) 桢编码模式 BUPFMAD是之前mad,BUCFMAD是当前madBUPFMAD=BUCFMAD;}}if(img->NumberofGOP==1)第1个gop第2个p图像开始计算tbl{if(img->NumberofPPicture==1)已经编码一个P图像目标缓冲水平等于当前缓冲占有率 Tbl(i,2)=Bc(i,2){因为起始CurrentBufferFullness=0 GOPTargetBufferLevel=0 更新 CurrentBufferFullness += nbits - bit_rate/frame_rate;编码位数减去流出其实也可以CurrentBufferFullness=BufferSize/8 GOPTargetBufferLevel=BufferSize/8 在带宽波动的情况下留点裕度这样可以保证流体流动通信模型(fluid flow traffic model)HRD缓存是不会向上或者向下溢出的TargetBufferLevel=CurrentBufferFullness;DeltaP=(CurrentBufferFullness-GOPTargetBufferLevel)/(TotalPFrame-1);这里DeltaP=-Tbl(i,2)/Np-1 GOPTargetBufferLevel=0不考虑了TargetBufferLevel -=DeltaP; TBL(i,j)-DeltaP}else if(img->NumberofPPicture>1)已当前GOP编码P图像数目大于1个TargetBufferLevel -=DeltaP; TBL(i,j)-DeltaP}else if(img->NumberofGOP>1)第2 3....个GOP第1个P开始就计算tbl用来自GOP的I桢编码后的当前缓冲占有率{if(img->NumberofPPicture==0){TargetBufferLevel=CurrentBufferFullness;DeltaP=(CurrentBufferFullness-GOPTargetBufferLevel)/TotalPFrame;TargetBufferLevel -=DeltaP;}else if(img->NumberofPPicture>0)TargetBufferLevel -=DeltaP;}}AWp和AWb的更新公式AWP=AWp/8+7*Wp/8 AWb=AWb/8+7*Wb/8 Wb=b(i,j)*QPb(i,j)/1.3636 Wp=b(i,j)*QPp(i,j)if(img->NumberofCodedPFrame==1)如果第1个P图像已编码AWp=WpAWp=Wp;如果以编码P图像小于8且大于1 用已编码图像1/NumberofCodedPFrame做加权毕竟已编码P数目小于8,用1/8加权平滑不合适if((img->NumberofCodedPFrame<8)&&(img->NumberofCodedPFrame>1))AWp=Wp*(img->NumberofCodedPFrame-1)/img->NumberofCodedPFrame+\AWp/img->NumberofCodedPFrame;else if(img->NumberofCodedPFrame>1)已编码P图像大于8的话用已编码图像1/8做加权AWP=AWp/8+7*Wp/8AWp=Wp/8+7*AWp/8;//compute the average complexity of B frames这里tbl+=AWp(i,j)*(L+1)*u(i,j)/Fr*AWp(i,j)*AWb(i,j)*L L表示后续B桢数目理解成2个P图像之间B的数目就好input->successive_Bframe就是Lif(input->successive_Bframe>0){//compute the target buffer levelTargetBufferLevel +=(AWp*(input->successive_Bframe+1)*bit_rate\/(frame_rate*(AWp+AWb*input->successive_Bframe))-bit_rate/frame_rate);}break;case B_SLICE:/* update the total number of bits if the bandwidth is changed*/按照原理公式Tr(i,j)=Tr(i,j-1)+ (u(i,j)-u(i,j-1))*(Ngop-j)/Fr-b(i,j-1) if(PreviousBit_Rate!=bit_rate)带宽变动情况下Gop中可用位数R必须修正,修正值u(i,j)-u(i,j-1))*(Ngop-j)/FrR +=(int) floor((bit_rate-PreviousBit_Rate)*(Np+Nb)/frame_rate+0.5);if((img->NumberofCodedPFrame==1)&&(img->NumberofCodedBFrame==1))编码第1个P和编码第1个B图像后如下初始化复杂度参数AWp {AWp=Wp;AWb=Wb;}else if(img->NumberofCodedBFrame>1)如果已编码的B数目大于1{//compute the average weightAWb的更新公式AWb=AWb/8+7*Wb/8 在已编码的B数目大小于8 加权系数取1/NumberofCodedBFrameif(img->NumberofCodedBFrame<8)AWb=Wb*(img->NumberofCodedBFrame-1)/img->NumberofCodedBFrame+\AWb/img->NumberofCodedBFrame;elseAWb=Wb/8+7*AWb/8;}break;}/*Compute the target bit for each frame*/计算每个桢的目标位数,为什么要这一步呢,理解如下如果实际缓冲的等级等同于我们的目标缓冲等级,当然可以保证每个GOP都精确分配到位数,但是R-D模型和mad预测模型是不精确地,导致实际缓冲水平和目标位元等级的误差较大,那么我们需要计算每张图像的目标位数用来降低实际缓冲水平和目标位元之间的误差,这就是细节控制如同往杯子里面倒水,如果要正好倒1升水, 当然1滴1滴倒最好了!if(img->type==P_SLICE) P图像模式{/*frame layer rate control*/if(img->BasicUnit==img->Frame_Total_Number_MB)BU中宏块数目等于桢中宏块数目{if(img->NumberofCodedPFrame>0)已编码的P数目大于1{通过Gop中R可用位数计算T是图像可用位数,公式如下f(i,j)=Wp(i,j-1)*Tr/(Wp(i,j-1)*Np+Wb(i,j-1)*Nb)也就是T = Wp*R/(Np*Wp+Nb*Wb)T = (long) floor(Wp*R/(Np*Wp+Nb*Wb) + 0.5);T是图像可用位数,当然是Gop中R可用位数下面考虑到第i个Gop的第J个图像的目标分配位数由目标缓冲等级Tbl=TargetBufferLevel 实际缓冲区占有率Bc(i,j)=CurrentBufferFullness 频宽u(i,j)=bit_rateGAMMAP在有B图像的情况下GAMMAP=0.25; 无B图像的情况下GAMMAP=0.5;为什么有B图像比无B图像GAMMAP要小,我这样理解,B编码产生位数少,当然需要减去的实际和目标的误差系数小公式f1=u(i,j)/Fr+gamma*(Tbl(i,j)-Bc(i,j))T1 = (long) floor(bit_rate/frame_rate-GAMMAP*(CurrentBufferFullness-TargetBufferLevel)+0.5);T1=MAX(0,T1);目标可用位数f(i,j)由f(i,j)和f1加权得到f(i,j)=beta*f(i,j)+(1-beta)*f1beta在没有B图像情况下beta=0.5 有B图像的情况下是0.9这说明有B图像情况主要由f(i,j)自身决定T = (long)(floor(BETAP*T+(1.0-BETAP)*T1+0.5));}}/*basic unit layer rate control*/基本单元层控制else{if((img->NumberofGOP==1)&&(img->NumberofCodedPFrame>0))第1个GOP并且已编码P数目大于0{通过Gop中R可用位数计算T是图像可用位数,公式如下:f(i,j)=Wp(i,j-1)*Tr/(Wp(i,j-1)*Np+Wb(i,j-1)*Nb)T = (int) floor(Wp*R/(Np*Wp+Nb*Wb) + 0.5);T1 = (int) floor(bit_rate/frame_rate-GAMMAP*(CurrentBufferFullness-TargetBufferLevel)+0.5);T1=MAX(0,T1);T = (int)(floor(BETAP*T+(1.0-BETAP)*T1+0.5));}else if(img->NumberofGOP>1)第2 3 .....个GOP{T = (long) floor(Wp*R/(Np*Wp+Nb*Wb) + 0.5);T1 = (long) floor(bit_rate/frame_rate-GAMMAP*(CurrentBufferFullness-TargetBufferLevel)+0.5);T1 = MAX(0,T1);T = (long)(floor(BETAP*T+(1.0-BETAP)*T1+0.5));}}/*reserve some bits for smoothing*/保留一些位数为了平滑很荒唐吧0.0*input->successive_Bframe估计0.0是个可调系数调整T中可用位数T=(long)((1.0-0.0*input->successive_Bframe)*T);/*HRD consideration*/保证图像可用位数T永远在[LowerBound,UpperBound2]范围内//这里的LowerBound和UpperBound2在图像编码结束后会调用rc_update_pict更新地//通过流出减去编码位数,如果流出大于流入(图像编码位数),瓶子空的更多了表示有更多可用的位数那么当前图像可用位数上下限应该增加 //如果流出大于流入(图像编码位数),表示有可用的位数减少瓶子空间更少了那么当前图像可用位数上下限应该减少//LowerBound +=(long)(bit_rate/frame_rate-nbits);//UpperBound1 +=(long)(bit_rate/frame_rate-nbits); UpperBound2 = (long)(OMEGA*UpperBound1); OMEGA=0.9保证裕度T = MAX(T, (long) LowerBound);T = MIN(T, (long) UpperBound2);if((topfield)||(fieldpic&&((input->;PicInterlace==ADAPTIVE_CODING)\||(input->MbInterlace))))场编码情况T_field=T;}}if(fieldpic||topfield)桢编码或者顶场编码{/*frame layer rate control*/图像层速率控制也叫桢层速率控制img->NumberofHeaderBits=0;还未编码先把头信息位数NumberofHeaderBits和纹理信息位数NumberofTextureBits清0img->NumberofTextureBits=0;/*basic unit layer rate control*/只有在BU中宏块小于桢中宏块数目才存在BU基本单元控制if(img->BasicUnit<img->Frame_Total_Number_MB){TotalFrameQP=0; 图像内所有BU的QP和img->NumberofBasicUnitHeaderBits=0; 头信息位数NumberofHeaderBitsimg->NumberofBasicUnitTextureBits=0;纹理信息位数NumberofTextureBitsimg->TotalMADBasicUnit=0; 图像内所有BU的MAD和TotalMADBasicUnitif(img->FieldControl==0)桢编码NumberofBasicUnit=TotalNumberofBasicUnit;else 场编码NumberofBasicUnit=TotalNumberofBasicUnit/2;}}if((img->type==P_SLICE)&&(img->BasicUnit<img->Frame_Total_Number_MB)\&&(img->FieldControl==1)){/*top filed at basic unit layer rate control*/顶场编码在BU层速率控制if(topfield){bits_topfield=0;T=(long)(T_field*0.6);顶场可用位数//顶场和底场的一共的可用位数T_field 0.6系数说明顶场编码重要性可能作参考场}/*bottom filed at basic unit layer rate control*/else{T=T_field-bits_topfield;场可用的位数T_field减去顶场编码产生的位数bits_topfield得到底场可用的位数img->NumberofBasicUnitHeaderBits=0;头信息位数NumberofHeaderBitsimg->NumberofBasicUnitTextureBits=0;纹理信息位数NumberofTextureBitsimg->TotalMADBasicUnit=0;图像内所有BU的MAD和TotalMADBasicUnitNumberofBasicUnit=TotalNumberofBasicUnit/2;场编码每个场中BU数目自然为桢BU数目的1半}}}作者: kingdexing 时间: 2008-9-18 11:46//calculate MAD for the current macroblock 计算当前宏块的MAD,diff是像素Y原值减去预测值MAD=sum(abs(diff))/256double calc_MAD(){int k,l;int s = 0;double MAD;for (k = 0; k < 16; k++)for (l = 0; l < 16; l++)s+= abs(diffy[k][l]);MAD=s*1.0/256;return MAD;}// update one picture after frame/field encoding在桢场编码后更新一个图像参数void rc_update_pict(int nbits){R-= nbits; /* remaining # of bits in GOP */GOP中剩余可用位数R,必须减去上个图像编码产生位数CurrentBufferFullness += nbits - bit_rate/frame_rate;当前缓冲满度用流入减去流出修正/*update the lower bound and the upper bound for the target bits of each frame, HRD consideration*///通过流出减去编码位数,如果流出大于流入(图像编码位数),瓶子空的更多了表示有更多可用的位数那么当前图像可用位数上下限应该增加 //如果流出大于流入(图像编码位数),表示有可用的位数减少瓶子空间更少了那么当前图像可用位数上下限应该减少LowerBound +=(long)(bit_rate/frame_rate-nbits);UpperBound1 +=(long)(bit_rate/frame_rate-nbits);OMEGA=0.9保证裕度UpperBound2 = (long)(OMEGA*UpperBound1);return;}// update after frame encoding 在桢编码后更新RCvoid rc_update_pict_frame(int nbits){/*update thecomplexity weight of I, P, B frame*/更新I P B的复杂度权int Avem_Qc; Avem_Qc是所有BU的QP平均值int X;/*frame layer rate control*/图象层速率控制I P B的复杂度权Wb=b(i,j)*QPb(i,j)/1.3636 Wp=b(i,j)*QPp(i,j) nbits=b(i,j)if(img->BasicUnit==img->Frame_Total_Number_MB)BU的宏块数目等于桢内宏块数目X = (int) floor(nbits*m_Qc+ 0.5);注意是m_Qc nbits编码产生位数/*basic unit layer rate control*/基本单元层速率控制else{if(img->type==P_SLICE)P图像模式{if(((img->IFLAG==0)&&(img->FieldControl==1))\场编码且不是第1个GOP的第1个I场图像 IFLAG=1可能代表seq的第1个场 ||(img->FieldControl==0))桢编码{Avem_Qc=TotalFrameQP/TotalNumberofBasicUnit;求出平均基本单元QcX=(int)floor(nbits*Avem_Qc+0.5);}}else if(img->type==B_SLICE)B图像模式X = (int) floor(nbits*m_Qc+ 0.5);}//I P B的复杂度权Wb=b(i,j)*QPb(i,j)/1.3636 Wp=b(i,j)*QPp(i,j) nbits=b(i,j)switch (img->type){case P_SLICE:/*filed coding*/if(((img->IFLAG==0)&&(img->FieldControl==1))\\场编码且不是第1个GOP的第1个I场图像||(img->FieldControl==0))桢图像{Xp = X;Np--; 已编码P图像了所以未编码P图像减1Wp=Xp;Pm_Hp=img->NumberofHeaderBits;头信息位数img->NumberofCodedPFrame++;已编码P图像数目NumberofCodedPFrameimg->NumberofPPicture++; 已编码P图像数目NumberofPPicture}else if((img->IFLAG!=0)&&(img->FieldControl==1))第1个GOP的第1个I场图像已经编码,那么此标志清0img->IFLAG=0;break;case B_SLICE:Xb = X;Nb--;已编码B图像了所以未编码P图像减1Wb=Xb/THETA; 来自Wb=b(i,j)*QPb(i,j)/1.3636 THETA=1.3636img->NumberofCodedBFrame++;已编码B图像数目NumberofCodedBFrameNumberofBFrames++; 已编码P图像数目NumberofCodedBFramebreak;}}// coded bits for top field 顶场编码产生的位数bits_topfieldvoid setbitscount(int nbits){bits_topfield = nbits;}作者: kingdexing 时间: 2008-9-18 11:47先休息下,估计要1星期才能把上10万行的代码,完全详细分析完毕!作者: kingdexing 时间: 2008-9-19 13:40//compute a quantization parameter for each frame计算每桢量化参数int updateQuantizationParameter(int topfield){double dtmp;记得初中学过的二次方程式吧其实就是delta=sqrt(b*b-4*a*c)int m_Bits;int BFrameNumber;int StepSize;int PAverageQP;int SumofBasicUnit;int i;/*frame layer rate control*/桢层速率控制if(img->BasicUnit==img->Frame_Total_Number_MB)BU内宏块数目等于桢内宏块数目自然不存在BU控制问题啦{/*fixed quantization parameter is used to coded I frame, the first P frame and the first B framethe quantization parameter is adjusted according the available channel bandwidth andthe type of vide*//*top field*/if((topfield)||(img->FieldControl==0))是顶场或者场控制信号为0{if(img->type==I_SLICE)I条带情况 m_qc取初始值{m_Qc=MyInitialQp;return m_Qc;}else if(img->type==B_SLICE)B条带{if(input->successive_Bframe==1)P与P之间只有1个B情况{successive_Bframe=1对1求余任何整数都是0阿下面的就可笑了,毫无意义BFrameNumber=(NumberofBFrames+1)%input->successive_Bframe;if(BFrameNumber==0)在这里又修正BFrameNumber=1说明BFrameNumber表示在2个P图像中的第几个B图像 真垃圾代码阿BFrameNumber=input->successive_Bframe;因为successive_Bframe=1说明在2个P图像中只有1个B图像BFrameNumber只可能为1/*adaptive field/frame coding*/else if(BFrameNumber==1){当L=1表示2个P图像之间有1个B图像公式如下:QB1=(QP1+QP2+2)/2 当QP1!=QP2QB1=QP1+2 当QP1 =QP2if((input->icInterlace==ADAPTIVE_CODING)\||(input->MbInterlace)){if(img->FieldControl==0)场控制关闭{/*previous choice is frame coding*/if(img->FieldFrame==1)之前选择是桢编码{PreviousQp1=PreviousQp2;例如P1B1P2B2P3当前是B1则PreviousQp1代表P1图像,PreviousQp2=P2PreviousQp2=FrameQPBuffer;}/*previous choice is field coding*/else之前选择是场编码{PreviousQp1=PreviousQp2;PreviousQp2=FieldQPBuffer;}}}}// m_Qc=QB1=(QP1+QP2+2)/2 当QP1!=QP2// m_Qc=QB1=QP1+2 当QP1 =QP2if(PreviousQp1==PreviousQp2)m_Qc=PreviousQp1+2;elsem_Qc=(PreviousQp1+PreviousQp2)/2+1;m_Qc = MIN(m_Qc, RC_MAX_QUANT); // clipping钳位0-51m_Qc = MAX(RC_MIN_QUANT, m_Qc);//clipping}else{//L=successive_Bframe>1 下面求余就有意义了说明BFrameNumber表示在2个P图像中的第几个B图像这样举例把L=2 PB1B2PB3B4P那么NumberofBFrames=2已编码的B数目是2那么当前是第3个B实际B3,BFrameNumber=1在实际P与P的位置是1已编码的B数目是3那么当前是第3个B实际B3,BFrameNumber=2通过对后续B的数目求余求得当前B在P 与P的位置BFrameNumber=(NumberofBFrames+1)%input->successive_Bframe;if(BFrameNumber==0)上面再NumberofBFrames=3时候求于地BFrameNumber=0必须修正为2BFrameNumber=input->successive_Bframe;/*adaptive field/frame coding*/else if(BFrameNumber==1){ 更新之前两个P图像的QP值因为是第1个B所以需要更新,其他B与第1个B采用的参考P是一致的作考虑if((input->icInterlace==ADAPTIVE_CODING)\||(input->MbInterlace))图像自适应编码或帧编码{if(img->FieldControl==0)场控制信号关闭当前图像可以使桢编码也可以是场编码{ 更新之前两个P图像的QP值/*previous choice is frame coding*/if(img->FieldFrame==1)图像选择是桢编码 {PreviousQp1=PreviousQp2;PreviousQp2=FrameQPBuffer;}/*previous choice is field coding*/else图像选择是场编码{PreviousQp1=PreviousQp2;PreviousQp2=FieldQPBuffer;}}}}当L>1表示两张P图像插入多张B图像公式如下:QBi=QP1+alpha+max{min{(QP2-QP1)/(L-1),2*(i-1)},-2*(i-1)}alpha取值如下:alpha=-3 if QP2-QP1<=-2*L-3alpha=-2 if QP2-QP1=-2*L-2alpha=-1 if QP2-QP1=-2*L-1alpha=0 if QP2-QP1=-2*Lalpha=1 if QP2-QP1=-2*L+1alpha=2 其他情况为什么需要alpha=StepSize修正QB,估计是按照2个P图像的Qp差deltaQ和L的关系,做个平滑处理,避免图像质量差别过大if((PreviousQp2-PreviousQp1)<=(-2*input->successive_Bframe-3))StepSize=-3;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe-2))StepSize=-2;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe-1))StepSize=-1;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe))StepSize=0;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe+1))StepSize=1;elseStepSize=2;m_Qc=PreviousQp1+StepSize;下面按照max{min{(QP2-QP1)/(L-1),2*(i-1)},-2*(i-1)}修正 估计保证播放顺序靠近第1个P的修正更加接近第1个P的Qp,接近第2个P图像的修正更加接近第2个P的Qp,也是为了做个平滑处理,避免图像质量差别过大m_Qc +=MIN(2*(BFrameNumber-1),MAX(-2*(BFrameNumber-1), \(BFrameNumber-1)*(PreviousQp2-PreviousQp1)/(input->successive_Bframe-1)));m_Qc = MIN(m_Qc, RC_MAX_QUANT); // clipping钳位0-51m_Qc = MAX(RC_MIN_QUANT, m_Qc);//clipping}return m_Qc;}else if((img->type==P_SLICE)&&(img->NumberofPPicture==0))当前是P图像并且已编码的P图像数目是0{m_Qc=MyInitialQp; MyInitialQp是GOP的QPif(img->FieldControl==0)场控制关闭{if(active_sps->frame_mbs_only_flag)只有桢模式桢宏块编码{img->TotalQpforPPicture +=m_Qc;TotalQpforPPicture表示GOP内已编码P图像Qp和PreviousQp1=PreviousQp2;更新2个P图像QcPreviousQp2=m_Qc;Pm_Qp=m_Qc;}/*adaptive field/frame coding*/自适应桢场模式elseFrameQPBuffer=m_Qc; FrameQPBuffer桢QP缓冲}return m_Qc;}else{/*adaptive field/frame coding*/if(((input->icInterlace==ADAPTIVE_CODING)\图像自适应桢场模式||(input->MbInterlace))\宏块场模式或自适应桢场模式&&(img->FieldControl==0))场控制关闭{/*previous choice is frame coding*/if(img->FieldFrame==1)桢模式{img->TotalQpforPPicture +=FrameQPBuffer;TotalQpforPPicture表示GOP内已编码P图像Qp和Pm_Qp=FrameQPBuffer;}/*previous choice is field coding*/else场模式{img->TotalQpforPPicture +=FieldQPBuffer;Pm_Qp=FieldQPBuffer;}}下面是2次r-d模型系数具体模型推导由taylor级数推导以后有时间相信写个RD模型推导(R-H)/MAD=C1/Qstep+C2/(Qstep*Qstep) 这里m_X1 m_X2就是C1 C2这里是(T-H)/MAD=MADPictureC1/Qstep+MADPictureC2/(Qstep*Qstep)m_X1=Pm_X1;m_X2=Pm_X2;m_Hp=PPreHeader;之前的头信息位数m_Qp=Pm_Qp;m_QP是m_可能代表宏块,因为BU宏块等于桢宏块数目,所以m_qp等于P图像Pm_Qp//PDuantQp=2;估计可用于对图像Qpc=min{Qpp+2,max(Qpp-2,Qpc)}进行clip,保证图像层Qpc在之前图像Qpp+-2范围内//保证当前和之前图像质量相差不大DuantQp=PDuantQp;MADPictureC1=PMADPictureC1; PMADPictureC1是预测MADMADPictureC2=PMADPictureC2; PMADPictureC2是预测MADPreviousPictureMAD=PPictureMAD[0]reviousPictureMAD之前图像MAD/* predict the MAD of current picture*/预测当前图像MADMADc=a1*MADp+a2 MADPictureC1=a1 MADPictureC2=a2 MADp是前1张图像对应位置的MAD,预测待编码基本单元的MAD 因为BU宏块等于桢宏块数目,所以直接用图像的MAD值PreviousPictureMADCurrentFrameMAD=MADPictureC1*PreviousPictureMAD+MADPictureC2;/*compute the number of bits for the texture*/if(T<0)T是图像可用位数,如果小于0,需要调大当前图像QP,减少位数{m_Qc=m_Qp+DuantQp;调大当前图像QPm_Qc = MIN(m_Qc, RC_MAX_QUANT); // clipping保证不大于最大量化步长51}else{公式(T-H)/MAD=MADPictureC1/Qstep+MADPictureC2/(Qstep*Qstep)m_Bits =T-m_Hp;去除头信息//MINVALUE=4.0; 在基本单元层分配基本单元的位数R R= MAX(R, (int)(bit_rate/(MINVALUE*frame_rate*TotalNumberofBasicUnit))); //这里TotalNumberofBasicUnit=1所以不存在基本单元层直接如下拉m_Bits = MAX(m_Bits, (int)(bit_rate/(MINVALUE*frame_rate)));dtmp = CurrentFrameMAD * m_X1 * CurrentFrameMAD * m_X1 \ //dtmp是2次方程式delta如果这都不懂回去练初中+ 4 * m_X2 * CurrentFrameMAD * m_Bits;//下面是2次方程式求解初中数学不详细推了if ((m_X2 == 0.0) || (dtmp < 0) || ((sqrt (dtmp) - m_X1 * CurrentFrameMAD) <= 0.0)) // fall back 1st order modem_Qstep = (float) (m_X1 * CurrentFrameMAD / (double) m_Bits);else // 2nd order modem_Qstep = (float) ((2 * m_X2 * CurrentFrameMAD) / (sqrt (dtmp) - m_X1 * CurrentFrameMAD));量化步长m_Qstep和量化索引QP关系:量化索引+6那么量化步长翻倍!量化索引+1那么量化索引增加12.5%和我们的uniform均一量化有区别吧具体为什么可能由于概率密度函数决定地量化概率分布和失真的关系吧求出0-51的量化索引m_qc吧m_Qc=Qstep2QP(m_Qstep);下面是保证+-2和1-51量化钳位保证图像质量前后差别不大,量化参数不超过上下限m_Qc = MIN(m_Qp+DuantQp, m_Qc); // control variationm_Qc = MIN(m_Qc, RC_MAX_QUANT); // clippingm_Qc = MAX(m_Qp-DuantQp, m_Qc); // control variationm_Qc = MAX(RC_MIN_QUANT, m_Qc);}if(img->FieldControl==0)场信号控制关闭{/*frame coding*/if(active_sps->frame_mbs_only_flag)只有宏块桢模式{img->TotalQpforPPicture +=m_Qc;TotalQpforPPicture表示GOP内已编码P图像Qp和 PreviousQp1=PreviousQp2;2个P图像的QP中间参数更新PreviousQp2=m_Qc;Pm_Qp=m_Qc;}/*adaptive field/frame coding*/自适应桢场模式elseFrameQPBuffer=m_Qc;}return m_Qc;}}/*bottom field*/底场不说了写到手麻else{if((img->type==P_SLICE)&&(img->IFLAG==0)){/*field coding*/if(input->icInterlace==FIELD_CODING){img->TotalQpforPPicture +=m_Qc;PreviousQp1=PreviousQp2+1;PreviousQp2=m_Qc;//+0 Recent change 13/1/2003Pm_Qp=m_Qc;}/*adaptive field/frame coding*/elseFieldQPBuffer=m_Qc;}return m_Qc;}}/*basic unit layer rate control*/基本单元速率控制下面和前面基本相似不多少说了作者: kingdexing 时间: 2008-9-19 13:46看我写的h.264代码理解基本每句都能帮助你理解把代码当小说看就不会累了人为什么看小说1天能1本看代码不行呢就是因为你是热爱喜欢还是功利性质地想懂!作者: kingdexing 时间: 2008-9-19 21:25/*basic unit layer rate control*/基本单元速率控制下面和前面基本相似不多少说了else{/*top filed of I frame*/if(img->type==I_SLICE)I图像{m_Qc=MyInitialQp;直接用GOP的QPreturn m_Qc;}/*bottom field of I frame*/是P条带场控制开启//还有待修改注释else if((img->type==P_SLICE)&&(img->IFLAG==1)&&(img->FieldControl==1)){m_Qc=MyInitialQp;直接用GOP的QPreturn m_Qc;}else if(img->type==B_SLICE)B条带{/*top filed of B frame*/顶场if((topfield)||(img->FieldControl==0))场控制关闭{if(input->successive_Bframe==1){BFrameNumber只能为1前面已经分析过了BFrameNumber=(NumberofBFrames+1)%input->successive_Bframe;if(BFrameNumber==0)BFrameNumber=input->successive_Bframe;/*adaptive field/frame coding*/else if(BFrameNumber==1){if((input->PicInterlace==ADAPTIVE_CODING)\图像自适应桢场编码||(input->MbInterlace))宏块自适应或场编码{if(img->FieldControl==0){ 更新之前两个P图像的QP值/*previous choice is frame coding*/if(img->FieldFrame==1)当前图像是桢编码{PreviousQp1=PreviousQp2;PreviousQp2=FrameQPBuffer;}/*previous choice is field coding*/else当前图像是场编码{PreviousQp1=PreviousQp2;PreviousQp2=FieldQPBuffer;}}}}// m_Qc=QB1=(QP1+QP2+2)/2 当QP1!=QP2// m_Qc=QB1=QP1+2 当QP1 =QP2if(PreviousQp1==PreviousQp2)m_Qc=PreviousQp1+2;elsem_Qc=(PreviousQp1+PreviousQp2)/2+1;m_Qc = MIN(m_Qc, RC_MAX_QUANT); // clipping钳位0-51m_Qc = MAX(RC_MIN_QUANT, m_Qc);//clipping}else后续B桢大于1的情况{//BFrameNumber只能为1-successive_Bframe前面已经分析过了,代表2个P之间第几个B图像BFrameNumber=(NumberofBFrames+1)%input->successive_Bframe;if(BFrameNumber==0)BFrameNumber=input->successive_Bframe;/*adaptive field/frame coding*/else if(BFrameNumber==1){if((input->PicInterlace==ADAPTIVE_CODING)\||(input->MbInterlace))图像自适应编码或帧编码{更新之前两个P图像的QP值if(img->FieldControl==0){/*previous choice is frame coding*/if(img->FieldFrame==1){PreviousQp1=PreviousQp2;PreviousQp2=FrameQPBuffer;}/*previous choice is field coding*/else{PreviousQp1=PreviousQp2;PreviousQp2=FieldQPBuffer;}}}}参见前面写的alpha取值和为什么要这样取值if((PreviousQp2-PreviousQp1)<=(-2*input->successive_Bframe-3))StepSize=-3;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe-2))StepSize=-2;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe-1))StepSize=-1;else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe))StepSize=0;//0else if((PreviousQp2-PreviousQp1)==(-2*input->successive_Bframe+1))StepSize=1;//1elseStepSize=2;//2m_Qc=PreviousQp1+StepSize;//保证播放顺序靠近第1个P的修正更加接近第1个P的Qp,//接近第2个P图像的修正更加接近第2个P的Qp,也是为了做个平滑处理,避免图像质量差别过大m_Qc +=MIN(2*(BFrameNumber-1),MAX(-2*(BFrameNumber-1), \(BFrameNumber-1)*(PreviousQp2-PreviousQp1)/(input->successive_Bframe-1)));m_Qc = MIN(m_Qc, RC_MAX_QUANT); // clipping钳位0-51m_Qc = MAX(RC_MIN_QUANT, m_Qc);//clipping}return m_Qc;}/*bottom field of B frame*/elsereturn m_Qc;}else if(img->type==P_SLICE)P条带{if((img->NumberofGOP==1)&&(img->NumberofPPicture==0))第1个GOP并且已经编码P数目为0,也就是GOP中所有P图像都还没编码时候 {if((img->FieldControl==0)||((img->FieldControl==1)\&&(img->IFLAG==0))){/*top field of the first P frame*/第1个P的顶场,取GOP的QP初始值,因为P未编码,索以把基本单元内头信息NumberofBasicUnitHeaderBits和纹理信息NumberofBasicUnitTextureBits都清零m_Qc=MyInitialQp;img->NumberofBasicUnitHeaderBits=0;img->NumberofBasicUnitTextureBits=0;NumberofBasicUnit--;BU数目减1/*bottom field of the first P frame*/第1个P的底场if((!topfield)&&(NumberofBasicUnit==0)){/*frame coding or field coding*/if((active_sps->frame_mbs_only_flag)||(input->PicInterlace==FIELD_CODING))只有宏块桢编码或者图像场编码{img->TotalQpforPPicture +=m_Qc;当前P的Qc总数和更新PreviousQp1=PreviousQp2;PreviousQp2=m_Qc;PAveFrameQP=m_Qc;介绍下PAveHeaderBits2 PAveHeaderBits3 PAveHeaderBits1吧用于计算所有单元的头信息的位数Mhdrl第l个基本单元实际产生的头信息位数AveMhdrl=AveMhdrl*(1-1/l)+Mhdrl/l 可见l=1时AveMhdrl=MhdrlPMhdrl是前一章图像所有基本单元预测得到地 PMhdrl=AveMhdrl/Nunit+PMhdrl*(1-1/Nunit)初始化PMhdrl=0PAveHeaderBits2是表示预测BU的头信息位数也就是平均BU的头信息位数PAveHeaderBits3=PAveHeaderBits2;}/*adaptive frame/field coding*/else if((input->PicInterlace==ADAPTIVE_CODING)\||(input->MbInterlace)){if(img->FieldControl==0){FrameQPBuffer=m_Qc;FrameAveHeaderBits=PAveHeaderBits2;平均BU的头信息位数}else{FieldQPBuffer=m_Qc;FieldAveHeaderBits=PAveHeaderBits2;平均BU的头信息位数}}}Pm_Qp=m_Qc;。