哈夫曼树重复元素
哈夫曼编码解码 原理

哈夫曼编码解码原理
哈夫曼编码是一种被广泛使用的无损数据压缩算法。
该算法的基本思想是根据字符出现的频率,构建一个哈夫曼树,然后利用该树对字符进行编码。
编码的过程是将每个字符映射为哈夫曼树上的一个叶子节点,然后沿着从根节点到叶子节点的路径输出该字符的编码。
由于频率高的字符被分配了较短的编码,而频率低的字符被分配了较长的编码,因此哈夫曼编码可以达到较高的压缩效率。
哈夫曼树的构建过程如下:
1. 将所有的字符按照出现的频率排序,从小到大。
2. 取出频率最小的两个字符,构建一棵二叉树,根节点的权值为这两个字符的频率之和,左右子树分别对应这两个字符。
3. 将刚才取出的两个字符从频率表中删除,将新构建的二叉树的权值加入频率表中。
4. 重复 2、3 步,直到频率表中只剩下一个元素,也就是哈夫曼树的根节点。
哈夫曼树构建完成后,即可对字符进行编码和解码。
编码过程是将每个字符映射为哈夫曼树上的一个叶子节点,然后沿着从根节点到叶子节点的路径输出该字符的编码。
解码过程是从哈夫曼树的根节点开始,按照编码的序列走下去,直到遇到一个叶子节点,即可输出对应的字符。
总之,哈夫曼编码是一种简单而有效的数据压缩算法,它可以在不损失数据信息的情况下,大大减小数据的存储空间。
【算法总结】哈夫曼树

【算法总结】哈夫曼树在⼀棵树中,从任意⼀个结点到达另⼀个结点的通路被称为路径,该路径上所需经过的边的个数被称为该路径的长度。
若树中结点带有表⽰某种意义的权值,那么从根结点到达该节点的路径长度再乘以该结点权值被称为该结点的带权路径长度。
树所有的叶⼦结点的带权路径长度和为该树的带权路径长度和。
给定 n 个结点和它们的权值,以它们为叶⼦结点构造⼀棵带权路径和最⼩的⼆叉树,该⼆叉树即为哈夫曼树,同时也被称为最优树。
给定结点的哈夫曼树可能不唯⼀,所以关于哈夫曼树的机试题往往需要求解的是其最⼩带权路径长度和。
回顾⼀下我们所熟知的哈夫曼树求法(原理很容易理解,就是把⼩的往下放)。
1.将所有结点放⼊集合 K。
2.若集合 K 中剩余结点⼤于 2 个,则取出其中权值最⼩的两个结点,构造他们同时为某个新节点的左右⼉⼦,该新节点是他们共同的双亲结点,设定它的权值为其两个⼉⼦结点的权值和。
并将该⽗亲结点放⼊集合 K。
重复步骤 2 或 3。
3.若集合 K 中仅剩余⼀个结点,该结点即为构造出的哈夫曼树数的根结点,所有构造得到的中间结点(即哈夫曼树上⾮叶⼦结点)的权值和即为该哈夫曼树的带权路径和。
为了⽅便快捷⾼效率的求得集合 K 中权值最⼩的两个元素,我们需要使⽤堆数据结构。
它可以以 O(logn)的复杂度取得 n 个元素中的最⼩元素。
为了绕过对堆的实现我们使⽤标准模板库中的相应的标准模板——优先队列。
:有4 个结点 a, b, c, d,权值分别为 7, 5, 2, 4,试构造以此 4 个结点为叶⼦结点的⼆叉树。
根据给定的n个权值{w1,w2,…,wn}构成⼆叉树集合F={T1,T2,…,Tn},其中每棵⼆叉树Ti中只有⼀个带权为wi的根结点,其左右⼦树为空.在F中选取两棵根结点权值最⼩的树作为左右⼦树构造⼀棵新的⼆叉树,且置新的⼆叉树的根结点的权值为左右⼦树根结点的权值之和.在F中删除这两棵树,同时将新的⼆叉树加⼊F中.重复,直到F只含有⼀棵树为⽌.(得到哈夫曼树)利⽤语句priority_queue<int> Q;建⽴⼀个保存元素为 int 的堆 Q,但是请特别注意这样建⽴的堆其默认为⼤顶堆,即我们从堆顶取得的元素为整个堆中最⼤的元素。
数据结构第六章 哈夫曼树
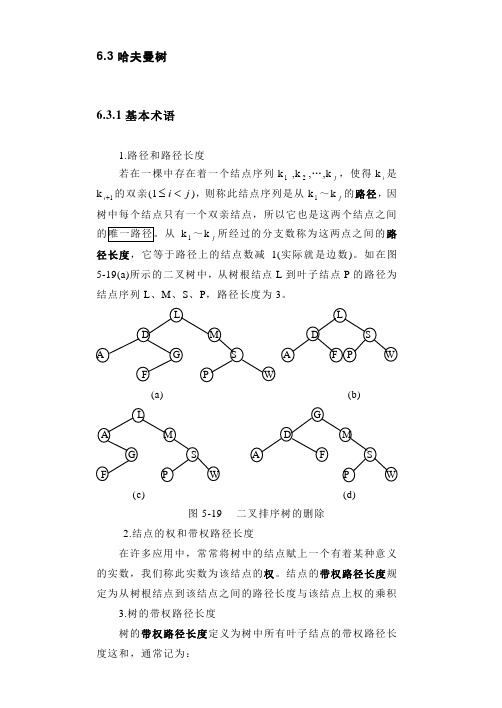
6.3哈夫曼树6.3.1基本术语1.路径和路径长度若在一棵中存在着一个结点序列k1 ,k2,…,kj,使得ki是k1+i 的双亲(1ji<≤),则称此结点序列是从k1~kj的路径,因树中每个结点只有一个双亲结点,所以它也是这两个结点之间k 1~kj所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1(实际就是边数)。
如在图5-19(a)所示的二叉树中,从树根结点L到叶子结点P的路径为结点序列L、M、S、P,路径长度为3。
(a) (b)(c) (d)图5-19 二叉排序树的删除2.结点的权和带权路径长度在许多应用中,常常将树中的结点赋上一个有着某种意义的实数,我们称此实数为该结点的权。
结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘积3.树的带权路径长度树的带权路径长度定义为树中所有叶子结点的带权路径长度这和,通常记为:2 WPL = ∑=n i i i lw 1其中n 表示叶子结点的数目,i w 和i l 分别表示叶子结点i k 的权值和根到i k 之间的路径长度 。
4.哈夫曼树哈夫曼(Huffman)树又称最优二叉树。
它是n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树。
因为构造这种树的算法是最早由哈夫曼于1952年提出的,所以被称之为哈夫曼树。
例如,有四个叶子结点a 、b 、c 、d ,分别带权为9、4、5、2,由它们构成的三棵不同的二叉树(当然还有其它许多种)分别如图5-20(a)到图5-20(c)所示。
b ac a b cd d c a b d(a) (b) (c)图5-20 由四个叶子结点构成的三棵不同的带权二叉树 每一棵二叉树的带权路径长度WPL 分别为:(a) WPL = 9×2 + 4×2 + 5×2 + 2×2 = 40(b) WPL = 4×1 + 2×2 + 5×3 + 9×3 = 50(c) WPL = 9×1 + 5×2 + 4×3 + 2×3 = 37其中图5-20(c)树的WPL 最小,稍后便知,此树就是哈夫曼树。
最优二叉树(哈夫曼树)的构建及编码

最优⼆叉树(哈夫曼树)的构建及编码参考:数据结构教程(第五版)李春葆主编⼀,概述1,概念 结点的带权路径长度: 从根节点到该结点之间的路径长度与该结点上权的乘积。
树的带权路径长度: 树中所有叶结点的带权路径长度之和。
2,哈夫曼树(Huffman Tree) 给定 n 个权值作为 n 个叶⼦结点,构造⼀棵⼆叉树,若该树的带权路径长度达到最⼩,则称这样的⼆叉树为最优⼆叉树,也称为哈夫曼树。
哈夫曼树是带权路径长度最短的树,权值较⼤的结点离根较近。
⼆,哈夫曼树的构建1,思考 要实现哈夫曼树⾸先有个问题摆在眼前,那就是哈夫曼树⽤什么数据结构表⽰? ⾸先,我们想到的肯定数组了,因为数组是最简单和⽅便的。
⽤数组表⽰⼆叉树有两种⽅法: 第⼀种适⽤于所有的树。
即利⽤树的每个结点最多只有⼀个⽗节点这种特性,⽤ p[ i ] 表⽰ i 结点的根节点,进⽽表⽰树的⽅法。
但这种⽅法是有缺陷的,权重的值需要另设⼀个数组表⽰;每次找⼦节点都要遍历⼀遍数组,⼗分浪费时间。
第⼆种只适⽤于⼆叉树。
即利⽤⼆叉树每个结点最多只有两个⼦节点的特点。
从下标 0 开始表⽰根节点,编号为 i 结点即为 2 * i + 1 和 2 * i + 2,⽗节点为 ( i - 1) / 2,没有⽤到的空间⽤ -1 表⽰。
但这种⽅法也有问题,即哈夫曼树是从叶结点⾃下往上构建的,⼀开始树叶的位置会因为⽆法确定⾃⾝的深度⽽⽆法确定,从⽽⽆法构造。
既然如此,只能⽤⽐较⿇烦的结构体数组表⽰⼆叉树了。
typedef struct HTNode // 哈夫曼树结点{double w; // 权重int p, lc, rc;}htn;2,算法思想 感觉⽐较偏向于贪⼼,权重最⼩的叶⼦节点要离根节点越远,⼜因为我们是从叶⼦结点开始构造最优树的,所以肯定是从最远的结点开始构造,即权重最⼩的结点开始构造。
所以先选择权重最⼩的两个结点,构造⼀棵⼩⼆叉树。
然后那两个最⼩权值的结点因为已经构造完了,不会在⽤了,就不去考虑它了,将新⽣成的根节点作为新的叶⼦节加⼊剩下的叶⼦节点,⼜因为该根节点要能代表整个以它为根节点的⼆叉树的权重,所以其权值要为其所有⼦节点的权重之和。
头歌赫夫曼树及其应用实践

头歌赫夫曼树及其应用实践头歌赫夫曼树是一种特殊的哈夫曼树算法,它在图像压缩、数据传输、数据存储等方面得到广泛应用。
本文将介绍头歌赫夫曼树的原理、构建方法以及应用实践。
一、头歌赫夫曼树的原理头歌赫夫曼树是由美国计算机科学家J. L. Bentley和A. J. Heineman在1986年所提出的算法。
该算法的核心思想是根据数据源中的出现频率来构建一棵哈夫曼树,使得重复次数多的数据用较短的编码表示,而出现较少的则用更长的编码表示。
头歌赫夫曼树相较于普通的哈夫曼树,使用的是无损压缩技术,将数据源的压缩结果保持无误的情况下完成数据压缩。
二、头歌赫夫曼树的构建方法头歌赫夫曼树的构建方法主要分为两个步骤:哈夫曼树的构建和头歌操作。
1. 哈夫曼树的构建(1)将数据源中的所有元素按照出现频率的高低进行排序,出现频率越高的排名越靠前。
(2)依次将排名靠前的两个元素作为一组,其中出现频率较高的元素为根节点,出现频率较低的元素为叶子节点。
将该组元素从数据源中删除,并将新生成的节点加入数据源。
(3)重复执行(1)和(2),直到数据源中只剩下一棵哈夫曼树。
2. 头歌操作头歌操作是在树的基础上,使用二进制位操作来达成哈夫曼编码。
(1)记录每个叶子节点所代表的字符和二进制编码。
(2)从根节点到叶子节点,如果在这条路径上向左走,则将下一位的二进制编码设为0,向右走则为1。
(3)将所有叶子节点的二进制编码连接起来,以形成数据源压缩后的结果。
三、头歌赫夫曼树的应用实践头歌赫夫曼树已经广泛应用于图像压缩、数据传输、数据存储等方面,以下是头歌赫夫曼树在这些领域的具体应用实践。
1. 图像压缩头歌赫夫曼树可以将图像中重复出现的像素点压缩为一个代表像素点的数据,从而达到压缩图像的效果,提高图像传输和存储的效率。
2. 数据传输头歌赫夫曼树可以将传输的数据进行压缩,缩短传输时间,减少传输量,有效地减轻传输负担。
3. 数据存储头歌赫夫曼树可以将数据存储为压缩格式,占用的存储空间更小,提高存储效率。
哈夫曼树和哈夫曼编码(数据结构程序设计)

课程设计(数据结构)哈夫曼树和哈夫曼编码二○○九年六月二十六日课程设计任务书及成绩评定课题名称表达式求值哈夫曼树和哈夫曼编码Ⅰ、题目的目的和要求:巩固和加深对数据结构的理解,通过上机实验、调试程序,加深对课本知识的理解,最终使学生能够熟练应用数据结构的知识写程序。
(1)通过本课程的学习,能熟练掌握几种基本数据结构的基本操作。
(2)能针对给定题目,选择相应的数据结构,分析并设计算法,进而给出问题的正确求解过程并编写代码实现。
Ⅱ、设计进度及完成情况Ⅲ、主要参考文献及资料[1] 严蔚敏数据结构(C语言版)清华大学出版社 1999[2] 严蔚敏数据结构题集(C语言版)清华大学出版社 1999[3] 谭浩强 C语言程序设计清华大学出版社[4] 与所用编程环境相配套的C语言或C++相关的资料Ⅳ、成绩评定:设计成绩:(教师填写)指导老师:(签字)二○○九年六月二十六日目录第一章概述 (1)第二章系统分析 (2)第三章概要设计 (3)第四章详细设计及实现代码 (8)第五章调试过程中的问题及系统测试情况 (12)第六章结束语 (13)参考文献 (13)第一章概述课程设计是实践性教学中的一个重要环节,它以某一课程为基础,可以涉及和课程相关的各个方面,是一门独立于课程之外的特殊课程。
课程设计是让同学们对所学的课程更全面的学习和应用,理解和掌握课程的相关知识。
《数据结构》是一门重要的专业基础课,是计算机理论和应用的核心基础课程。
数据结构课程设计,要求学生在数据结构的逻辑特性和物理表示、数据结构的选择和应用、算法的设计及其实现等方面,加深对课程基本内容的理解。
同时,在程序设计方法以及上机操作等基本技能和科学作风方面受到比较系统和严格的训练。
在这次的课程设计中我选择的题目是表达式求值和哈夫曼树及哈夫曼编码。
这里我们介绍一种简单直观、广为使用的算法,通常称为“算符优先法”。
哈夫曼树又称最优树,是一类带权路径长度最短的树,有着广泛的应用。
哈夫曼树

F
K
11110
111111 110
F 24
0
Z 2
1
K 7
L
U
Z
100
111110
哈夫曼编码的效率。
我们定义该编码方案的平均编码长度为: B(T)=(c1p1+ c2p2 +…+ cnpn)/pt 其中: ci和pi是字符集中第i个字符的代码长度及 其相对频率,pt是字符集的总频率。对本例计算平 均编码长度≈2.565 若采用固定长度编码,每个字母需log28=3位, 而哈夫曼编码只需2.565位,节省空间约12%。 哈夫曼编码对于典型的文本文件将比ASCII编 码节省约40%的空间。
用途:用于通信和数据传送中字符的二进制编码,可以 使文件编码总长度最短。 例字符集: C D E F K L U Z 频 率:32 42 120 24 7 42 37 2
306
0
1 186
C D E
1110 101 0
E 79 0 1 120 0 U D 37 42
1 107 1 65 0 1 L 0 33 42 C 0 1 9
哈夫曼树及其应用
1.问题的提出
在程序设计中,常用一个代码来表示一个 元素,标准ASCII码就是一个例子。它用log2128 即7位提供了128个不同的代码来表示ASCII表中 的128个字符。假设所有代码都等长,则表示n 个不同的代码需要log2n位,称为固定长度编码 (如ASCII码)。如果每个字符的使用频率相等, 则固定长度编码的空间效率最高。但事实上,每 个字符的使用频率并非一样。
if (socre<60) printf(“bad”); else if (socre<70) printf(“pass”); else if (score<80) printf(“general”); else if (score<90) printf(“good”); esle printf(“very good”);
哈夫曼算法的理解及原理分析算法实现构造哈夫曼树的算法

哈夫曼算法的理解及原理分析算法实现构造哈夫曼树的算法哈夫曼算法(Huffman Algorithm)是一种贪心算法,用于构建最优二叉树(也称为哈夫曼树或者最优前缀编码树),主要用于数据压缩和编码。
它通过统计字符出现的频率来构建一个编码表,将较频繁出现的字符用较短的编码表示,从而减少存储空间和传输带宽。
原理分析:1.统计字符出现的频率:遍历待编码的字符串,统计每个字符出现的次数。
2.构建哈夫曼树:根据字符频率构建二叉树,频率越高的字符位置越靠近根节点,频率越低的字符位置越远离根节点。
构建哈夫曼树的通常做法是使用最小堆来存储频率,并反复合并堆中最小的两个节点,直到堆中只剩一个节点,即根节点。
3.生成编码表:从根节点开始,沿着左子树为0,右子树为1的路径将所有叶子节点的编码存储在一个编码表中。
算法实现:下面是一个简单的Python实现示例:```pythonclass Node:def __init__(self, char, freq):self.char = charself.freq = freqself.left = Noneself.right = Nonedef build_huffman_tree(text):#统计字符频率freq_dict = {}for char in text:if char in freq_dict:freq_dict[char] += 1else:freq_dict[char] = 1#构建最小堆heap = []for char, freq in freq_dict.items(: node = Node(char, freq)heap.append(node)heap.sort(key=lambda x: x.freq)#构建哈夫曼树while len(heap) > 1:left = heap.pop(0)right = heap.pop(0)parent = Node(None, left.freq + right.freq) parent.left = leftparent.right = rightheap.append(parent)heap.sort(key=lambda x: x.freq)root = heap[0]#生成编码表code_table = {}generate_code(root, "", code_table)return code_tabledef generate_code(node, code, code_table):if node.char:code_table[node.char] = codereturngenerate_code(node.left, code + "0", code_table) generate_code(node.right, code + "1", code_table) ```构造哈夫曼树的算法:上述的 `build_huffman_tree` 函数通过统计频率构建了最小堆`heap`,然后不断地合并最小的两个节点,直到堆中只剩下一个节点,即哈夫曼树的根节点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
哈夫曼树重复元素
哈夫曼树是一种重要的数据结构,在信息编码和压缩领域有广泛的应用。
它是一种特殊的二叉树,用于实现无损数据压缩。
在哈夫曼树中,重复元素会被合并,从而达到压缩数据的目的。
哈夫曼树的构建过程非常有趣。
首先,我们需要统计每个元素的出现频率。
这些频率可以用来决定元素在哈夫曼树中所占的位置。
频率越高的元素将被放置在更靠近根节点的位置,而频率较低的元素则会被放置在更远离根节点的位置。
接下来,我们需要将这些元素按照频率从小到大进行排序。
在排序完成后,我们将选择频率最低的两个元素,合并它们,生成一个新的节点。
这个节点的频率将等于这两个元素的频率之和。
然后,我们将这个新节点插入到原来的序列中,并重新排序。
重复这个过程,直到只剩下一个节点,即树的根节点。
通过这个过程,我们可以看到重复元素是如何被合并的。
在合并的过程中,频率较低的元素会被合并到频率较高的元素中,从而减少了重复元素的数量。
这样一来,我们就能够实现对数据进行压缩的目的,同时保证了数据的完整性。
在实际应用中,哈夫曼树被广泛用于数据压缩。
通过将重复元素合并,我们可以大大减少数据的存储空间。
例如,在文本文件中,某些字符的出现频率非常高,而其他字符的出现频率非常低。
通过使
用哈夫曼树,我们可以将高频字符用较短的编码表示,而将低频字符用较长的编码表示。
这样一来,我们就能够在不损失数据的情况下,大幅度减少文件的大小。
除了数据压缩,哈夫曼树还有其他的应用。
例如,在通信领域,哈夫曼树可以用于实现最优编码方式,从而提高数据传输的效率。
在图像处理领域,哈夫曼树可以用于实现图像的无损压缩,从而减小图像文件的大小。
在网络领域,哈夫曼树可以用于实现路由表的最优选择,从而提高网络传输的速度。
哈夫曼树是一种非常重要的数据结构,通过合并重复元素,实现了对数据的压缩和编码。
它在信息编码、压缩和通信领域有广泛的应用。
通过合理地构建和利用哈夫曼树,我们可以在保证数据完整性的同时,大幅度减小数据的存储空间和传输带宽。
这使得哈夫曼树成为了现代信息技术中不可或缺的一部分。