常用语种代码
中国语种代码_代码表
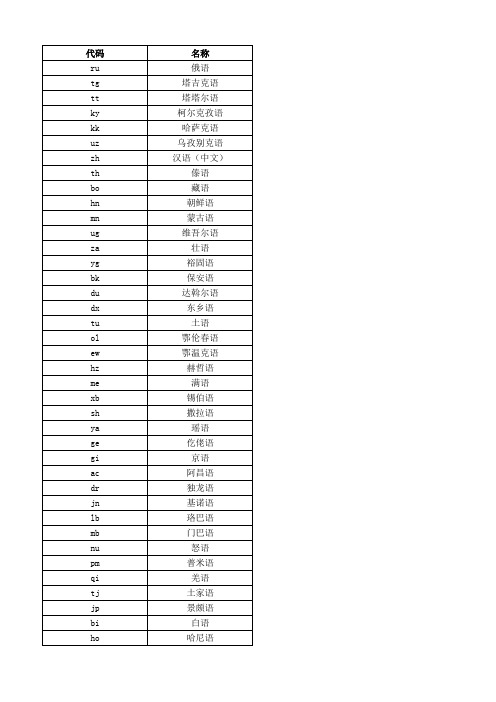
名称 俄语 塔吉克语 塔塔尔语 柯尔克孜语 哈萨克语 乌孜别克语 汉语(中文) 傣语 藏语 朝鲜语 蒙古语 维吾尔语 壮语 裕固语 保安语 达斡尔语 东乡语 土语 鄂伦春语 鄂温克语 赫哲语 满语 锡伯语 撒拉语 瑶语 仡佬语 京语 阿昌语 独龙语 基诺语 珞巴语 门巴语 怒语 普米语 羌语 土家语 景颇语 白语 哈
nx
纳西语
yi
彝语
li
黎语
do
侗语
mm
仫佬语
mu
毛难语
sy
水语
by
布依语
mh
苗语
bb
崩龙语
bl
布朗语
va
佤语
gs
高山语
部标代码含义表

附件6:部标代码含义表(1)ZZMMDM(政治面貌代码):01中共党员02中共预备党员03共青团员04民革会员05民盟盟员06民建会员07民进会员08农工党党员09致公党党员 10九三学社社员 11台盟盟员 12无党派民主人士13群众(2)MZDM(民族代码):01汉族02蒙古族03回族04藏族05维吾尔族06苗族07彝族08壮族09布依族 10朝鲜族11满族12侗族13瑶族14白族15土家族16哈尼族17哈萨克族 18傣族19黎族20傈傈族21佤族22畲族23高山族 24拉祜族 25水族26东乡族27纳西族 28景颇族 29柯尔克孜 30土族31达斡尔族32仫佬族 33羌族34布朗族 35撤拉族36毛难族37仡佬族 38锡伯族 39阿昌族40普米族41塔吉克族42怒族43乌孜别克 44俄罗斯族 45鄂温克族46崩龙族47保安族48裕固族49京族50塔塔尔族51独龙族52鄂伦春族 53赫哲族 54门巴族 55珞巴族56基诺族97其他98外国血统中国籍人士注:以上民族中未包含的少数民族归并到其他类(97)。
(3)KSLBDM(考生类别代码):1城市应届 2农村应届 3城市往届 4农村往届注:凡已获得中等学历教育证书一年(含)以上者均为往届,其他归并为应届。
(4)KSLXDM(考试类型代码):O春季统考 1秋季统考 2保送3小语种4二学位5实践青年 6职教师资 7运动训练、民族传统体育8高职班9自定义项(单考)注:“KSLXDM”为9的各省自定义项须有明确含义,并报教育部备案,建议作为高职班(单考)的补充码,以便考务工作中编排单考应试科类。
(5)BYLBDM(毕业类别代码):0普通高中毕业 1中等师范毕业 2其他中等专业学校毕业3职业高中毕业 4技工学校毕业 5其他中等学历教育毕业6高职(专科)学历教育毕业7本科(含)以上学历教育毕业注:从初中毕业生中招收的“五年一贯制”等中等学历教育毕业直升者,均属其他中等学历教育毕业,并在转入高等学历教育当年参加高考报名,考生类别归为应届毕业生。
中文图书机读目录数据(MARC)处理细则

中文图书机读目录数据(MARC)处理细则中文图书机读目录数据(MARC)处理细则前言本手册为中文图书机读目录数据处理细则的简化版,主要使用对象是本系统内初期建立中文图书机读目录的工作人员。
本文编写是以中华人民共和国国家标准《文献著录总则》(GB3792.1)、《普通图书著录规则》(GB3792.2)为依据,同时参照了《国际标准书目著录》(ISBD)相关内容及《中国文献编目规则》(广东人民出版社 1996年出版)等文献。
机读目录格式是以《中国机读目录格式》(WH/T0503-96)为依据,并按字段标识号顺序叙述。
本手册未做详细叙述的部分请参照上述所列的国家及国际标准。
填写各功能块的信息源著录信息源来自文献本身,如文献本身信息不足时,可参考其它资料。
取自文献本身以外的著录信息或编目员自拟的著录信息均须加方括号。
与所著录文献具有永久性联系的信息源优先于仅有临时性联系或易失的信息源。
中文图书著录项目的规定信息源如下:著录项目规定信息源书名与责任说明项书名页或版权页、封面版本项版权页或书名页、封面、出版说明等处出版发行项版权页或书名页、封面、出版说明等处载体形态项整部图书及附件丛书项整部图书附注项任何信息源标准编号与获得方式项任何信息源常用名词术语1、字段:由字段标识符标识的被定义的字符串,它可以包含一个或多个子字段。
2、可变长安段:长度不定的字段,字段长度因字段描述的内容不同而变化。
3、固定长字段:长度固定的字段,字段长度不因字段描述的内容不同而变化。
4、必备字段:机读目录必需具有的字段。
5、可重复性:表示字段可以在一条机读目录中重复使用。
6、字段标识符:用于识别各个字段的三位数字,也称字段号。
7、字段指示符:与变长字段联用的字符,形式为数字或字母。
提供有关字段内容、字段间的关系等及一些附加信息。
8、子字段:字段内所定义的数据单元。
9、子字段标识符:由两个字符组成的代码,用以识别变长字段中的不同子字段。
1--编码信息块

100字段——通用处理数据
(5)修改记录代码(字符位置21) 这种情况可以认为是修改记录,用1位字 符代码表示。若题名页上出现其它字符 集也没有收入的符号或图形,因而无法 照录,则不认为记录已被修改。 0=未修改的记录 1=已修改的记录
2013-7-12 21
100字段——通用处理数据
本字段定长,包含的编码数据适 用于任何载体文献的记录。对所 有在编文献,本字段均为必备, 且不可重复。 指示符有两个。这两个指示符都 是空(未定义)
2013-7-12 3
100字段——通用处理数据
包含子字段$a $a以字符位置标识全部数据。字符 位从0-35计数,共包含36个字符。 $a不可重复。各数据元素字符位置、 占字符数及名称如下:
(3)阅读对象代码(17-19) 用三位字符表示使用对象。 从左至右顺序填写,不足三位时用 空位表示。
2013-7-12
12
100字段——通用处理数据
(3)阅读对象代码(17-19) a = 普通青少年(不用或不能用b、c、 d、e时,用此代码) b = 学龄前儿童(0-5岁) c = 小学生(5-10岁) d = 少年(9-14岁)
1—编码信息块
2013-7-12
1
介绍内容
普通图书编目常用的字段包括 100 通用处理数据 101 文献语种 102 出版或制作国别 105 编码数据:专著性文字资料 106 编码数据:文字资料—形态特征 123 编码数据:测绘制图资料—比例 尺与坐标
2013-7-12 2
100字段——通用处理数据
2013-7-12
15
100字段——通用处理数据
(3)阅读对象代码(17-19) d =初中 de=青少年读物 em=高中(高、中等教材,普及读物) emk=研究生(一般研究,字典) km=学术性较强 k=学术性很强
民族、性别代码 语种代码

1 2
1汉语、2维语、 3哈语、4蒙语、 5柯语、6民考汉 、7维双语、8哈 双语、9蒙双语 、0柯双语
1汉语言
2维语言 3哈语言 4蒙语言 5柯语言 6民考汉 7维双语 8哈双语 9蒙双语 0柯双语
01 02 03 04 05 06 07 08 09 10 11 12
ห้องสมุดไป่ตู้
汉族 蒙古族 回族 藏族 维吾尔族 苗族 彝族 壮族 布依族 朝鲜族 满族 侗族 性别代码 男 女 语种代码
13 14 15 16 17 18 19 20 21 22 23 24
瑶族 白族 土家族 哈尼族 哈萨克族 傣族 黎族 傈傈族 佤族 畲族 高山族 拉祜族
民族代码 25 水族 26 东乡族 27 纳西族 28 景颇族 29 柯尔克孜族 30 土族 31 达斡尔族 32 仫佬族 33 羌族 34 布朗族 35 撒拉族 36 毛难族
37 仡佬族 49 京族 38 锡伯族 50 塔塔尔族 39 阿昌族 51 独龙族 40 普米族 52 鄂伦春族 41 塔吉克族 53 赫哲族 42 怒族 54 门巴族 43 乌孜别克族 55 珞巴族 44 俄罗斯族 56 基诺族 45 鄂温克族 46 崩龙族 97 其他 47 保安族 外国血统中 98 48 裕固族 国籍人士
GBT48801991语种名称代码新

GB/T4880-1991《语种名称代码》语种名称代码语种名称代码阿布哈兹语ab芬兰语fi 阿尔巴尼亚语sq弗里西亚语fy 阿法尔语aa格陵兰语kl 阿芳·奥洛莫语om格鲁吉亚语ka 阿非利堪斯语af古吉拉特语gu 阿拉伯语ar瓜拉尼语gn 阿姆哈拉语am国际语A ia 阿萨姆语as国际语E ie 阿塞拜疆语az哈萨克语kk 艾马拉语ay汉语(中文)zh 爱尔兰语ga豪萨语ha 爱沙尼亚语et荷兰语nl 奥克西唐语oc吉尔吉斯语ky 奥利亚语or基尼阿万达语rw 巴什基尔语ba基隆迪语rn 巴斯克语eu加利西亚语gl 白俄罗斯语be加泰隆语ca 保加利亚语bg柬埔寨语km 比哈尔语bh捷克语cs 比斯拉玛语bi凯楚亚语qu 冰岛语is坎纳达语kn 波兰语pl克罗地亚语hr 波斯语fa克什米尔语ks 不丹语dz科萨语xh 布列塔尼语br科西嘉语co 朝鲜语ko库尔德语ku 傣语th拉丁语la 丹麦语da拉脱维亚语lv 德语de老挝语lo 俄语ru立陶宛语lt 法语fr利托-罗曼语rm 法罗斯语fo林加拉语ln 梵语sa罗马尼亚语ro 斐济语fj马达加斯加语mg马耳他语mt塔塔尔语tt 马拉提语mr泰米尔语ta 马拉亚拉姆语ml泰卢固语te 马来语ms汤加语to 马其顿语mk特威语tw 毛利语mi提格里尼亚语ti 蒙古语mn土耳其语tr 孟加拉语bn土库曼语tk 缅甸语my威尔士语cy 摩尔达维亚语mo维吾尔语ug 挪威语no沃拉普克语vo 瑙鲁语na沃洛夫语wo 尼泊尔语ne乌尔都语ur 旁遮普语pa乌克兰语uk 普什图语ps乌兹别克语uz 葡萄牙语pt西班牙语es 其他语言zz希伯来语iw 日语ja希腊语el 瑞典语sv信德语sd 塞茨瓦纳语tn匈牙利语hu 塞尔维亚语sr巽他语su 塞尔维亚-克罗地亚语sh亚美尼亚语hy 塞斯瓦替语ss意大利语it 塞索托语st依地语ji 桑戈语sg依努庇克语ik 僧加罗语si印地语hi 萨摩亚语sm印尼语in 绍纳语sn英语en 世界语eo约鲁巴语yo 斯洛伐克语sk越南语vi 斯洛文尼亚语sl藏语bo 斯瓦希里语sw爪哇语jv 苏格兰语gd壮语za 索马里语so宗加语ts 他加禄语tl祖鲁语zu 塔吉克语tg。
中国机读目录格式
– 如:00957oam2#2200289###450#
执行代码
由4位字符构成,字符位:6-9;分别定义记录类型、书 目级别、层次等级代码;第9位字符未定义,用“#”表示。
– 记录类型
• 《 中国机读目录使用手册》规定了14种记录类型代码。 • 如:00957oam2#2200289 ### 450#
– 可检字段与不可检字段
200 1#$a西游录$f(元)耶律楚才著$c异域志$f(元)周致中著
有关概念
数据字段区所含的数据有如下两种形式
• 数据控制字段——定长字段(00X)结构:
数据
字段分隔符
• 变长字段(010—999)结构 :
字段指示符 1 字段指示符 2 $a
数据 ……
字段分隔符
200 1#$a西游录$f(元)耶律楚才著
内容标识符
字段指示符
• 指与变长字段相关的字符(数字和字母),它提供有关可变长 字段的内容、记录中不同字段的关系及某些数据处理过程中所 需操作的附加信息。
如:200 题名与责任说明字段 0# 题名无意义 1# 题名有意义
子字段标识符
• 由2个字符组成的代码,用以识别可变长字段中不同的子字段。 • 第一个字符用$表示;第二个字符可以用数字或字母
中国机读目录格式
主要内容
CNMARC机读记录的逻辑结构 记录头标 地址目次区 数据字段区 常用字段的使用方法
第一节 CNMARC机读记录的逻辑结构
CNMARC机读记录结构如下
区域 记录头标 地址目次区
记录 数据字段区
记录分隔符
功能块 0----标识块 1----编码信息块 2----著录信息块—— 3----附注块 4----款目连接块 5----相关题名块 6----主题分析块 7----知识责任块 8----国际使用块 9----国内使用块
常用ASCII码对照表
常用ASCII码对照表1. ASCII码在计算机内部,所有的信息最终都表示为一个二进制的字符串;每一个二进制位bit有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节byte;也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到;上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定;这被称为ASCII码,一直沿用至今;ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32十进制的32,用二进制表示就是00100000,大写的字母A是65二进制01000001;这128个符号包括32个不能打印出来的控制符号,只占用了一个字节的后面7位,最前面的1位统一规定为0;2、非ASCII编码英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的;比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示;于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号;比如,法语中的é的编码为130二进制;这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号;但是,这里又出现了新的问题;不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样;比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel ,在俄语编码中又会代表另一个符号;但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段;至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右;一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号;比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号;正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号;因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码;为什么电子邮件常常出现乱码就是因为发信人和收信人使用的编码方式不一样;解释:同一个文本文件,假设内容是用英语写的,在英语编码的情况下,每个字符会和一个二进制数对应如00101000类似,然后存到计算机中,这时把这个英语文件发给一个俄语国家的用户,计算机传输的是二进制流,即0101之类的数据,到了俄语用户这方,需要有它的俄语编码方式进行解码,把每个二进制流转为字符显示,由于俄语编码表中对每串二进制流数据的解释方式不同,同一个数据如00101000在英语中可能代表A,而在俄语中则代表B,这样就会产生乱码,这是我个人的理解;GB2312编码、日文编码等也是非unicode编码,是要通过转换表codepage转换成unicode 编码的,要不怎么显示出来呢可以想象,如果有一种编码,将世界上所有的符号都纳入其中;每一个符号都给予一个独一无二的编码,那么乱码问题就会消失;这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码;Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号;每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”;具体的符号对应表,可以查询,或者专门的;4. Unicode的问题需要注意的是,Unicode只是一个符号集,只是一种规范、标准,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储在计算机上;比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位01,也就是说这个符号的表示至少需要2个字节;表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多;这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的;它们造成的结果是:1出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode;2unicode在很长一段时间内无法推广,直到互联网的出现;互联网的普及,强烈要求出现一种统一的编码方式;UTF-8就是在互联网上使用最广的一种unicode的实现方式;其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用;重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一,它规定了字符如何在计算机中存储、传输等;UTF-8最大的一个特点,就是它是一种变长的编码方式;它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度;UTF-8的编码规则很简单,只有二条:1对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码;因此对于英语字母,UTF-8编码和ASCII码是相同的;2对于n字节的符号n>1,第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10;剩下的没有提及的二进制位,全部为这个符号的unicode码;下表总结了编码规则,字母x表示可用编码的位;Unicode符号范围 | UTF-8编码方式十六进制 | 二进制--------------------+---------------------------------------------0000 0000-0000 007F | 0xxxxxxx0000 0080-0000 07FF | 110xxxxx 10xxxxxx0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx下面,还是以汉字“严”为例,演示如何实现UTF-8编码;已知“严”的unicode是4E2501,根据上表,可以发现4E25处在第三行的范围内0000 0800-0000 FFFF,因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”;然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0;这样就得到了,“严”的UTF-8编码是“10100101”,这是保存在计算机中的实际数据,转换成十六进制就是E4B8A5,转成十六进制的目的为了便于阅读;6. Unicode与UTF-8之间的转换通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的;它们之间的转换可以通过程序实现;在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序;打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最底部有一个“编码”的下拉条;里面有四个选项:ANSI,Unicode,Unicode big endian 和 UTF-8;1ANSI是默认的编码方式;对于英文文件是ASCII编码,对于简体中文文件是GB2312编码只针对Windows简体中文版,如果是繁体中文版会采用Big5码;2Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码;这个选项用的little endian格式;3Unicode big endian编码与上一个选项相对应;我在下一节会解释little endian和big endian的涵义;4UTF-8编码,也就是上一节谈到的编码方法;选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了;7. Little endian和Big endian上一节已经提到,Unicode码可以采用UCS-2格式直接存储;以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25;存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式;那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“ZERO WIDTH NO-BREAK SPACE,用FEFF表示;这正好是两个字节,而且FF比FE大1;如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式;8. 实例下面,举一个实例;打开”记事本“程序,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存;然后,用文本编辑软件的”十六进制功能“,观察该文件的内部编码方式;1ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的;2Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25;3Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储;4UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的;推荐这篇文章看一下:解决的问题:一、如何在中文系统中运行非Unicode编码程序有很多意大利文版除英文版学习软件、百科全书等软件在中文系统上会出现乱码,解决方法:WindowsXP内核是Unicode编码,支持多语种,对于Unicode编码的应用程序会正常显示原文因为windows核心是用unicode代码写的,所以不存在问题,但是,很多程序不是用Unicode编码写的,这时WindowsXP系统可以指定以特定的编码运行非Unicode编码程序,中文版WindowsXP默认的是“简体中文GB2312”;你只需在控制面板--〉区域和语言选项--〉高级--〉为非Unicode程序的语言选择“意大利语”,即可正确运行意大利文版的游戏程序;分析:我理解的流程是这样:程序------>意大利语编码转换表codepage------>解释成unicode识别的编码通过指定的转换表将非 Unicode 的字符编码转换为同一字符对应的系统内部使用的 Unicode 编码------>被系统翻译成意大利文因为每个unicode编码对应了相应的意大利文字,便可以正常显示了;二、消除网页乱码网页乱码是浏览器对HTML网页解释时形成的,如果网页制作时编码为繁体big5,浏览器却以编码gb2312显示该网页,就会出现乱码,因此只要你在浏览器中也以繁体big5显示该网页,就会消除乱码;打个比方有些像字典,繁体字得用繁体字典来查看,简体字得用简体字典来查看,不然你看不懂;解决办法:在浏览器中选择“编码”菜单,事先为浏览器安装多语言支持包例如在安装IE时要安装多语言支持包,这样当浏览网页出现乱码时,即可手工更改查看此网页的编码方式,在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文GB2312,如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文BIG5,其他语言依此类推,便可消除网页乱码现象;分析:因为繁体big5编码后的文件,每个文字对应一个二进制流假设是1212对应繁这个字,当我们以编码gb2312显示该网页时,gb2312编码会到表里去找1212二进制流不会变的对应谁,肯定不再是繁这个字了,当然显示的就不再是那个繁字了,也就会出现乱码了;这样理解简单些,其实中间还要转换成同一字符对应的系统内部使用的Unicode 编码,然后通过系统底层unicode编码还原成相应字符显示出来;推荐两个编码查询网站:1. 2.ASCII 表上的数字 0–31 分配给了控制字符,用于控制像打印机等一些外围设备;例如,12 代表换页/新页功能;此命令指示打印机跳到下一页的开头;ASCII 非打印控制字符表十进制十六进制字符十进制十六进制字符000空1610数据链路转意101头标开始1711设备控制 1202正文开始1812设备控制 2303正文结束1913设备控制 3404传输结束2014设备控制 4505查询2115反确认606确认2216同步空闲707震铃2317传输块结束808backspace2418取消909水平制表符2519媒体结束100A换行/新行261A替换110B竖直制表符271B转意120C换页/新页281C文件分隔符130D回车291D组分隔符140E移出301E记录分隔符150F移入311F单元分隔符ASCII 打印字符数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现;数字127 代表 DELETE 命令;ASCII 打印字符表十进制十六进制字符十进制十六进制字符3220space8050P33218151Q3422"8252R35238353S3624$8454T3725%8555U3826&8656V 3927'8757w 40288858X 41298959Y 422A905A Z 432B+915B 442C,925C\ 452D-935D 462E.945E^472F/955F_483009660`493119761a513339963c 5234410064d 5335510165e 5436610266f 5537710367g 5638810468h 5739910569i593B;1076B k 603C<1086C l 613D=1096D m 623E>1106E n 633F1116F o 644011270p 6541A11371q6642B11472r 6743C11573s 6844D11674t 6945E11775u 7046F11876v 7147G11977w 7248H12078x 7349I12179y744A J1227A z754B K1237B{764C L1247C|774D M1257D}784E N1267E~794F O1277F DEL扩展 ASCII 打印字符扩展的 ASCII 字符满足了对更多字符的需求;扩展的 ASCII 包含 ASCII 中已有的 128 个字符数字 0–32 显示在下图中,又增加了 128 个字符,总共是 256 个;即使有了这些更多的字符,许多语言还是包含无法压缩到 256 个字符中的符号;因此,出现了一些 ASCII的变体来囊括地区性字符和符号;例如,许多软件程序把 ASCII 表又称作 ISO 8859-1用于北美、西欧、澳大利亚和非洲的语言;扩展的ASCII 打印字符表十进制十六进制字符十进制十六进制字符12880192C0└12981ü193C1┴13082é194C2┬13284196C4─13385à197C5┼13486198C6╞13587199C7╟13688ê200C8╚13789201C9╔1388Aè202CA╩1408C204CC╠1418Dì205CD═1428E206CE╬1438F207CF╧14490é208D0╨14591209D1╤14692210D2╥14894212D4 14995ò213D5╒15096214D6╓15197ù215D7╫15298216D8╪15399217D9┘1549Aü218DA┌1559B219DB█1569C£220DC▄1579D¥221DD▌1589E222DE 1599F223DF160A0á224E0α161A1í225E1162A2ó226E2Γ164A4228E4Σ165A5229E5σ166A6a230E6μ167A7o231E7τ168A8232E8Φ169A9233E9Θ170AA234EAΩ172AC236EC∞173AD237EDφ174AE238EEε175AF239EF∩176B0240F0≡177B1241F1±178B2▓242F2≥180B4┤244F4 181B5╡245F5 182B6╢246F6÷183B7╖247F7≈184B8╕248F8≈185B9╣249F9 186BA║250FA·187BB╗251FB√188BC╝252FC189BD╜253FD2190BE╛254FE■191BF┐255FFAA 0001100018取消000011000C 换页/新页A6 a CA╩E5σ010******* T 00110001311 010*******U 010011004C L 0010010125% 010*******SC5┼010******* TB10001000111设备控制 1AA AA1818取消0C0C 换页/新页A6A6 a CA CA╩E5E5σ5454 T 31311 5555U4C4C L 2525%1B1B转意0101头标开始。
语种名称代码2字母代码_代码表
加泰隆语 科西嘉语
捷克语 威尔士语
丹麦语 德语 不丹语 希腊语 英语 世界语 西班牙语 爱沙尼亚语 巴斯克语 波斯语 芬兰语 斐济语 法罗斯语 法语 弗里西亚语 爱尔兰语 苏格兰语 加利西亚语 瓜拉尼语
转成国标
gu
古吉拉特语
ha
豪萨语
hi
印地语
hr
克罗地亚语
hu
匈牙利语
hy
亚美尼亚语
rw
基尼阿万达语
sa
梵语
sd
信德语
sg
桑戈语
sh
塞尔维亚-克罗地亚语
si
僧加罗语
sk
斯洛伐克语
sl
斯洛文尼亚语
sm
萨摩亚语
sn
绍纳语
so
索马里语
sq
阿尔巴尼亚语
sr
塞尔维亚语
ss
塞斯瓦替语
st
塞索托语
su
巽他语
sv
瑞典语
sw
斯瓦希里语
ta
泰米尔语
te
泰卢固语
tg
塔吉克语
th
傣语
ti
提格里尼亚语
tk
土库曼语
毛利语
mk
马其顿语
ml
马拉亚拉姆语
mn
蒙古语
mo
摩尔达维亚语
mr
马拉提语
ms
马来语
mt
马耳他语
my
缅甸语
na
瑙鲁语
ne
尼泊尔语
nl
芬兰语
no
挪威语
oc
奥克西唐语
om
阿芳·奥洛莫语
or
奥利亚语
pa
string常见编码格式
String 常见编码格式本文介绍 String 常见的编码格式,包括 UTF-8、UTF-16、UTF-32 以及ASCII 等,并分析它们的特点和使用场景。
下面是本店铺为大家精心编写的3篇《String 常见编码格式》,供大家借鉴与参考,希望对大家有所帮助。
《String 常见编码格式》篇1在计算机中,字符串是一种常见的数据类型。
字符串的编码方式决定了字符串在内存中的存储方式和传输方式。
本文将介绍几种常见的字符串编码格式。
1. UTF-8UTF-8 是一种可变长度的编码方式,它使用 1 到 4 个字节来编码字符。
UTF-8 编码支持全球所有的字符,包括中文、英文、数字和特殊符号等。
UTF-8 编码的特点是,对于亚洲语言,它的编码长度比其他编码方式更短,因此更加节省空间。
UTF-8 编码已经成为了字符串编码的默认标准。
2. UTF-16UTF-16 是一种固定长度的编码方式,它使用 2 个字节来编码字符。
UTF-16 编码支持全球所有的字符,包括中文、英文、数字和特殊符号等。
UTF-16 编码的特点是,对于亚洲语言,它的编码长度比UTF-8 编码方式更长,因此会占用更多的空间。
但是,UTF-16 编码可以提供更快的文本渲染速度,因为它的编码方式可以更好地支持Unicode 字符集。
3. UTF-32UTF-32 是一种固定长度的编码方式,它使用 4 个字节来编码字符。
UTF-32 编码支持全球所有的字符,包括中文、英文、数字和特殊符号等。
UTF-32 编码的特点是,它的编码长度最长,因此会占用最多的空间。
但是,UTF-32 编码可以提供最准确的文本渲染速度和字符支持,因为它的编码方式可以直接映射到 Unicode 字符集中的每个字符。
4. ASCIIASCII 是一种固定的编码方式,它使用 1 个字节来编码字符。
ASCII 编码只能支持基本的英文字母、数字和一些特殊符号,不能支持中文和其他亚洲语言。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
阿尔巴尼亚语alb 汉语chi 斯洛伐克语slo 阿拉伯语ara 荷兰语dut 世界语esp 埃及语egy 哈萨克语kaz 泰国语tha 保加利亚语bul 捷克语cze 土耳其语tur 冰岛语ice 吉尔吉斯语kir 维吾尔语uig 波兰语pol 拉丁语lat 希腊语gre 波斯语per 老挝语lao 希伯来语heb 朝鲜语kor 罗马尼亚语rum 西班牙语spa 丹麦语dan 缅甸语bur 匈牙利语hun 德语ger 孟加拉语ben 叙利亚语syr 多种语mul 蒙古语mon 印度语inc 俄语rus 挪威语nor 印尼语ind 法语fre 尼泊尔语nep 英语eng 梵语san 葡萄牙语por 瑶族语yao 刚果语kon 日语jpn 越南语vie 柬埔寨语cam 瑞典语swe 意大利语Ita
白语bay 柯尔克孜语kir 普米语pum 布依语buy 朝鲜语kor 藏语tib 傣语dai 拉祜语lah 维吾尔语uig 侗语don 僳僳语lis 佤语way 哈尼语han 满语man 锡伯语xib
京语jin 苗语mia 瑶语yao 景颇语jip 蒙语mon 彝语yiz 哈萨克语kaz 纳西语nax 壮语zhu。